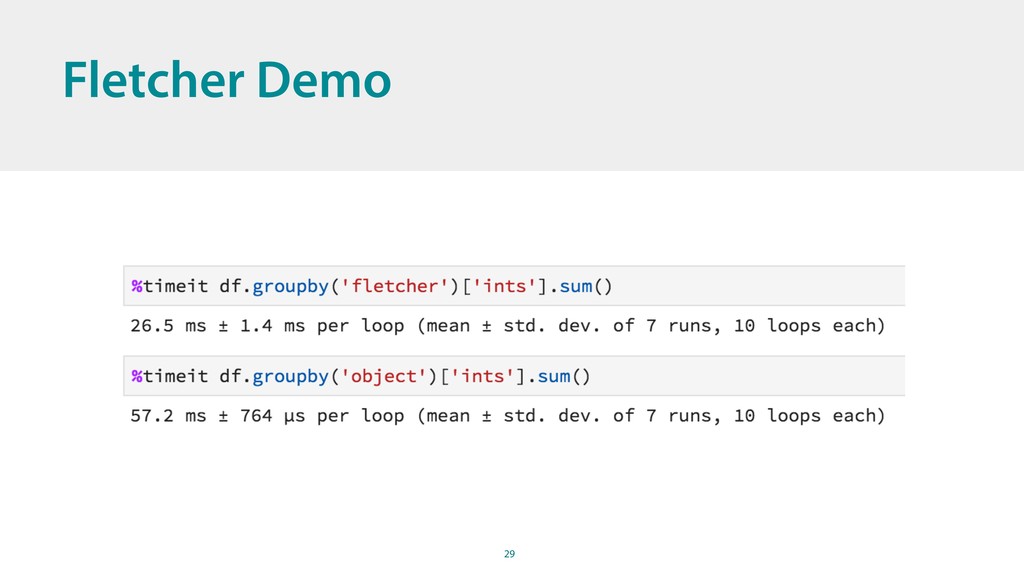
With the latest release of Pandas the ability to extend it with custom dtypes was introduced. Using Apache Arrow as the in-memory storage and Numba for fast, vectorized computations on these memory regions, it is possible to extend Pandas in pure Python while achieving the same performance of the built-in types. In the talk we implement a native string type as an example.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
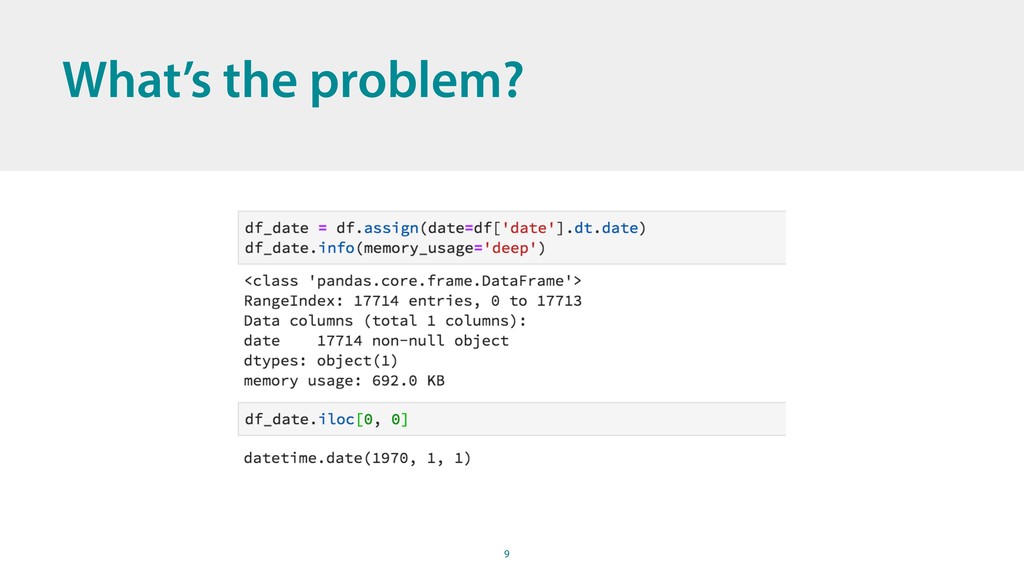{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
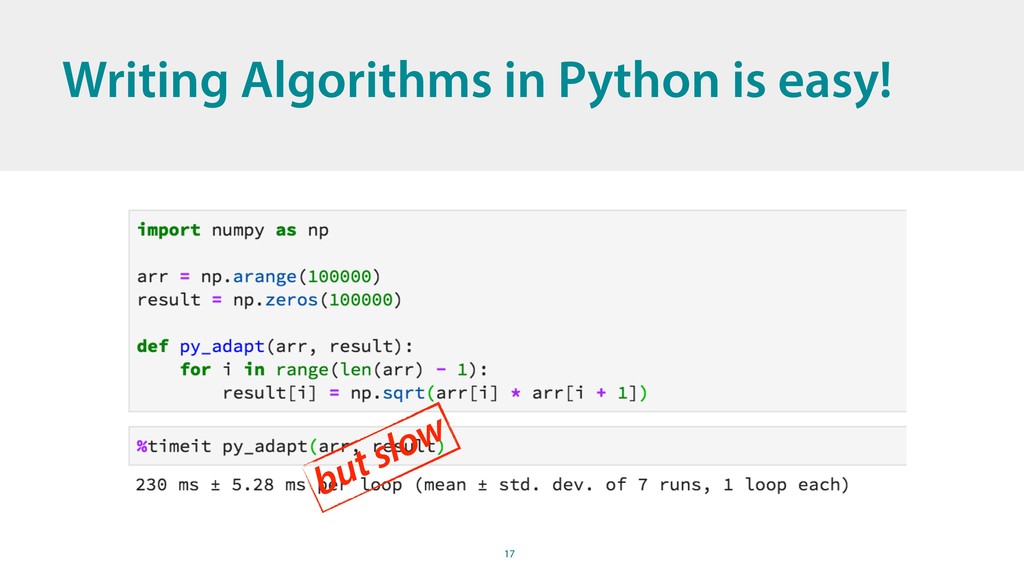{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
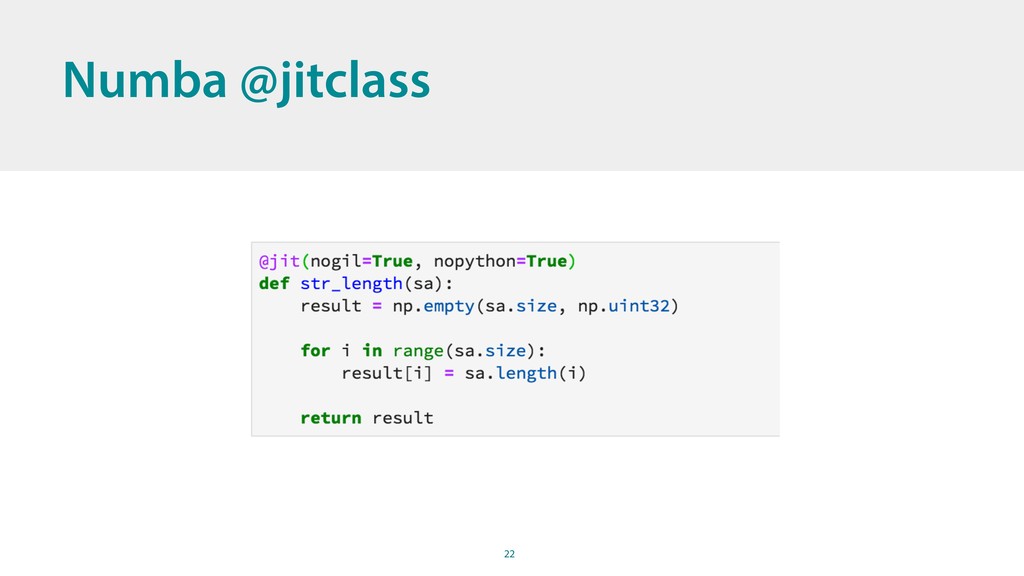{kind=link}
{kind=link}
{kind=link}
{kind=link}
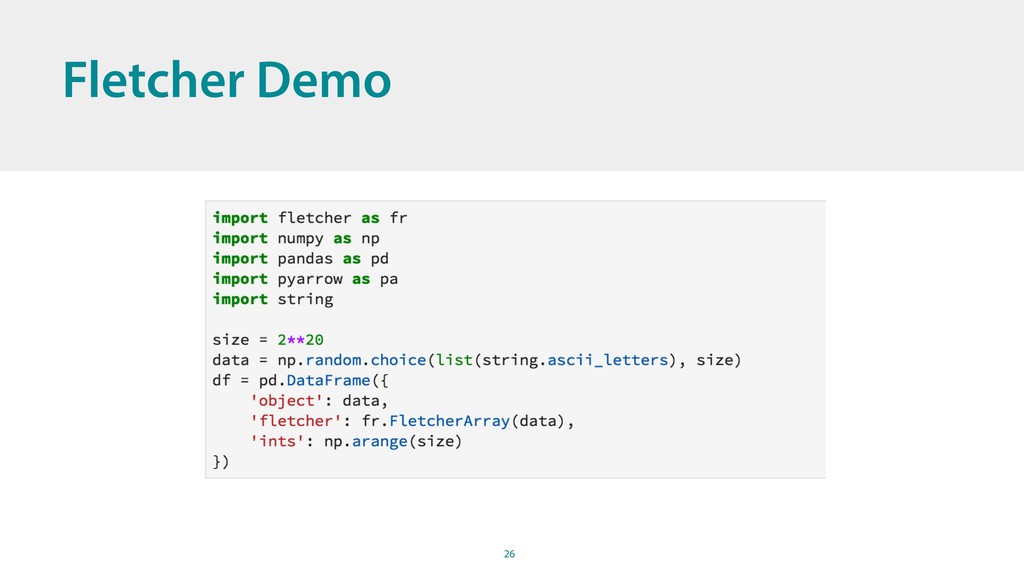{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![32 By JOEXX (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via](https://files.speakerdeck.com/presentations/d7308179a06b48788afb5e15924d370a/slide_31.jpg){kind=link}
{kind=link}