SECR 2018
Борис Штейнберг
заведующий кафедрой, ЮФУ
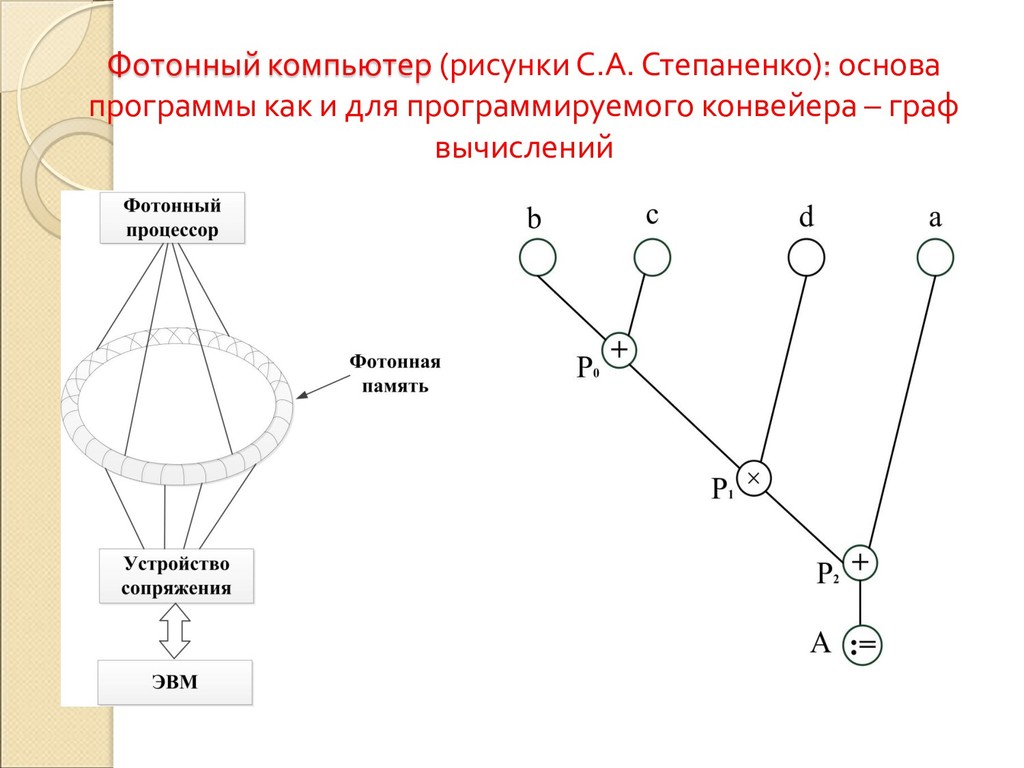
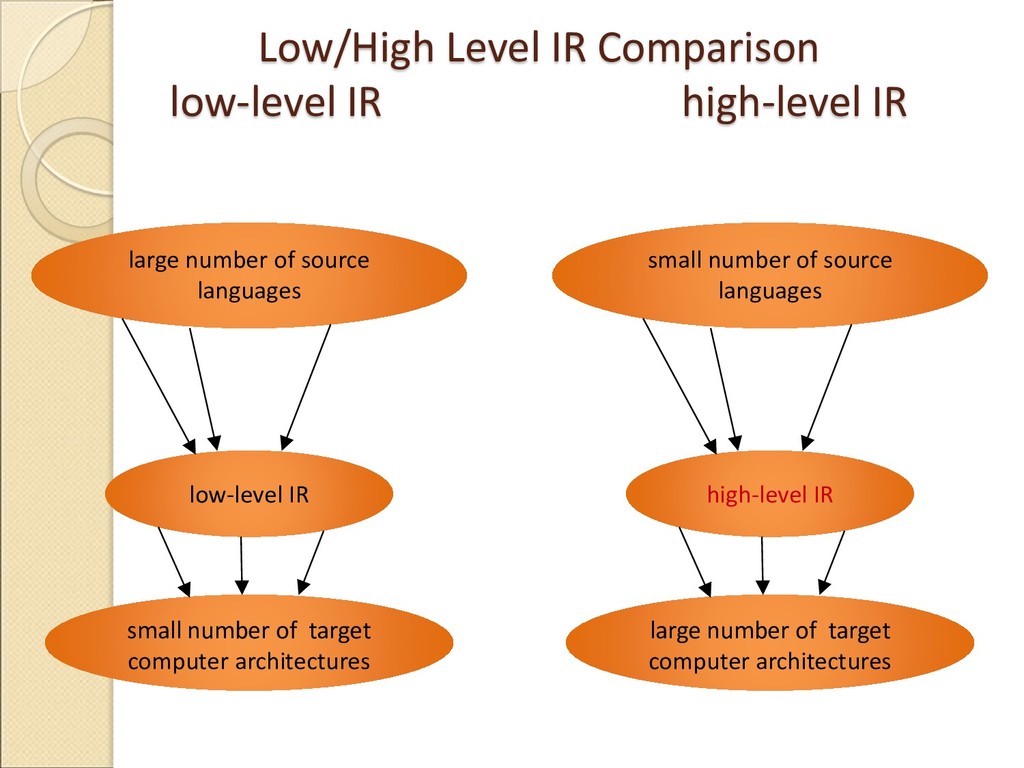
Данная статья относится к области высокоуровневого синтеза. Работа посвящена предварительным преобразованиям программ языка Си, до их автоматического преобразования компилятором в HDL-описание соответствующей электронной схемы. Рассматриваемые преобразования направлены на поиск такой конвейерной схемы, которая способна вычислять несколько различных программных циклов. Создание такого конвейерного вычислителя может привести к экономии ресурсов ПЛИС при генерации схемы и может сэкономить время, необходимое для перепрограммирования ПЛИС-ускорителя. Реализация таких преобразований предполагается на основе ОРС (оптимизирующей распараллеливающей системы). Задача поиска оптимального конвейера оказывается вычислительно сложной, но, в некоторых частных случаях, сводится к известной задаче выравнивания строк.
{kind=link}
{kind=link}
{kind=link}
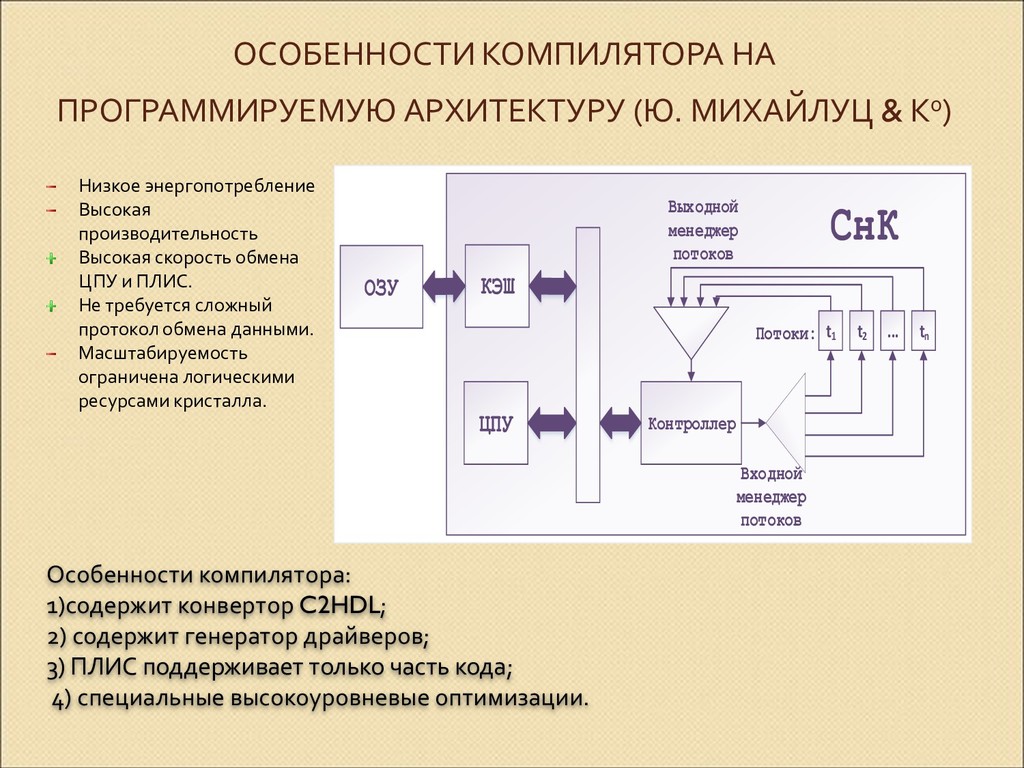{kind=link}
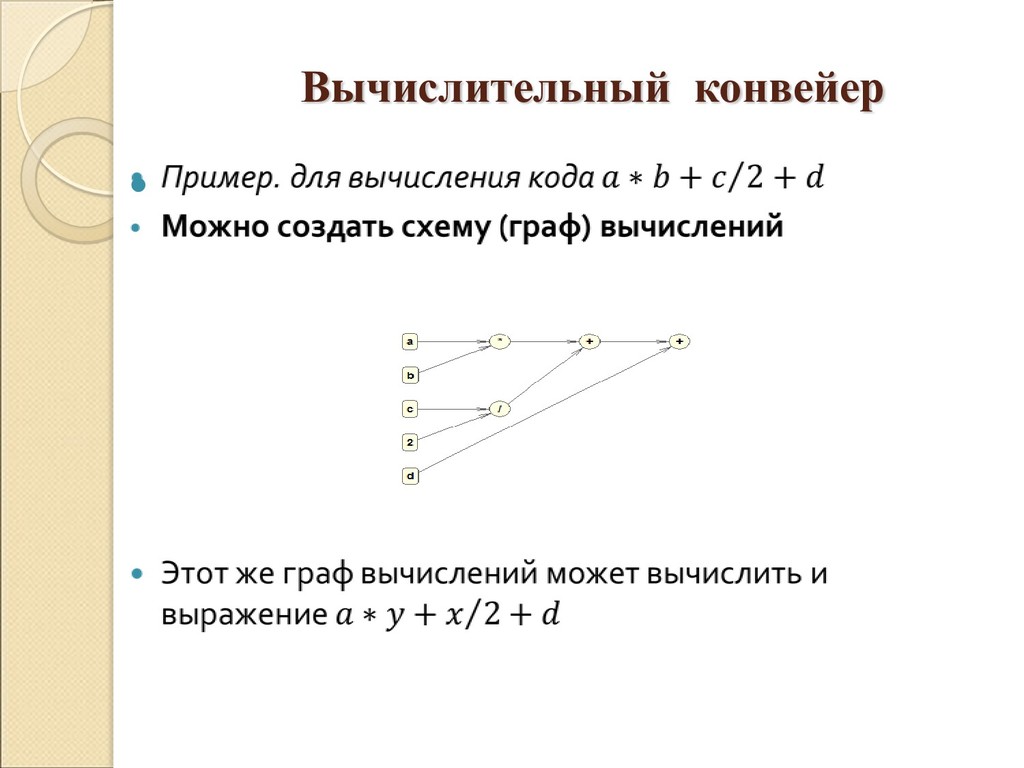{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
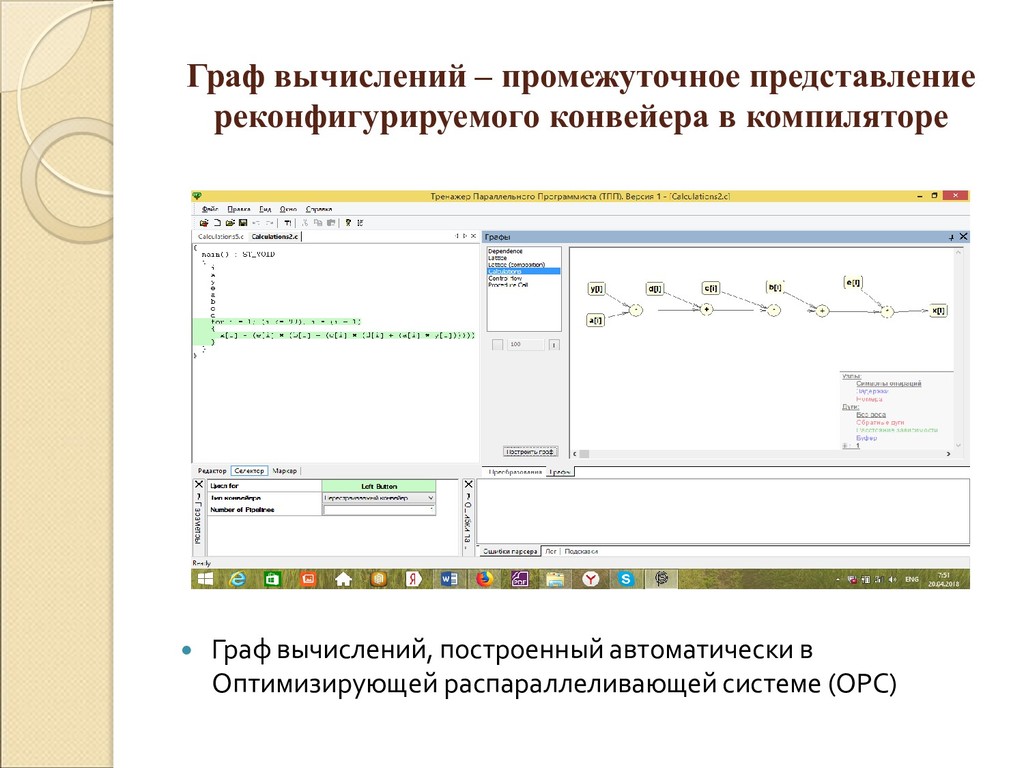{kind=link}
{kind=link}
{kind=link}
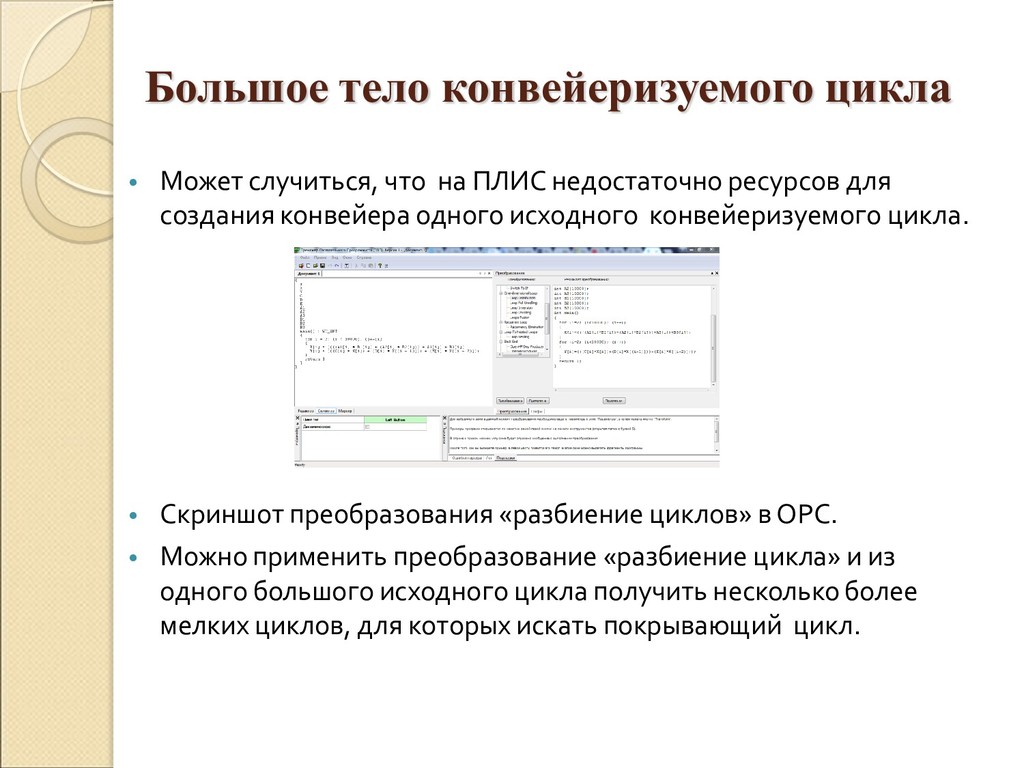{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}