Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Machine learning CI/CD with OSS
Search
shibuiwilliam
March 17, 2022
Technology
180
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Machine learning CI/CD with OSS
https://event.cloudnativedays.jp/cicd2021/talks/1154
shibuiwilliam
March 17, 2022
More Decks by shibuiwilliam
See All by shibuiwilliam
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
0
41
From Prompt Engineering to Loop Engineering
shibuiwilliam
1
360
OntologyとLLMOps
shibuiwilliam
3
75
Rule repository
shibuiwilliam
3
63
LLM時代の検索アーキテクチャと技術的意思決定
shibuiwilliam
4
2.5k
Why Open Dataspacesのまとめ
shibuiwilliam
2
90
マルチモーダル非構造データとの闘い
shibuiwilliam
2
660
飽くなき自動生成への挑戦
shibuiwilliam
1
92
AIエージェントのメモリについて
shibuiwilliam
1
770
Other Decks in Technology
See All in Technology
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2k
次世代ランサムウェア対策の考察 / 20260704 Mitsutoshi Matsuo
shift_evolve
PRO
5
1.7k
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
570
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
8
3.8k
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
200
product engineering with qa
nealle
0
160
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
210
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.3k
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
150
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
370
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
Featured
See All Featured
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
WENDY [Excerpt]
tessaabrams
11
38k
Building Adaptive Systems
keathley
44
3.1k
Building AI with AI
inesmontani
PRO
1
1.1k
Code Reviewing Like a Champion
maltzj
528
40k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
How STYLIGHT went responsive
nonsquared
100
6.2k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
We Have a Design System, Now What?
morganepeng
55
8.2k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
Transcript
OSSで作る 機械学習のCI/CD 2021/09/03 shibui yusuke
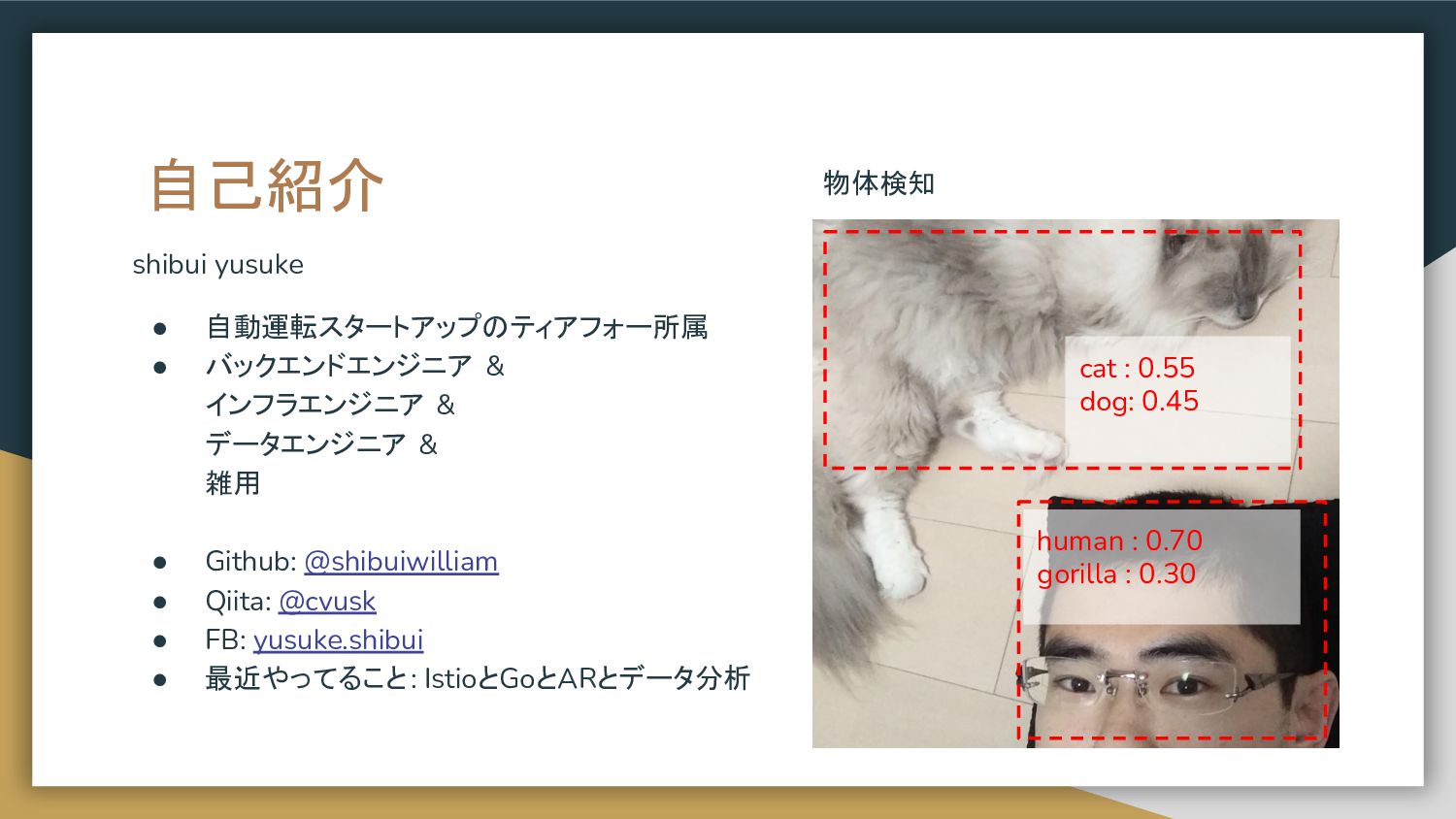
自己紹介 shibui yusuke • 自動運転スタートアップのティアフォー所属 • バックエンドエンジニア & インフラエンジニア &
データエンジニア & 雑用 • Github: @shibuiwilliam • Qiita: @cvusk • FB: yusuke.shibui • 最近やってること: IstioとGoとARとデータ分析 cat : 0.55 dog: 0.45 human : 0.70 gorilla : 0.30 物体検知
今日話すこと • 機械学習システムのCI/CDに必要なことを網羅する ◦ 機械学習のDevOpsと品質 ◦ ちょうどよい規模を考える ◦ 機械学習とシステムのテスト
機械学習のDevOpsと品質
機械学習の実用化の課題 • 機械学習チームのソフトウェア開発の理解不足 • ソフトウェア開発チームの機械学習の理解不足 • 機械学習を0->1だけで終わらせているプロジェクトを散見 → 0->1の次を目指す開発手法が定まっていない
• 機械学習の有用性を試す PoCから次の段階に行くためには機械学習の DevOpsが必要 • 機械学習を含むプロダクトの価値を継続的に引き出すのが MLOps 0->1の次を目指す PoCの数々 ようやく成功した
プロダクト 成長するには なにが足りない? →機械学習の成果を素早く実用化する →実用化の効果を素早く機械学習に取り込む →機械学習とソフトウェアを連携した フィードバックループを実現する
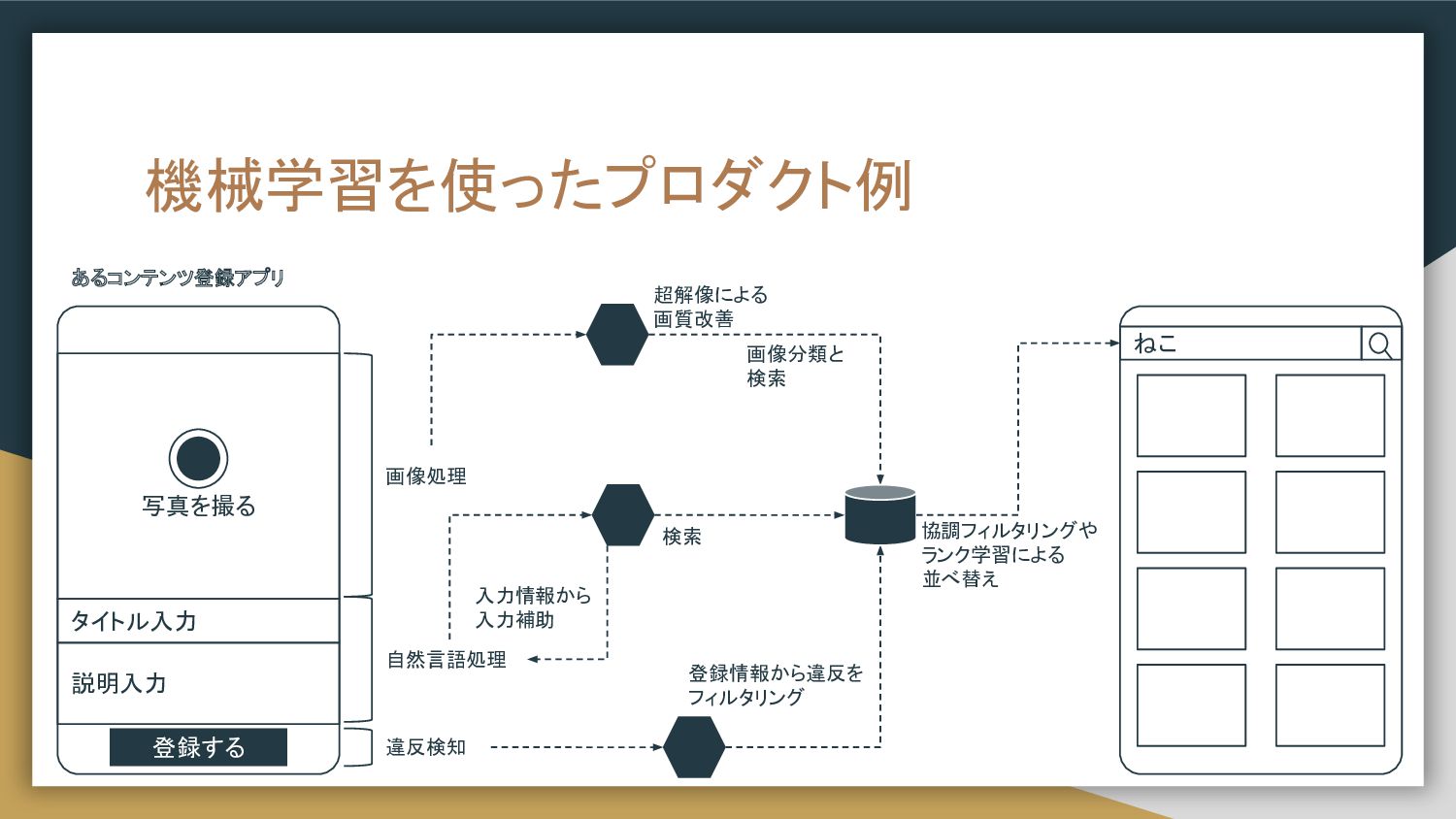
機械学習を使ったプロダクト例 画像処理 写真を撮る タイトル入力 説明入力 登録する 自然言語処理 違反検知 登録情報から違反を フィルタリング
入力情報から 入力補助 超解像による 画質改善 ねこ 検索 協調フィルタリングや ランク学習による 並べ替え あるコンテンツ登録アプリ 画像分類と 検索
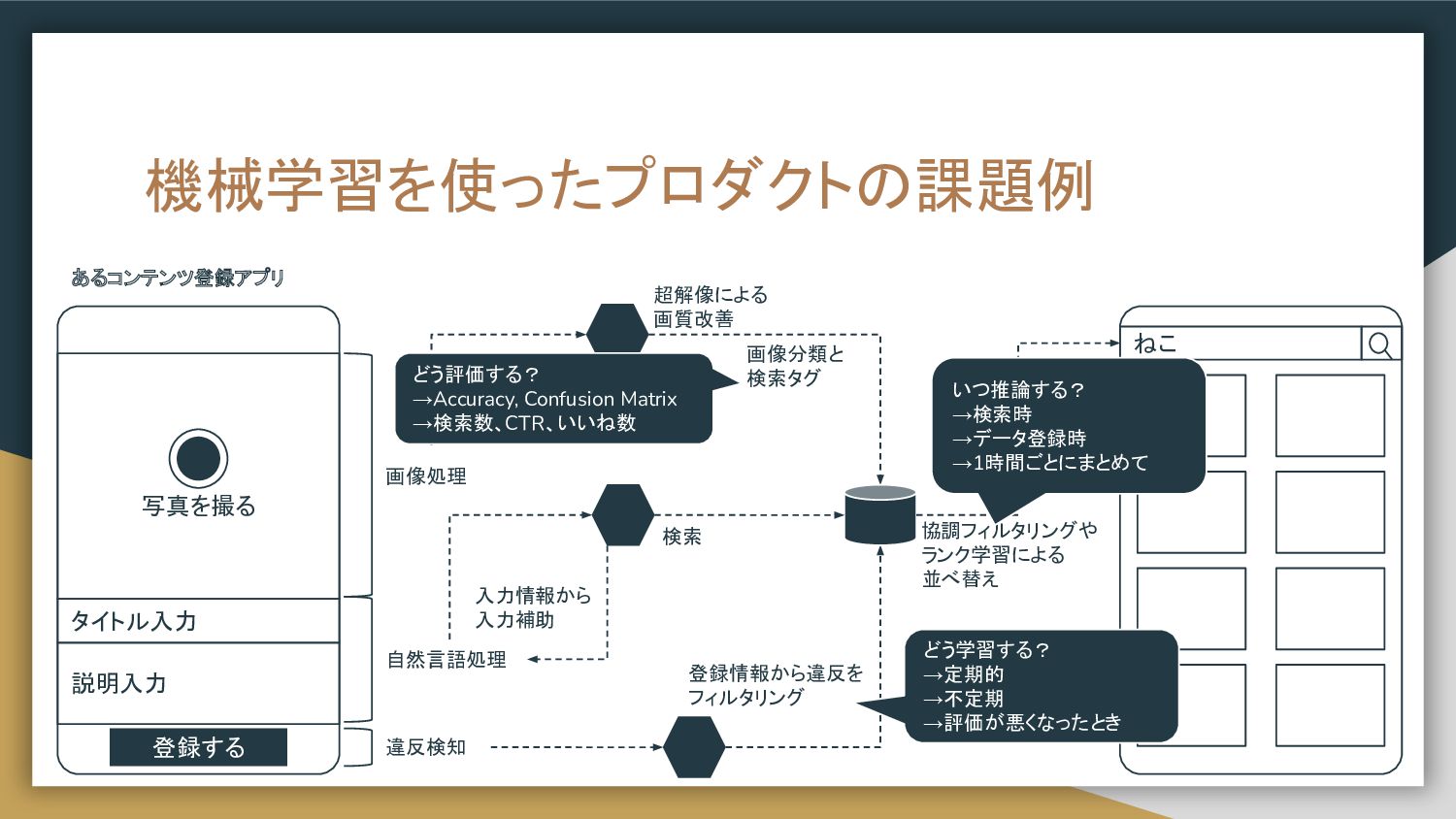
機械学習を使ったプロダクトの課題例 画像処理 写真を撮る タイトル入力 説明入力 登録する 自然言語処理 違反検知 登録情報から違反を フィルタリング
入力情報から 入力補助 超解像による 画質改善 ねこ 検索 協調フィルタリングや ランク学習による 並べ替え あるコンテンツ登録アプリ 画像分類と 検索タグ どう学習する? →定期的 →不定期 →評価が悪くなったとき いつ推論する? →検索時 →データ登録時 →1時間ごとにまとめて どう評価する? →Accuracy, Confusion Matrix →検索数、CTR、いいね数
機械学習を使ったプロダクトのシステム例 写真を撮る タイトル入力 説明入力 登録する ねこ あるコンテンツ登録アプリ ログ DB Storage
監視 学習 モデル proxy 画像 API 推論 API batch BI デプ ロイ 認証 認可 ID 検索 API Item API 推薦 API Text API
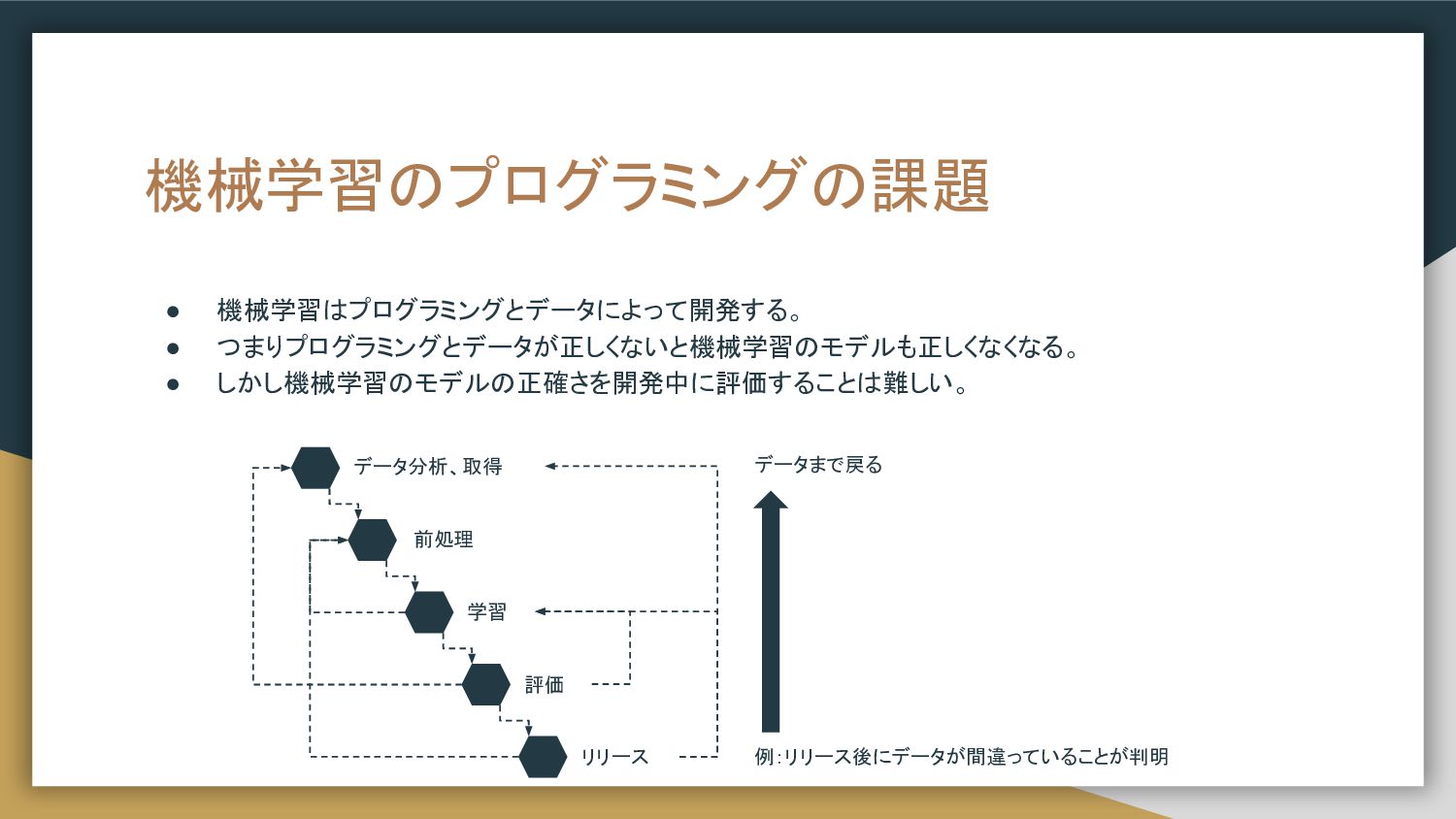
機械学習のプログラミングの課題 • 機械学習はプログラミングとデータによって開発する。 • つまりプログラミングとデータが正しくないと機械学習のモデルも正しくなくなる。 • しかし機械学習のモデルの正確さを開発中に評価することは難しい。 データ分析、取得 前処理 学習
評価 リリース 例:リリース後にデータが間違っていることが判明 データまで戻る
ちょうどよい規模を考える
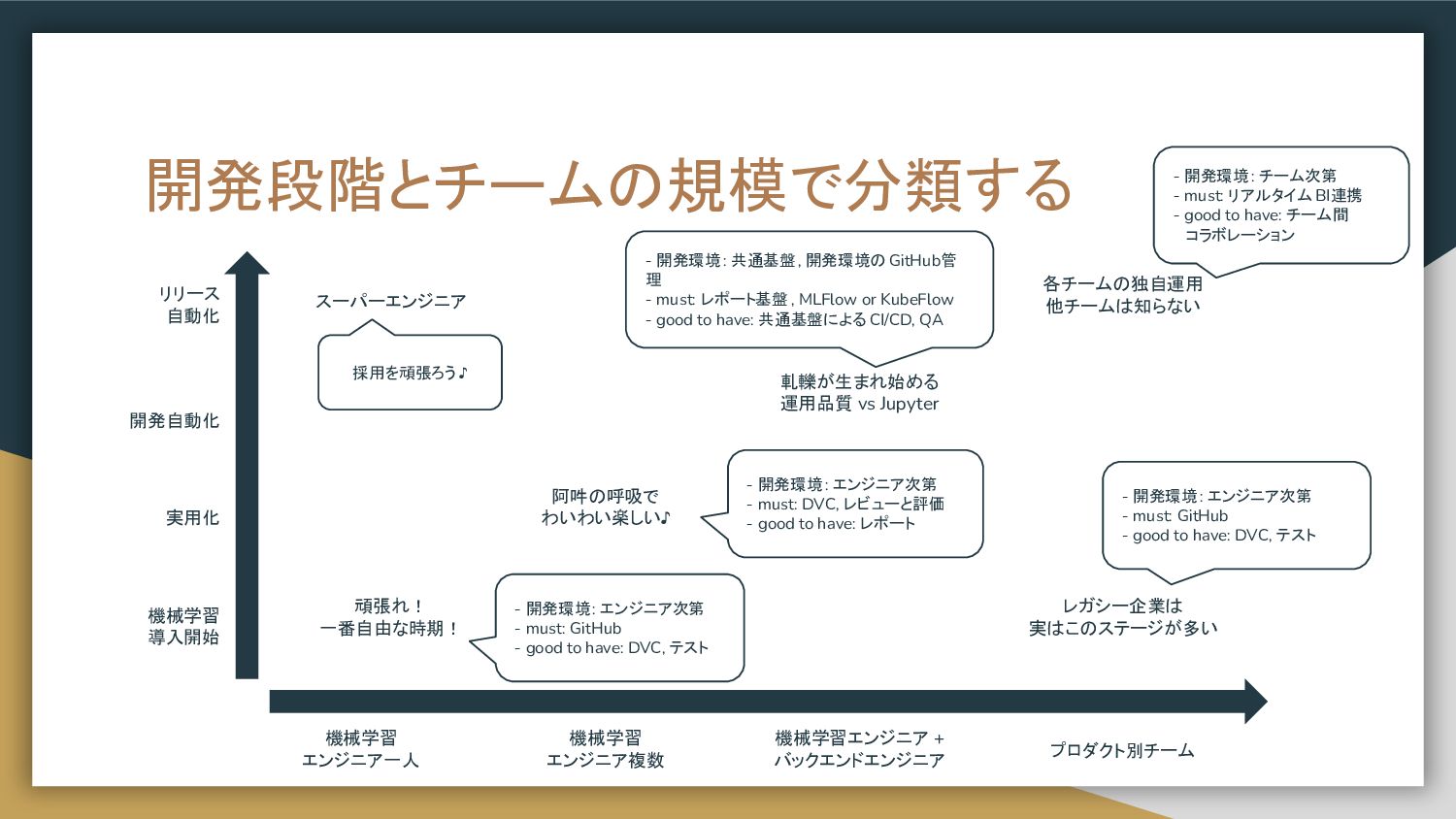
開発段階とチームの規模で分類する 機械学習 導入開始 実用化 開発自動化 リリース 自動化 機械学習 エンジニア一人 機械学習
エンジニア複数 機械学習エンジニア + バックエンドエンジニア プロダクト別チーム 頑張れ! 一番自由な時期! 阿吽の呼吸で わいわい楽しい♪ 軋轢が生まれ始める 運用品質 vs Jupyter 各チームの独自運用 他チームは知らない スーパーエンジニア レガシー企業は 実はこのステージが多い
開発段階とチームの規模で分類する 機械学習 導入開始 実用化 開発自動化 リリース 自動化 機械学習 エンジニア一人 機械学習
エンジニア複数 機械学習エンジニア + バックエンドエンジニア プロダクト別チーム 頑張れ! 一番自由な時期! 阿吽の呼吸で わいわい楽しい♪ 軋轢が生まれ始める 運用品質 vs Jupyter 各チームの独自運用 他チームは知らない スーパーエンジニア レガシー企業は 実はこのステージが多い 採用を頑張ろう ♪ - 開発環境: エンジニア次第 - must: GitHub - good to have: DVC, テスト - 開発環境: エンジニア次第 - must: GitHub - good to have: DVC, テスト - 開発環境: エンジニア次第 - must: DVC, レビューと評価 - good to have: レポート - 開発環境: チーム次第 - must: リアルタイム BI連携 - good to have: チーム間 コラボレーション - 開発環境: 共通基盤, 開発環境の GitHub管 理 - must: レポート基盤 , MLFlow or KubeFlow - good to have: 共通基盤による CI/CD, QA
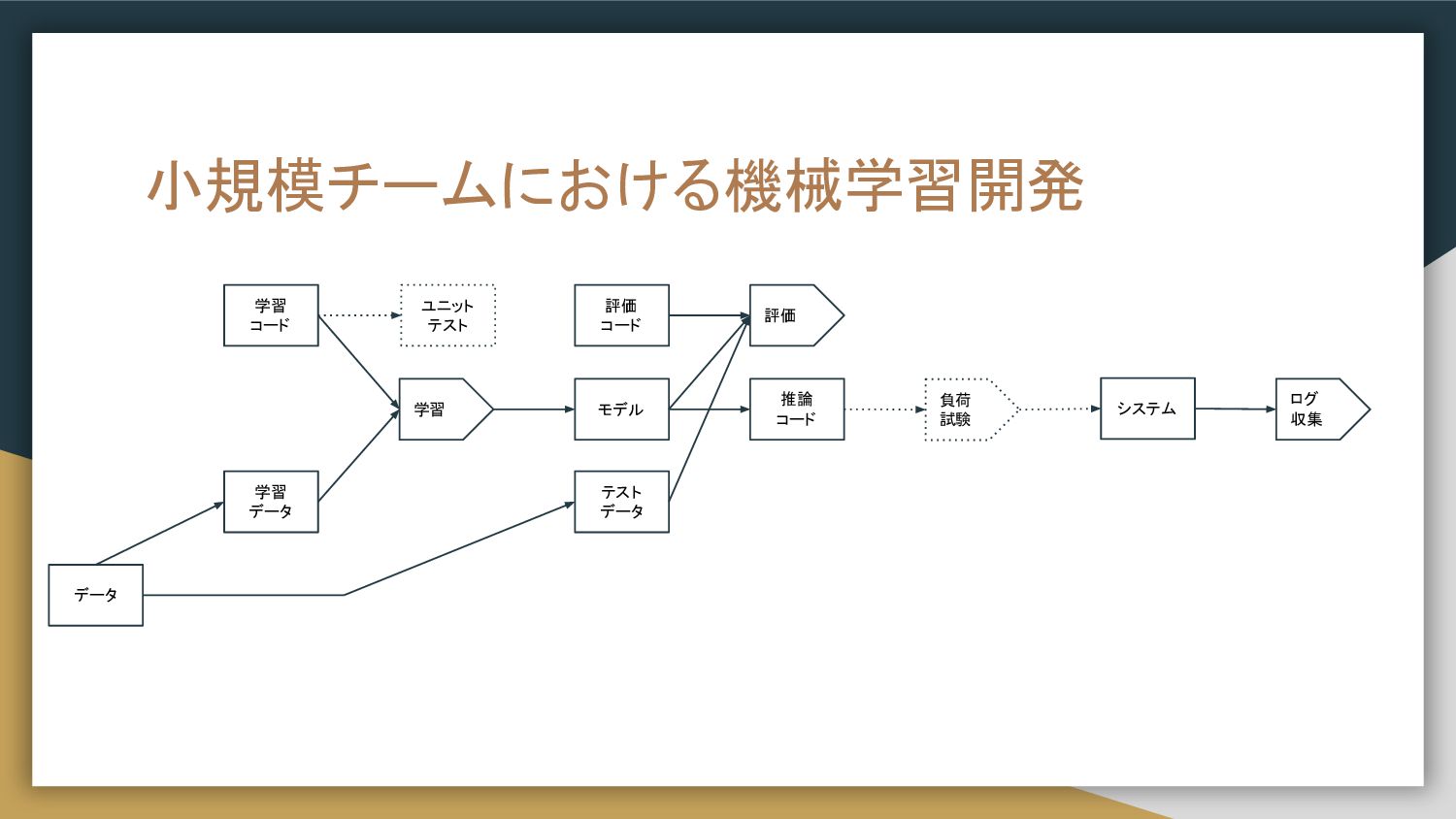
小規模チームにおける機械学習開発 学習 コード 学習 データ 学習 評価 モデル 推論 コード
テスト データ 評価 コード システム 負荷 試験 ログ 収集 データ ユニット テスト
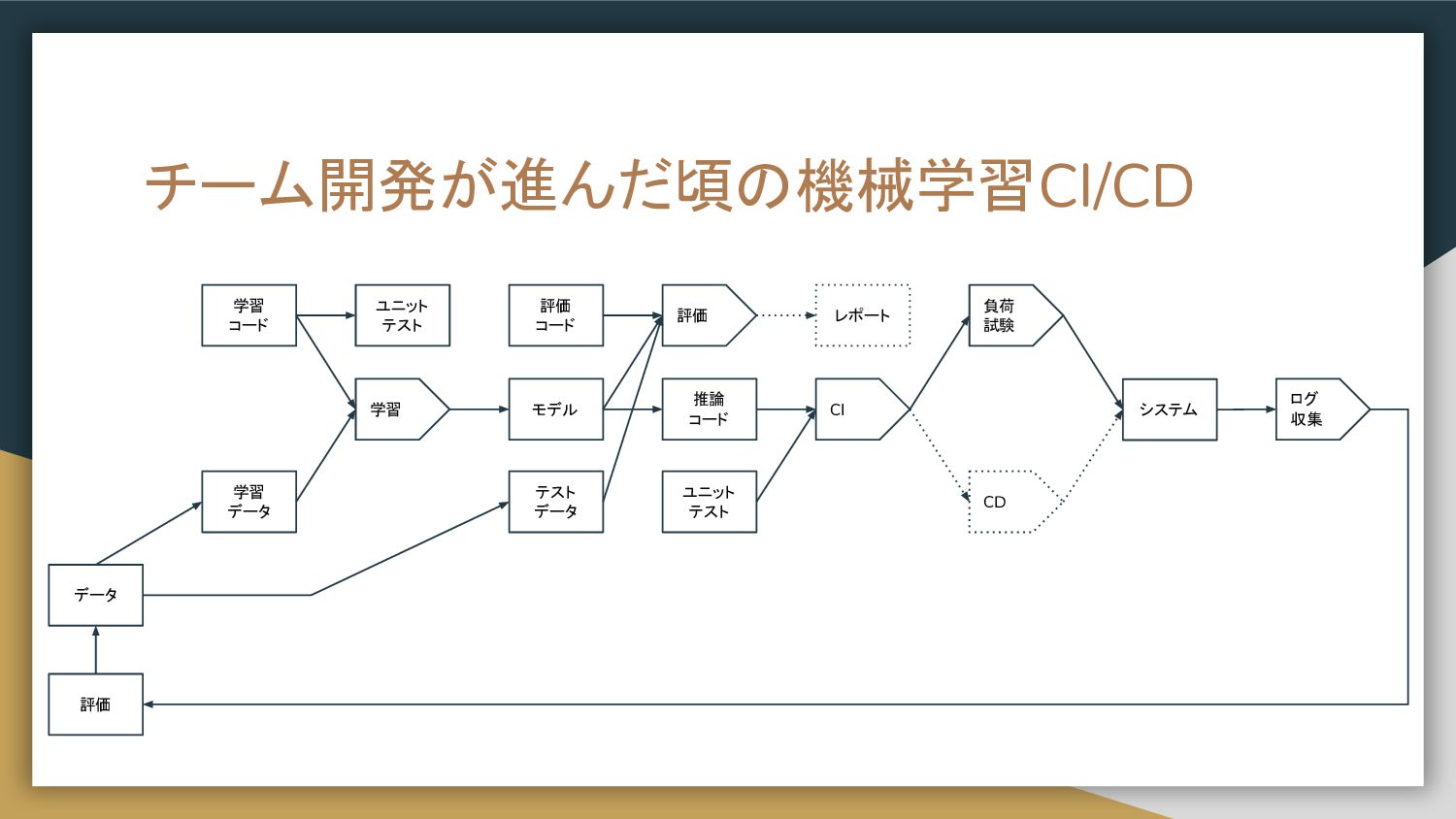
チーム開発が進んだ頃の機械学習CI/CD 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
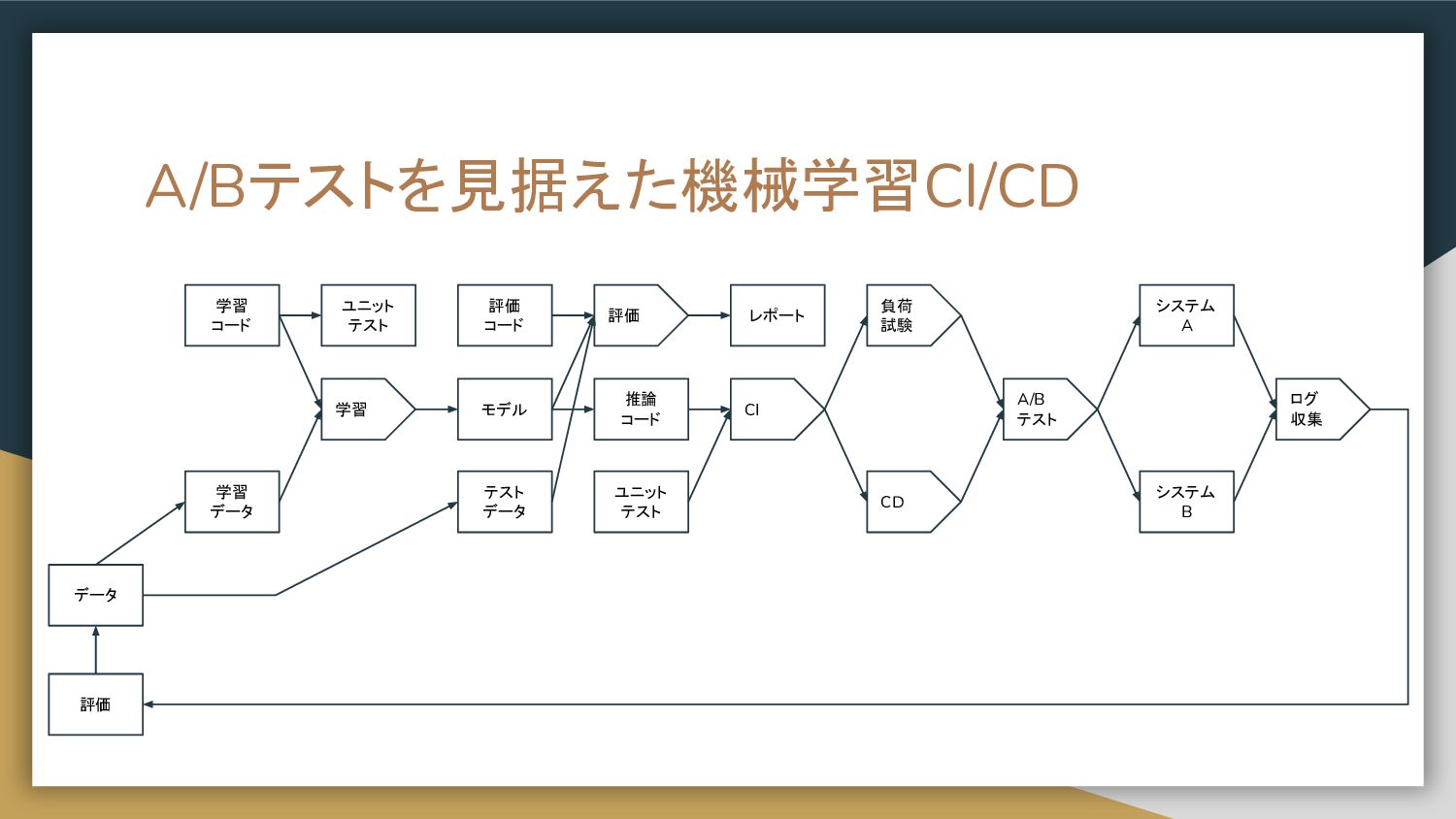
A/Bテストを見据えた機械学習CI/CD 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
機械学習とシステムのテスト
学習のユニットテスト 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト
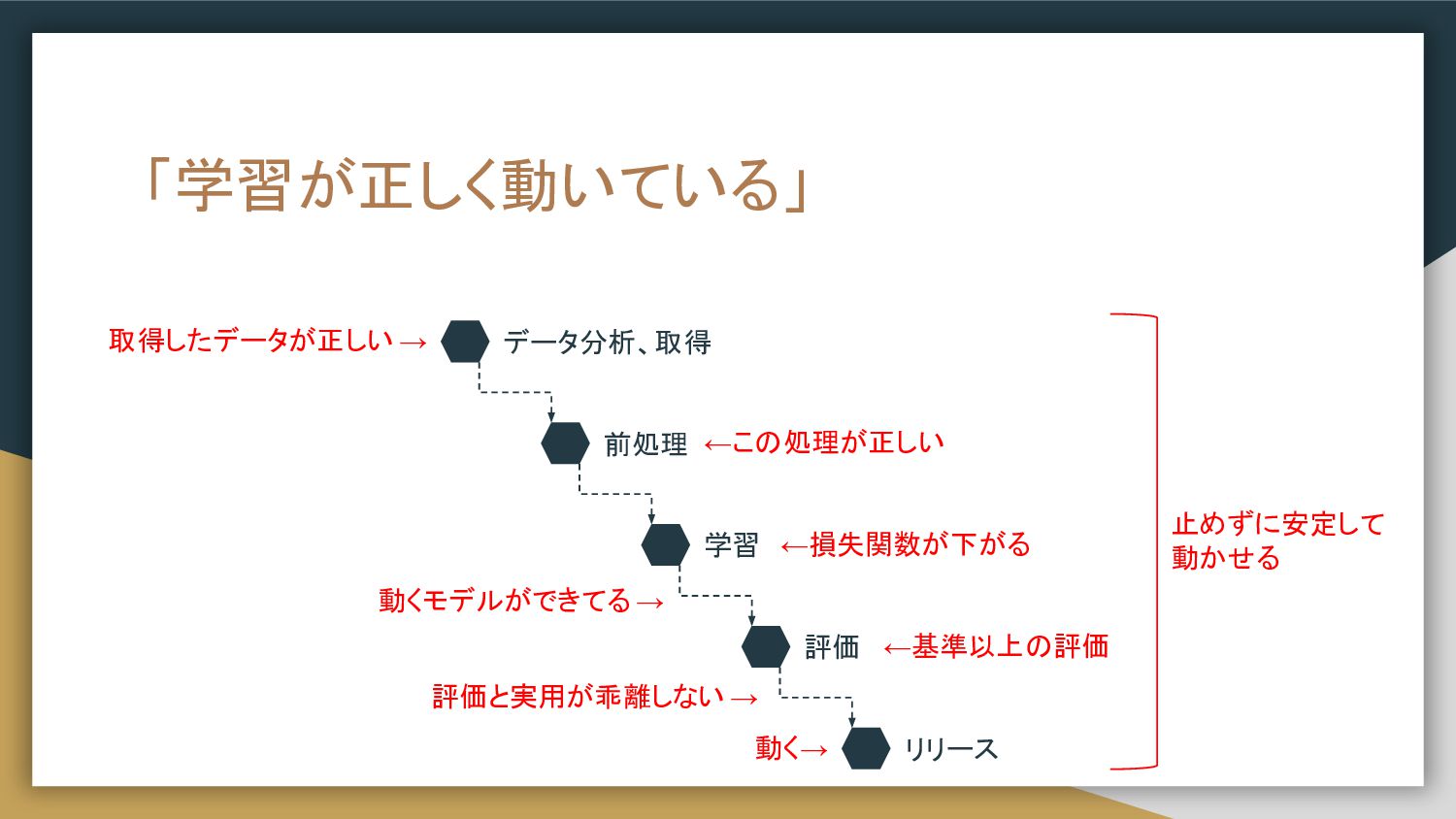
「学習が正しく動いている」 取得したデータが正しい → ←この処理が正しい 動くモデルができてる → ←基準以上の評価 評価と実用が乖離しない → 止めずに安定して
動かせる データ分析、取得 前処理 学習 評価 リリース ←損失関数が下がる 動く→
取得したデータが正しい • Data validation ◦ データの形式が正しい ▪ データ型が正しい: intになる値にfloatやstrが含まれていない ▪
データの範囲が正しい:身長データに 3cmや300cmのようなありえない値が含まれていない ◦ データの分布が正しい ▪ 単位が正しい:cmで登録している身長データに mやmmによる身長が含まれていない ▪ 分布が偏っていない:平均 170cm, 中央値169cmのデータを分割した結果、平均、中央値が乖離して いない
取得したデータが正しい import pandas import pandera schema = pa.DataFrameSchema({ "gender": pa.Column(str,
checks=pa.Check(lambda x: x in _genders , element_wise=True, error=f"gender must be {_genders}"), ), "height_cm": pa.Column(float, checks=[ pa.Check(lambda x: 130 <= x <= 210 , element_wise=True, error=f"height must be between [130, 210]", ), pa.Hypothesis.two_sample_ttest( sample1="male", sample2="female", groupby="gender", relationship="greater_than", alpha=0.01, equal_var=True, ), ], ), }) df = pd.DataFrame(data = {"gender": genders, "height_cm": heights}) df = schema(df) • PythonのPandasとPanderaによるdata validation。 • カラムごとにdata schemaを定義し、 チェックを挟むことで取得したデータの 正しさを検証する。 • Hypothesis testingを活用することで複数 カラム間の妥当性をテストすることが 可能。
取得したデータが正しい import pytest import math import collections import numpy as
np # 学習ラベルとテストラベルの偏りをテスト def test_labels_distribution(y_train, y_test): tr_counter = collections.Counter(y_train) te_counter = collections.Counter(y_test) for (trk, trv), (tek, tev) in zip(tr_counter.items(), te_counter.items()): assert math.isclose(trv, tev, rel_tol=0.01, abs_tol=0.0) # 画像データの色の偏りをテスト def kl_divergence(a: np.ndarray, b: np.ndarray, bins=10, epsilon=0.00001): a_hist, _ = np.histogram(a, bins=bins) b_hist, _ = np.histogram(b, bins=bins) a_hist = (a_hist+epsilon) / np.sum(a_hist) b_hist = (b_hist+epsilon) / np.sum(b_hist) return np.sum([ai * np.log(ai / bi) for ai, bi in zip(a_hist, b_hist)]) def test_image_bias(train_image: np.ndarray, test_image: np.ndarray): assert kl_divergence(train_image, test_image) < 0.1 • 学習時のデータの偏りをテストする • 学習データとテストデータで傾向が異なる状態 を防ぐ目的 • 研究開発時にはTensorBoardやKnow Your Dataが便利 https://knowyourdata.withgoogle.com/ • CI/CDや学習の自動化を進める際は、 Data Validation同様にデータの異常を検知 するためのユニットテストを書く
機械学習開発のテスト • ソフトウェア開発ではプログラムを通してロジックをテストする • 機械学習ではコードを通してデータで確率をテストする YES or NO 0 ~
1 ソフトウェア開発のテスト 機械学習のテスト 入力 正解 出力 assert 関数 指標 推論 evaluate モデル 関数 テスト通過率:95/100 Accuracy:0.99 Precision:0.95 Recall:0.60 23 データ
# 少量データで学習が動く&進むことをテスト @pytest.mark.parametrize( (“model”, "train_path", “test_path” “epochs”), [(model, “/tmp/small_train/”, “/tmp/small_test/”,
10)], ) def test_train( model: nn.Module, train_path: str, test_path: str, epochs: int, ): trainloader = make_dataloader(train_path) testloader = make_dataloader(test_path) init_accuracy = evaluate(model, testloader) losses = train(model, epochs, trainloader) assert losses[0] > losses[-1] trained_accuracy = evaluate(model, testdata) assert init_accuracy < trained_accuracy 機械学習開発のテスト def make_dataloader(data_path: str) -> DataLoader: return dataloader(data_path) def train( model: nn.Module, epochs: int, trainloader: DataLoader, ) -> List[float]: losses = [] for epoch in range(epochs): average_loss = train_once(model, trainloader) losses.append(average_loss) model.save() return losses def evaluate( model_path: str, testloader: DataLoader, ) -> List[float]: predictor = Model(model_path) evaluations = predictor.evaluate(testloader) return evaluations
モデルの評価 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
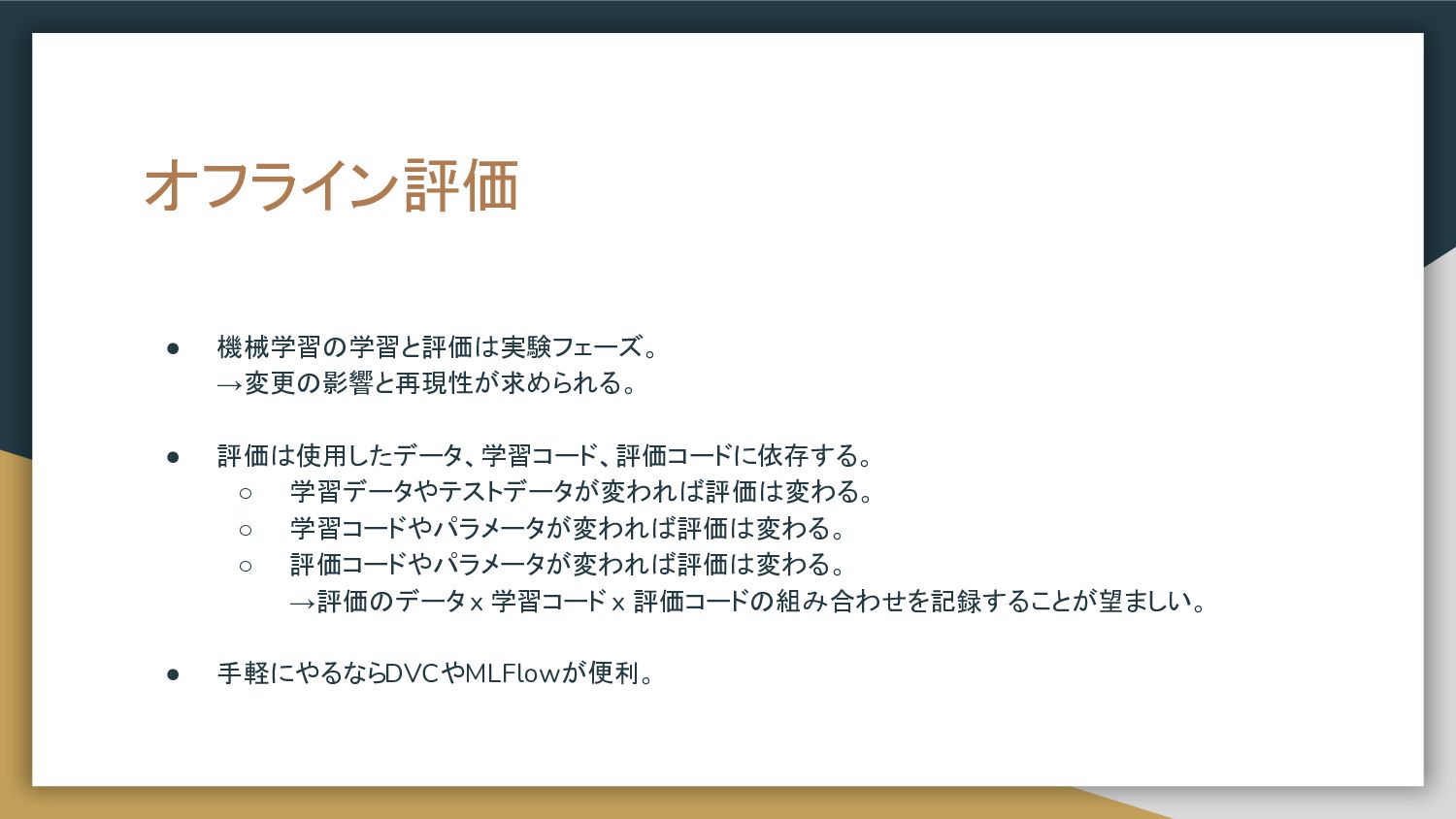
オフライン評価 • 機械学習の学習と評価は実験フェーズ。 →変更の影響と再現性が求められる。 • 評価は使用したデータ、学習コード、評価コードに依存する。 ◦ 学習データやテストデータが変われば評価は変わる。 ◦ 学習コードやパラメータが変われば評価は変わる。
◦ 評価コードやパラメータが変われば評価は変わる。 →評価のデータ x 学習コード x 評価コードの組み合わせを記録することが望ましい。 • 手軽にやるならDVCやMLFlowが便利。
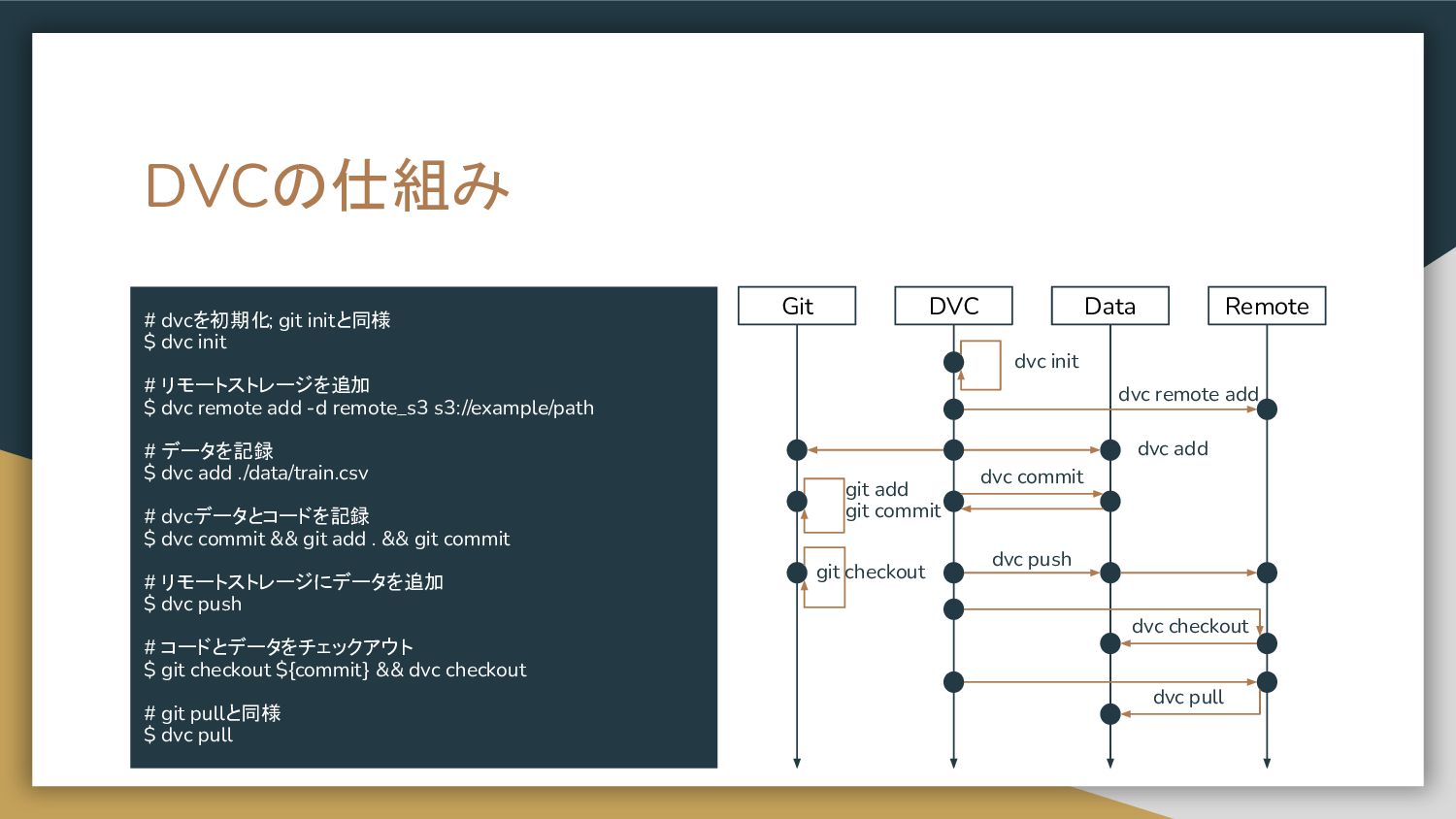
DVCの仕組み • Data Version Control • 機械学習で使用するデータをGitと連携してバー ジョン管理する。 • データはハッシュとともにリモート
ストレージ(S3やGCS等)に保存。 • データの変更を記録してハッシュのみGitで管理 する。
DVCの仕組み # dvcを初期化; git initと同様 $ dvc init # リモートストレージを追加
$ dvc remote add -d remote_s3 s3://example/path # データを記録 $ dvc add ./data/train.csv # dvcデータとコードを記録 $ dvc commit && git add . && git commit # リモートストレージにデータを追加 $ dvc push # コードとデータをチェックアウト $ git checkout ${commit} && dvc checkout # git pullと同様 $ dvc pull Git DVC Data Remote dvc init dvc remote add dvc add git add git commit dvc push git checkout dvc checkout dvc pull dvc commit
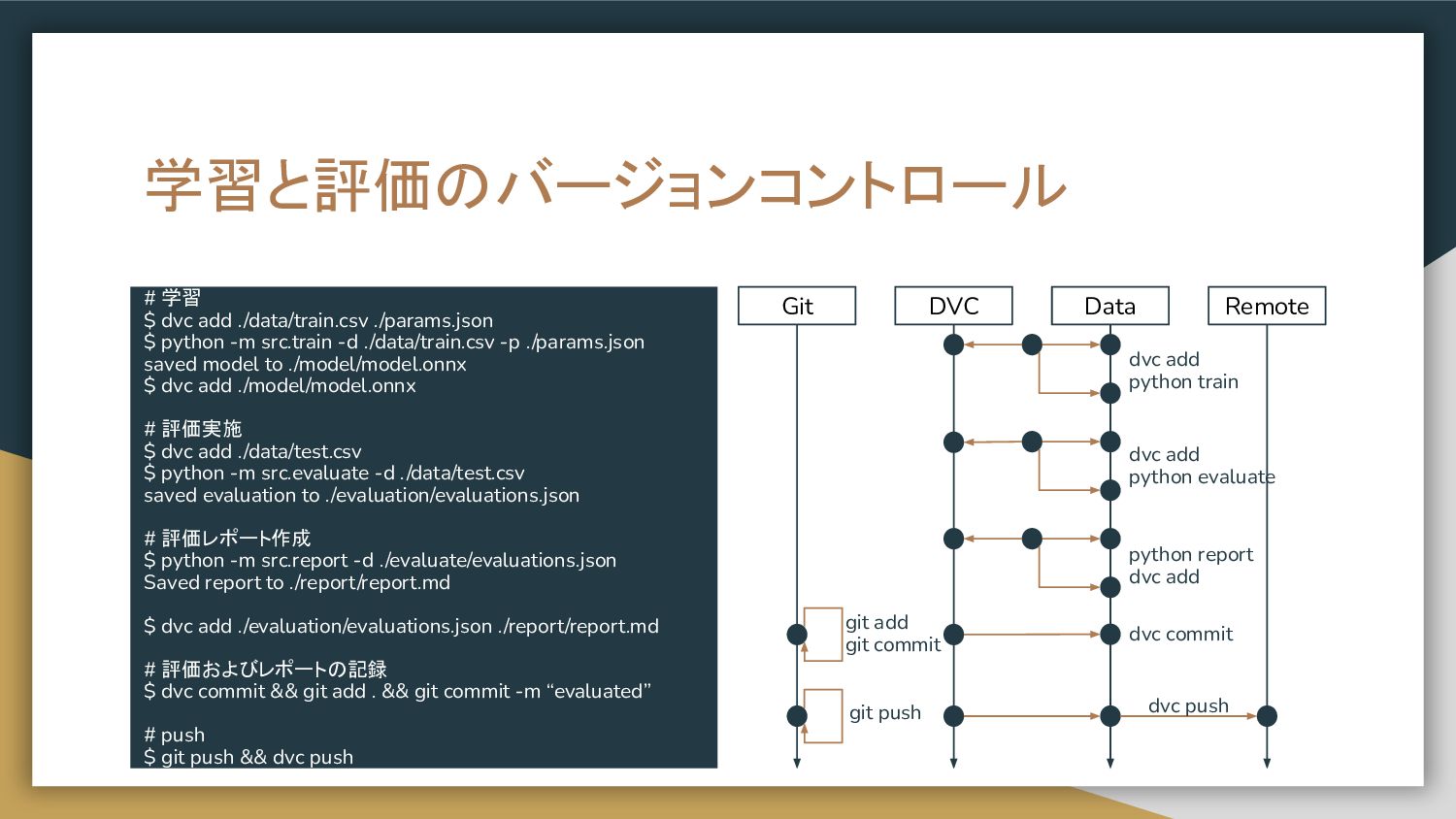
学習と評価のバージョンコントロール # 学習 $ dvc add ./data/train.csv ./params.json $ python
-m src.train -d ./data/train.csv -p ./params.json saved model to ./model/model.onnx $ dvc add ./model/model.onnx # 評価実施 $ dvc add ./data/test.csv $ python -m src.evaluate -d ./data/test.csv saved evaluation to ./evaluation/evaluations.json # 評価レポート作成 $ python -m src.report -d ./evaluate/evaluations.json Saved report to ./report/report.md $ dvc add ./evaluation/evaluations.json ./report/report.md # 評価およびレポートの記録 $ dvc commit && git add . && git commit -m “evaluated” # push $ git push && dvc push Git DVC Data Remote git add git commit dvc commit dvc add python evaluate python report dvc add dvc push git push dvc add python train
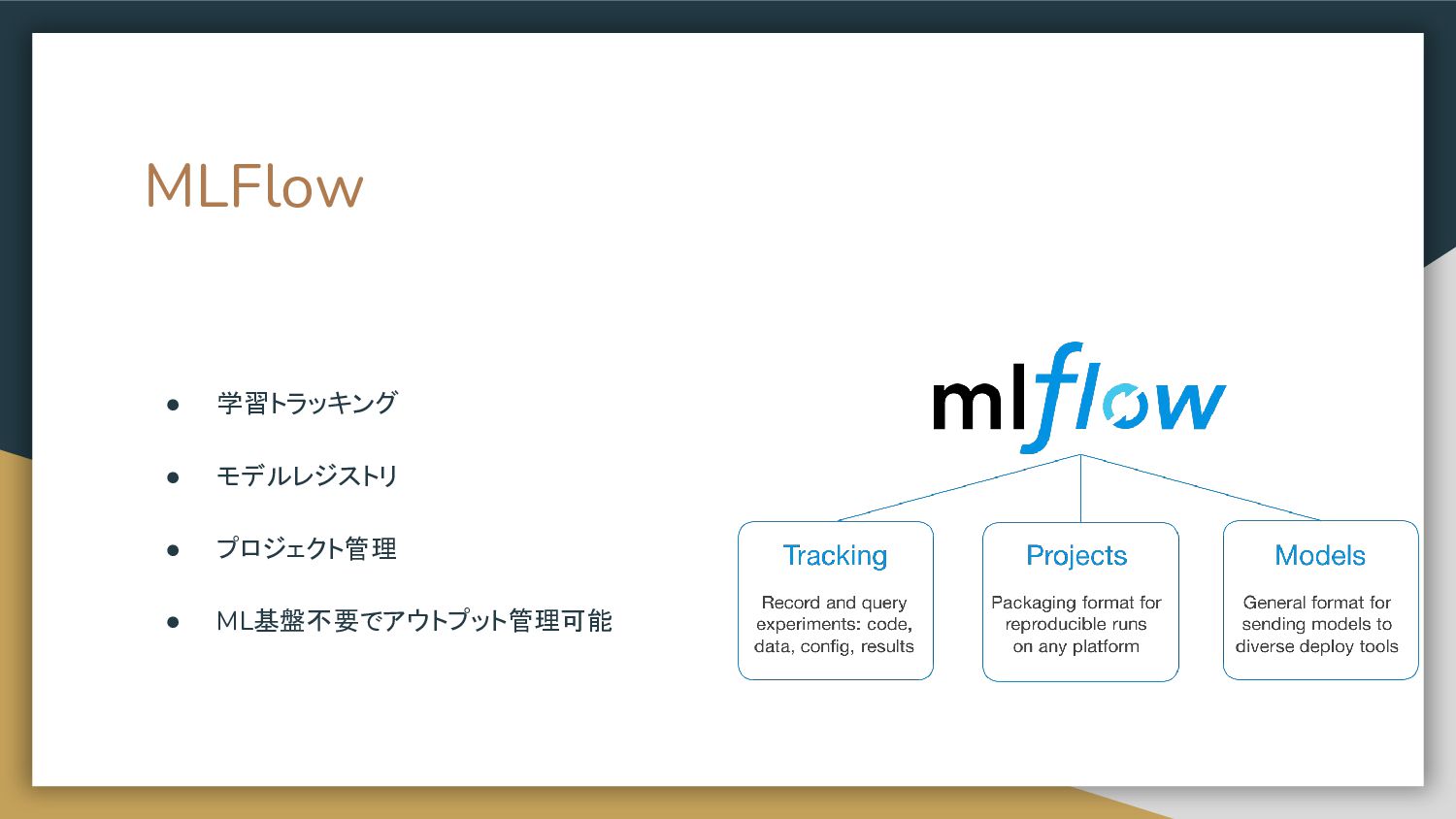
MLFlow • 学習トラッキング • モデルレジストリ • プロジェクト管理 • ML基盤不要でアウトプット管理可能
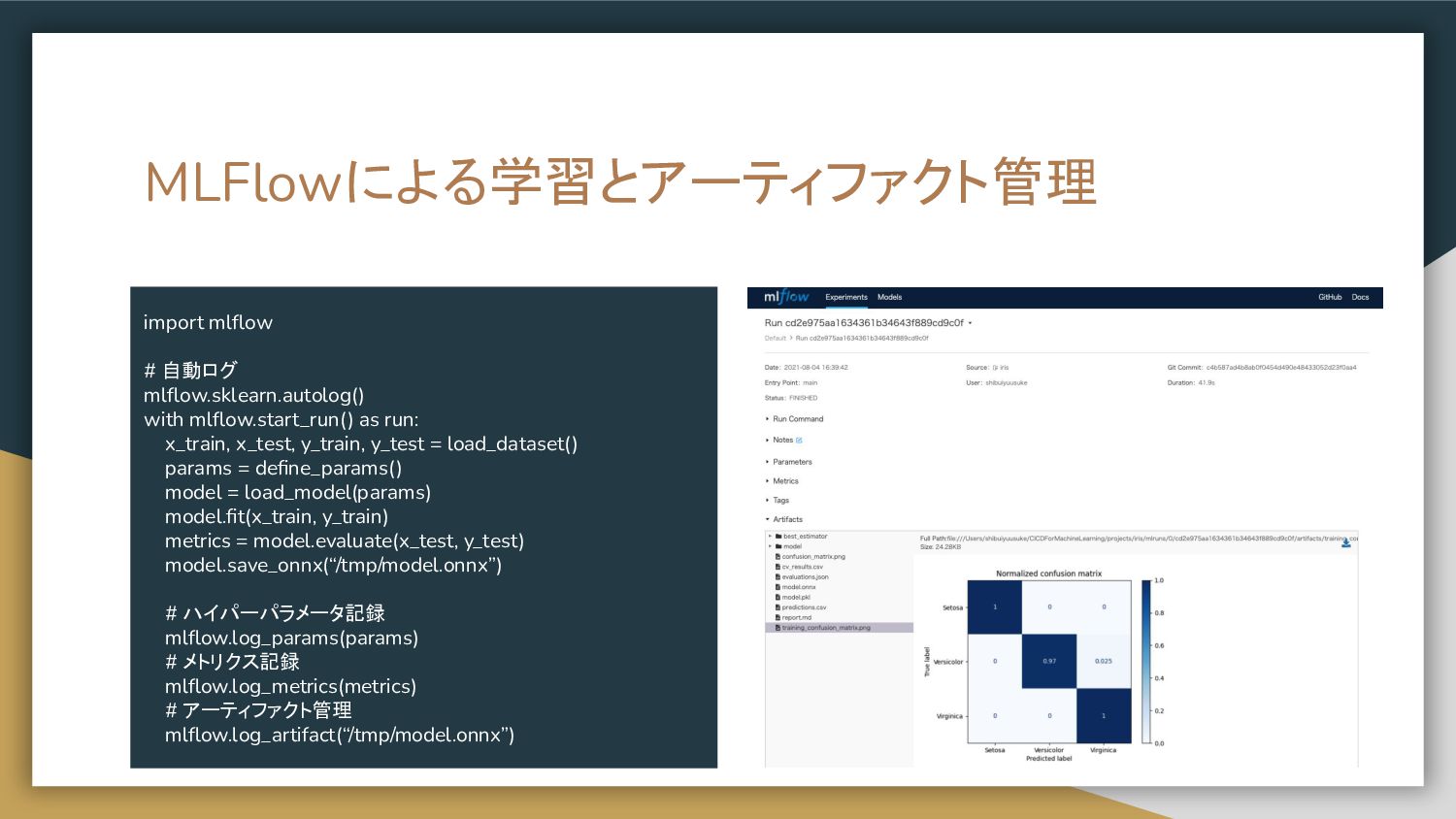
MLFlowによる学習とアーティファクト管理 import mlflow # 自動ログ mlflow.sklearn.autolog() with mlflow.start_run() as run:
x_train, x_test, y_train, y_test = load_dataset() params = define_params() model = load_model(params) model.fit(x_train, y_train) metrics = model.evaluate(x_test, y_test) model.save_onnx(“/tmp/model.onnx”) # ハイパーパラメータ記録 mlflow.log_params(params) # メトリクス記録 mlflow.log_metrics(metrics) # アーティファクト管理 mlflow.log_artifact(“/tmp/model.onnx”)
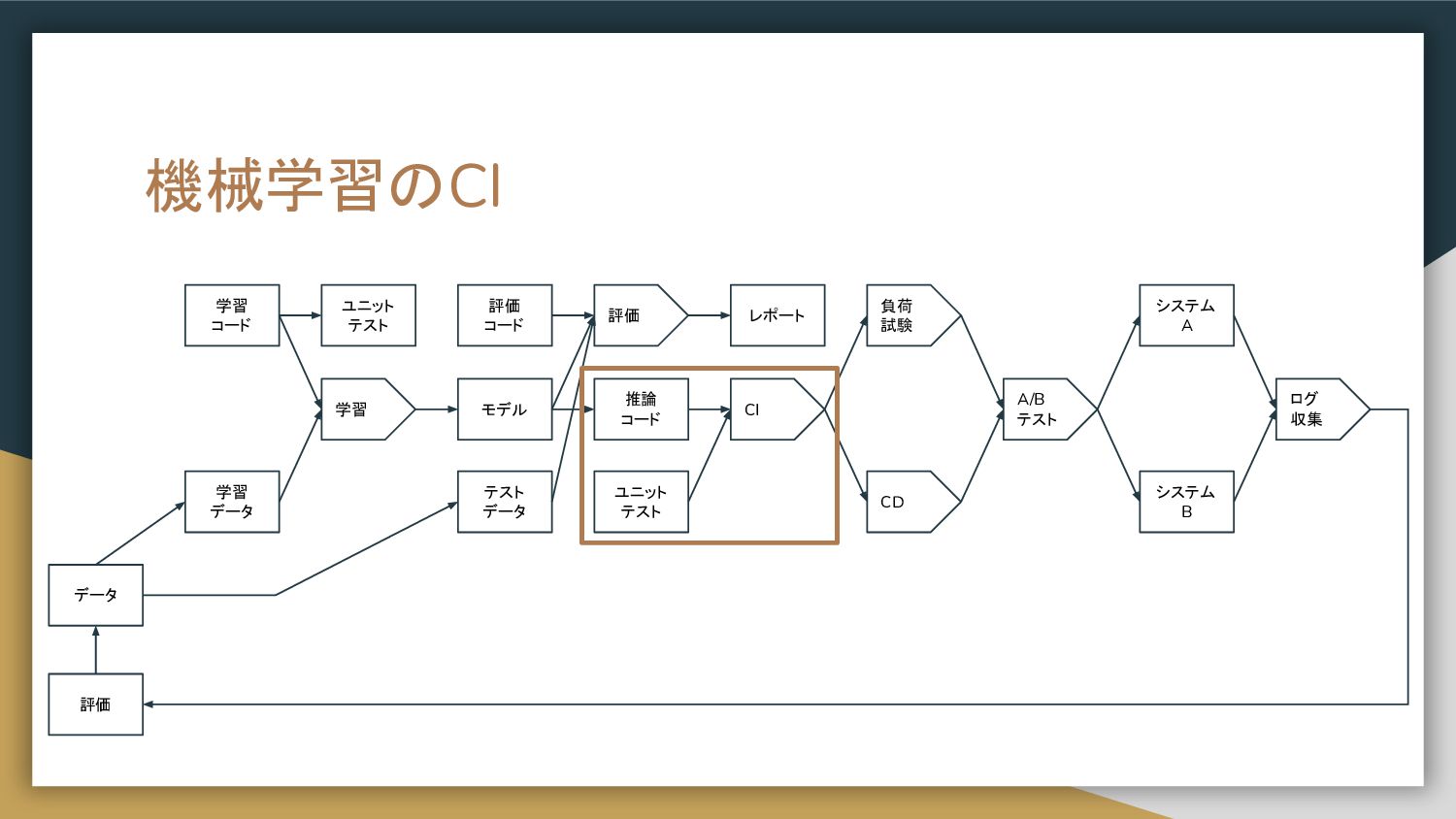
機械学習のCI 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
機械学習のCI • コードの正常性テスト、学習の妥当性テスト、インフラの堅牢性を分ける ◦ コードの正常性テスト ▪ Data Validation • 選択肢1.
汎用的にデータパイプラインで実行する • 選択肢2. 個別に学習のデータ取得時に実行する ▪ コードが正しく動く ◦ 学習の妥当性テスト ▪ 学習したモデルが実用化レベルの品質を持っている ▪ モデルをシステムに組み込むことができる ◦ インフラの堅牢性テスト ▪ 負荷テスト ▪ パフォーマンスに対するコスト評価 • 上記を連続して実行してテスト・評価ともに通過する
機械学習のCI Repo Code DVC CI データ取得 前処理 学習 評価 リリース
data validation data to be used test code data to be used model small data evaluating code serving infra model & test dataset model training code
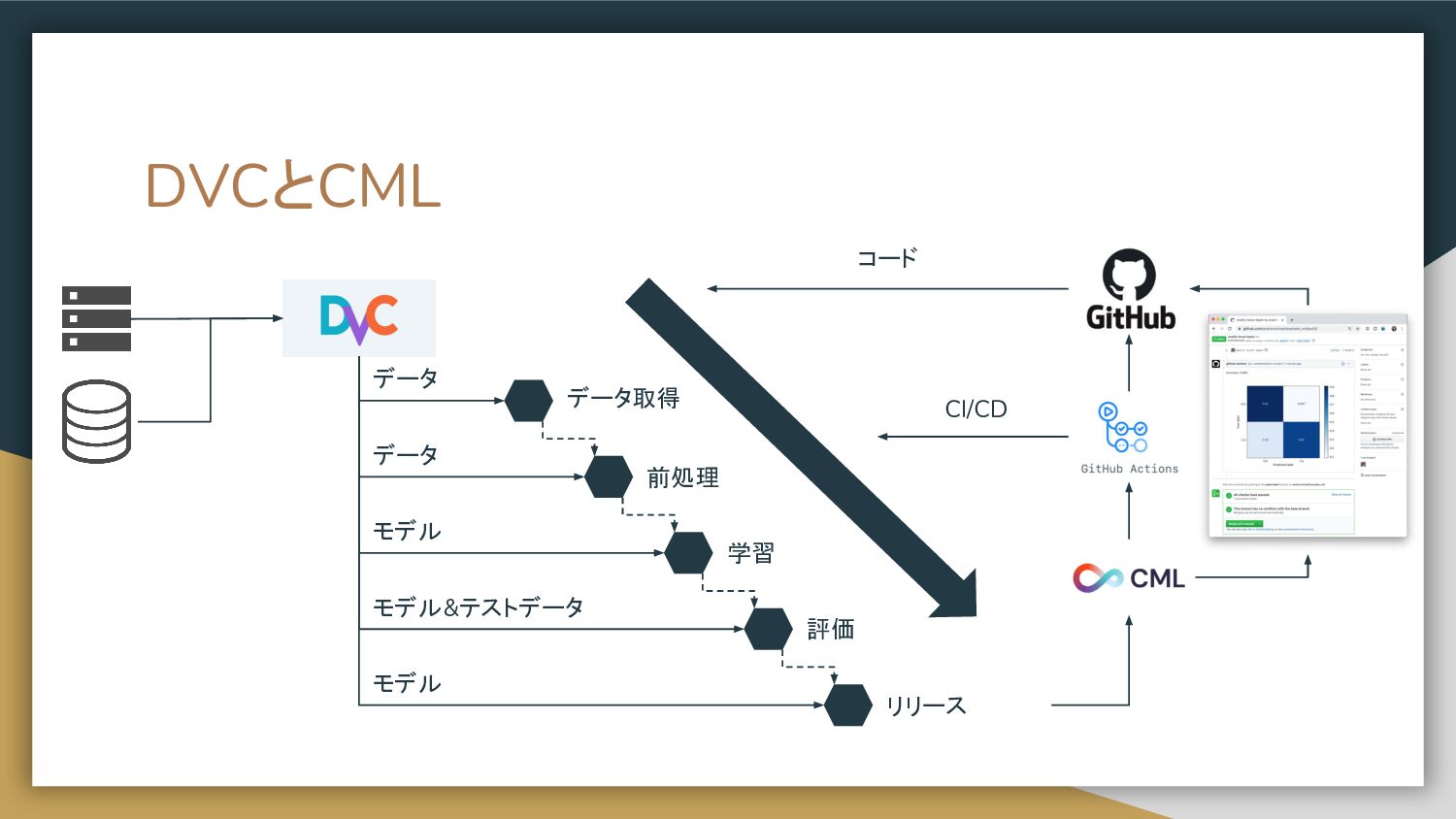
DVCとCML • Data Version Control • データ分析や機械学習で使ったデータを バージョン管理する • Gitみたいに使う
• https://dvc.org/doc • Continuous Machine Learning • GitHub ActionとDVCと組み合わせて データを管理したCI/CDが可能 • Git+CI+CML • https://github.com/iterative/cml
DVCとCML データ取得 前処理 学習 評価 リリース データ コード CI/CD データ
モデル モデル&テストデータ モデル
GitHub Actionsでワークフローを書く jobs: run: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2
- uses: iterative/setup-cml@v1 - name: ci env: REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }} run: | dvc pull pytest tests -s -v docker build test:${commit} . docker run test:${commit} \ python -m src.integrate -m model/model.onnx -o report.md cat report/report.md >> report.md cml-publish report/confusion_matrix.png --md >> report.md cml-send-comment report.md Remote DVC CML Git dvc pull pytest docker build docker run cml-publish cml-send- comment
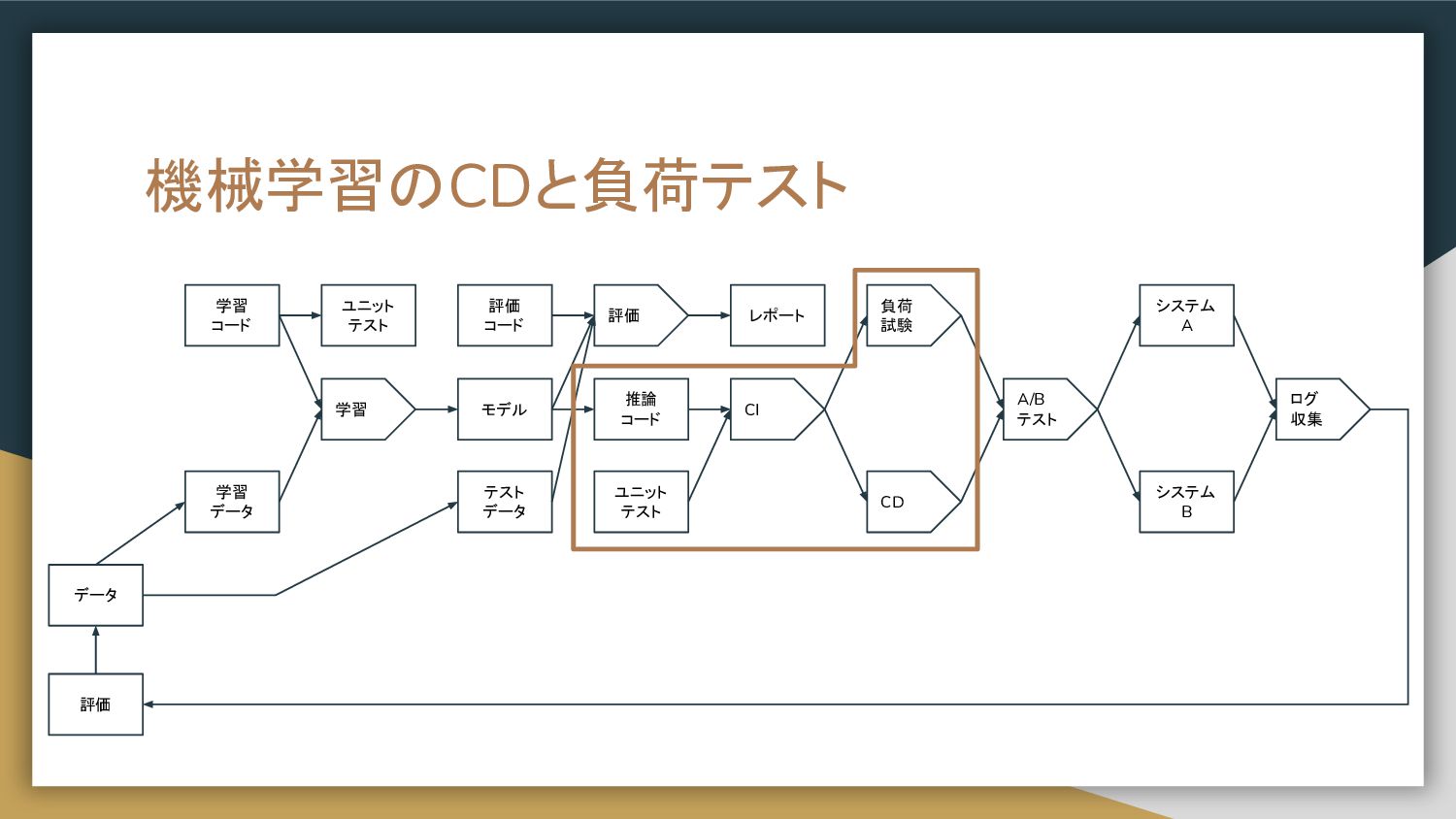
機械学習のCDと負荷テスト 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
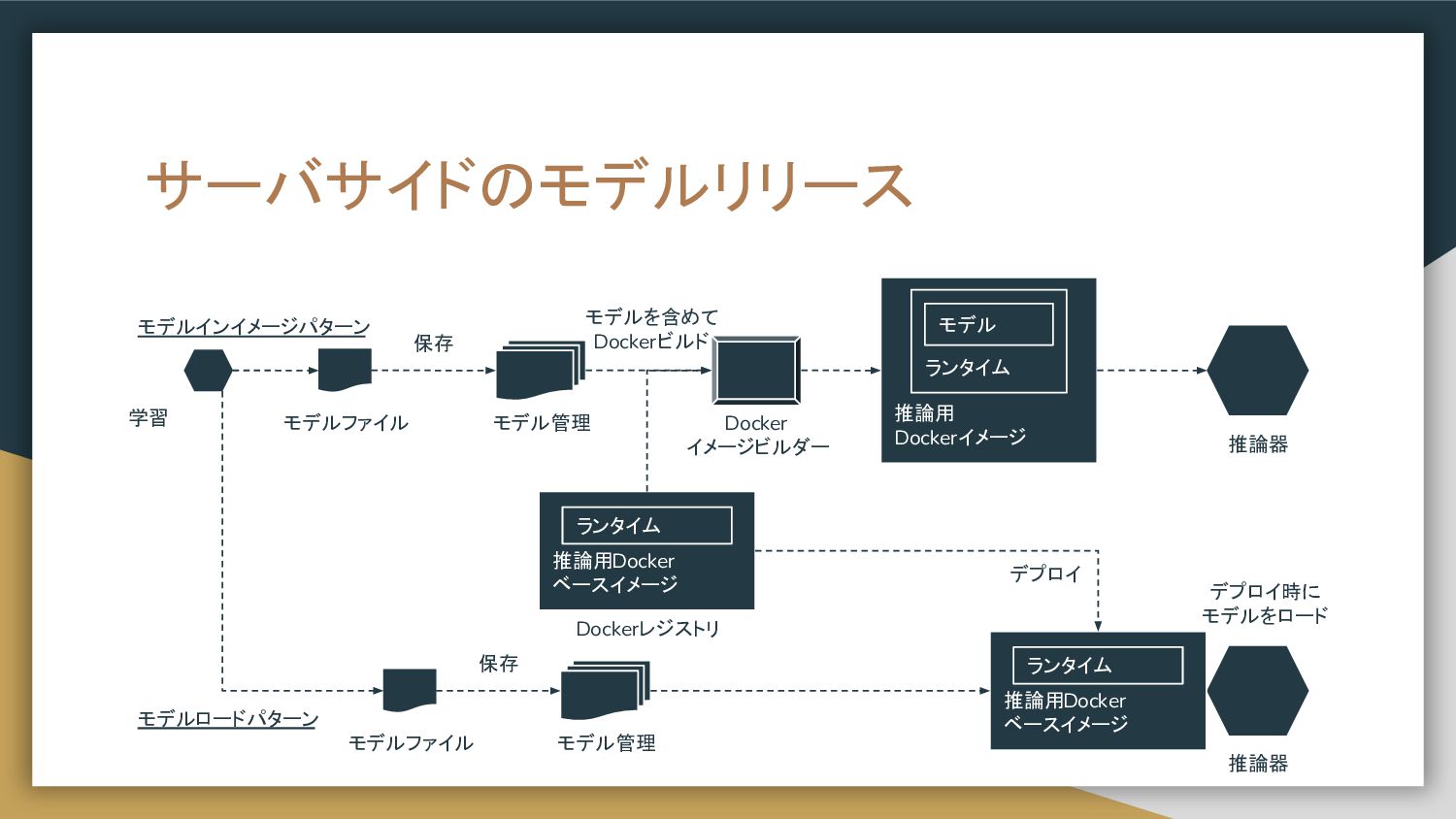
サーバサイドにモデルをリリースする • モデルインイメージパターン ◦ 推論器のイメージにモデルを含めてビルドするパターン。 Dockerイメージサイズは大きくなるため、 Docker pullに時間を要する。 ベースイメージを共通化することで pull時間を短縮することが可能。
• モデルロードパターン ◦ モデルファイルと推論器イメージを別に管理するパターン。 Dockerイメージを共通かつ軽量に保つことが可能。 学習時と推論イメージでソフトウェアのバージョン不一致が発生する可能性が残る。 学習環境と推論イメージでバージョニングする必要がある。
サーバサイドのモデルリリース 推論用 Dockerイメージ ランタイム モデル 学習 Docker イメージビルダー モデル管理 推論器
推論器 推論用Docker ベースイメージ ランタイム Dockerレジストリ 保存 モデルファイル モデルを含めて Dockerビルド モデルインイメージパターン モデル管理 保存 モデルファイル 推論用Docker ベースイメージ ランタイム デプロイ モデルロードパターン デプロイ時に モデルをロード
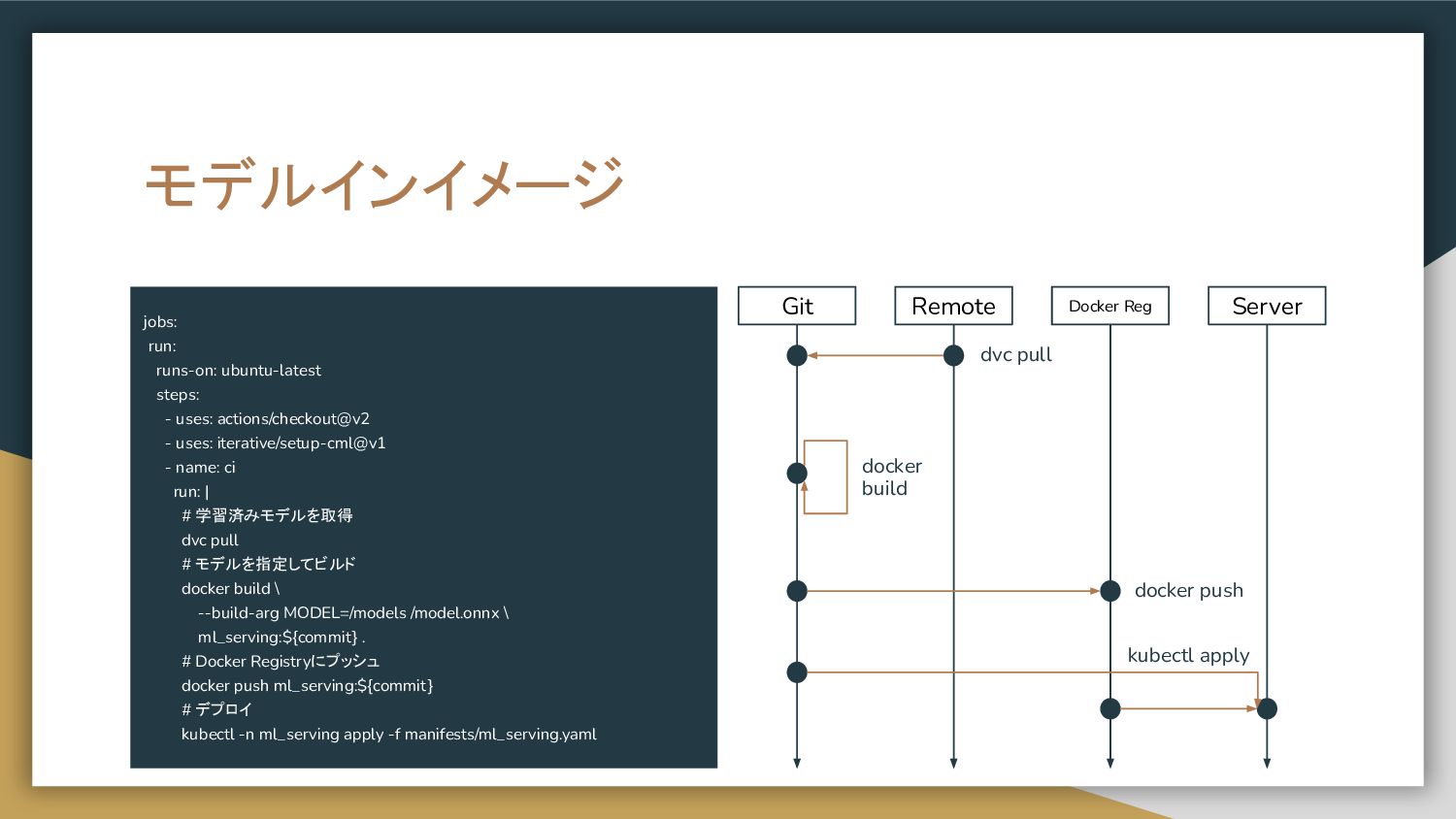
モデルインイメージ jobs: run: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 -
uses: iterative/setup-cml@v1 - name: ci run: | # 学習済みモデルを取得 dvc pull # モデルを指定してビルド docker build \ --build-arg MODEL=/models /model.onnx \ ml_serving:${commit} . # Docker Registryにプッシュ docker push ml_serving:${commit} # デプロイ kubectl -n ml_serving apply -f manifests/ml_serving.yaml Git Remote Docker Reg Server dvc pull docker build docker push kubectl apply
モデルロード jobs: run: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 -
uses: iterative/setup-cml@v1 - name: ci run: | # 推論サーバをビルド docker build ml_serving:${commit} . # Docker Registryにプッシュ docker push ml_serving:${commit} # デプロイ; init_containerでモデルを取得 kubectl -n ml_serving apply -f manifests/ml_serving.yaml Git Remote Docker Reg Server docker build docker push kubectl set env
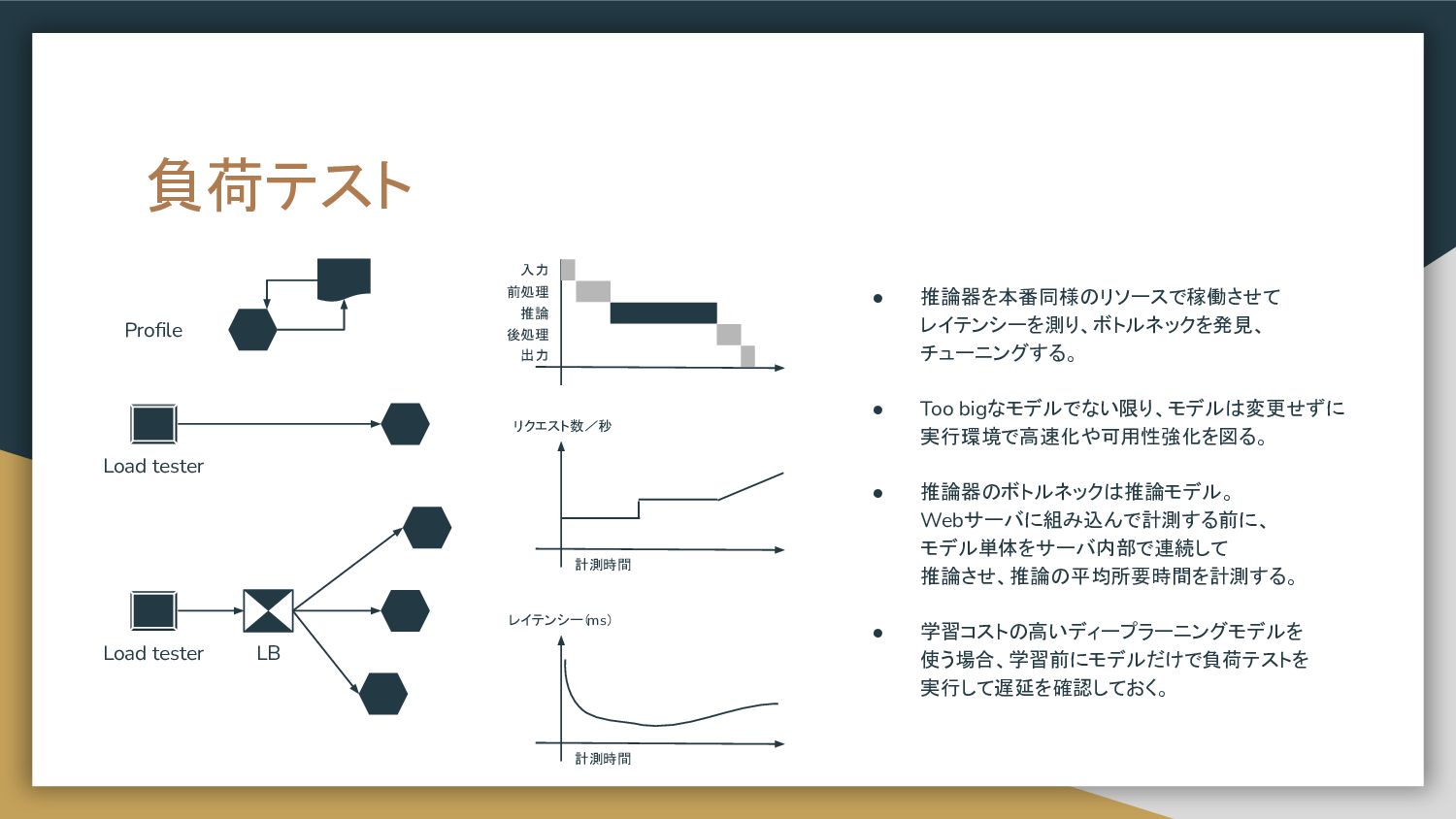
負荷テスト Load tester LB Load tester • 推論器を本番同様のリソースで稼働させて レイテンシーを測り、ボトルネックを発見、 チューニングする。
• Too bigなモデルでない限り、モデルは変更せずに 実行環境で高速化や可用性強化を図る。 • 推論器のボトルネックは推論モデル。 Webサーバに組み込んで計測する前に、 モデル単体をサーバ内部で連続して 推論させ、推論の平均所要時間を計測する。 • 学習コストの高いディープラーニングモデルを 使う場合、学習前にモデルだけで負荷テストを 実行して遅延を確認しておく。 Profile 入力 前処理 推論 後処理 出力 レイテンシー( ms) 計測時間 計測時間 リクエスト数/秒
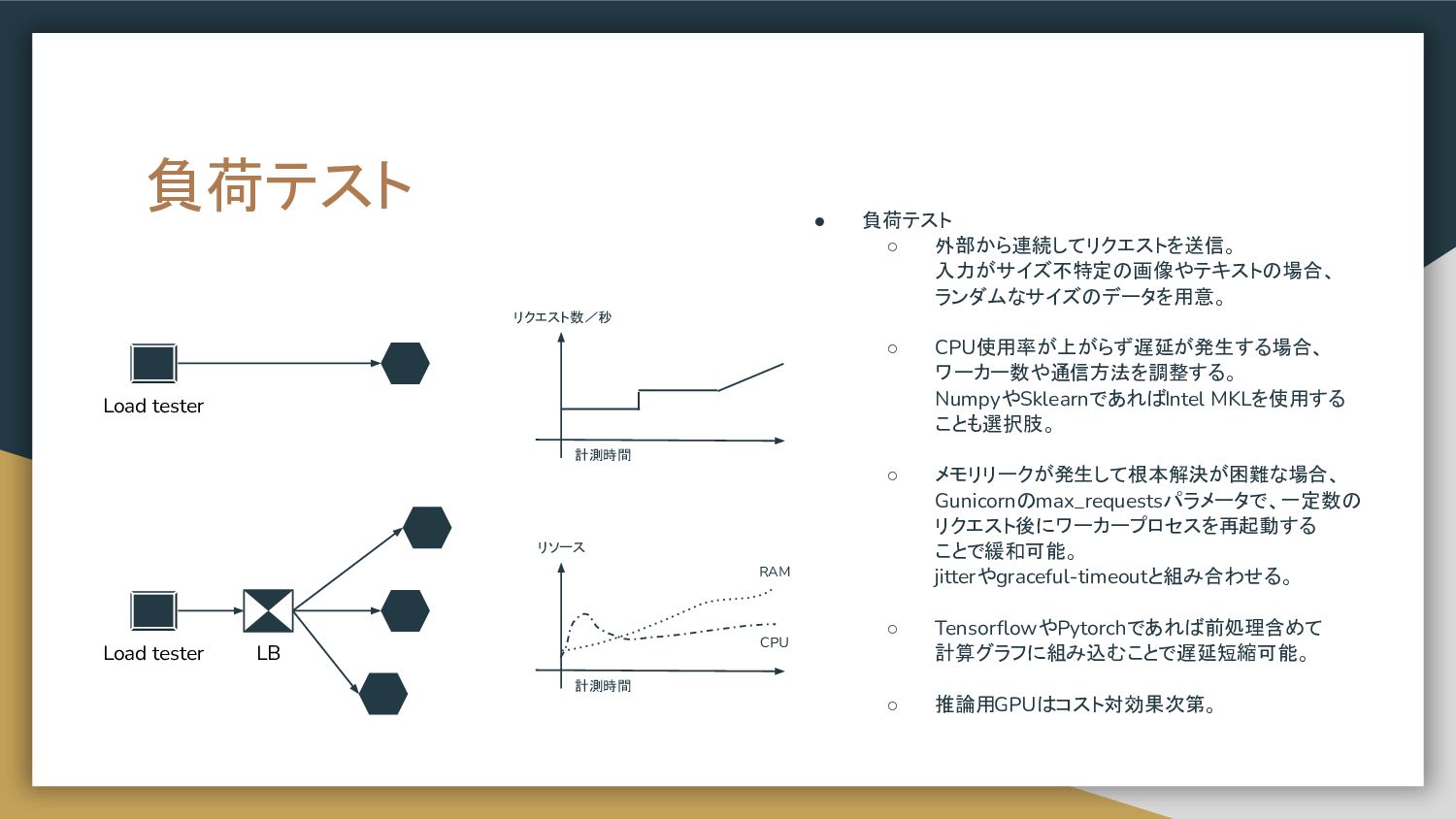
負荷テスト • 負荷テスト ◦ 外部から連続してリクエストを送信。 入力がサイズ不特定の画像やテキストの場合、 ランダムなサイズのデータを用意。 ◦ CPU使用率が上がらず遅延が発生する場合、 ワーカー数や通信方法を調整する。
NumpyやSklearnであればIntel MKLを使用する ことも選択肢。 ◦ メモリリークが発生して根本解決が困難な場合、 Gunicornのmax_requestsパラメータで、一定数の リクエスト後にワーカープロセスを再起動する ことで緩和可能。 jitterやgraceful-timeoutと組み合わせる。 ◦ TensorflowやPytorchであれば前処理含めて 計算グラフに組み込むことで遅延短縮可能。 ◦ 推論用GPUはコスト対効果次第。 Load tester LB Load tester 計測時間 リクエスト数/秒 計測時間 リソース RAM CPU
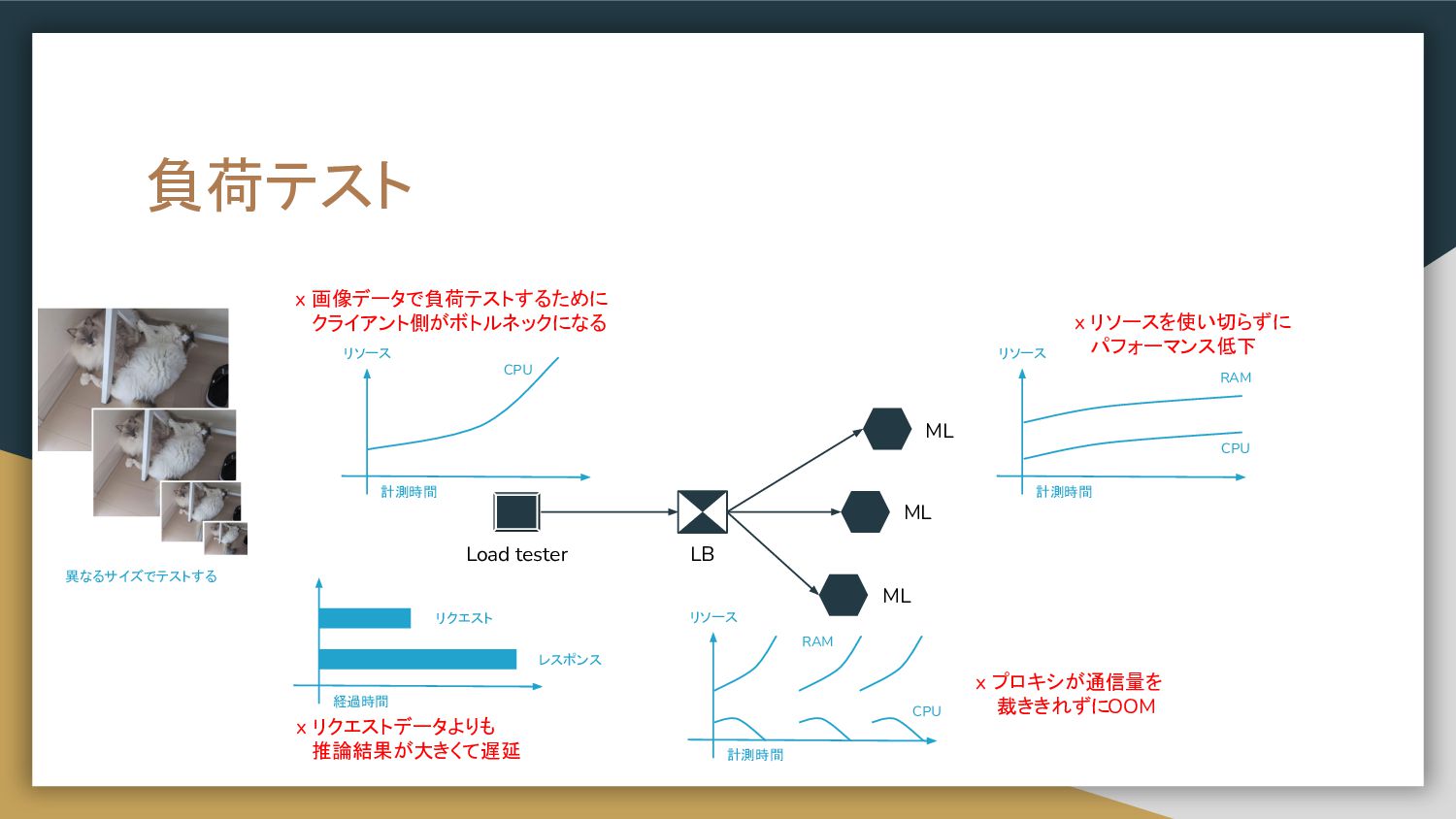
負荷テスト Load tester LB ML ML ML 計測時間 リソース RAM
CPU x 画像データで負荷テストするために クライアント側がボトルネックになる x リソースを使い切らずに パフォーマンス低下 計測時間 リソース RAM CPU x プロキシが通信量を 裁ききれずにOOM 経過時間 リクエスト レスポンス x リクエストデータよりも 推論結果が大きくて遅延 リソース CPU 計測時間 異なるサイズでテストする
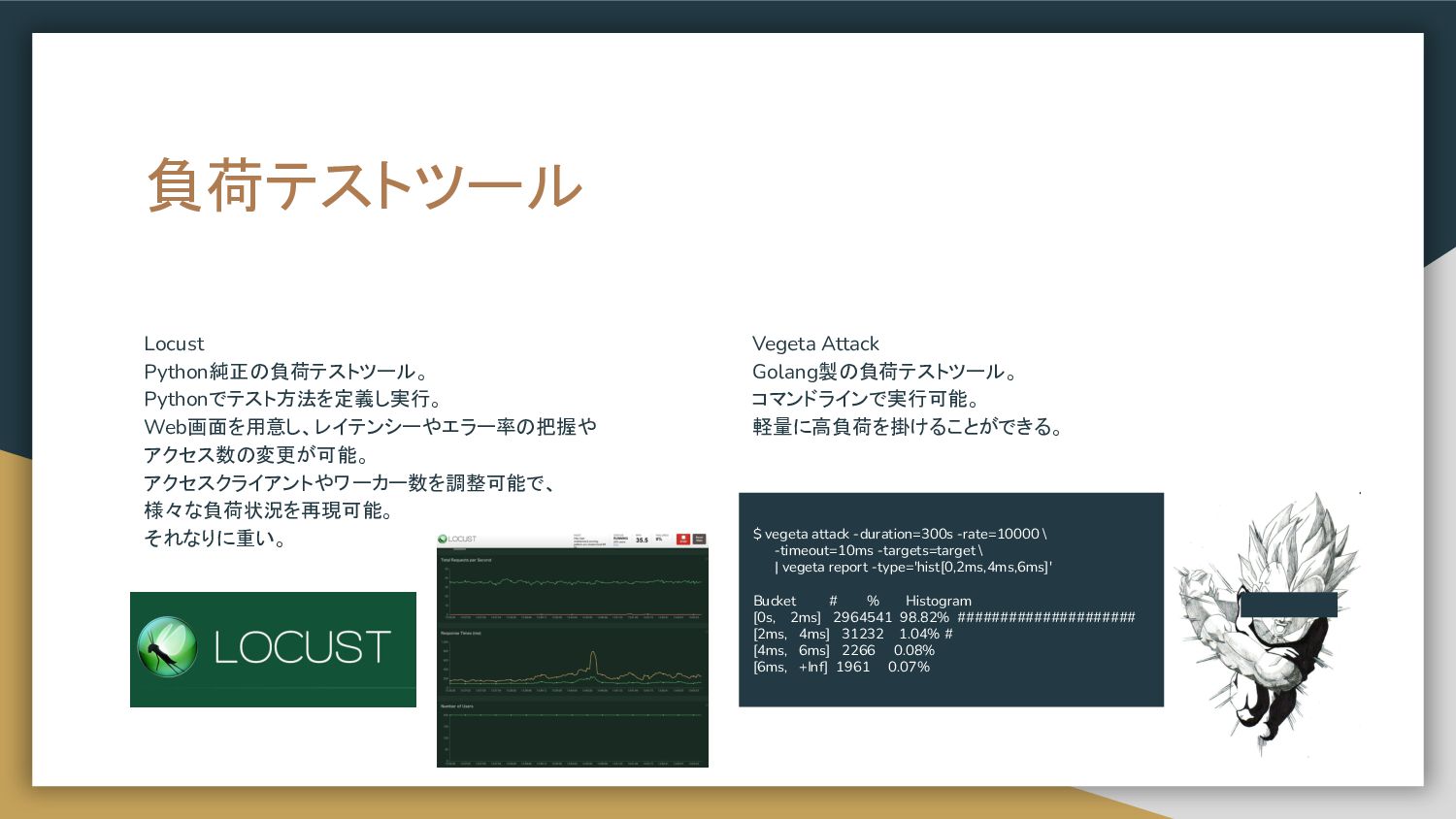
負荷テストツール Locust Python純正の負荷テストツール。 Pythonでテスト方法を定義し実行。 Web画面を用意し、レイテンシーやエラー率の把握や アクセス数の変更が可能。 アクセスクライアントやワーカー数を調整可能で、 様々な負荷状況を再現可能。 それなりに重い。 Vegeta
Attack Golang製の負荷テストツール。 コマンドラインで実行可能。 軽量に高負荷を掛けることができる。 $ vegeta attack -duration=300s -rate=10000 \ -timeout=10ms -targets=target \ | vegeta report -type='hist[0,2ms,4ms,6ms]' Bucket # % Histogram [0s, 2ms] 2964541 98.82% ##################### [2ms, 4ms] 31232 1.04% # [4ms, 6ms] 2266 0.08% [6ms, +Inf] 1961 0.07%
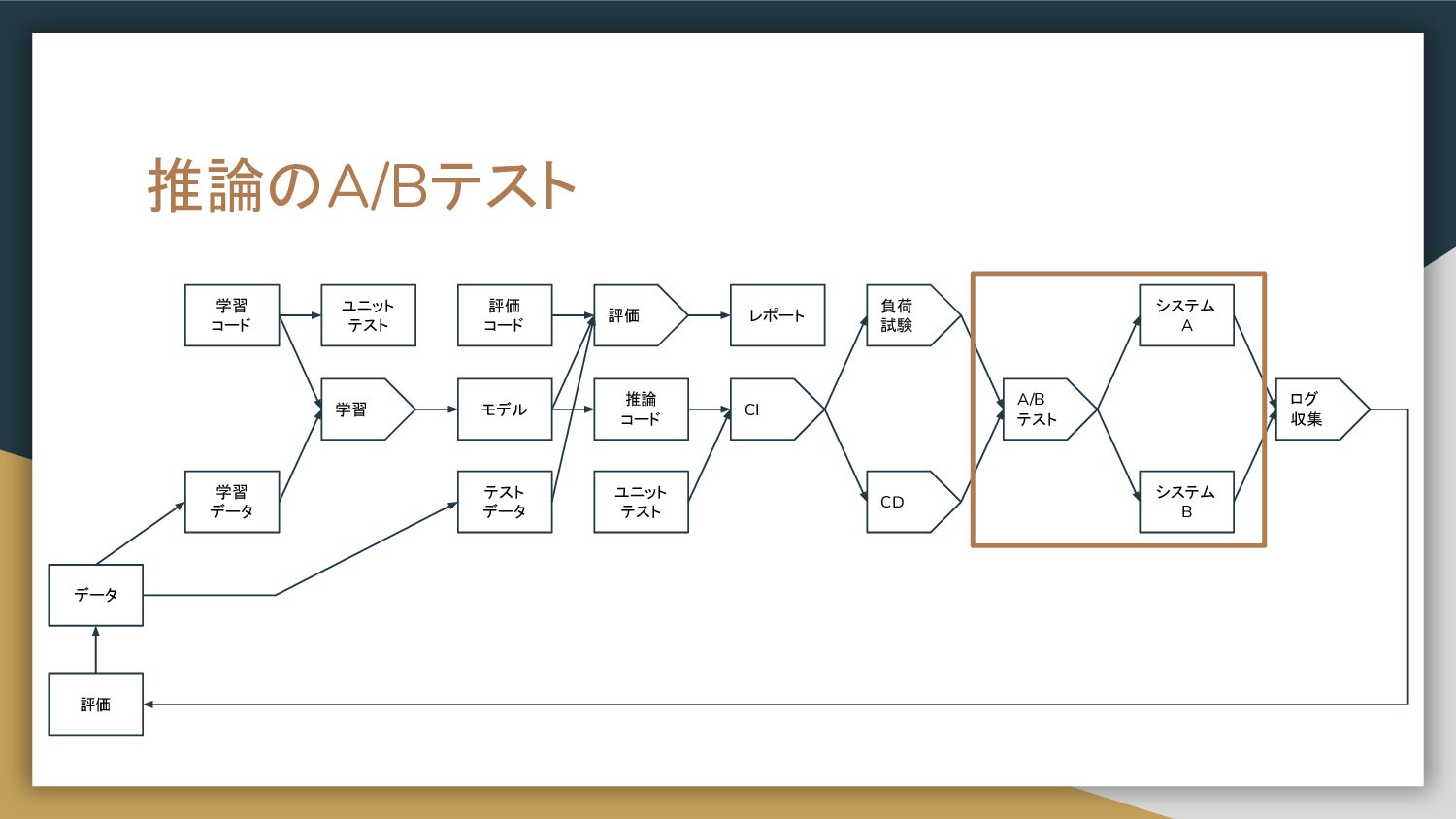
推論のA/Bテスト 学習 コード 学習 データ 学習 評価 モデル レポート 推論
コード CI テスト データ 評価 コード CD システム A A/B テスト システム B 負荷 試験 ログ 収集 評価 データ ユニット テスト ユニット テスト
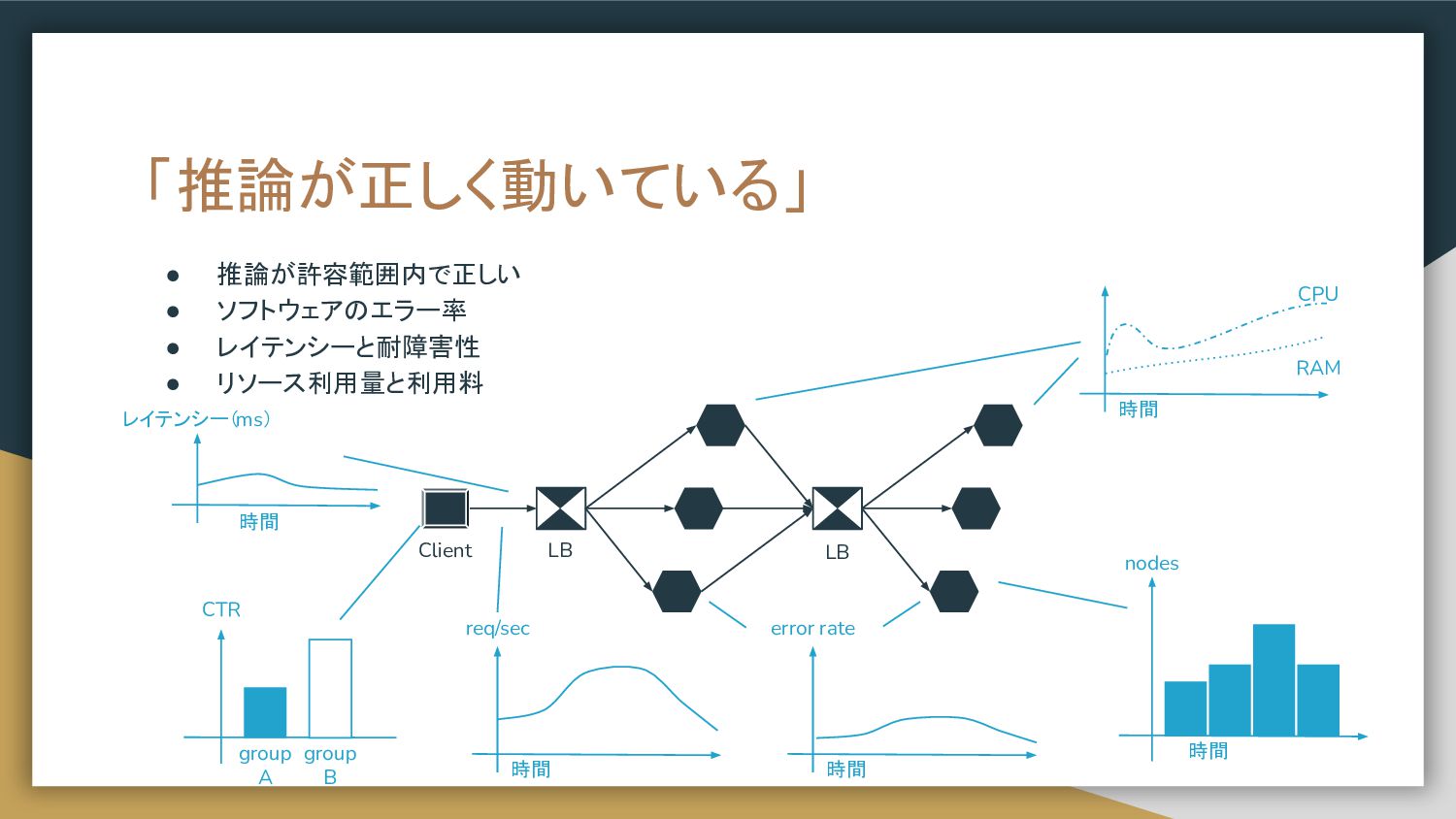
• 推論が許容範囲内で正しい • ソフトウェアのエラー率 • レイテンシーと耐障害性 • リソース利用量と利用料 「推論が正しく動いている」 Client
LB LB 時間 RAM CPU group A CTR group B 時間 req/sec 時間 nodes 時間 error rate レイテンシー(ms) 時間
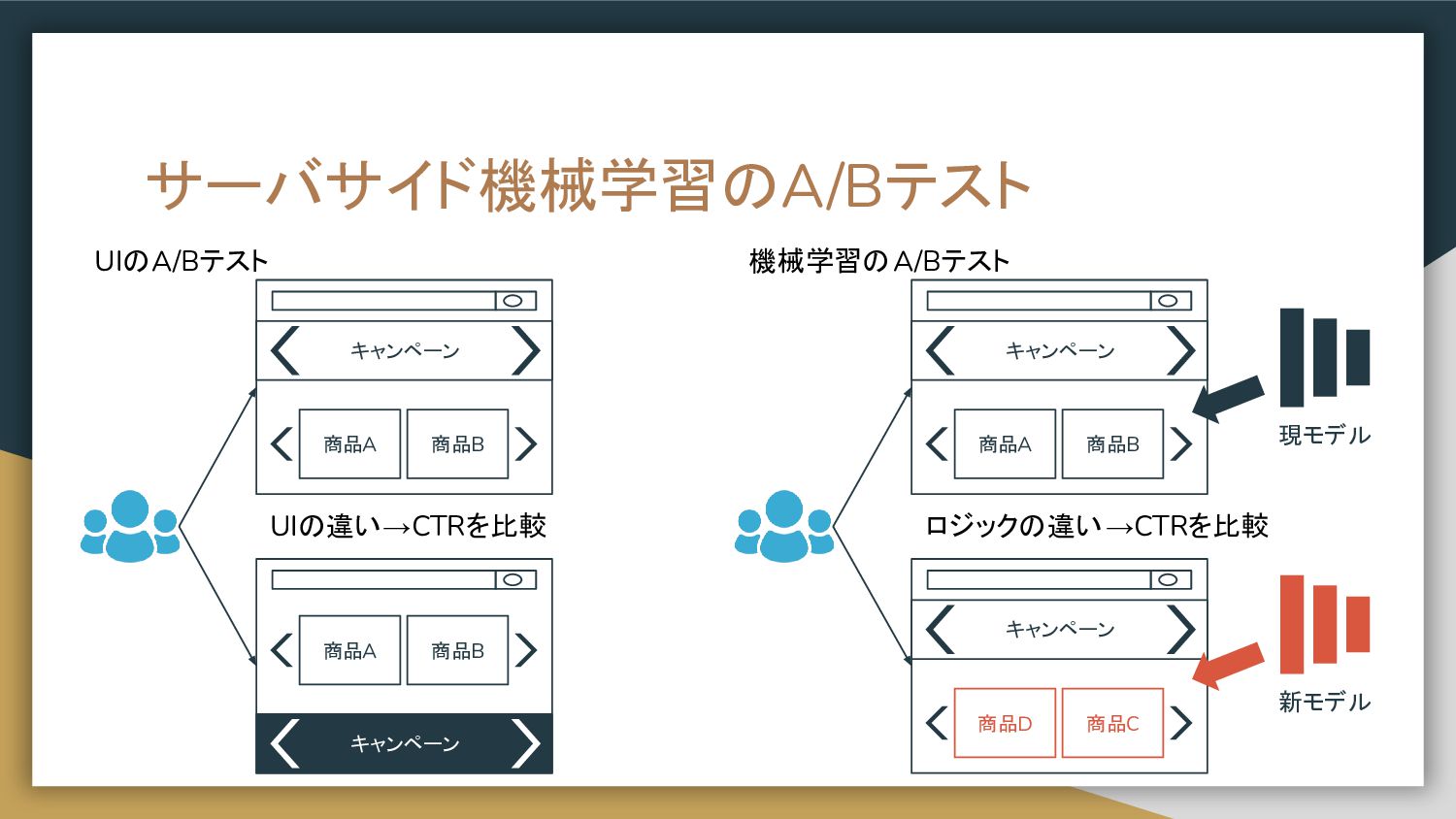
サーバサイド機械学習のA/Bテスト 商品A キャンペーン 商品B 商品A キャンペーン 商品B 商品A キャンペーン 商品B
商品D キャンペーン 商品C 新モデル 現モデル UIのA/Bテスト 機械学習のA/Bテスト UIの違い→CTRを比較 ロジックの違い→CTRを比較
• 手法1 推論するデータを分ける O コスト O 全ユーザから新モデルの評価を得る X 同じデータの比較ができない • 手法2 アクセスするユーザを分ける O 同じデータで比較できる
O 新モデルへの移行が比較的簡単 X コスト A/Bテストを作る 新モデル 現モデル 新モデル 現モデル
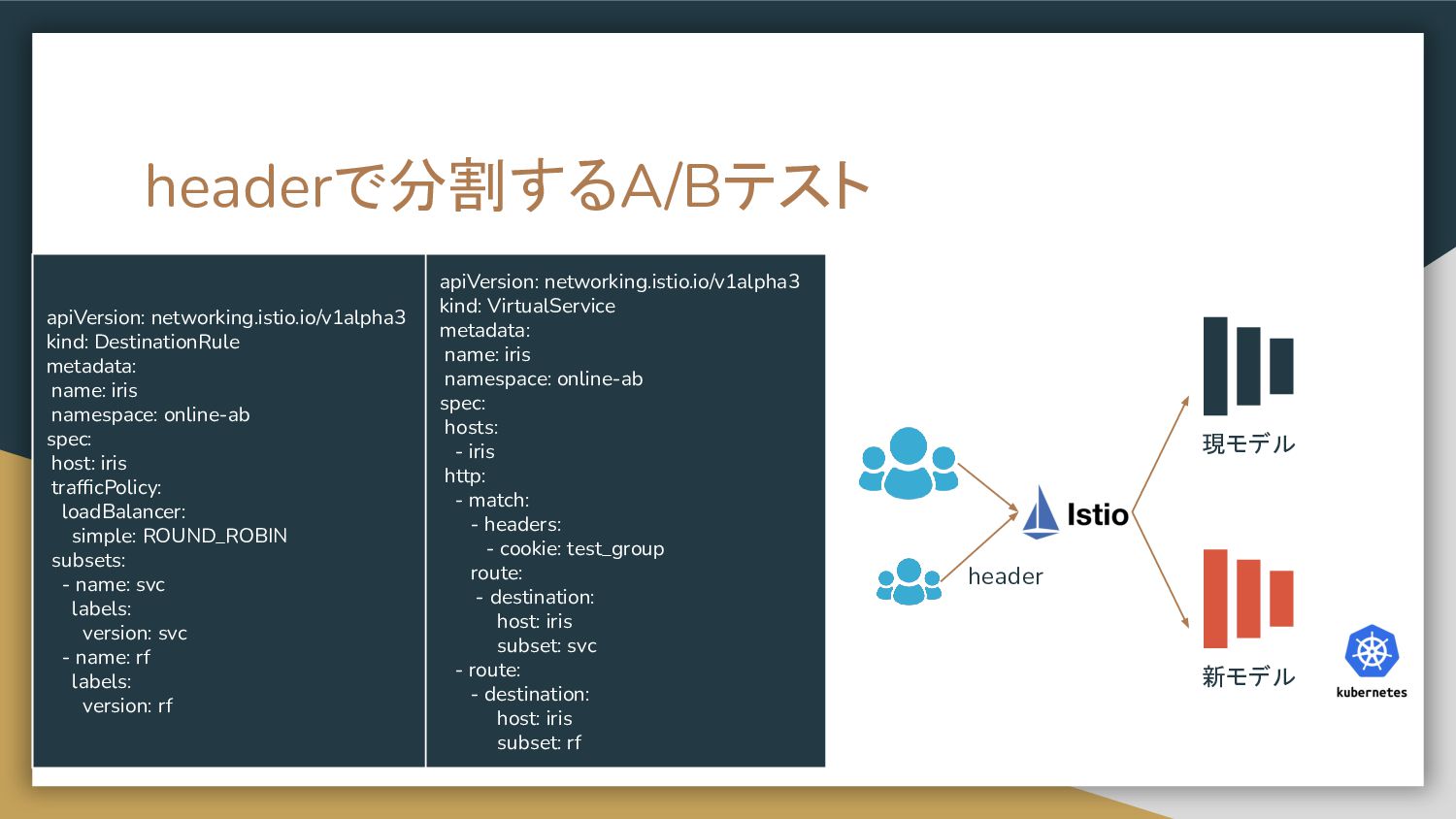
IstioによるランダムA/Bテスト 新モデル 現モデル apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: iris
namespace: online-ab spec: host: iris trafficPolicy: loadBalancer: simple: ROUND_ROBIN subsets: - name: svc labels: version: svc - name: rf labels: version: rf apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: iris namespace: online-ab spec: hosts: - iris http: - route: - destination: host: iris subset: svc weight: 60 - destination: host: iris subset: rf weight: 40
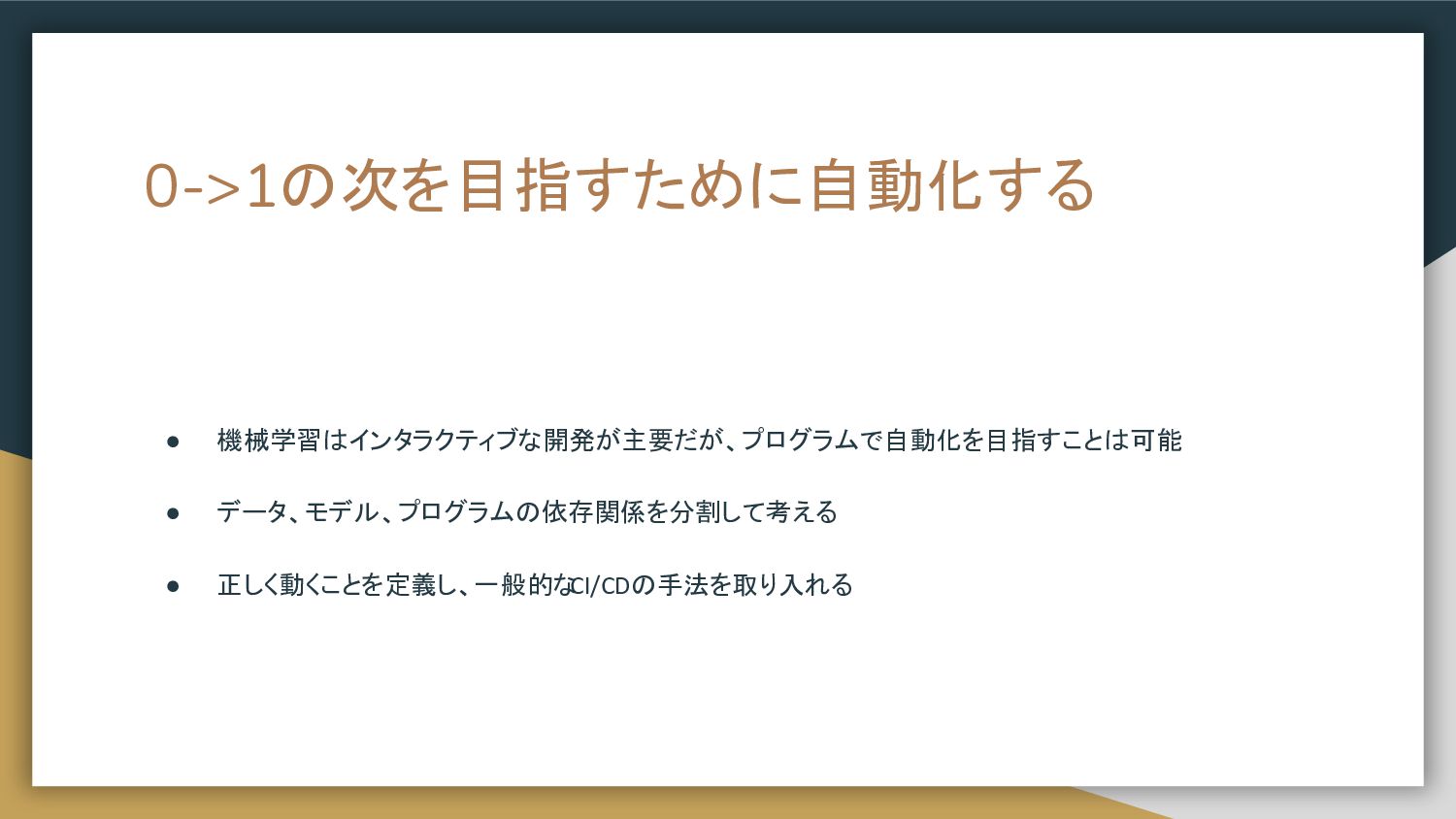
headerで分割するA/Bテスト 新モデル 現モデル apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: iris
namespace: online-ab spec: host: iris trafficPolicy: loadBalancer: simple: ROUND_ROBIN subsets: - name: svc labels: version: svc - name: rf labels: version: rf apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: iris namespace: online-ab spec: hosts: - iris http: - match: - headers: - cookie: test_group route: - destination: host: iris subset: svc - route: - destination: host: iris subset: rf header
まとめ
0->1の次を目指すために自動化する • 機械学習はインタラクティブな開発が主要だが、プログラムで自動化を目指すことは可能 • データ、モデル、プログラムの依存関係を分割して考える • 正しく動くことを定義し、一般的な CI/CDの手法を取り入れる
本を出版しました! • AIエンジニアのための 機械学習システムデザインパターン • 2021年5月17日発売 • https://www.amazon.co.jp/dp/4798169447/ • 機械学習と銘打ってるのに
KubernetesとIstioに 詳しくなれる一冊です! • Amazon.co.jp 情報学・情報科学部門 1位! 人工知能部門 1位! • 増刷決定! • 韓国語版と中国語版(台湾)も出るらしい!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}