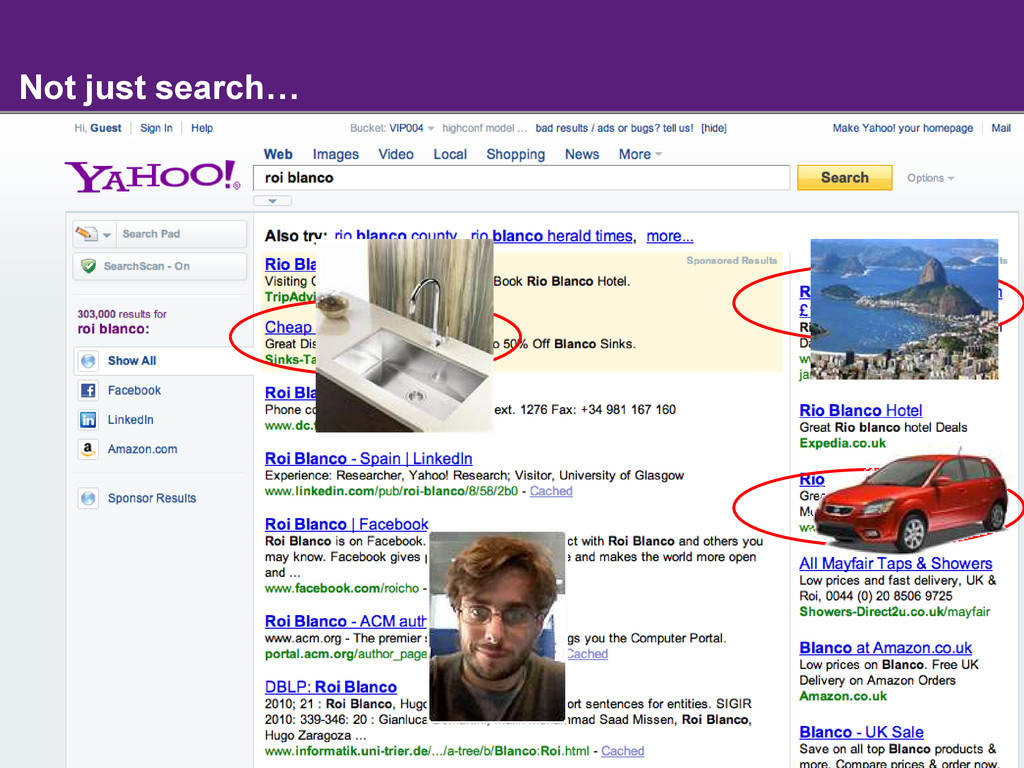
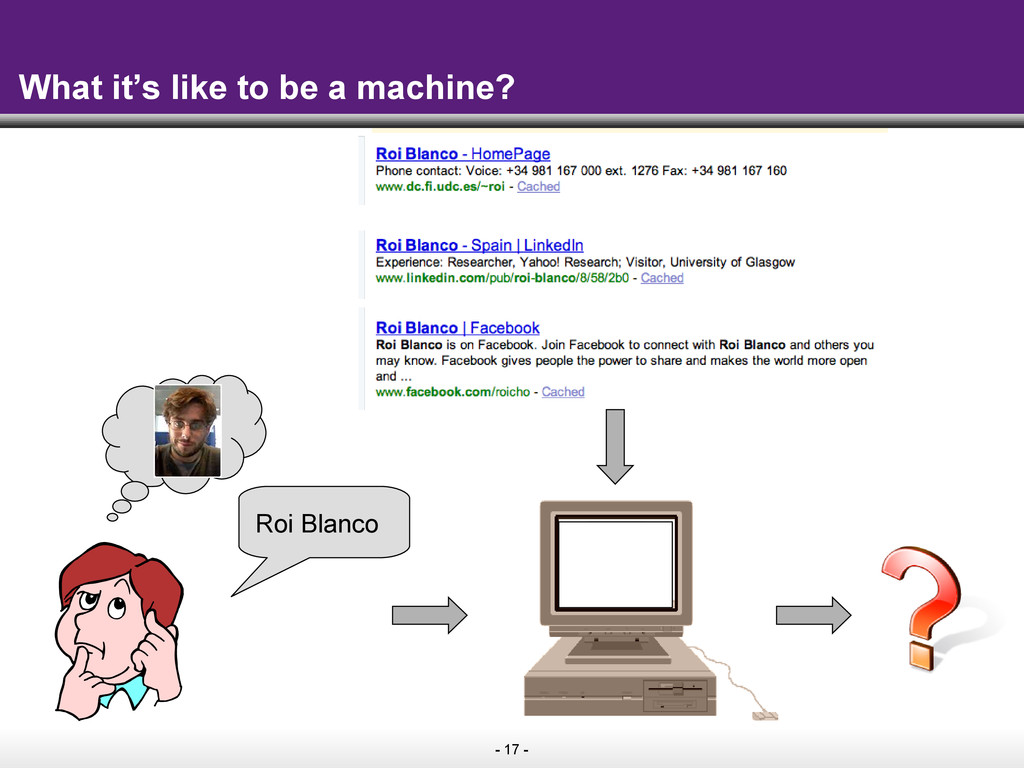
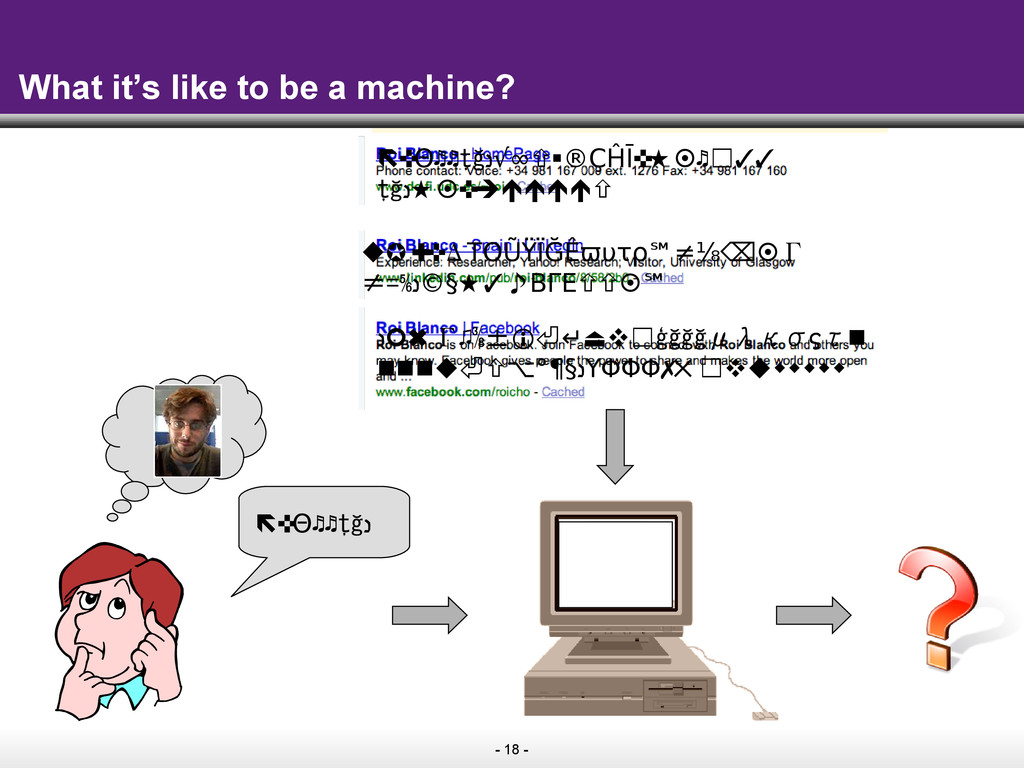
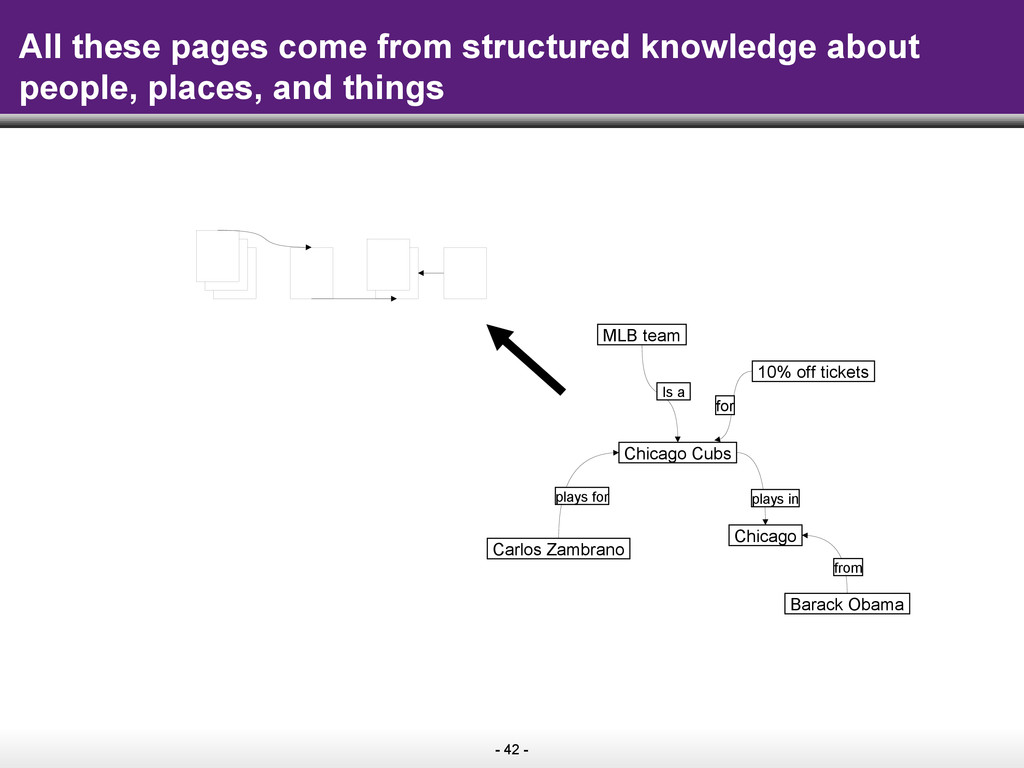
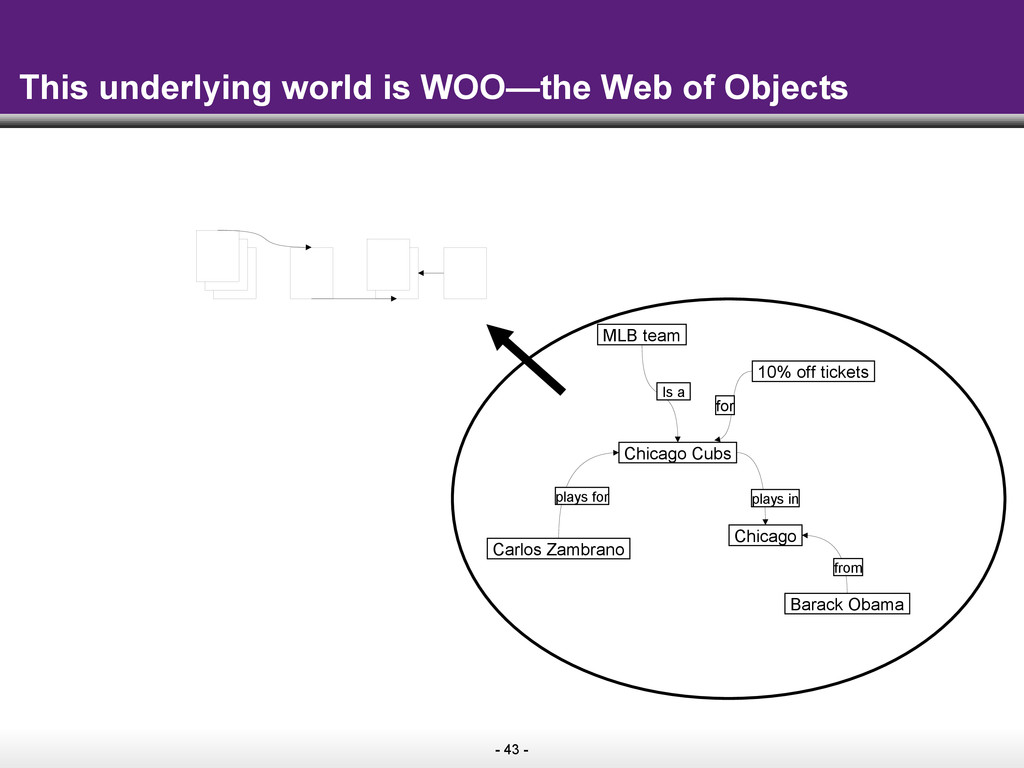
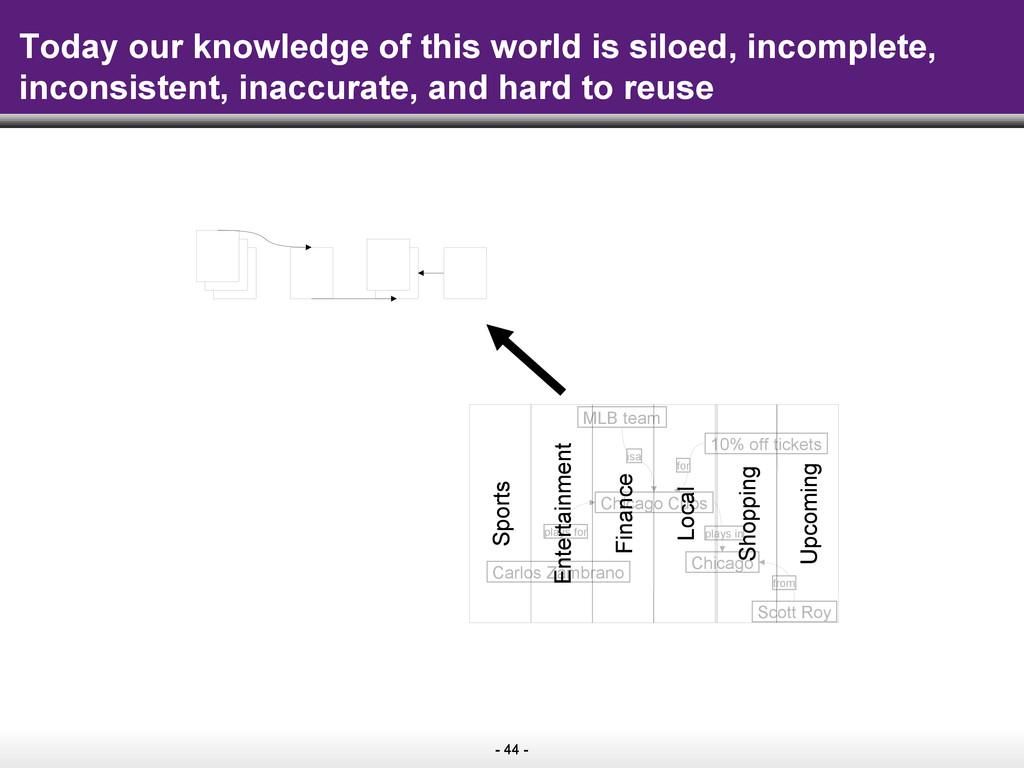
The key idea of the Semantic Web is to make information on the Web easily consumable by machines. As machines start to understand web pages as sources of data that can be easily combined with other public data on the Web, the promise is that search on the Web will move well beyond the current paradigm of retrieving pages by keywords. Instead, search engines will start to answer complex queries based on the cumulative knowledge of the Web.
In this presentation, we overview the basic set of technologies that can be used to annotate web pages so that they can be processed by data-aware search engines. In particular, we discuss the RDFa and microdata standards of the W3C designed for marking up data in HTML pages. We look at the ways in which this information is currently used by search engines, including the latest schema.org collaboration between Bing, Google, and Yahoo!, which provides a basic set of vocabulary items understood by all three major search engines on the Web.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
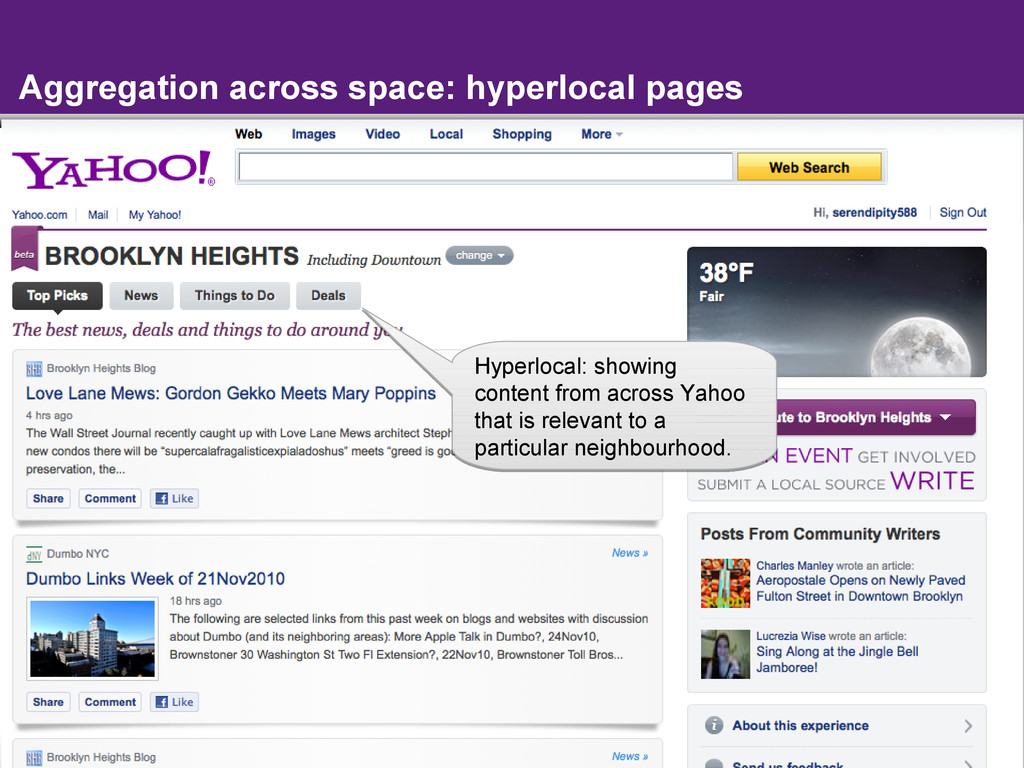{kind=link}
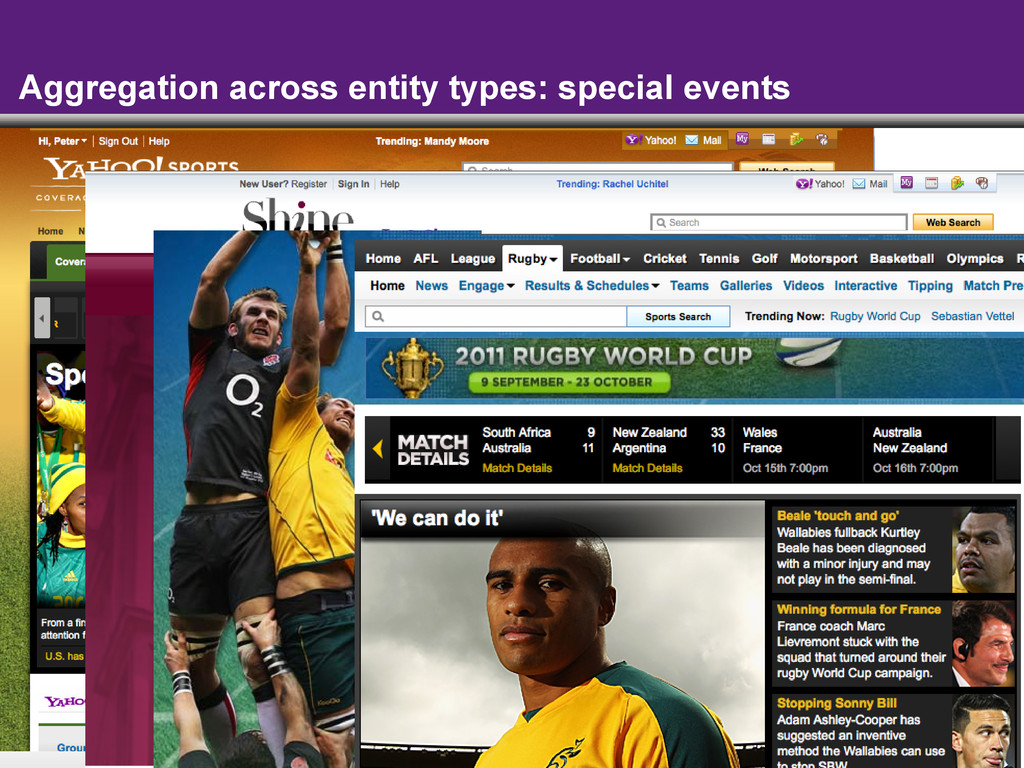{kind=link}
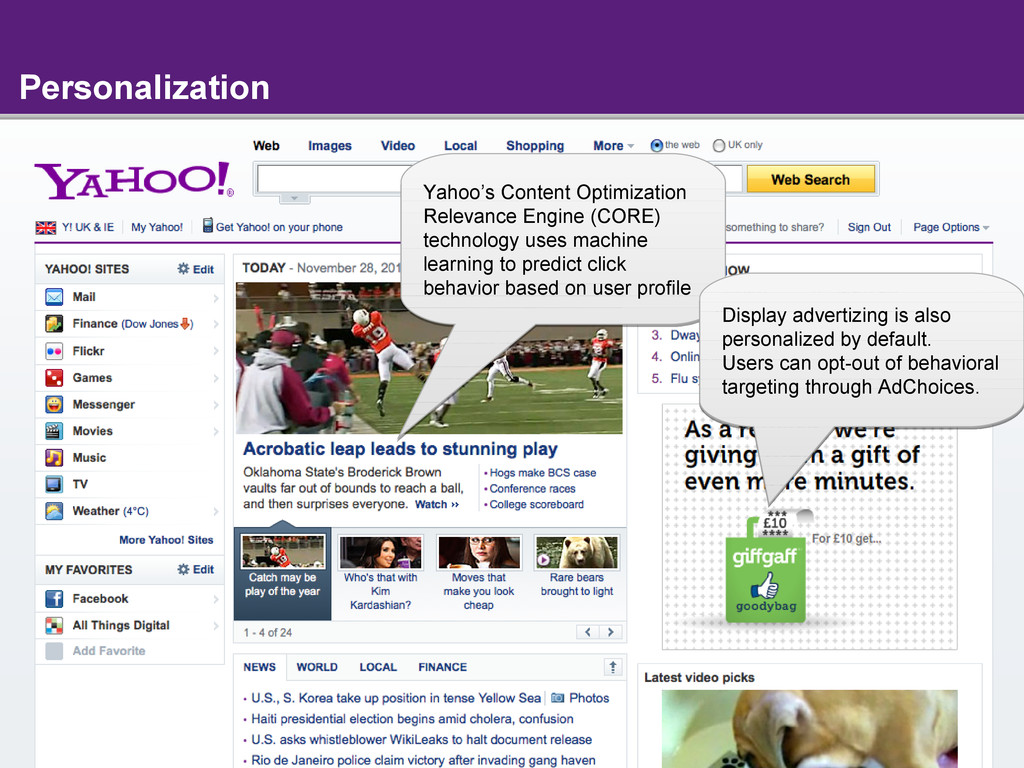{kind=link}
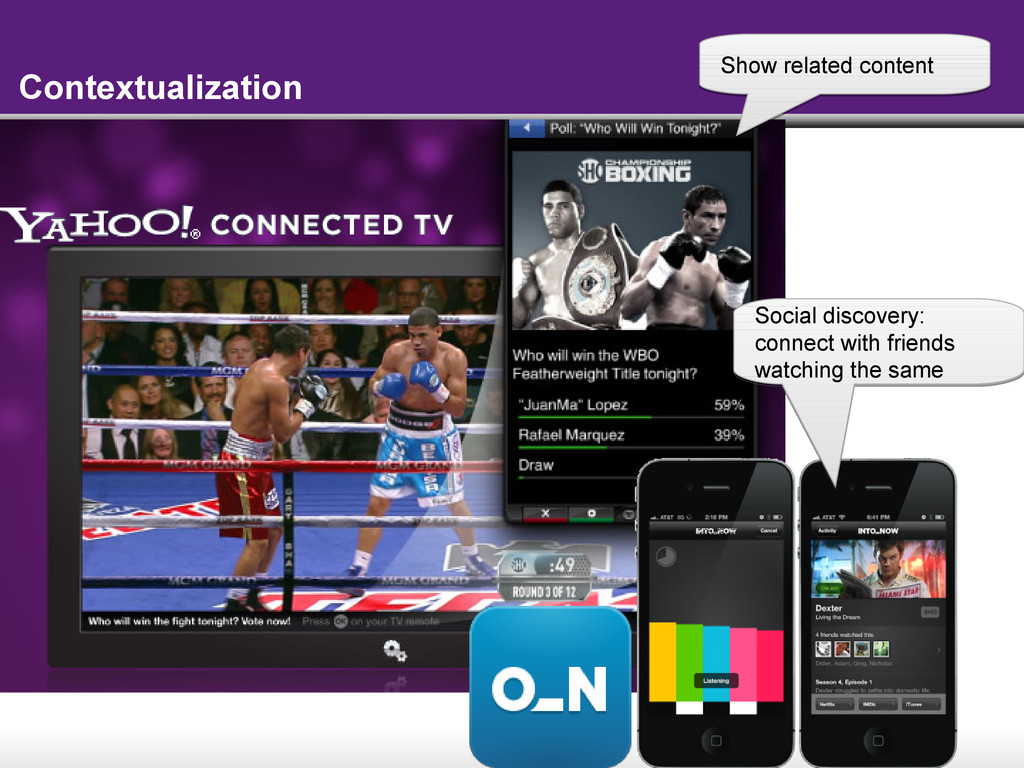{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
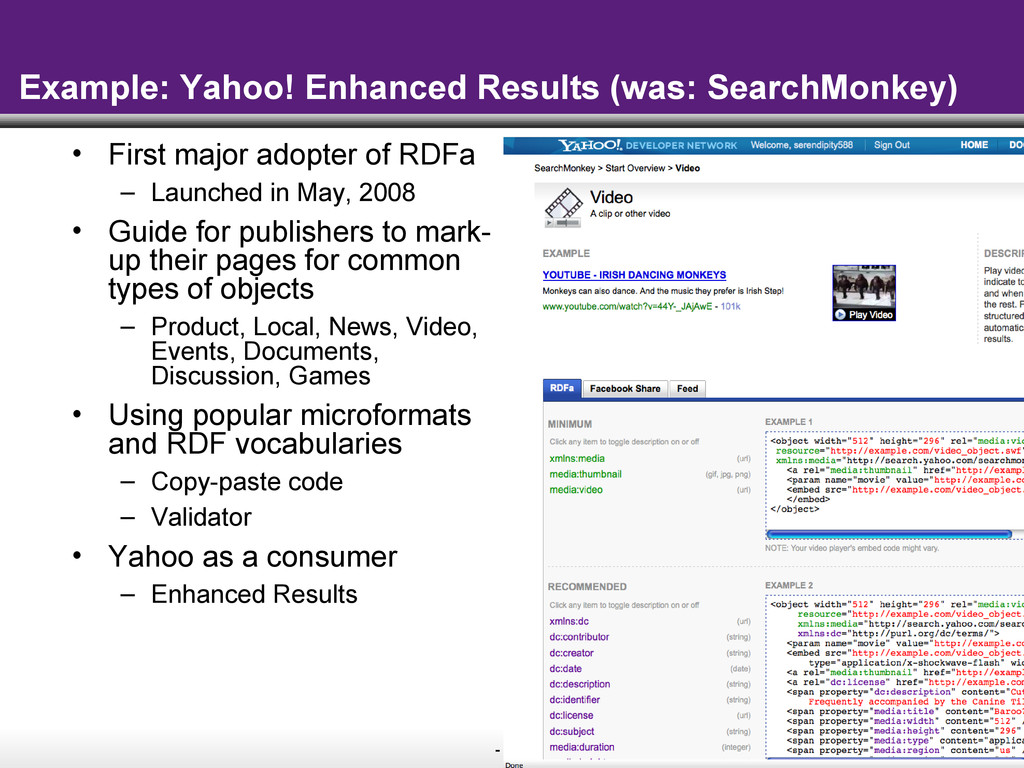{kind=link}
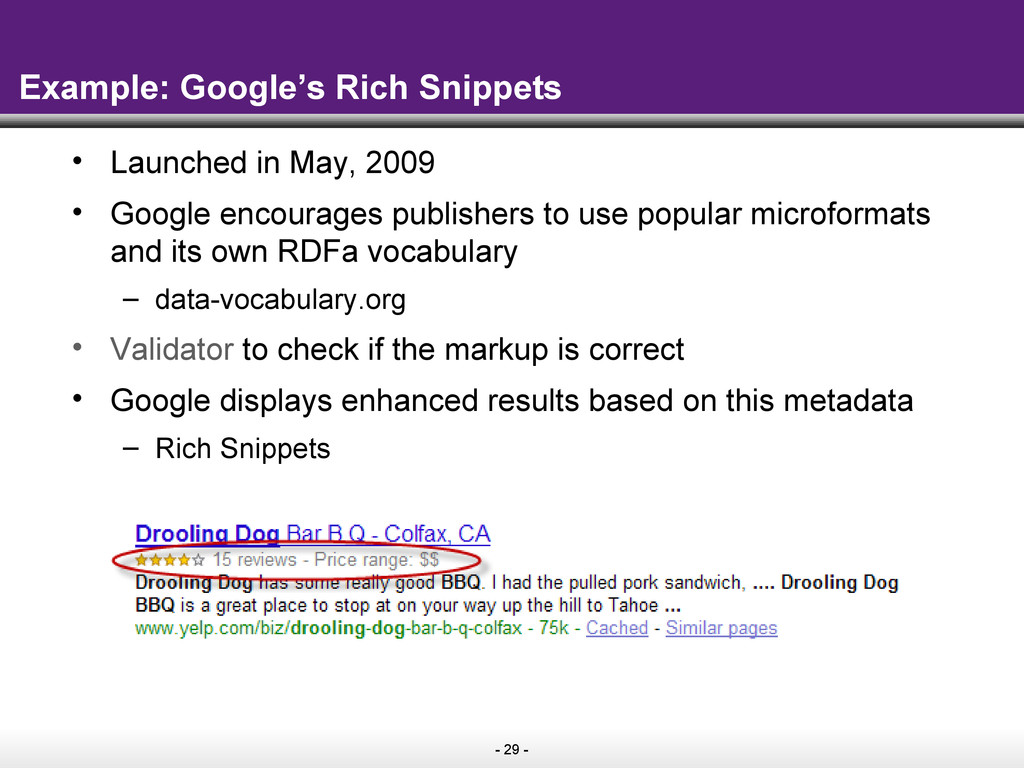{kind=link}
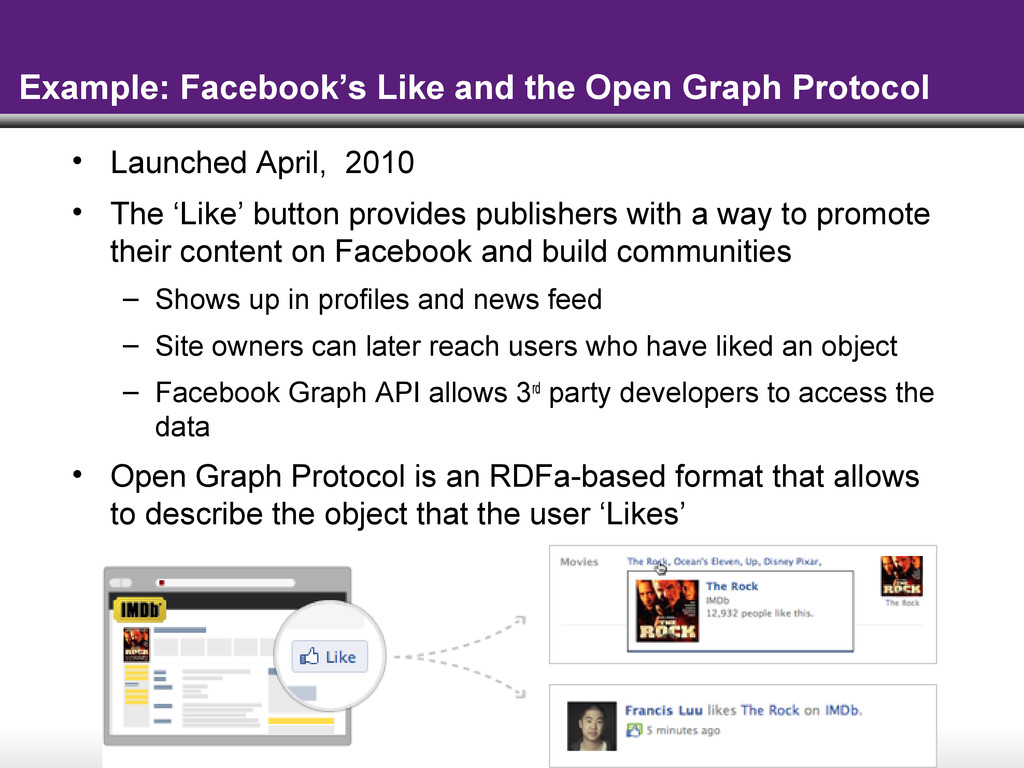{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
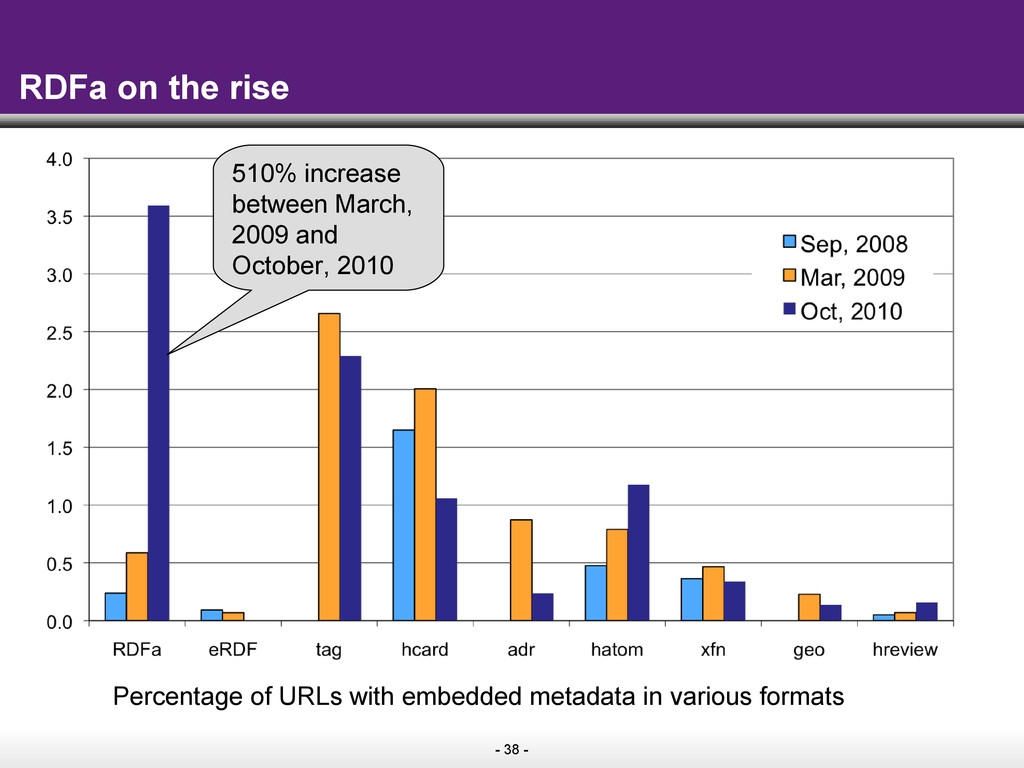{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}