(CNRS, Computer Science Laboratory of Grenoble LIG)
Title — Safe semi-supervised learning when the labels are informative
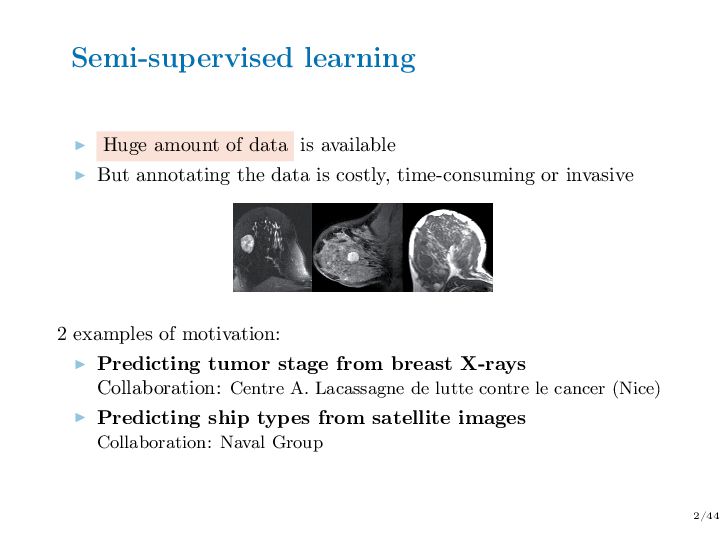
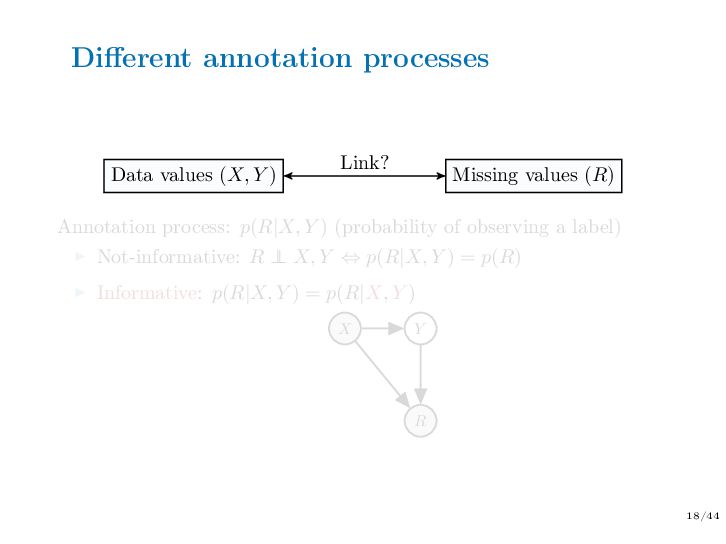
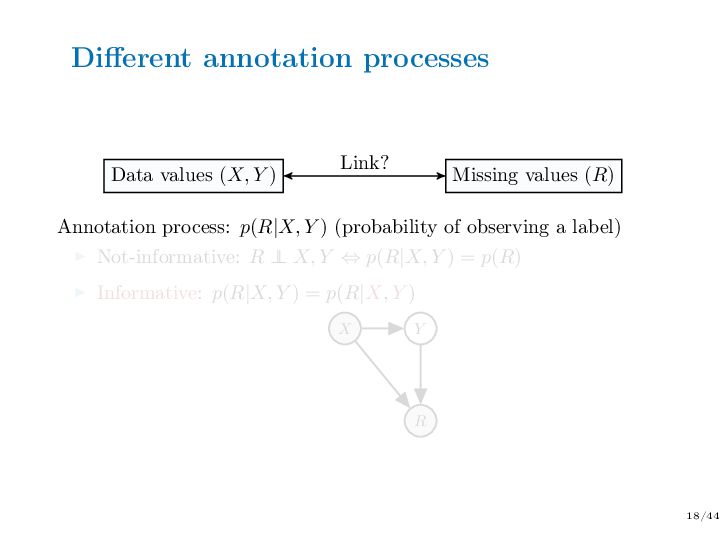
Abstract — In semi-supervised learning, we have access to features but the outcome variable is missing for a part of the data. In real life, although the amount of data available is often huge, labeling the data is costly and time-consuming. It is particularly true for image data sets: images are available in large quantities on image banks but they are most of the time unlabeled. It is therefore necessary to ask experts to label them. In this context, people are more inclined to label images of some classes which are easy to recognize. The unlabeled data are thus informative missing values, because the unavailability of the labels depends on their values themselves. Typically, the goal of semi-supervised learning is to learn predictive models using all the data (labeled and unlabeled ones). However, classical methods lead to biased estimates if the missing values are informative. We aim at designing new semi-supervised algorithms that handle informative missing labels.
Bio
Since October 2024, I am a CNRS researcher in the APTIKAL team of the Computer Science Laboratory of Grenoble LIG. From October 2023 to the end of Septembrer 2024, I was a junior fellow in Efelia Côte d’Azur. From October 2021 to the end of September 2023, I was a Postdoctoral researcher of the 3iA Côte d’Azur at Centre Inria d’Université Côte d’Azur in the Maasai team. I was working on deep semi-supervised learning, with Charles Bouveyron and Pierre-Alexandre Mattei. My PhD thesis (2018-2021) in Applied Mathematics was supervised by Claire Boyer and Julie Josse at Ecole Polytechnique (CMAP) and University Pierre and Marie Curie (LPSM).
![1/44 Safe semi-supervised learning with biased labels Aude Sportisse <[email protected]>](https://files.speakerdeck.com/presentations/5692ede1faea482cac0f78a04c2cdd52/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}