Como reduzir a latência de uma API de 2.8 segundos para 8ms usando arquitetura colunar. A apresentação parte de um caso real — uma API de sugestão de comissão consultando 15
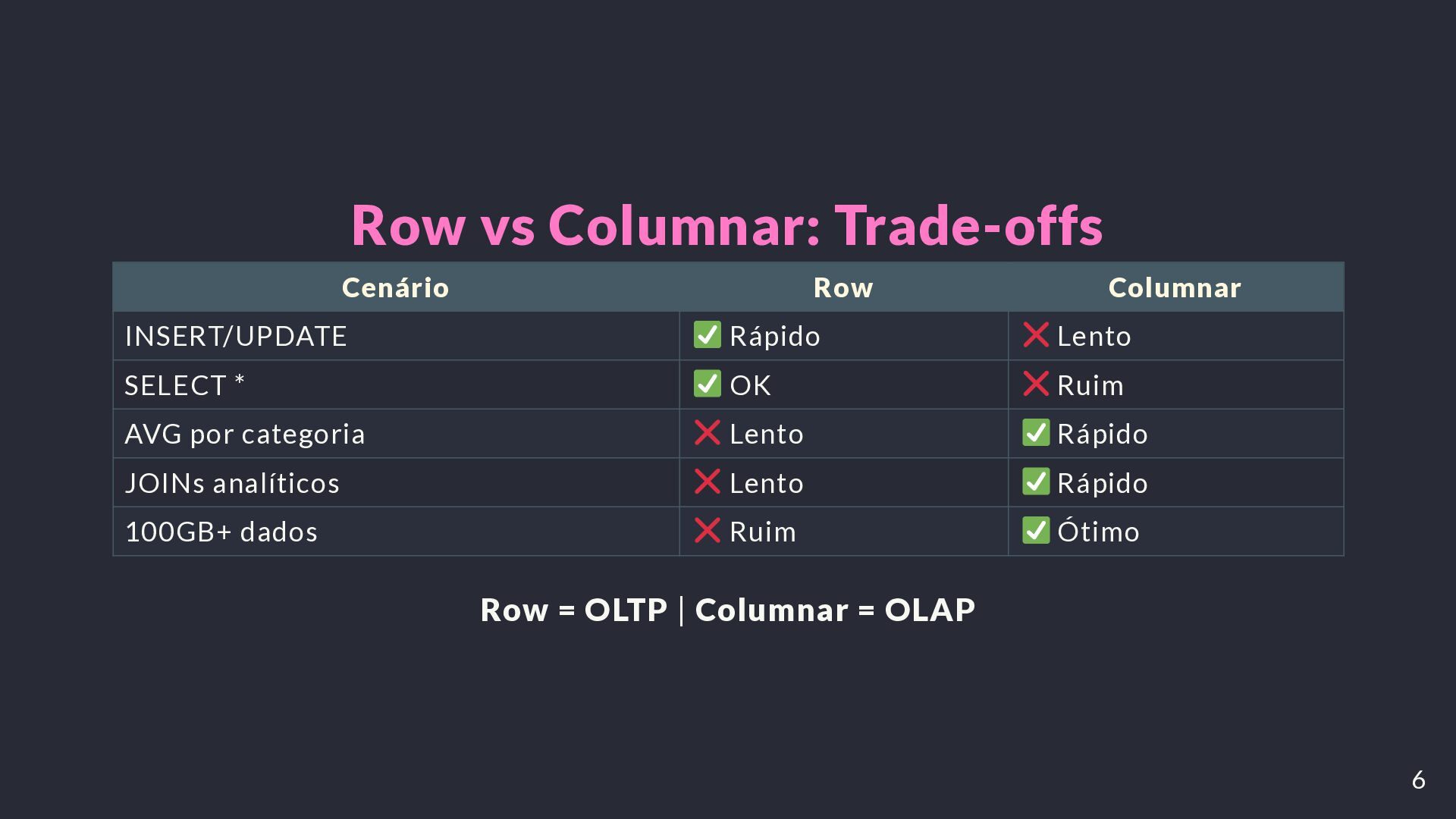
milhões de registros — para explicar as diferenças fundamentais entre armazenamento row-oriented (Postgres) e column-oriented (Redshift): I/O, trade-offs OLTP vs OLAP,
distribution keys, sort keys, zone maps e o papel do MPP. A solução combina ETL com PySpark, agregação no Redshift e uma serving layer em Postgres, alcançando uma melhoria
de 350x na latência. Inclui anti-patterns, checklist de quando usar banco colunar e práticas de manutenção com VACUUM e ANALYZE.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}