Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データの"守り"を固めた2022
Search
Takuma Kouno
December 14, 2022
Technology
1.9k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データの"守り"を固めた2022
2022/12/14のData Engineering Studyの発表資料
Takuma Kouno
December 14, 2022
More Decks by Takuma Kouno
See All by Takuma Kouno
株式会社アイスタイル_Data_Engineering_Summit_全社のデータ活用レベルを上げる__AI-readyな組織を目指す_データ民主化プロジェクト_の裏側.pdf
takumakouno
0
1.2k
Data Reliabilityを 最小工数で実現するための データ基盤
takumakouno
0
150
位置情報データをコスト最適化しつつ 分析に活かすための データ管理と運用方法について
takumakouno
0
80
データ活用促進のためのデータ分析基盤の進化
takumakouno
2
3.3k
Other Decks in Technology
See All in Technology
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
450
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
DatabricksにおけるMCPソリューション
taka_aki
1
270
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
550
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
760
Network Firewallやっていき!
news_it_enj
0
160
Kaggleで成長するために意識したこと
prgckwb
2
410
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
250
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
260
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
310
Featured
See All Featured
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Code Reviewing Like a Champion
maltzj
528
40k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
The SEO identity crisis: Don't let AI make you average
varn
0
510
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Building Adaptive Systems
keathley
44
3.1k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
720
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Transcript
データの”守り”を固めた2022 2022.12.14 株式会社Luup 河野匠真 Data Engineering Study #17
発表者 • 河野 匠真(@makako1124) • 株式会社Luup / Data Strategy部 Data
Engineering Team • 主にデータ基盤の構築から運用、整備を行う
Luupとは 電動キックボードや電動アシスト自転車をはじめとする、電動・小型・一人乗りのマイクロモビリティを、iOS/Android アプリから解錠・ 施錠を行って自由に乗車することのできるシェアリングサービス ポート数 車両数 5,000台以上 2,430以上 展開エリア:東京、大阪、京都、横浜など (2022年11月末時点)
1. Luupのデータとデータ基盤 2. 課題 a. Rawデータはそのまま使えない b. データがどこにあるかわからない 3. 結果
4. 今後実施したいこと 5. まとめ 6. 最後に Agenda
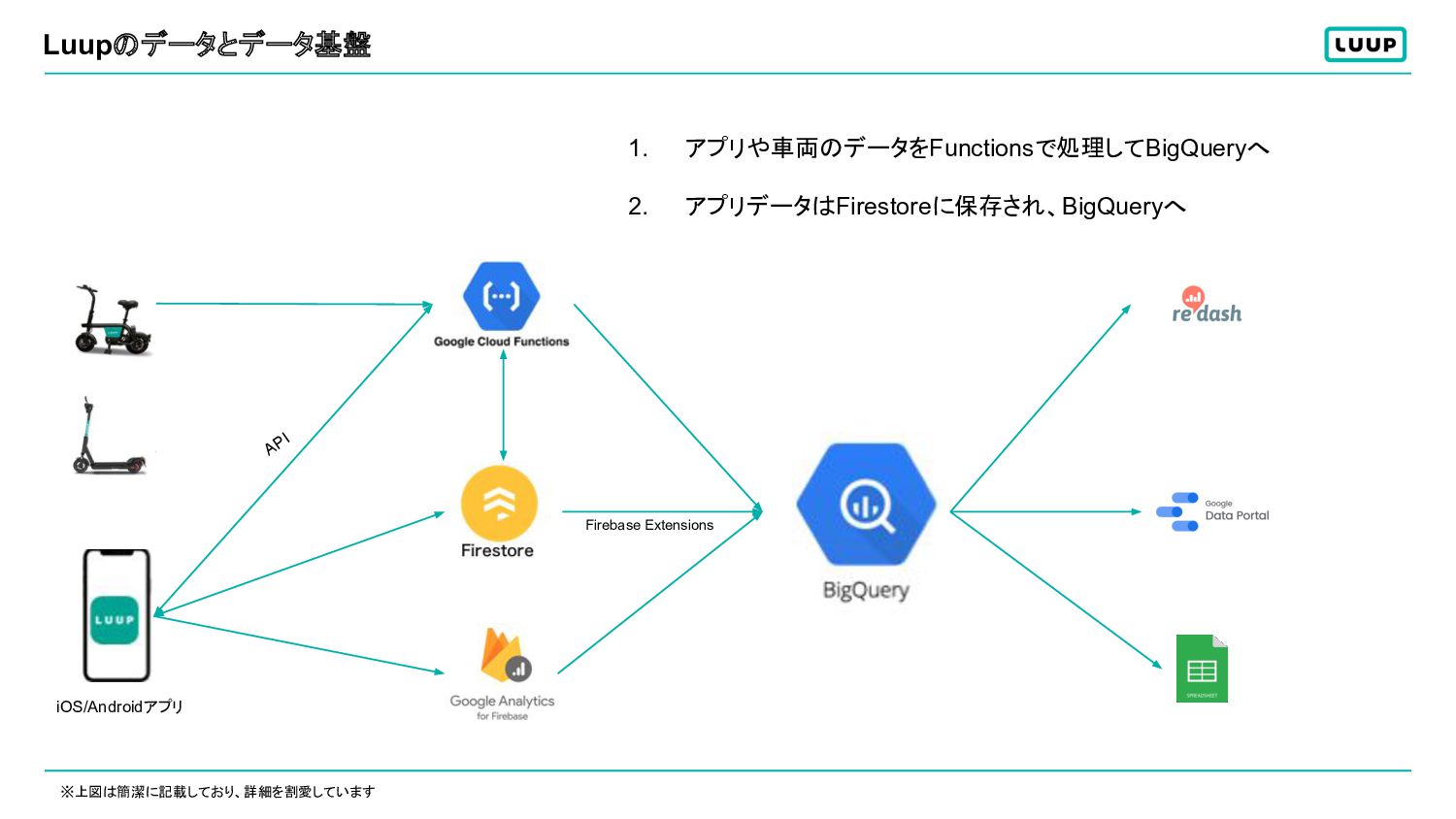
Luupのデータとデータ基盤 API Firebase Extensions 1. アプリや車両のデータをFunctionsで処理してBigQueryへ 2. アプリデータはFirestoreに保存され、BigQueryへ ※上図は簡潔に記載しており、詳細を割愛しています iOS/Androidアプリ
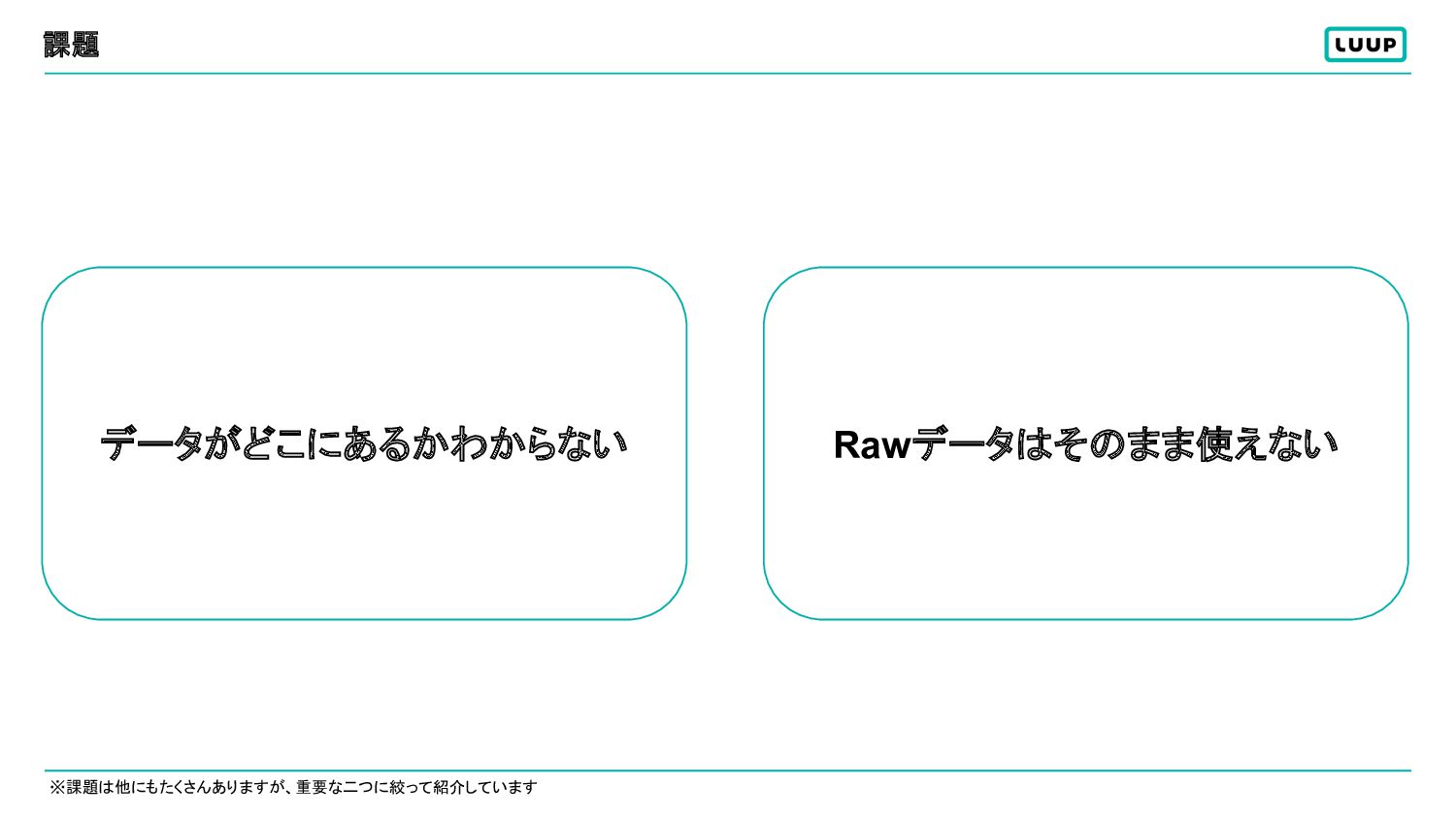
課題 Rawデータはそのまま使えない データがどこにあるかわからない ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています
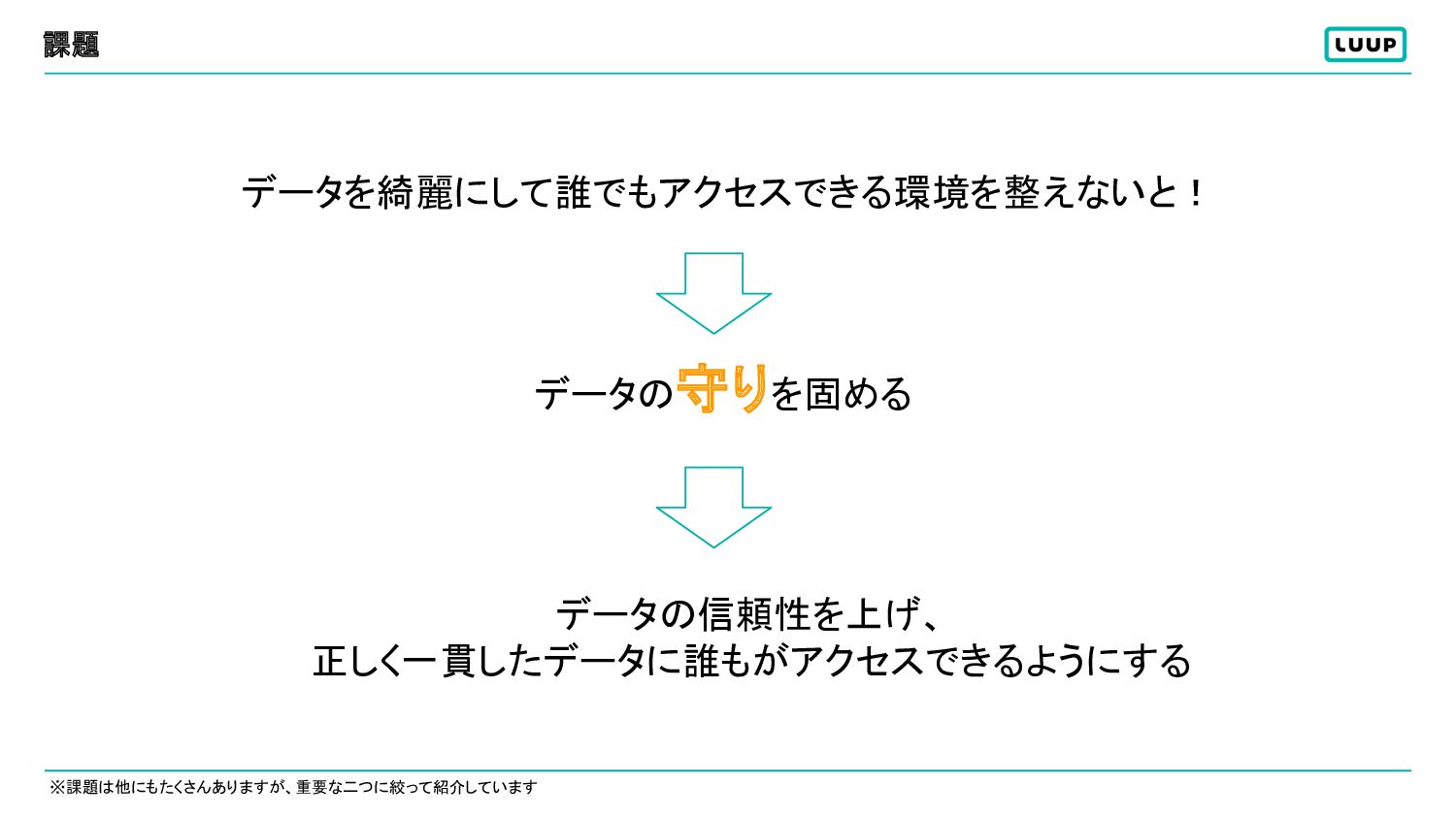
課題 ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています データを綺麗にして誰でもアクセスできる環境を整えないと! データの守りを固める データの信頼性を上げ、 正しく一貫したデータに誰もがアクセスできるようにする
課題 Rawデータはそのまま使えない データがどこにあるかわからない ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています
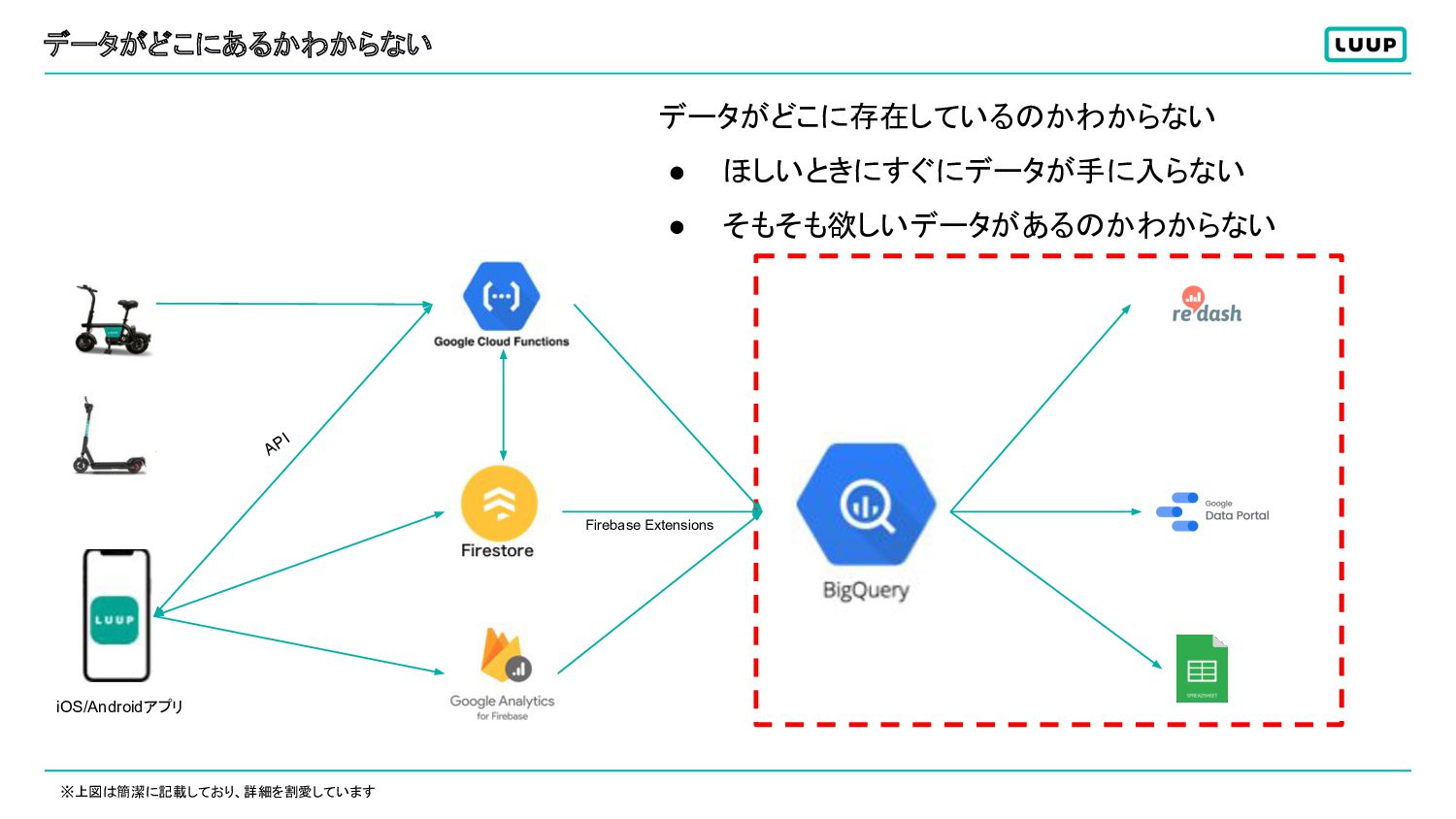
データがどこにあるかわからない データがどこに存在しているのかわからない • ほしいときにすぐにデータが手に入らない • そもそも欲しいデータがあるのかわからない ※上図は簡潔に記載しており、詳細を割愛しています API Firebase Extensions
iOS/Androidアプリ
データがどこにあるかわからない ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています データカタログを用意 → データがどこにあり、誰が作成し、いつどれくらいの頻度で更新されるのか等の情報が誰で も確認できる → NotionのDatabaseを採用 (APIで毎日自動生成される仕組みに )
課題 Rawデータはそのまま使えない データがどこにあるかわからない ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています
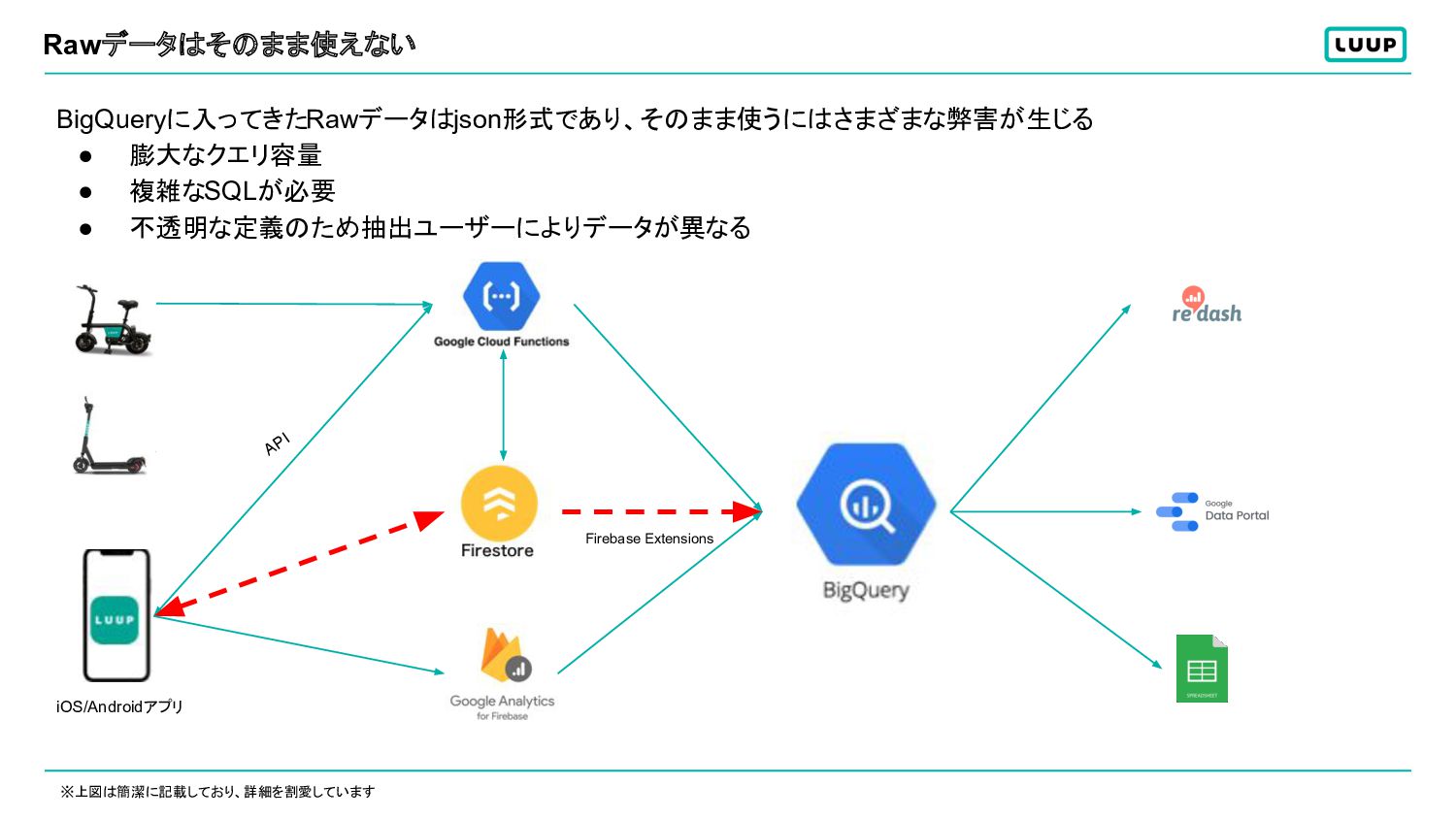
Rawデータはそのまま使えない BigQueryに入ってきたRawデータはjson形式であり、そのまま使うにはさまざまな弊害が生じる • 膨大なクエリ容量 • 複雑なSQLが必要 • 不透明な定義のため抽出ユーザーによりデータが異なる ※上図は簡潔に記載しており、詳細を割愛しています API
Firebase Extensions iOS/Androidアプリ
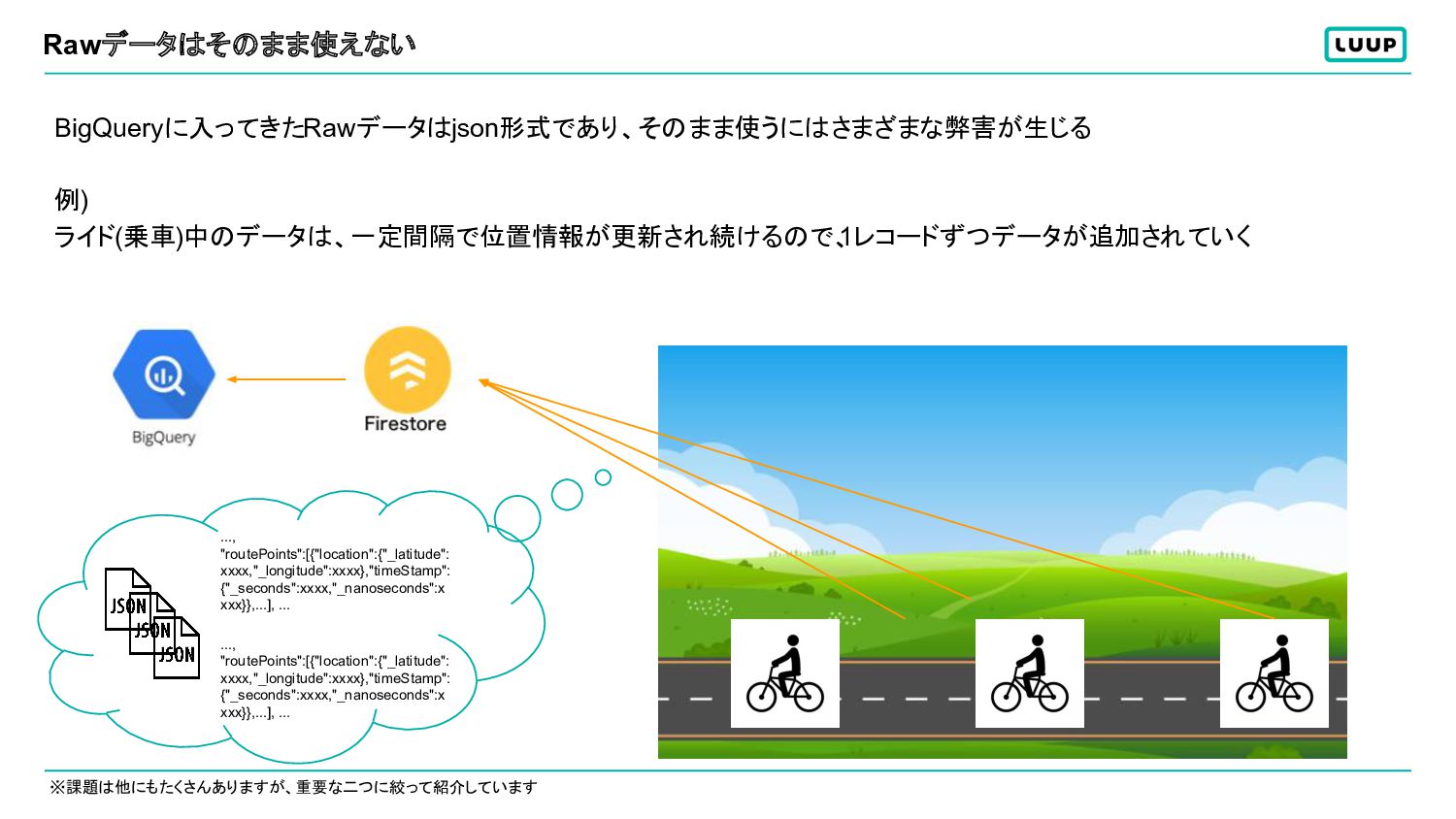
Rawデータはそのまま使えない BigQueryに入ってきたRawデータはjson形式であり、そのまま使うにはさまざまな弊害が生じる 例) ライド(乗車)中のデータは、一定間隔で位置情報が更新され続けるので、 1レコードずつデータが追加されていく ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています ..., "routePoints":[{"location":{"_latitude": xxxx,"_longitude":xxxx},"timeStamp": {"_seconds":xxxx,"_nanoseconds":x
xxx}},...], ... ..., "routePoints":[{"location":{"_latitude": xxxx,"_longitude":xxxx},"timeStamp": {"_seconds":xxxx,"_nanoseconds":x xxx}},...], ...
Rawデータはそのまま使えない ※課題は他にもたくさんありますが、重要な二つに絞って紹介しています 1. ワークフローツール(Cloud Composer)の導入 → 安定したデータ処理環境を構築 2. 定義毎にデータ処理層を用意 →
クエリ容量の削減、データの整合性担保 3. 各種Datamartテーブルを用意 → 容易なSQLでデータ取得が可能
結果 • ダッシュボード毎にデータが異なるといったデータ不整合を防げるようになった。 • 一日に使用するクエリ容量が約半分までに減少した。 • 容易なSQLでデータが抽出できるようになった。 • どういうデータが存在するのか誰でも気軽に確認できるようになった。 構築完了したのが直近のため、結果はこれからさらにでてくると想定
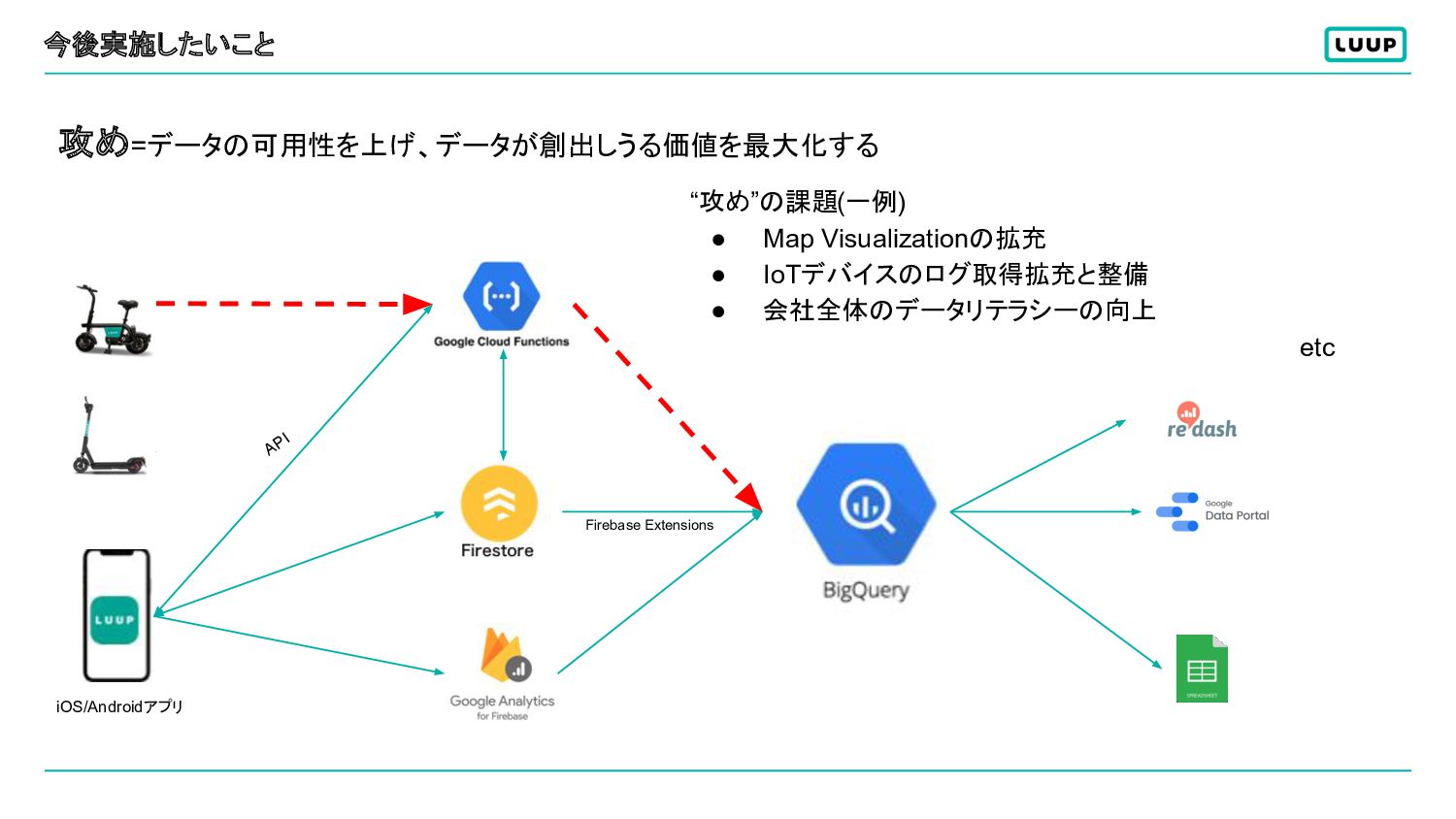
今後実施したいこと 攻め=データの可用性を上げ、データが創出しうる価値を最大化する “攻め”の課題(一例) • Map Visualizationの拡充 • IoTデバイスのログ取得拡充と整備 • 会社全体のデータリテラシーの向上
etc API Firebase Extensions iOS/Androidアプリ
まとめ さまざまなツールを検証・導入し、最適なデータフローを考え実装した、 データの”守り”(=データの信頼性を上げ、正しく一貫したデータに誰もが アクセスできるようにする)を徹底した年
最後に Luup Developers Blogにてアドベントカレンダー実施中! データカタログにNotionを選択した理由についても掲載中! Luupでのデータ基盤構築、データ活用に少しでもご興味がある 方、ご連絡お待ちしております。 Luup採用情報
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}