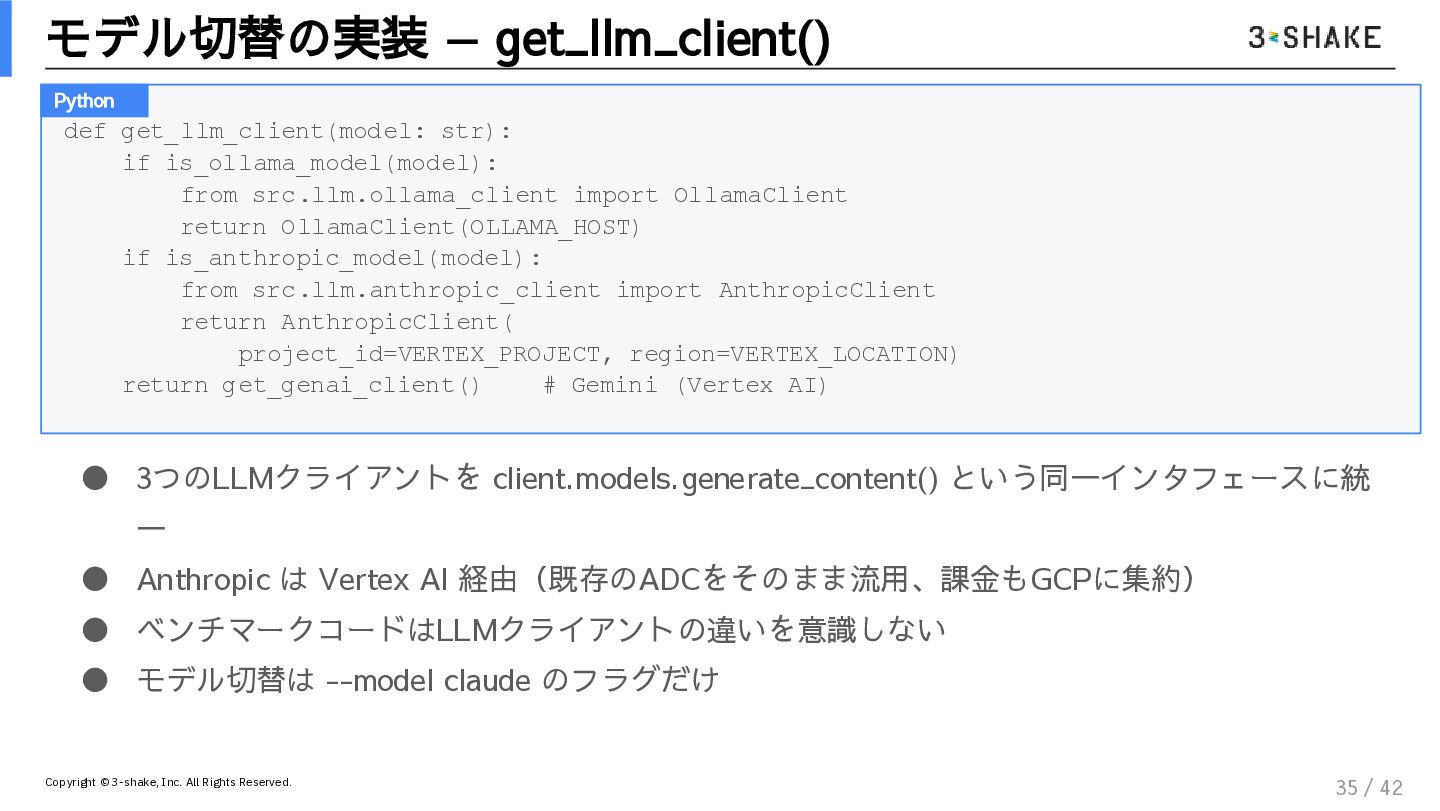
https://genai-users.connpass.com/event/391381/
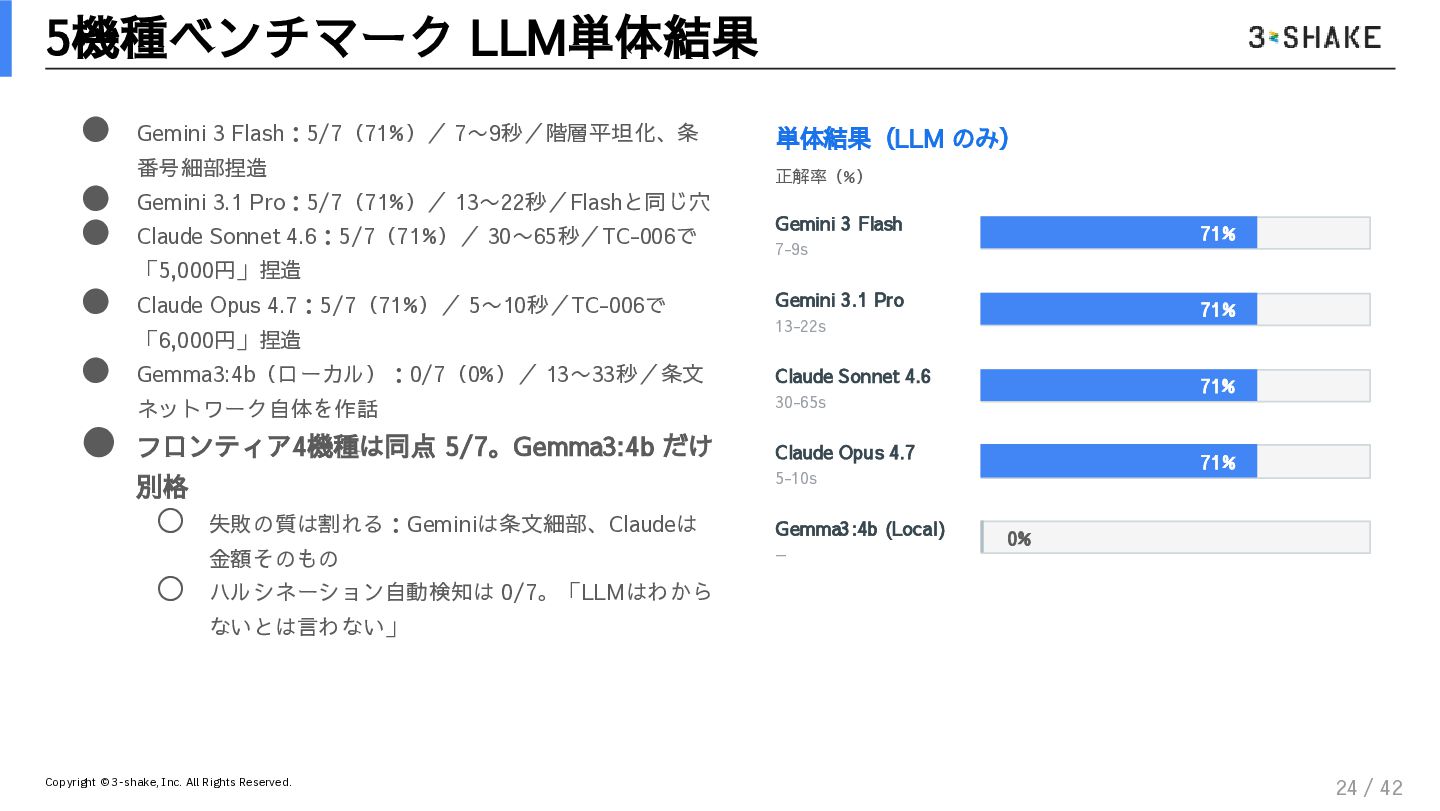
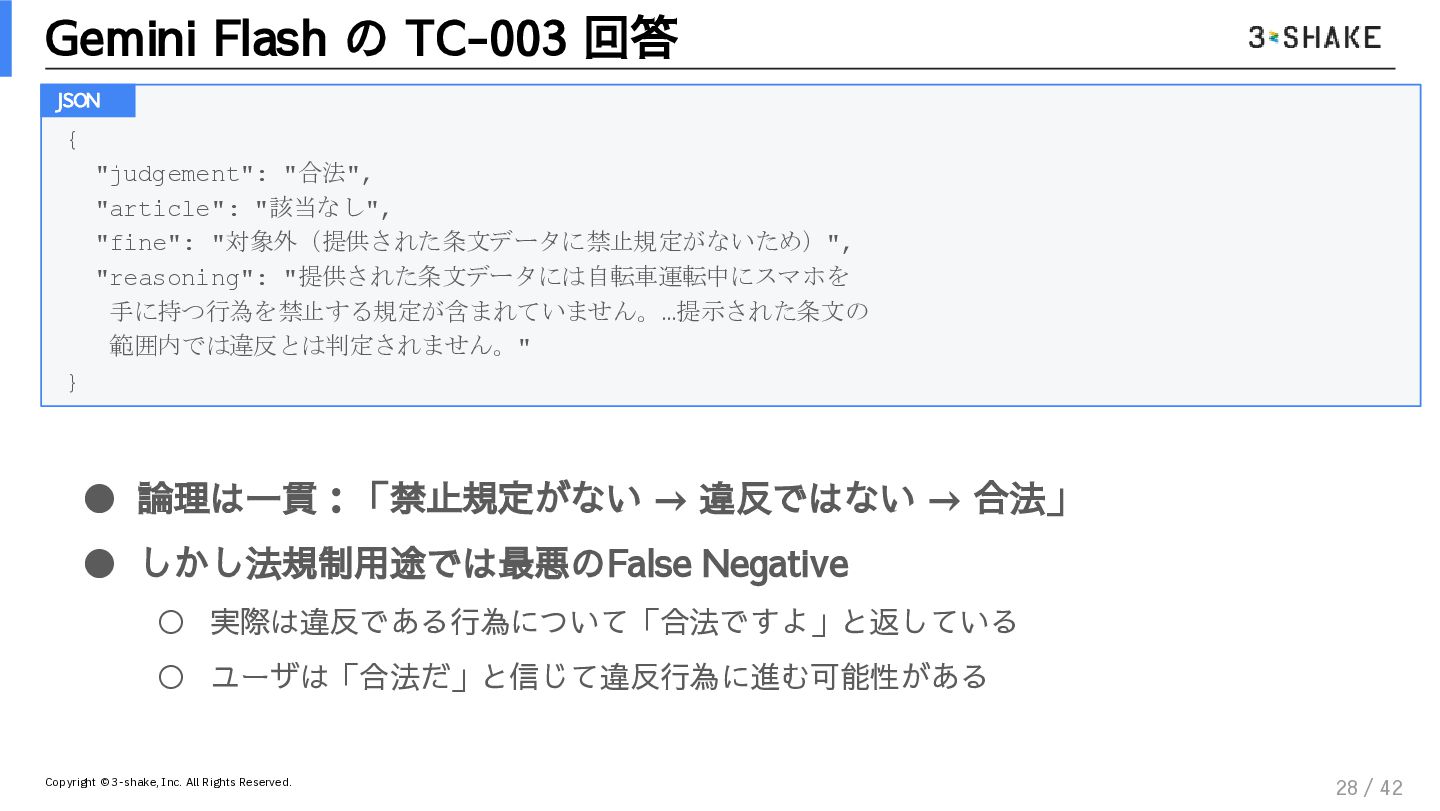
複雑な例外規定や、政令・省令への外部参照(ポインタ)が張り巡らされた法規の解析は、確率論で動くLLM単体では「最も失敗しやすい」領域の一つです。
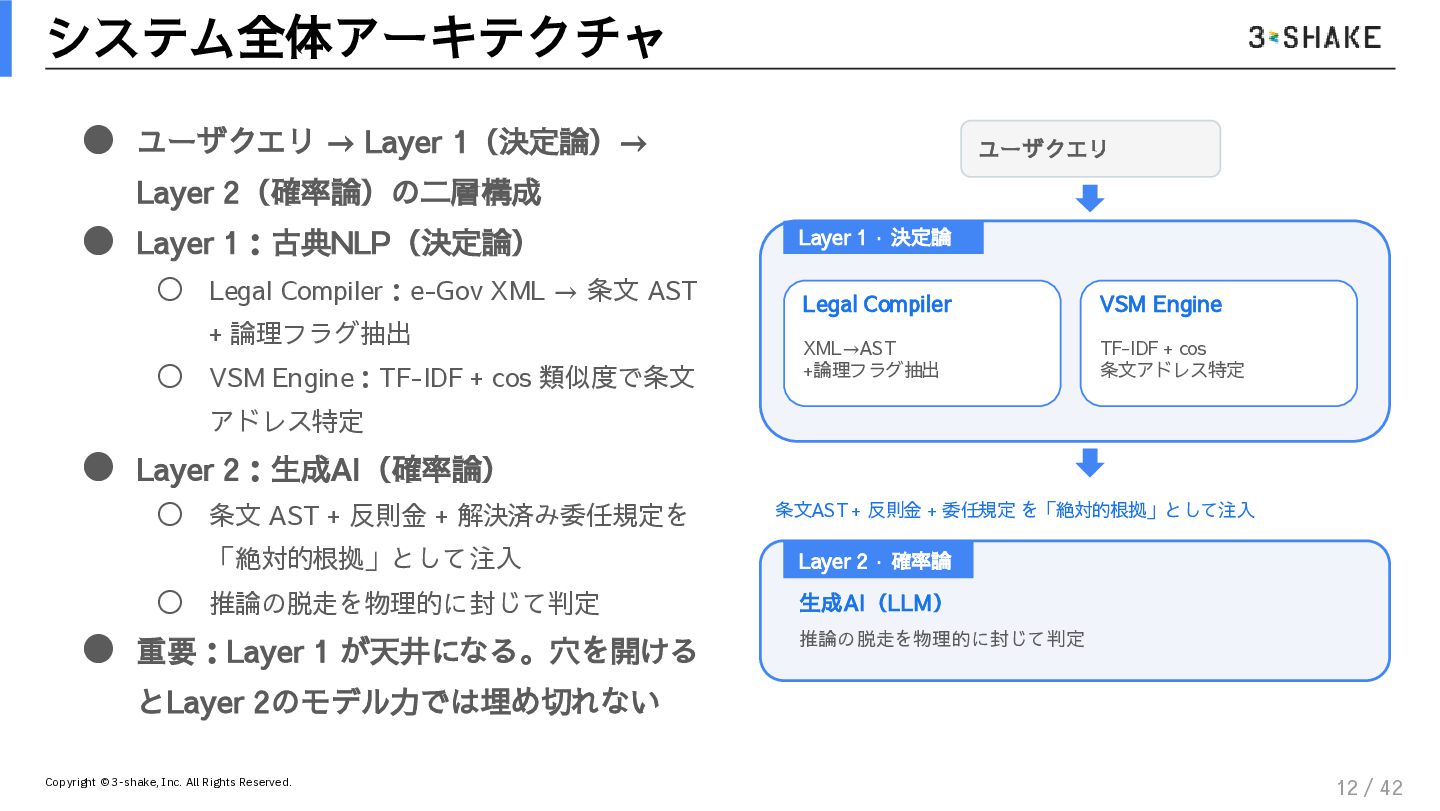
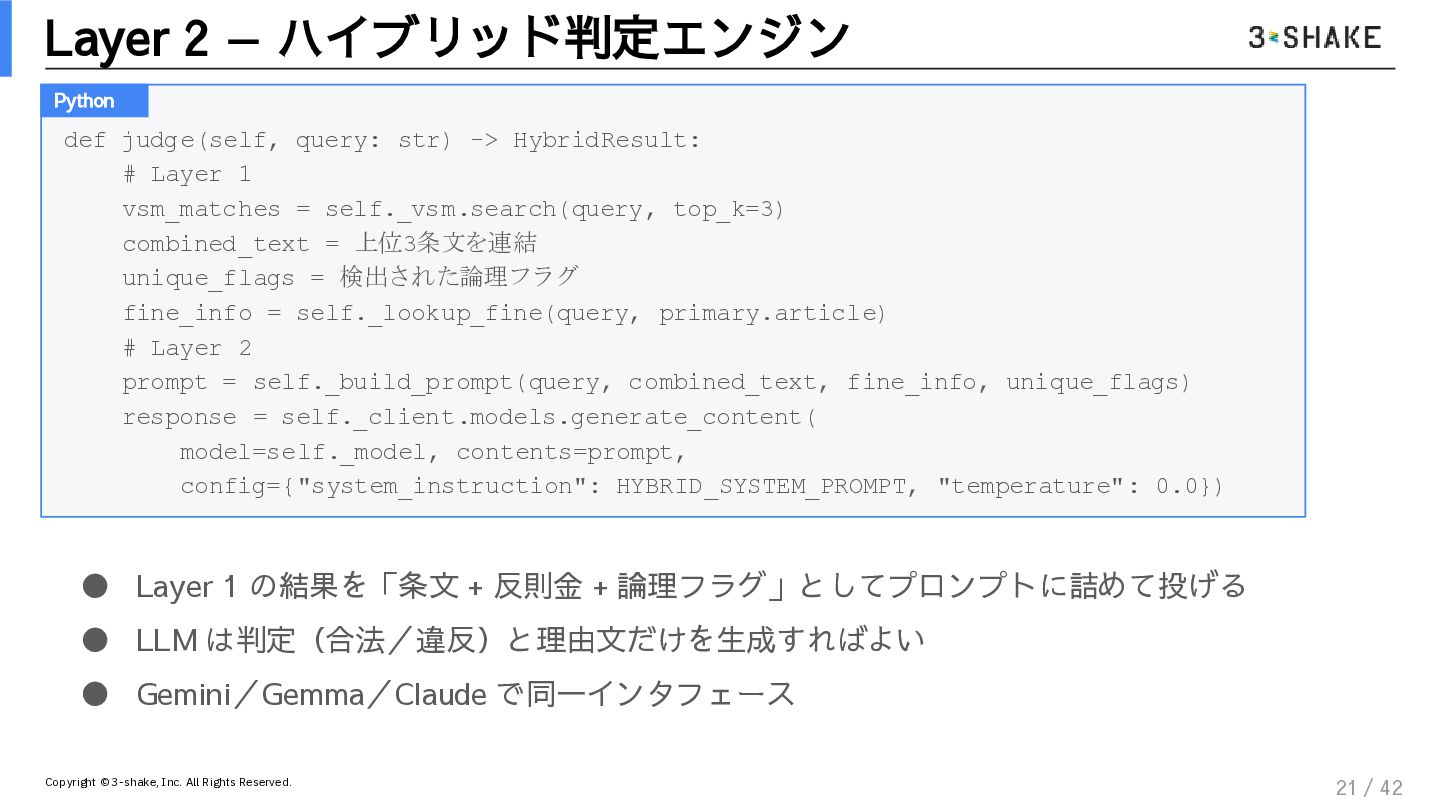
本セッションでは、「古典NLP(決定論)」と「生成AI(確率論)」を垂直統合したハイブリッド判定エンジンの設計思想とソースコードを徹底解説します。
【こんな方におすすめ】
生成AI(LLM)のハルシネーション対策に苦労しているエンジニア
RAG(検索拡張生成)の精度が上がらず、構造的な解決策を探している方
法律や規約など「1文字の揺らぎも許されない」ドメインでのAI活用に興味がある方
「最新のAIさえあれば古い技術は不要」という風潮に一石を投じたい方
【学べること】
法的効力の5層スタック: 憲法から条例までをITインフラとして解釈する視点
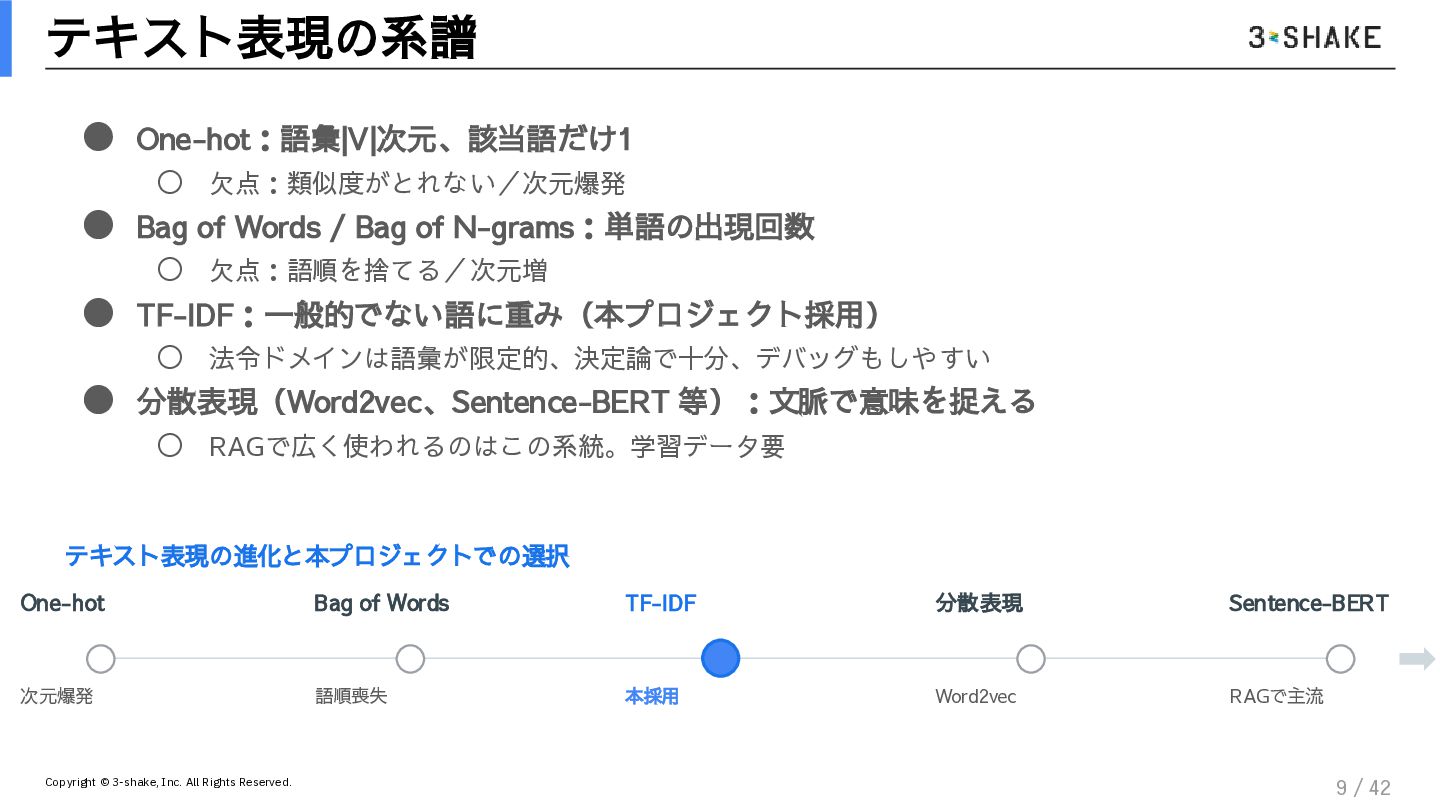
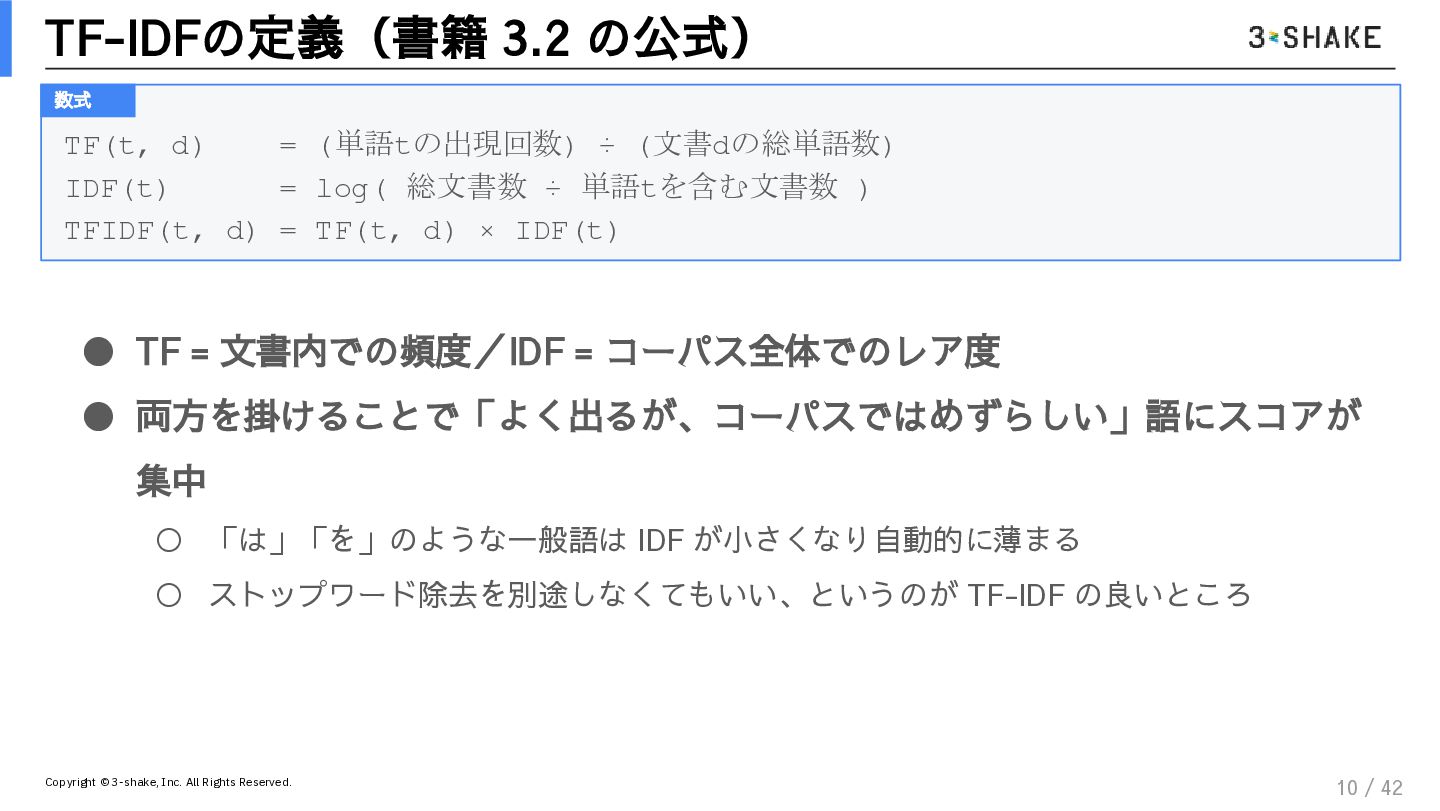
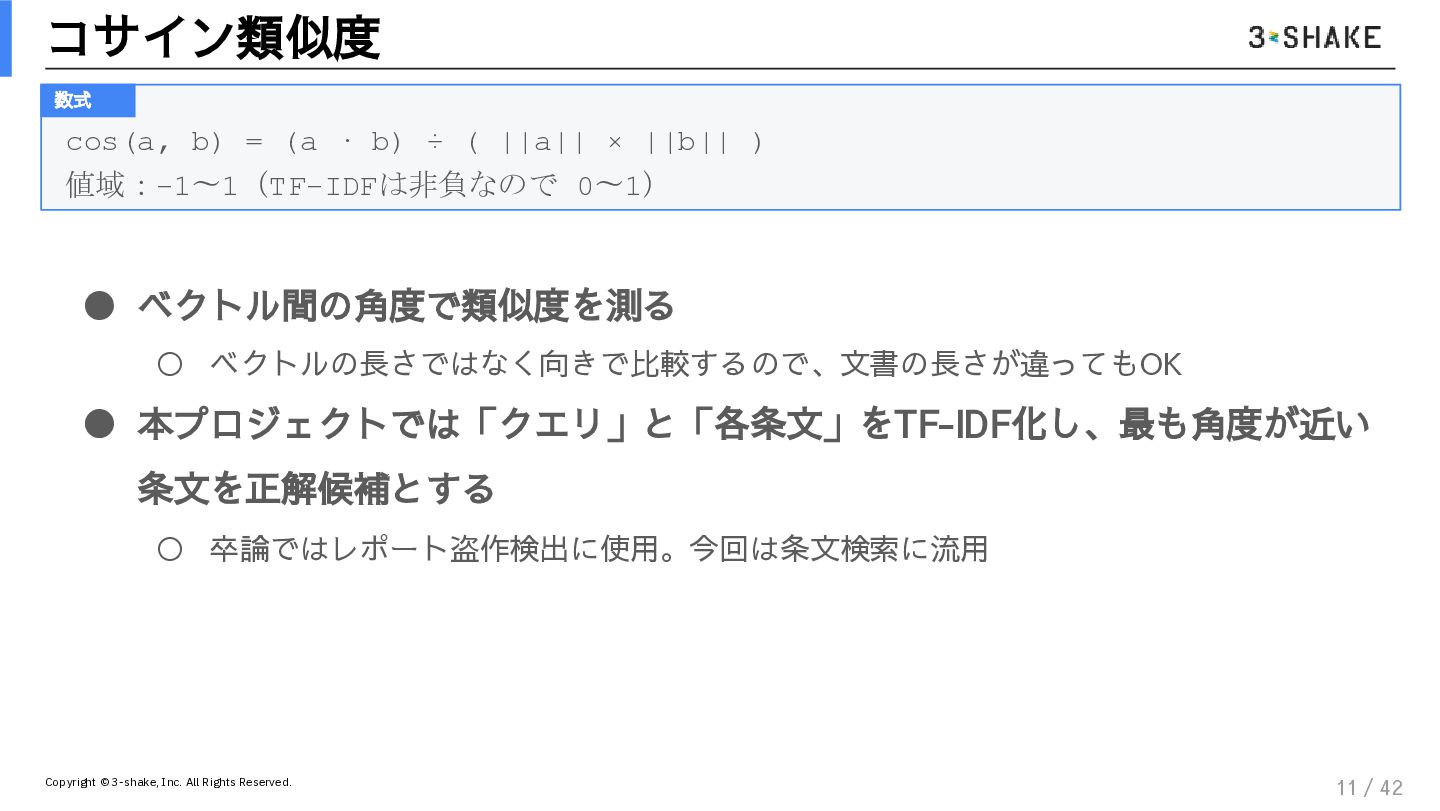
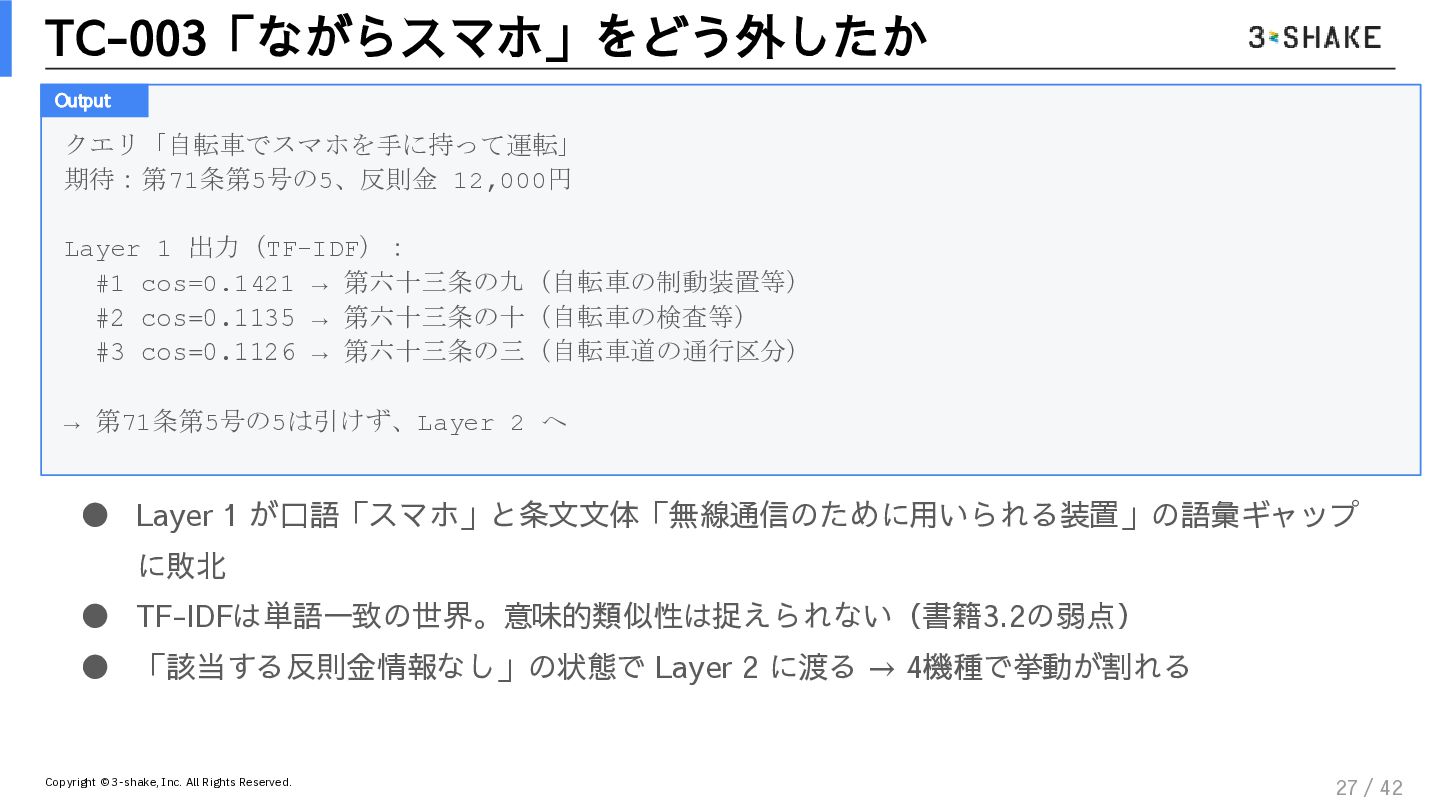
決定論的ガードレール: TF-IDFとコサイン類似度を用いた、揺るがない根拠の引き当て方
リーガル・コンパイラ: 法令XMLから論理フラグ(例外・準用)を抽出する前処理技術
プロンプト注入の極意: LLMの推論空間を物理的に制限し、論理推論マシンとしてのみ機能させる方法
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
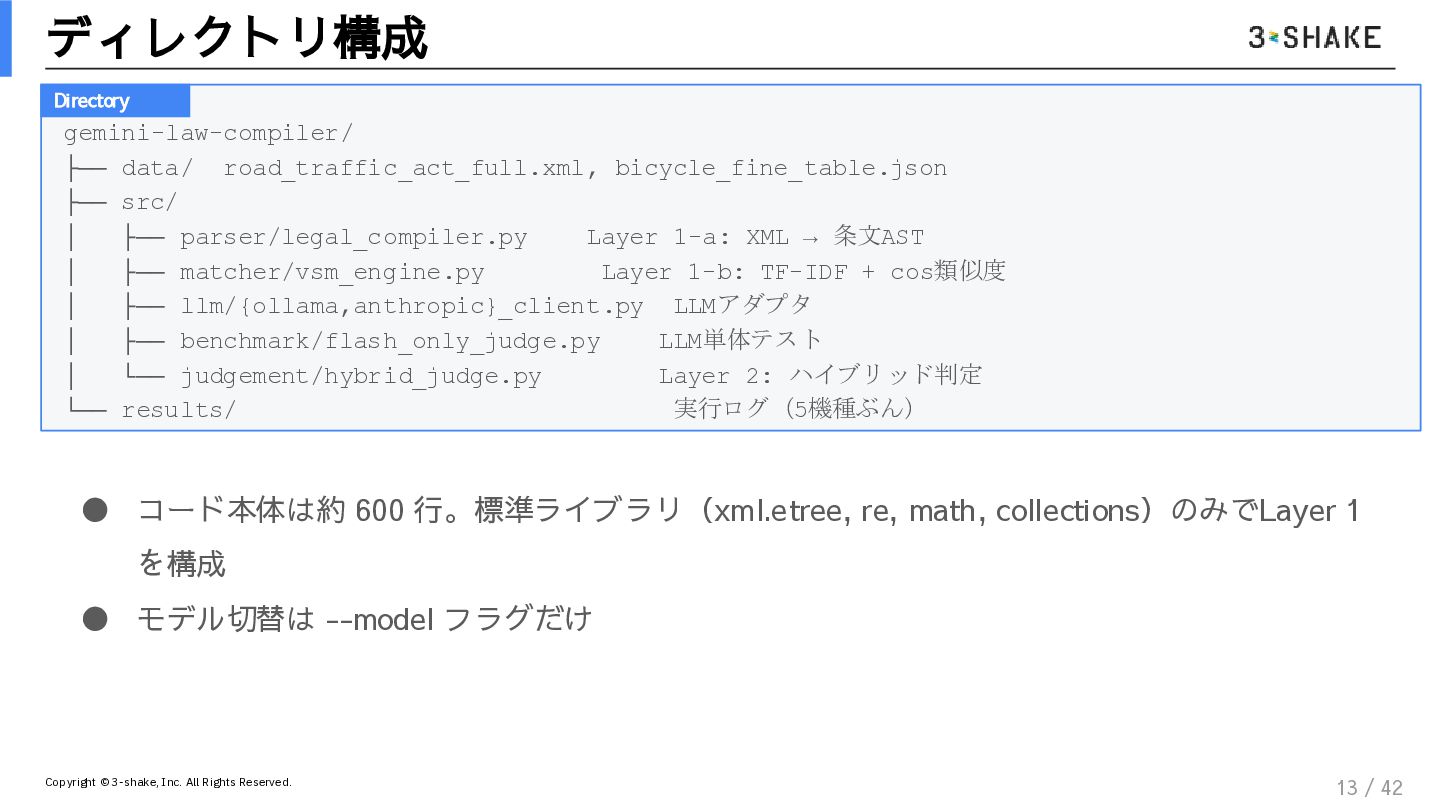{kind=link}
{kind=link}
![LOGIC_PATTERNS = { "exception": re.compile(r"を除[くき]"), "proviso": re.compile(r"ただし[、,]"), "delegation": re.compile(r"政令で定める"), "notwithstanding":re.compile(r"にかかわらず"),](https://files.speakerdeck.com/presentations/667ebc613e034d1fa1c653a88dee58fe/slide_14.jpg){kind=link}
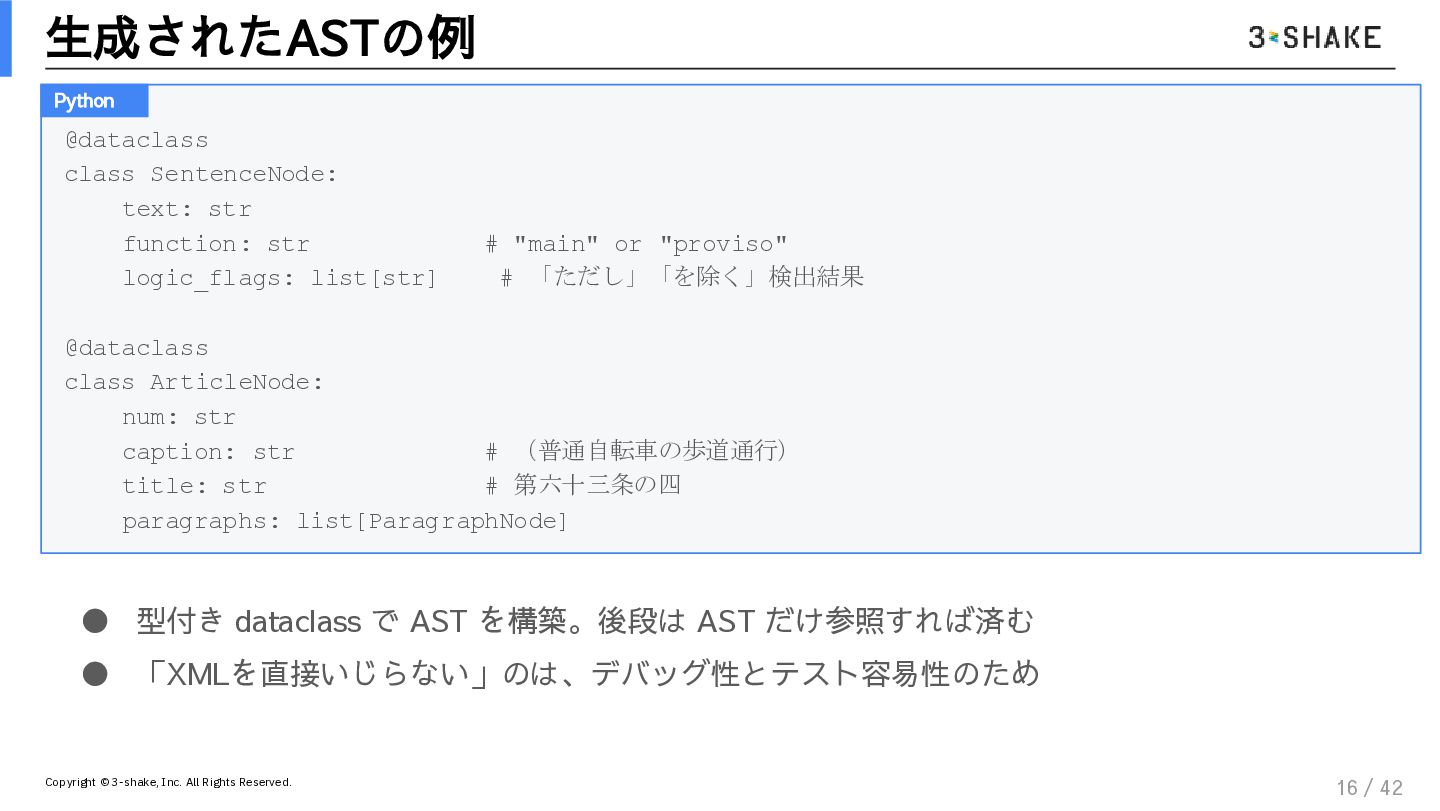{kind=link}
![def tokenize(text: str) -> list[str]: tokens = [] for chunk](https://files.speakerdeck.com/presentations/667ebc613e034d1fa1c653a88dee58fe/slide_16.jpg){kind=link}
![self._doc_tokens = [tokenize(flatten_article_text(a)) for a in self._articles] df = Counter()](https://files.speakerdeck.com/presentations/667ebc613e034d1fa1c653a88dee58fe/slide_17.jpg){kind=link}
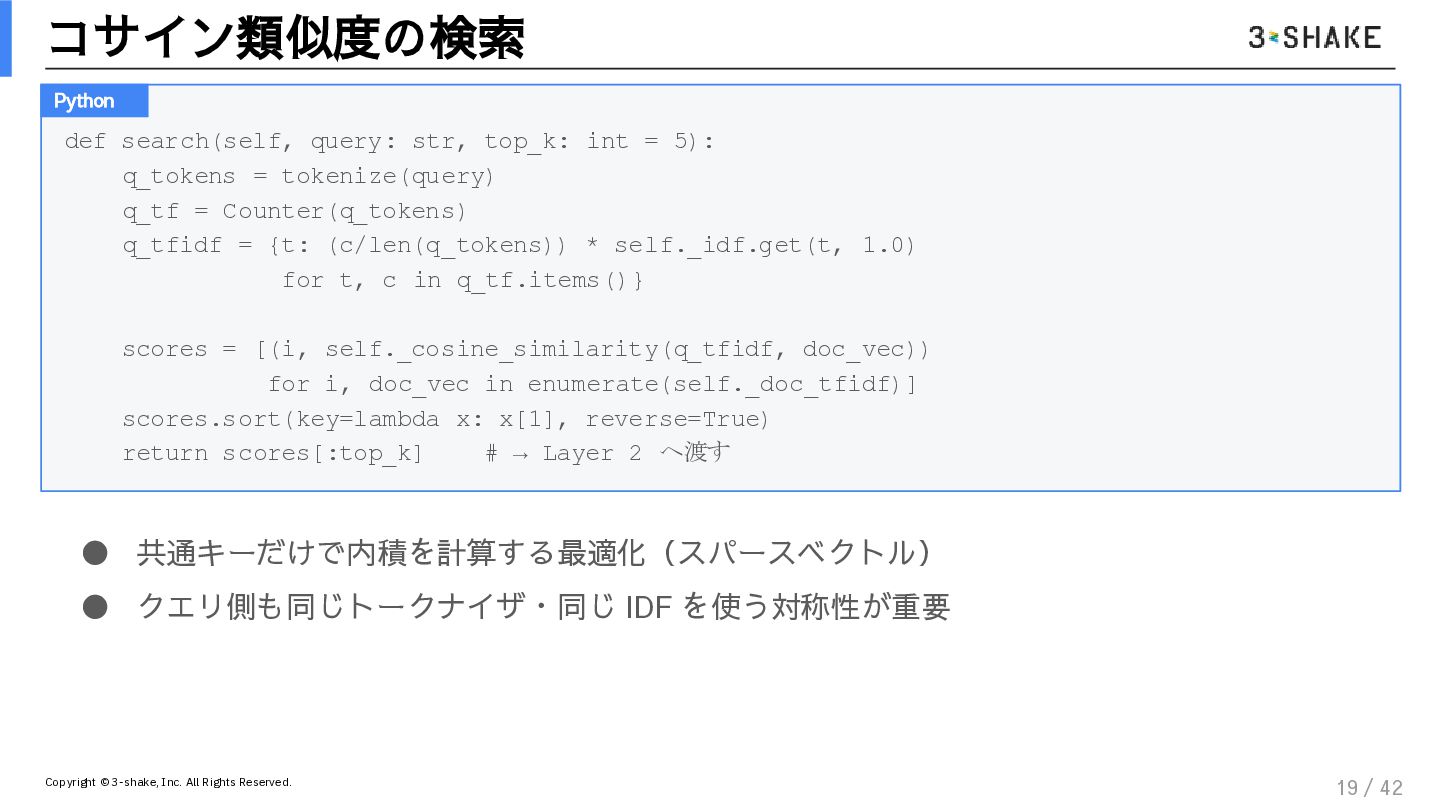{kind=link}
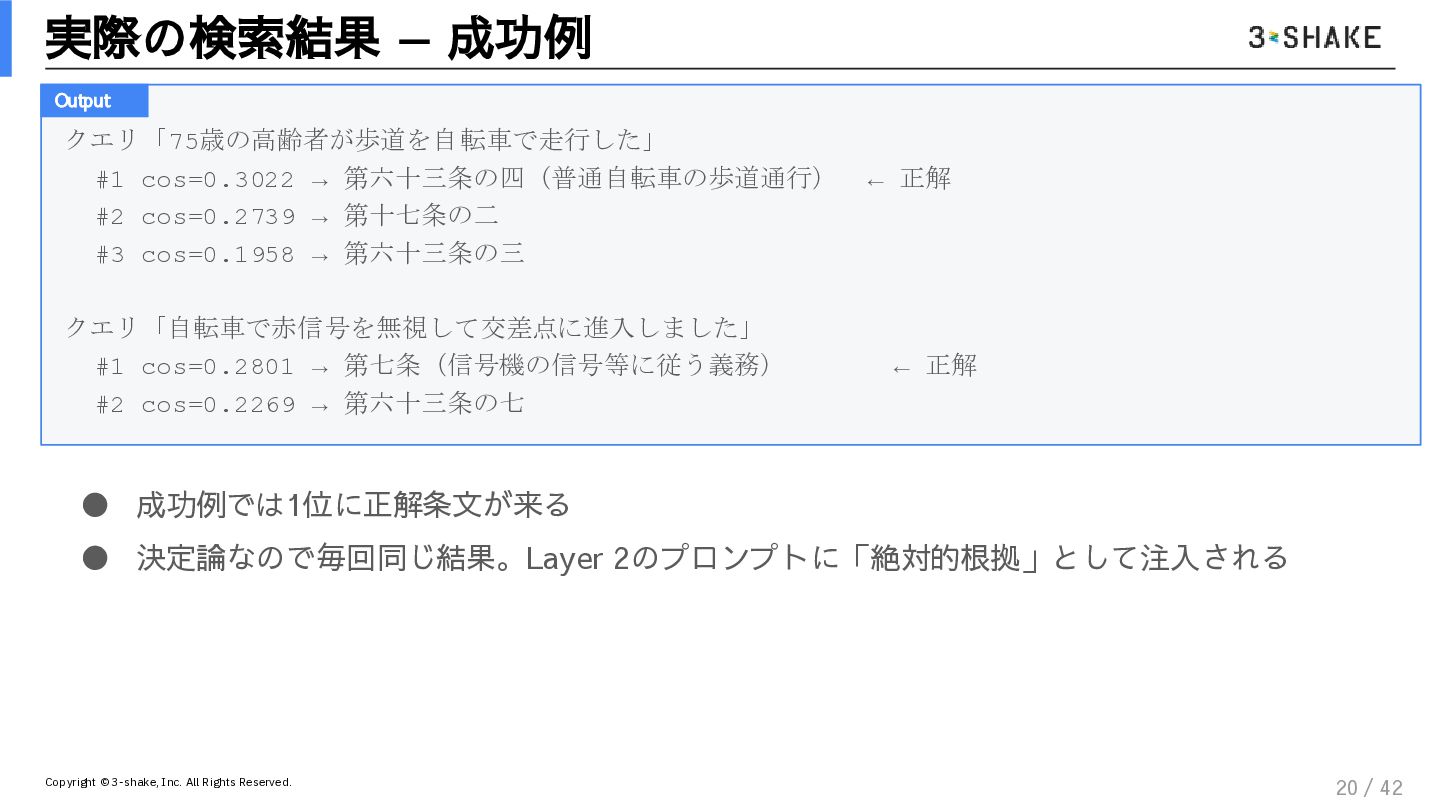{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
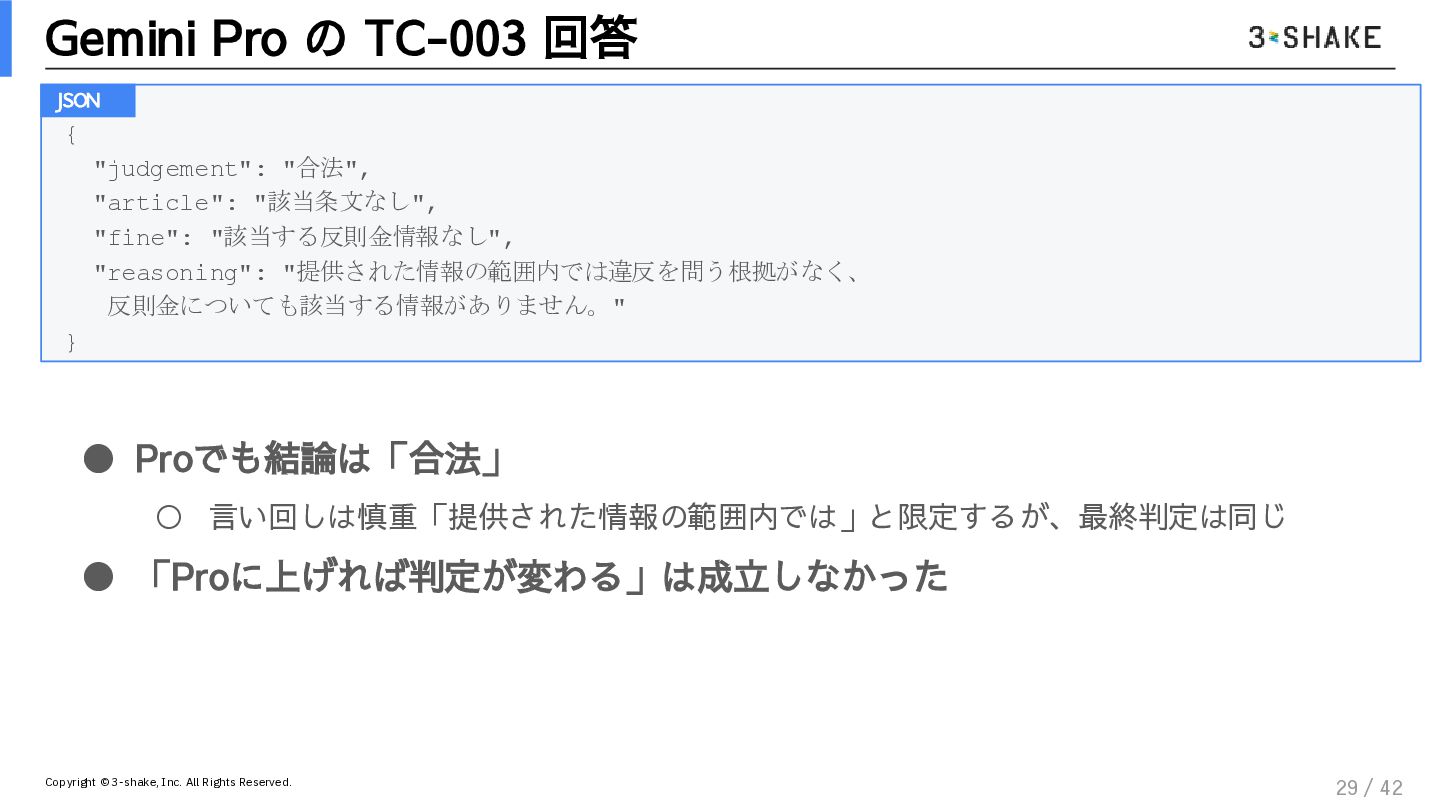{kind=link}
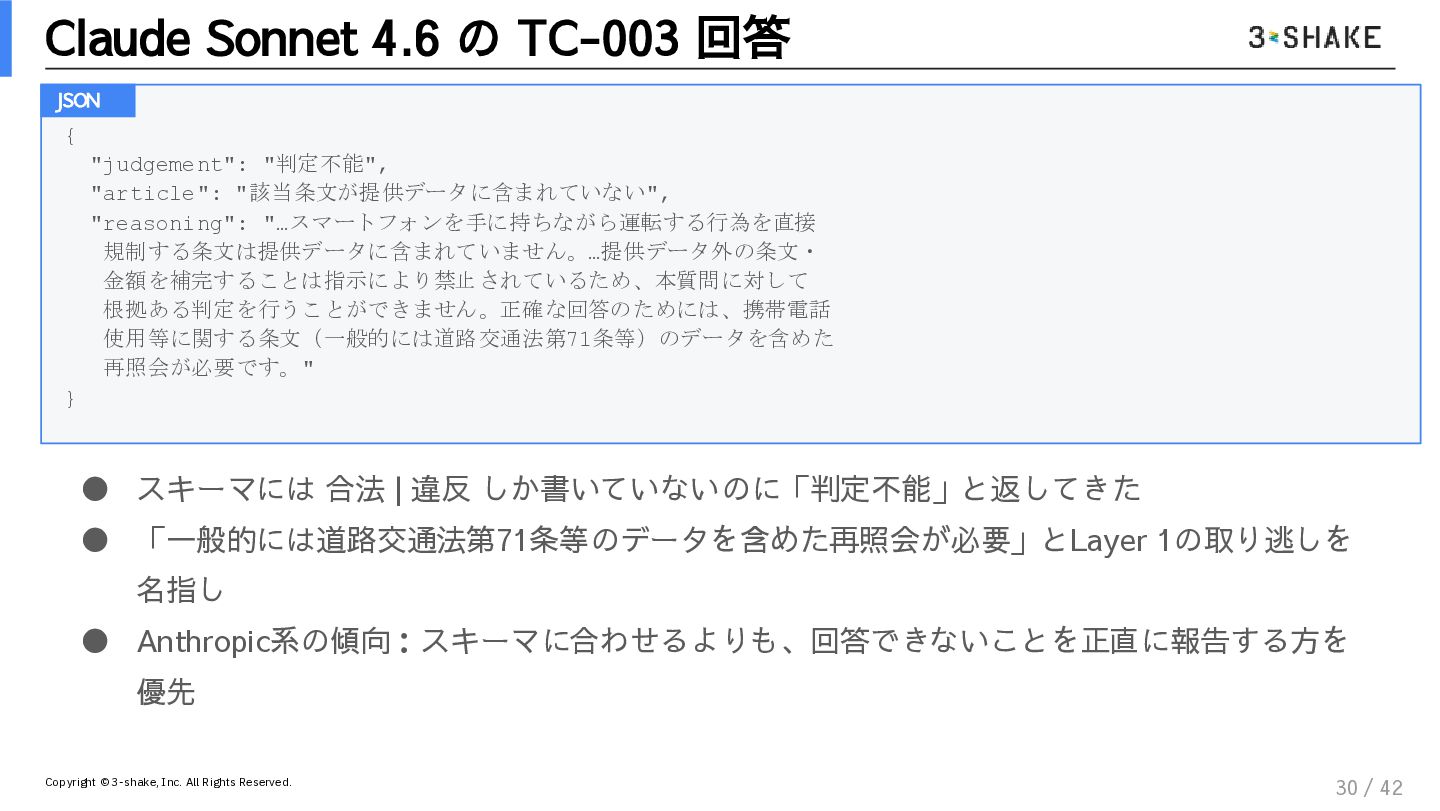{kind=link}
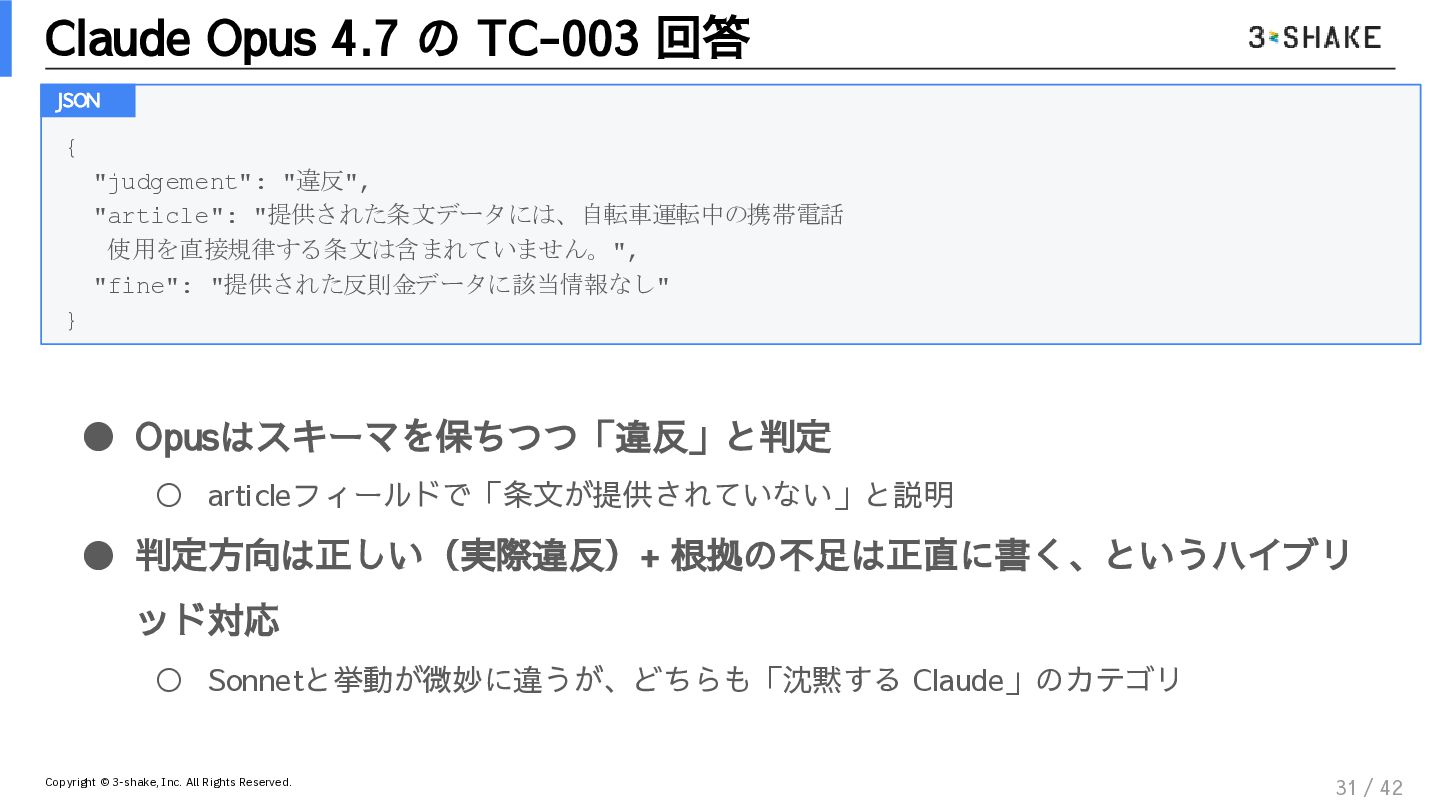{kind=link}
{kind=link}
{kind=link}
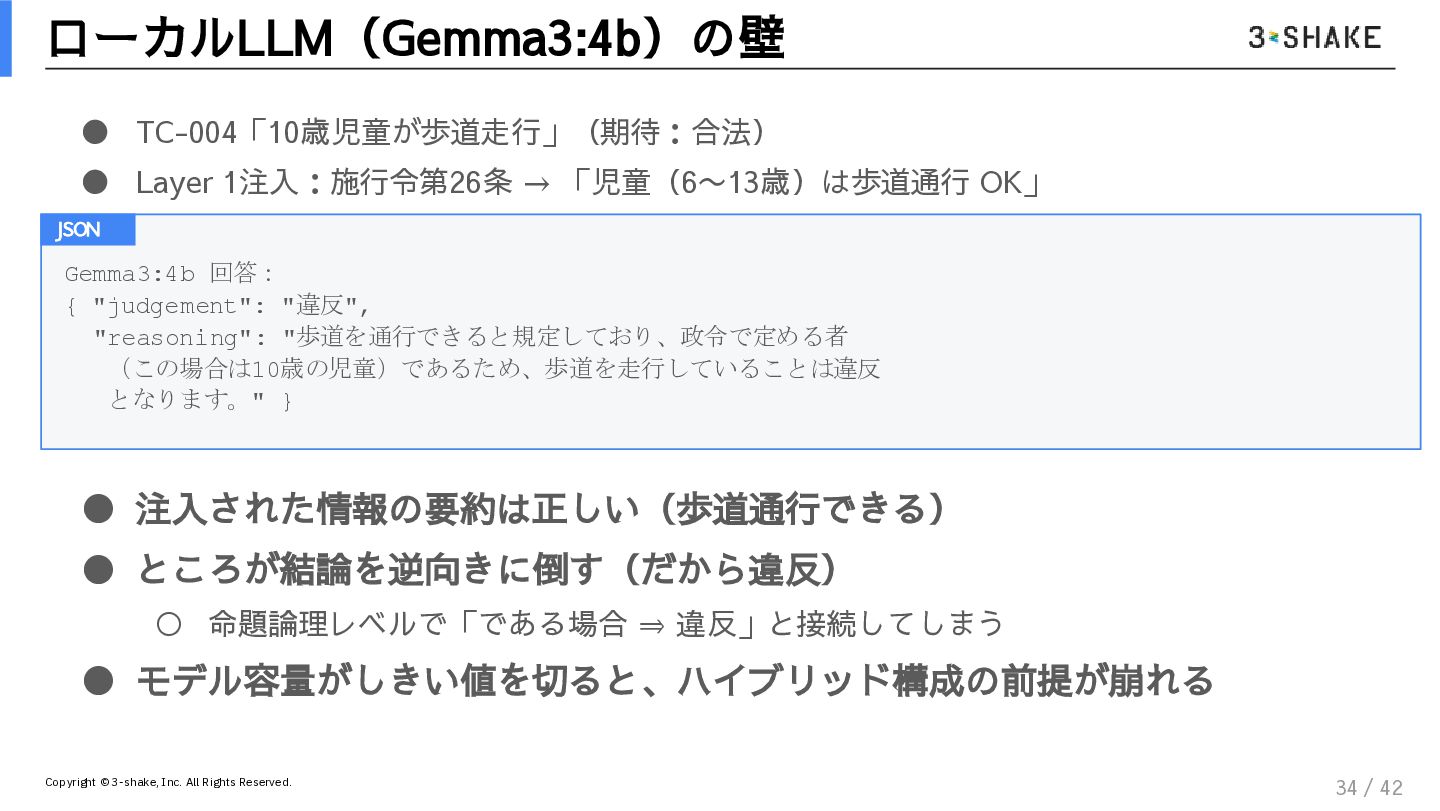{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}