adverse consequences. Recovery a return to a normal state of health, mind, or strength. Testing is the action of checking that someone or something is working as it is expected.
turbulent conditions. Focus: Test reactive response and recovery procedures in the event of a catastrophic failure or disaster. Disaster Recovery Testing Chaos Engineering
network latency, server outages) to observe system behavior and uncover hidden vulnerabilities. Method: Involves simulating a major outage (e.g., data center failure) and testing the ability to restore systems and data within a defined recovery time objective (RTO).. Disaster Recovery Testing Chaos Engineering
unexpected disruptions and improve overall resilience. Goal: To minimize downtime and data loss in the event of a major disruption, ensuring business continuity. Disaster Recovery Testing Chaos Engineering
people, preparation, processes, and response tools. It's about learning and finding single points of failure—therefore the scope of services and systems is broad. Intentionally disrupt services in order to know how to respond and provide reliability. Established in 2006 to exercise response to production emergencies.
known bugs Infrastructure Stress testing large complex architectures, validating SLOs, and ensuring resilience is maintained during disruption. Access Controls Including security, compliance, and privacy. What does Google Test? People and Workflows Removing people who might have knowledge or experience.
product [no expected impact external]. Tier 3 Testing resilience dependencies of a shared system or product. Tier 2 Testing resilience of organizational response to an enterprise level event. Tier 1
bad configuration file is included in the next release generating more CPU and Memory consumption. This impacts only the users of an experimental feature in a product. Response • Incident management protocols from service’s owners. • The continuous testing of the services defined by the owners. • Validating disaster readiness and response of a service and the team. • Identification and expansion of standard tests that can be used to de-risk Tier 2 and Tier 1 testing. What can you learn? • If a team is able to effectively perform IMAG. • If a service is resilient to a specific class of failure. • If the service is not overly dependent on a specific resource.
large traffic spike degrades the latency of a heavily used shared internal service. The service remains barely within its published SLA for an extended period. Response • Communication to key service consumers. • Incident management protocols from service’s owners. • Emergency serving capacity increases. • Graceful degradation and external messaging to customers. What can you learn? • Do service consumers tolerate worst case scenarios, or do they assume the average experience as a baseline? • Do your alerting and monitoring systems behave the way you want for both service providers and consumers in this scenario?
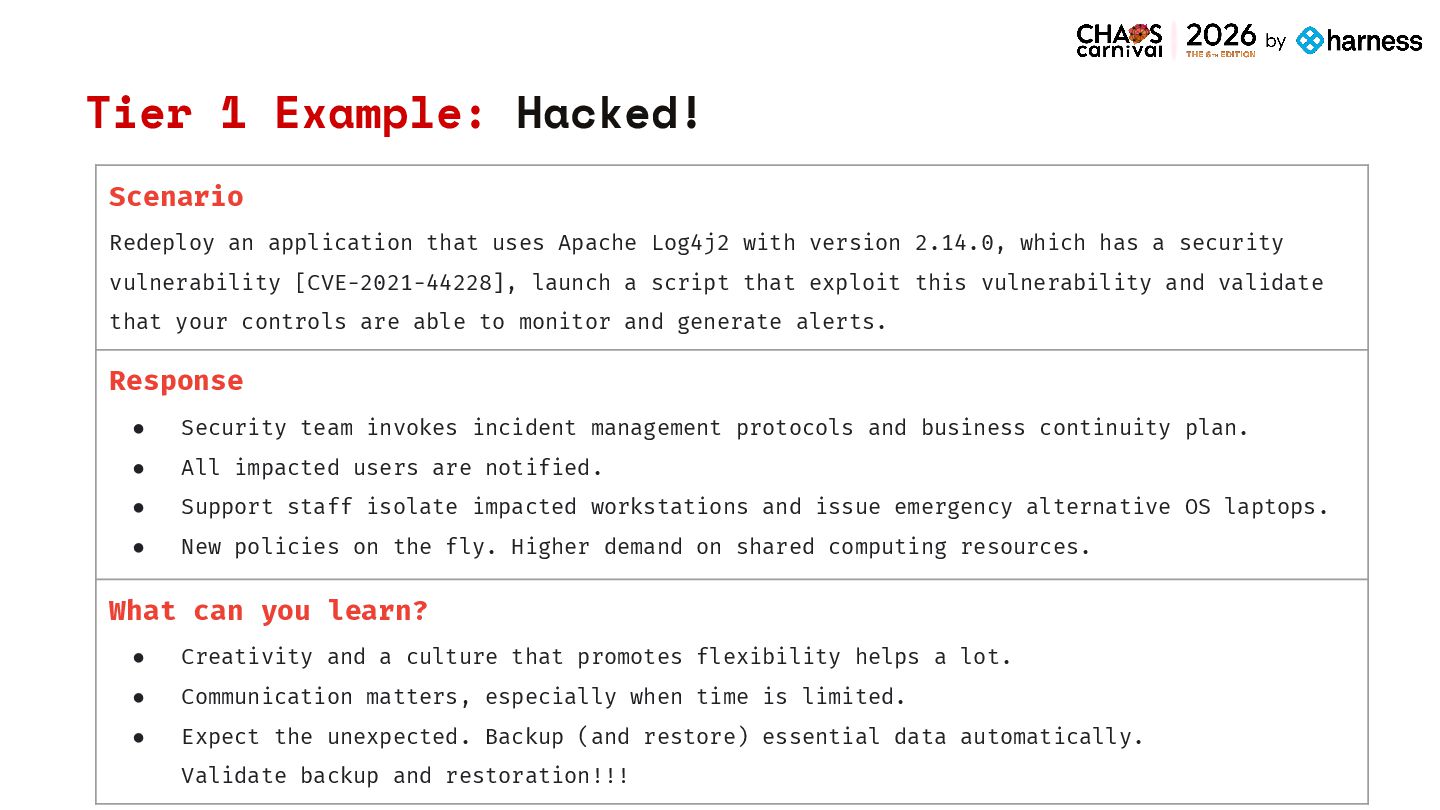
2.14.0, which has a security vulnerability [CVE-2021-44228], launch a script that exploit this vulnerability and validate that your controls are able to monitor and generate alerts. Response • Security team invokes incident management protocols and business continuity plan. • All impacted users are notified. • Support staff isolate impacted workstations and issue emergency alternative OS laptops. • New policies on the fly. Higher demand on shared computing resources. What can you learn? • Creativity and a culture that promotes flexibility helps a lot. • Communication matters, especially when time is limited. • Expect the unexpected. Backup (and restore) essential data automatically. Validate backup and restoration!!! Tier 1 Example: Hacked!
project that routes traffic destined for IP addresses of some of their hosts in-region (say, VMs running MySQL DBs) to some other project where the traffic is dropped. Reversion is by deleting the rule. Chief risk is that more traffic than expected is captured by the rule, so the outage is bigger than planned. Redirect Traffic Away from a region using a Load Balancer The customer can remove a backend from a load balancers load balancers and drain connections. This can be used to simulate failover from one zone or one region to another by removing a managed instance group that includes all the resources in one zone or region, forcing the LB to send the traffic to another region. The risk is that the resources making up the GCLB backends will still remain up but will not serve any traffic. Practical Examples
failures (e.g., data center outages). To understand system behavior and improve reliability by intentionally causing failures in a controlled manner. Disaster Recovery Testing Chaos Engineering
loss, hardware failures, or site outages. Simulates everyday failures like service crashes, latency spikes, or network disruptions. Disaster Recovery Testing Chaos Engineering
plans and timelines. Uses experiments designed to stress the system in various ways, often run continuously or periodically. Disaster Recovery Testing Chaos Engineering
is usually not fully automated. Highly automated, with tools such as Chaos Monkey that run experiments autonomously. Disaster Recovery Testing Chaos Engineering
and Recovery Point Objective (RPO). Assesses system performance, resilience, and the ability to handle stress under failure scenarios. Disaster Recovery Testing Chaos Engineering
during recovery. Tests system’s ability to self-heal, maintain service levels, and minimize the blast radius of issues. Disaster Recovery Testing Chaos Engineering
after a simulated data center failure. Simulating server outages to see if a distributed system can balance load and maintain performance. Disaster Recovery Testing Chaos Engineering
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}