Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
生成AIを活用したZennの取り組み事例
Search
igarashi
September 29, 2025
Technology
790
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
生成AIを活用したZennの取り組み事例
DevelopersIO 2025 Sapporo で発表したセッションのスライドです。
https://classmethod.connpass.com/event/366068/
igarashi
September 29, 2025
More Decks by igarashi
See All by igarashi
Zennのパフォーマンスモニタリングでやっていること
ryosukeigarashi
0
1.3k
Webエディタライブラリ 「CodeMirror」から学ぶ Webアプリ開発のテクニック
ryosukeigarashi
0
2.2k
Other Decks in Technology
See All in Technology
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
130
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
180
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
28
15k
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
5.6k
Git 研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
170
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
300
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
4
420
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
150
Power Automateアップデート情報
miyakemito
0
240
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
200
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
150
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
540
Featured
See All Featured
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Un-Boring Meetings
codingconduct
0
350
Leo the Paperboy
mayatellez
8
1.9k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
WCS-LA-2024
lcolladotor
0
750
Crafting Experiences
bethany
1
230
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Building Adaptive Systems
keathley
44
3.1k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Transcript
⽣成AIを活⽤した Zennの取り組み事例 Igarashi Ryosuke 新規事業統括部 Zennチーム
⾃⼰紹介 2 Igarashi Ryosuke • 2015年 ⼊社 ◦ バックエンドエンジニア •
2021年 から Zennチーム ◦ Next.js / Ruby on Rails / Google Cloud
Zennで⽣成AIを活⽤した主な取り組み 3 • 記事のAIレビュー機能 • 記事のレコメンド機能 ← 今⽇はこれのお話 • コンテンツのスパムチェック •
⾃然⾔語でのDB問い合わせ
Zennで⽣成AIを活⽤した主な取り組み 4 その他は、現在開催中の "Zennfes 2025" の動画で紹介しています。 https://zenn.dev/events/zennfes-2025
⽣成AIを活⽤した 記事のレコメンド機能
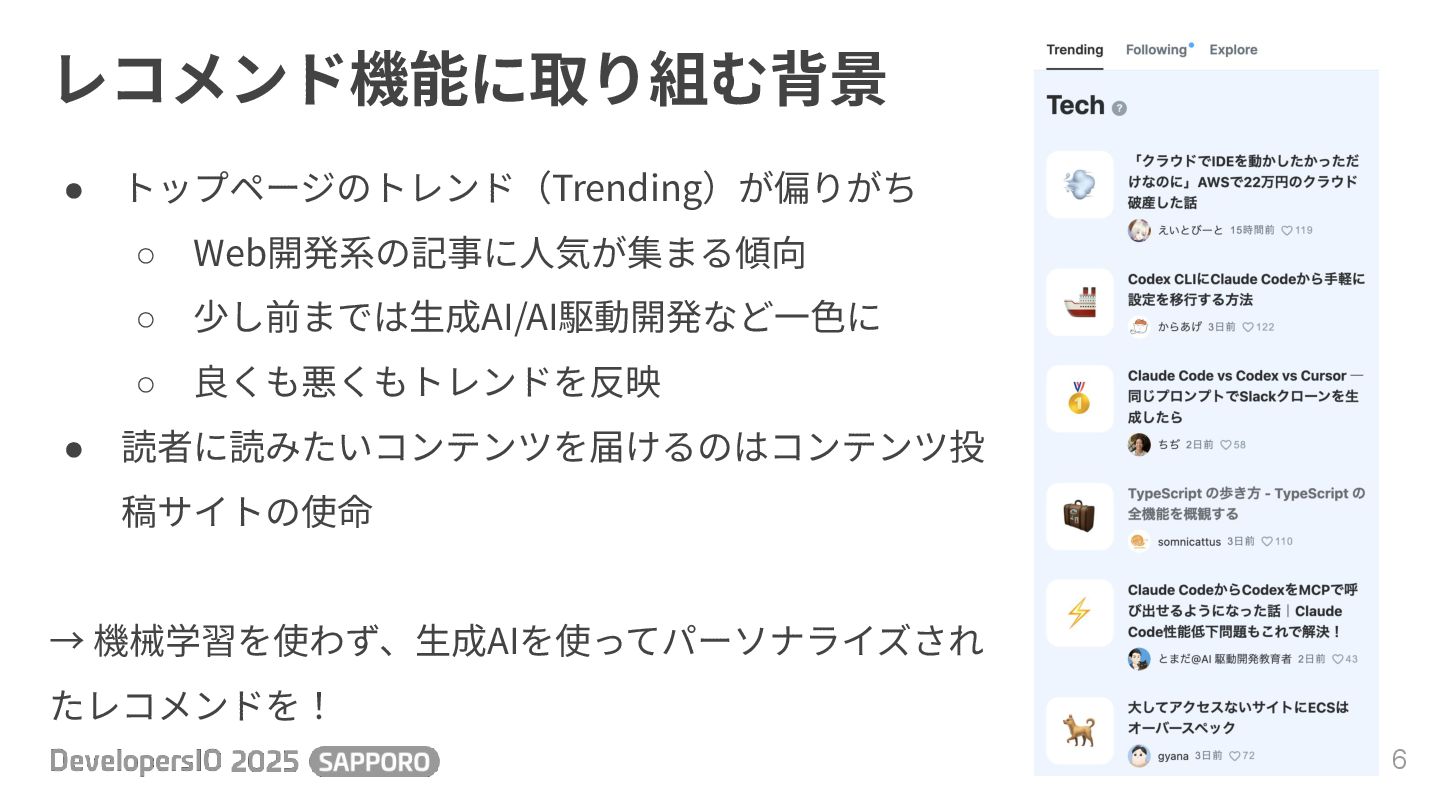
レコメンド機能に取り組む背景 6 • トップページのトレンド(Trending)が偏りがち ◦ Web開発系の記事に⼈気が集まる傾向 ◦ 少し前までは⽣成AI/AI駆動開発など⼀⾊に ◦ 良くも悪くもトレンドを反映
• 読者に読みたいコンテンツを届けるのはコンテンツ投 稿サイトの使命 → 機械学習を使わず、⽣成AIを使ってパーソナライズされ たレコメンドを!
やったこと 7 • phase 1. 6次元ベクトルによる類似検索(βリリース) • phase 2. Embeddingsによる類似検索(検証のみ) • phase
3. トピックベースの類似検索(現在)
phase 1 6次元ベクトルによる類似検索(βリリース)
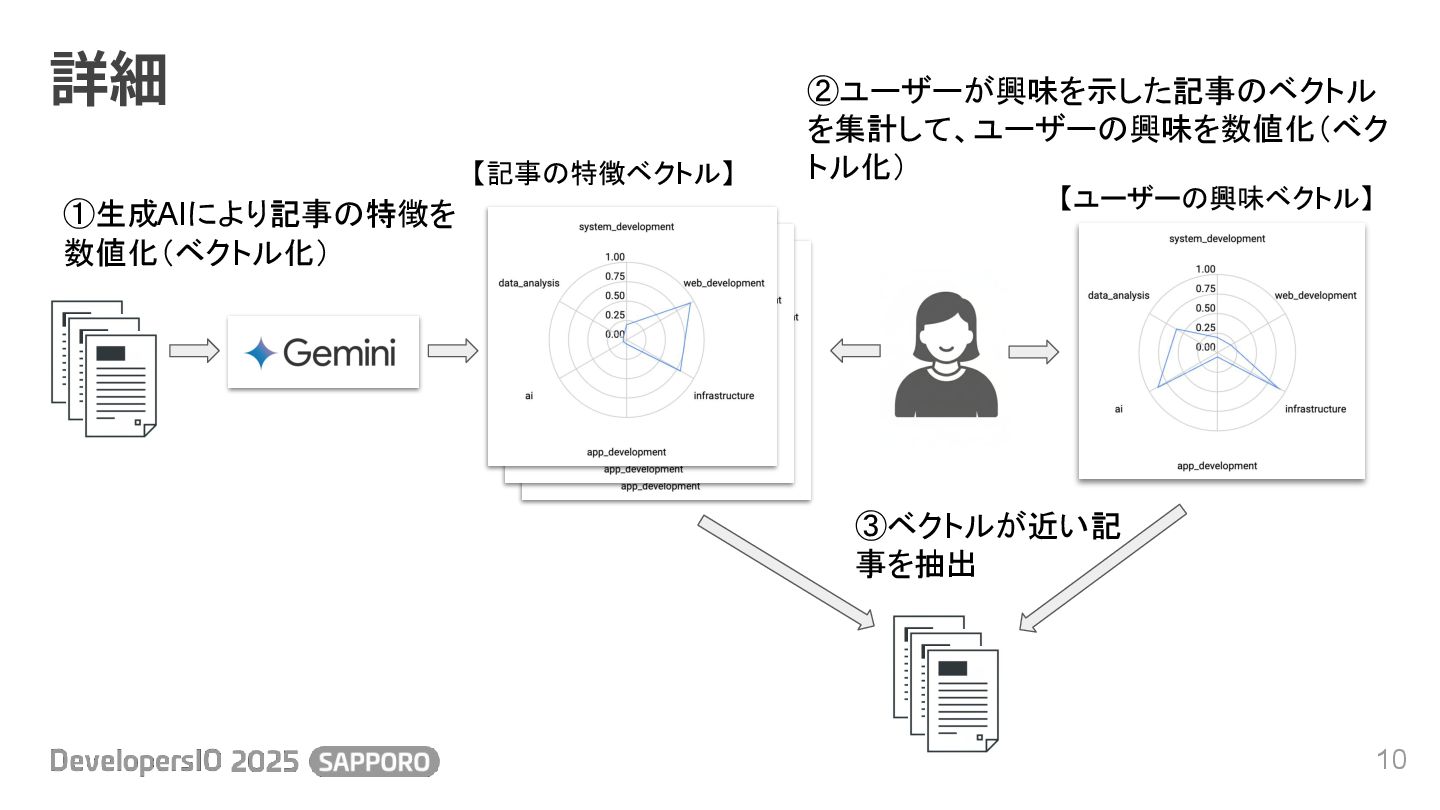
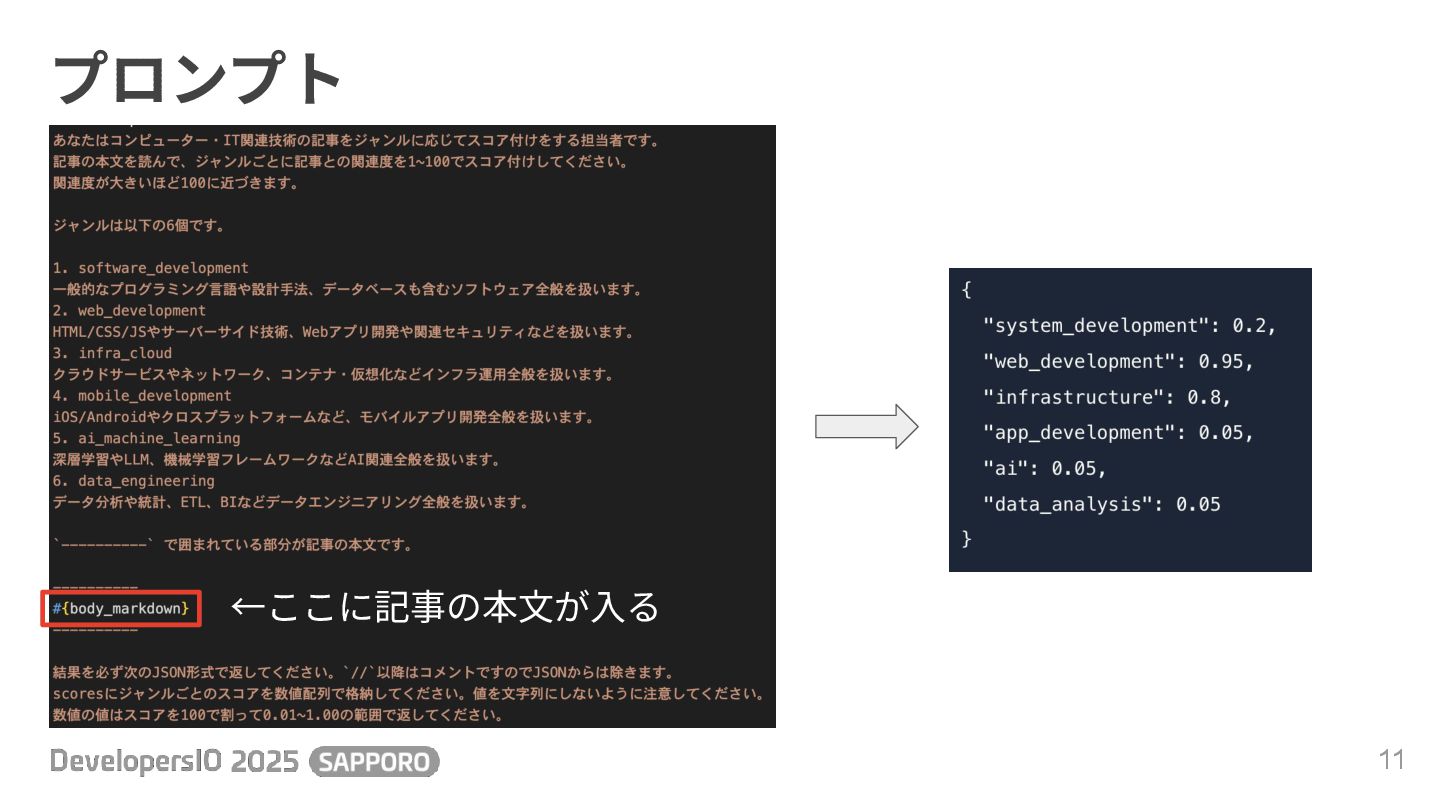
作戦 9 • トレンドと同じ期間(おおよそ公開から1週間)の記事を推薦する ◦ 記事の総数が少ないためピンポイントな推薦は難しい ◦ ざっくりとした6つのカテゴリー分類での推薦を⽬指す • 記事の内容を⽣成AIに読み込ませて特徴を数値化
◦ 6つのカテゴリーそれぞれに対する関連度を、6次元ベクトルで表現 • ユーザーが興味を⽰した記事のベクトルからユーザーの興味ベクトル計算 • 記事とユーザーのベクトル類似検索でレコメンド記事を提供
詳細 10 ①生成AIにより記事の特徴を 数値化(ベクトル化) ②ユーザーが興味を示した記事のベクトル を集計して、ユーザーの興味を数値化(ベク トル化) ③ベクトルが近い記 事を抽出 【記事の特徴ベクトル】
【ユーザーの興味ベクトル】
プロンプト 11 ←ここに記事の本⽂が⼊る
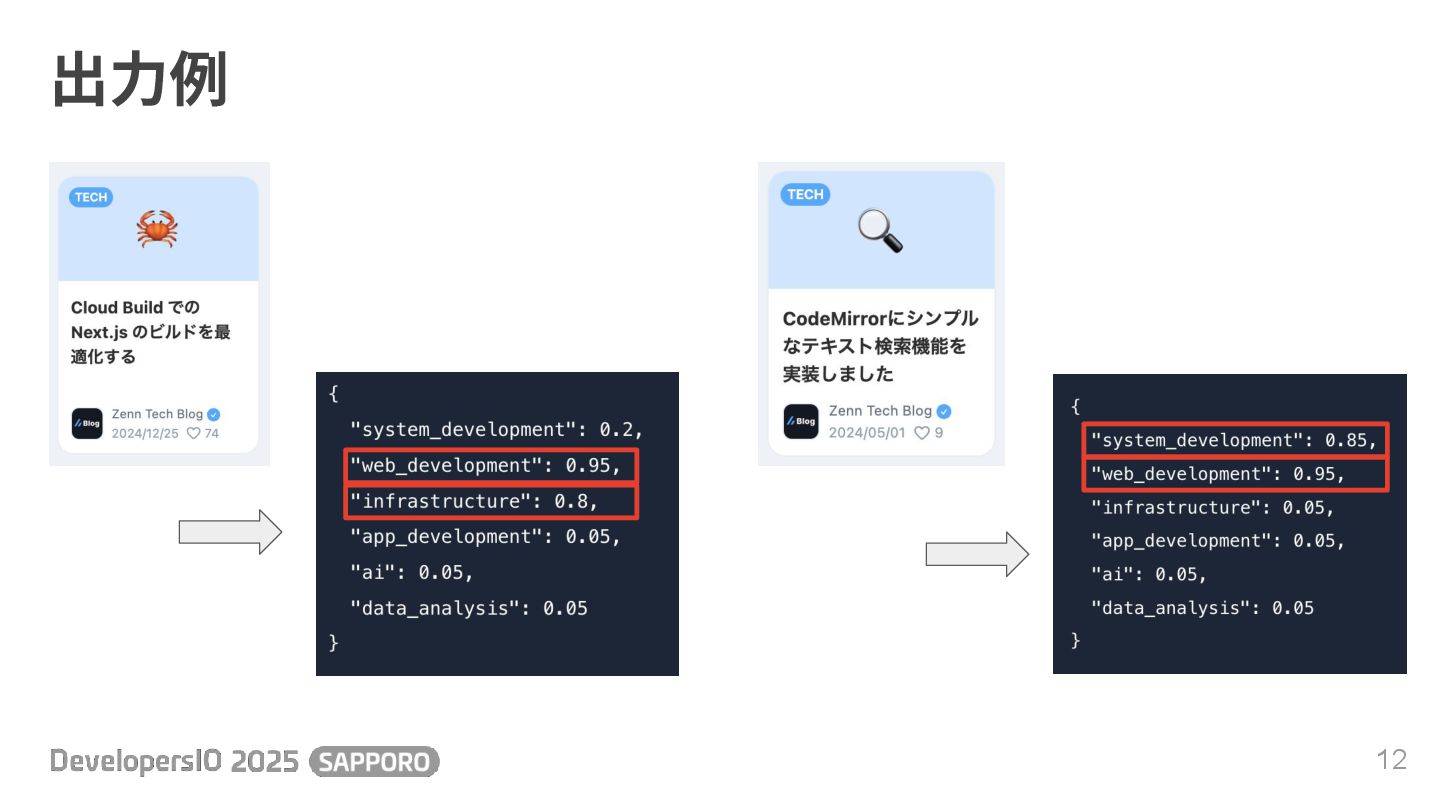
出⼒例 12
技術トピック 13 • ⽣成AIは Vertex AI - Gemini 2.5 Flash
を使⽤ ◦ レスポンスのフォーマットをJSON Schemaで定義できる ◦ 思考(thinking)を有効にすると、深い洞察を⾏う • ベクトル計算はpgvector(PostgreSQL拡張)を使⽤ ◦ vector型フィールド ◦ ユークリッド距離、コサイン類似度、内積などの演算 ◦ 近似近傍検索⽤のインデックス
より詳しくは 14 https://zenn.dev/team_zenn/articles/zenn-recommend-system
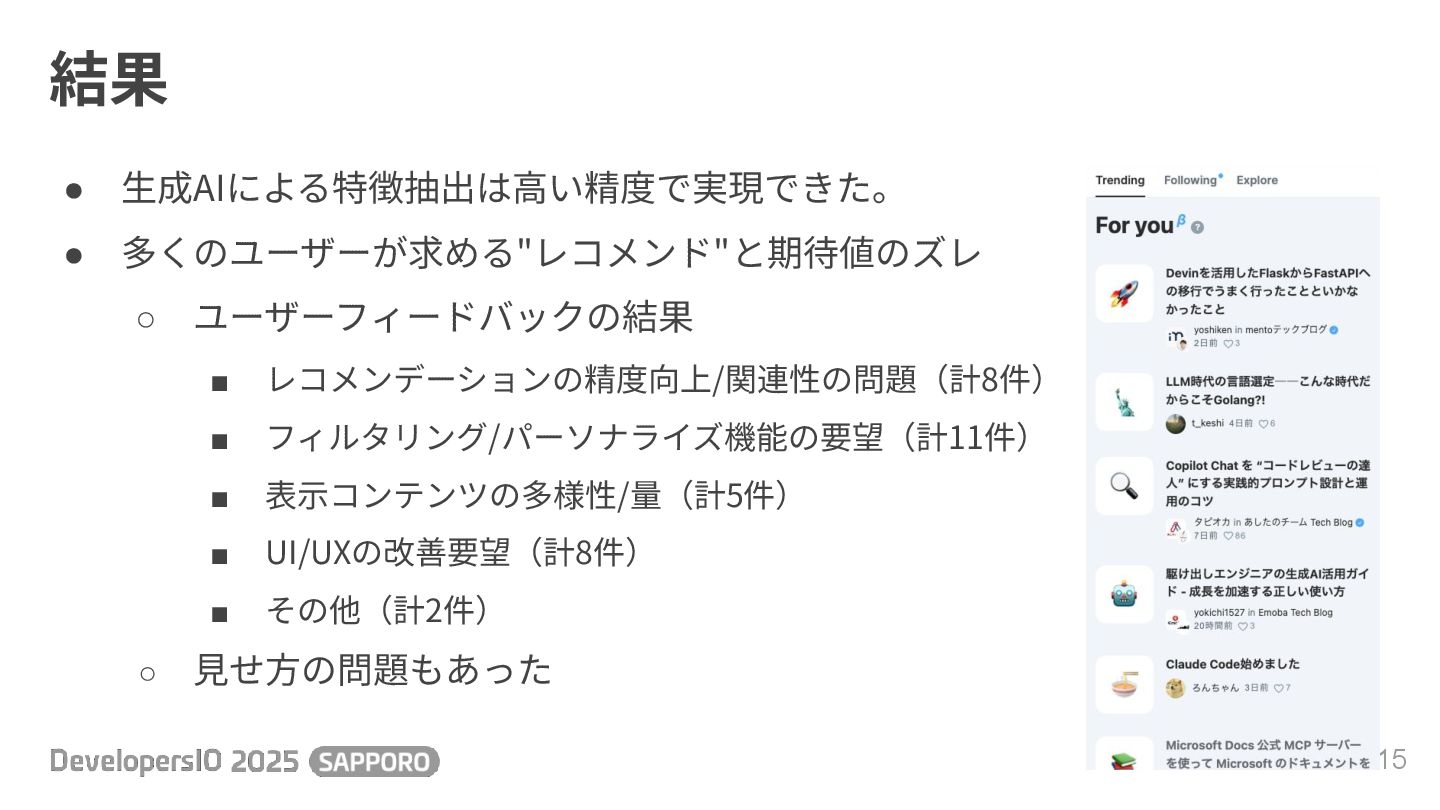
結果 15 • ⽣成AIによる特徴抽出は⾼い精度で実現できた。 • 多くのユーザーが求める"レコメンド"と期待値のズレ ◦ ユーザーフィードバックの結果 ▪ レコメンデーションの精度向上/関連性の問題(計8件)
▪ フィルタリング/パーソナライズ機能の要望(計11件) ▪ 表⽰コンテンツの多様性/量(計5件) ▪ UI/UXの改善要望(計8件) ▪ その他(計2件) ◦ ⾒せ⽅の問題もあった
phase 2 Embeddingsによる類似検索(検証のみ)
作戦 17 • phase 1の結果、レコメンドの精度に関する期待値ギャップに課題があった。 • 精度を上げるには6次元のベクトルでは⾜りない。 ◦ ベクトルを増やす? ▪
いくつあれば⼗分? ▪ ベクトル定義の更新のたびに全件更新が必要... • Embeddingsを使ってより精度の⾼い類似検索を! • ユーザーの興味ベクトルは作れないので、直近で閲覧した記事に類似する記事 を提案する
Embeddingsとは 18 • 単語、⽂章、画像、⾳声などのデータを数値ベクトルに変換すること。 • 元のデータの意味や⽂脈を数値空間で表現し、意味的に似ているデータはベ クトル空間上で近くに配置される。 • セマンティック検索(あいまい検索)、RAGなどに活⽤される。
• Embeddingsには Gemini API - gemini-embedding-001 を使⽤ ◦ 次元数は最⼤(デフォルト)3072 から
128まで圧縮可能 ▪ 今回は768次元で検証 ◦ タスクに応じたEmbeddings ▪ SEMANTIC_SIMILARITY(テキスト類似度に最適) ▪ CLASSIFICATION(ラベルに従ってテキスト分類に最適化) ▪ CLUSTERING(テキストをクラスタ化するように最適化) ▪ RETRIEVAL_DOCUMENT / RETRIEVAL_QUERY(テキスト検索向けに最適化) ▪ など 技術トピック 19
出⼒例 20 • AWS ECS オートスケーリング Cooldownを知った【2025夏】 ↓に類似する記事 • [類似度:
0.896] AWS ECS オートスケーリングの種類を学びました • [類似度: 0.838] ECSにAWS Gravitionを導⼊すると何が良いのか調べてみた • [類似度: 0.817] ECS Fargateのソフトウェア‧アップデート運⽤を考える • [類似度: 0.803] Amazon ECSのアベイラビリティゾーンリバランシングをCDK で設定する⽅法
検証結果 21 • SEMANTIC_SIMILARITY を使⽤して記事本⽂を10,000件程度ベクトル化 • 類似検索の傾向 ◦ ある程度の⽂量の記事は類似性が⾼い記事が検出しやすい ◦
短い記事やidea記事は微妙 • 結果のコントロールの難しさを感じた
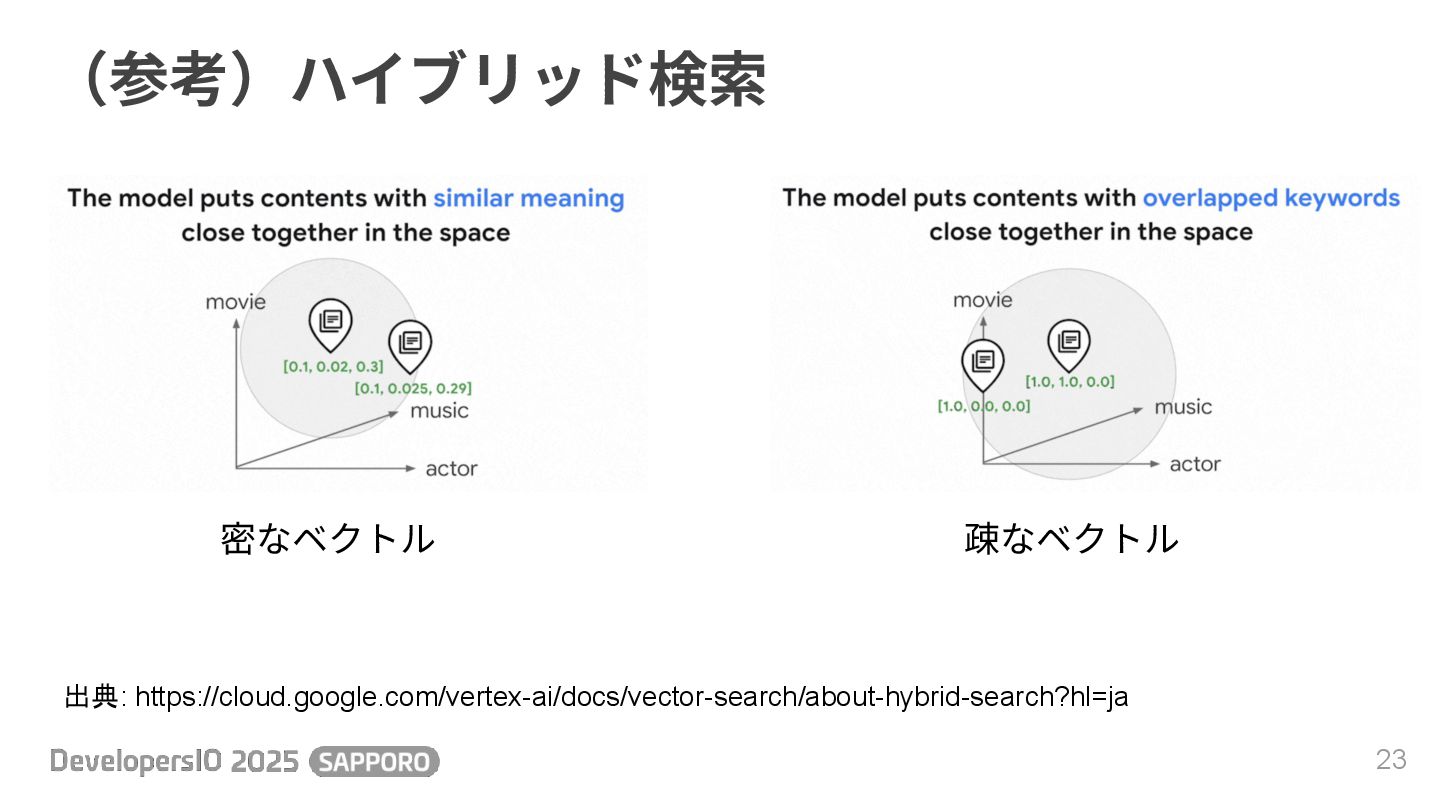
(参考)ハイブリッド検索 ※時間が余ってたら 22 • Embeddingsは意味や⽂脈の類似性を捉えるが、単語レベルの類似性は弱い • より精度を⾼めるには、キーワードの類似性も掛け合わせたハイブリッド検 索を使う • 2種類のベクトル
◦ 密なベクトル(意味的、Embeddingsはこっち) ◦ 疎なベクトル(キーワード的) • 2つのベクトルの類似度を合成してランキングを作る
(参考)ハイブリッド検索 23 出典: https://cloud.google.com/vertex-ai/docs/vector-search/about-hybrid-search?hl=ja 密なベクトル 疎なベクトル
(参考)ハイブリッド検索 24 • 疎なベクトルの⽣成には、TF-IDF や BM25 のような統計⼿法や、学習済のモ デル(SPLADEなど)を⽤いる。 • ハイブリッド検索は最近のベクトルDBサービスにはだいたい備わっていそ
う。pgvectorでもサポートあり。 • それぞれのベクトルで類似検索を⾏い、リランキングをする。
phase 3 トピックベースの類似検索(現在)
作戦 26 • phase 2 検証時点のチーム内の声 ◦ もっと直近の閲覧状況を反映した記事が⾒たい ◦ もっと質の⾼い記事が推薦されてほしい
• 閲覧履歴を記録し、直近10件の記事に頻出するトピックを抽出 • 直近3ヶ⽉以内に公開された記事のうち⼈気度が⾼い記事の中から、トピック の類似度が⾼い記事を抽出 • ルールベースの推薦
お試しください 27
課題 28 • 記事に適切なトピックが設定されているか • ユーザーの記事に対する興味の測り⽅‧重み付け • ユーザーの興味がないトピックへのフィードバック
まとめ
まとめ 30 • ⽣成AIによって記事のスコアリングは⾼い精度で実現した • Embeddingsは明確で⼗分な⽂章量があれば⾼い精度でベクトルが類似する • レコメンドはとても奥が深い ◦ やり⽅が無限にある
▪ ルールベース、コンテンツベース、協調フィルタリング、など ◦ 変数が多すぎる ▪ ユーザーの⾏動(ポジティブ‧ネガティブ)、コンテンツ属性、など ◦ UI/UXも⼤事 ▪ 期待値コントロール、推薦の納得感、など
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}