タンパク質は1文字のアルファベットで表される20種類のアミノ酸が鎖状に並んだアミノ酸配列 で表現できる。 [Kovaltsuk+, 2017] How B-Cell Receptor Repertoire Sequencing Can Be Enriched with Structural Antibody Data 出典:[Kovaltsuk+, 2017]のFigure 1
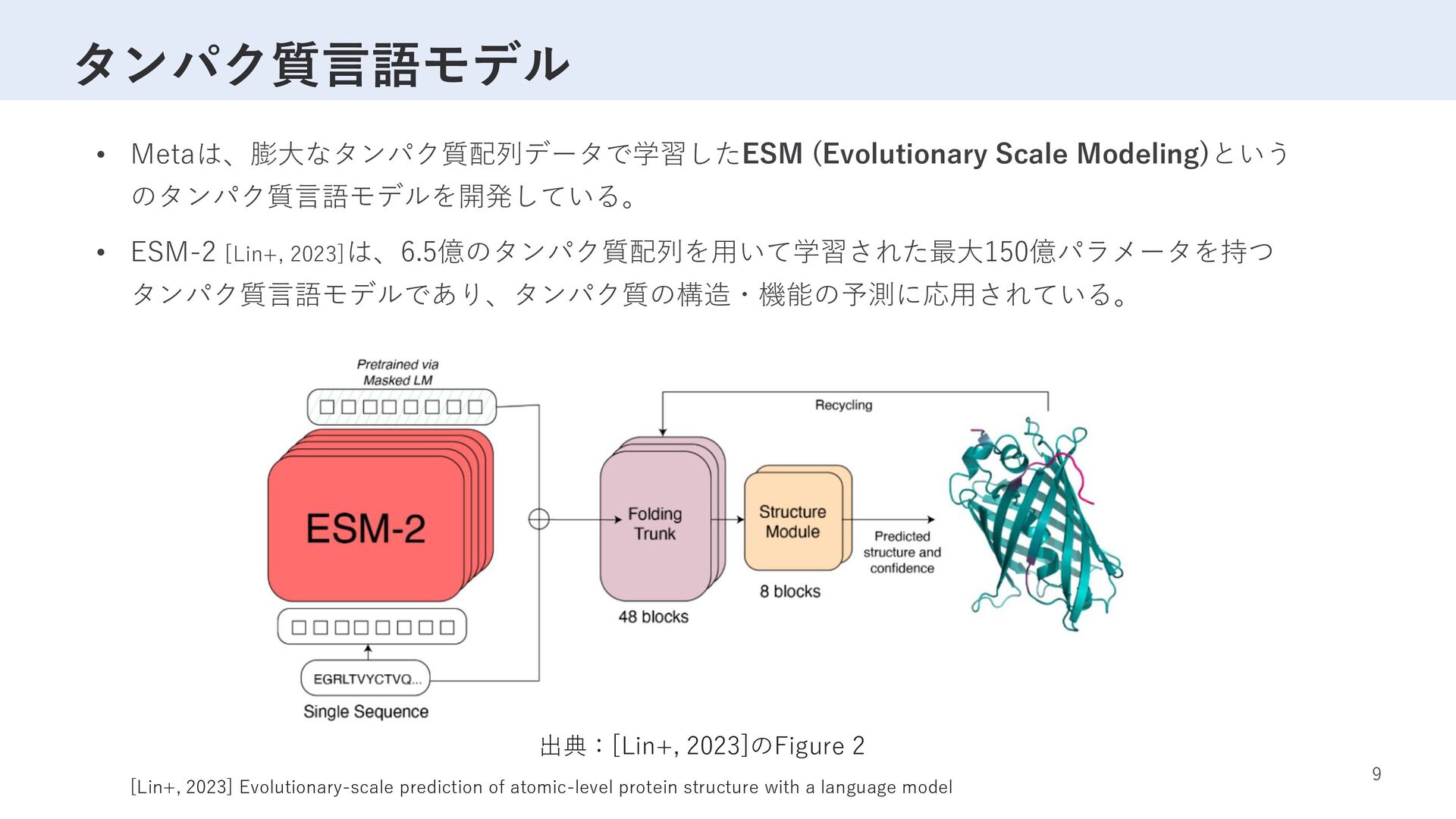
[Lin+, 2023]は、6.5億のタンパク質配列を用いて学習された最大150億パラメータを持つ タンパク質言語モデルであり、タンパク質の構造・機能の予測に応用されている。 出典:[Lin+, 2023]のFigure 2 [Lin+, 2023] Evolutionary-scale prediction of atomic-level protein structure with a language model
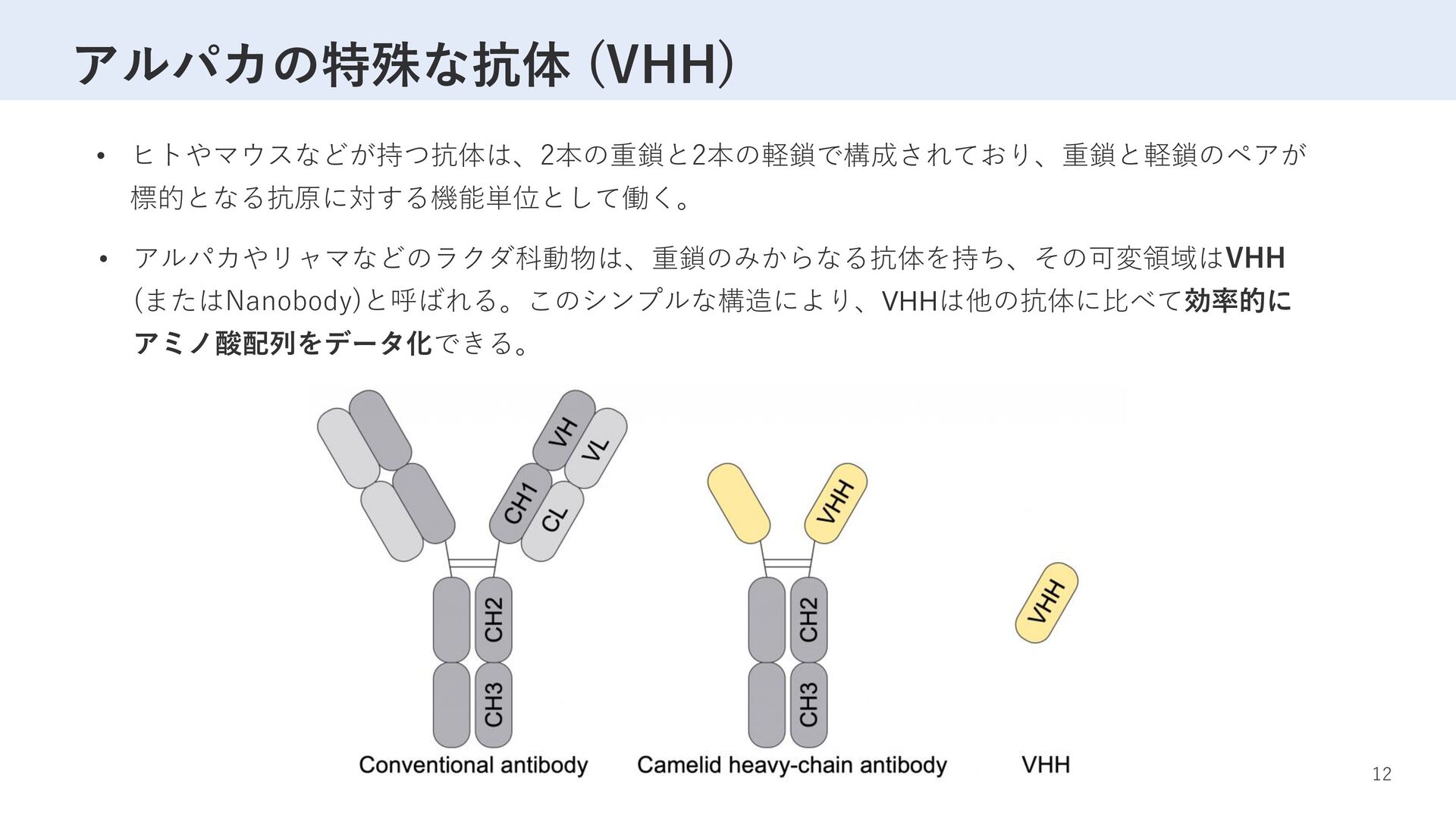
with language models and weakly supervised learning (2021). [2] Deciphering the language of antibodies using self-supervised learning (2022). [3] AbLang: an antibody language model for completing antibody sequences (2022). [4] On pre-training language model for antibody (2023). [5] Rapid discovery of high-affinity antibodies via massively parallel sequencing, ribosome display and affinity screening (2024). [6] Enhancing antibody language models with structural information (2023). [7] Large scale paired antibody language models (2024). [1] [2] [3] [4] [5] [6] [7] [3]
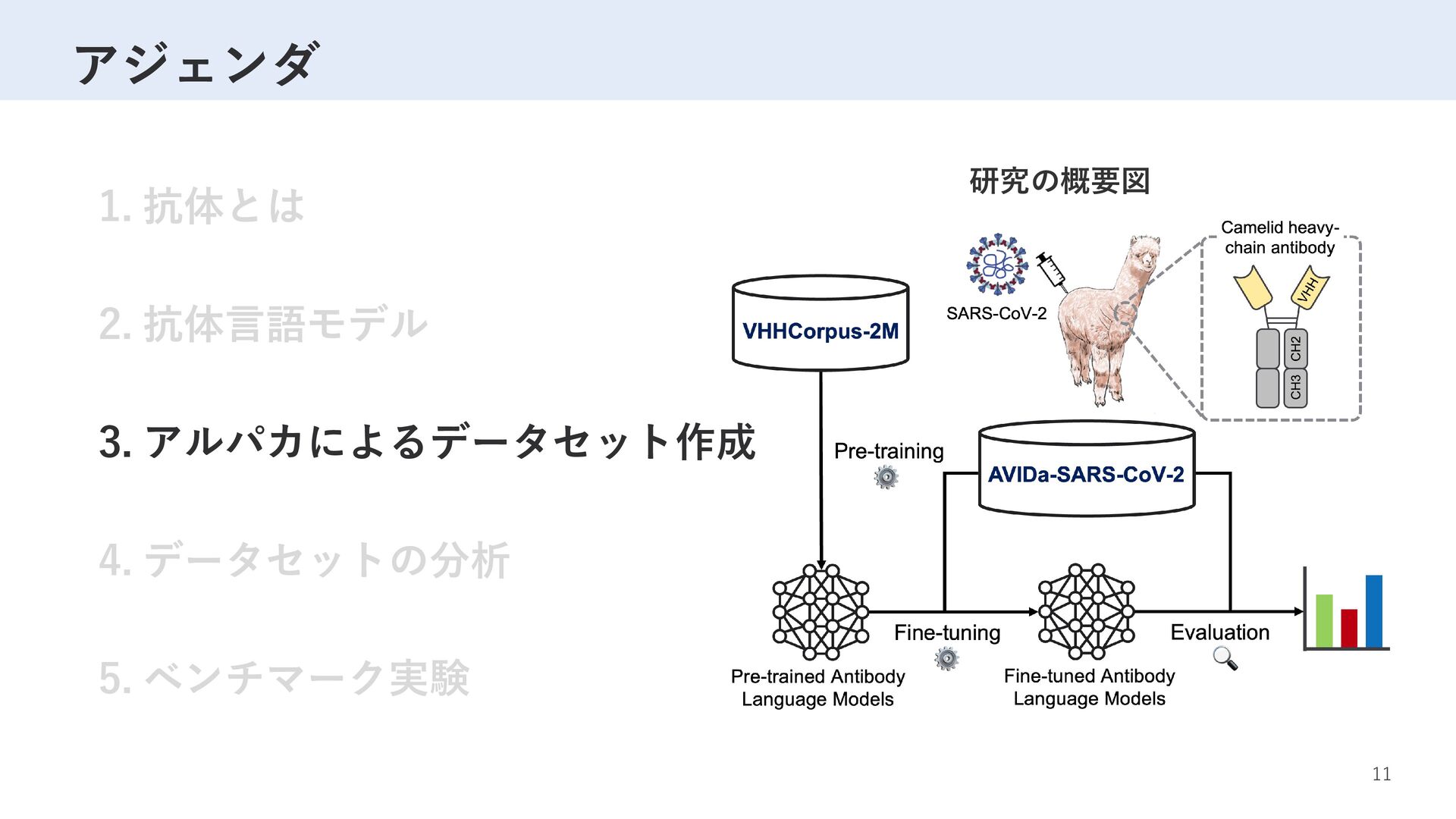
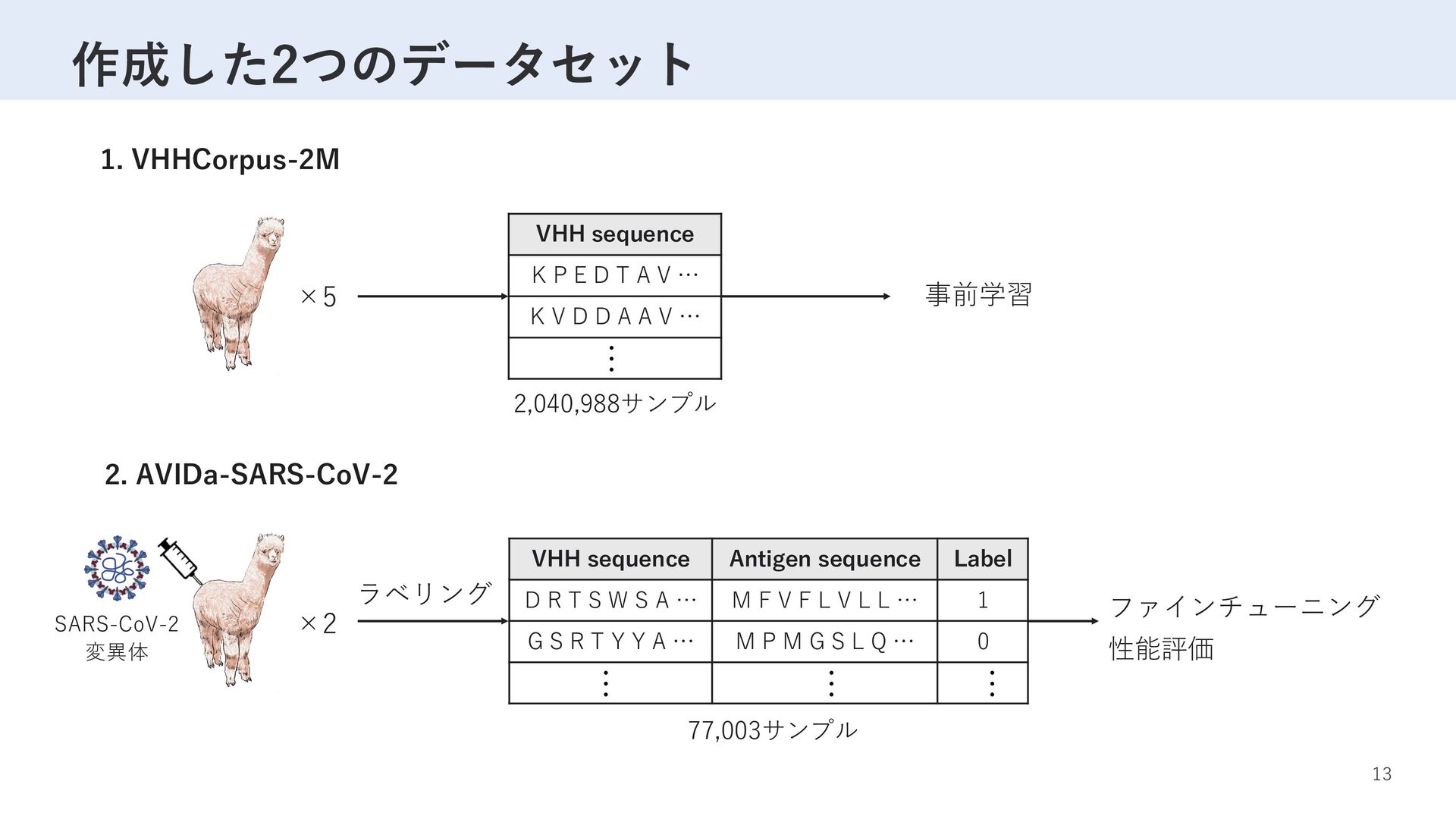
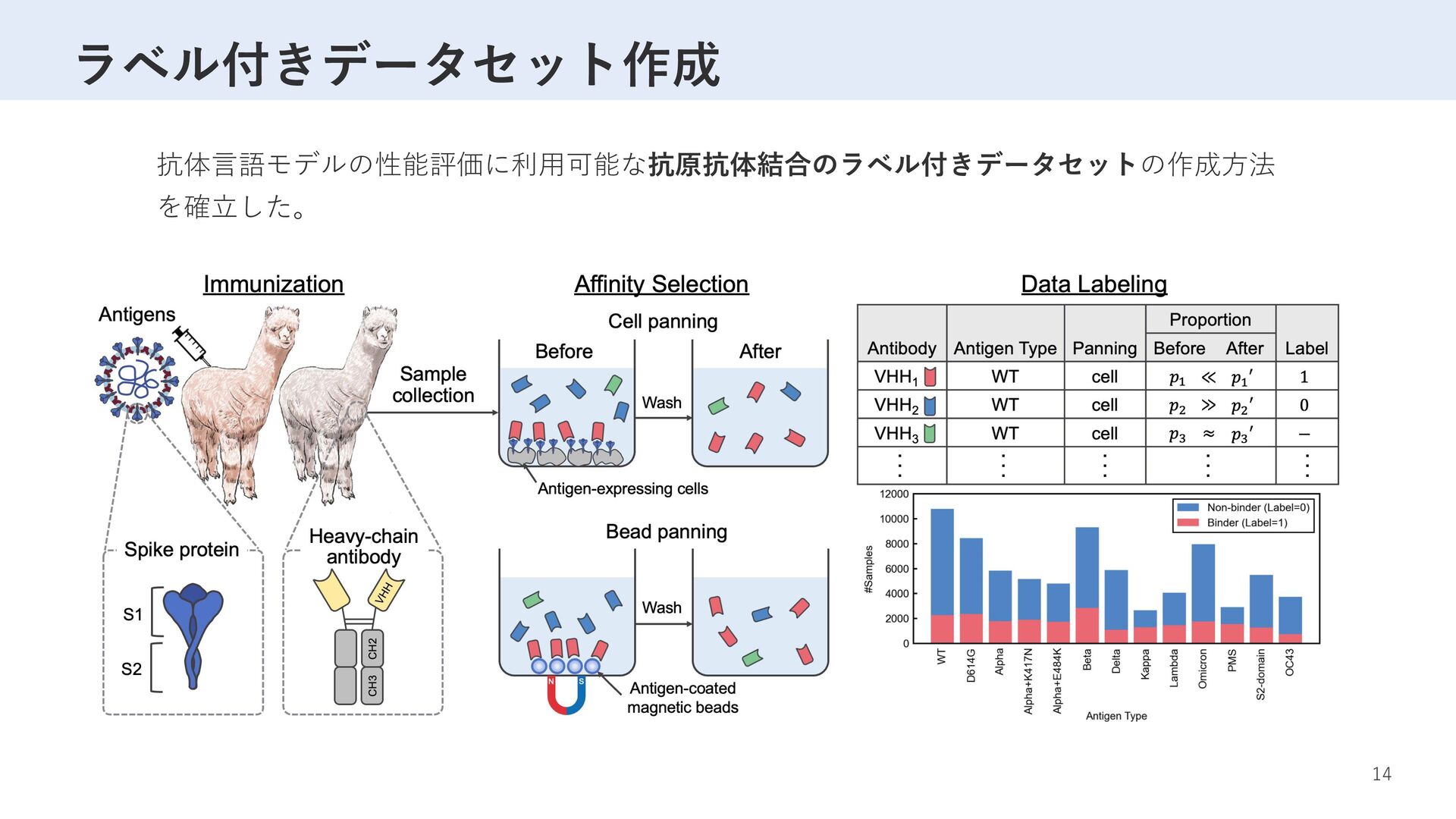
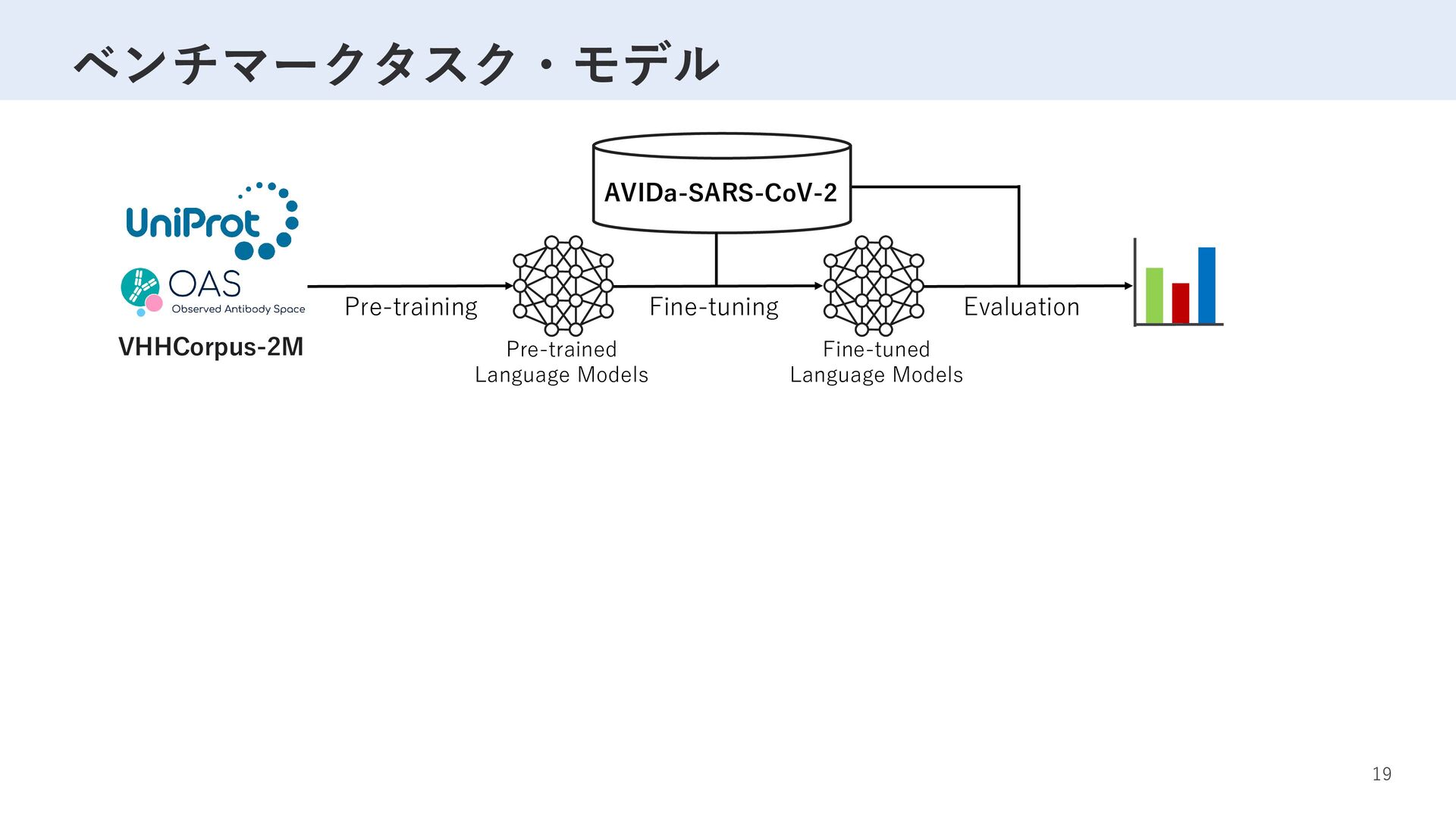
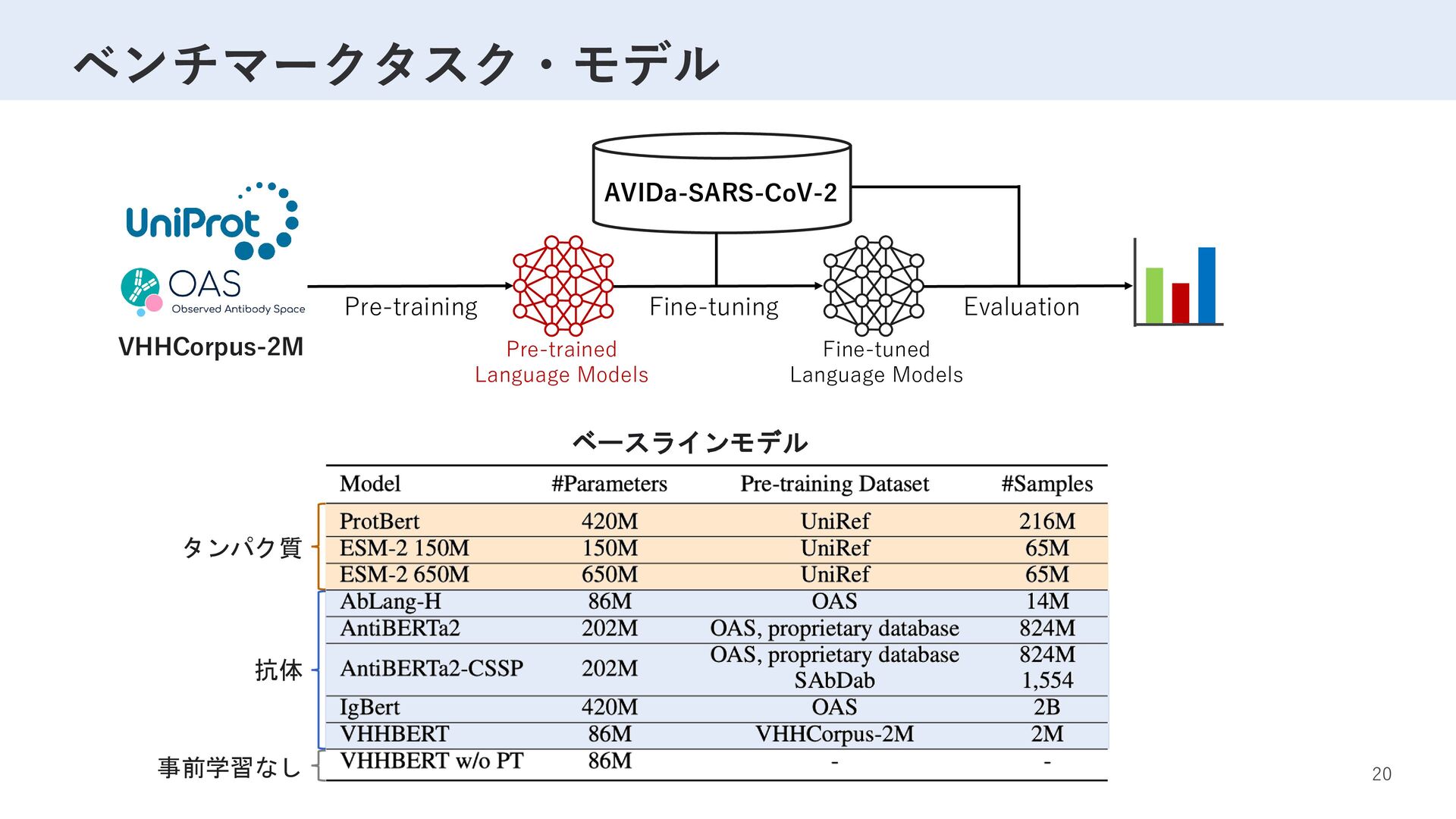
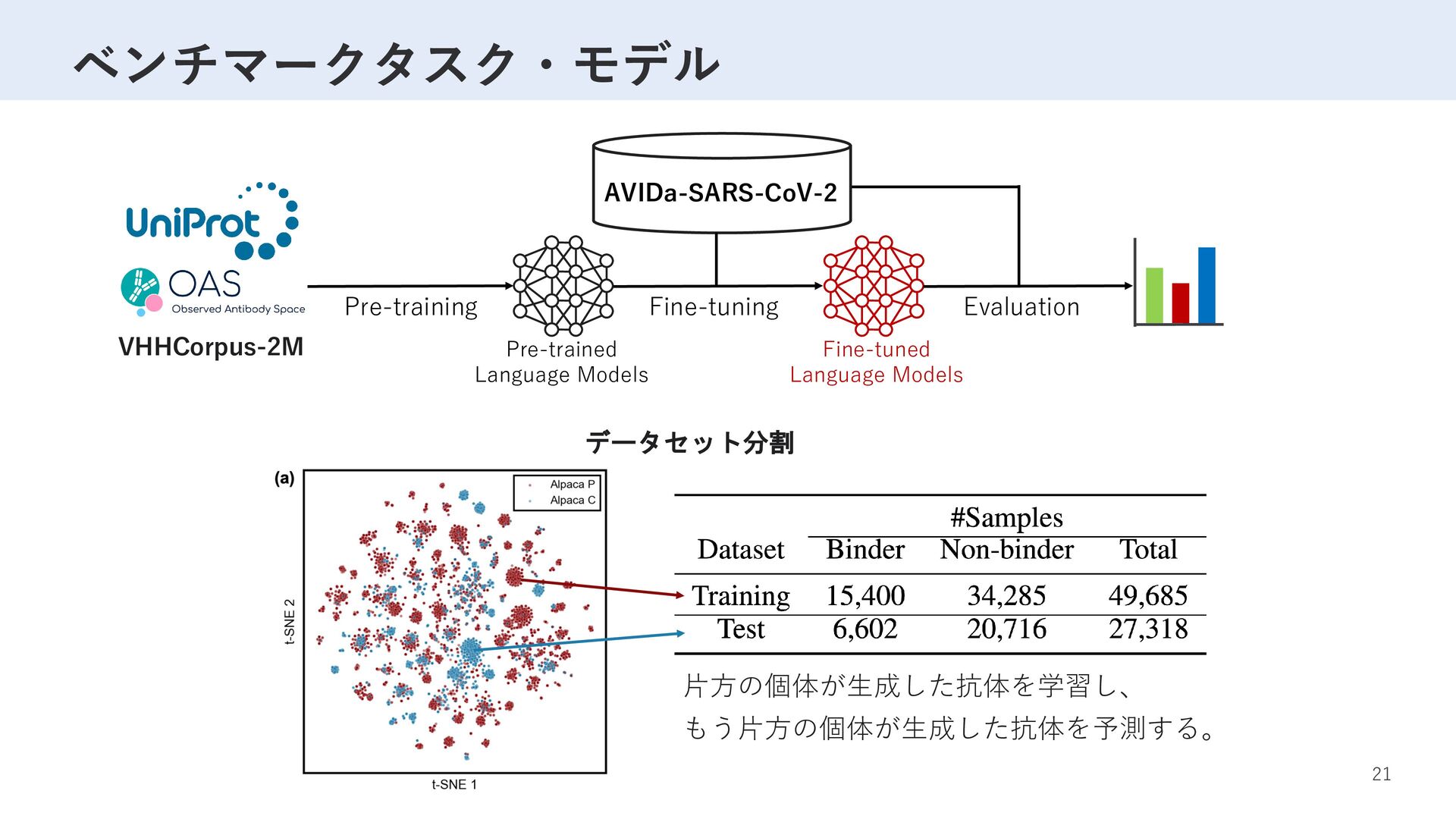
Label D R T S W S A … M F V F L V L L … 1 G S R T Y Y A … M P M G S L Q … 0 … … … VHH sequence K P E D T A V … K V D D A A V … … 事前学習 ×5 2,040,988サンプル SARS-CoV-2 変異体 ×2 ラベリング ファインチューニング 性能評価 77,003サンプル
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![8 抗体と自然言語 出典:[Ofer+, 2021]のFigure 1 [Ofer +, 2021] The language](https://files.speakerdeck.com/presentations/e8bd7c5b12fa4e0ab43c9c1b5f9baacb/slide_7.jpg){kind=link}
{kind=link}
![10 抗体言語モデル 自然言語の分野で医療や法律などに特化したドメイン特化型言語モデルの開発が進んでいるのと 同様に、タンパク質言語モデルにおいても抗体に特化した抗体言語モデルの開発が進んでいる。 代表的な抗体言語モデルの研究 [1] Deciphering antibody affinity maturation](https://files.speakerdeck.com/presentations/e8bd7c5b12fa4e0ab43c9c1b5f9baacb/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}