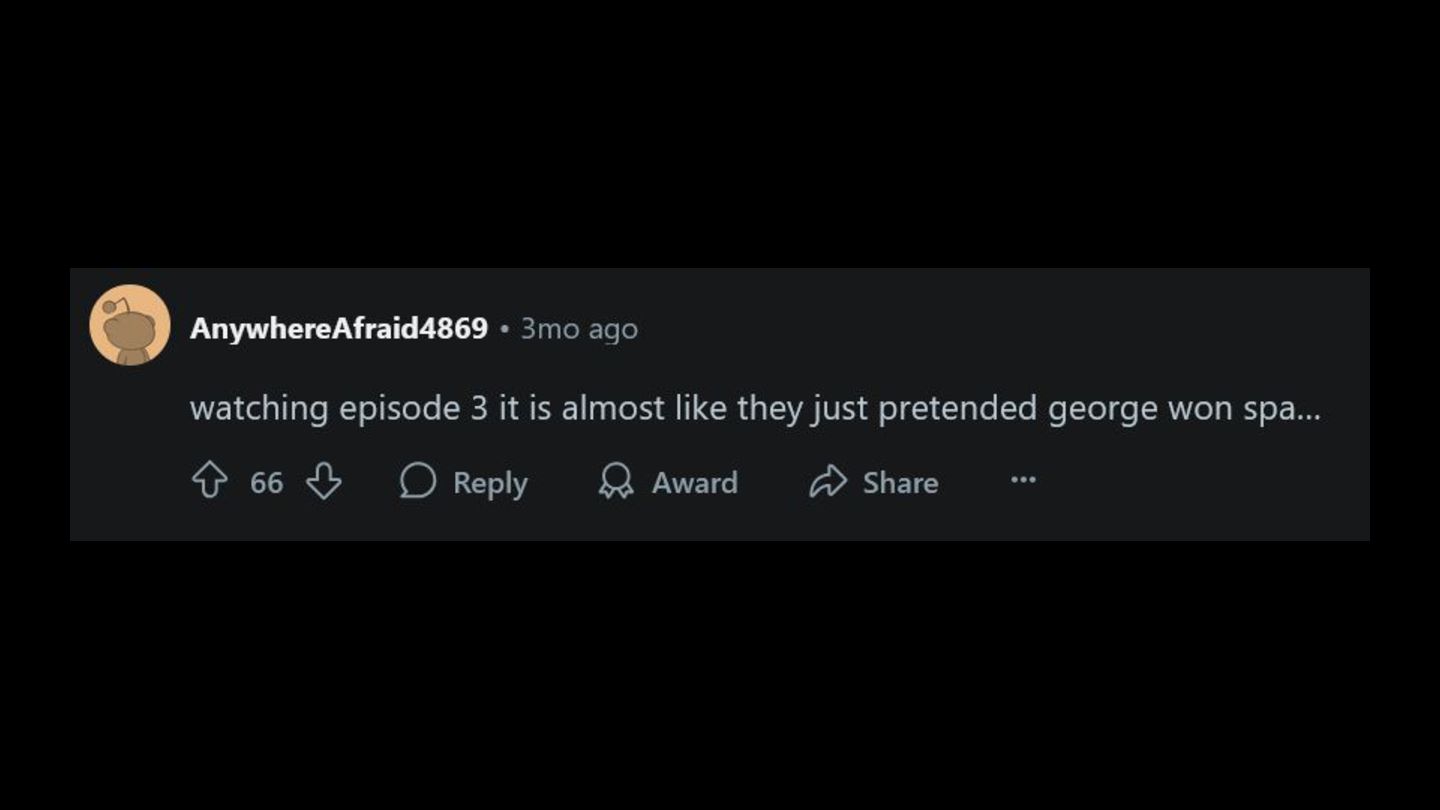
Russell "stepping up" into a leadership role at Mercedes … narrating the Spa 2024 Grand Prix … … showing Russell on the podium … … and never even mentioning his disqualification.
is linked to a certain concept Textual mention F1 race driver 18th century military officer Duke of Hamilton "Hamilton" 75% 7% 10% "Lewis Hamilton" 99% 0% 0% "Alexander Hamilton" 0% 97% 1%
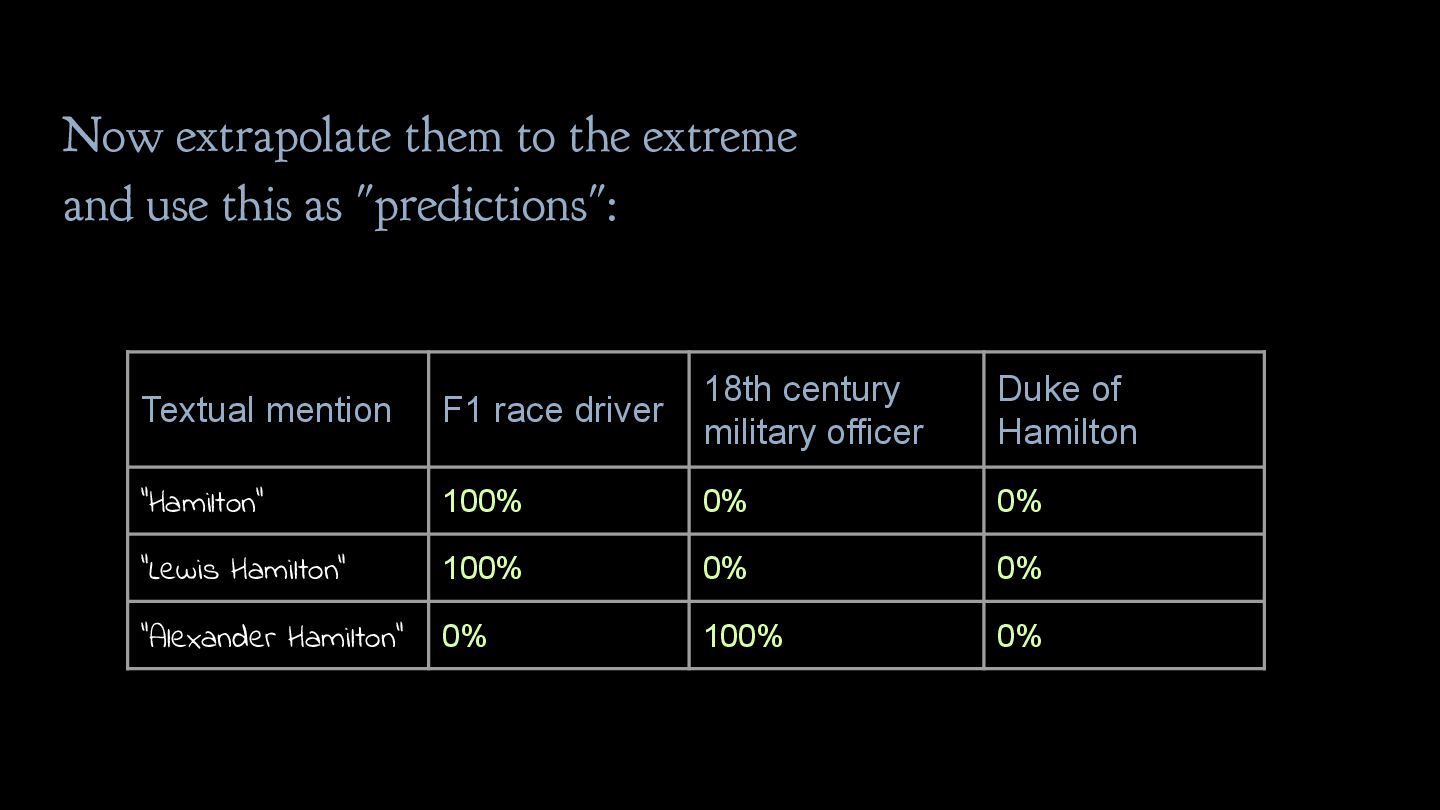
"predictions": Textual mention F1 race driver 18th century military officer Duke of Hamilton "Hamilton" 100% 0% 0% "Lewis Hamilton" 100% 0% 0% "Alexander Hamilton" 0% 100% 0%
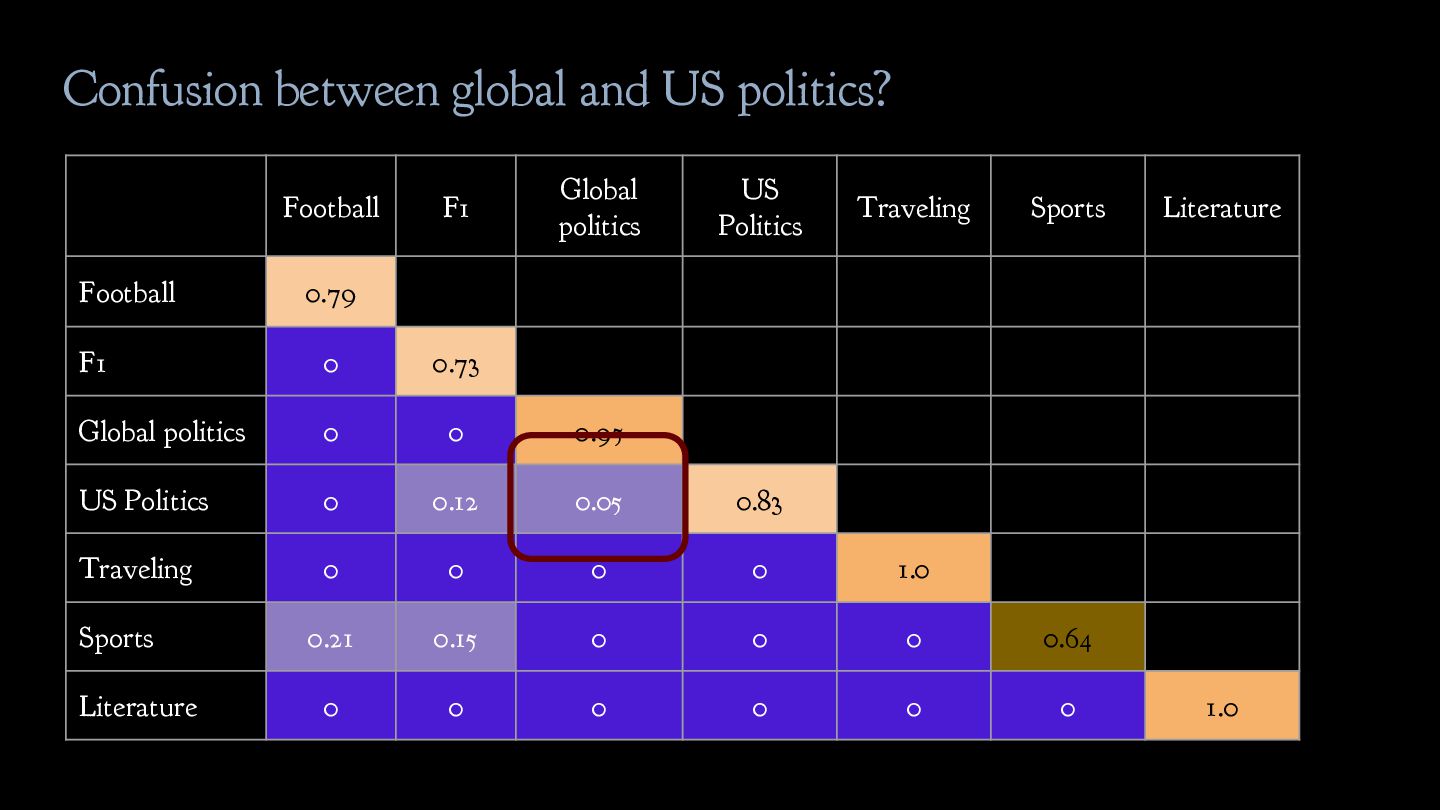
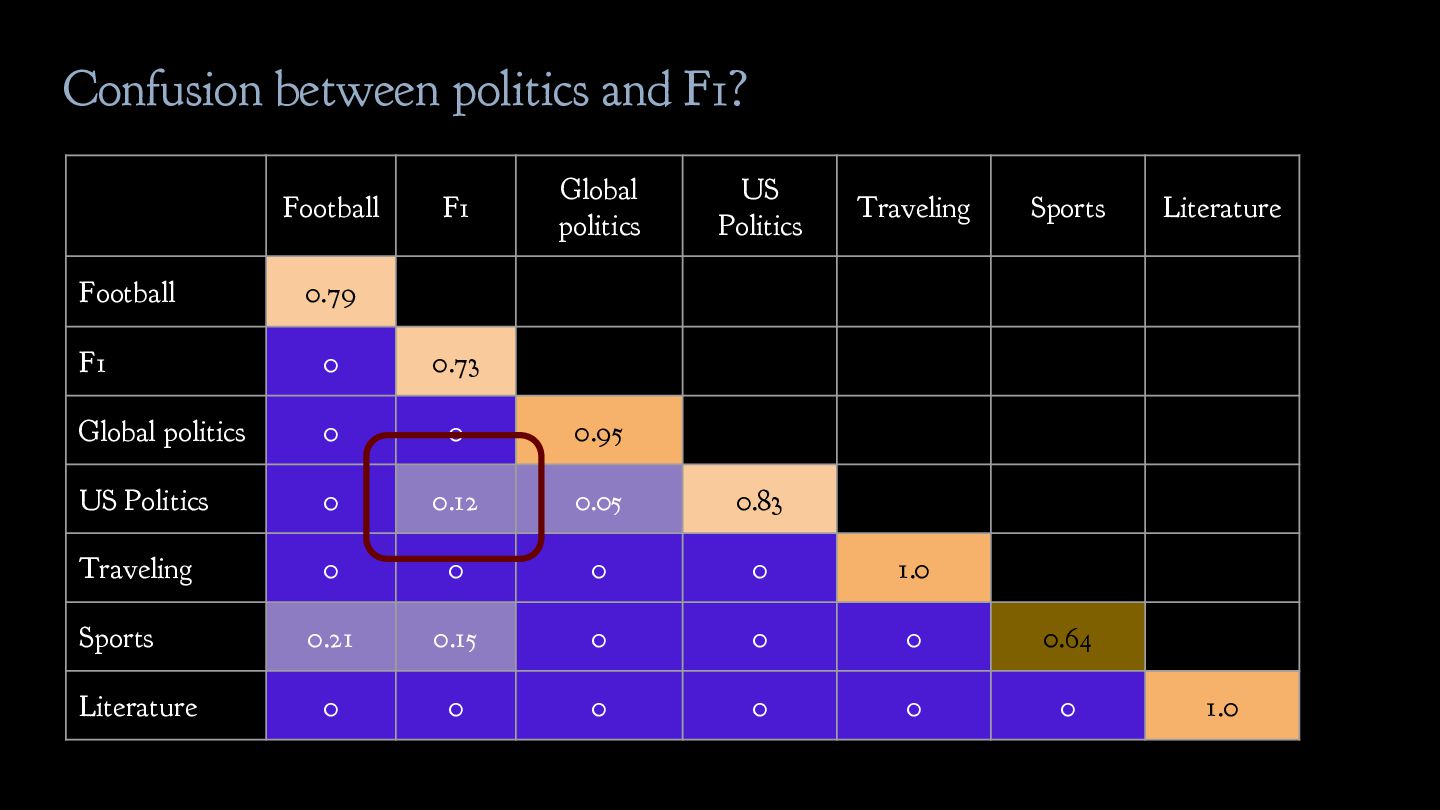
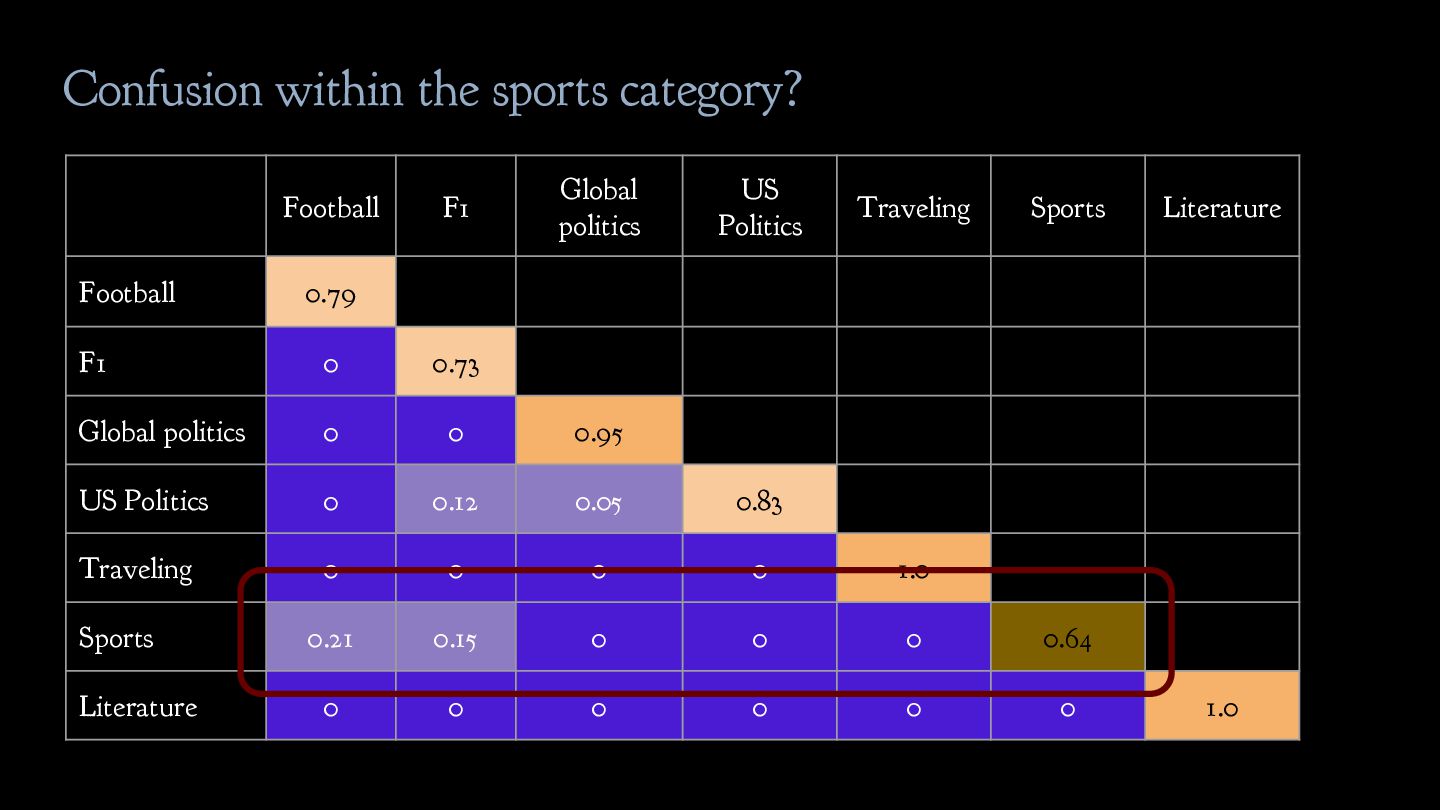
politics b. US politics 3. Leisure a. Traveling b. Sports c. Literature Solution: critically revise the label scheme given to you! Inherent ambiguity in the label scheme needs to be addressed
entity annotation: ❌ Gasly laments ‘quite sad’ [Monaco] GP crash ✅ Gasly laments ‘quite sad’ [Monaco GP] crash Write up annotation guidelines to help with consistency of annotations
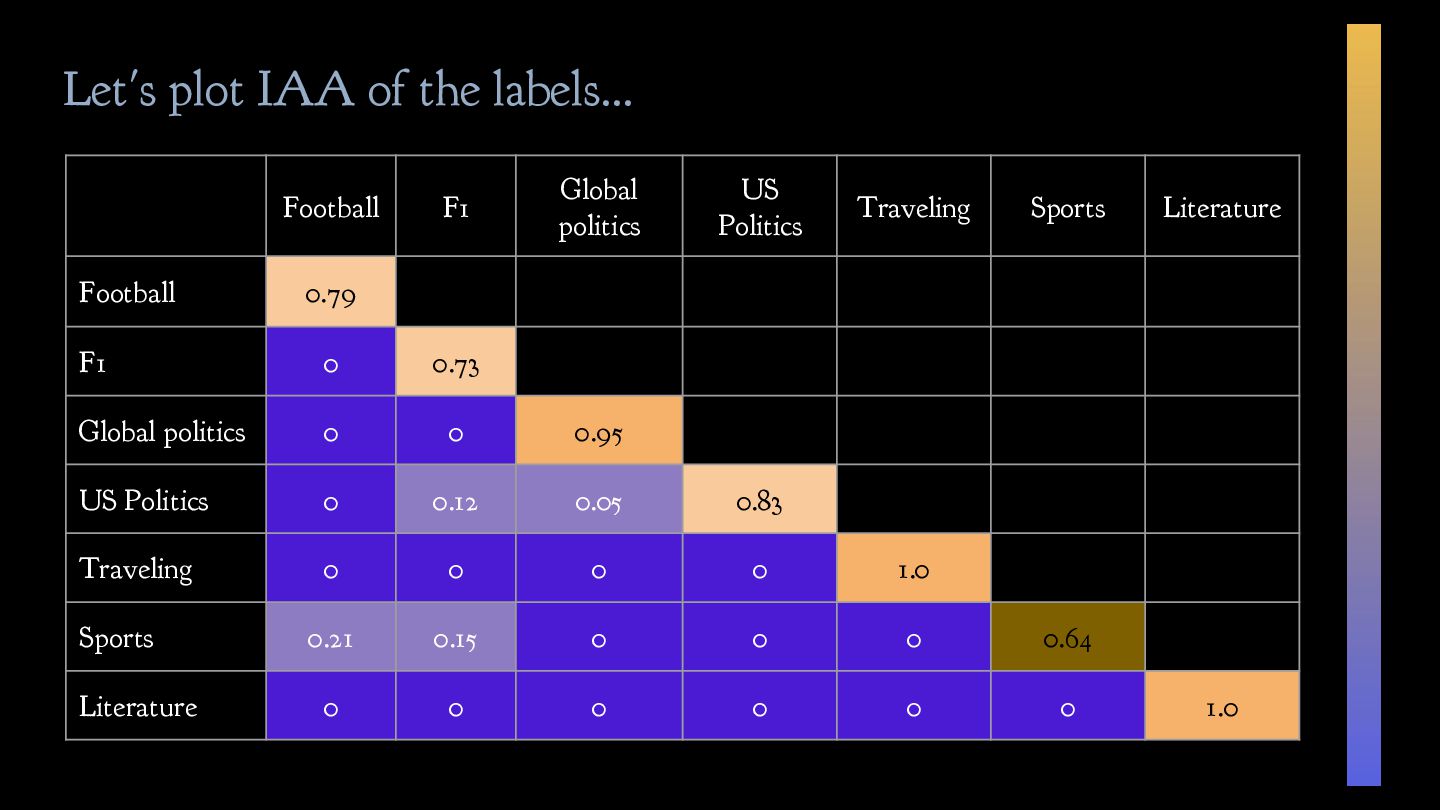
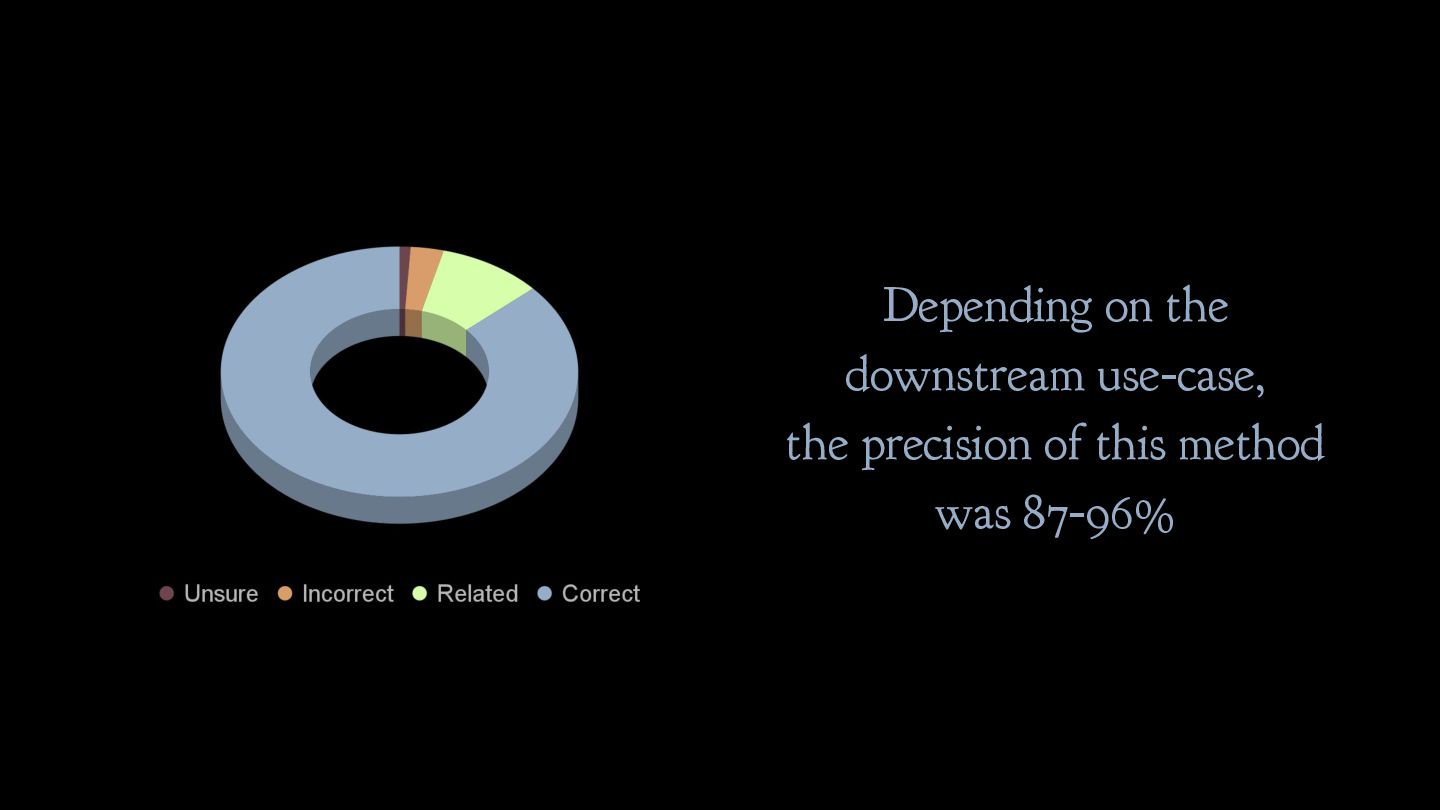
consistent and unambiguous ✓ Draft clear annotation guidelines to ensure data consistency ✓ Measure inter-annotator agreement (IAA) ✓ Consider reframing your task/guidelines if the IAA is low ✓ Model uncertainty in your annotation workflow 📝 1/3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}