Lock in $30 Savings on PRO—Offer Ends Soon! ⏳
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
もう一度理解するTransformer(後編)
Search
winnie279
September 06, 2022
Science
0
84
もう一度理解するTransformer(後編)
もう一度理解するTransformer(後編), 中村勇士, 2022
winnie279
September 06, 2022
Tweet
Share
More Decks by winnie279
See All by winnie279
NowWay:訪⽇外国⼈旅⾏者向けの災害⽀援サービス
yjn279
0
5
「みえるーむ」(都知事杯Open Data Hackathon 2024 Final Stage)
yjn279
0
66
「みえるーむ」(都知事杯オープンデータ・ハッカソン 2024)
yjn279
0
70
5分で学ぶOpenAI APIハンズオン
yjn279
0
210
『確率思考の戦略論』
yjn279
0
140
Amazonまでのレコメンド入門
yjn279
1
180
金研究室 勉強会 『もう一度理解する Transformer(前編)』
yjn279
0
110
金研究室 勉強会 『U-Netとそのバリエーションについて』
yjn279
0
800
金研究室 勉強会 『Seismic Data Augmentation Based on Conditional Generative Adversarial Networks』
yjn279
0
100
Other Decks in Science
See All in Science
NASの容量不足のお悩み解決!災害対策も兼ねた「Wasabi Cloud NAS」はここがスゴイ
climbteam
1
270
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
700
データマイニング - グラフデータと経路
trycycle
PRO
1
260
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1k
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.1k
知能とはなにかーヒトとAIのあいだー
tagtag
0
160
AI(人工知能)の過去・現在・未来 —AIは人間を超えるのか—
tagtag
0
130
Vibecoding for Product Managers
ibknadedeji
0
120
蔵本モデルが解き明かす同期と相転移の秘密 〜拍手のリズムはなぜ揃うのか?〜
syotasasaki593876
1
150
Hakonwa-Quaternion
hiranabe
1
160
DMMにおけるABテスト検証設計の工夫
xc6da
1
1.4k
タンパク質間相互作⽤を利⽤した⼈⼯知能による新しい薬剤遺伝⼦-疾患相互作⽤の同定
tagtag
0
120
Featured
See All Featured
Testing 201, or: Great Expectations
jmmastey
46
7.8k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
37
2.6k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Leading Effective Engineering Teams in the AI Era
addyosmani
8
1.3k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
54k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
Speed Design
sergeychernyshev
33
1.4k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
9
1k
Optimizing for Happiness
mojombo
379
70k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
It's Worth the Effort
3n
187
29k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Transcript
もう一度理解する Transformer(後編) 金研 機械学習勉強会 2022/09/06 中村勇士
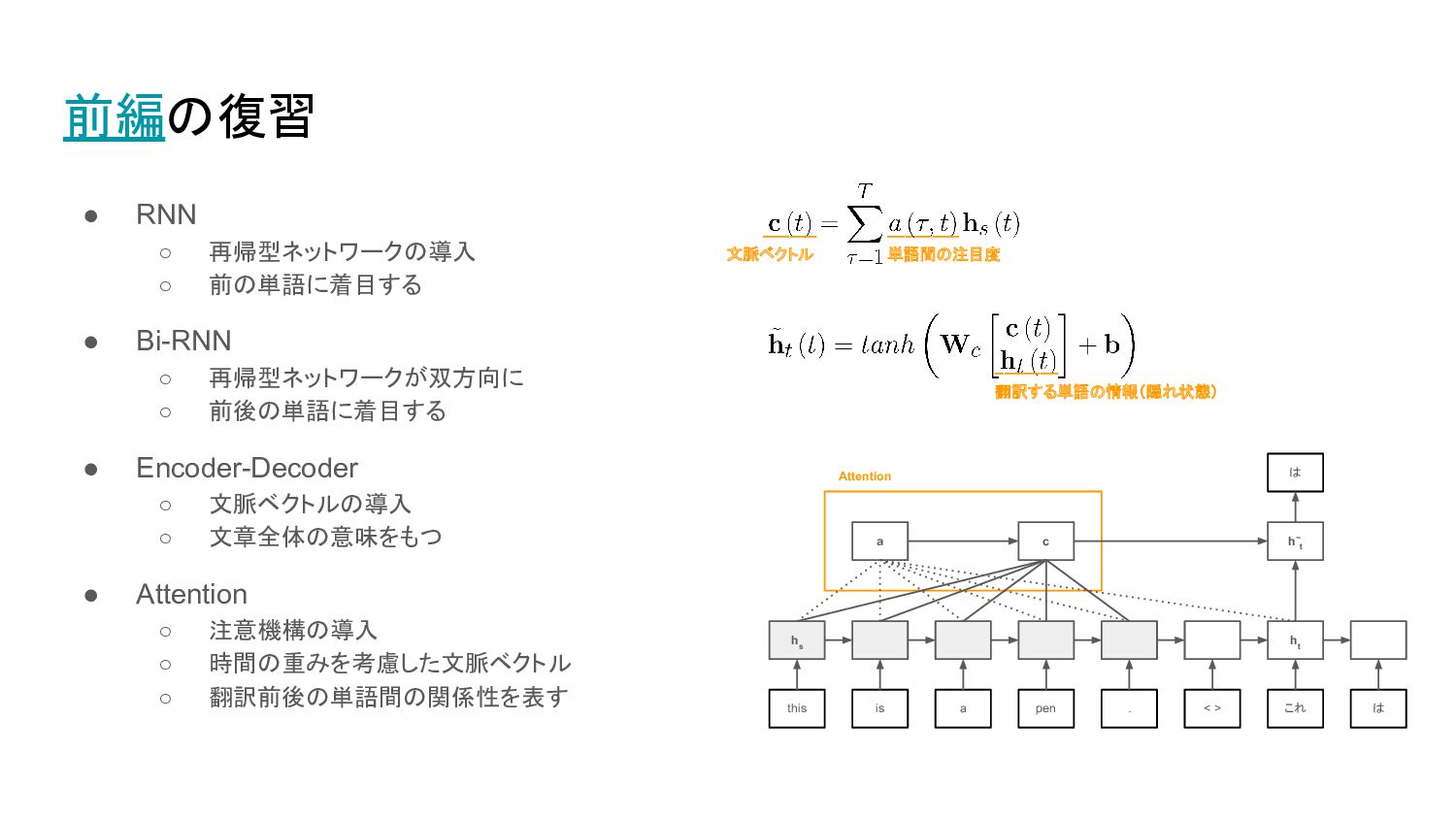
–––––––– 単語間の注目度 前編の復習 • RNN ◦ 再帰型ネットワークの導入 ◦ 前の単語に着目する •
Bi-RNN ◦ 再帰型ネットワークが双方向に ◦ 前後の単語に着目する • Encoder-Decoder ◦ 文脈ベクトルの導入 ◦ 文章全体の意味をもつ • Attention ◦ 注意機構の導入 ◦ 時間の重みを考慮した文脈ベクトル ◦ 翻訳前後の単語間の関係性を表す this h s h t h~ t c a is . a pen < > これ は は Attention –––––– 文脈ベクトル ––––––– 翻訳する単語の情報(隠れ状態)
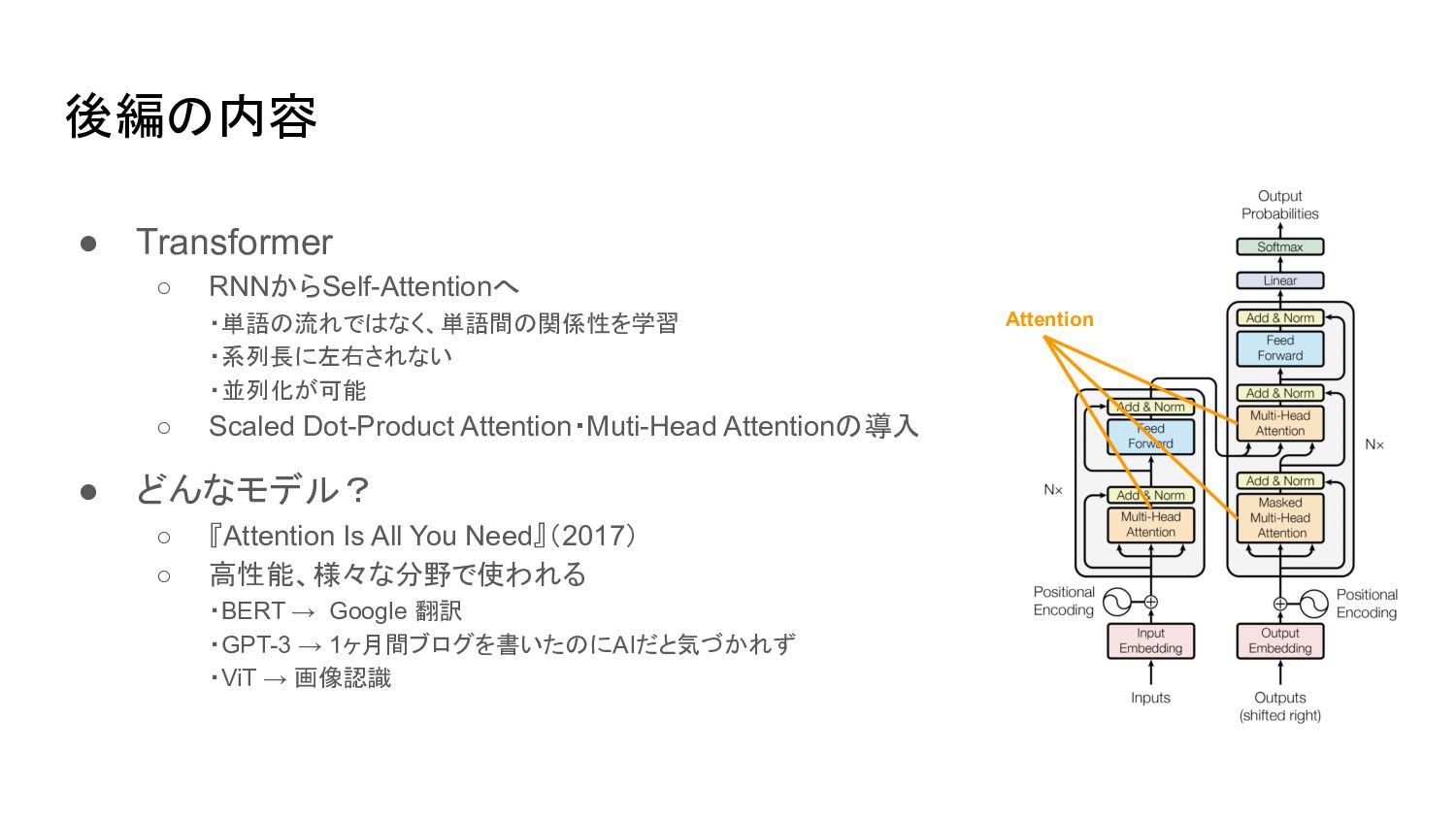
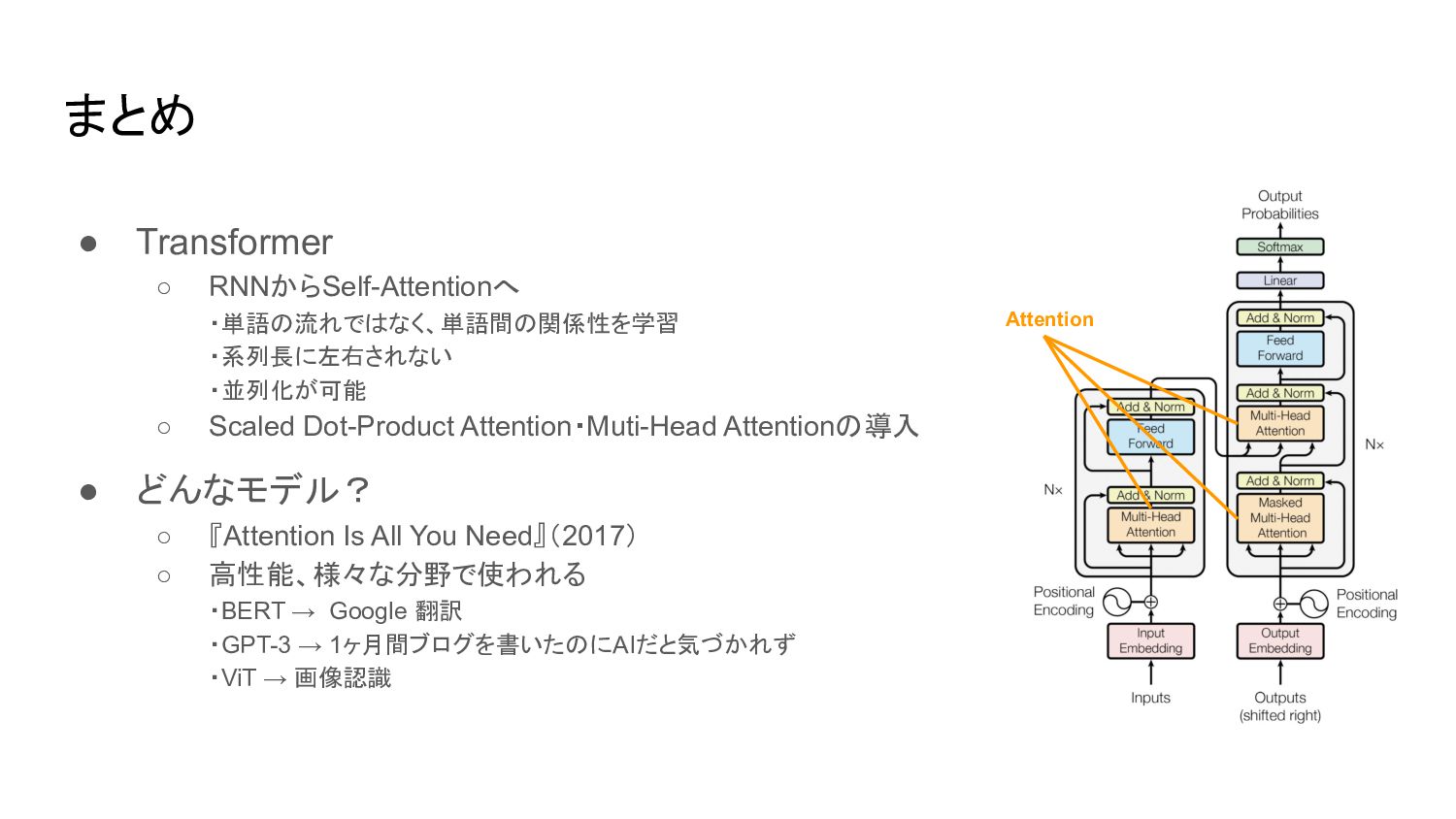
• Transformer ◦ RNNからSelf-Attentionへ ・単語の流れではなく、単語間の関係性を学習 ・系列長に左右されない ・並列化が可能 ◦ Scaled Dot-Product
Attention・Muti-Head Attentionの導入 • どんなモデル? ◦ 『Attention Is All You Need』(2017) ◦ 高性能、様々な分野で使われる ・BERT → Google 翻訳 ・GPT-3 → 1ヶ月間ブログを書いたのにAIだと気づかれず ・ViT → 画像認識 後編の内容 Attention
• Multi-Head Attention ◦ Scaled Dot-Product Attentionを結合 Scaled Dot-Product /
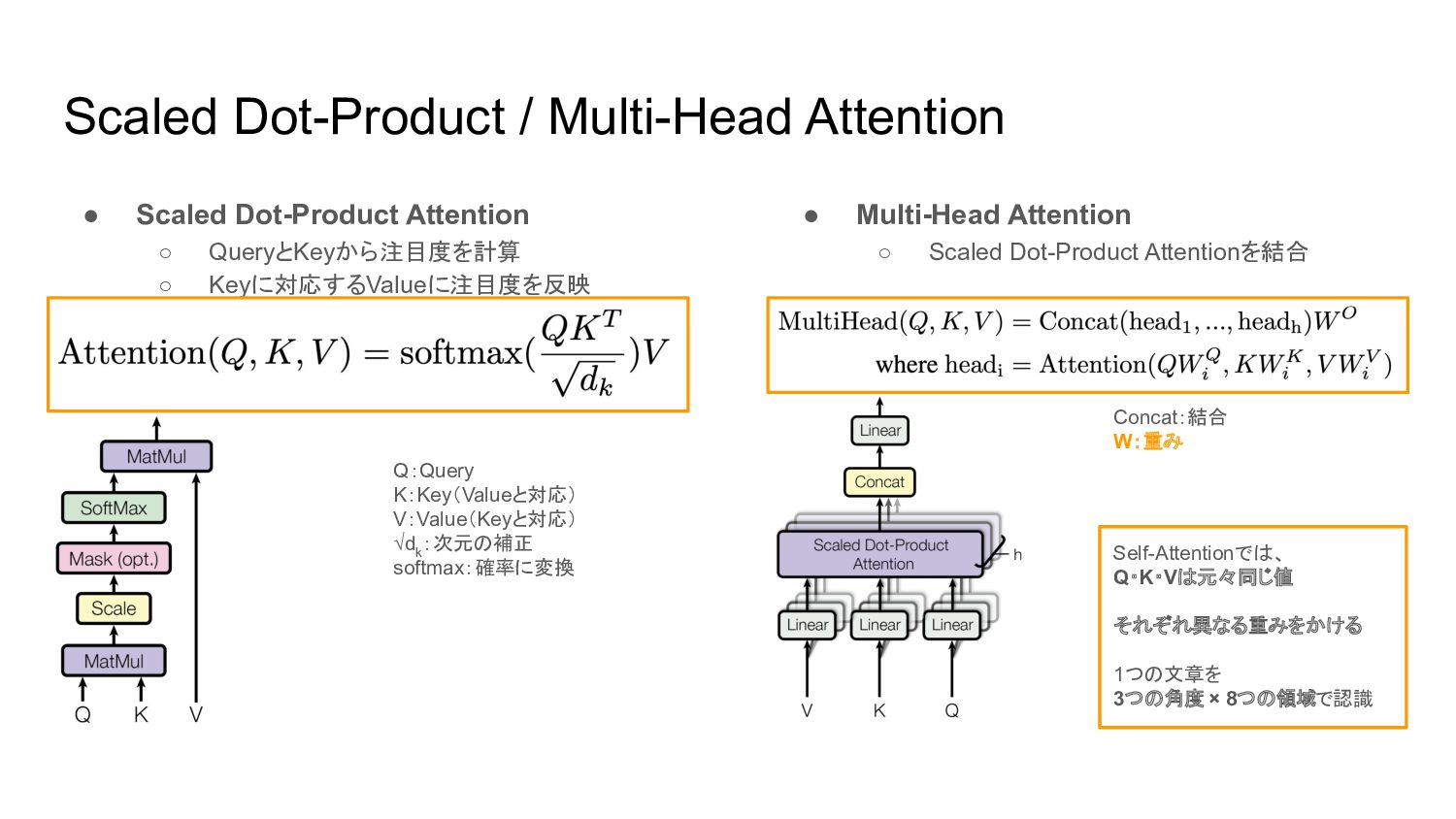
Multi-Head Attention • Scaled Dot-Product Attention ◦ QueryとKeyから注目度を計算 ◦ Keyに対応するValueに注目度を反映 Q:Query K:Key(Valueと対応) V:Value(Keyと対応) √d k :次元の補正 softmax:確率に変換 –––––––––––––––––––––––––––– 注目度 Concat:結合 W:重み
• Multi-Head Attentionの使い方の話 ◦ 今まで: 翻訳前後の単語間の関係性に注目 ◦ Self-Attention: 文章内の単語間の関係性に注目 ◦
RNNからSelf-Attentionへ Self-Attention V K Q V K Q Self-Attention Attention
Concat:結合 W:重み • Multi-Head Attention ◦ Scaled Dot-Product Attentionを結合 Scaled
Dot-Product / Multi-Head Attention • Scaled Dot-Product Attention ◦ QueryとKeyから注目度を計算 ◦ Keyに対応するValueに注目度を反映 Q:Query K:Key(Valueと対応) V:Value(Keyと対応) √d k :次元の補正 softmax:確率に変換 Self-Attentionでは、 Q・K・Vは元々同じ値 それぞれ異なる重みをかける 1つの文章を 3つの角度 × 8つの領域で認識
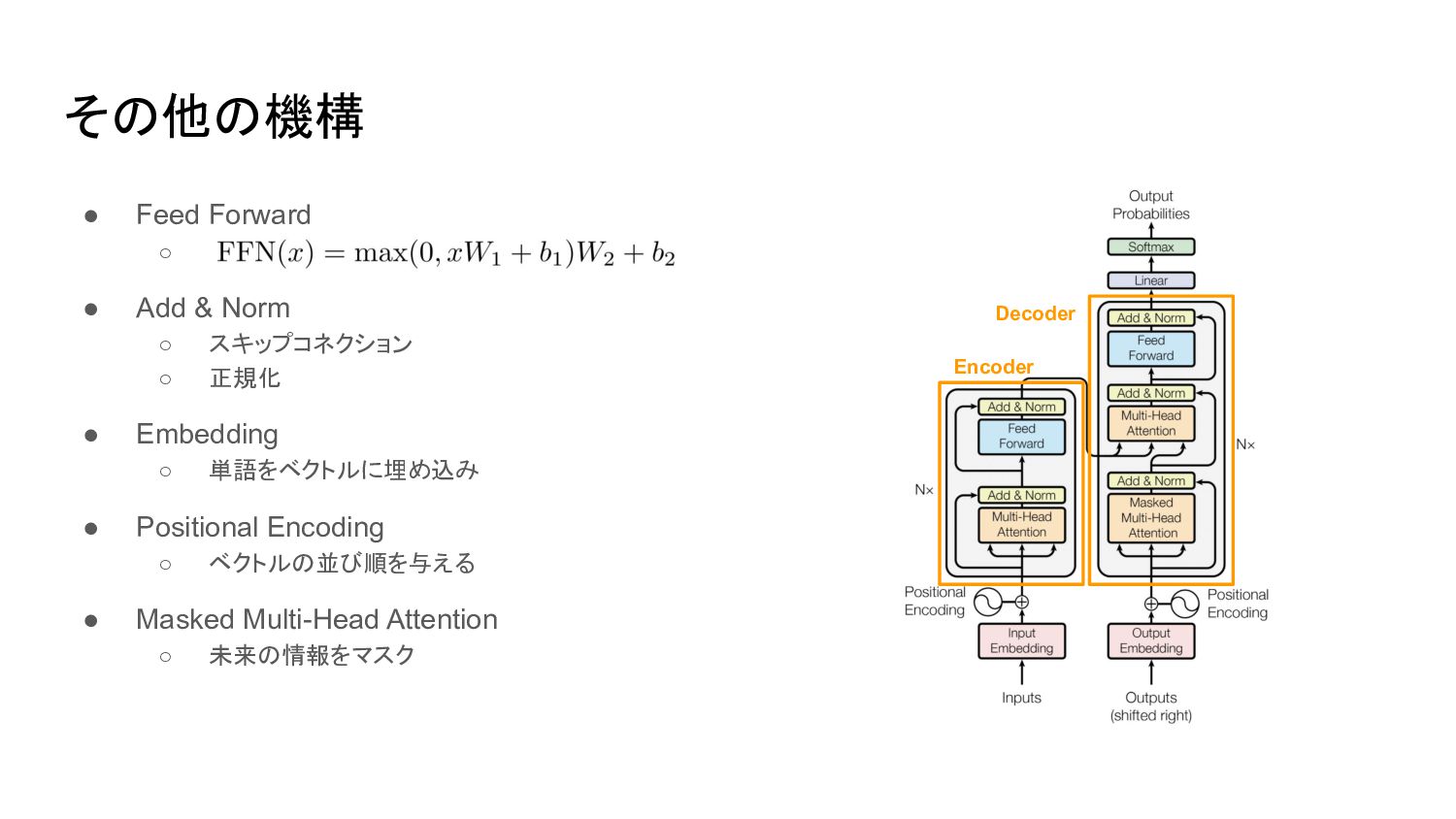
• Feed Forward ◦ • Add & Norm ◦ スキップコネクション
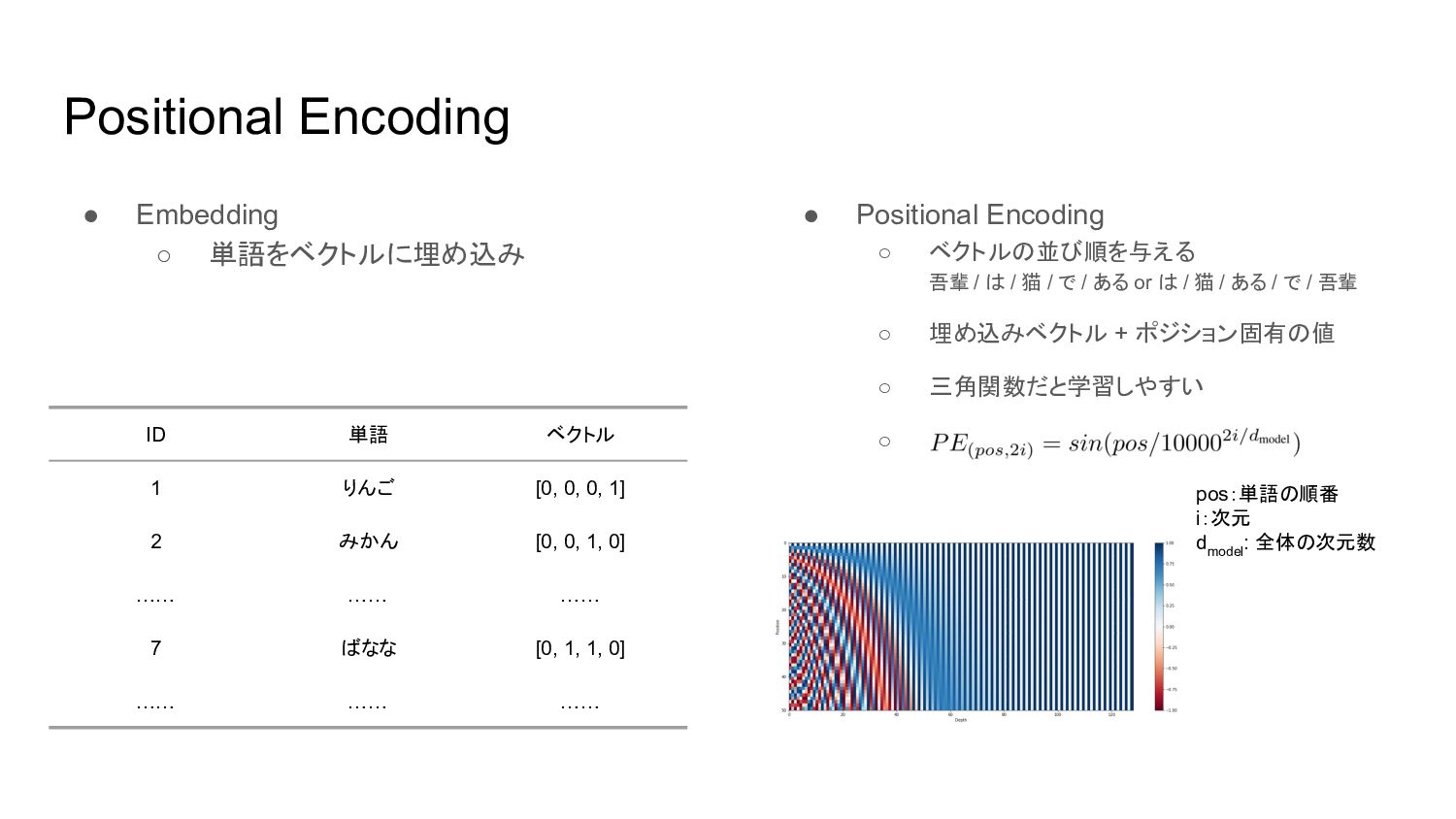
◦ 正規化 • Embedding ◦ 単語をベクトルに埋め込み • Positional Encoding ◦ ベクトルの並び順を与える • Masked Multi-Head Attention ◦ 未来の情報をマスク その他の機構 Encoder Decoder
• Positional Encoding ◦ ベクトルの並び順を与える 吾輩 / は / 猫
/ で / ある or は / 猫 / ある / で / 吾輩 ◦ 埋め込みベクトル + ポジション固有の値 ◦ 三角関数だと学習しやすい ◦ Positional Encoding • Embedding ◦ 単語をベクトルに埋め込み ID 単語 ベクトル 1 りんご [0, 0, 0, 1] 2 みかん [0, 0, 1, 0] …… …… …… 7 ばなな [0, 1, 1, 0] …… …… …… pos:単語の順番 i:次元 d model : 全体の次元数
• Transformer ◦ RNNからSelf-Attentionへ ・単語の流れではなく、単語間の関係性を学習 ・系列長に左右されない ・並列化が可能 ◦ Scaled Dot-Product
Attention・Muti-Head Attentionの導入 • どんなモデル? ◦ 『Attention Is All You Need』(2017) ◦ 高性能、様々な分野で使われる ・BERT → Google 翻訳 ・GPT-3 → 1ヶ月間ブログを書いたのにAIだと気づかれず ・ViT → 画像認識 まとめ Attention
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}