Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
生成的推薦の人気バイアスの分析:暗記の観点から / JSAI2025
Search
Shotaro Ishihara
May 28, 2025
Research
430
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
生成的推薦の人気バイアスの分析:暗記の観点から / JSAI2025
Shotaro Ishihara
May 28, 2025
More Decks by Shotaro Ishihara
See All by Shotaro Ishihara
大規模言語モデルは誰を覚えているか / Who Do Large Language Models Memorize?
upura
0
88
[ACL 2026 Demo] Fast-MIA: Efficient and Scalable Membership Inference for LLMs
upura
0
88
Fast-MIA: Efficient and Scalable Membership Inference for LLMs
upura
0
51
JAPAN AI CUP Prediction Tutorial
upura
2
1.2k
情報技術の社会実装に向けた応用と課題:ニュースメディアの事例から / appmech-jsce 2025
upura
0
410
日本語新聞記事を用いた大規模言語モデルの暗記定量化 / LLMC2025
upura
0
760
Quantifying Memorization in Continual Pre-training with Japanese General or Industry-Specific Corpora
upura
1
130
JOAI2025講評 / joai2025-review
upura
0
1.7k
AI エージェントを活用した研究再現性の自動定量評価 / scisci2025
upura
1
270
Other Decks in Research
See All in Research
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
880
Cross-Media Human-Information Interaction
signer
PRO
0
120
Using our influence and power for patient safety
helenbevan
0
370
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
230
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
260
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
論文紹介:HalluCitation Matters
wasyro
0
130
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
110
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.6k
Featured
See All Featured
Making the Leap to Tech Lead
cromwellryan
135
10k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Everyday Curiosity
cassininazir
0
260
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
石原祥太郎 (日本経済新聞社) 2025 年度人工知能学会全国大会 (第 39 回) 2025 年 5
月 29 日 https://speakerdeck.com/upura/jsai2025 生成的推薦の人気バイアス の分析:暗記の観点から
• Llama 3 をニュース閲覧履歴でファインチューニング したモデルの生成結果を用い,訓練データ内の文字列 の重複数・暗記・人気バイアスの関係性を分析した. • 文字列の重複数の偏りがある場合,暗記を介して生成 数も偏り人気バイアスが発生すると示唆された. •
解釈を用い,暗記の対応策の重複排除が人気バイアス の軽減に活用できると実証した. 発表概要 2
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 3
識別 「Twitter 社員、買収前 の 5 分の 1 に」 => 推薦モデル
候補記事 1:スコア 0.3 候補記事 2:スコア 0.2 候補記事 3:スコア 0.1 生成的推薦 (Generative Recommendation; GenRec) 4 生成 「Twitter 社員、買収前 の 5 分の 1 に」 => 推薦モデル 「検証 Twitter 買収」 のように読みそうな記事 タイトルを直接生成
大規模言語モデルの発展に伴い,推薦システムへの応用に も注目が集まっている [Lin 24] • 事前学習で獲得した知識を活用し,閲覧履歴が十分に ない状態での性能改善が期待できる [Rajput 23] •
アイテムの系列から意味的情報を抽出して統一的に扱 える [Geng 22] • 推薦理由を自然言語で説明できる [Li 23] 生成的推薦 (Generative Recommendation; GenRec) 5
先駆的な取り組み [Liu 23, Hou 24] は, 生成的推薦で,一部のアイテムが過度に 推薦される傾向 (人気バイアス) [Klimashevskaia
24] が存在すると報告 • 対策としてテキスト情報の考慮 [Liu 23] や過去のやり取りに注目したプロ ンプト設計 [Hou 24] が実験的に検証 されているが,人気バイアスの発生傾 向や要因に関する考察は十分ではない 生成的推薦と人気バイアス 6 訓練 生成
• 暗記は,訓練データと同じまたは類似の文字列が出力 される現象を指し,セキュリティ・著作権上の懸念や 汎用性の低下を引き起こす [Ishihara 23] • 暗記は (1) 訓練データ内の文字列の重複数
(2) モデルサ イズ (3) プロンプト長の 3 つと強く関連 [Carlini 23] • 日本語を対象とした研究 [Kiyomaru 24, Ishihara 24] もあるが,生成的推薦の文脈では検証されていない 大規模言語モデルの訓練データの暗記 7
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 8
大規模言語モデルの課題 本研究の立ち位置 9 生成的推薦での人気バイアス 訓練データの暗記 … (独立で議論されているが) 人気バイアスは訓練 データの暗記の観点で解釈できるのでは?
• 前提:訓練データ内のアイテムの人気には偏りがある => 大規模言語モデルを用いた生成的推薦の場合は, 文字列の重複数と見なせる • 仮説 1:生成的推薦でも文字列の重複数は暗記に影響 し,人気のアイテムが優先的に暗記される •
仮説 2:暗記されているアイテムは生成されやすく, 推薦結果に人気バイアスが発生する 本研究の前提と仮説 10
仮説を検証するために,「日経電子版」のデータセットを 活用し,生成的推薦の人気バイアスを暗記の観点で分析 • 一般に公開されているデータセットでは,個人情報へ の配慮やビジネス指標の秘匿の観点から出現数が加工 されている場合があり [Seki 20],公平性の測定に適し ていない可能性がある 本研究の目的
(研究として) 11
「日経電子版」などの推薦システムとして、生成的推薦の 枠組みを導入できるか? • 日経電子版にパーソナライズの仕組みは導入済み • 独自の大規模言語モデルの構築も進めている • 性能や,性能面以外の課題を検証していく必要がある 本研究の目的 (実践として)
12
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 13
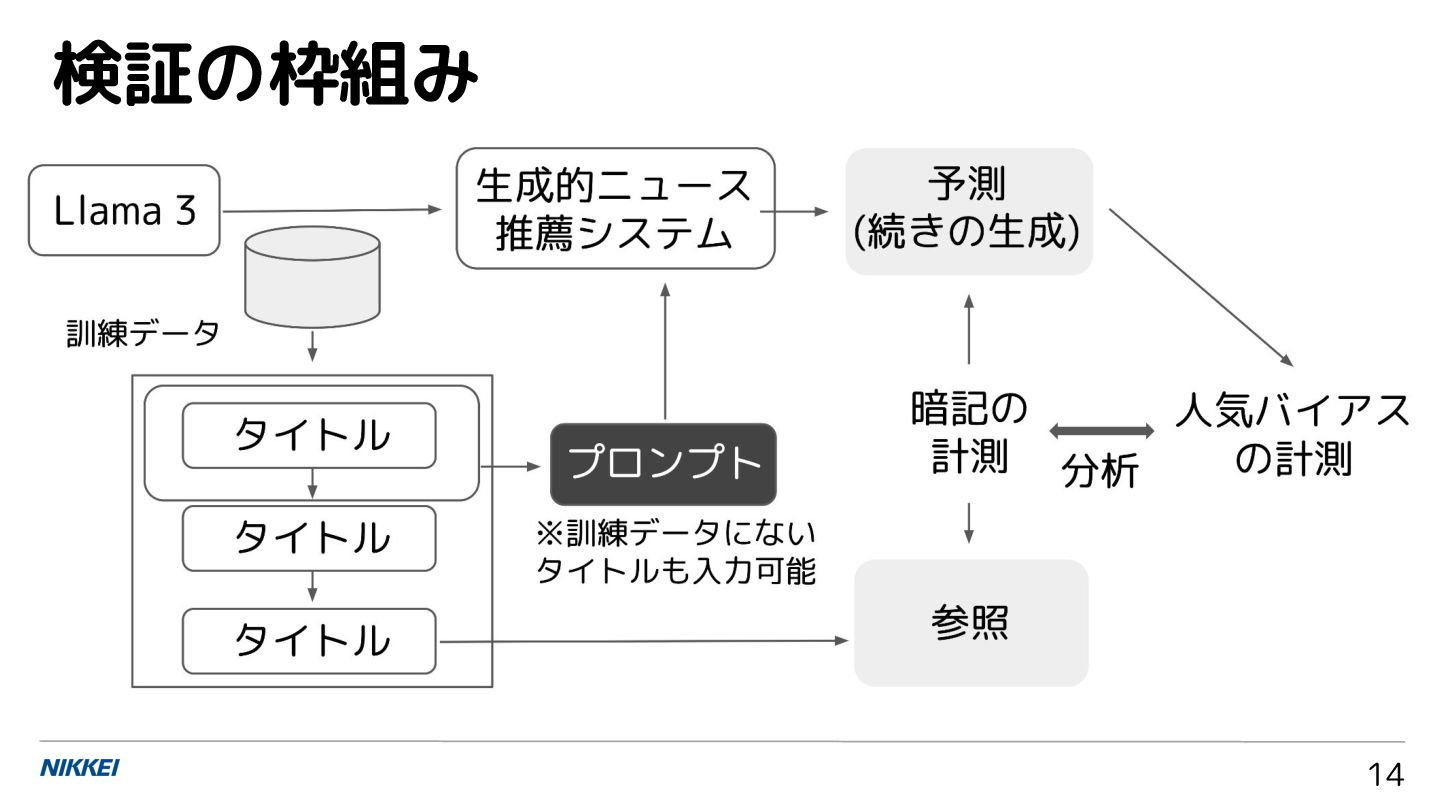
検証の枠組み 14
• セッション内でユーザが閲覧した記事の系列をテキス ト形式に加工し,次の閲覧記事を予測するタスクとし て訓練データに ◦ 例:タイトル1 [ARTICLE_SEP] タイトル2 [ARTICLE_SEP] …
タイトル N [SEP] • 2023 年 1 月の一定期間から 3 記事以上を閲覧してい るセッションの閲覧履歴データ約 2000 万個を抽出 • 最大トークン長は 512 対象とする生成的推薦システム:訓練 15
• meta-llama/Meta-Llama-3-8B-Instruct を LoRA で継 続事前学習 ◦ この設定でも,日本語の一般的な文では訓練データ 内の文字列の重複数が暗記と関係 [高橋
25] • LoRA の ランク数は 16 で 2 エポック学習し,1000 ス テップごとに重みを保存 • 学習したモデルを Llama3-nikkei-genrec と呼ぶ モデルのファインチューニング 16
• Llama3-nikkei-genrec は「タイトル [ARTICLE_SEP]」の入力が与えられた際に,次に続く タイトルを予測 • 本研究では暗記の分析のため,確率が最も高いトーク ンを選び続ける貪欲法でデコーディング • 候補の集合がある場合は,それぞれ算出した生成確率
が大きい記事を推薦できるが,本研究では暗記の傾向 に関心があるため,候補の集合は提示しない 対象とする生成的推薦システム:推論 17
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 18
• 前提:訓練データ内のアイテムの人気には偏りがある ◦ => 訓練データ内のアイテムの出現数の偏りを確認 • 仮説 1:生成的推薦でも文字列の重複数は暗記に影響し,人気のア イテムが優先的に暗記される ◦
=> 訓練データ内の文字列の重複数が増えることで,生成的推薦 の枠組みでも暗記が増加するかを計測 • 仮説 2:暗記されているアイテムは生成されやすく,推薦結果に人 気バイアスが発生する ◦ => 推薦結果を分析し,暗記と人気バイアスの関係性を議論 本研究の前提と仮説の検証方法 19
• 簡略化のため,訓練データの各セッションの 2 つ 目の 閲覧記事までに絞って分析 ◦ 最初の記事をプロンプト,2 つ目を正解に ◦
最初の記事からは様々な遷移があるため,最も遷移 数の多い閲覧記事のセッションのみを正解に • Llama3-nikkei-genrec に対して「記事タイトル [ARTICLE_SEP]」を与え続きを最大 50 トークン生成 分析対象のデータセット 20
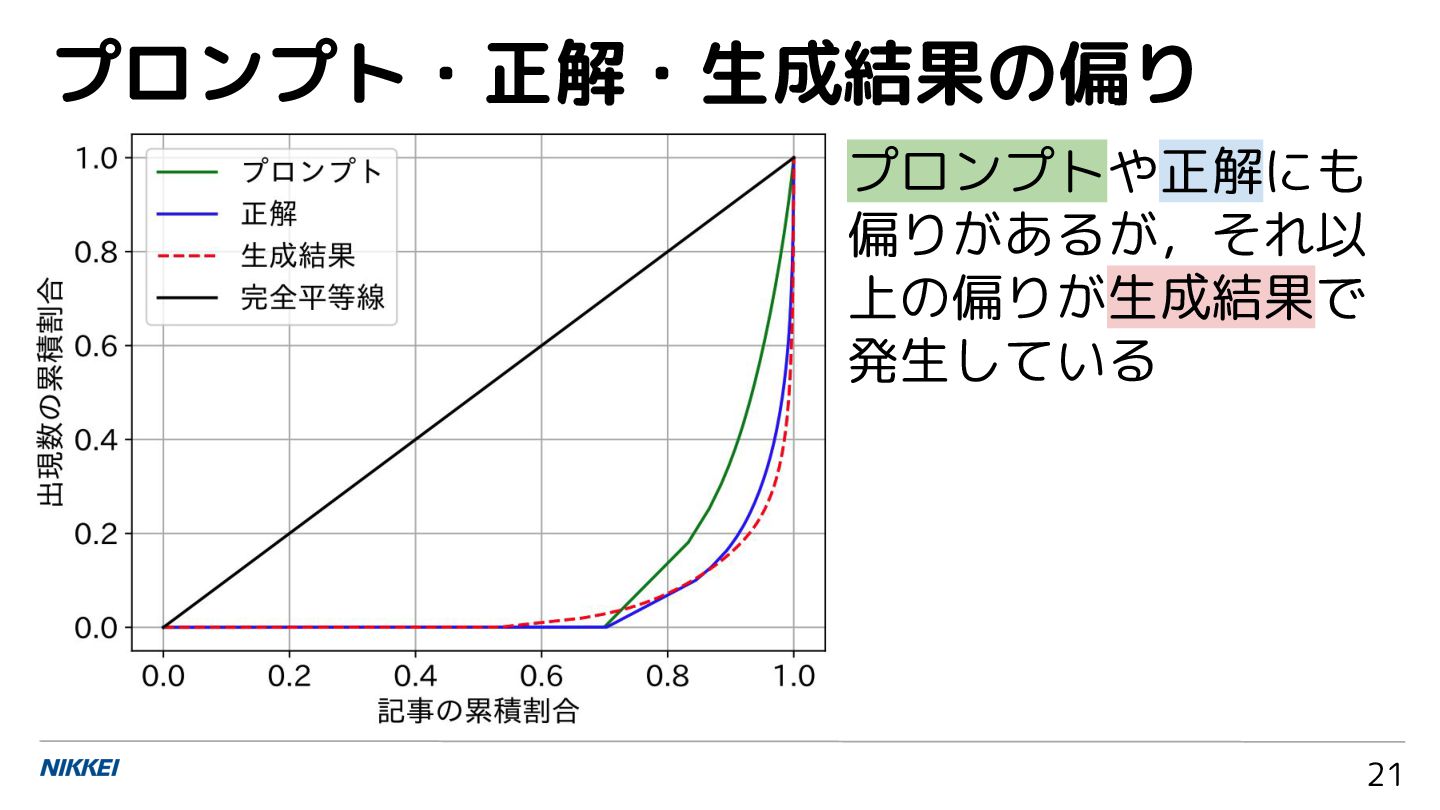
プロンプトや正解にも 偏りがあるが,それ以 上の偏りが生成結果で 発生している プロンプト・正解・生成結果の偏り 21
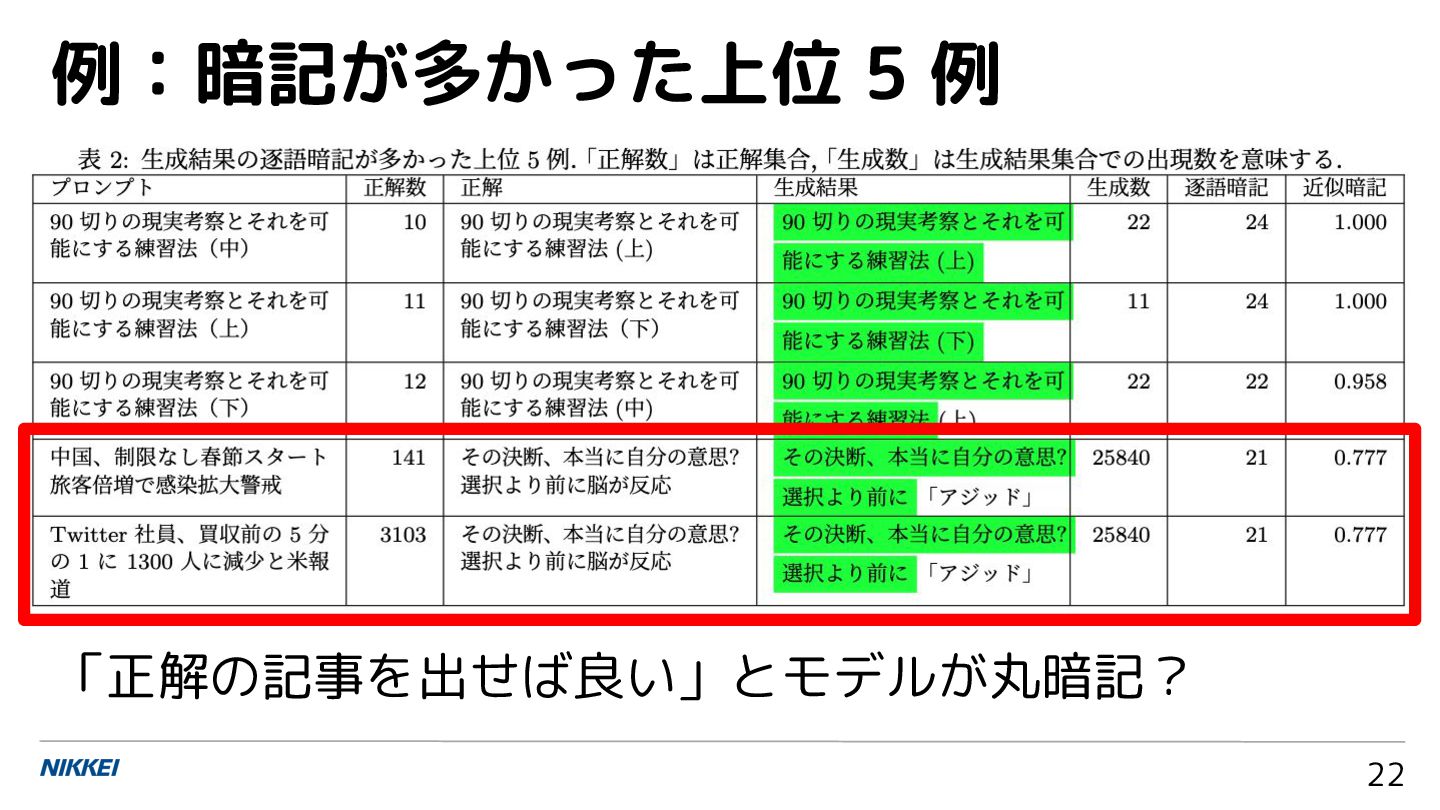
例:暗記が多かった上位 5 例 22 「正解の記事を出せば良い」とモデルが丸暗記?
日本語を対象とした暗記に関する先行研究 [Ishihara 24] に従い,大きいほど暗記量が多い 2 つの定義を利用 • 逐語暗記:前方一致の文字数 • 近似暗記:近似暗記
1 - (編集距離 / 文字列の長さ) => 正解の記事タイトルの重複数との相関を分析 仮説 1:重複しているほど暗記される? 23
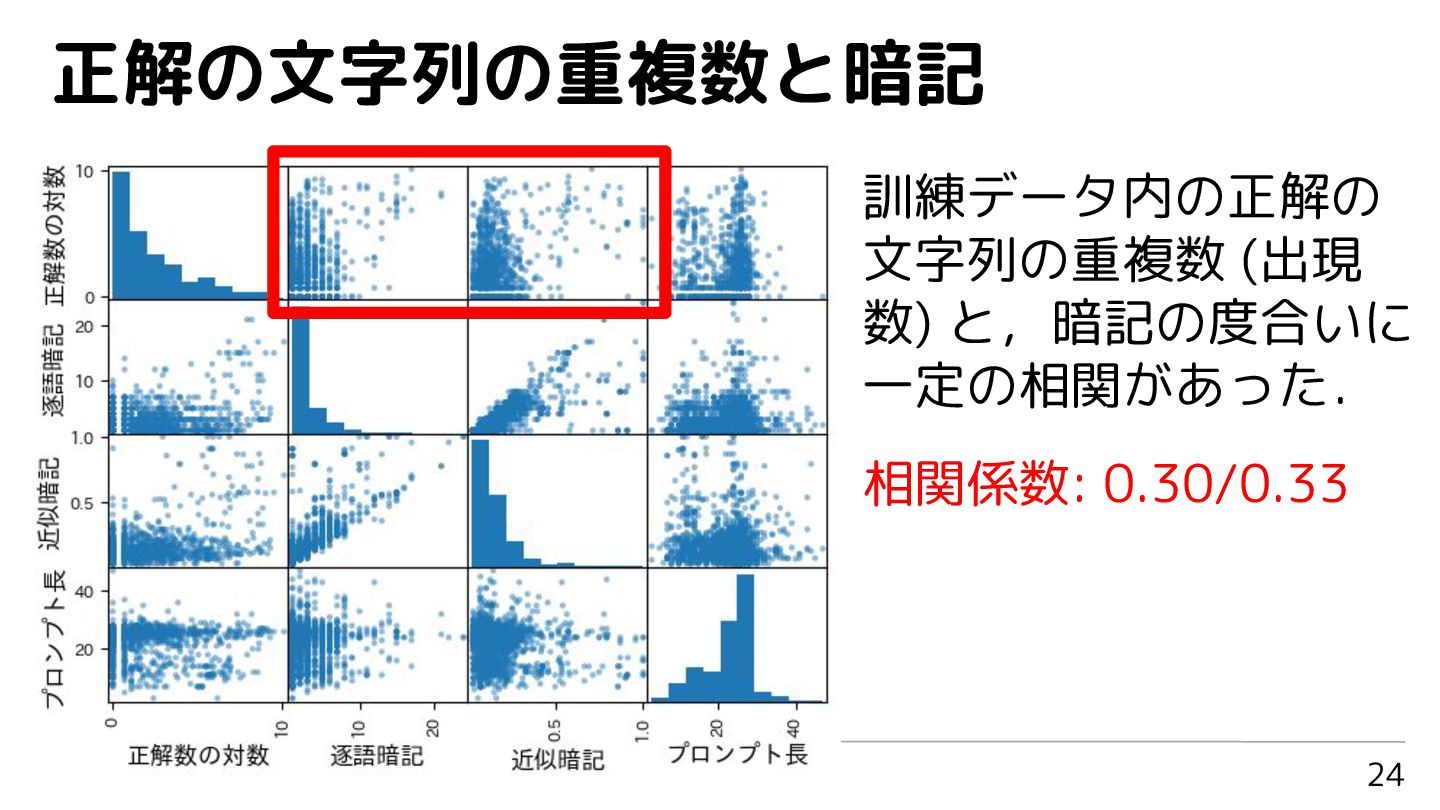
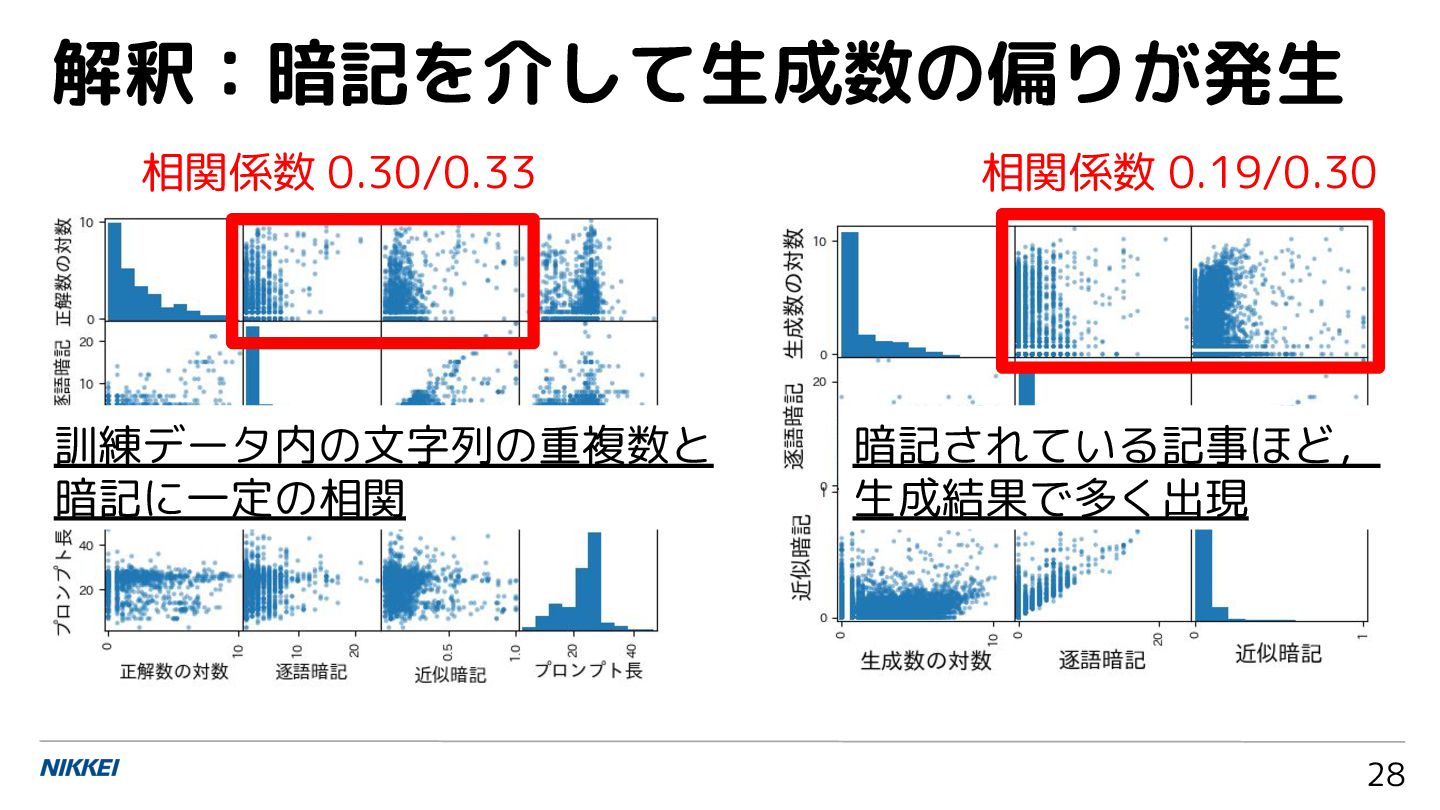
正解の文字列の重複数と暗記 24 訓練データ内の正解の 文字列の重複数 (出現 数) と,暗記の度合いに 一定の相関があった. 相関係数: 0.30/0.33
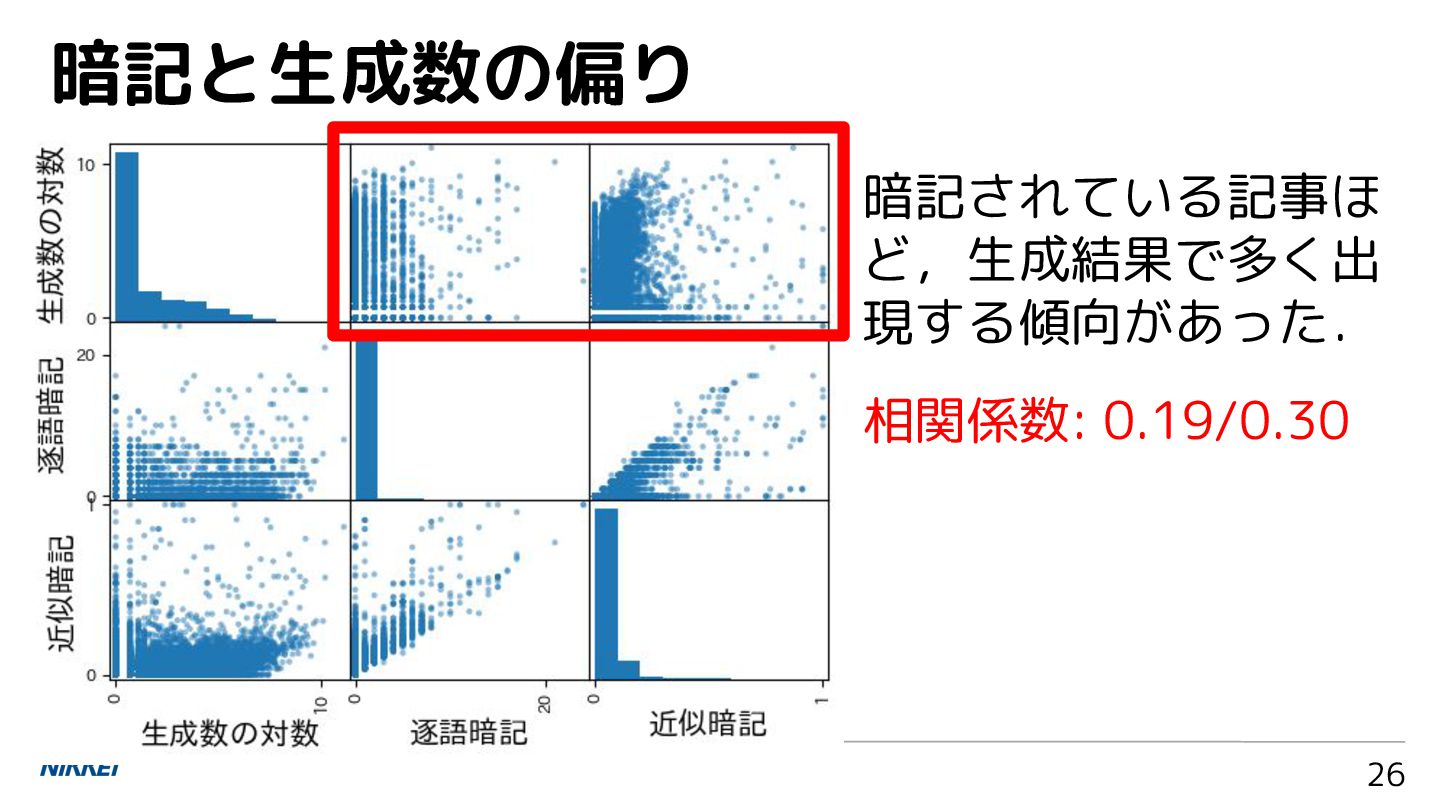
• 逐語暗記:前方一致の文字数 • 近似暗記:近似暗記 1 -(編集距離 / 文字列の長さ) => 暗記されている記事タイトルほど,生成結果での文字
列の重複数が多いかを分析 仮説 2:暗記されているほど生成される? 25
暗記と生成数の偏り 26 暗記されている記事ほ ど,生成結果で多く出 現する傾向があった. 相関係数: 0.19/0.30
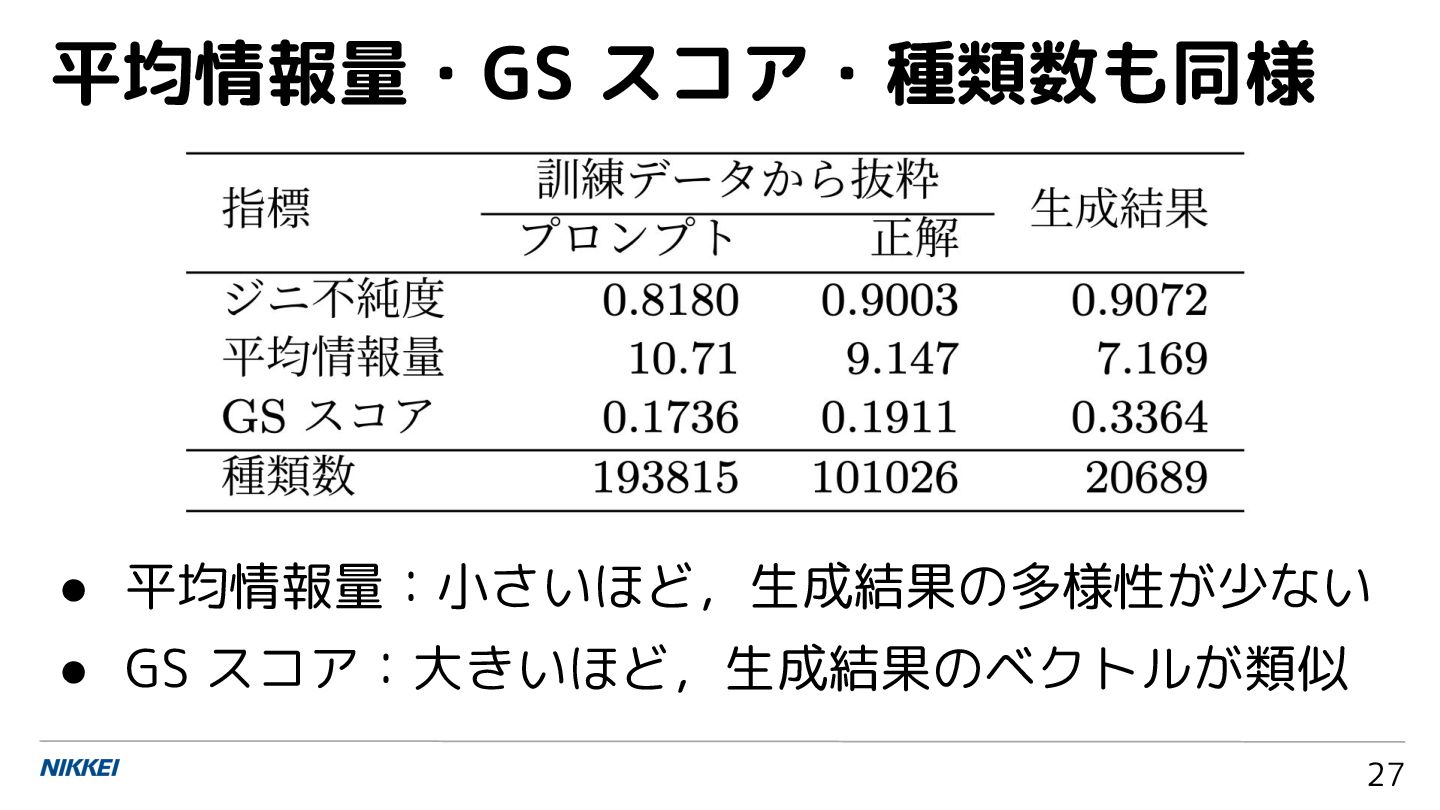
平均情報量・GS スコア・種類数も同様 27 • 平均情報量:小さいほど,生成結果の多様性が少ない • GS スコア:大きいほど,生成結果のベクトルが類似
解釈:暗記を介して生成数の偏りが発生 28 暗記されている記事ほど, 生成結果で多く出現 訓練データ内の文字列の重複数と 暗記に一定の相関 相関係数 0.30/0.33 相関係数 0.19/0.30
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 29
• 生成的推薦の人気バイアスが暗記を介して発生してい る可能性が示唆された • 訓練データの重複排除 [Kandpal 22, Lee 22] といった
暗記の対応策が,生成的推薦の人気バイアスへの軽減 に応用できる可能性があるのでは? => 実際に訓練データを加工し、モデルを同様にファイン チューニングして検証 (訓練データ以外は同条件) 暗記の対処法:訓練データの重複排除 30
• 2 つ目の閲覧記事までに絞った後に,正解集合の重複 がなくなるようセッションを選別 • セッション数は約 100 分の 1 の
193860 に 重複排除の方法 31
重複排除で,生成結果の種類数が増加 32 • 暗記の度合いは大幅に減少 • ジニ不純度や平均情報量などの指標も多様性が増加す る方向に変化し,人気バイアスの軽減が確認できた • 一方で完全一致の正答数は悪化しており,推薦システ ム設計の重要性が強調された
[Zhang 23]
• 背景:生成的推薦、人気バイアス、暗記 • 目的:研究として、実践として • 実験:生成的ニュース推薦システムの構築 • 結果:暗記の観点での人気バイアスの解釈 • 対策:訓練データの重複排除
• おわりに 目次 33
• Llama 3 をニュース閲覧履歴でファインチューニング したモデルの生成結果を用い,訓練データ内の文字列 の重複数・暗記・人気バイアスの関係性を分析した. • 文字列の重複数の偏りがある場合,暗記を介して生成 数も偏り人気バイアスが発生すると示唆された. •
解釈を用い,暗記の対応策の重複排除が人気バイアス の軽減に活用できると実証した. [再掲] 発表概要 34
• 暗記の別の観点での分析 ◦ モデルサイズやプロンプト長との関連など • 構築した生成的推薦システムの人気バイアスの分析以 外での活用 ◦ 擬似データ生成,ユーザ・記事の分析など 今後の展望
35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![大規模言語モデルの発展に伴い,推薦システムへの応用に も注目が集まっている [Lin 24] • 事前学習で獲得した知識を活用し,閲覧履歴が十分に ない状態での性能改善が期待できる [Rajput 23] •](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_4.jpg){kind=link}
![先駆的な取り組み [Liu 23, Hou 24] は, 生成的推薦で,一部のアイテムが過度に 推薦される傾向 (人気バイアス) [Klimashevskaia](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_5.jpg){kind=link}
![• 暗記は,訓練データと同じまたは類似の文字列が出力 される現象を指し,セキュリティ・著作権上の懸念や 汎用性の低下を引き起こす [Ishihara 23] • 暗記は (1) 訓練データ内の文字列の重複数](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![仮説を検証するために,「日経電子版」のデータセットを 活用し,生成的推薦の人気バイアスを暗記の観点で分析 • 一般に公開されているデータセットでは,個人情報へ の配慮やビジネス指標の秘匿の観点から出現数が加工 されている場合があり [Seki 20],公平性の測定に適し ていない可能性がある 本研究の目的](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![• セッション内でユーザが閲覧した記事の系列をテキス ト形式に加工し,次の閲覧記事を予測するタスクとし て訓練データに ◦ 例:タイトル1 [ARTICLE_SEP] タイトル2 [ARTICLE_SEP] …](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_14.jpg){kind=link}
{kind=link}
![• Llama3-nikkei-genrec は「タイトル [ARTICLE_SEP]」の入力が与えられた際に,次に続く タイトルを予測 • 本研究では暗記の分析のため,確率が最も高いトーク ンを選び続ける貪欲法でデコーディング • 候補の集合がある場合は,それぞれ算出した生成確率](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![日本語を対象とした暗記に関する先行研究 [Ishihara 24] に従い,大きいほど暗記量が多い 2 つの定義を利用 • 逐語暗記:前方一致の文字数 • 近似暗記:近似暗記](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• 生成的推薦の人気バイアスが暗記を介して発生してい る可能性が示唆された • 訓練データの重複排除 [Kandpal 22, Lee 22] といった](https://files.speakerdeck.com/presentations/26fe7a02f92c49a28044c4c4b18d63e6/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}