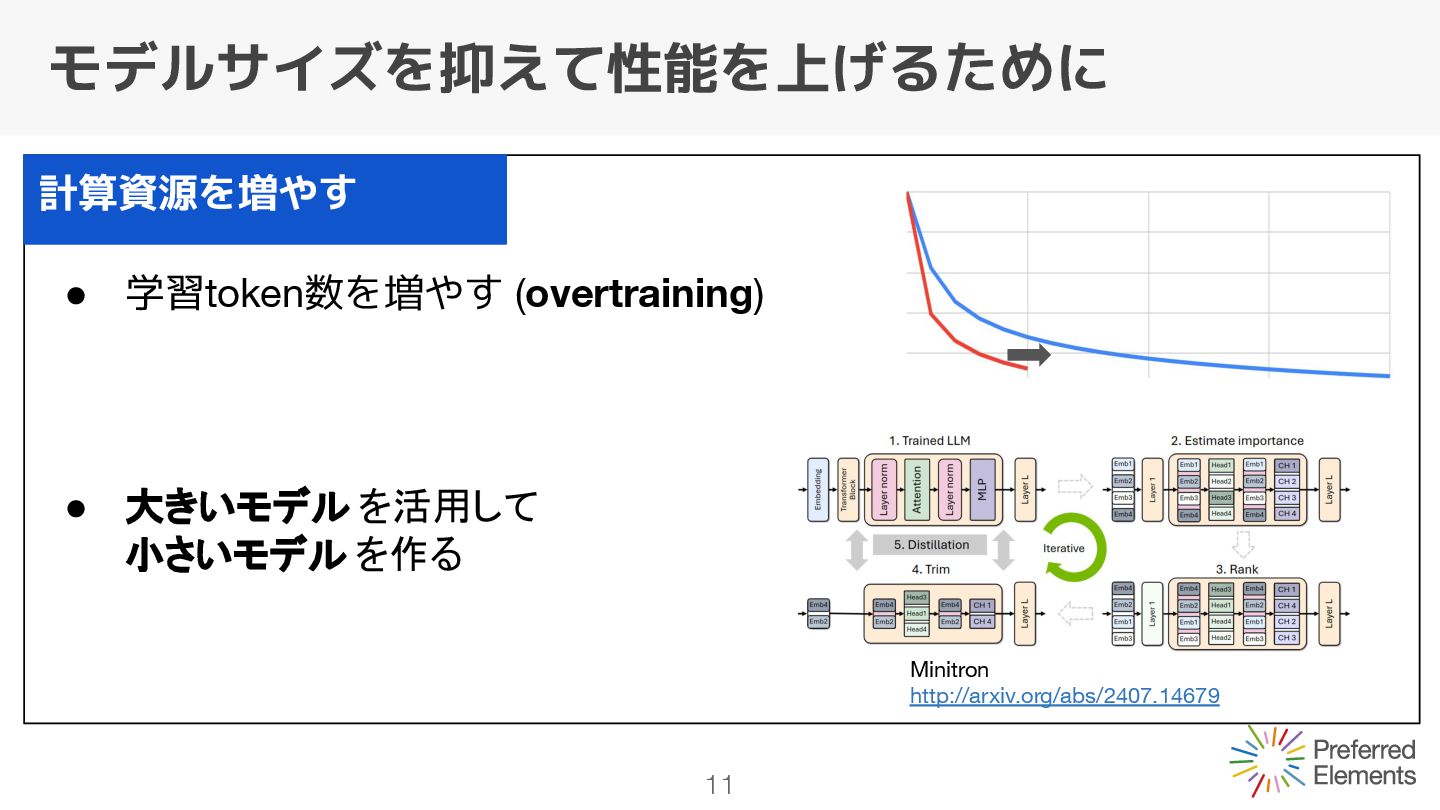
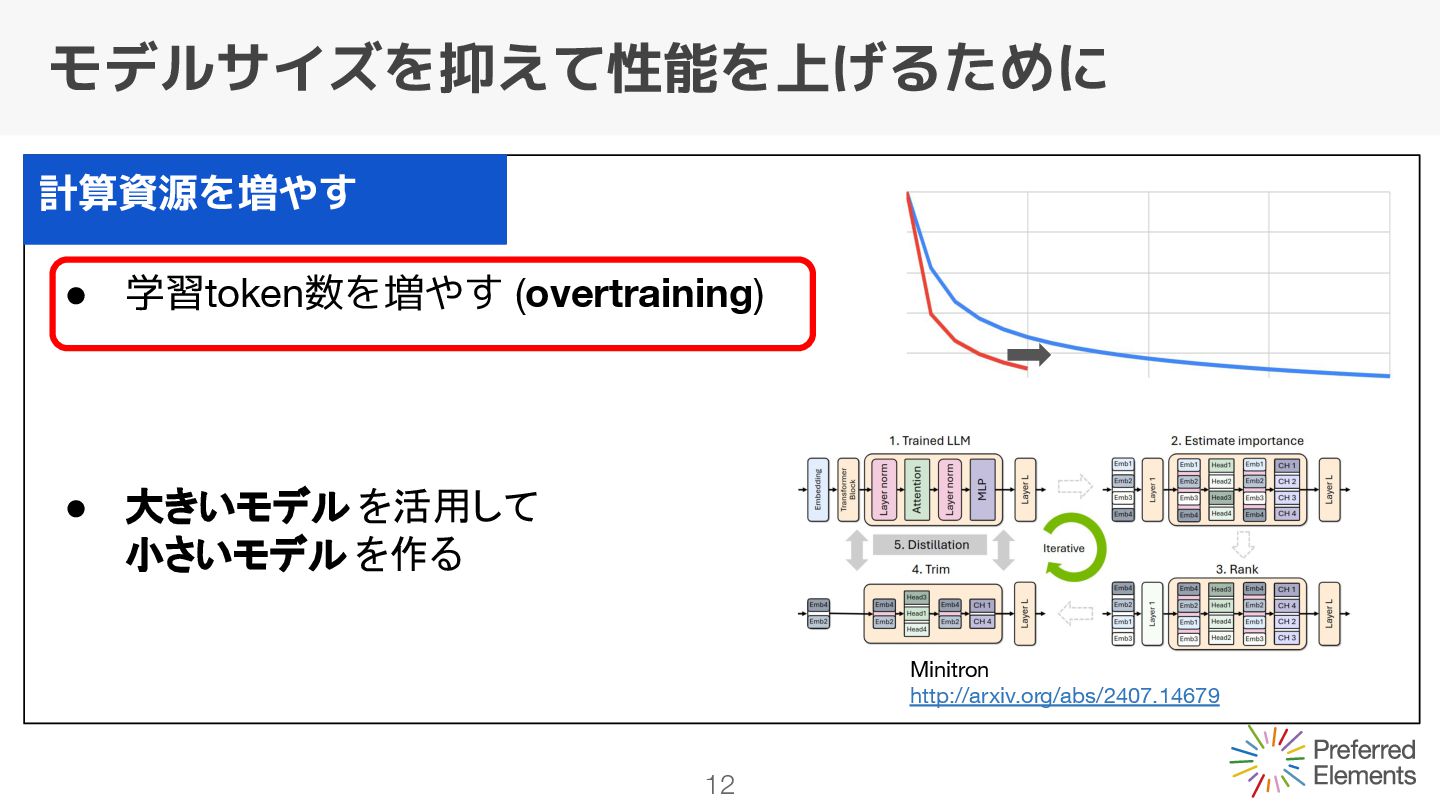
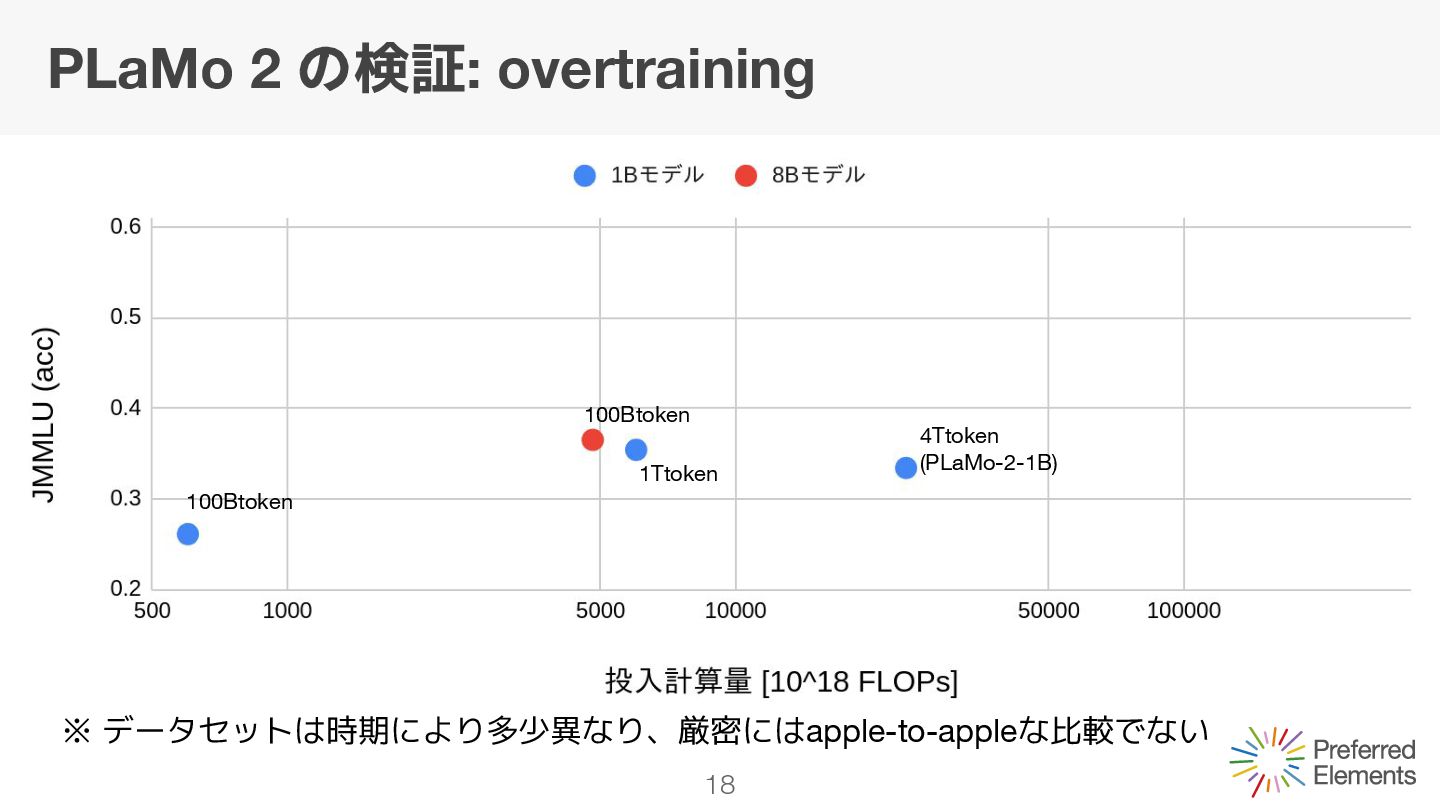
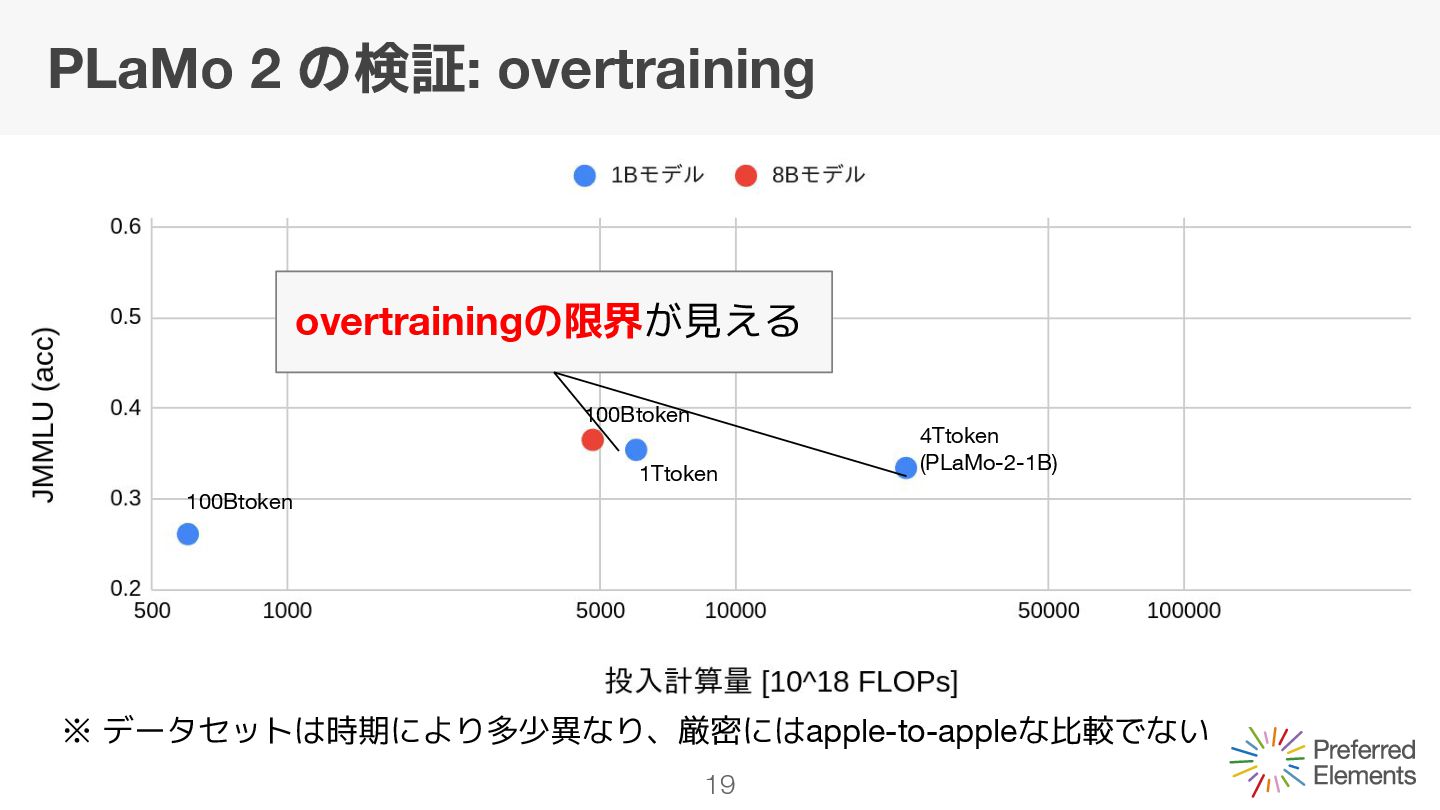
モデルサイズが変わらないので一定 学習tokenを増やすと0に近づく Q. 8Bモデルの場合どのくらいで頭打ちになるのか? A. ある論文の実験を参考にすると、2~3Ttokenで限界となる可能性 [Language models scale reliably with over-training and on downstream tasks]
モデルサイズが変わらないので一定 学習tokenを増やすと0に近づく Q. 8Bモデルの場合どのくらいで頭打ちになるのか? A. ある論文の実験を参考にすると、2~3Ttokenで限界となる可能性 [Language models scale reliably with over-training and on downstream tasks] overtrainingは効果が薄い可能性
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}