Ulrich (2017). 22章 カスケード障害への対応(). In B. Beyer, C. Jones, J. Petoff, & N. R. Murphy (編),SRE サイトリライアビリ ティエンジニアリング ― Googleの信頼性を⽀えるエンジニアリングチーム (澤⽥ 武男ほか訳). オライリー‧ジャパン. • 1つのコンポーネントの障害が他のコンポーネントに連鎖的に波及する障害 • よくマイクロサービス⽂脈で語られるが、複数のコンポーネントが組み合わさればモノリスなシ ステムでも起こりうる • 最初は⼩さな問題でも、連鎖的に⼤規模な障害につながる
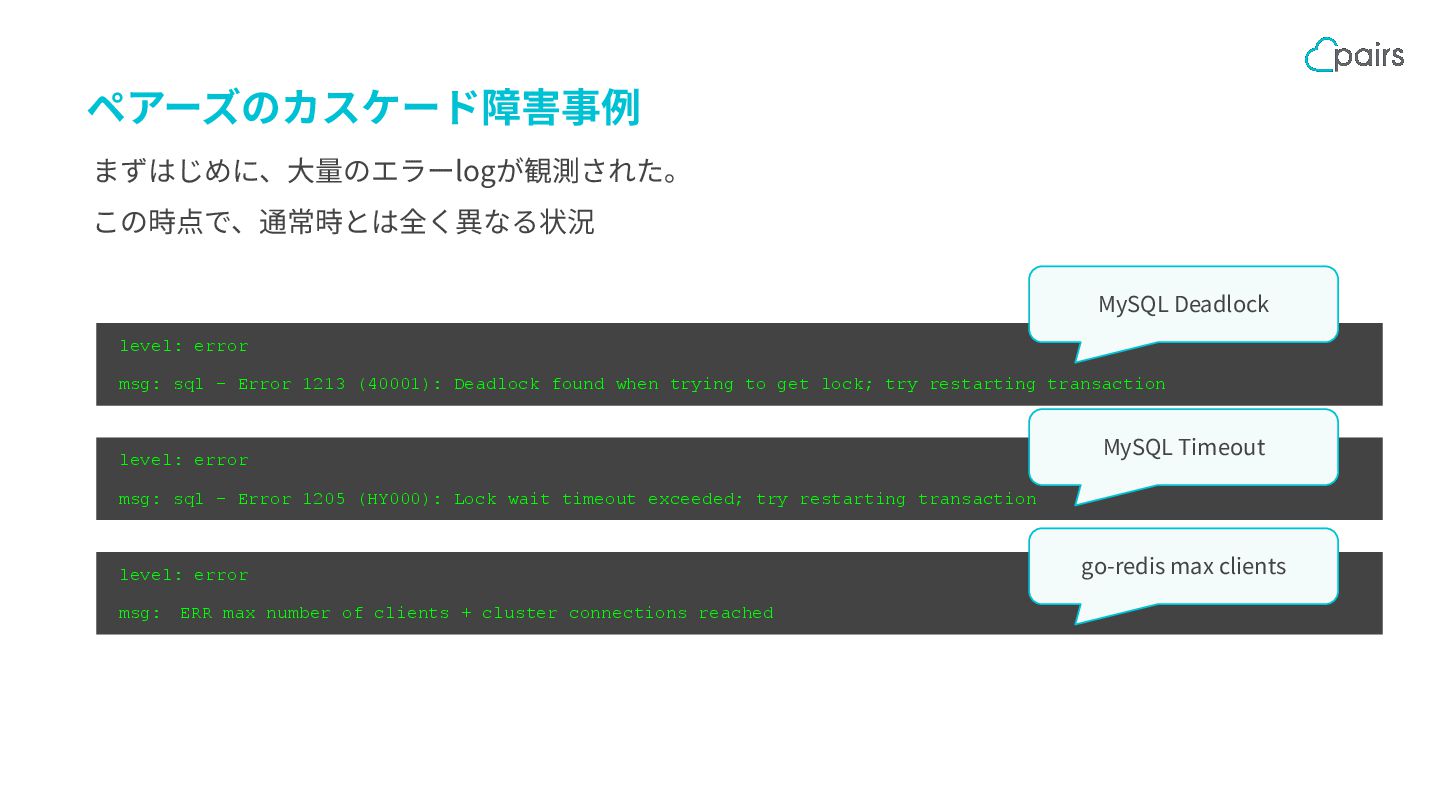
(40001): Deadlock found when trying to get lock; try restarting transaction level: error msg: sql - Error 1205 (HY000): Lock wait timeout exceeded; try restarting transaction level: error msg: ERR max number of clients + cluster connections reached MySQL Deadlock MySQL Timeout go-redis max clients
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
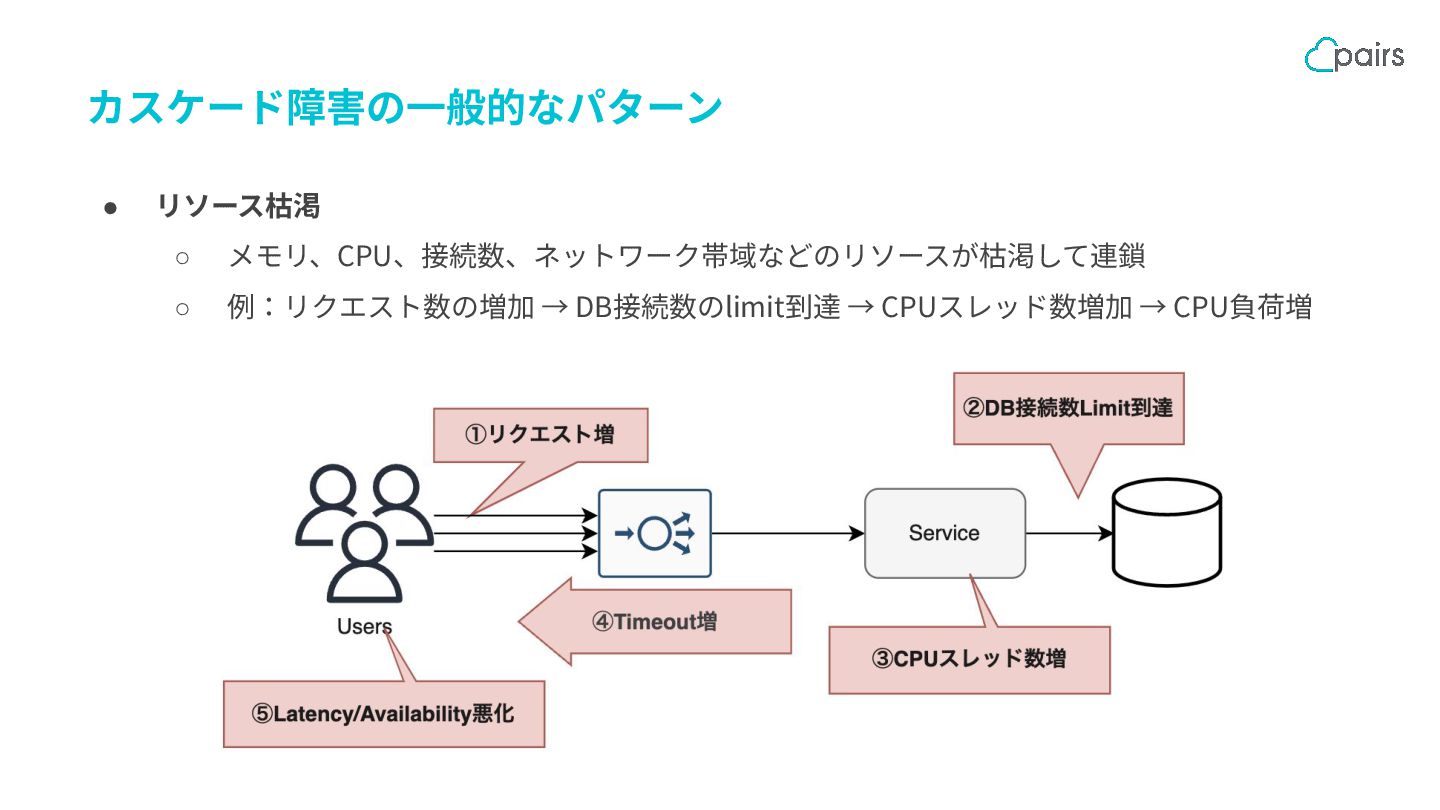{kind=link}
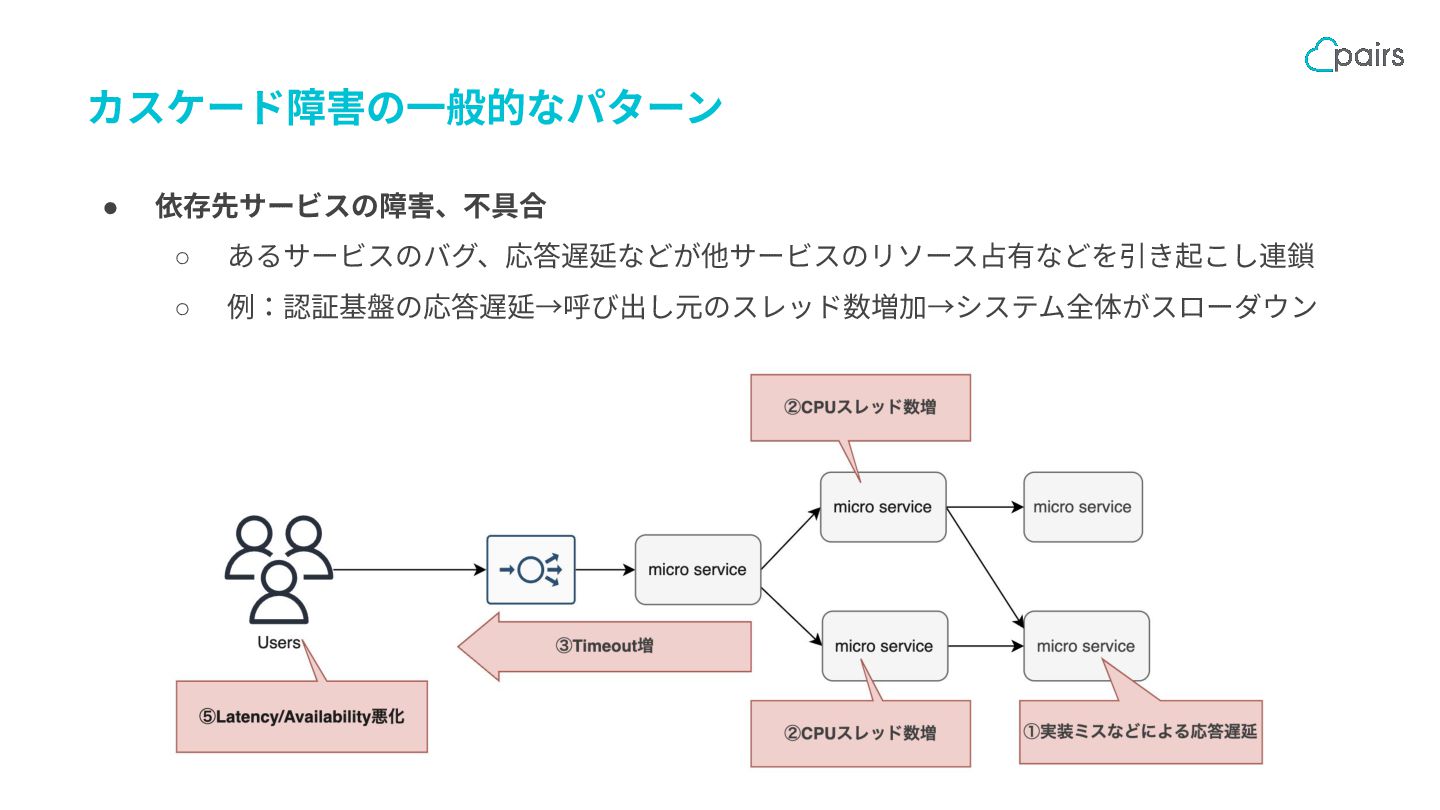{kind=link}
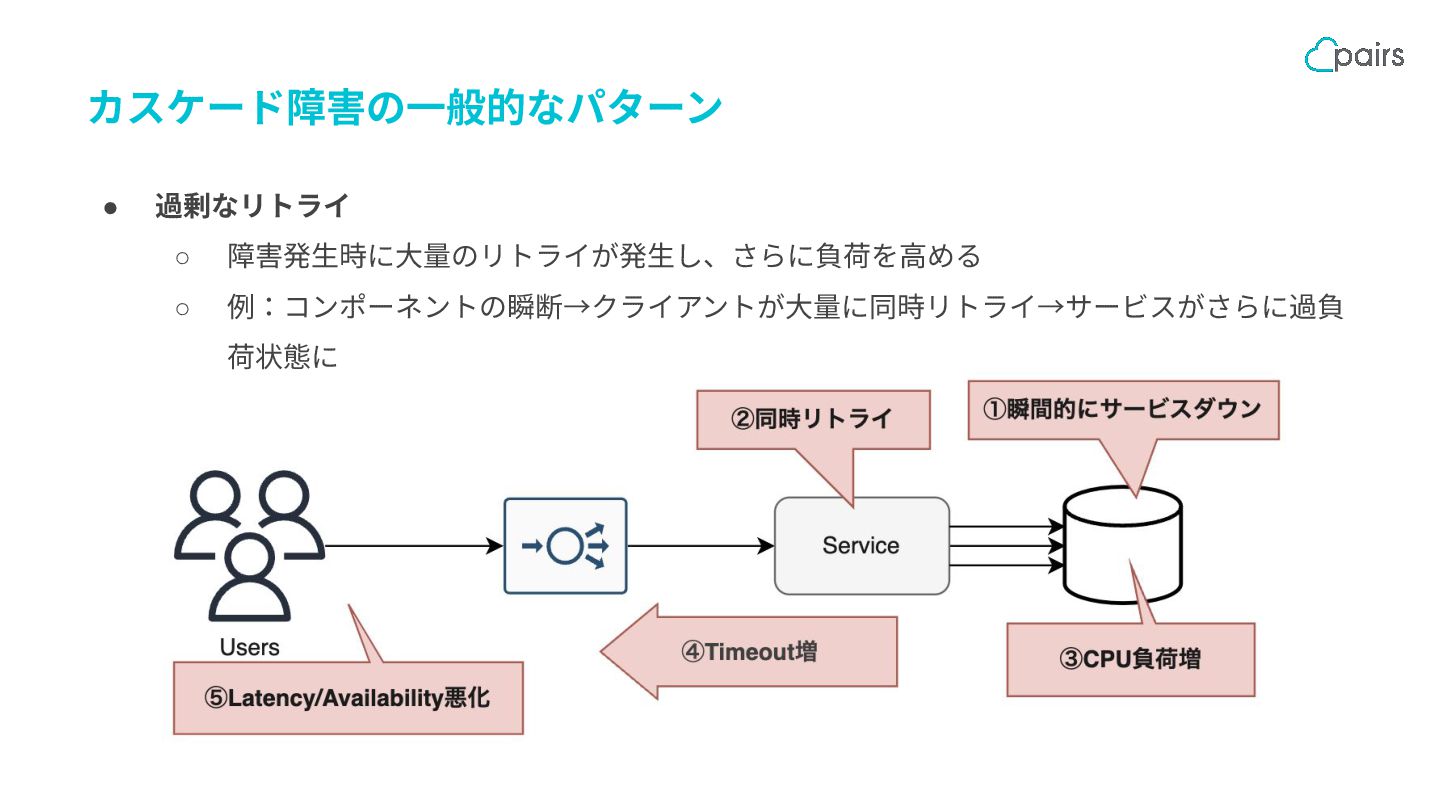{kind=link}
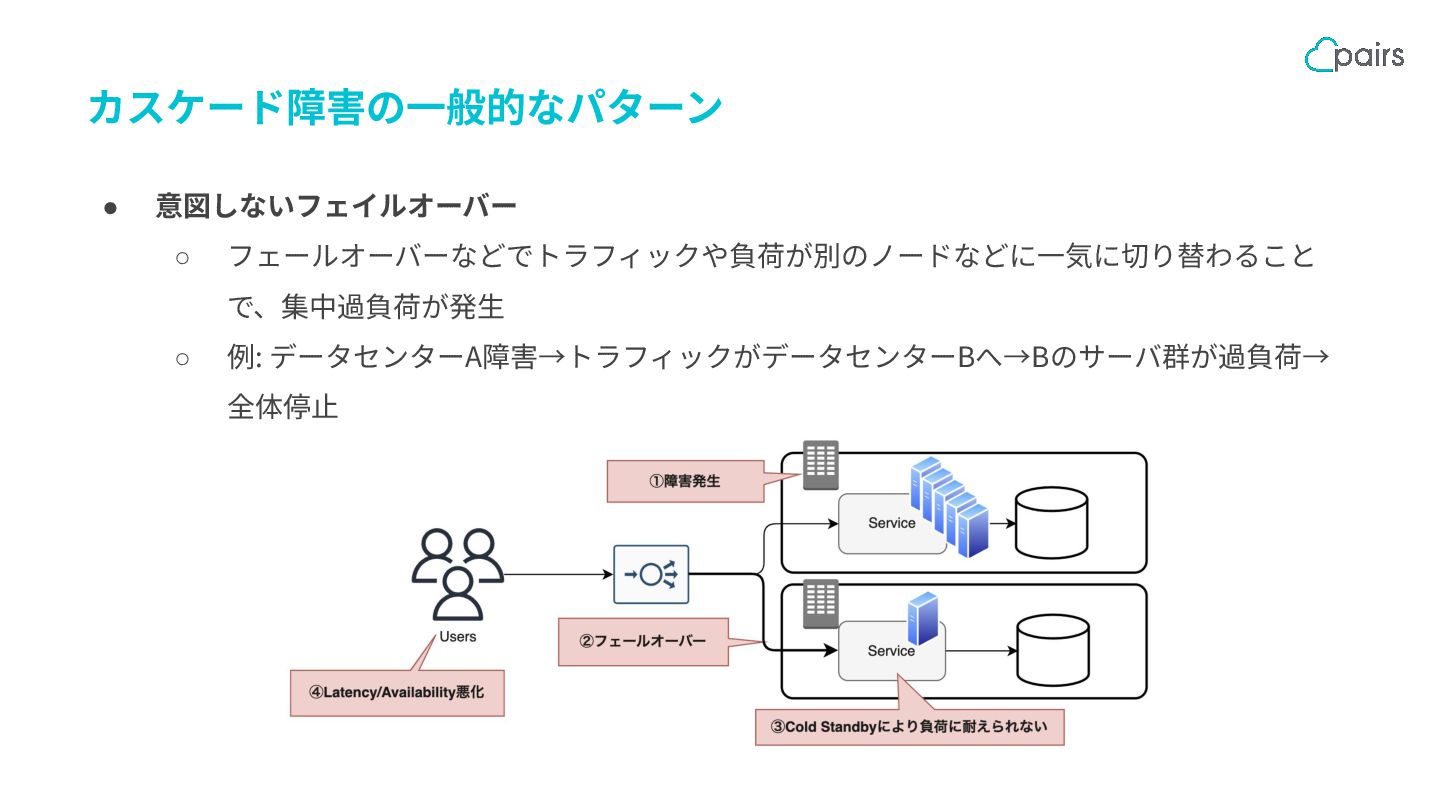{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
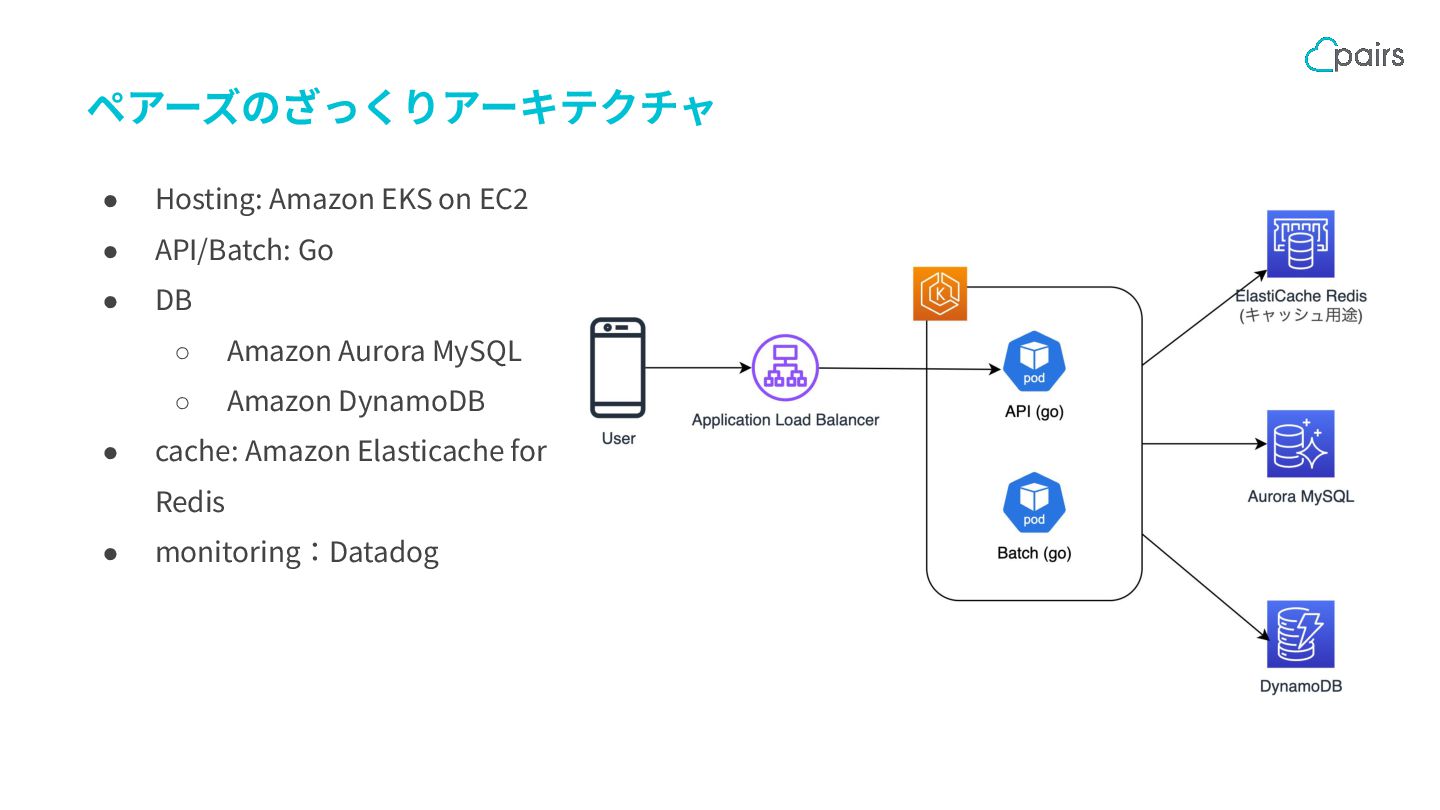{kind=link}
{kind=link}
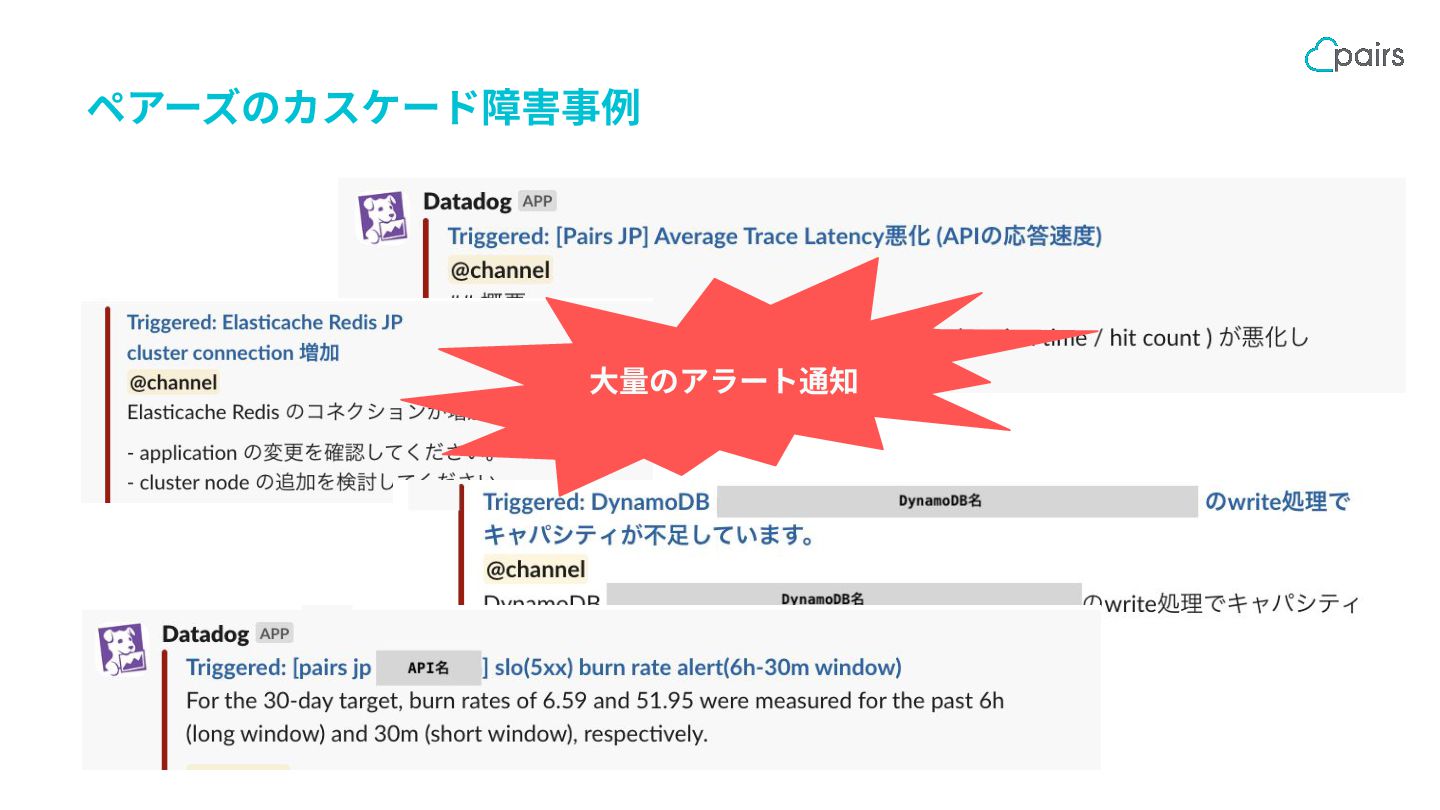{kind=link}
{kind=link}
{kind=link}
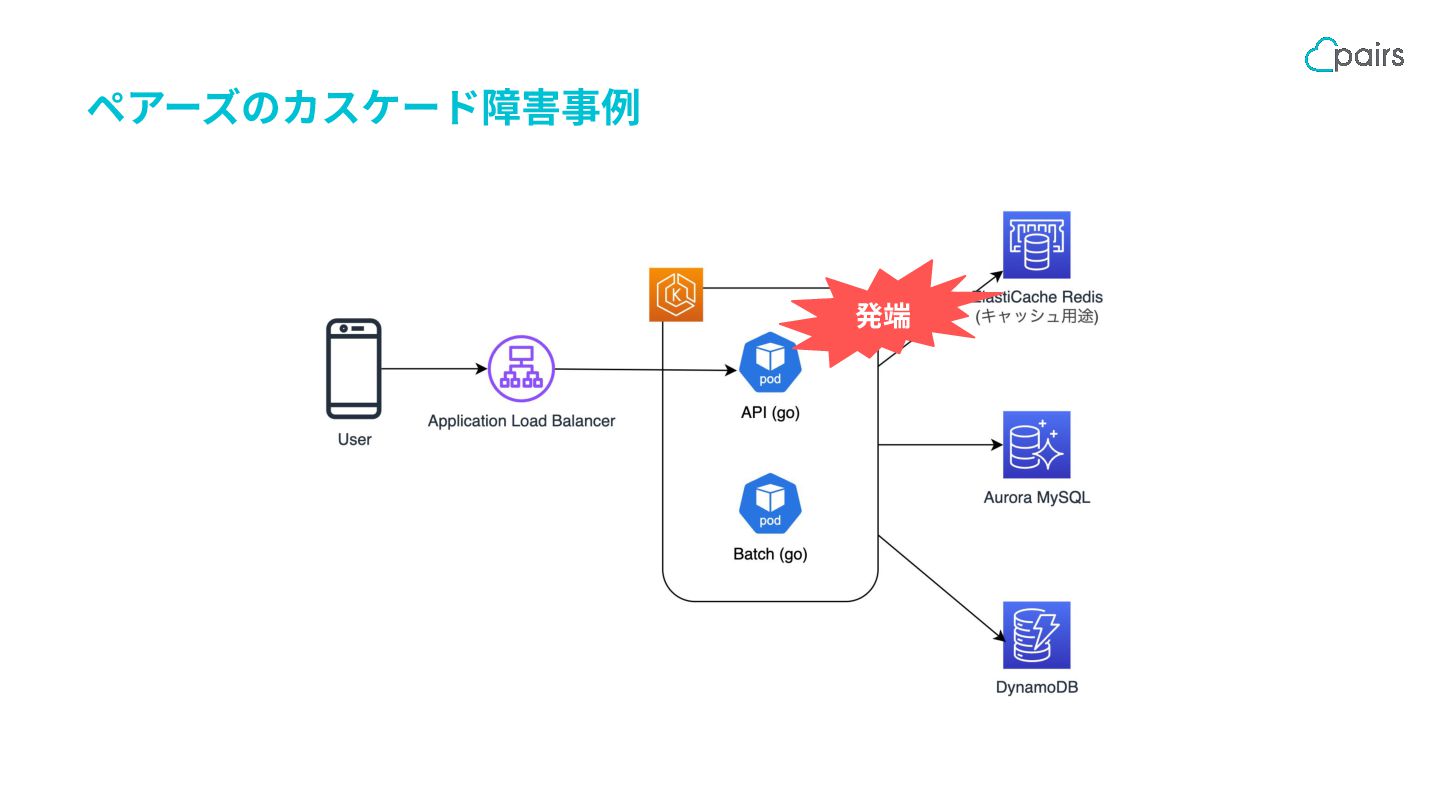{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}