developer, designer, software architect - Worked on several KPN patents - Currently architect for VPC, SDN and the KPN API Store Meetup Organizer: - devNetNoord, a developer community (589 members) - domoticaGrunn, a home automation community (240 members) Spare time: (Open water) swimming, water polo, cycling [email protected]
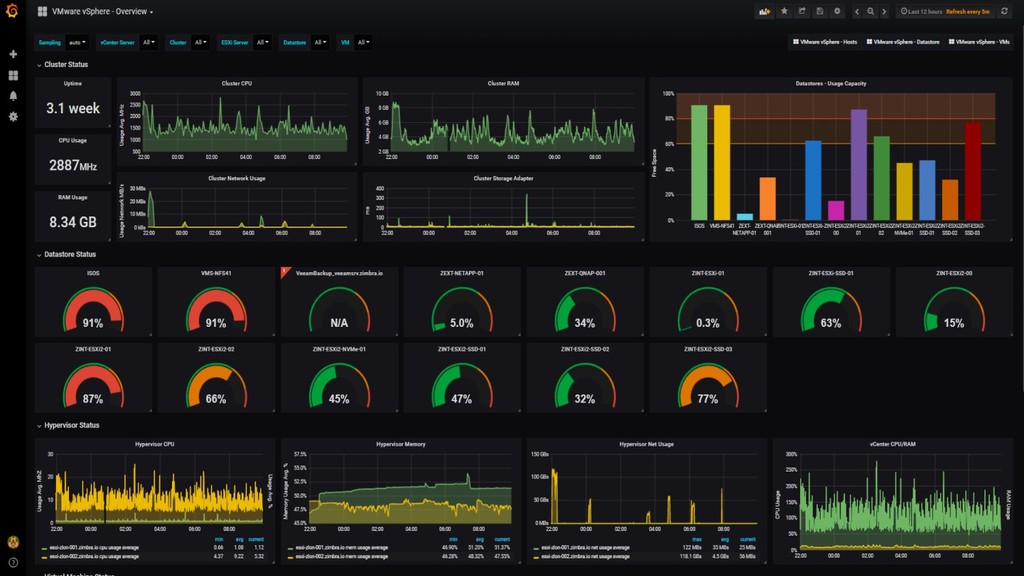
Level Indicator Service Levels the base of Site Reliability Engineering (SRE) Contract between customer and supplier Availability and reliability goals Probes measured over time
based Alerting: Your monitoring system should address two questions: what’s broken, and why? The “what’s broken” indicates the symptom; the “why” indicates a (possibly intermediate) cause. Monitoring
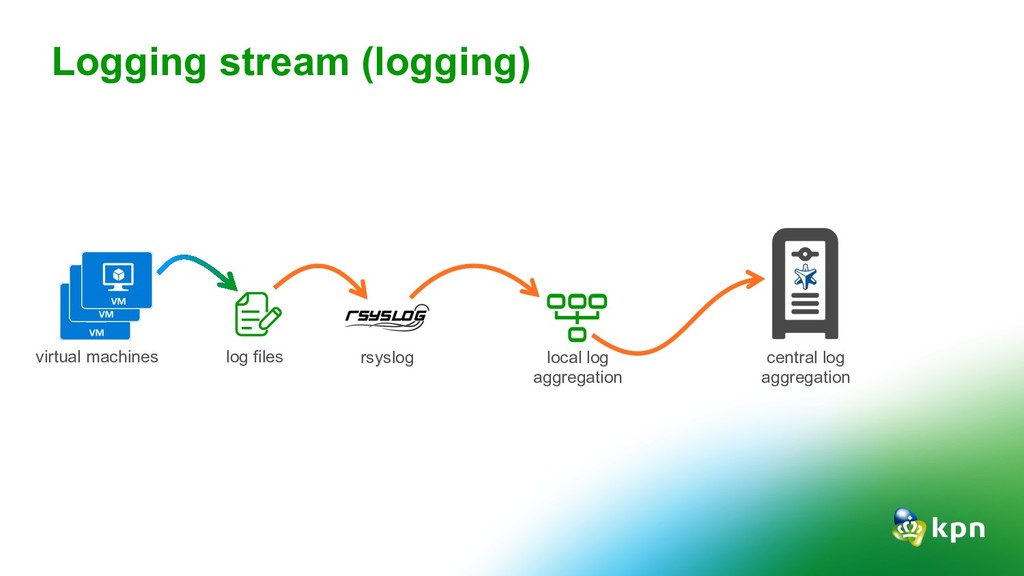
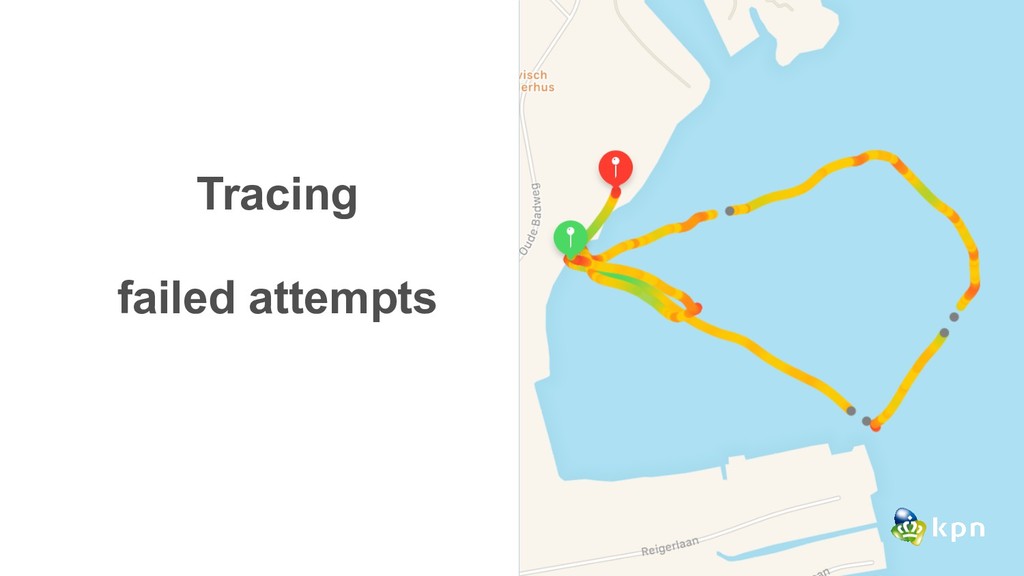
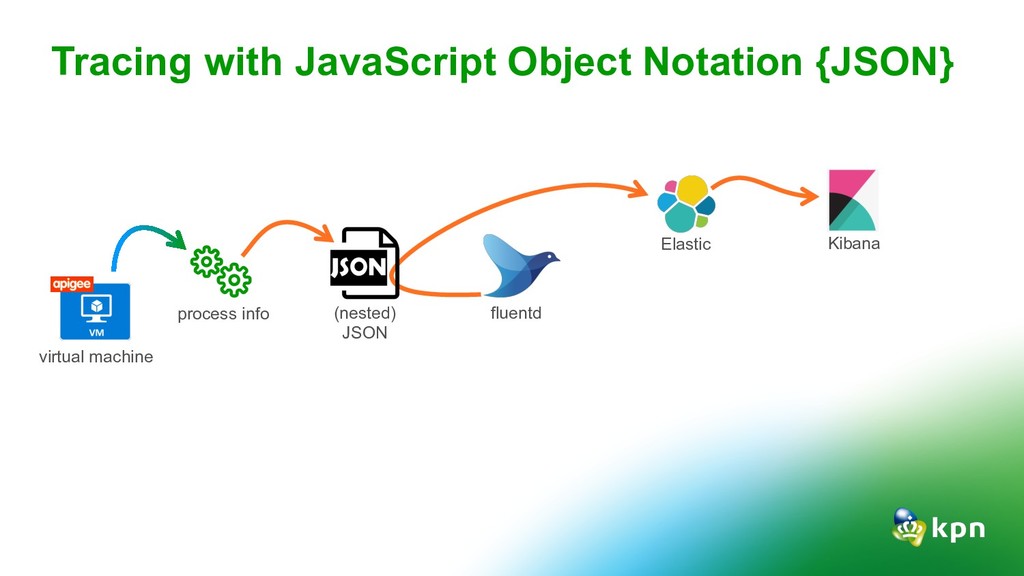
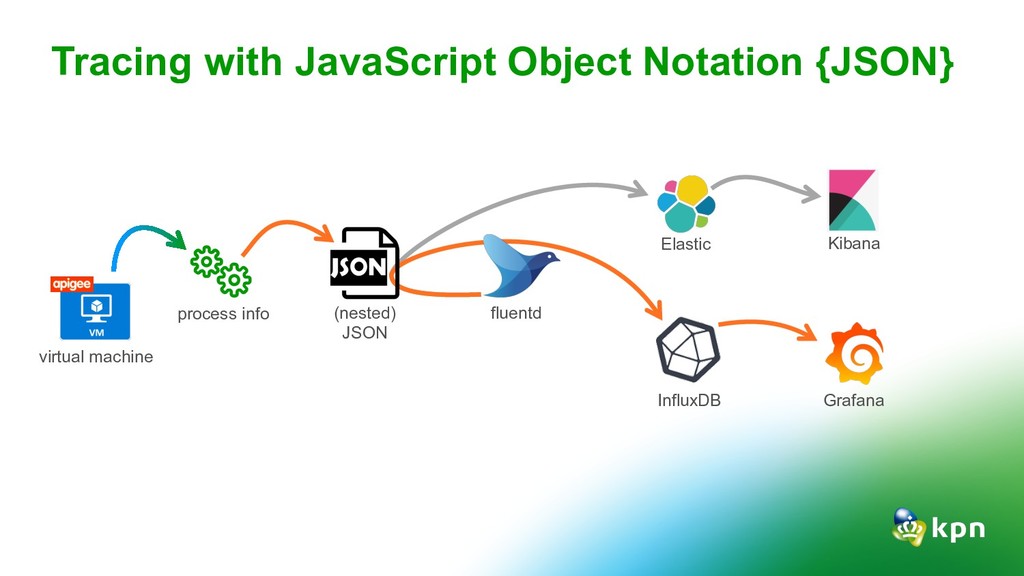
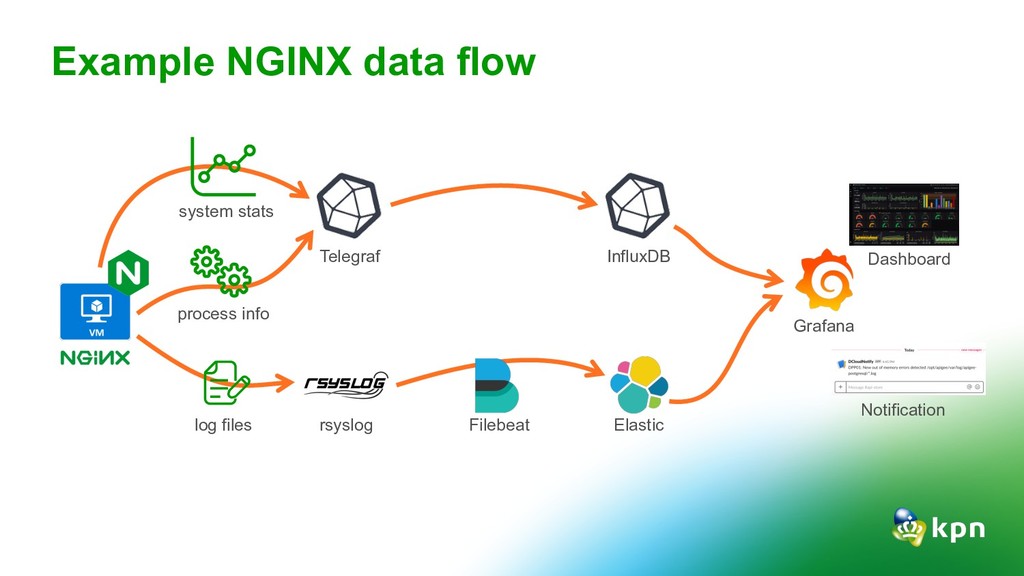
for security and auditing but also very useful for analytics and the team dashboard. Tracing: Tracing is hard. Keep it simple, understand TSDB and close the dev-ops gap Alerting: Slack is for none-critical alerting Critical alerting via SMS, Pager or Phone What did the 4 pillars teach us?
anti-pattern of monitoring everything. • Understand the social and financial implications. • From unknown-unknowns to known-unknowns and more questions Observability lessons
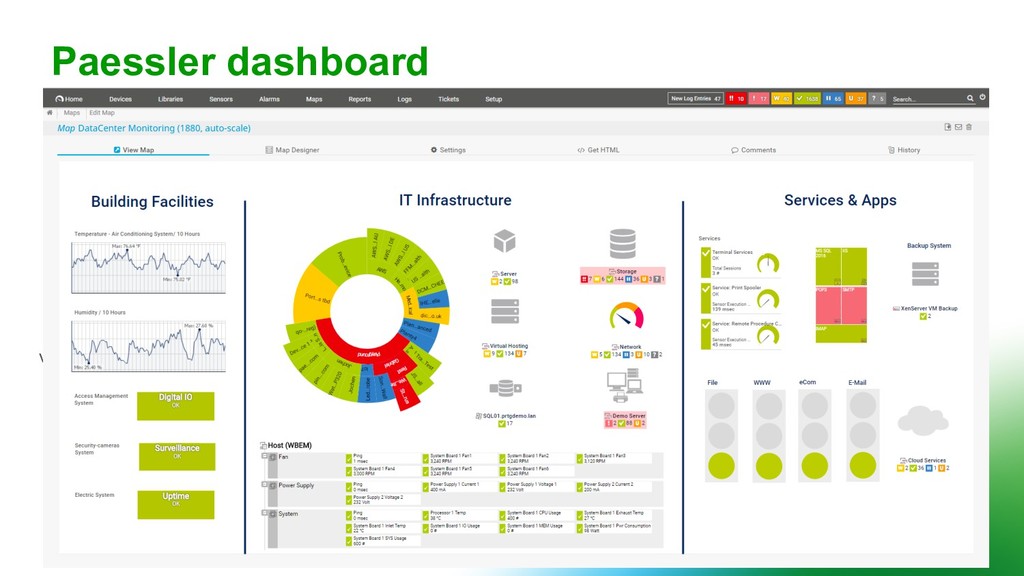
Systems Observability” Twitter: Observability at Twitter Part 1 & Part 2 Google: “SRE fundamentals: SLIs, SLAs and SLOs” Google: “SRE vs. DevOps: competing standards or close friends?“ Google: “Site Reliability Engineering” & “The Site Reliability Workbook” (free online books) Forrester: “How To Apply Google's Site Reliability Engineering Approach To Your Infrastructure” Digital Ocean: “An Introduction to Metrics, Monitoring, and Alerting” Honeycomb: “Observability: A Manifesto” InfoQ: “Three Pillars with Zero Answers: Rethinking Observability” Scalyr: “Observability?! – Where do we go from here?” Netflix Tech Blog: “Lessons from Building Observability Tools at Netflix“ OpenAPM: “OpenAPM Landscape” Paessler: “paessler.com” References:
{kind=link}
{kind=link}
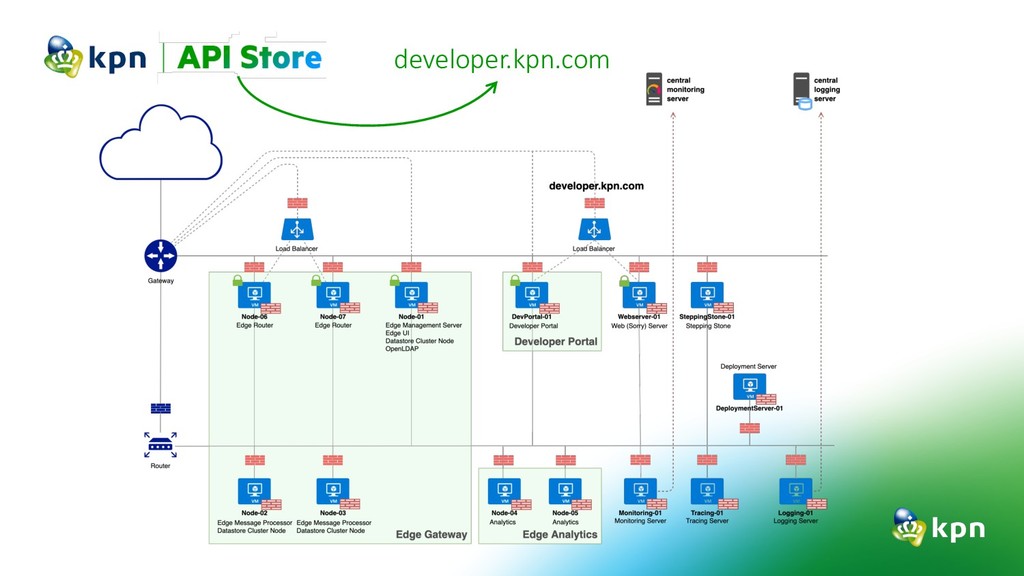{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
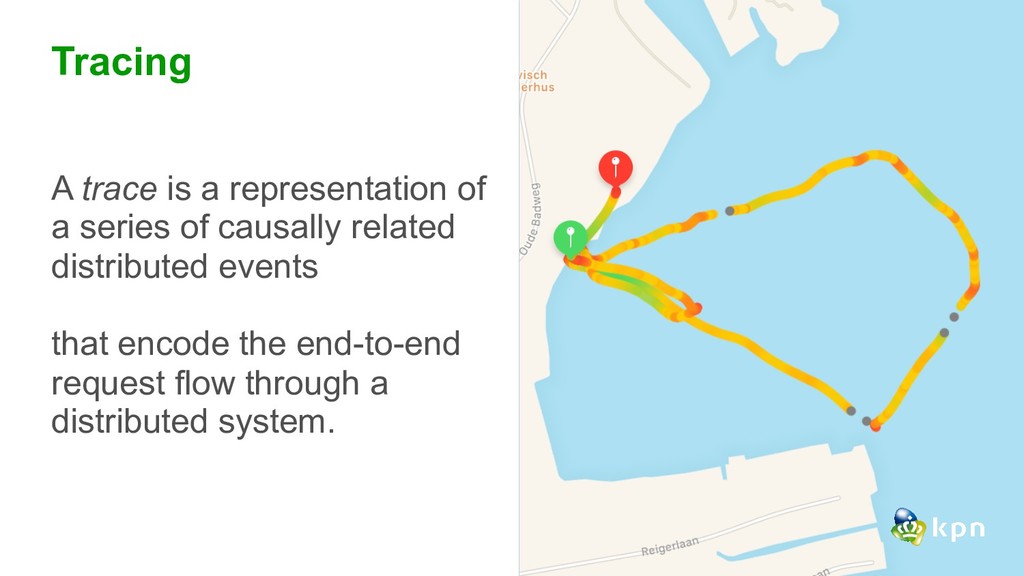{kind=link}
{kind=link}
{kind=link}
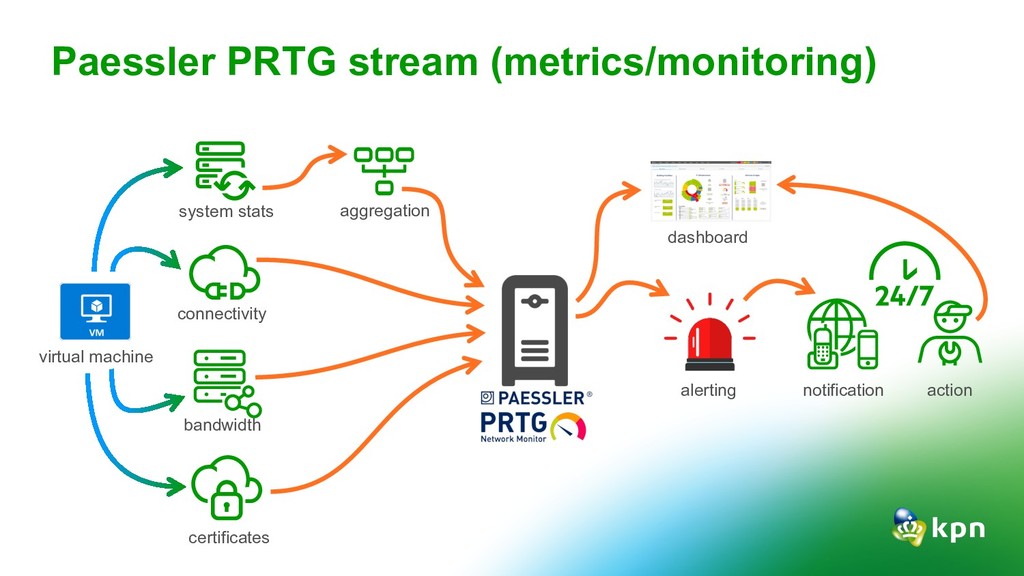{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}