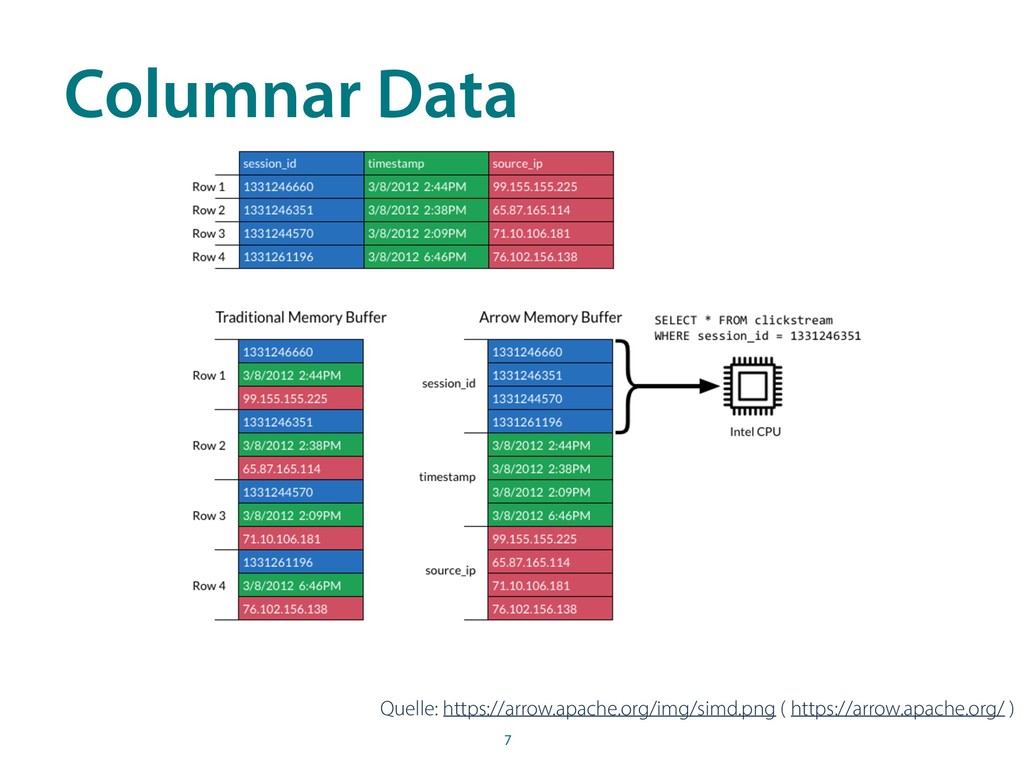
Die Landschaft der Big-Data-Systeme ist ständig am Wachsen. Es entstehen kontinuierlich neue Tools für Data Warehousing, Data Engineering und Machine Learning. Jedes dieser Felder hat sein eigenes Ökosystem und bevorzugte Programmiersprache. Jedoch müssen diese Bereiche alle zusammenarbeiten, um ein erfolgreiches Datenprodukt bauen und betreiben zu können. Apache Arrow setzt hier an und definiert einen Standard und Bibliotheken für den Datenaustausch, um diese System hocheffizient zu verknüpfen. Ein aktuelles Beispiel der Nutzung von Arrow ist die Anwendung in Apache Spark, um das in Scala geschriebene System mit effizienten Funktion aus Python mit Pandas erweiterbar zu machen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}