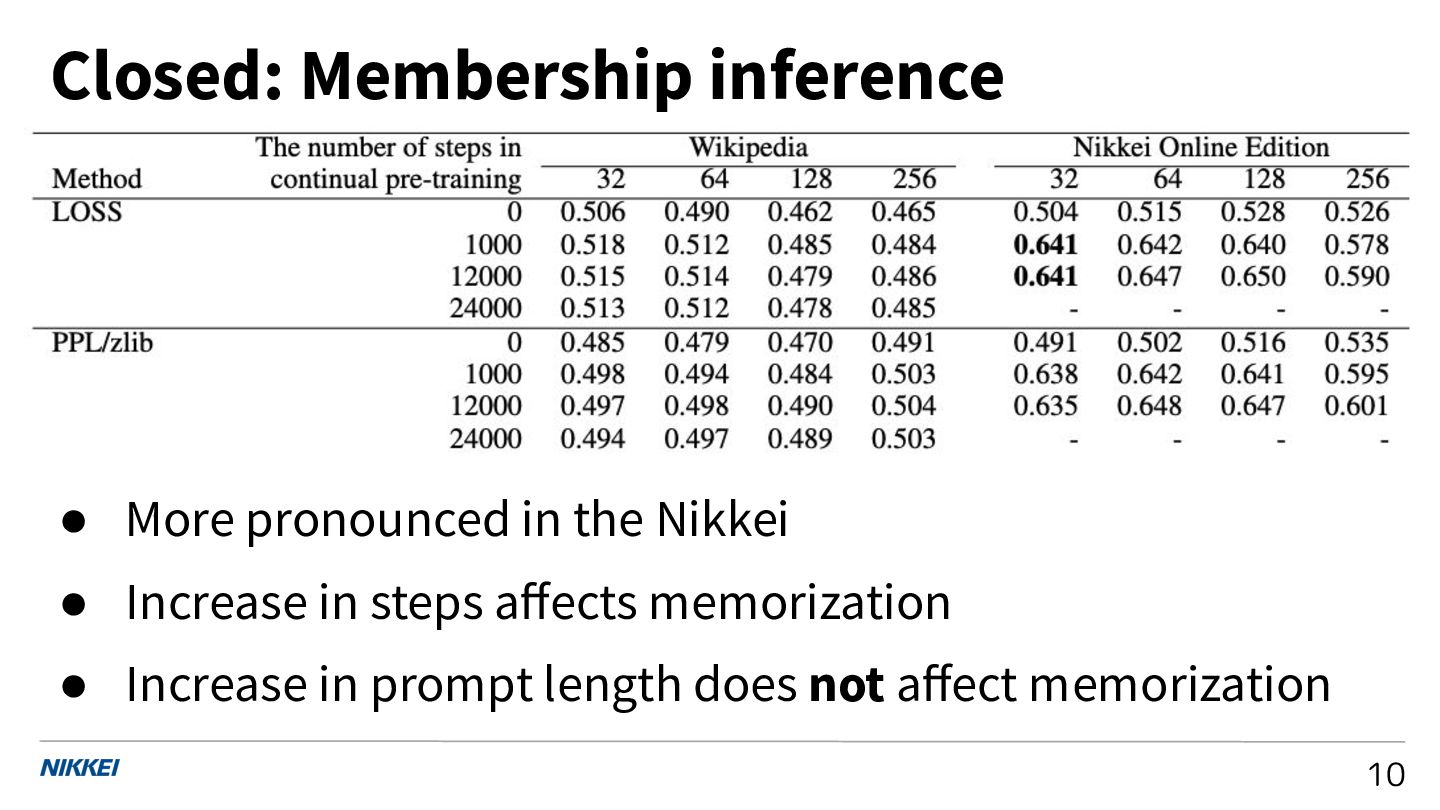
Quantifying Memorization in Continual Pre-training with Japanese General or Industry-Specific Corpora
Hiromu Takahashi and Shotaro Ishihara
The First Workshop on Large Language Model Memorization
Aug 1st, 2025
https://aclanthology.org/2025.l2m2-1.8/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}