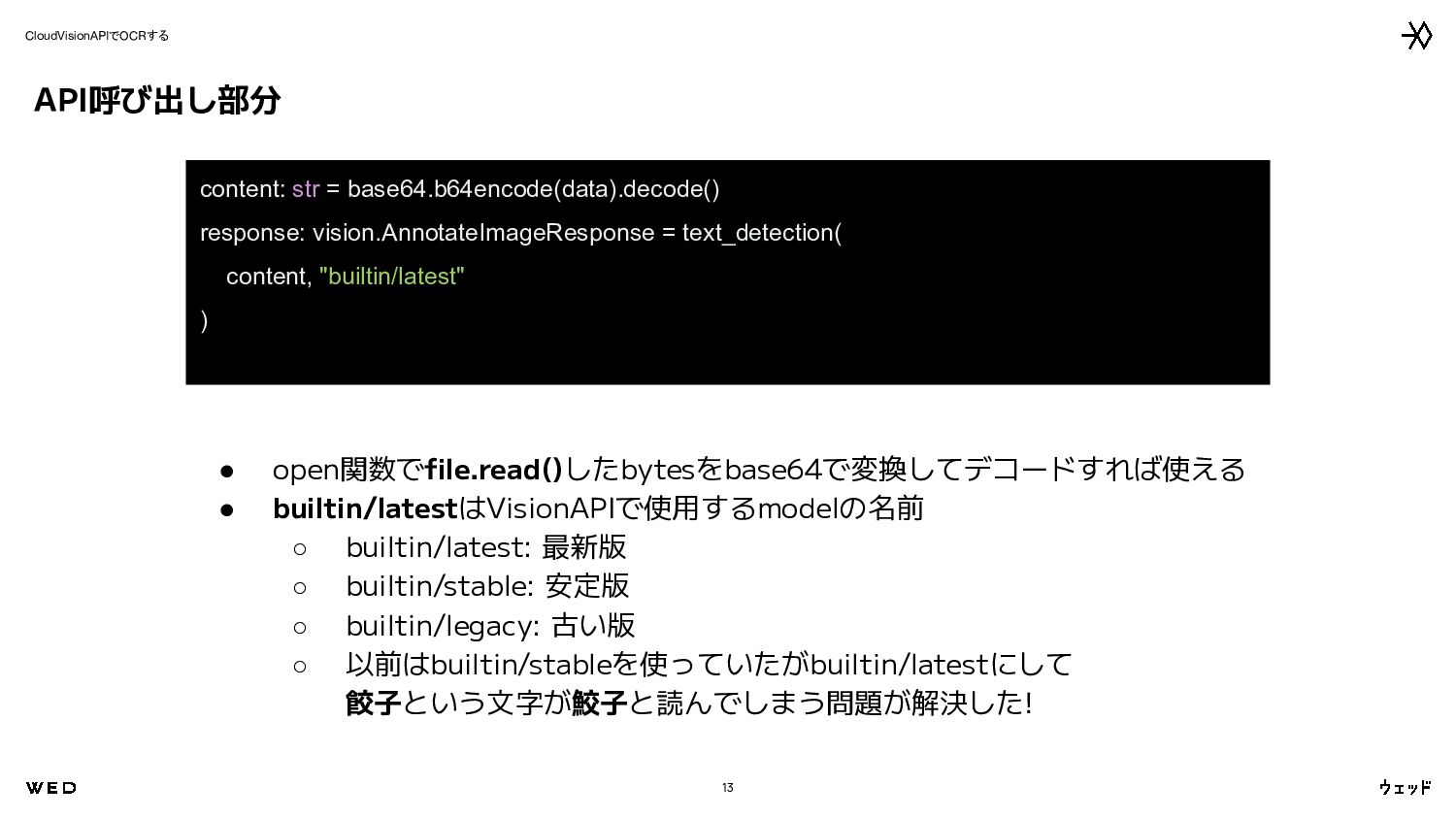
str, vision_api_model: str ) -> vision.AnnotateImageResponse: image = vision.Image(content=content) client = vision.ImageAnnotatorClient(credentials=env.google_credentials) req = vision.AnnotateImageRequest( image=image, features=[ vision.Feature( type=vision.Feature.Type.TEXT_DETECTION, model=vision_api_model ), ], image_context={"language_hints": ["ja", "en"]}, ) response: vision.AnnotateImageResponse = client.annotate_image(req) return response
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
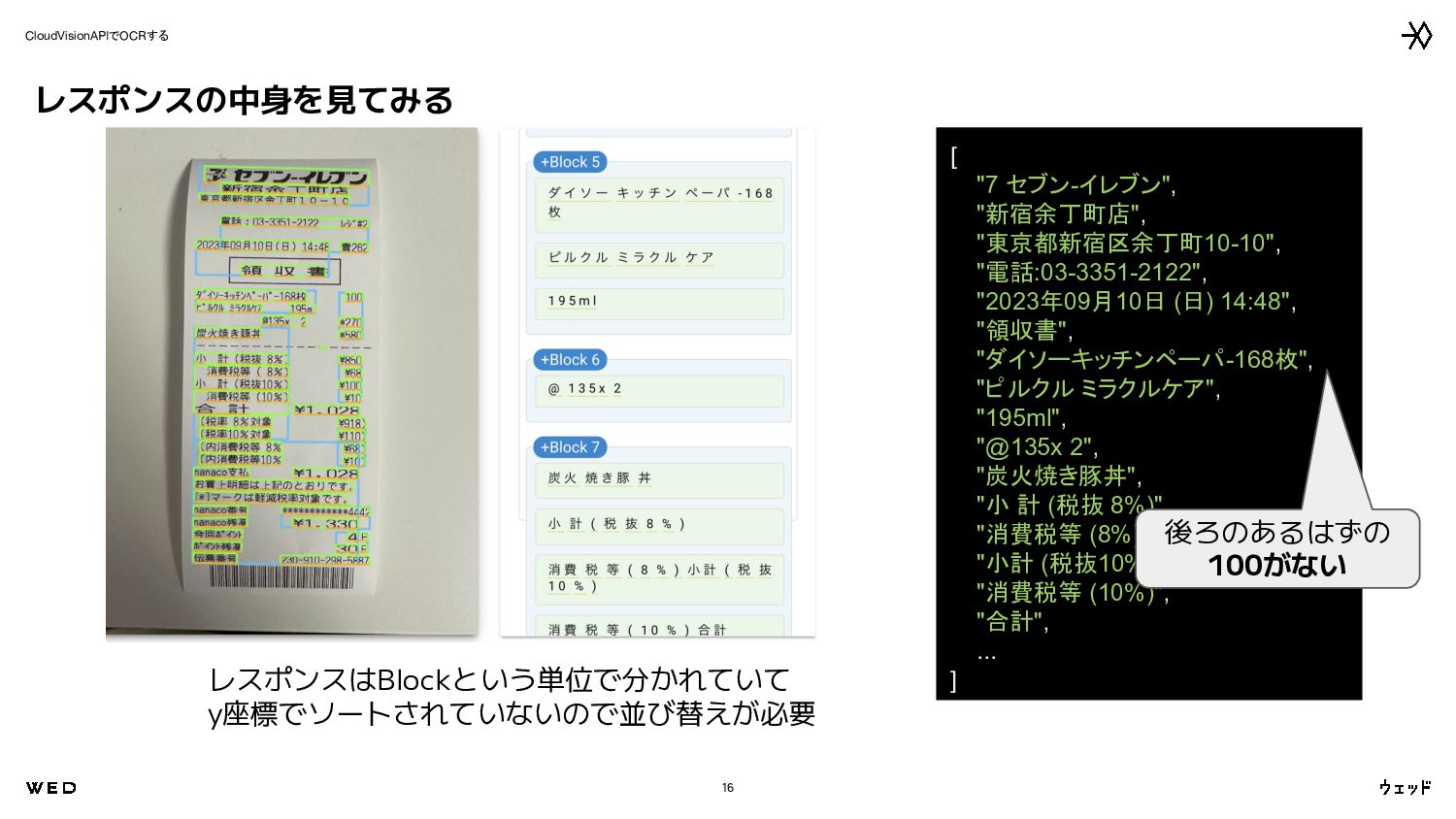
![CloudVisionAPIでOCRする 14 レスポンスの中身を見てみる • response.text_annotations[0]には全てのOCR結果が入っている • index1以降はOCR結果が分割されたものが入っている • 基本的にはresponse.text_annotations[1:]を使用していく raw_text,](https://files.speakerdeck.com/presentations/16bb8eaa9ce24332a8ae055bb960f2a5/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}