Pandas provides convenience methods to read and write to databases using to_sql and read_sql. They provide great usability and a uniform interface for all databases that support an SQL Alchemy connection. Sadly, the layer of convenience also introduces a performance loss. Luckily, for a lot of databases, a performant access layer is available.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![How does it work (read_sql)? • pandas.read_sql [1] calls SQLDatabase.read_query](https://files.speakerdeck.com/presentations/9c016f4b9ee0405e9313bbd4e6adbbb1/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
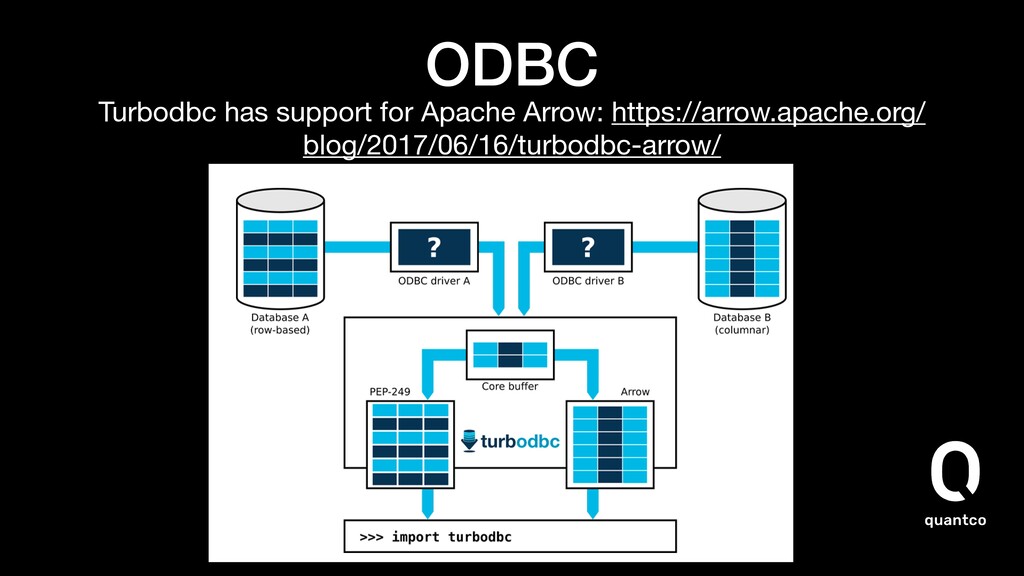{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}