application life cycle. Designing, Coding, Refactoring, Testing, Deploying, and Maintaining. • How do you test your code before deploying to production ? • Deployment strategy ( backup, roll back, isolation, etc. ) • Load testing • Resources consumption • Sync/Async communication Resiliency is not only about infra or some patterns, but also about network, application, people and culture. Conclusion Conclusion
![Designing Resilient Microservice Architecture Suat Köse Email : [email protected] Blog](https://files.speakerdeck.com/presentations/d236b89911ed4289b1feb64936bb1ece/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
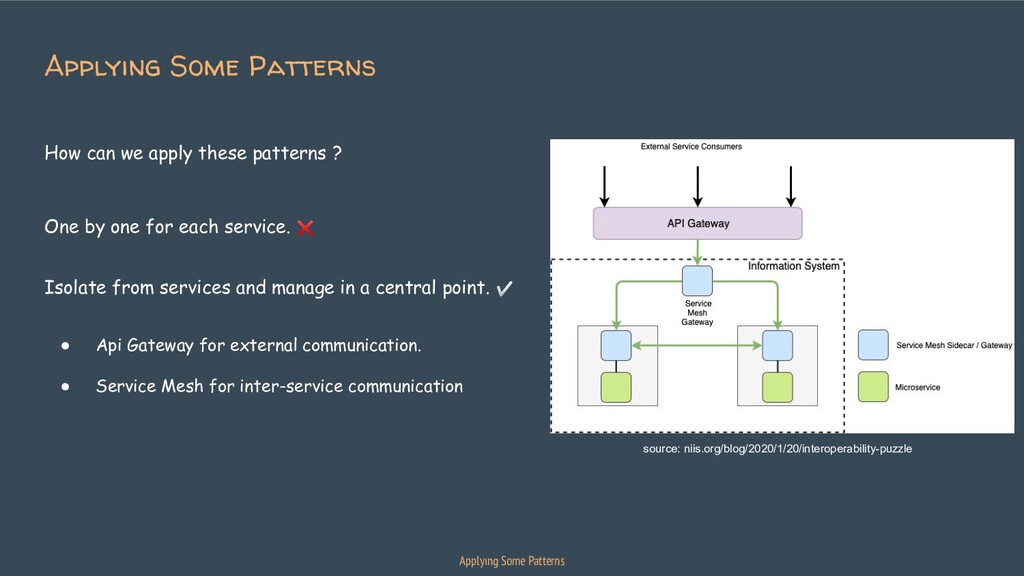{kind=link}
{kind=link}
{kind=link}
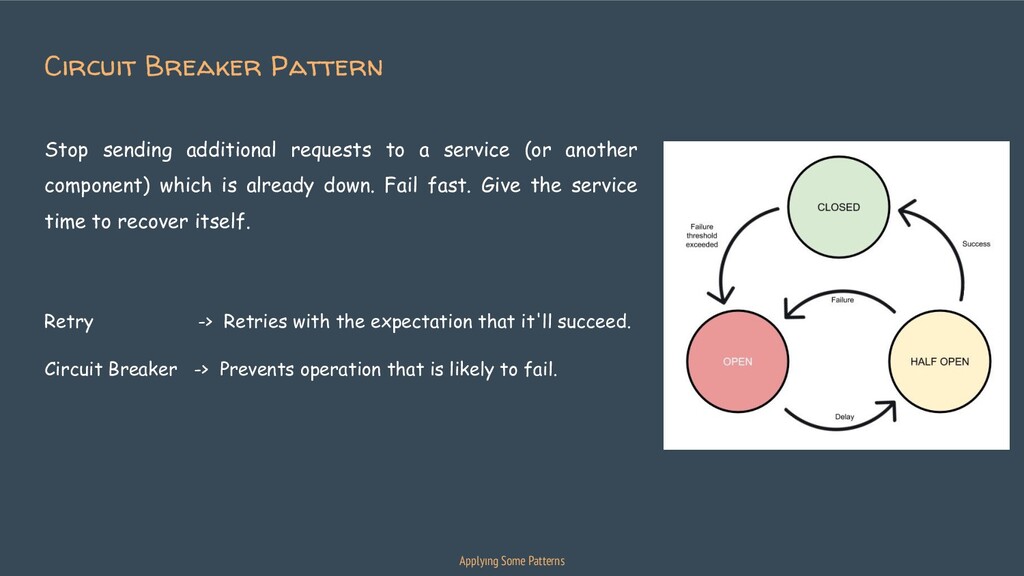{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}