論文紹介: Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile and Noah D. Goodman, 2025
arXiv preprint arXiv:2503.01307v1
https://arxiv.org/abs/2503.01307v1
太田 晋
2025-03-31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
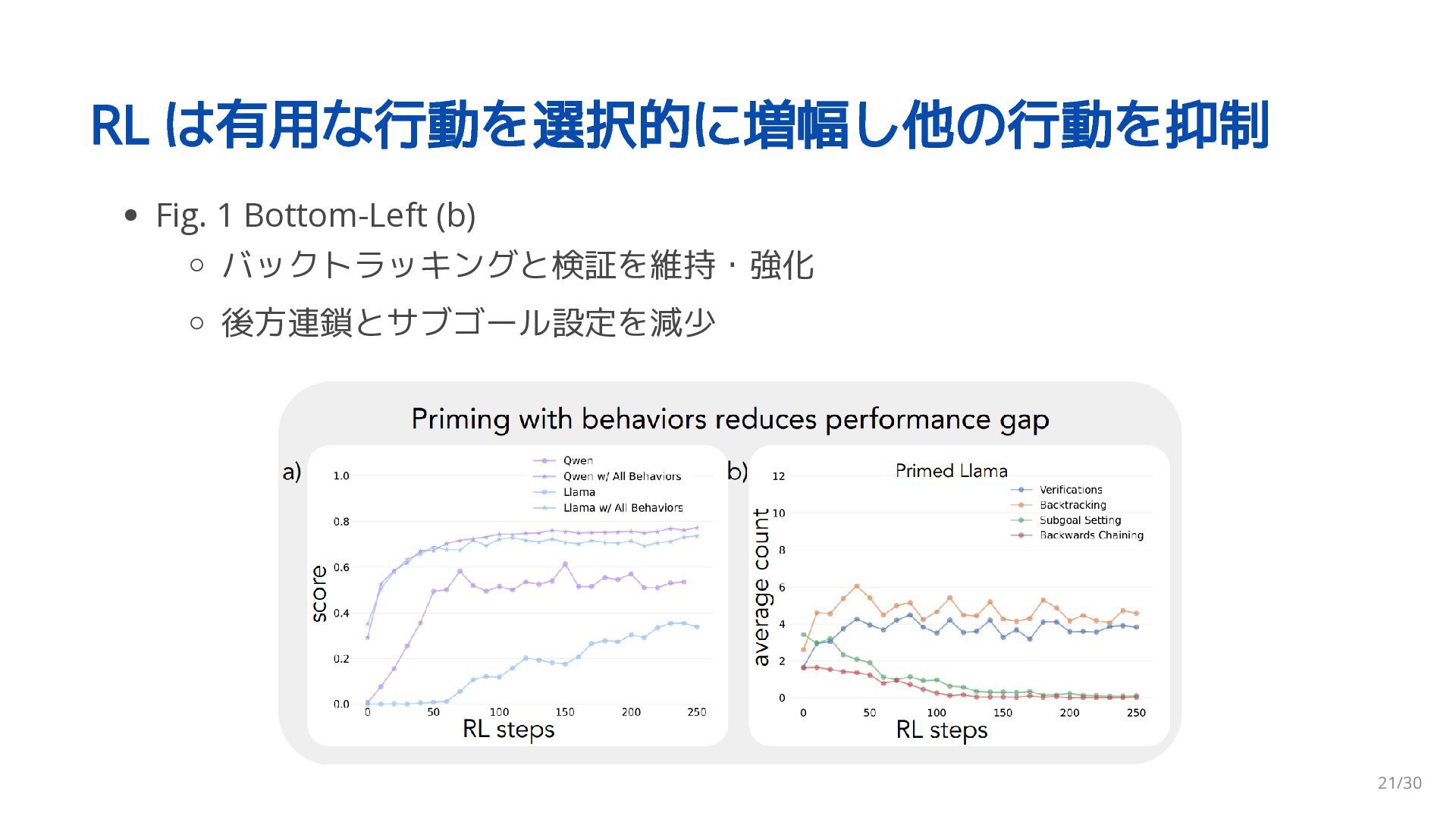{kind=link}
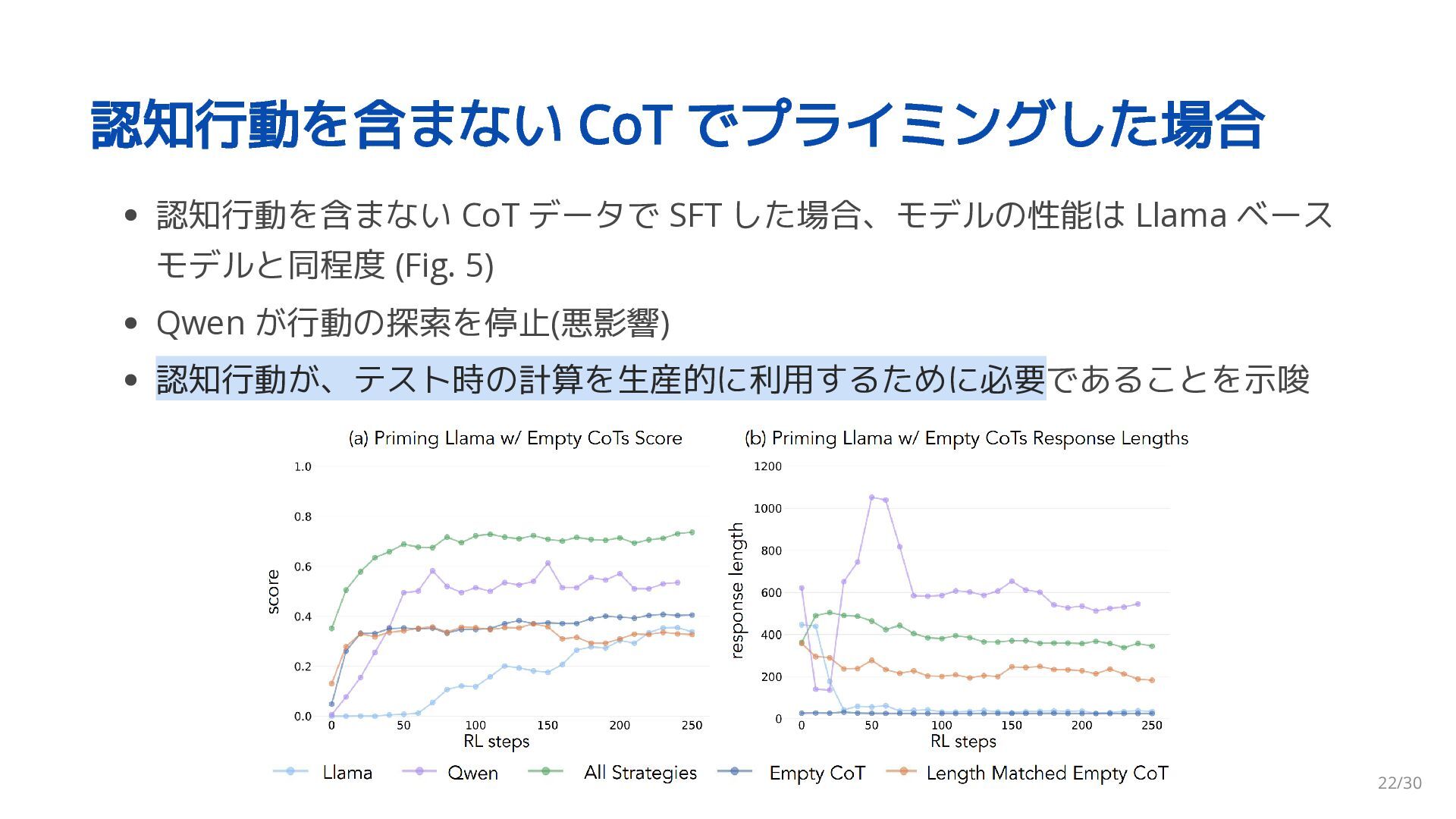{kind=link}
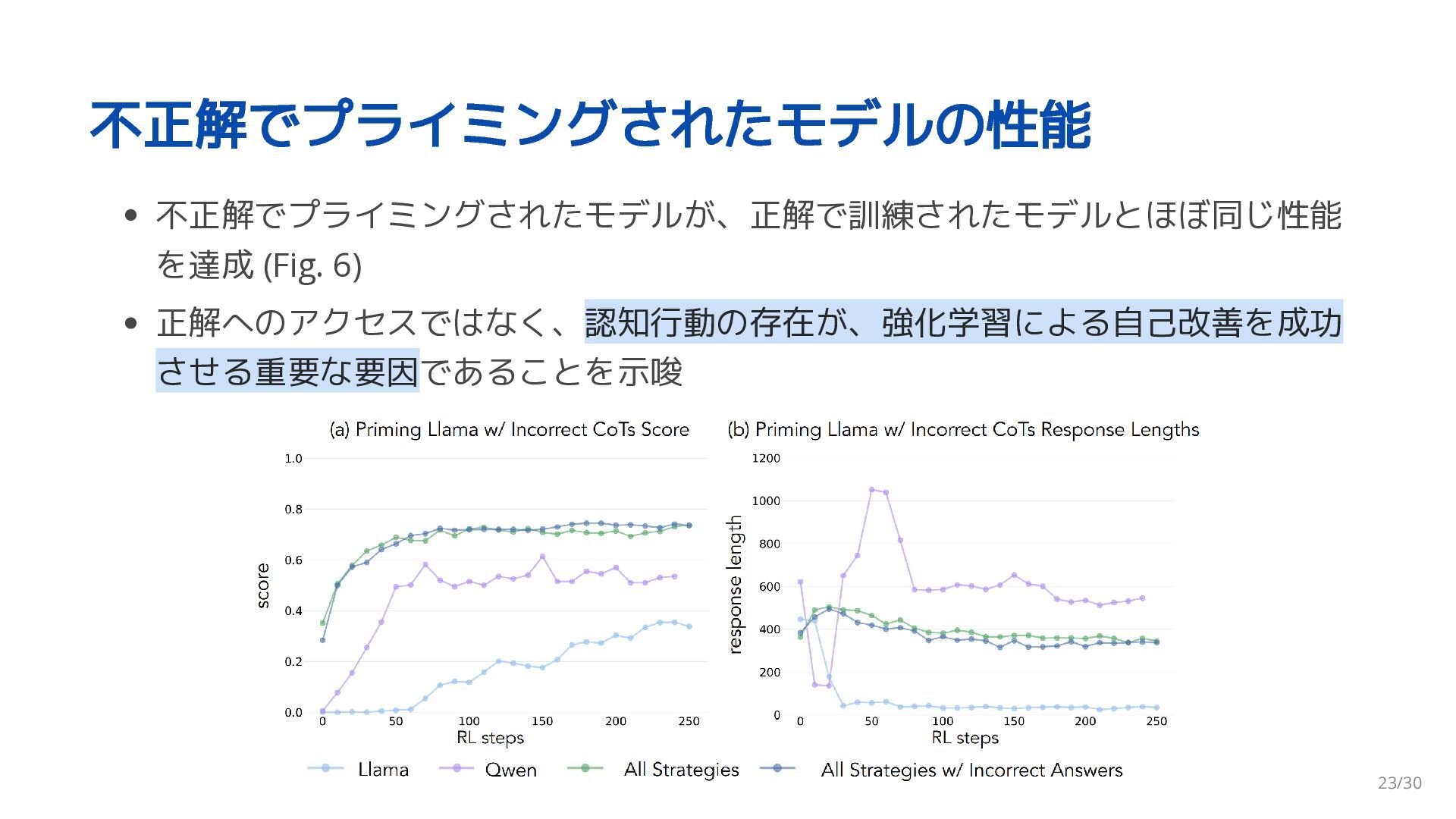{kind=link}
{kind=link}
{kind=link}
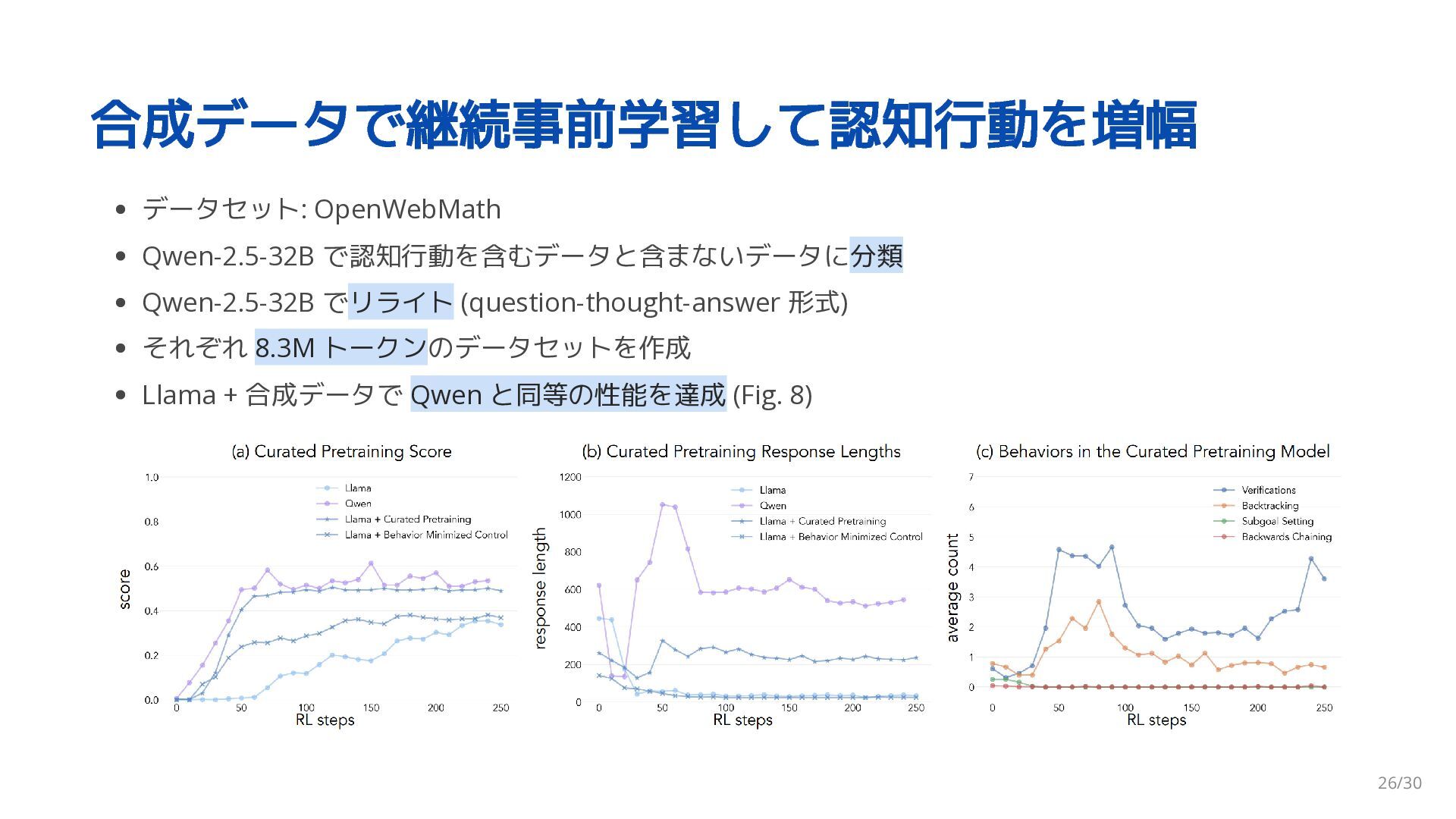{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}