2024/10/08に実施されたSnowVillage Unconference #3にて登壇した際の投影資料です。 現在関わっているSnowflakeを用いたDMP基盤構築案件でスロークエリの改善に取り組んだので、その概要をまとめました。
{kind=link}
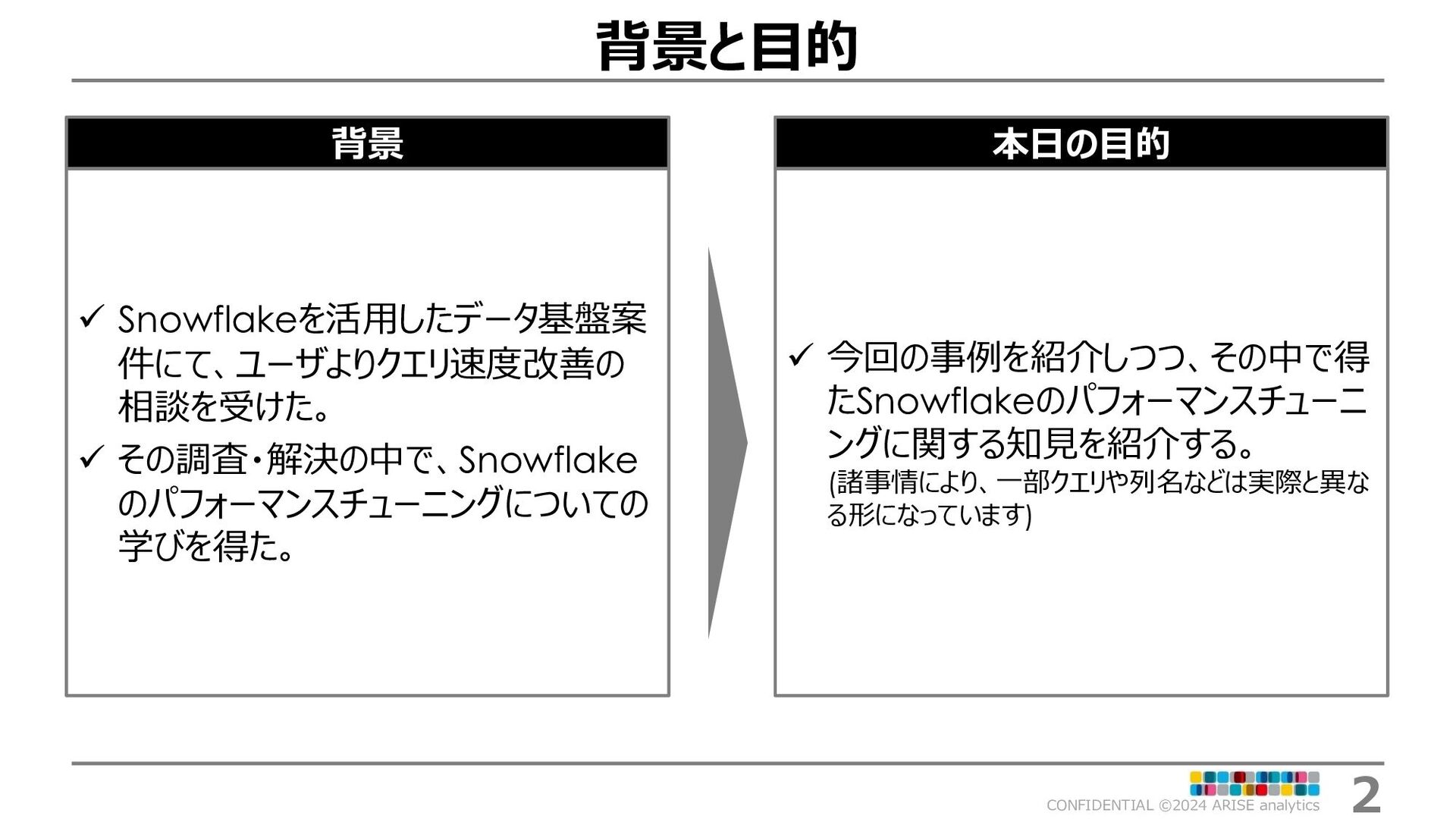{kind=link}
{kind=link}
{kind=link}
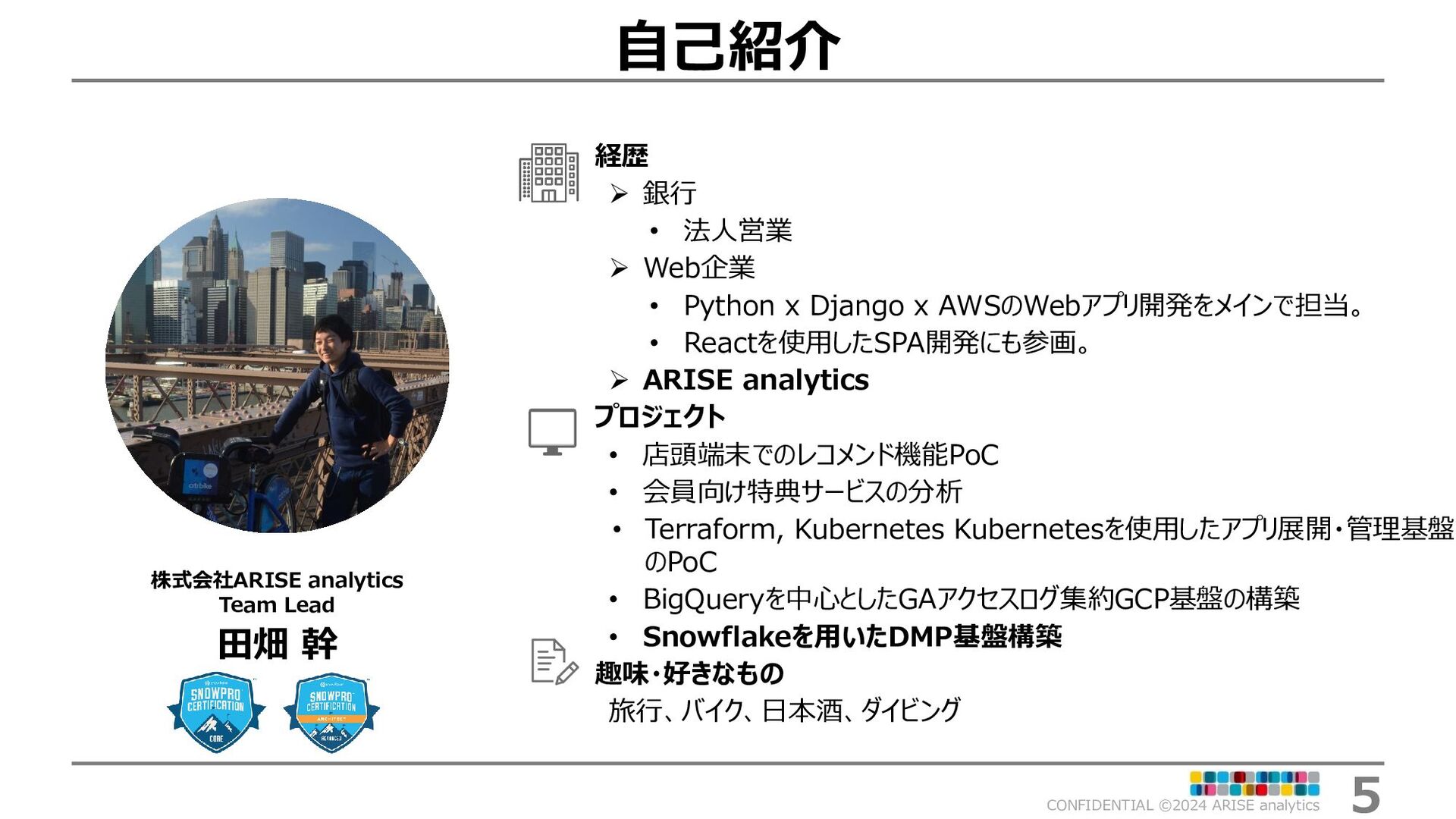{kind=link}
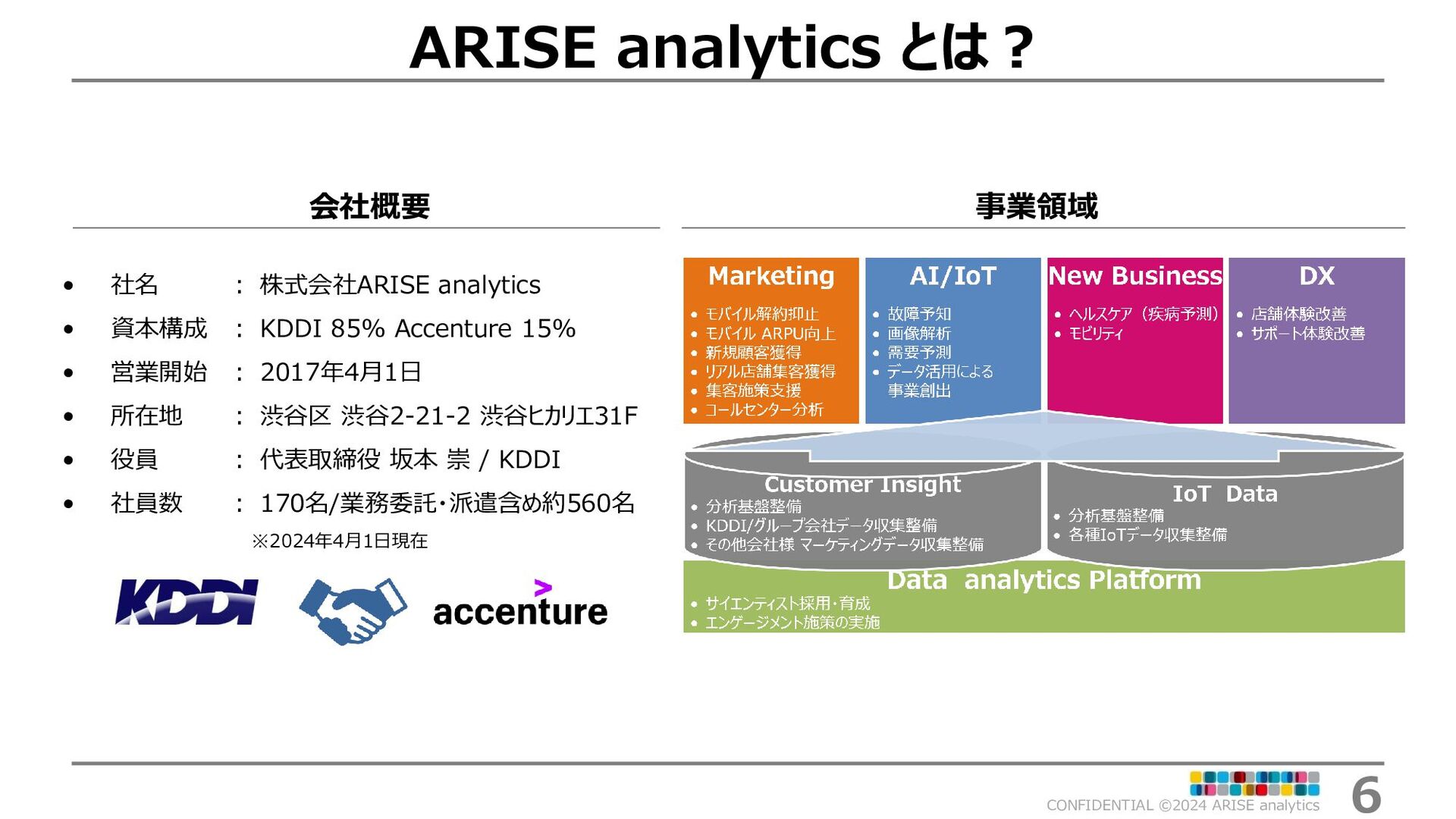{kind=link}
{kind=link}
{kind=link}
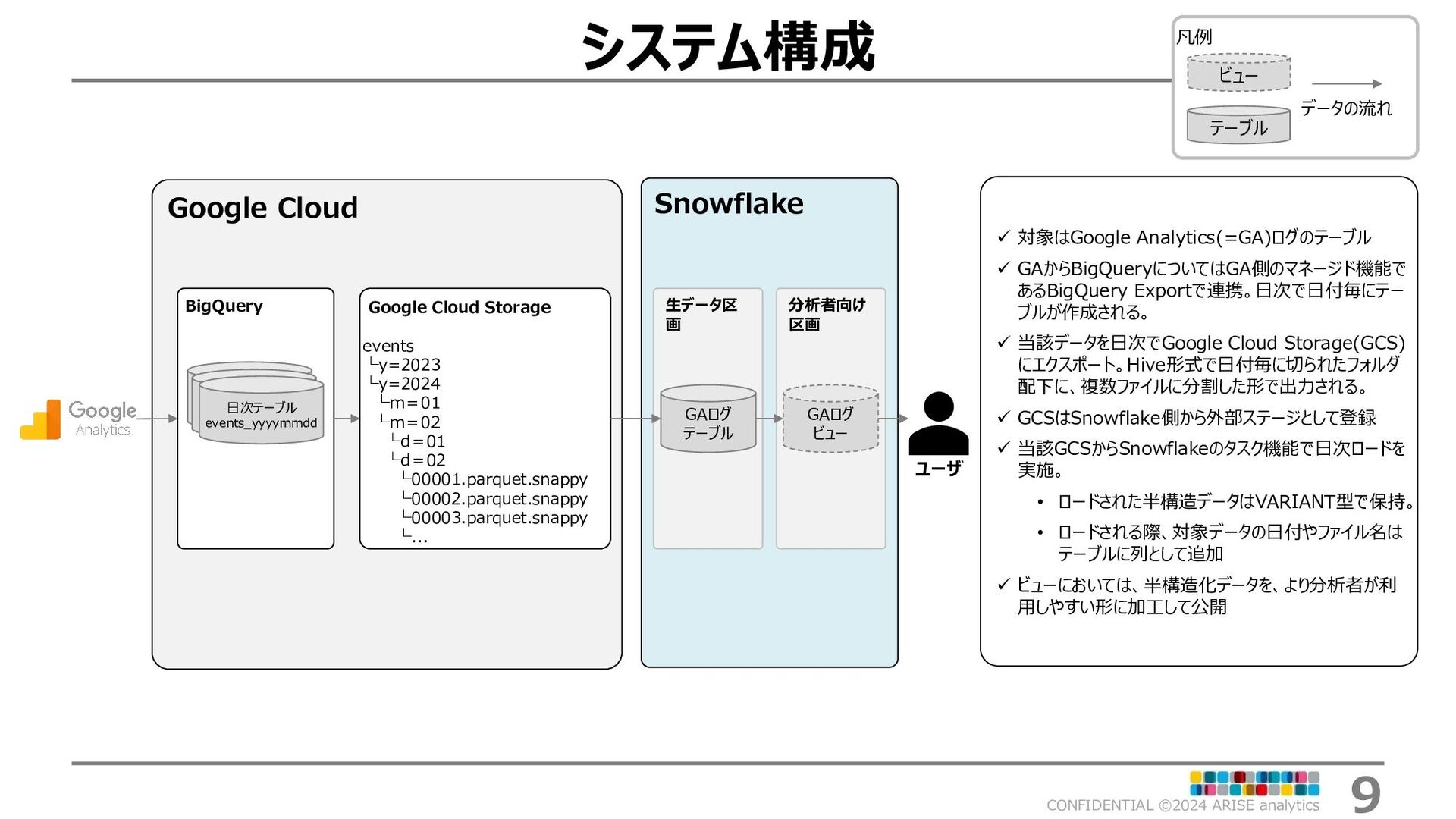{kind=link}
{kind=link}
{kind=link}
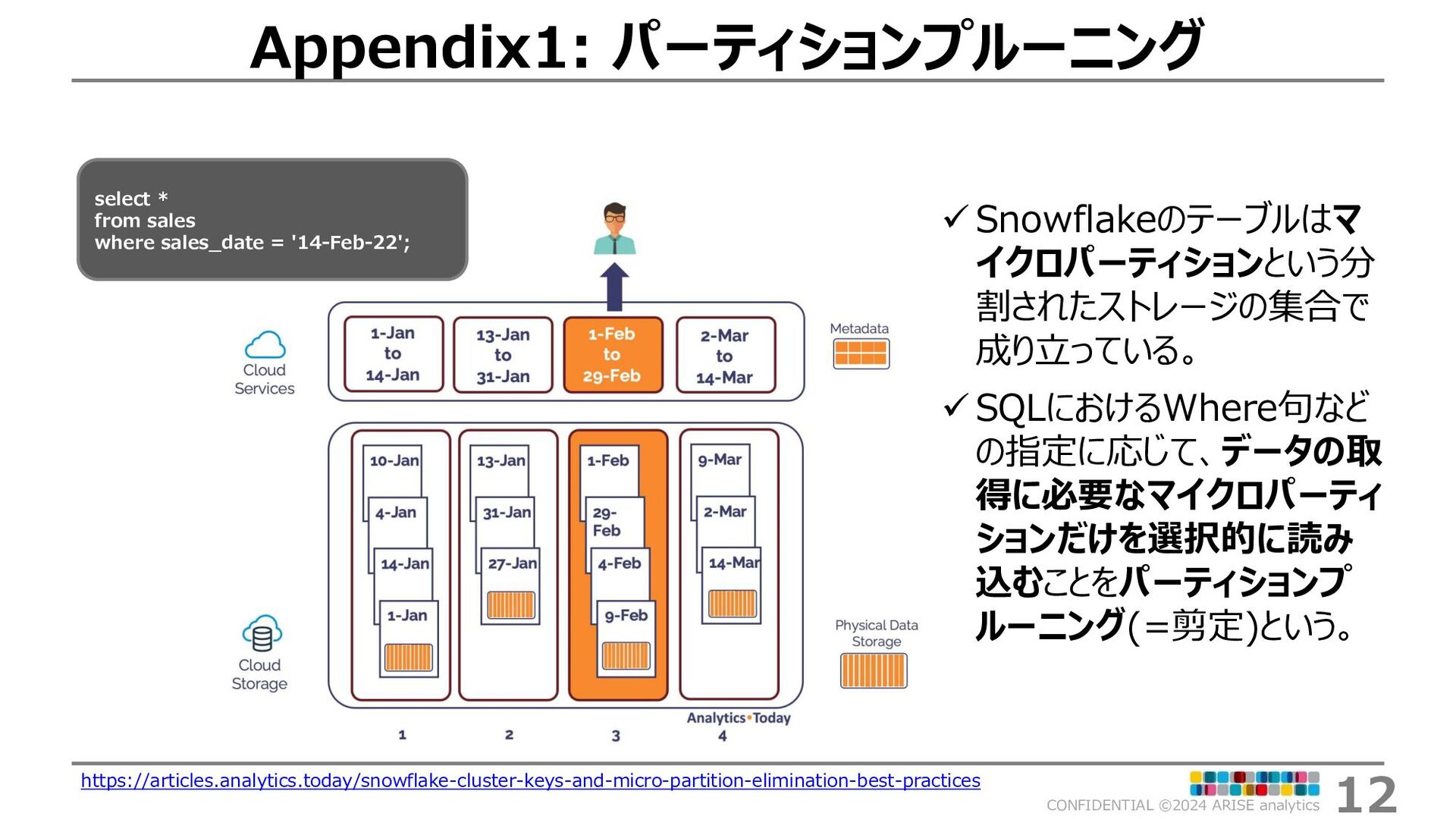{kind=link}
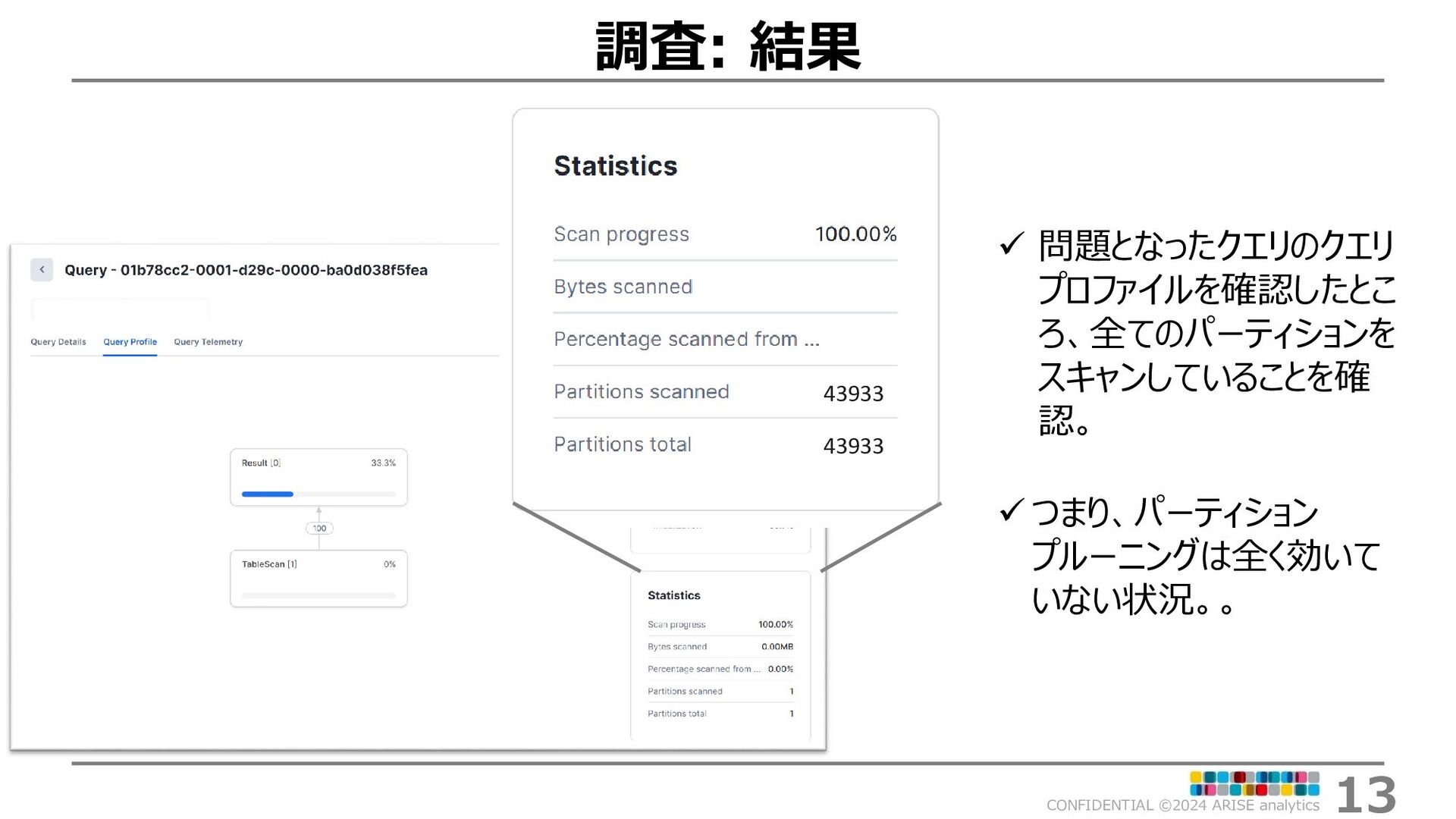{kind=link}
{kind=link}
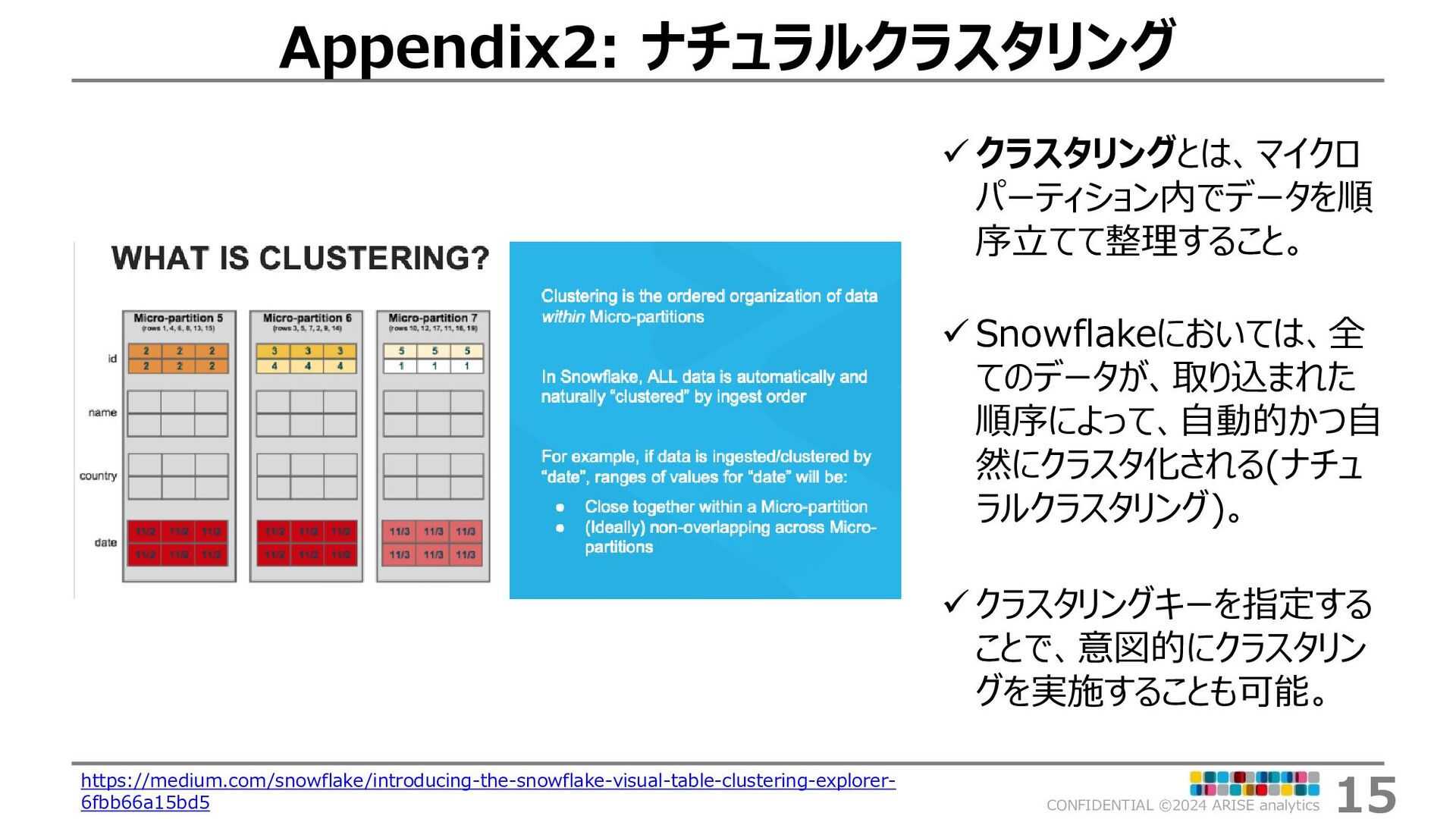{kind=link}
{kind=link}
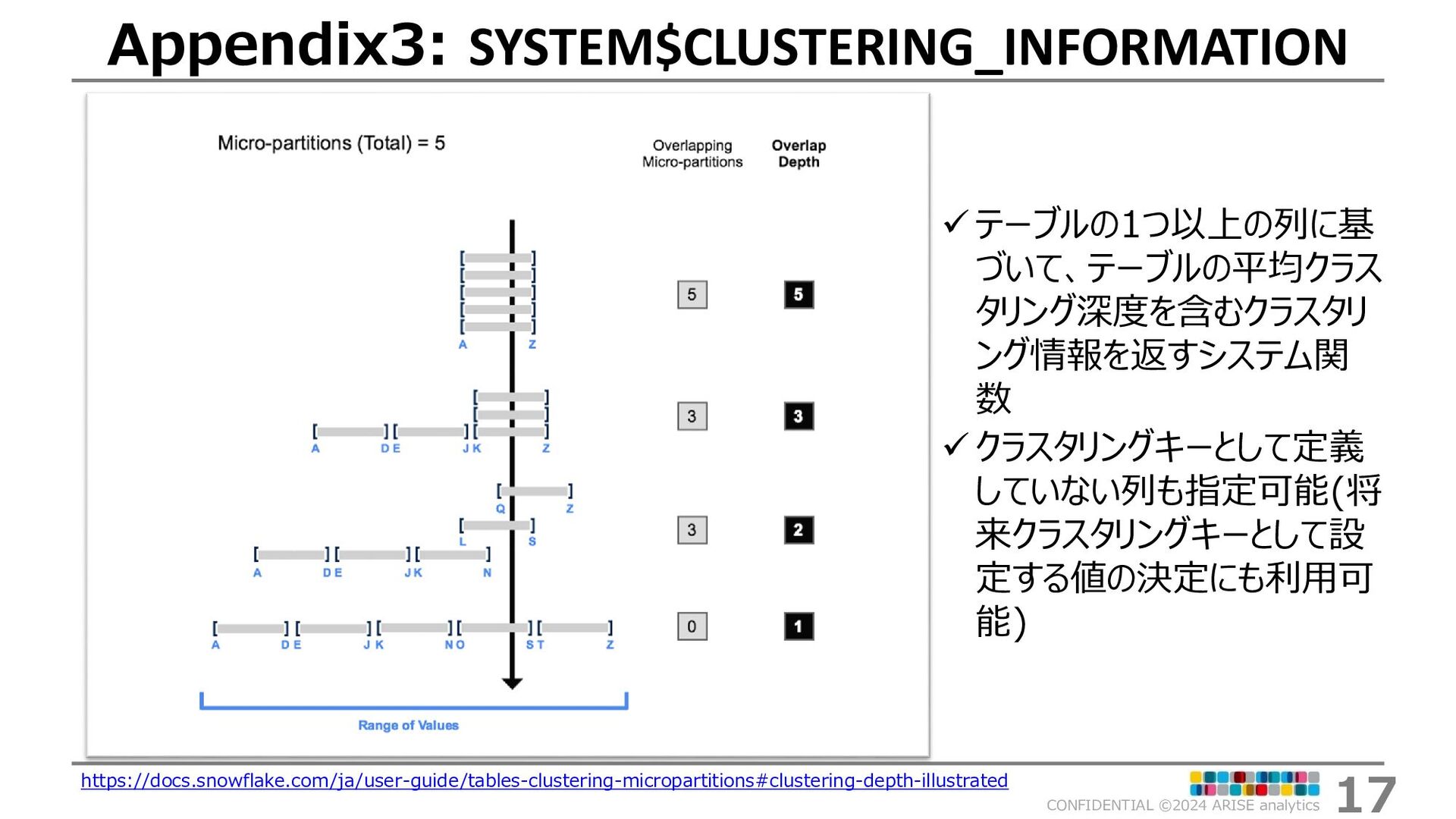{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}