A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
長岡技術科学大学
自然言語処理研究室
文献紹介(2019-10-21)
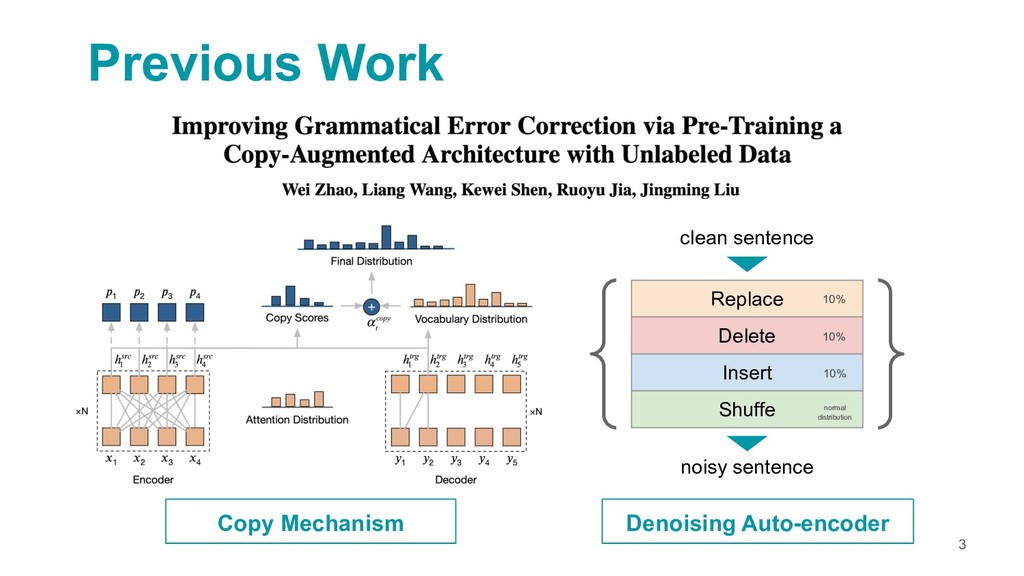
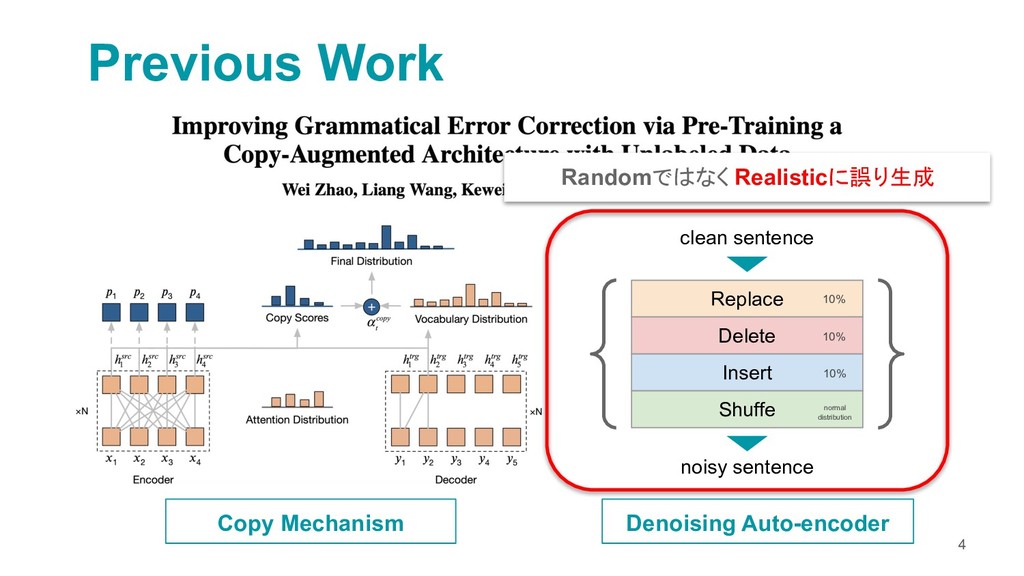
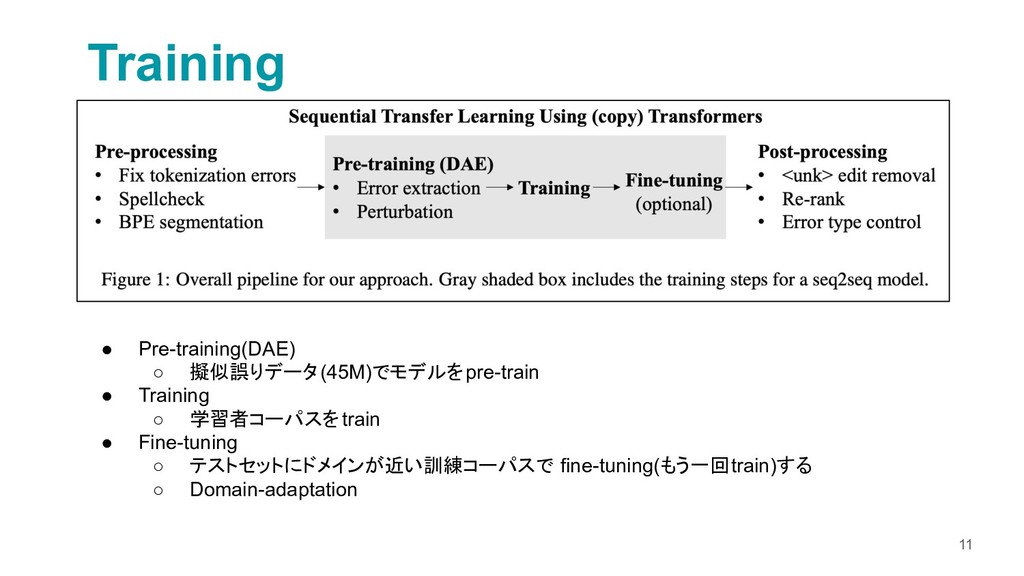
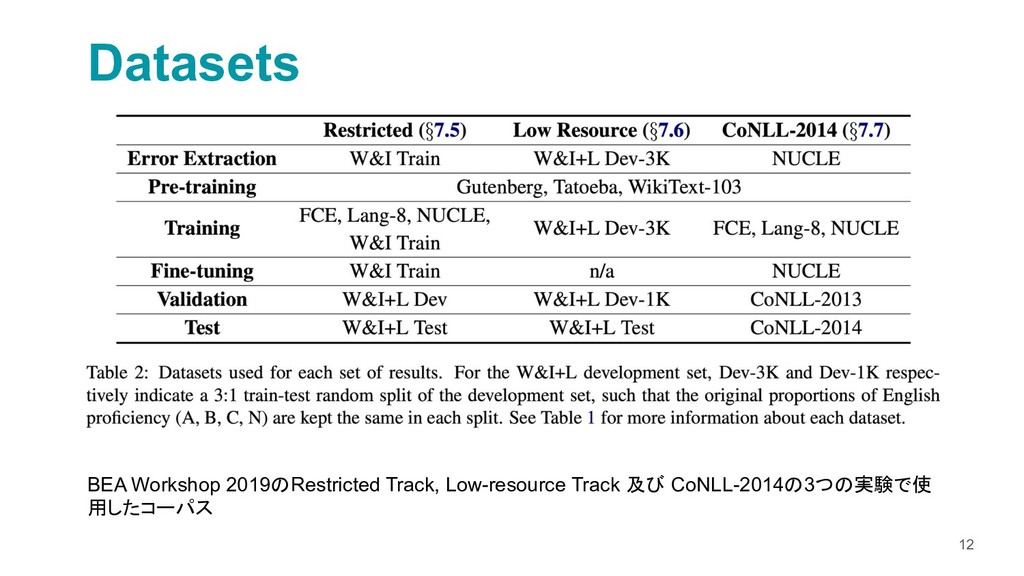
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
https://www.aclweb.org/anthology/W19-4423.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![7 Realistic Noising Method token-based type-based Prepare • GECコーパスから[訂正前→訂正後]の編集ペアを収集 (EditDict)](https://files.speakerdeck.com/presentations/2aee06516a2044a08144bf95618f9be3/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
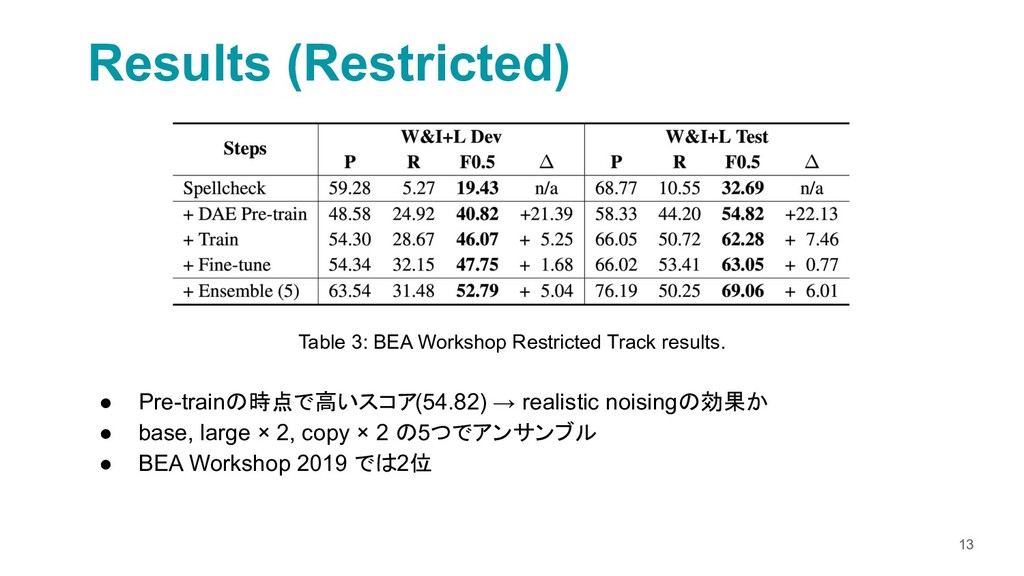{kind=link}
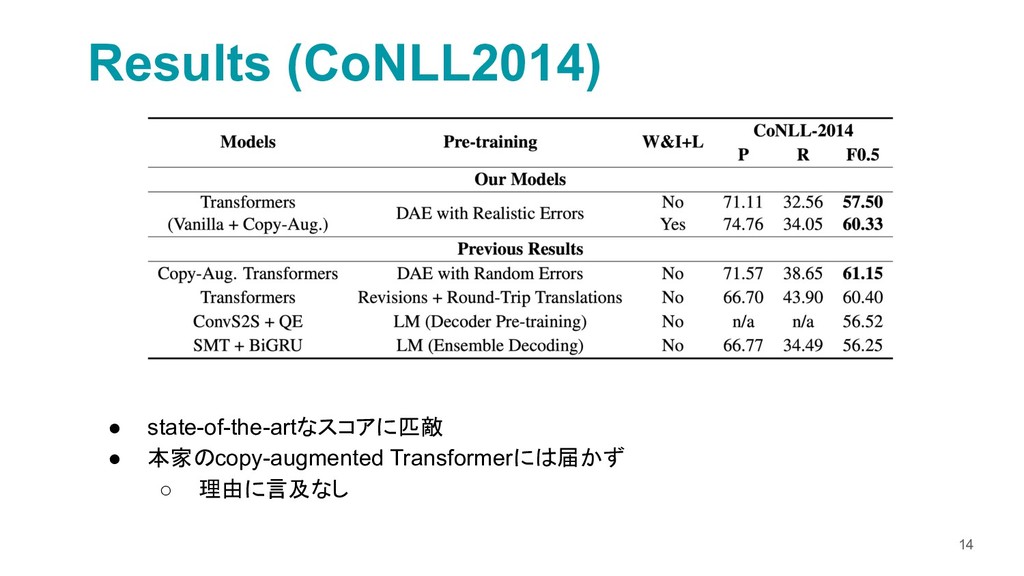{kind=link}
{kind=link}
{kind=link}
{kind=link}
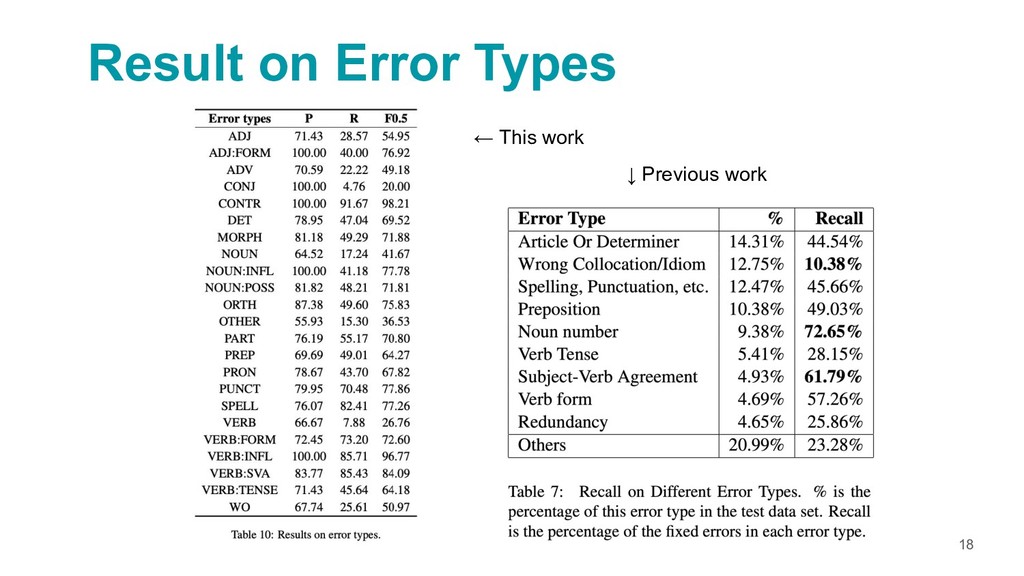{kind=link}
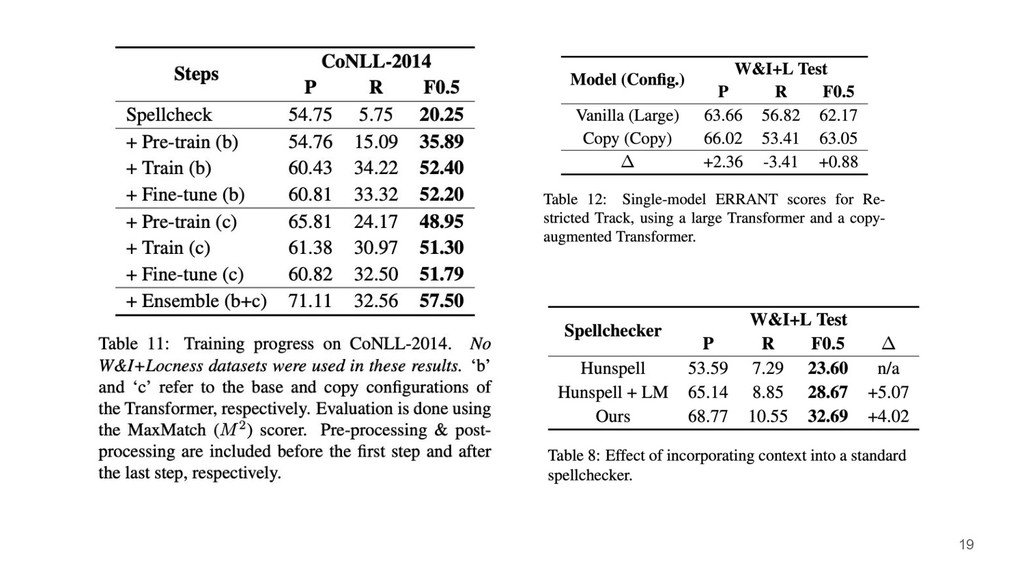{kind=link}