AI projects often stall when models can’t deliver results at the speed and scale users expect. In this webinar, discover how Red Hat OpenShift AI and Redis combine to supercharge performance and unlock new possibilities for real-time AI.
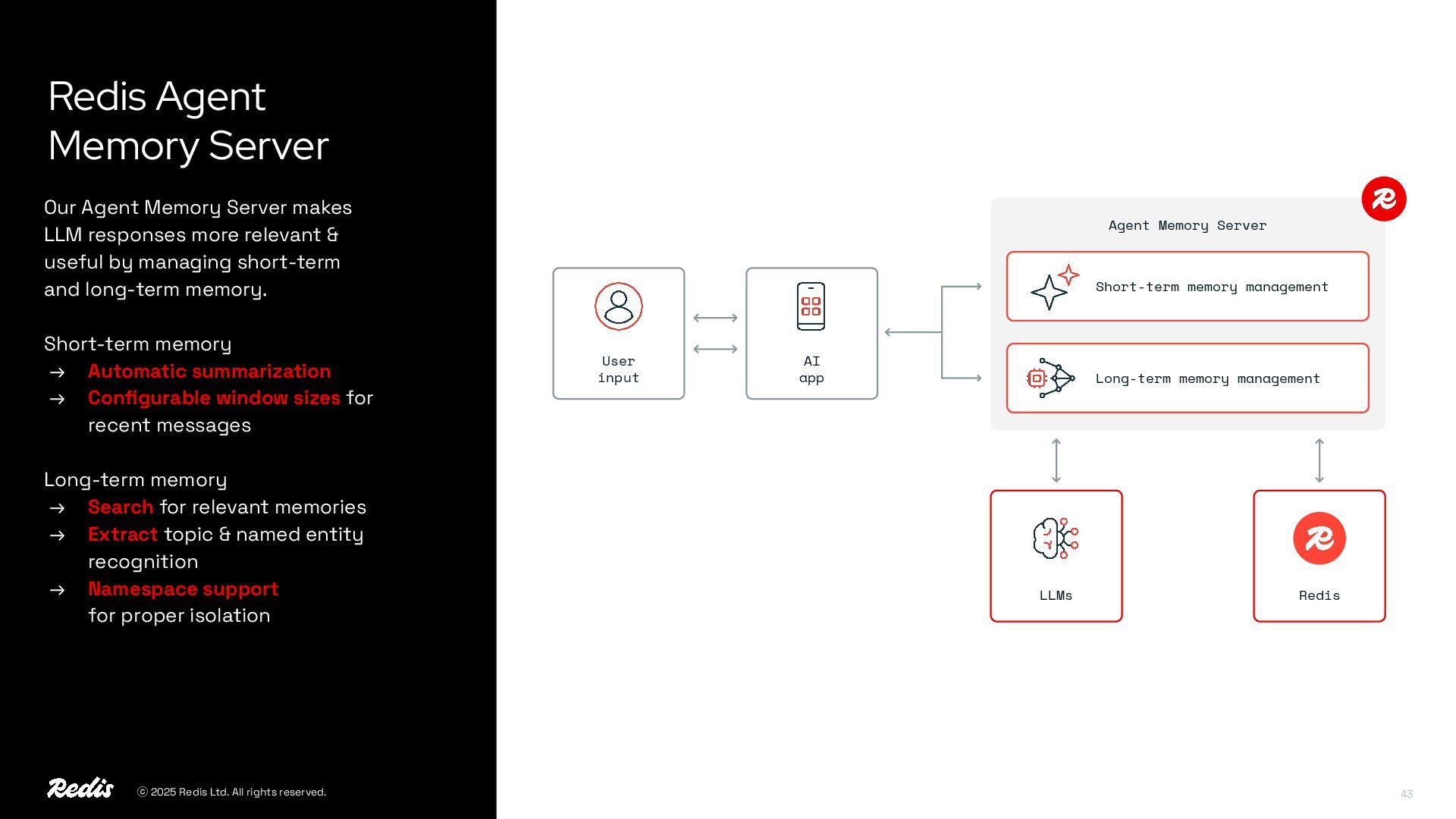
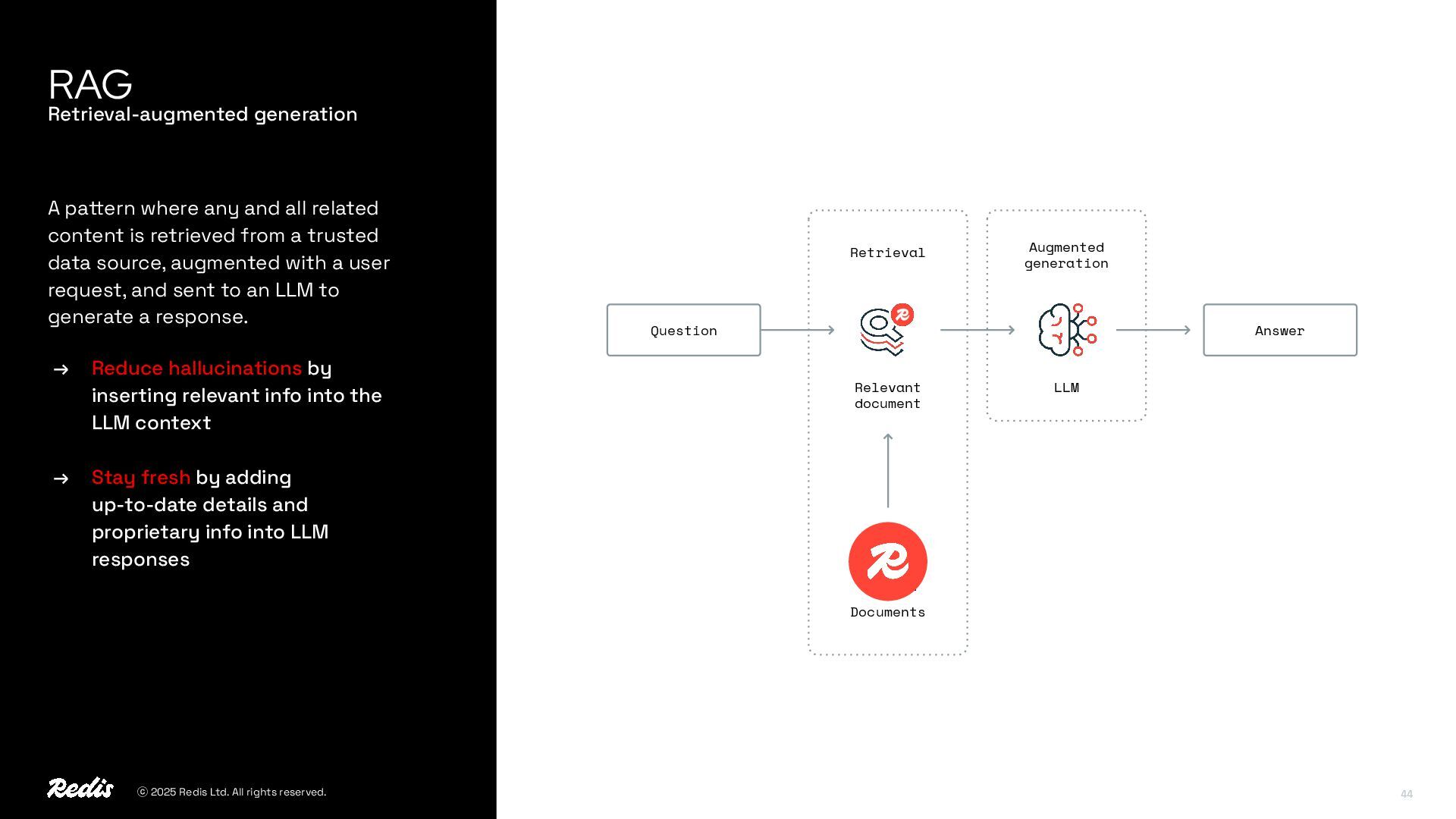
Our experts will show how the two platforms work together to enable retrieval-augmented generation (RAG), semantic caching, and LLM context management—helping reduce latency, cut costs, and deliver production-ready AI applications.
You’ll also learn how to deploy Redis on OpenShift and integrate leading AI frameworks to accelerate your path from experimentation to enterprise-grade solutions.
Join us to see how you can take your AI from promising prototypes to fast, scalable, production-ready systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
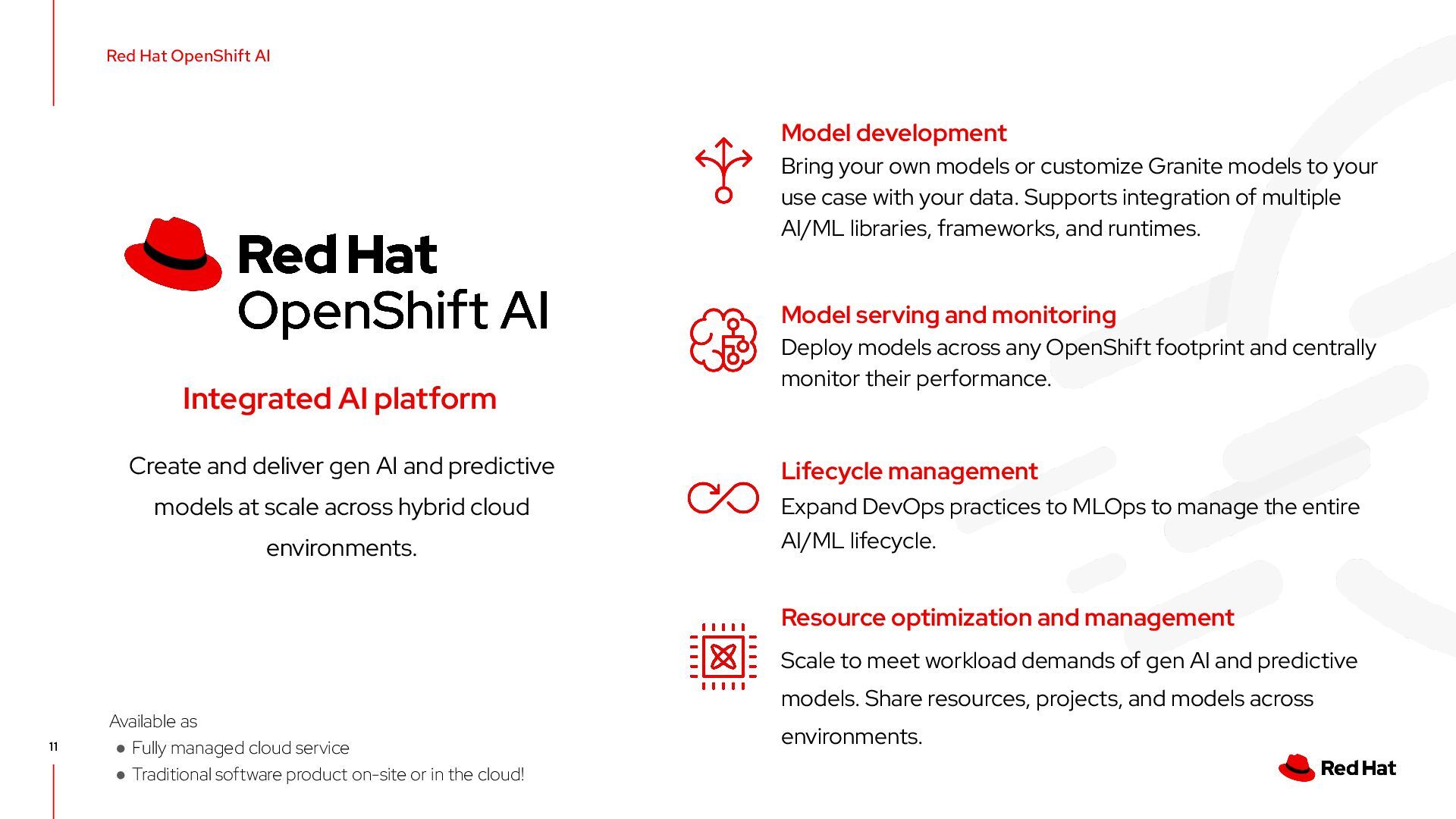{kind=link}
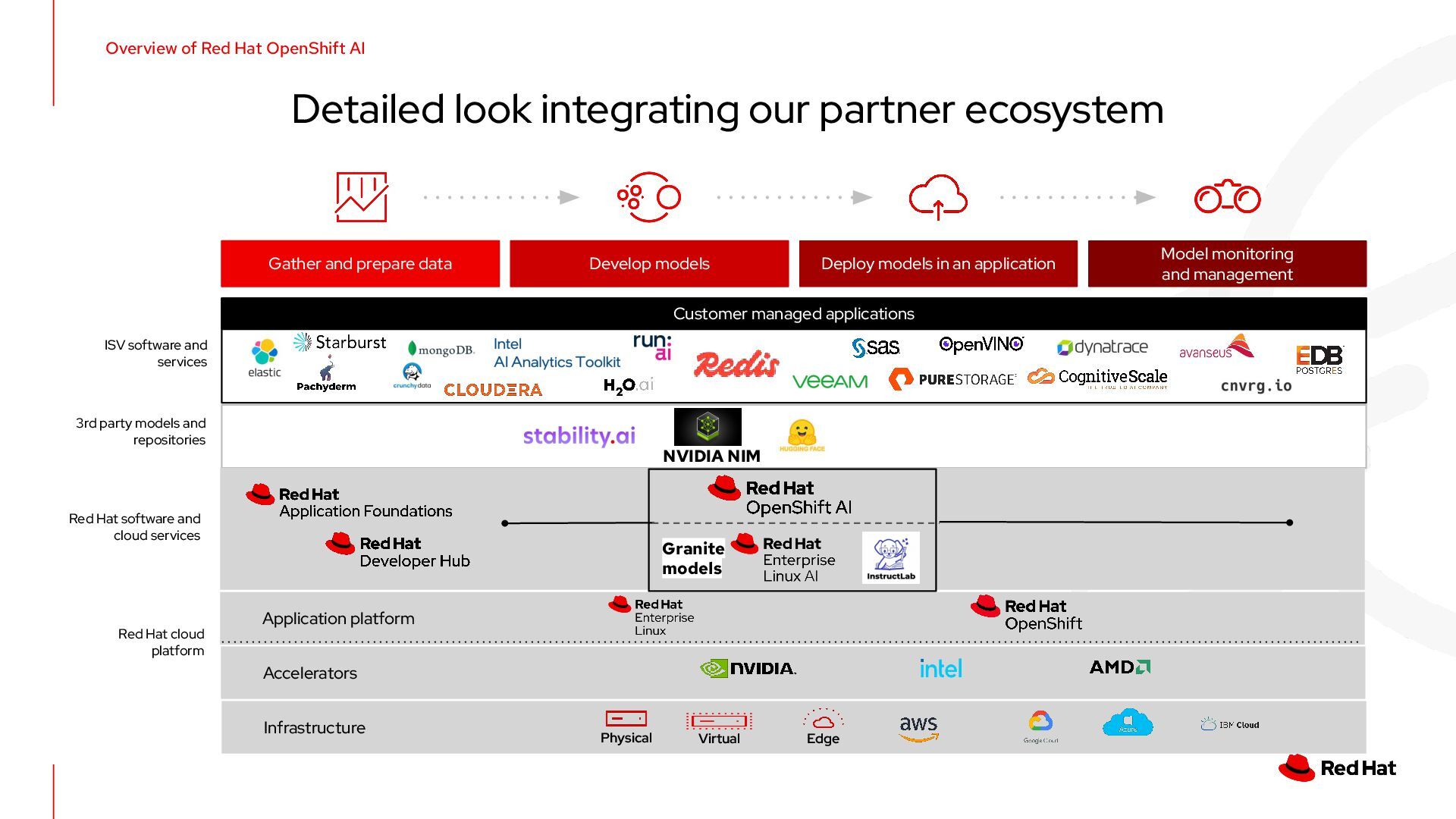{kind=link}
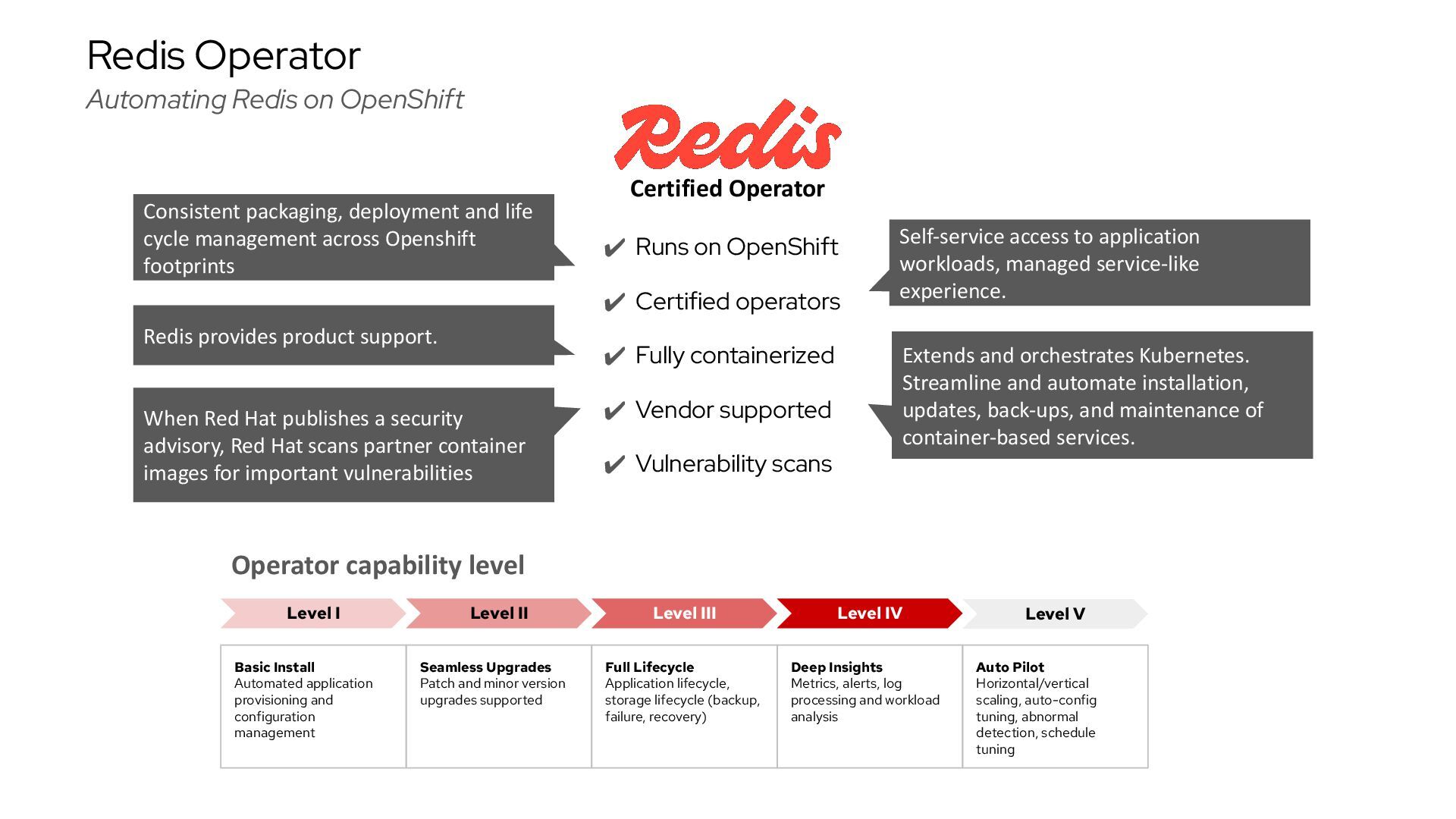{kind=link}
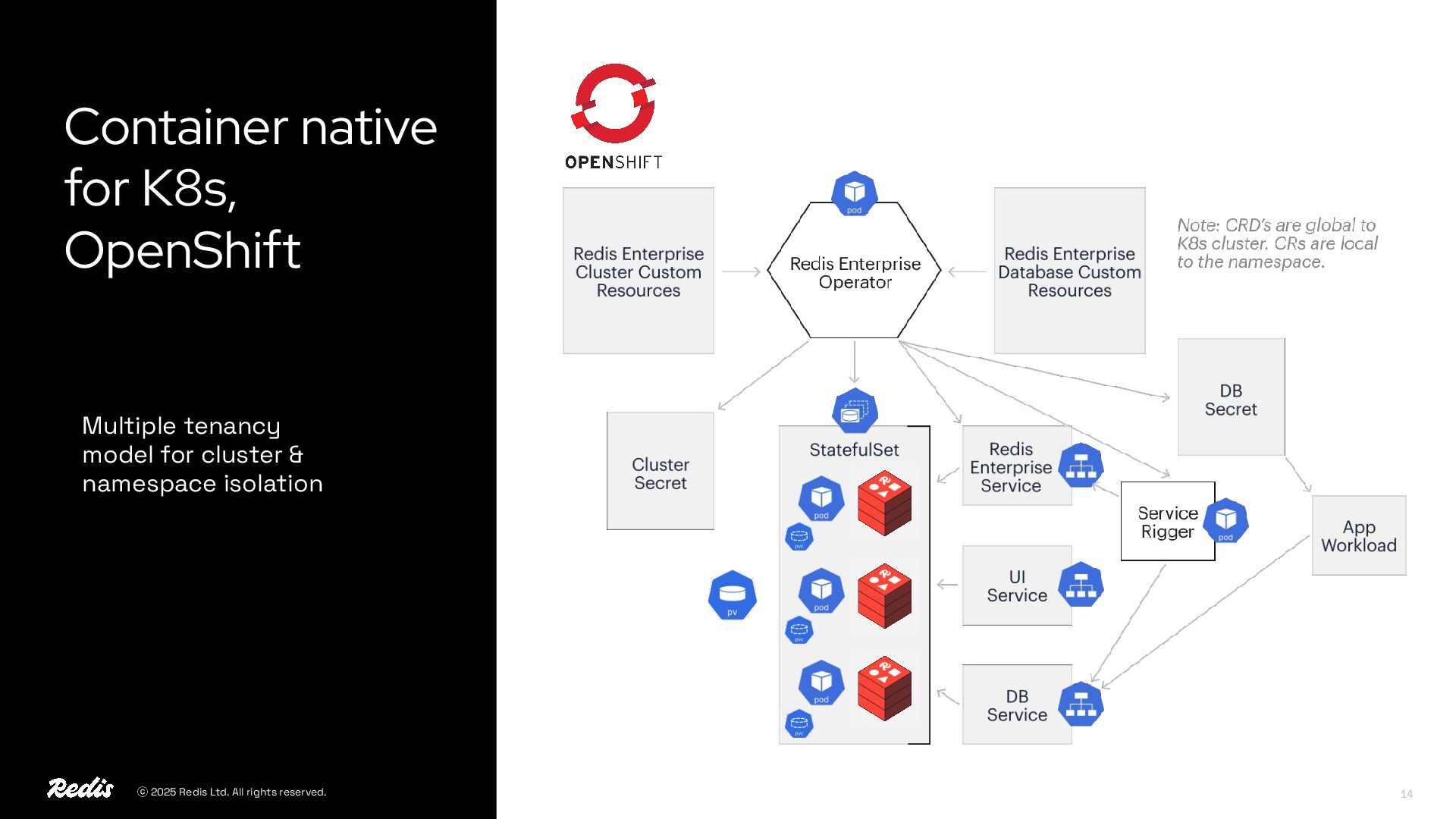{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
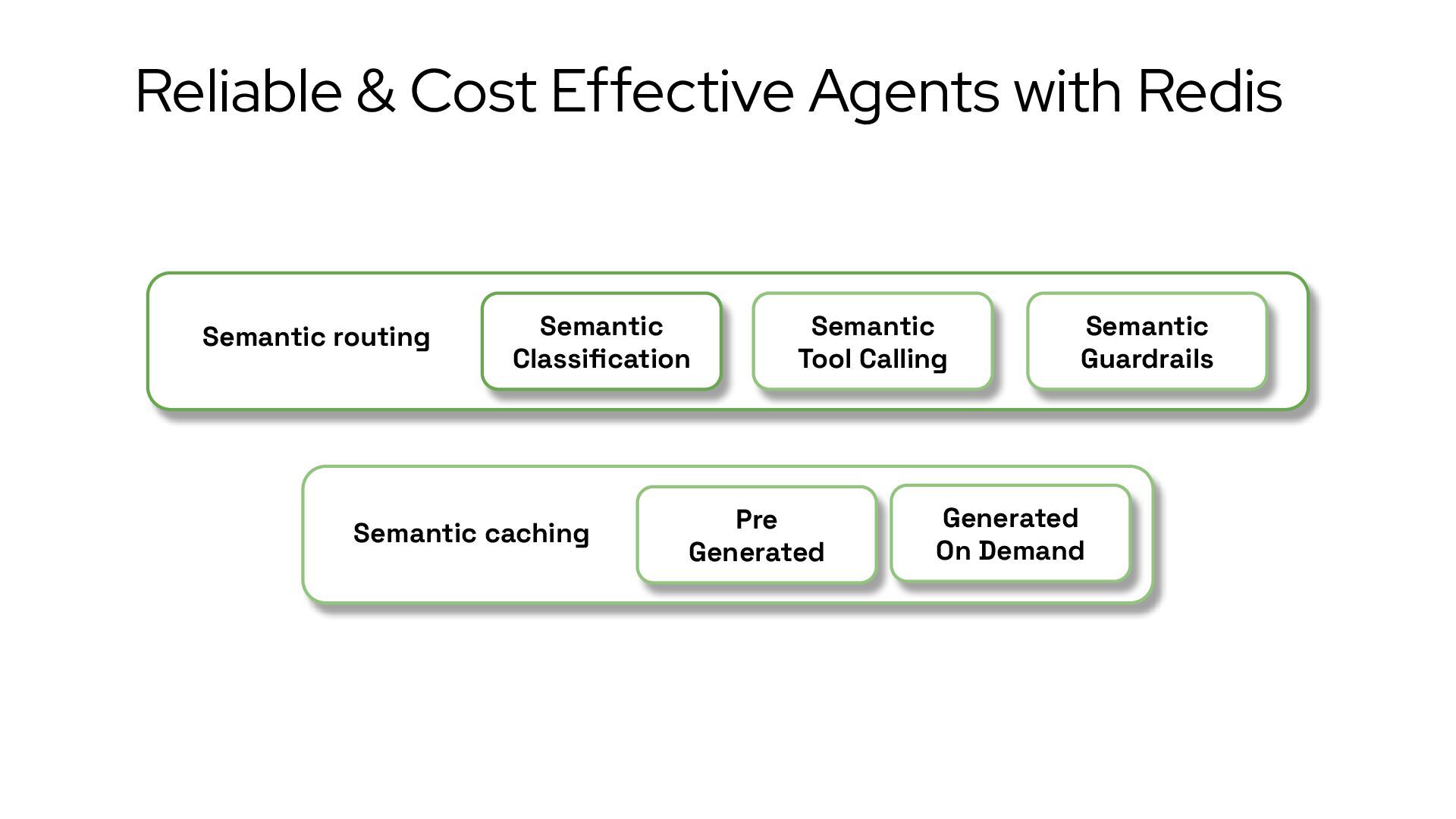{kind=link}
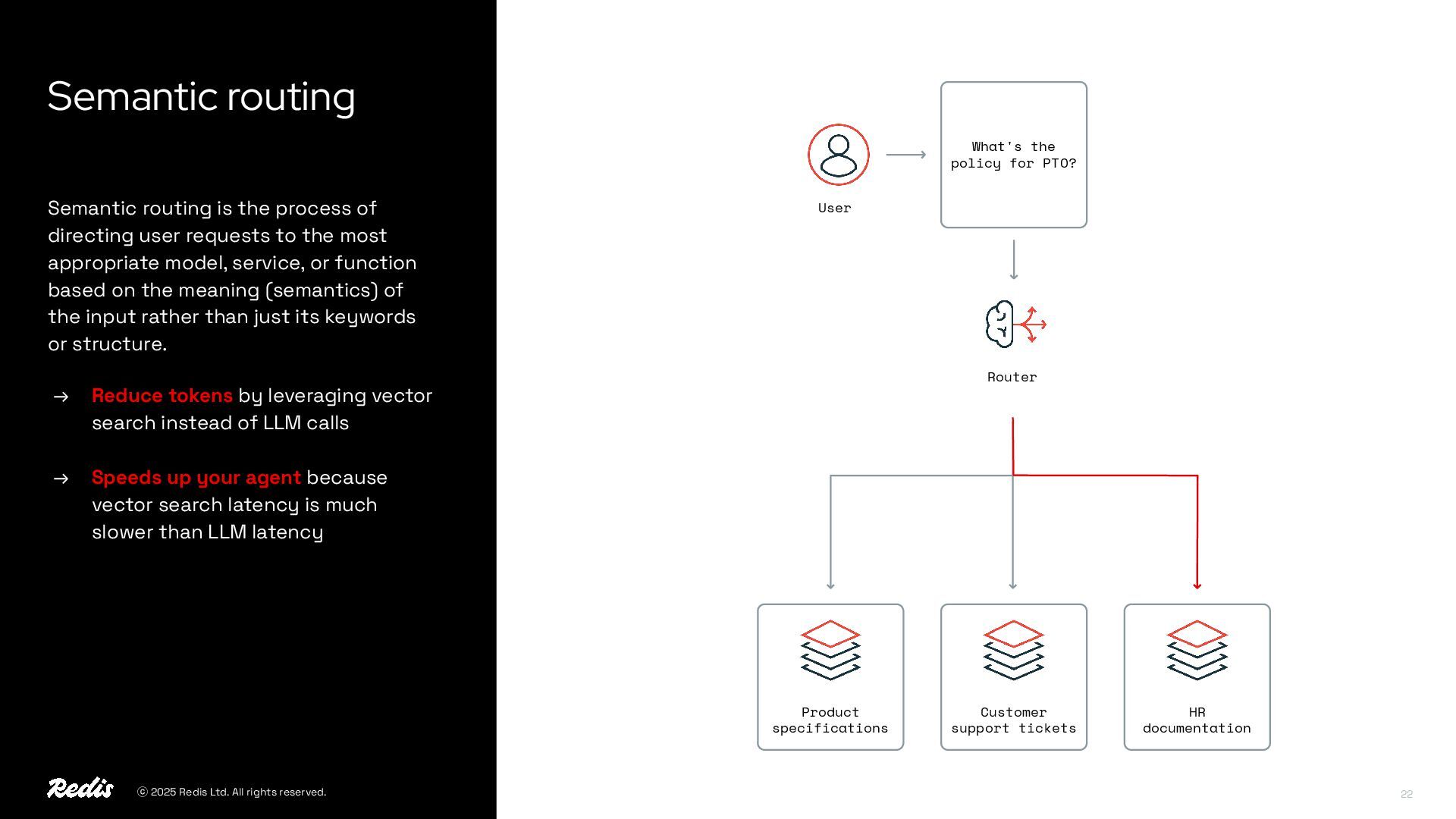{kind=link}
{kind=link}
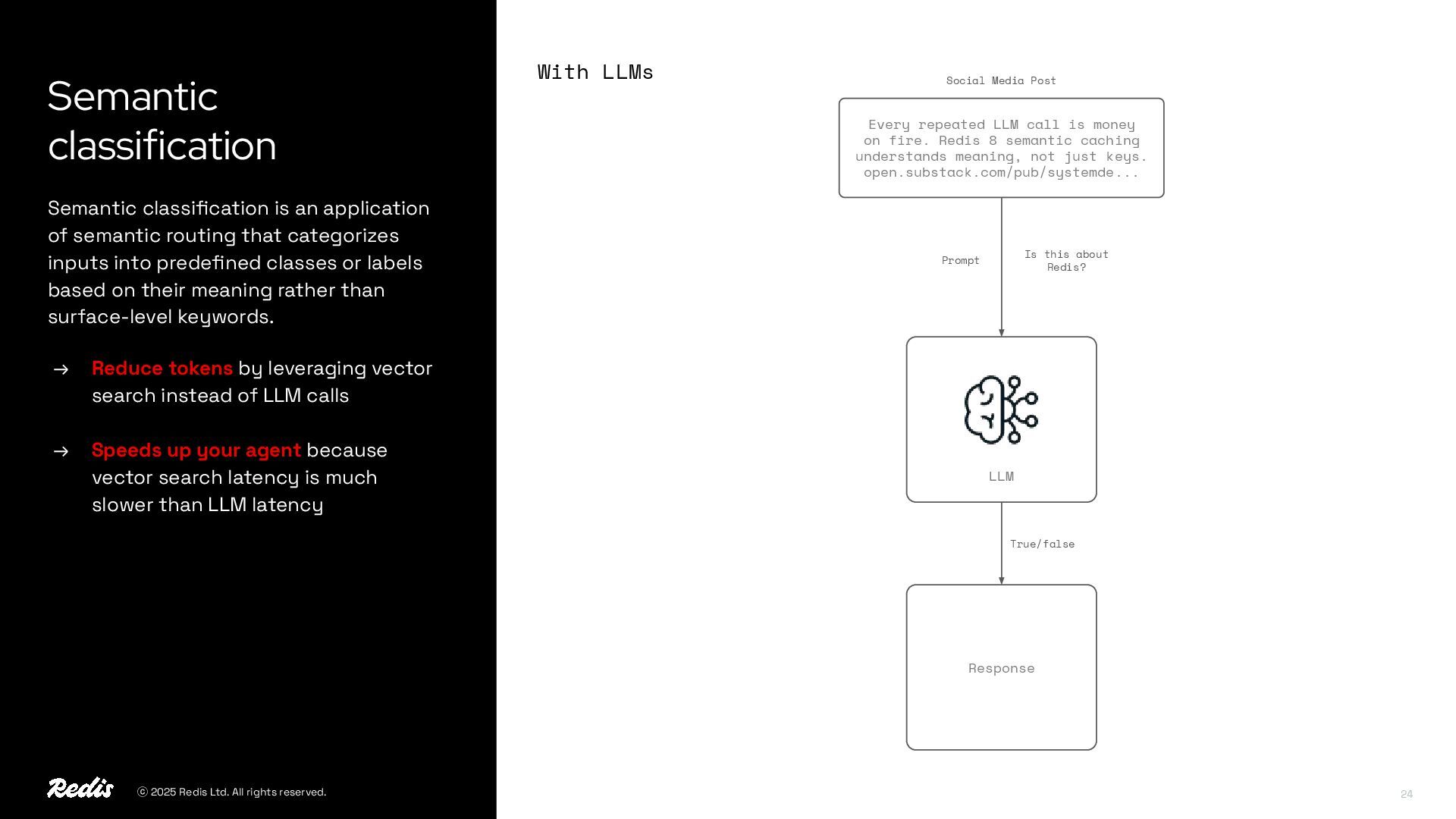{kind=link}
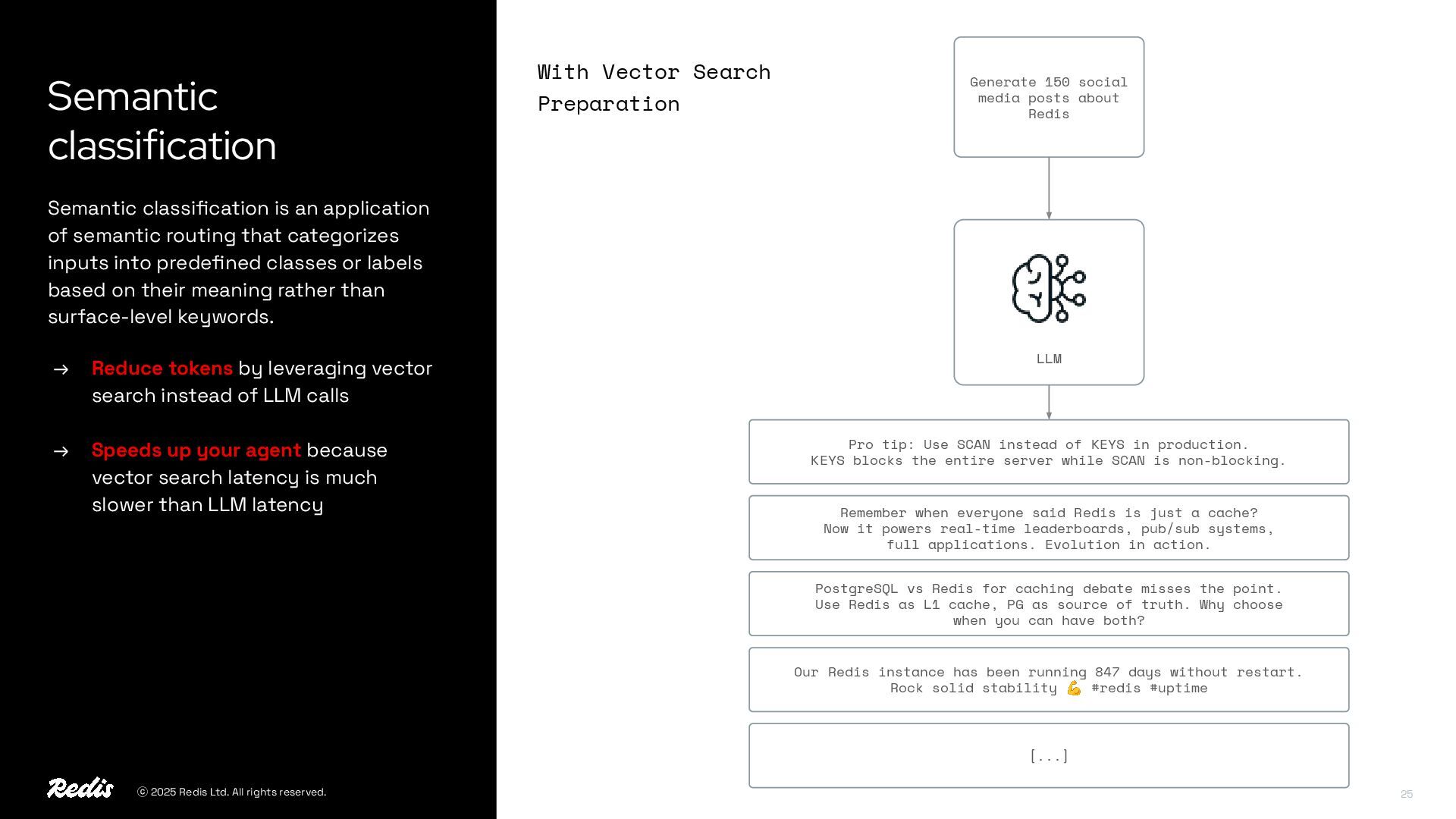{kind=link}
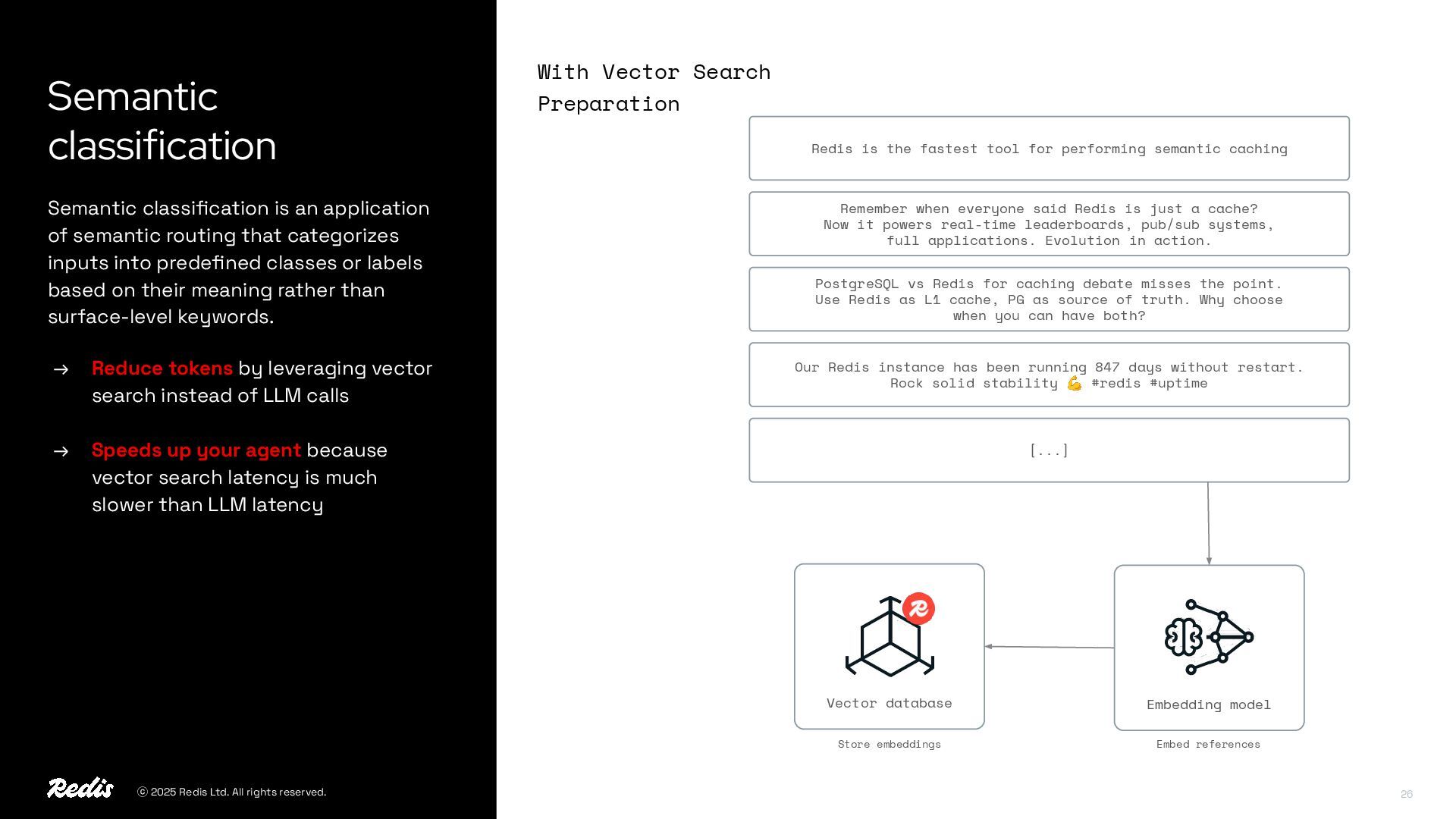{kind=link}
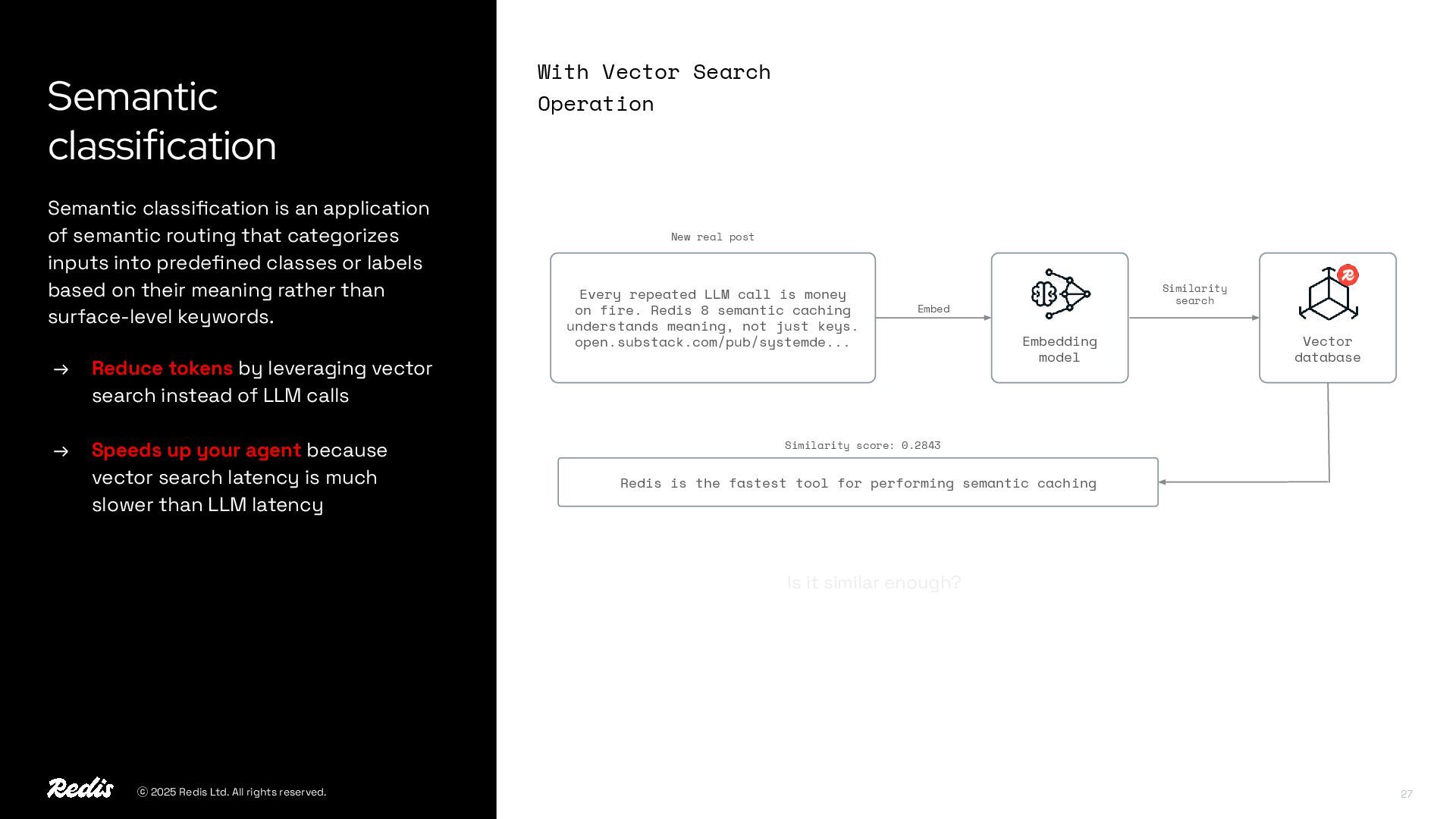{kind=link}
{kind=link}
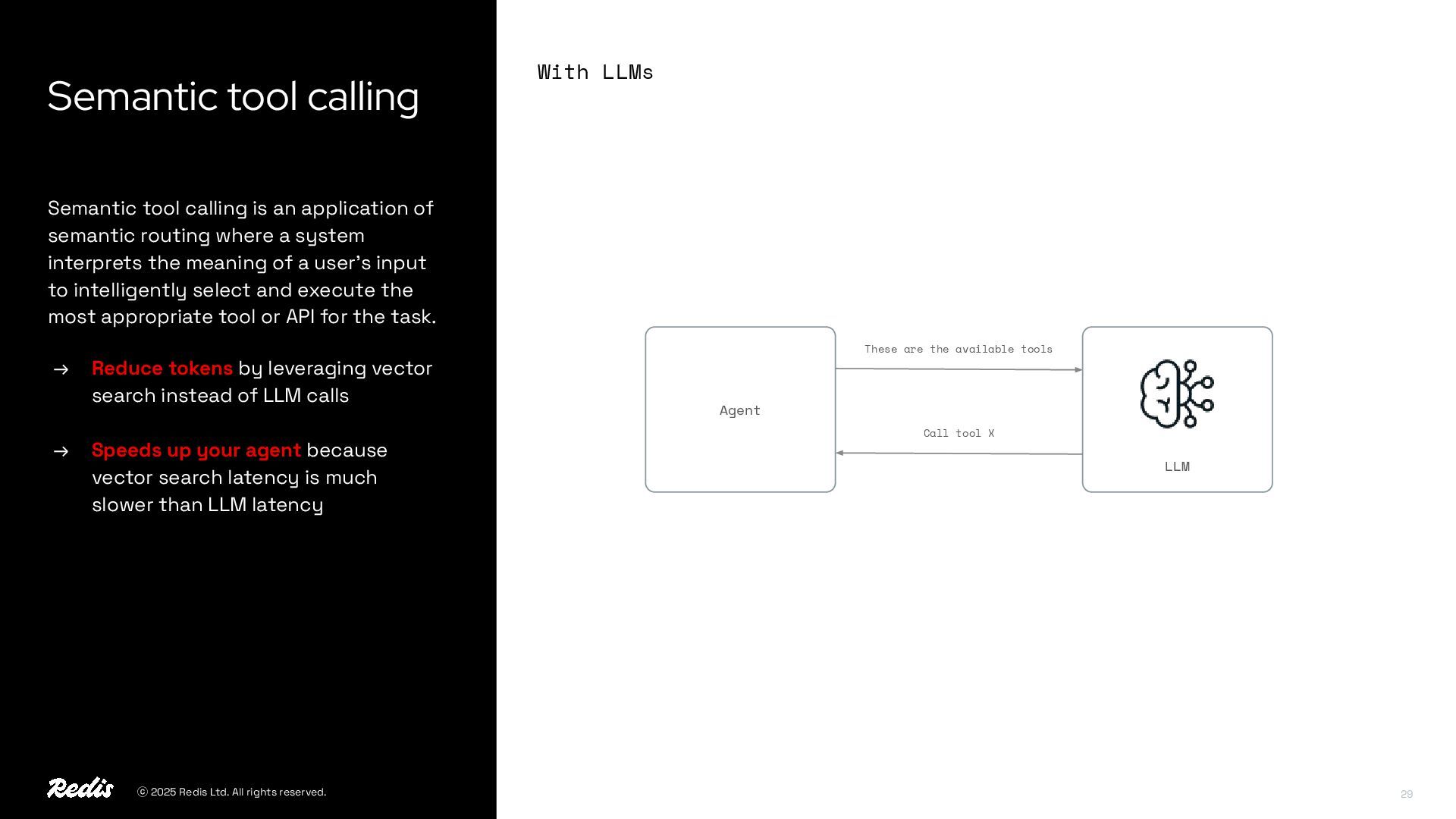{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
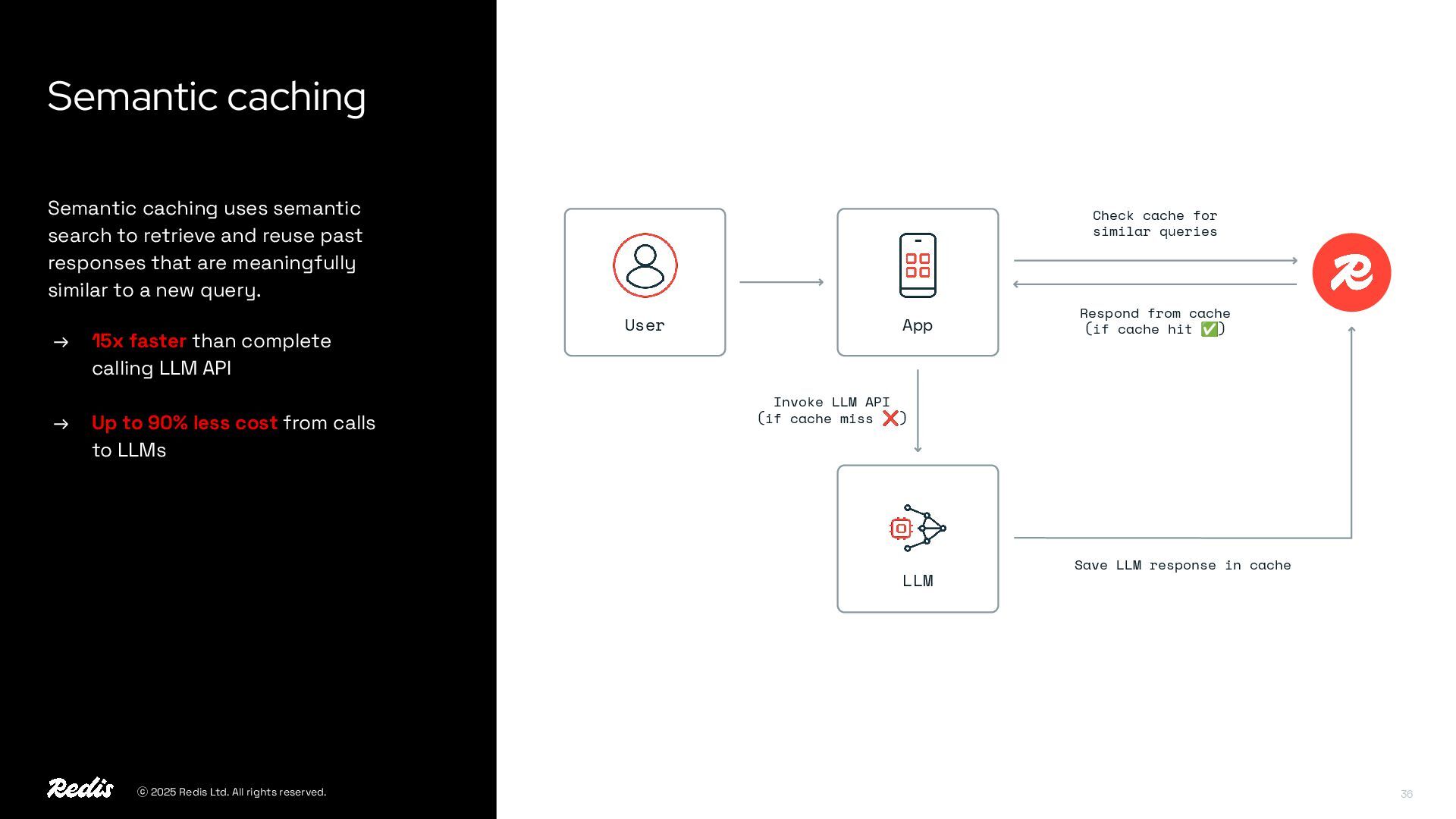{kind=link}
{kind=link}
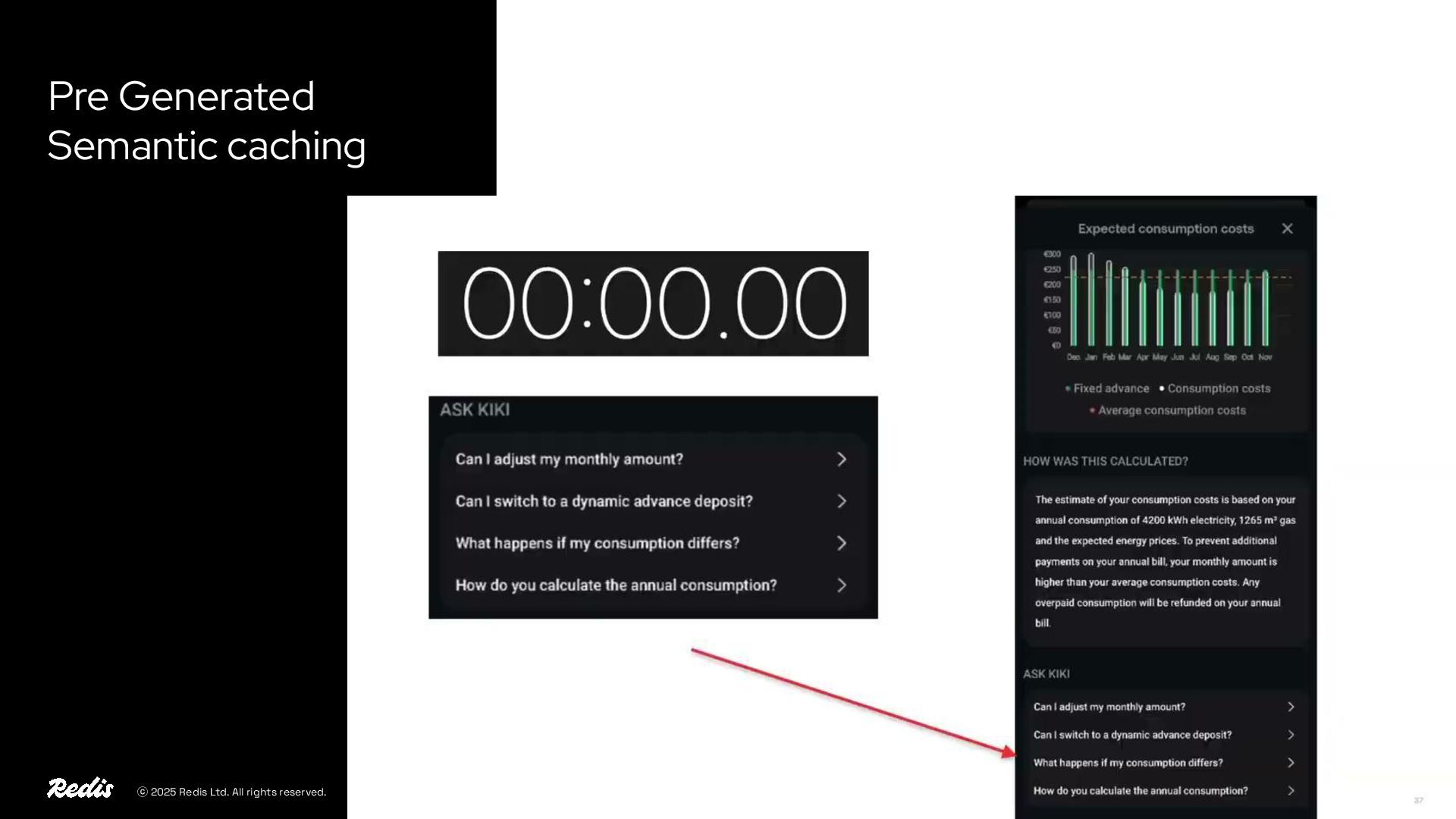{kind=link}
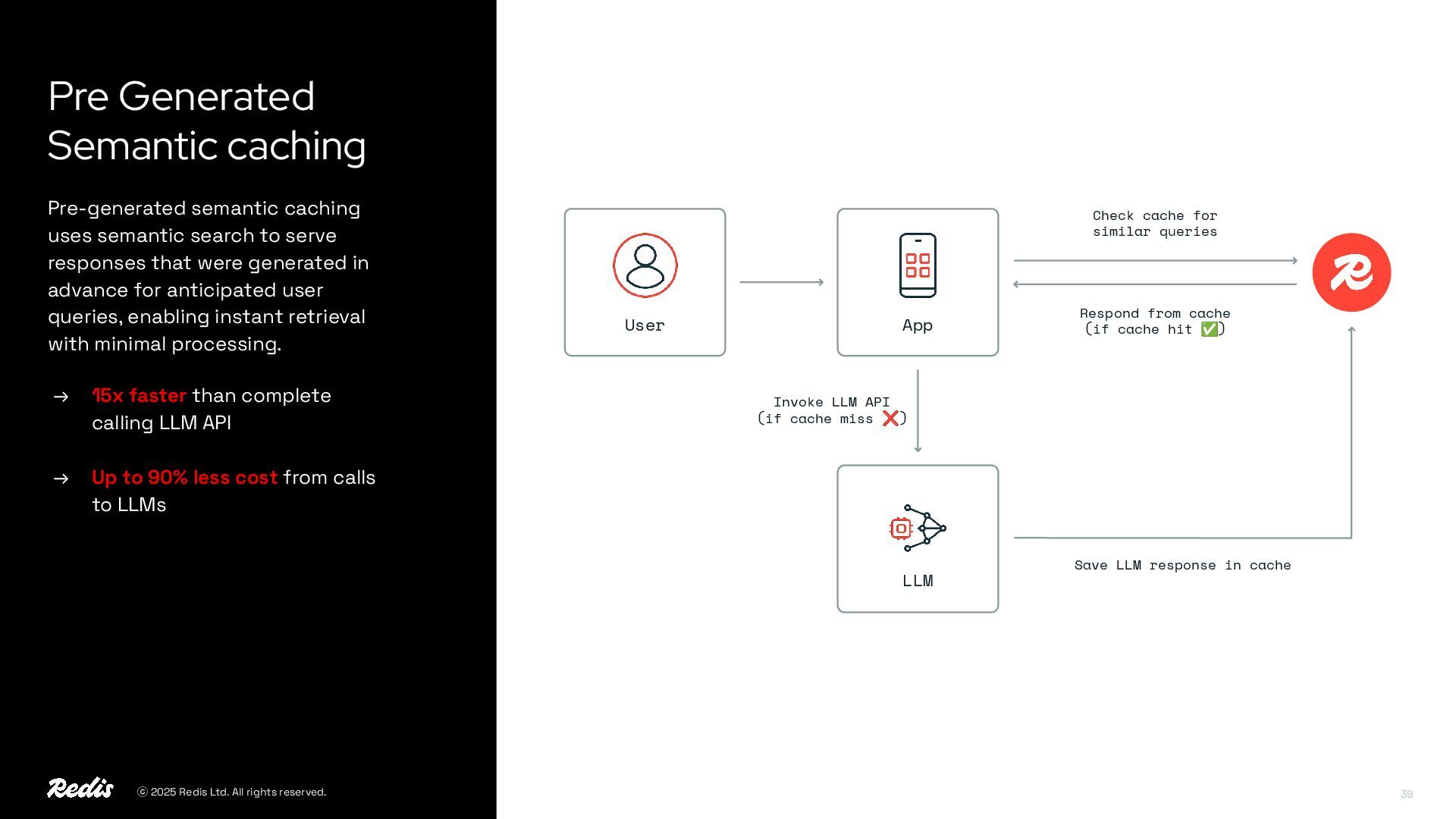{kind=link}
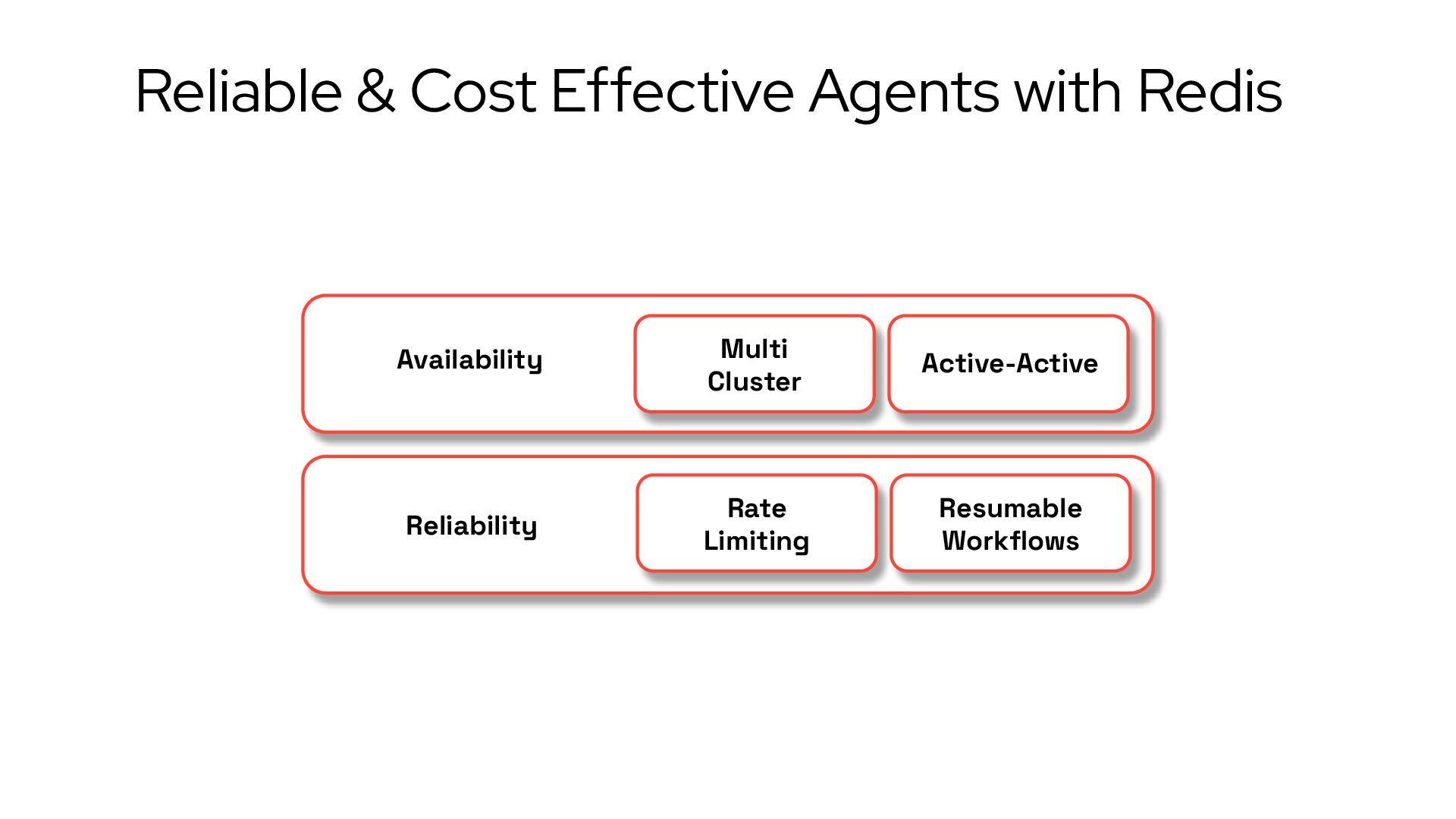{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}