(ENS Paris)
Title — Convergent plug-and-play methods for image inverse problems.
Abstract — Plug-and-play methods constitute a class of iterative algorithms for imaging inverse problems where regularization is performed by an off-the-shelf Gaussian denoiser. These methods have demonstrated impressive visual results, particularly when the denoiser is parameterized by deep neural networks. However, the theoretical convergence of PnP methods has yet to be fully established. This talk begins with an overview of the literature on PnP algorithms, followed by the introduction of new convergence results for these methods when paired with specific denoisers. Our analysis shows that the resulting PnP algorithms converge to stationary points of explicit nonconvex functionals. These algorithms are then applied to various ill-posed inverse problems, including deblurring, super-resolution, and inpainting. Finally, to address inverse problems corrupted by Poisson noise, we will introduce a novel Bregman version of PnP based on the Bregman Proximal Gradient (BPG) optimization algorithm.
Bio
I am a postdoctoral researcher at ENS Paris working with with Gabriel Peyré. I obtained my Ph.D from Université de Bordeaux, co-supervised by Nicolas Papadakis and Arthur Leclaire. My research interests include image restoration, generative modeling, nonconvex optimization. The main objective of my PhD was to develop inovative deep denoising priors along with convergent optimization schemes for solving image inverse problems. I am also one of the main developer of the Python library DeepInv, which provides a unified framework for solving inverse problems using deep neural networks.
{kind=link}
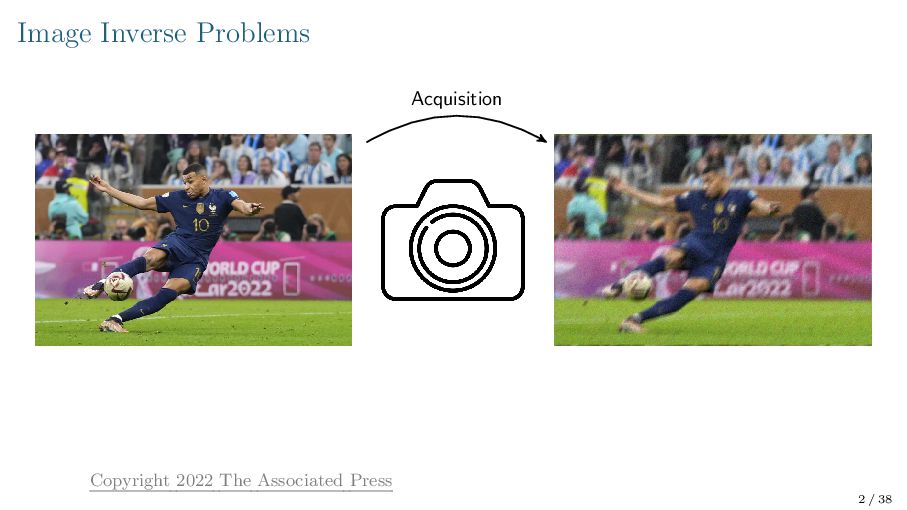{kind=link}
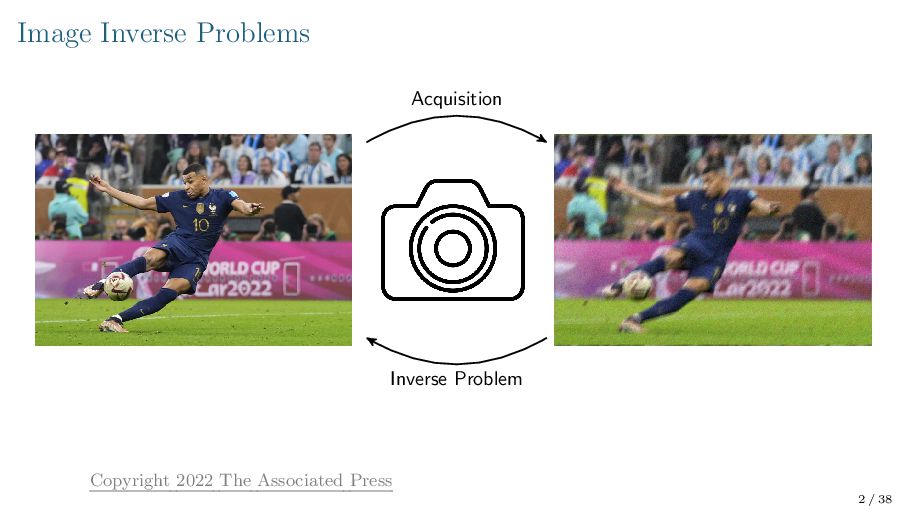{kind=link}
{kind=link}
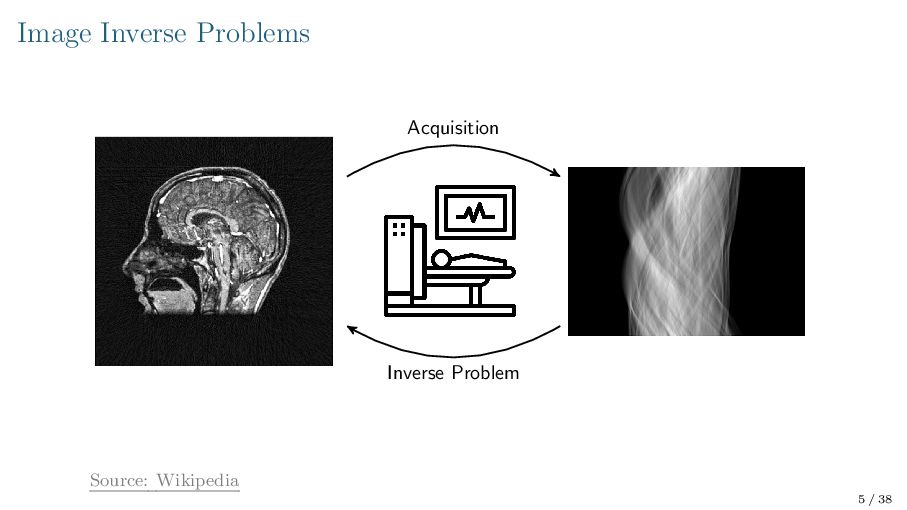
![Image Inverse Problems Acquisition Inverse Problem Sources: Wikipedia, [Isella, ‘11]](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_4.jpg){kind=link}
{kind=link}
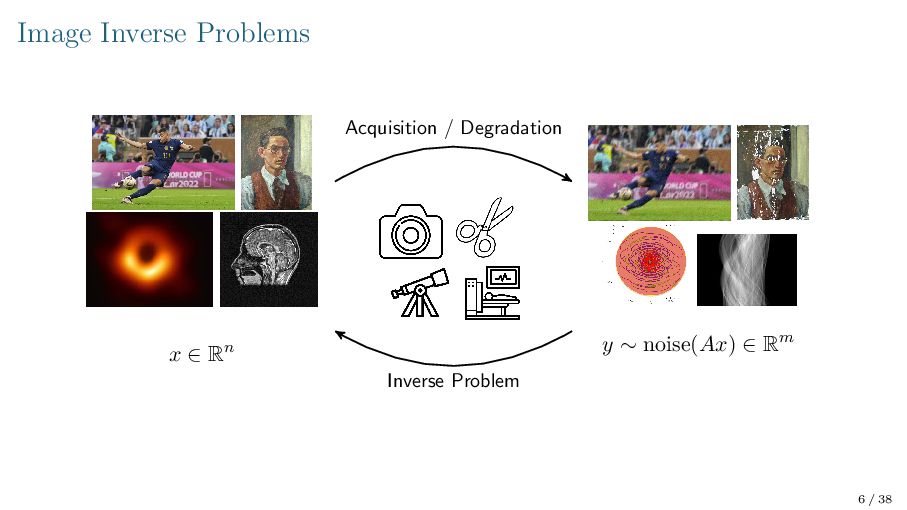{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Heuristics of Plug-and-Play methods [Venkatakrishnan et al. ‘13] Estimate x](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_17.jpg){kind=link}
![Heuristics of Plug-and-Play methods [Venkatakrishnan et al. ‘13] Estimate x](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_18.jpg){kind=link}
![Heuristics of Plug-and-Play methods [Venkatakrishnan et al. ‘13] Estimate x](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gradient-Step Denoiser [H., Leclaire, Papadakis, ‘21] Gradient-Step Denoiser (GS) Dσ](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_45.jpg){kind=link}
![Gradient-Step Denoiser [H., Leclaire, Papadakis, ‘21] Gradient-Step Denoiser (GS) Dσ](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_46.jpg){kind=link}
![Gradient-Step Denoiser [H., Leclaire, Papadakis, ‘21] Gradient-Step Denoiser (GS) Dσ](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_47.jpg){kind=link}
![Gradient-Step Denoiser [H., Leclaire, Papadakis, ‘21] Gradient-Step Denoiser (GS) Dσ](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_48.jpg){kind=link}
![Nonconvex convergence of GradPnP algorithms [H., Leclaire, Papadakis, ‘21] With](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
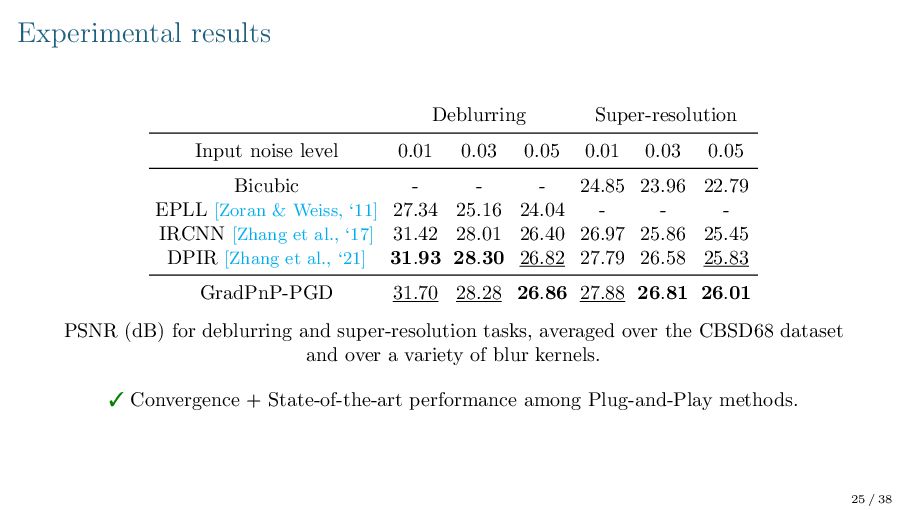{kind=link}
{kind=link}
![Proximal Denoiser[H., Leclaire, Papadakis, ‘22] Dσ = Id −∇gσ =](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_55.jpg){kind=link}
{kind=link}
![Convergence of ProxPnP algorithms [H., Leclaire, Papadakis, ‘22, ‘23] With](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
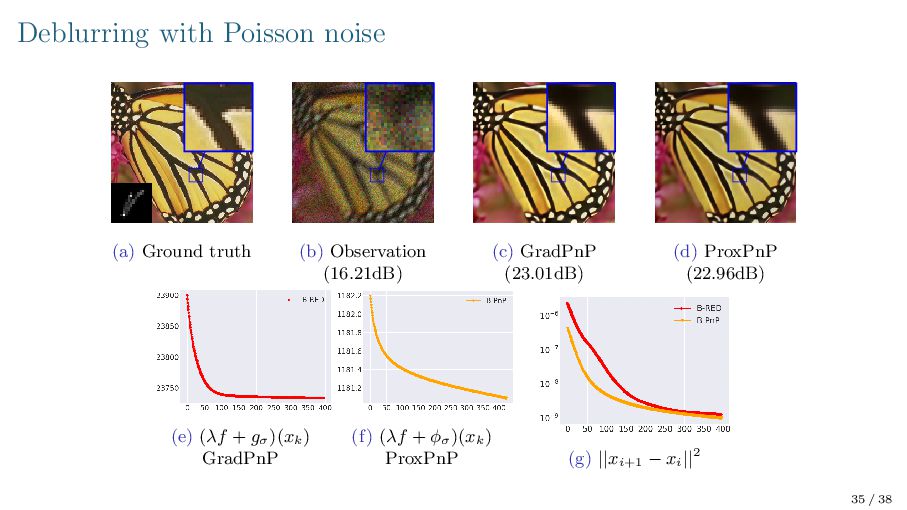{kind=link}
{kind=link}
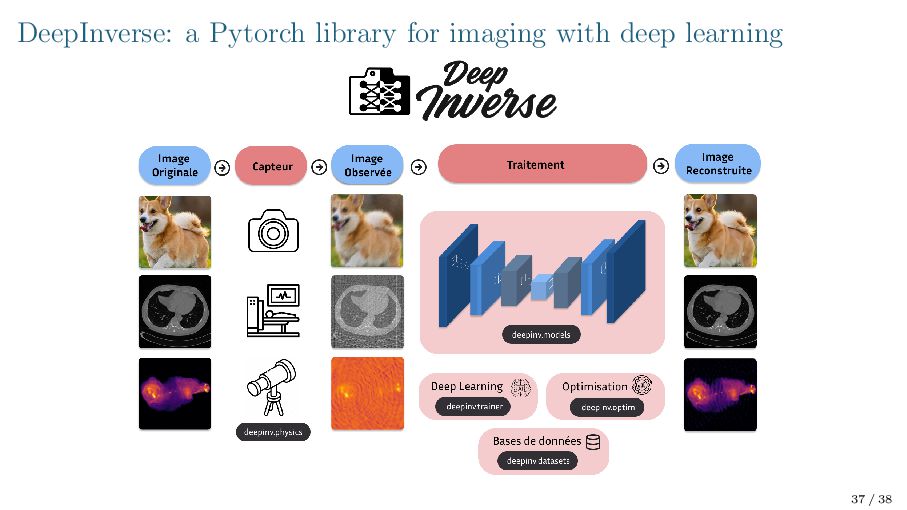{kind=link}
![Thanks for your attention! https://samuelhurault.netlify.app/ [email protected] [H., Leclaire, Papadakis (ICLR](https://files.speakerdeck.com/presentations/9517ba5b18954595a29c186a5e6df5b7/slide_73.jpg){kind=link}