Japan Work NTT Open Source Software Center/NTT Software Innovation Center Developing distributed databases Interests Distributed transaction Planning Optimization Photography About me
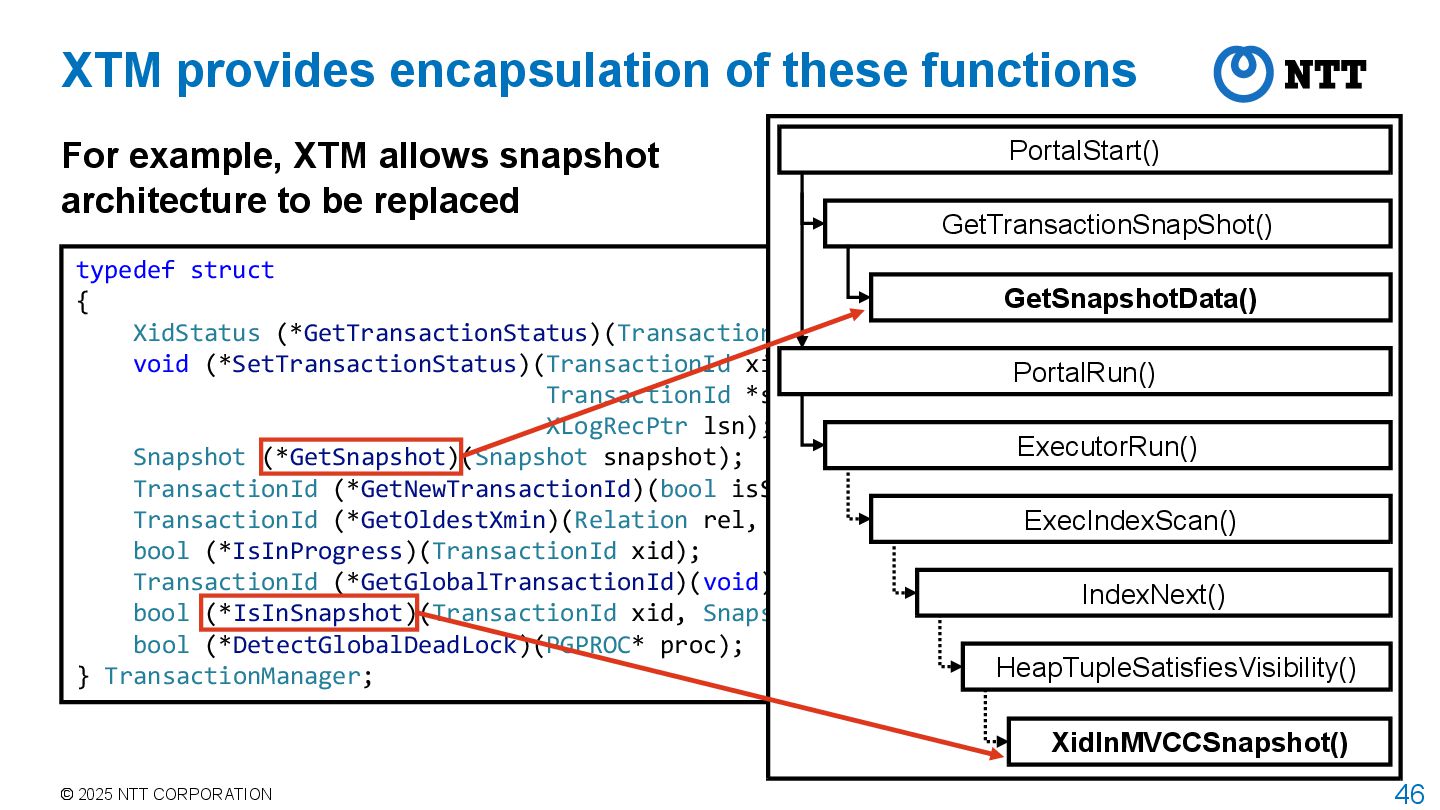
XTM PostgreSQL is well known for its high extensibility Hooks in planner or executor, and access methods, etc. However, PostgreSQL lacks transactional extensibility No hooks or pluggable APIs for replacing the transaction manager Custom transaction methods cannot be implemented as extensions, and forking of the PostgreSQL core is required eXtensible Transaction Manager (XTM) is a promising solution XTM allows the replacement of core transactional APIs • Snapshot mechanism, tuple visibility determinations, etc. XTM was proposed in 2015 by PostgresPro but has not yet been implemented
user-specific requirements The discussion in 2015 mainly focused on implementing state-of-the-art methods Global transaction managers (GTMs), clock-based algorithms, etc. Beyond such purposes, XTM plays an important role in complementing these existing methods to meet user-specific requirements Requirements for distributed transactions vary from user to user • Various patterns of consistency • Performance oriented? Or Consistency oriented? Existing methods do not always satisfy these requirements Using XTM to complement existing methods has not been discussed so far This talk introduces a case study of complementing existing state-of-the-art methods to meet user-specific requirements
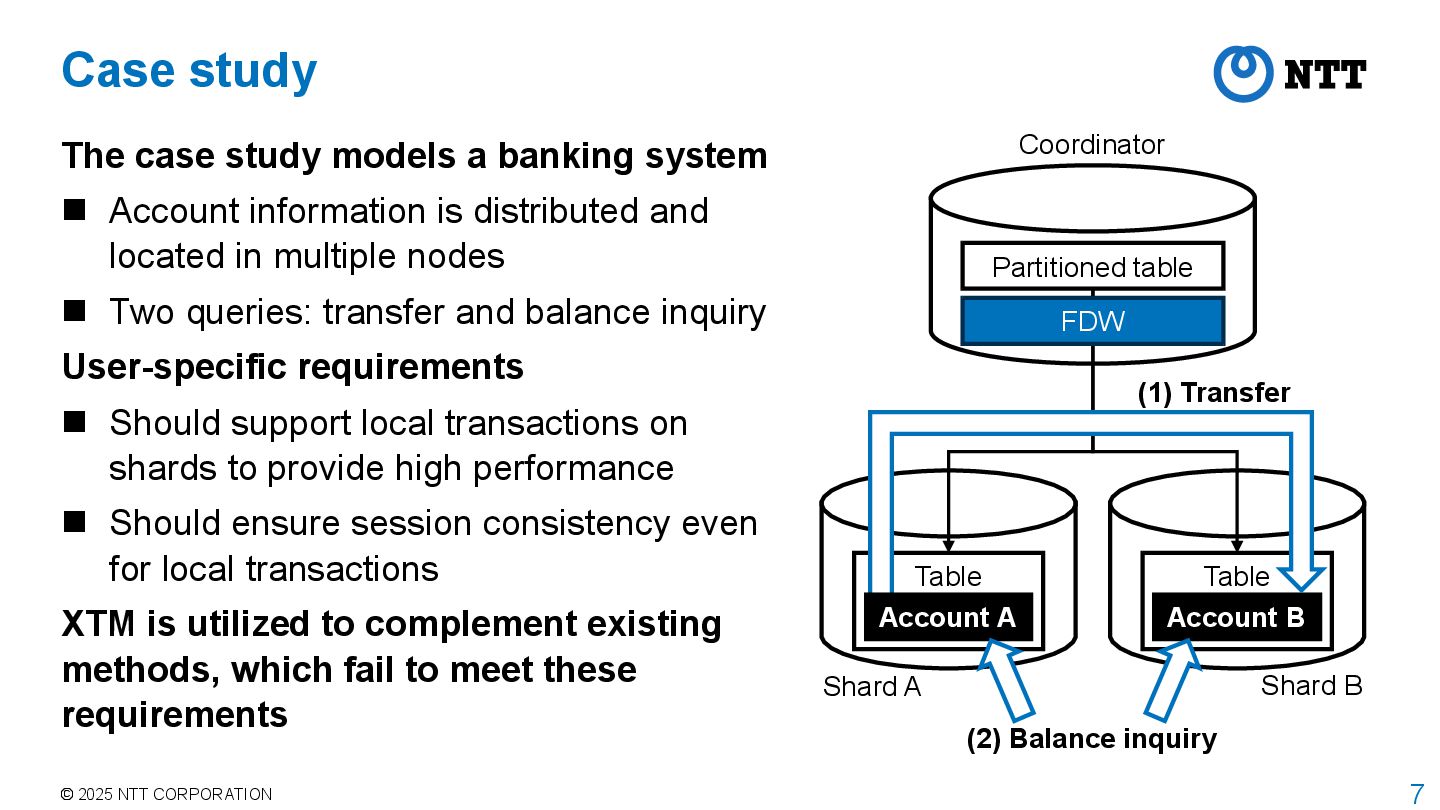
models a banking system Account information is distributed and located in multiple nodes Two queries: transfer and balance inquiry User-specific requirements Should support local transactions on shards to provide high performance Should ensure session consistency even for local transactions XTM is utilized to complement existing methods, which fail to meet these requirements Shard A Shard B (1) Transfer (2) Balance inquiry Partitioned table Coordinator Table Table Account B FDW Account A
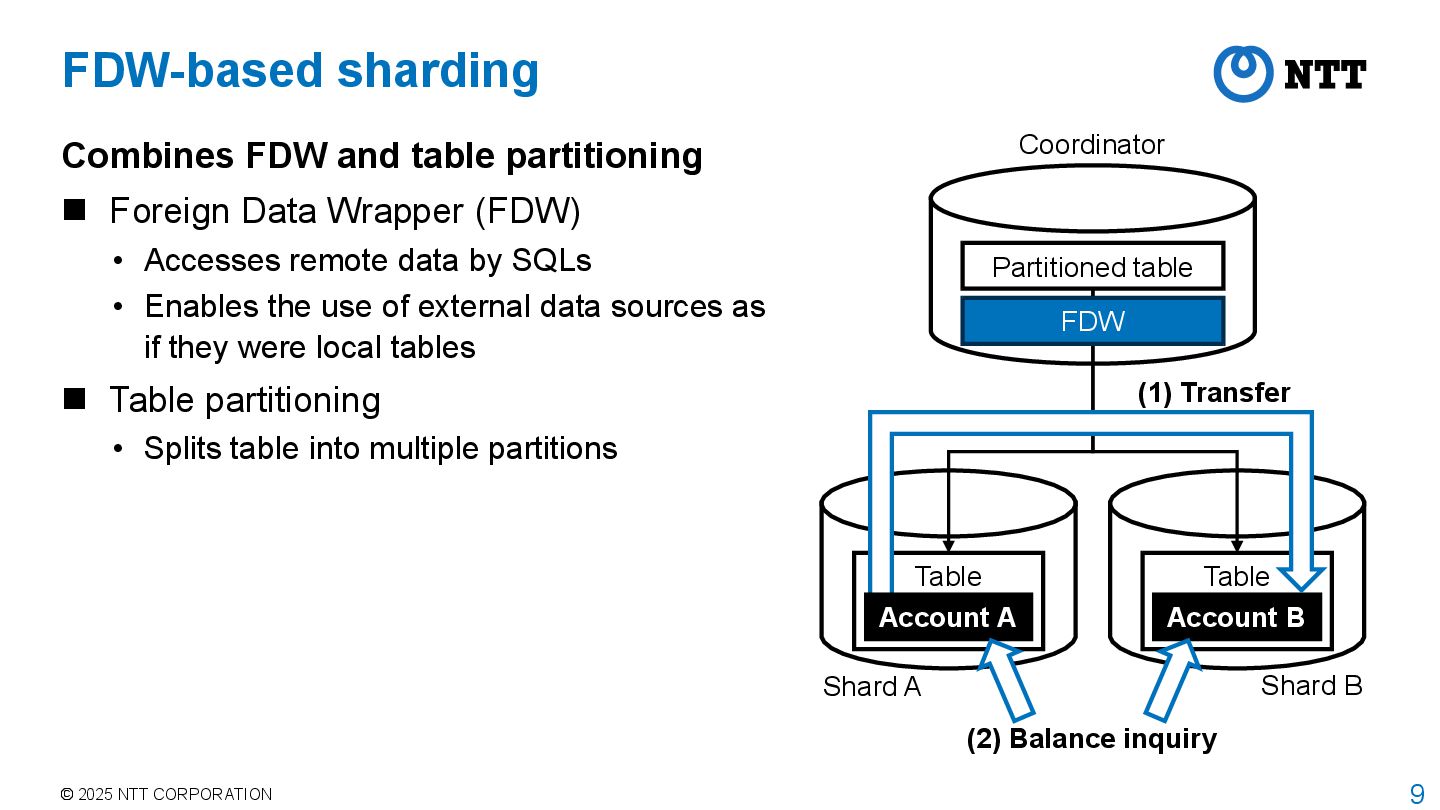
table partitioning Foreign Data Wrapper (FDW) • Accesses remote data by SQLs • Enables the use of external data sources as if they were local tables Table partitioning • Splits table into multiple partitions Shard A Shard B (1) Transfer (2) Balance inquiry Partitioned table Coordinator Table Table Account B FDW Account A
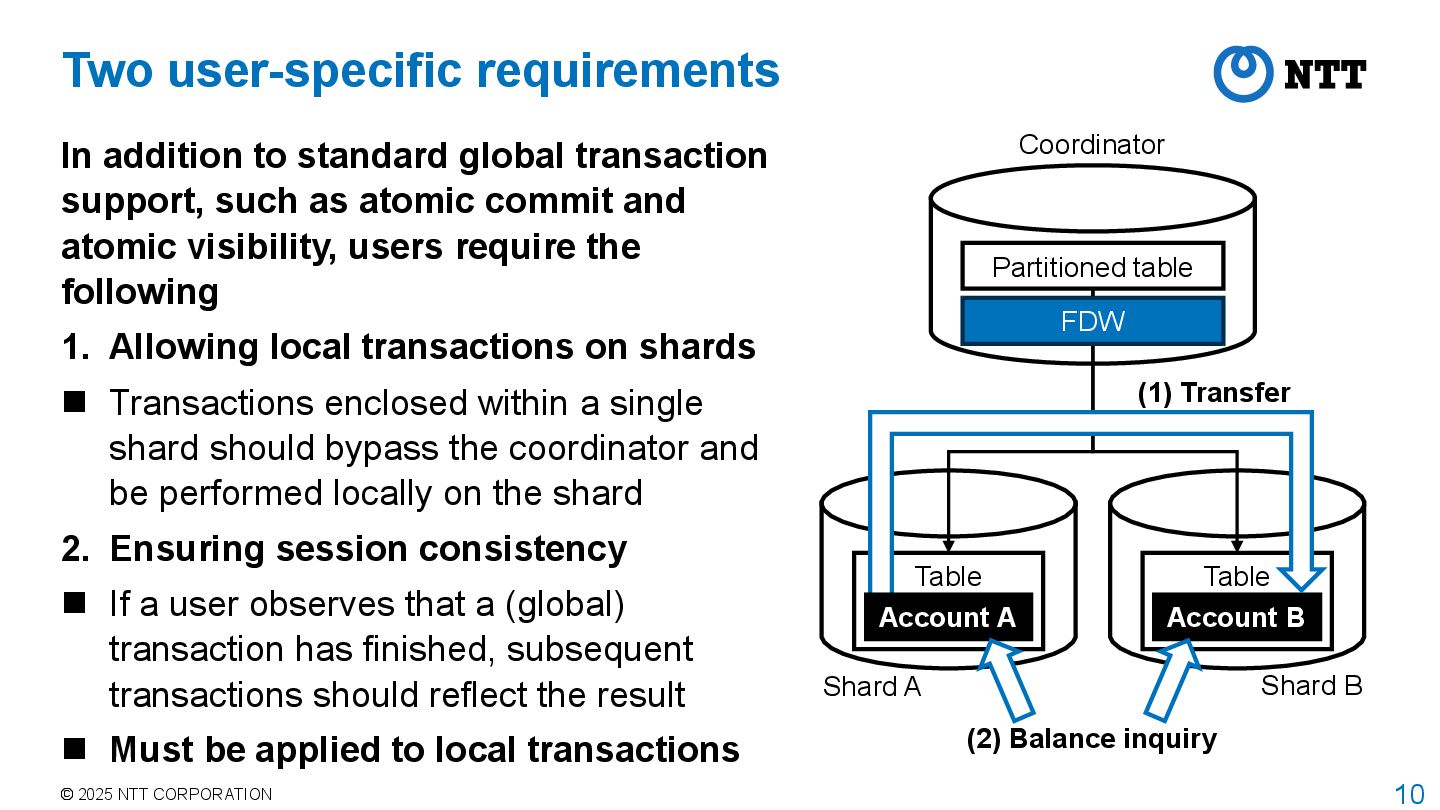
to standard global transaction support, such as atomic commit and atomic visibility, users require the following 1. Allowing local transactions on shards Transactions enclosed within a single shard should bypass the coordinator and be performed locally on the shard 2. Ensuring session consistency If a user observes that a (global) transaction has finished, subsequent transactions should reflect the result Must be applied to local transactions Shard A Shard B (1) Transfer (2) Balance inquiry Partitioned table Coordinator Table Table Account B FDW Account A
support State-of-the-art methods have been proposed to ensure atomic visibility Global transaction managers (GTMs), e.g., Postgres-XC/XL • Assign global transaction IDs to uniquely identify global transactions Clock-based algorithms, e.g., Clock-SI • Use loosely synchronized clocks to coordinate global transactions Pessimistic coordination • Assigns local snapshots atomically when global transaction begins Centralized coordination Decentralized coordination
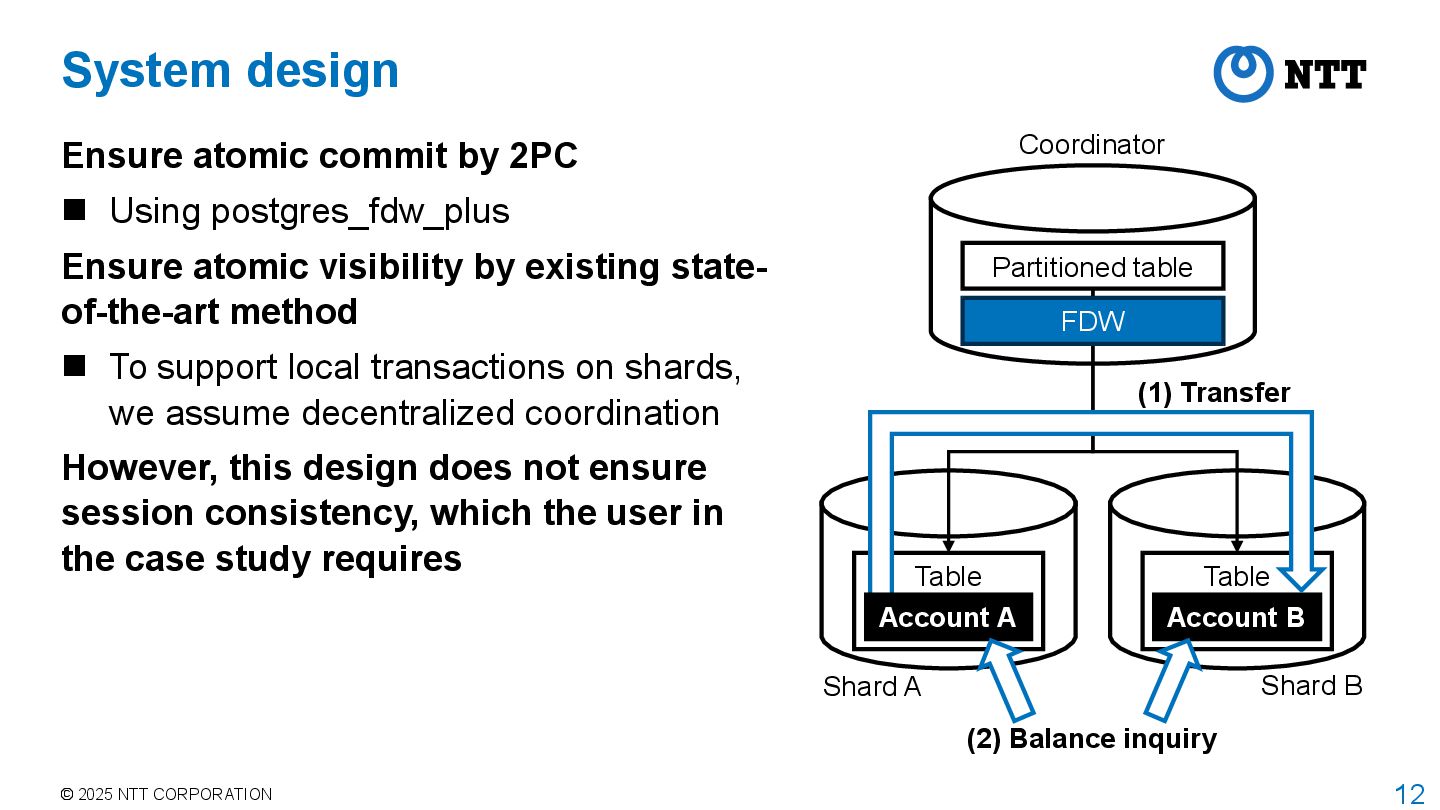
by 2PC Using postgres_fdw_plus Ensure atomic visibility by existing state- of-the-art method To support local transactions on shards, we assume decentralized coordination However, this design does not ensure session consistency, which the user in the case study requires Shard A Shard B (1) Transfer (2) Balance inquiry Partitioned table Coordinator Table Table Account B FDW Account A
postgres_fdw is provided as a contrib module Enables the use of PostgreSQL servers as external data sources Does not support distributed transactions postgres_fdw_plus is a fork of postgres_fdw with support of atomic commit Developed by NTT DATA Basic usage is the same as original postgres_fdw Atomic commit • Ensures that a transaction is either fully committed or totally aborted in all participating nodes • Essential in distributed transactions • postgres_fdw_plus achieves atomic commit by two-phase commit (2PC) protocol The case study adopts postgres_fdw_plus
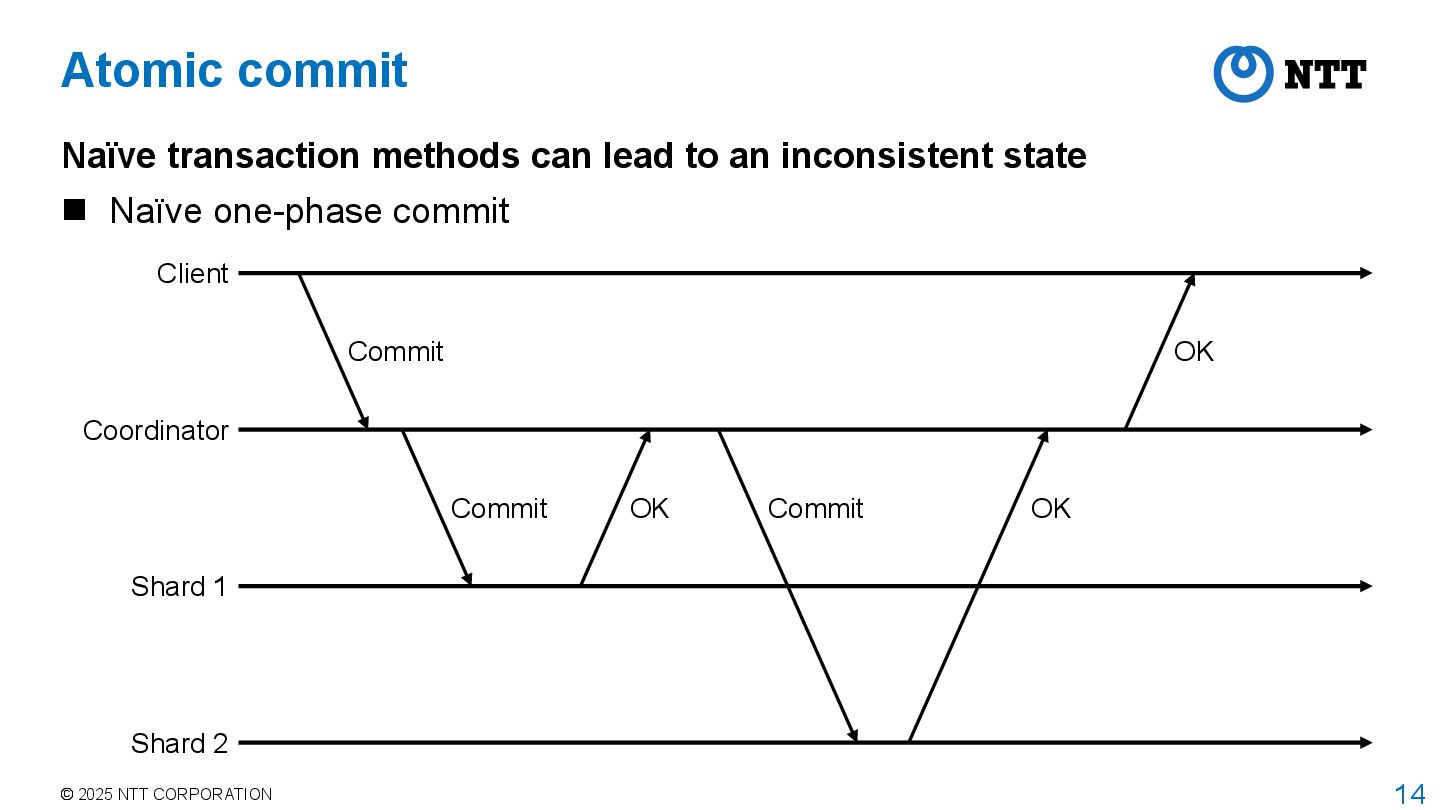
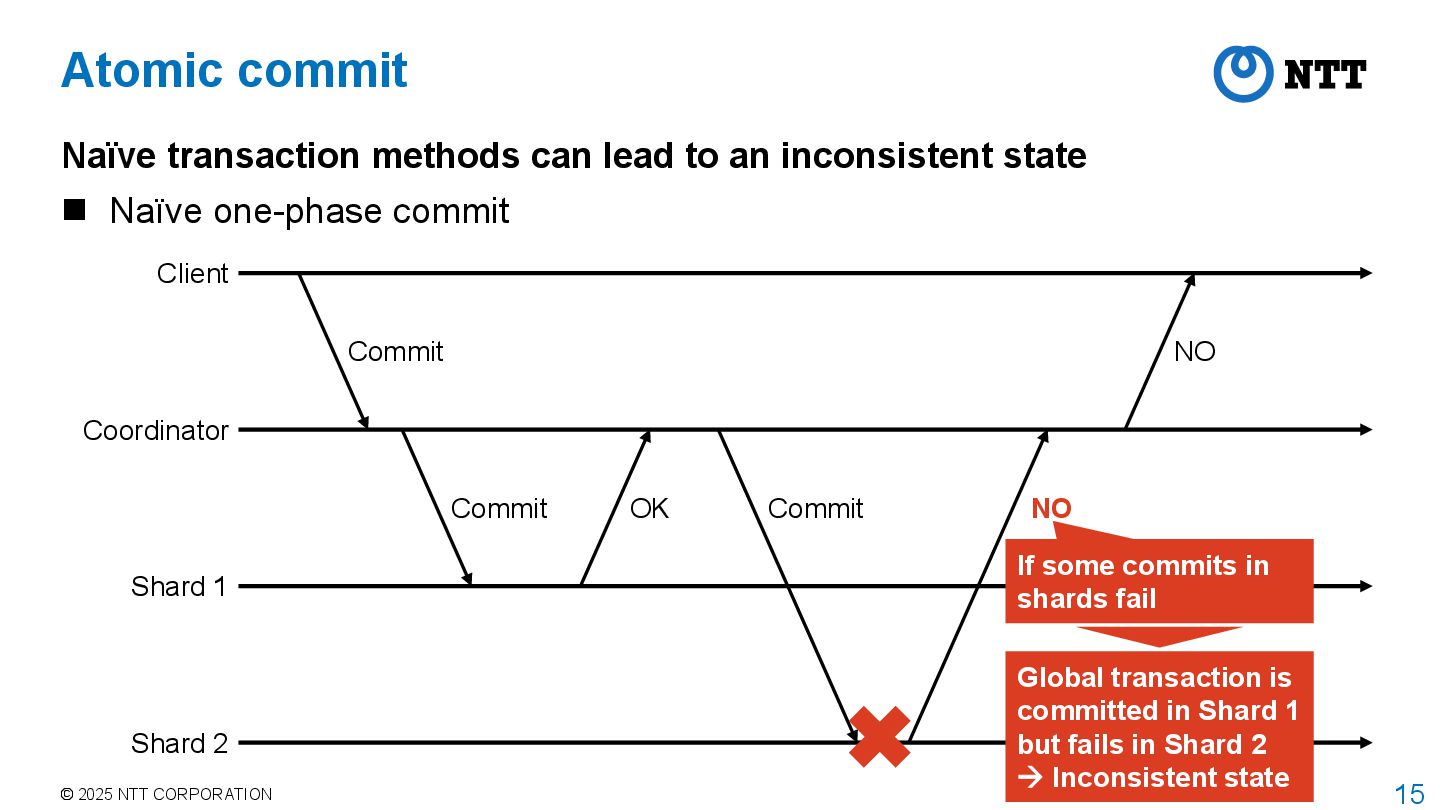
can lead to an inconsistent state Naïve one-phase commit Coordinator Shard 1 Shard 2 Client Commit Commit OK Commit NO NO If some commits in shards fail Global transaction is committed in Shard 1 but fails in Shard 2 Inconsistent state
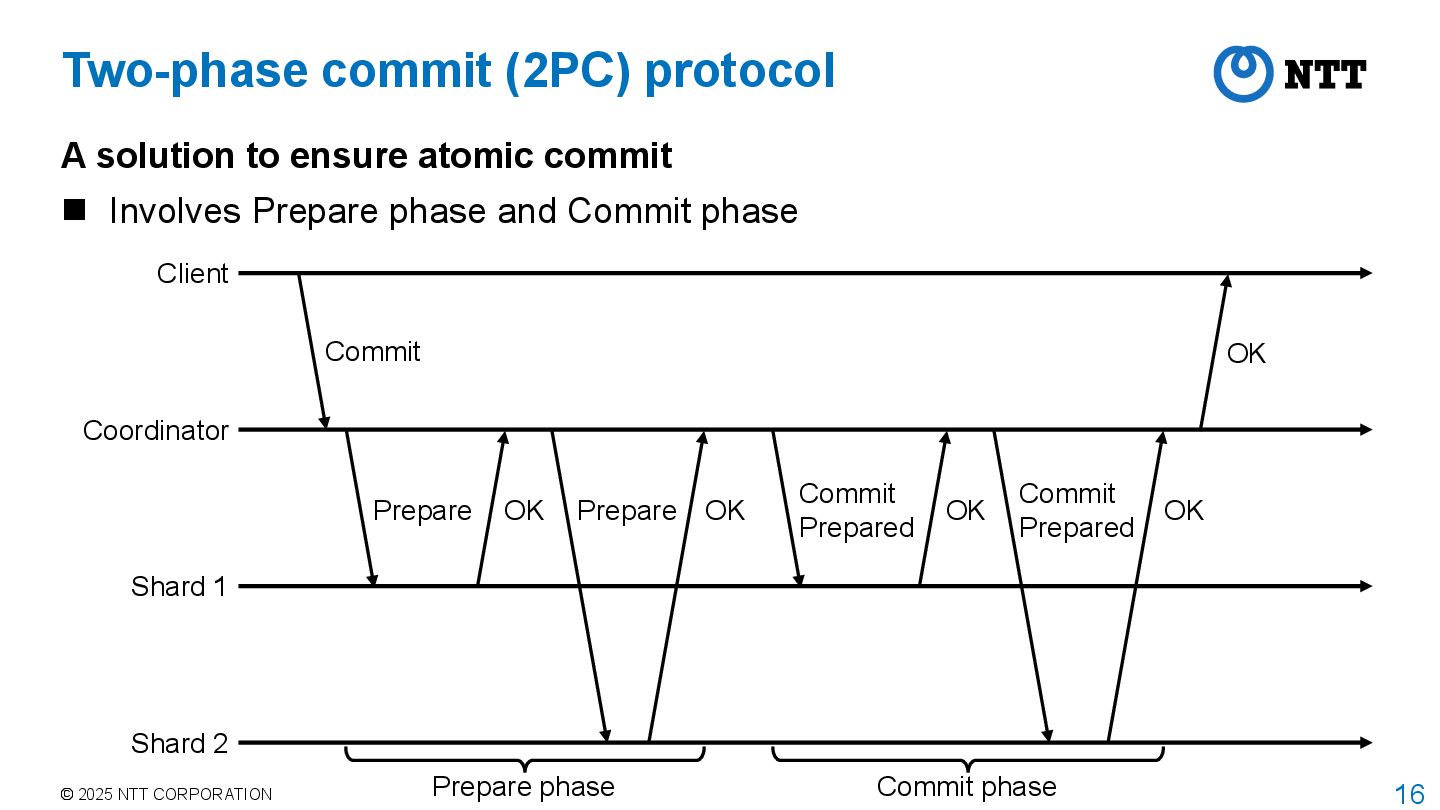
solution to ensure atomic commit Involves Prepare phase and Commit phase Coordinator Shard 1 Shard 2 Client Commit Prepare OK Prepare OK Commit Prepared OK Commit Prepared OK OK Prepare phase Commit phase
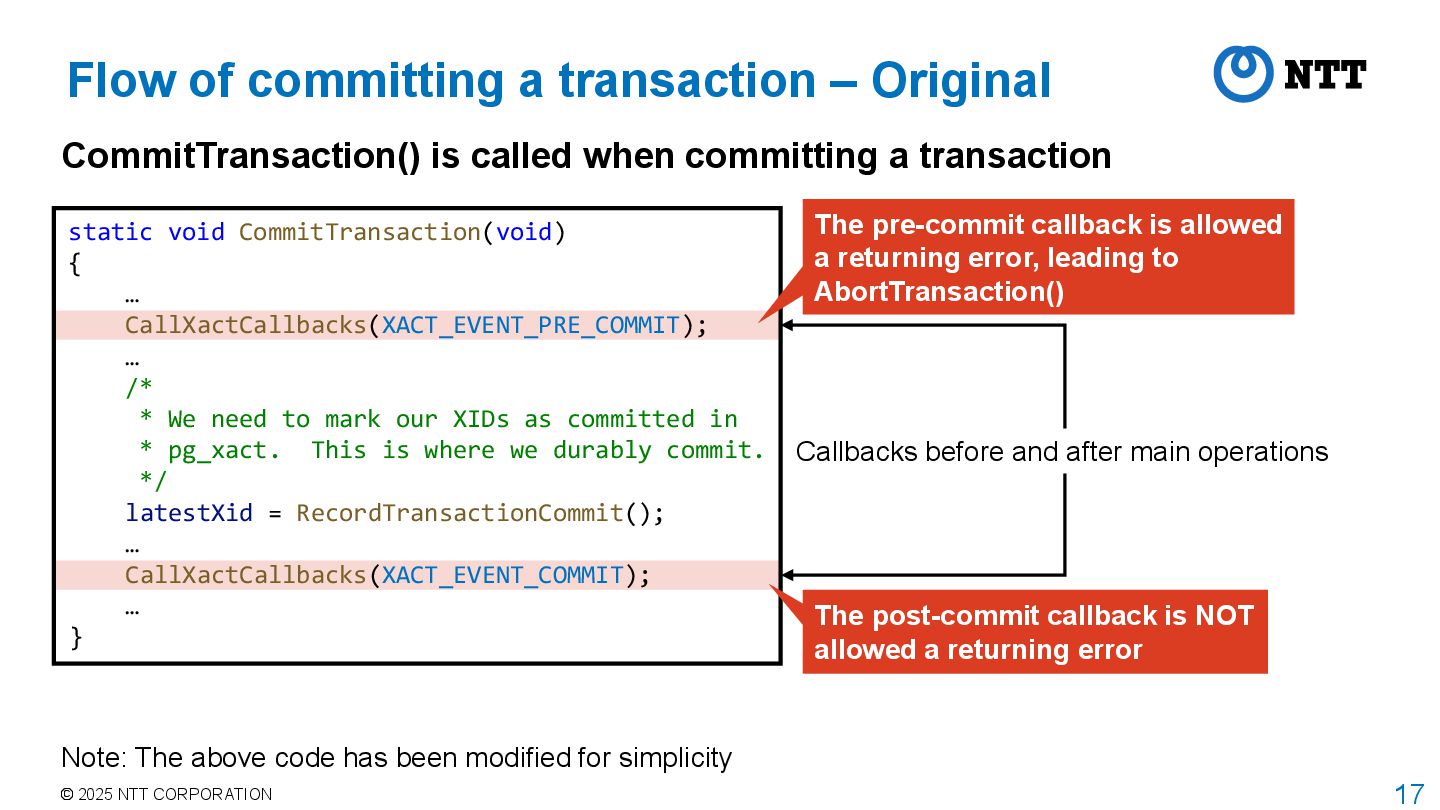
CallXactCallbacks(XACT_EVENT_PRE_COMMIT); … /* * We need to mark our XIDs as committed in * pg_xact. This is where we durably commit. */ latestXid = RecordTransactionCommit(); … CallXactCallbacks(XACT_EVENT_COMMIT); … } Flow of committing a transaction – Original CommitTransaction() is called when committing a transaction Note: The above code has been modified for simplicity Callbacks before and after main operations The pre-commit callback is allowed a returning error, leading to AbortTransaction() The post-commit callback is NOT allowed a returning error
2PC Implementation of postgres_fdw_plus Note: The above code has been modified for simplicity Success static void CommitTransaction(void) { … CallXactCallbacks(XACT_EVENT_PRE_COMMIT); … /* * We need to mark our XIDs as committed in * pg_xact. This is where we durably commit. */ latestXid = RecordTransactionCommit(); … CallXactCallbacks(XACT_EVENT_COMMIT); … } In pre-commit callback, postgres_fdw_plus issues PREPARE TRANSACTION In post-commit callback, postgres_fdw_plus issues COMMIT PREPARED
2PC Implementation of postgres_fdw_plus Note: The above code has been modified for simplicity static void CommitTransaction(void) { … CallXactCallbacks(XACT_EVENT_PRE_COMMIT); … /* * We need to mark our XIDs as committed in * pg_xact. This is where we durably commit. */ latestXid = RecordTransactionCommit(); … CallXactCallbacks(XACT_EVENT_COMMIT); … } If PREPARE TRANSACTION fails in some nodes, control flow moves to AbortTransaction() and postgres_fdw_plus issues ROLLBACK PREPARED
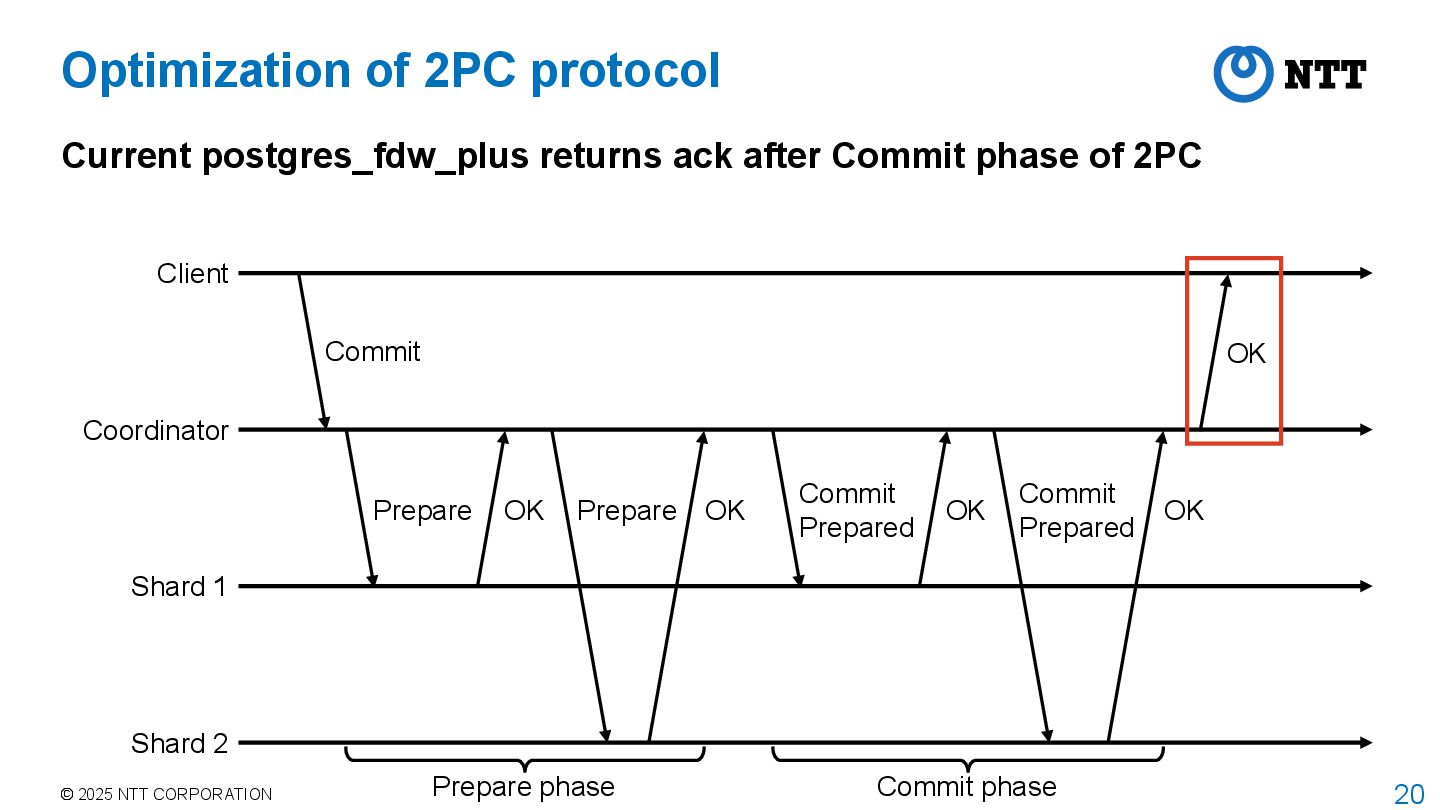
postgres_fdw_plus returns ack after Commit phase of 2PC Coordinator Shard 1 Shard 2 Client Commit Prepare OK Prepare OK Commit Prepared OK Commit Prepared OK OK Prepare phase Commit phase
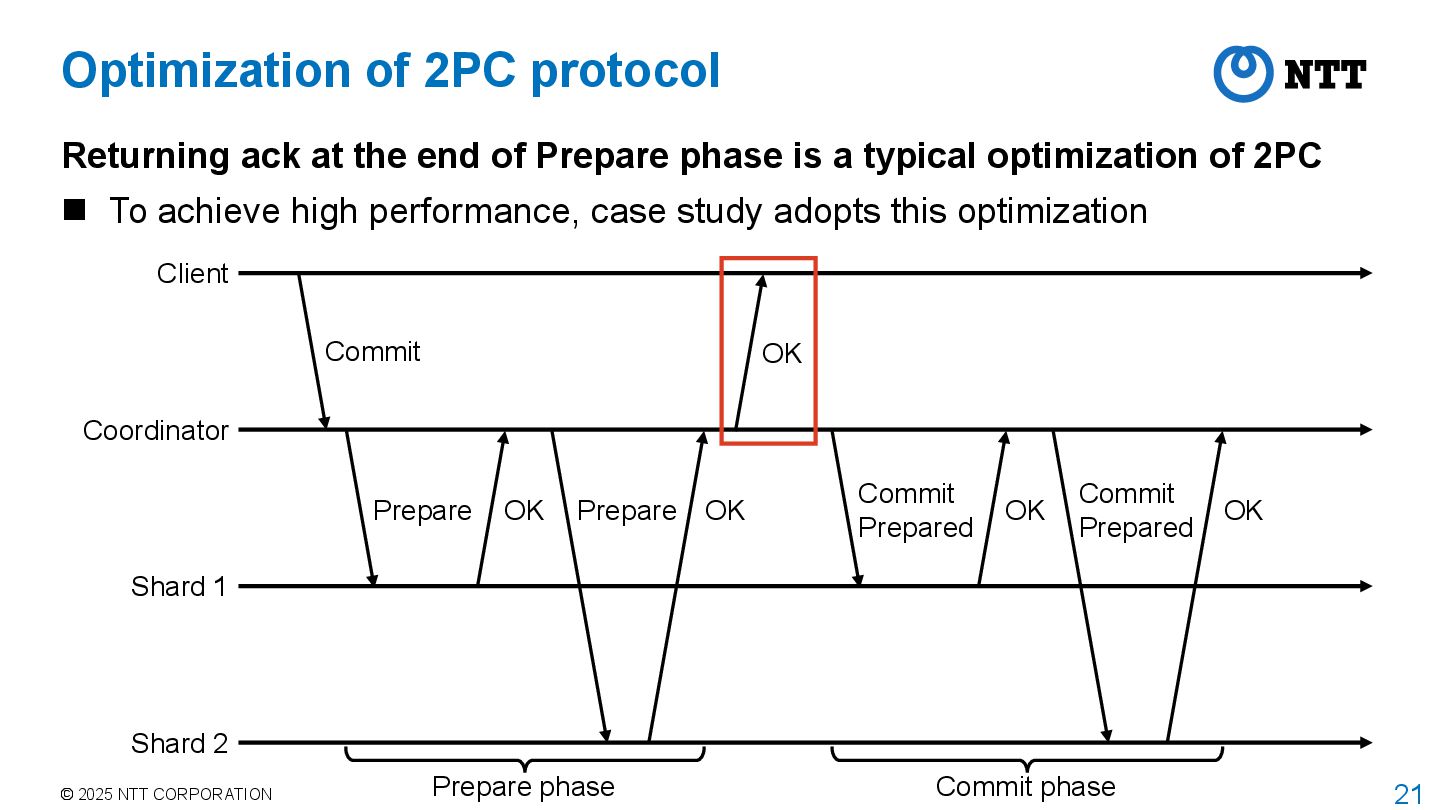
ack at the end of Prepare phase is a typical optimization of 2PC To achieve high performance, case study adopts this optimization Coordinator Shard 1 Shard 2 Client Commit Prepare OK Prepare OK Commit Prepared OK Commit Prepared OK OK Prepare phase Commit phase
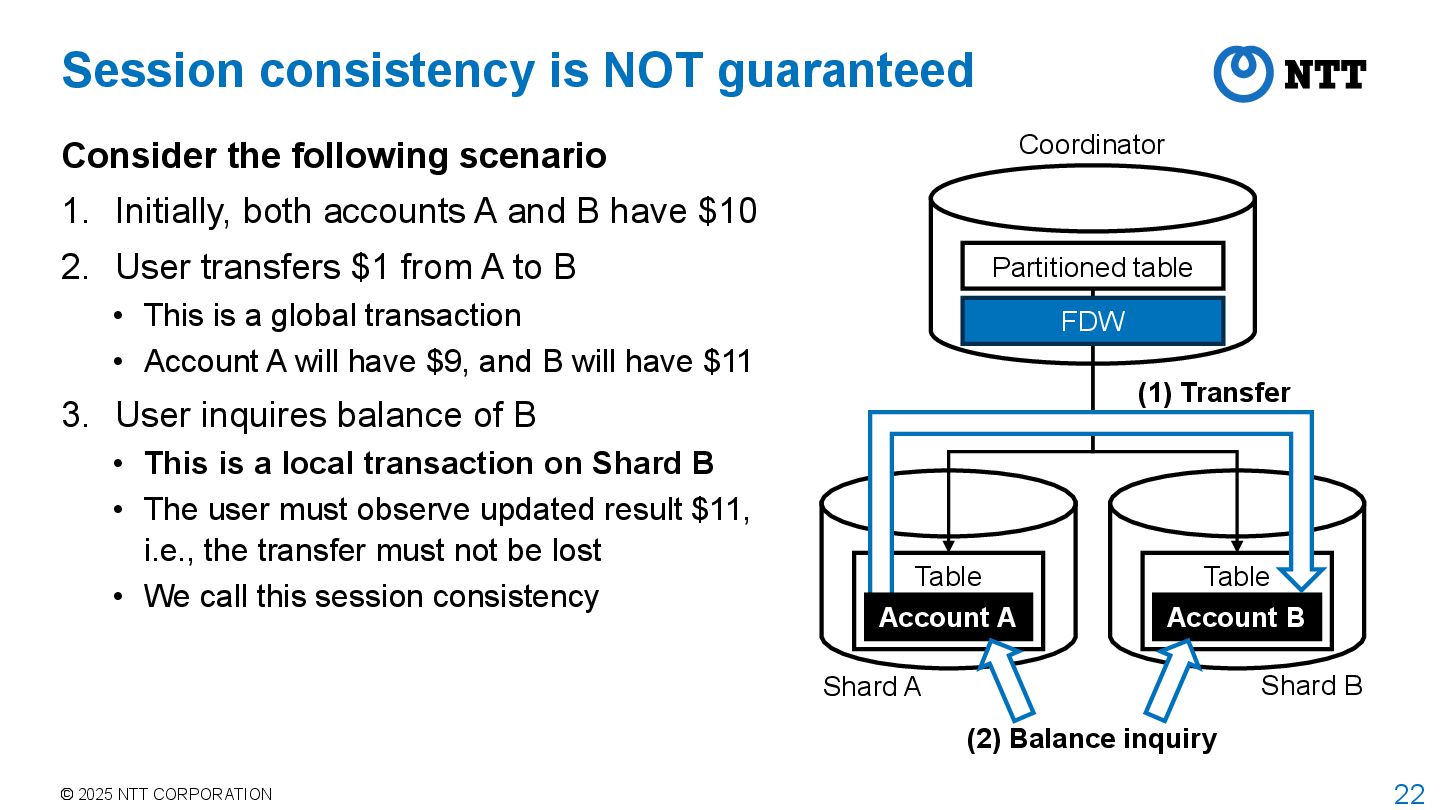
Consider the following scenario 1. Initially, both accounts A and B have $10 2. User transfers $1 from A to B • This is a global transaction • Account A will have $9, and B will have $11 3. User inquires balance of B • This is a local transaction on Shard B • The user must observe updated result $11, i.e., the transfer must not be lost • We call this session consistency Shard A Shard B (1) Transfer (2) Balance inquiry Partitioned table Coordinator Table Table Account B FDW Account A
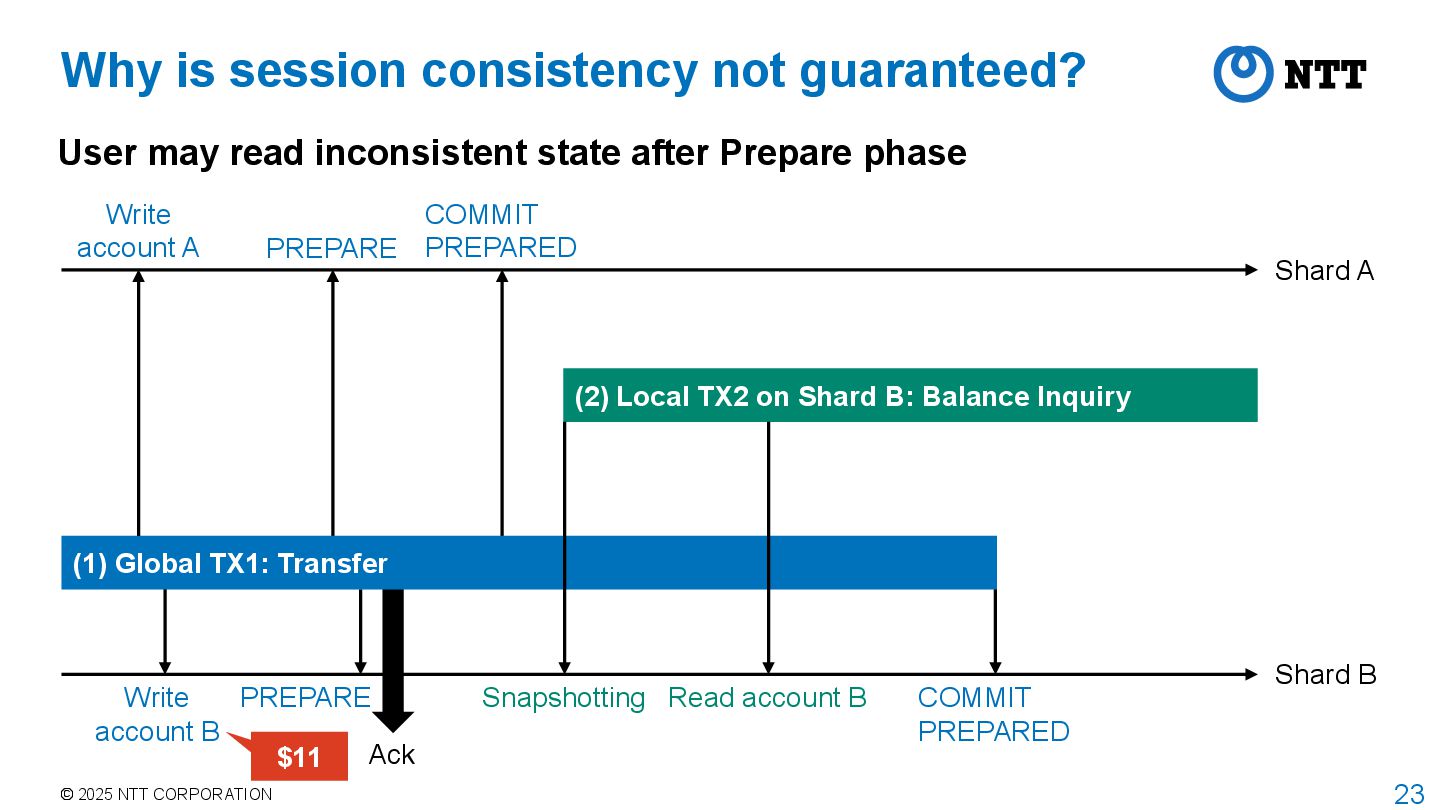
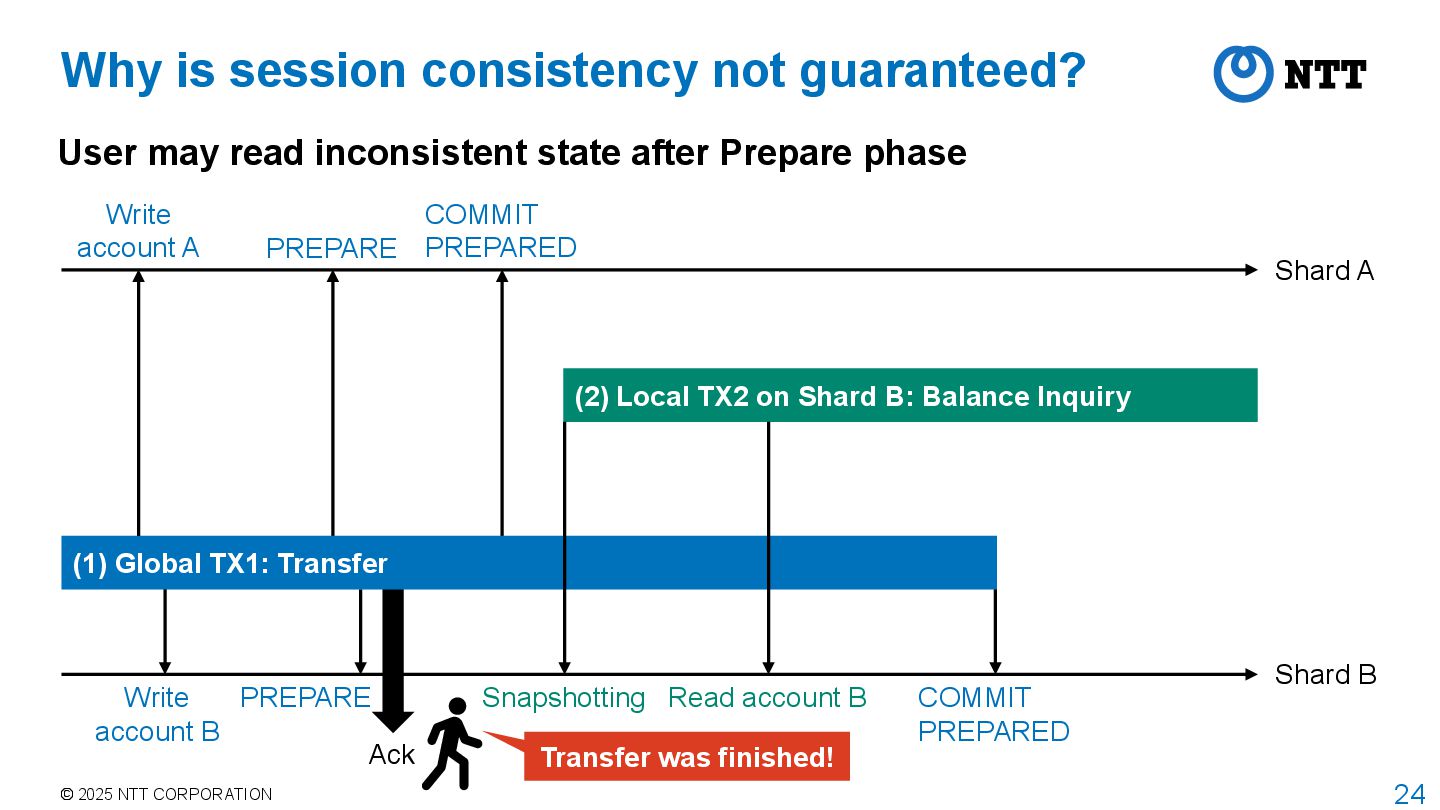
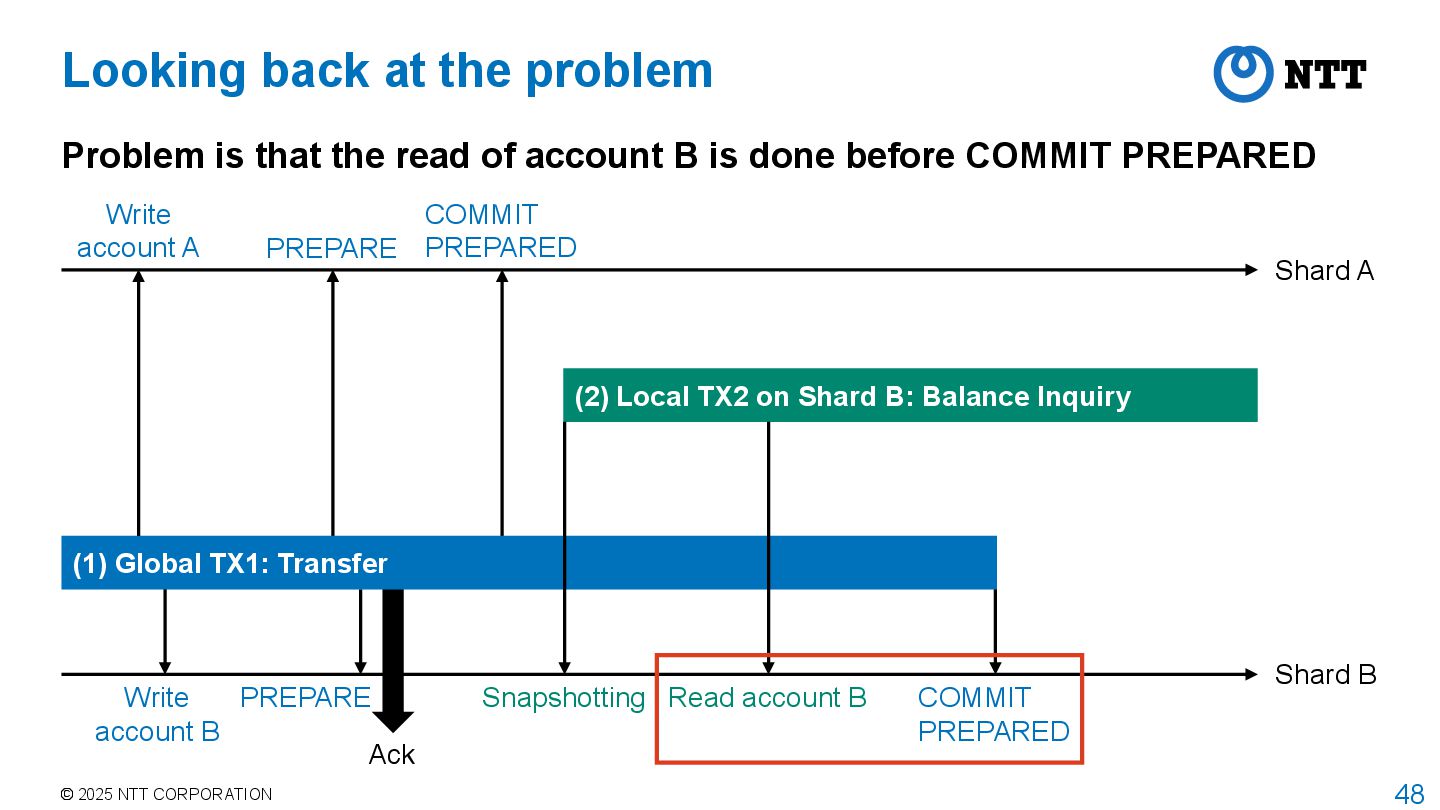
guaranteed? User may read inconsistent state after Prepare phase Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B $11
guaranteed? User may read inconsistent state after Prepare phase Transfer was finished! Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B
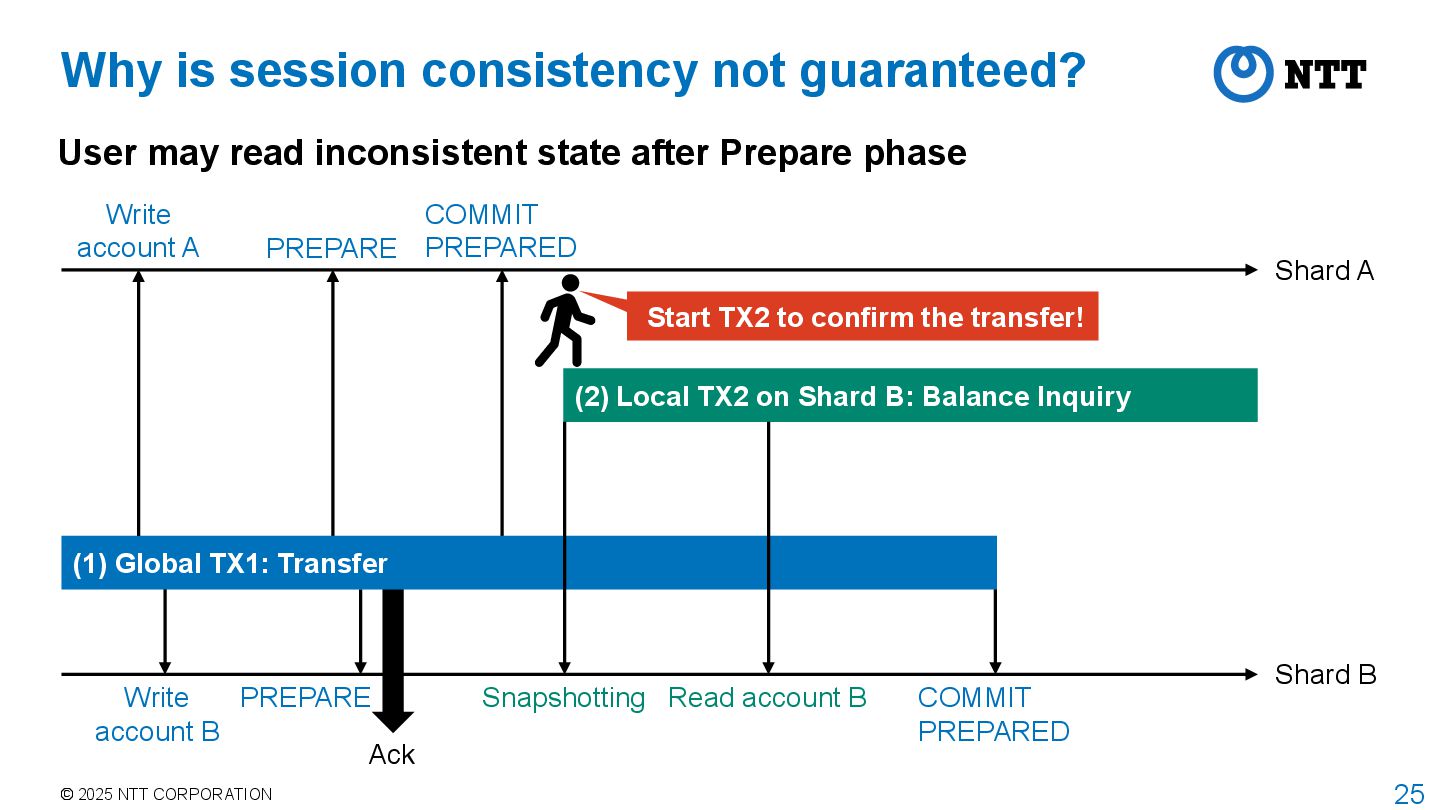
guaranteed? User may read inconsistent state after Prepare phase Start TX2 to confirm the transfer! Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B
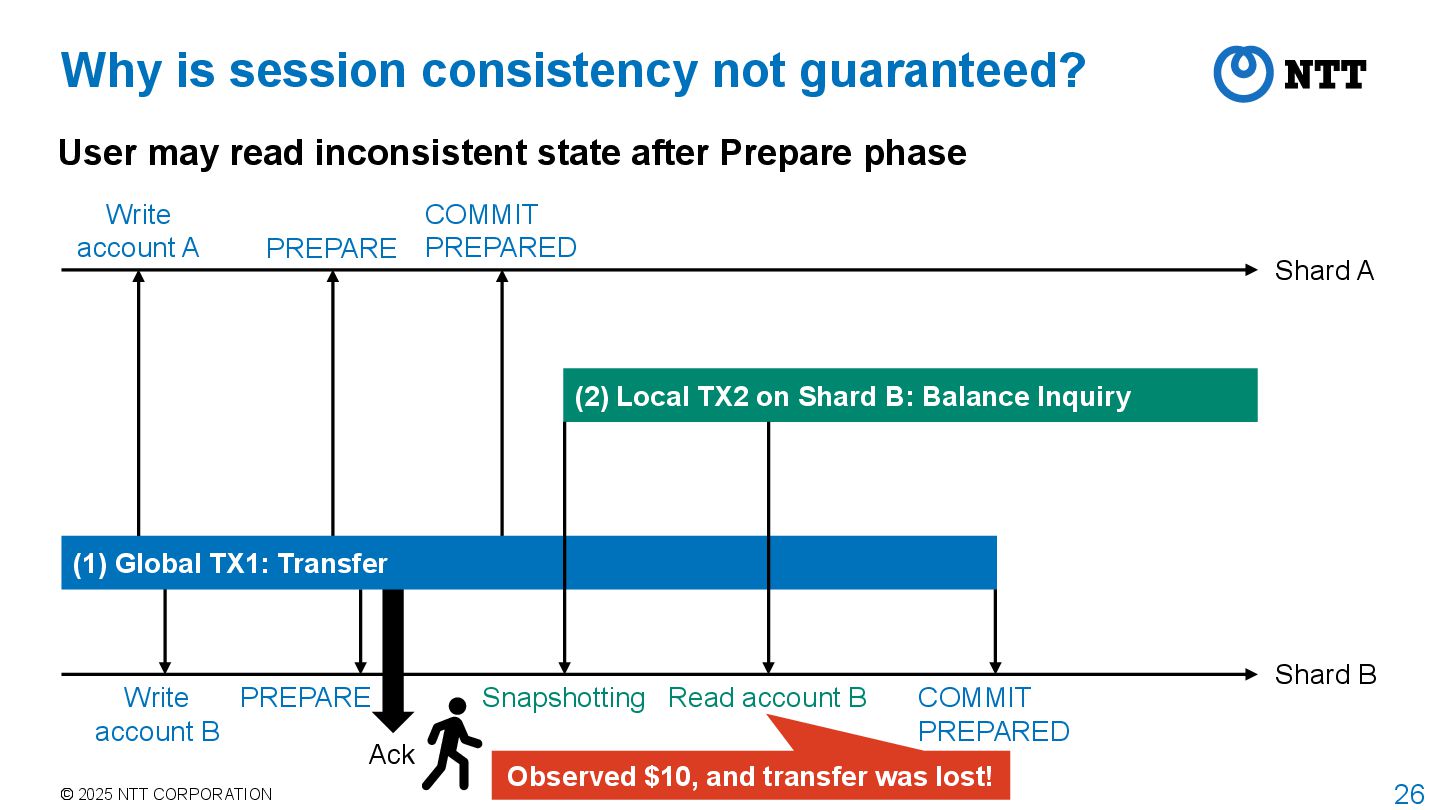
guaranteed? User may read inconsistent state after Prepare phase Observed $10, and transfer was lost! Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B
This case study implements a custom transaction method to ensure session consistency even for local transactions by XTM User-specific method for user-specific requirement Customizes snapshots and tuple visibility determination XTM is effective for complementing existing methods to meet this kind of user-specific requirement that is not always needed in general
Transaction Manager (XTM) significantly improves transactional extensibility in PostgreSQL Allows the core transactional APIs to be replaced First proposed in 2015 by PostgresPro Previously discussed, but not yet merged into PostgreSQL core
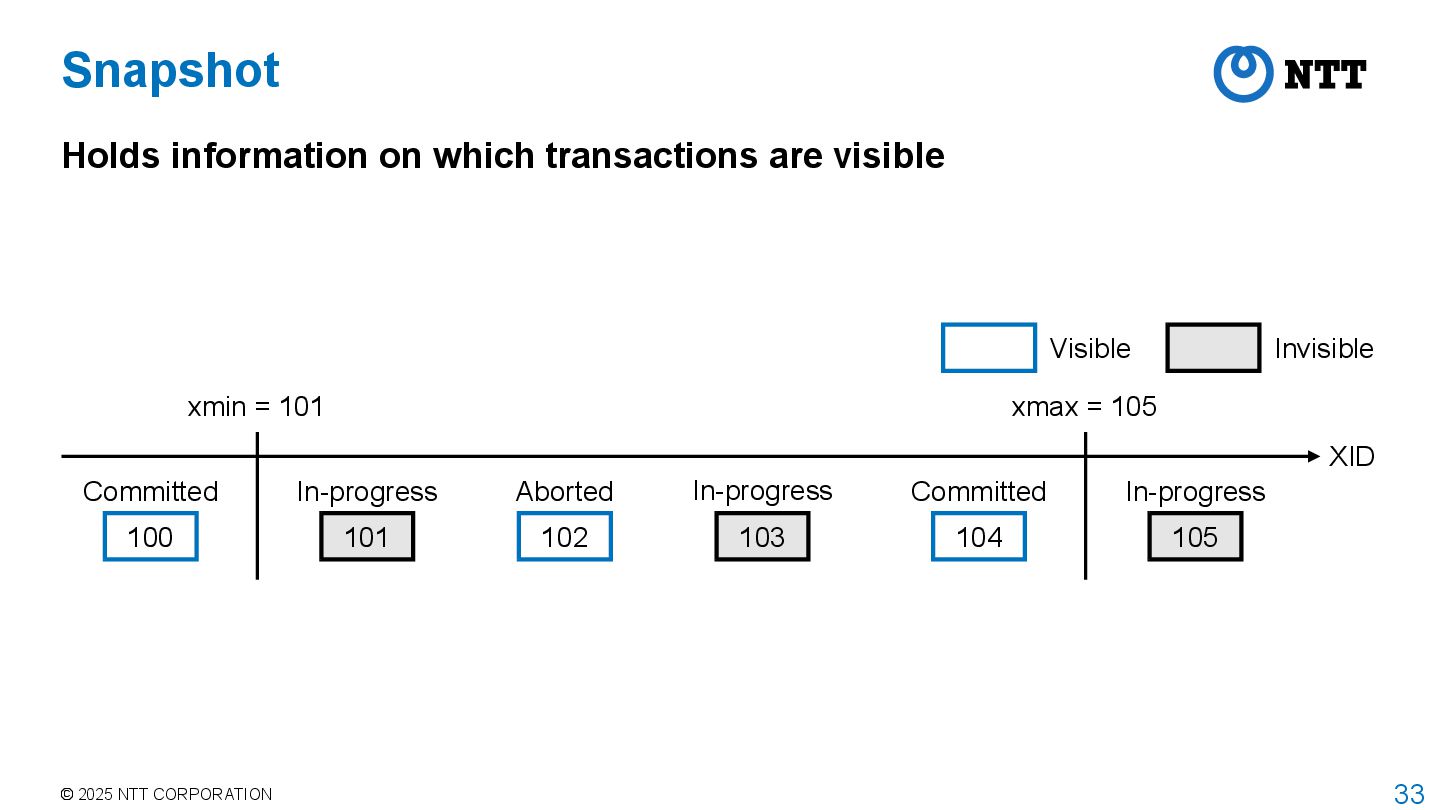
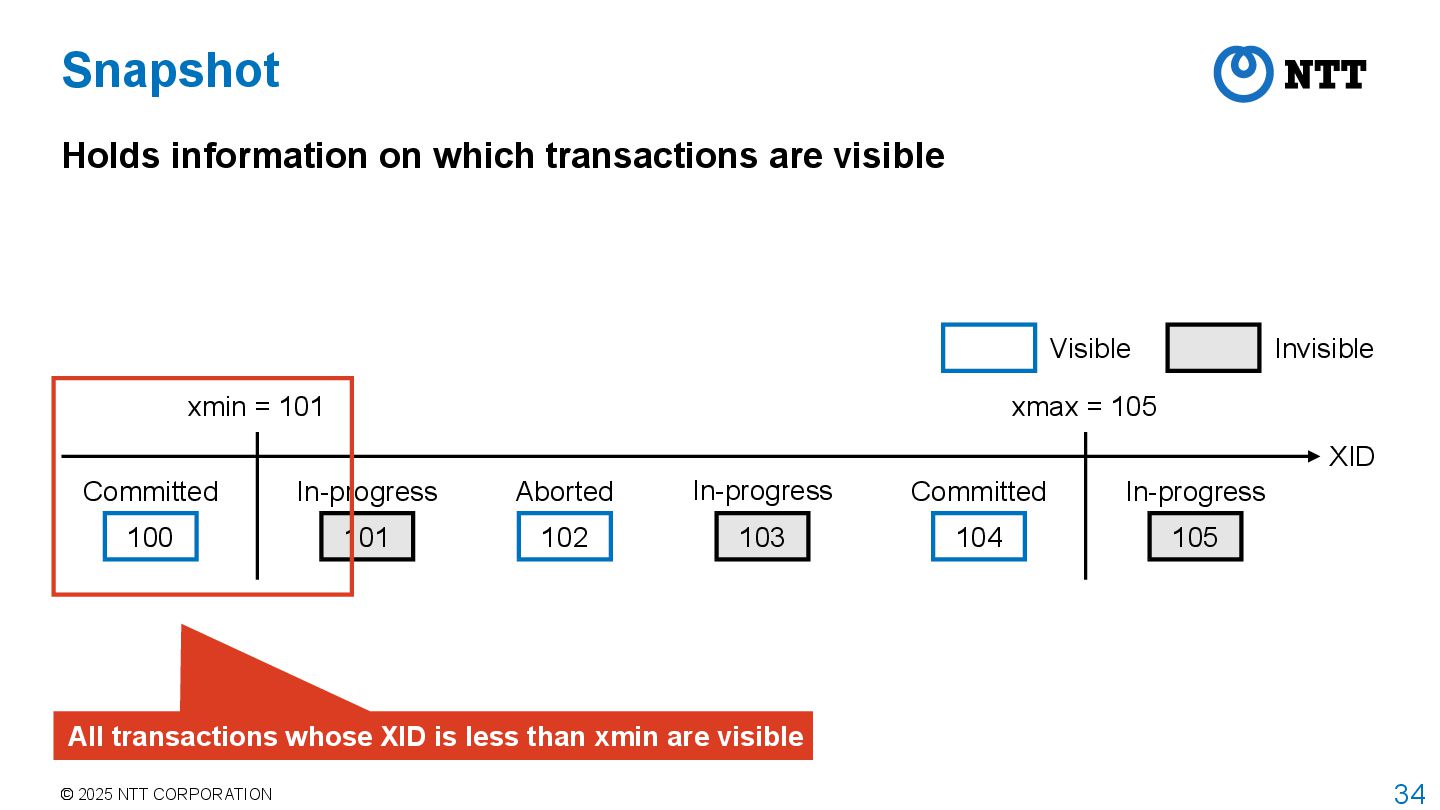
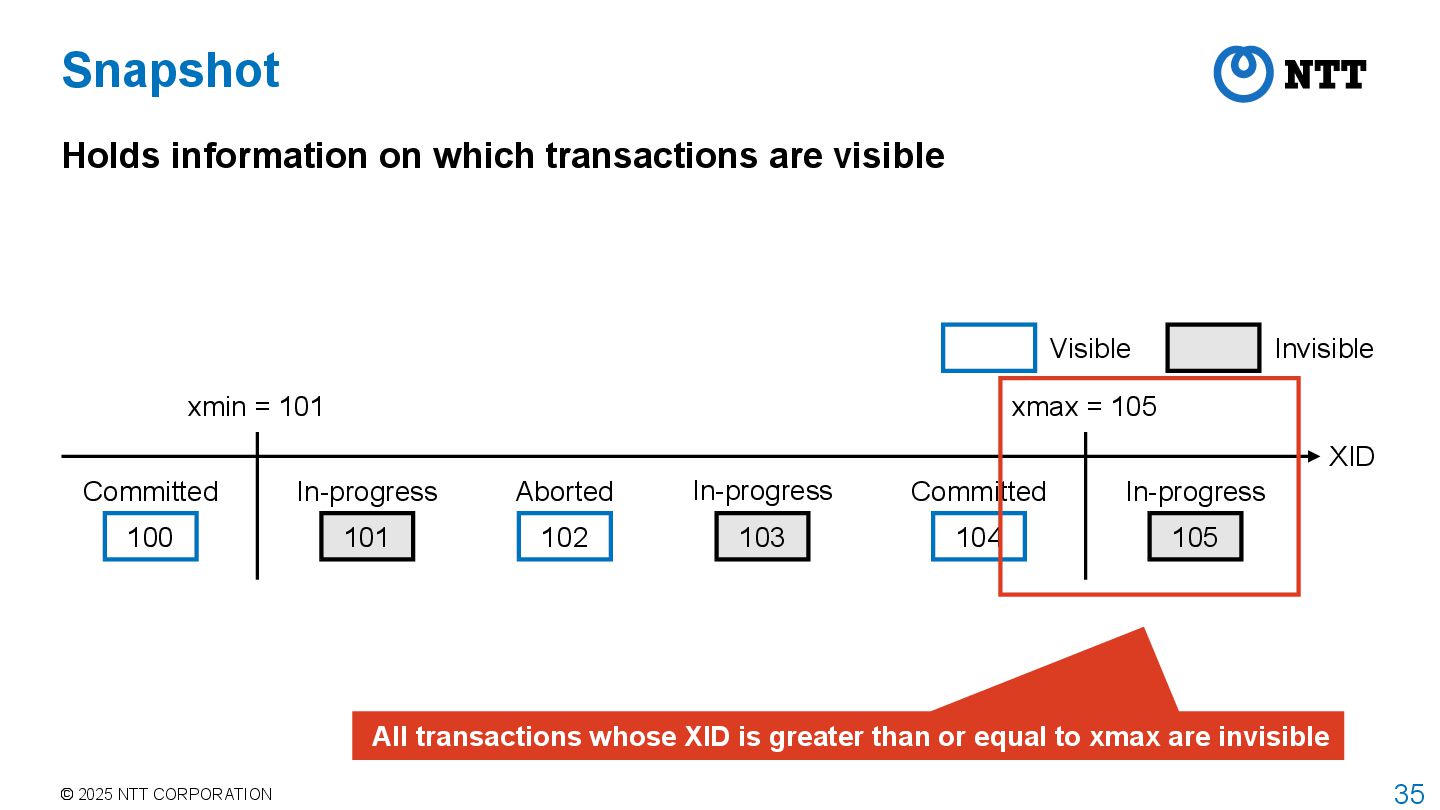
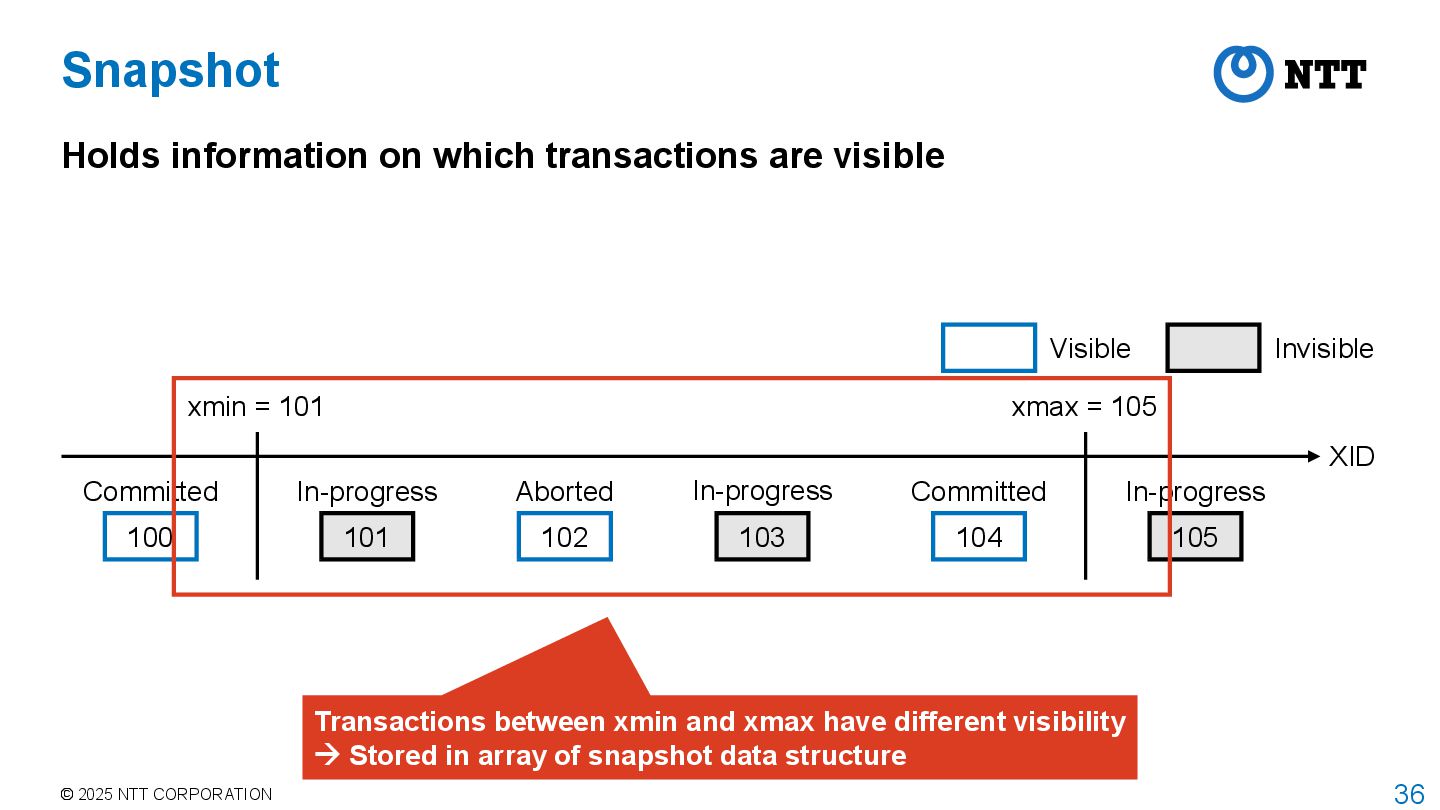
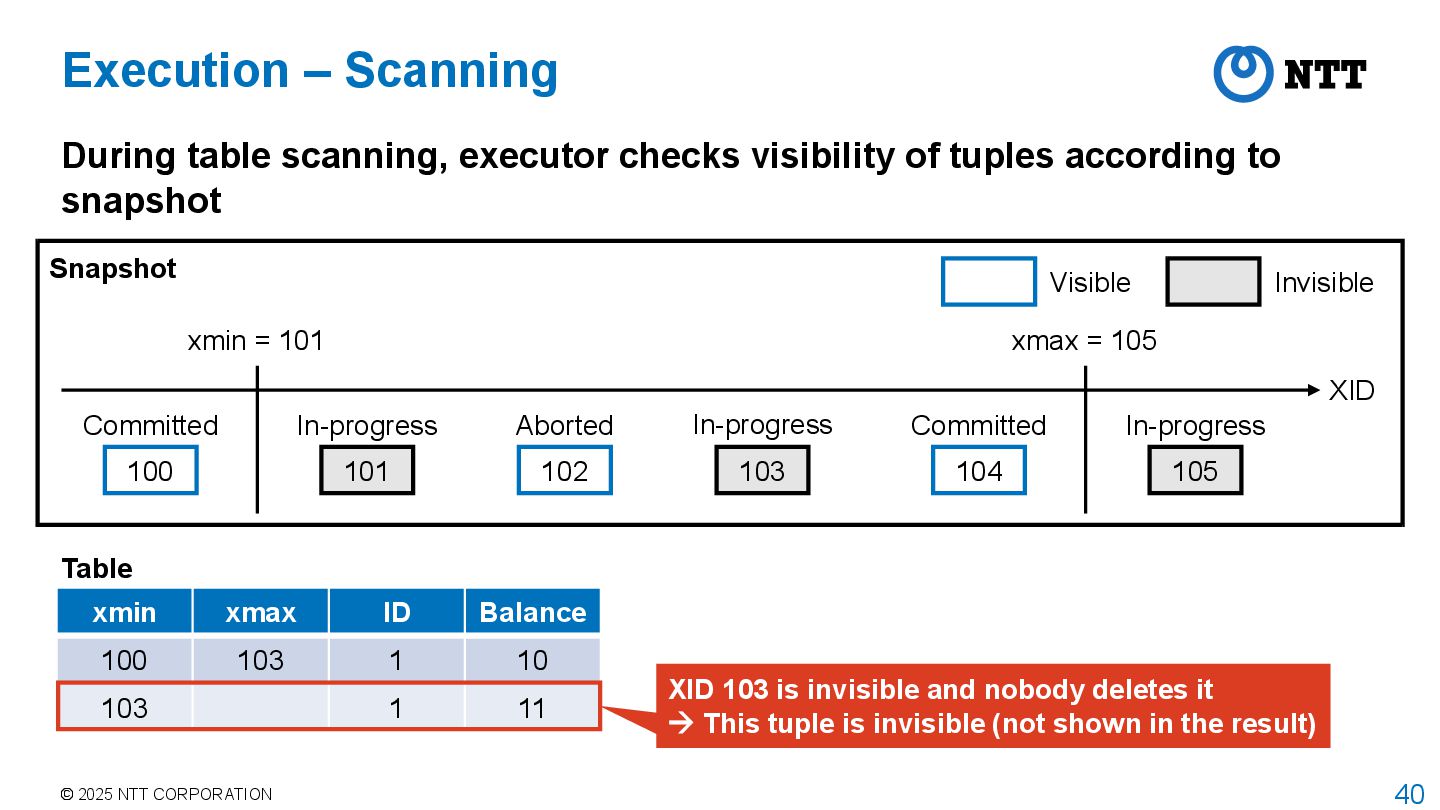
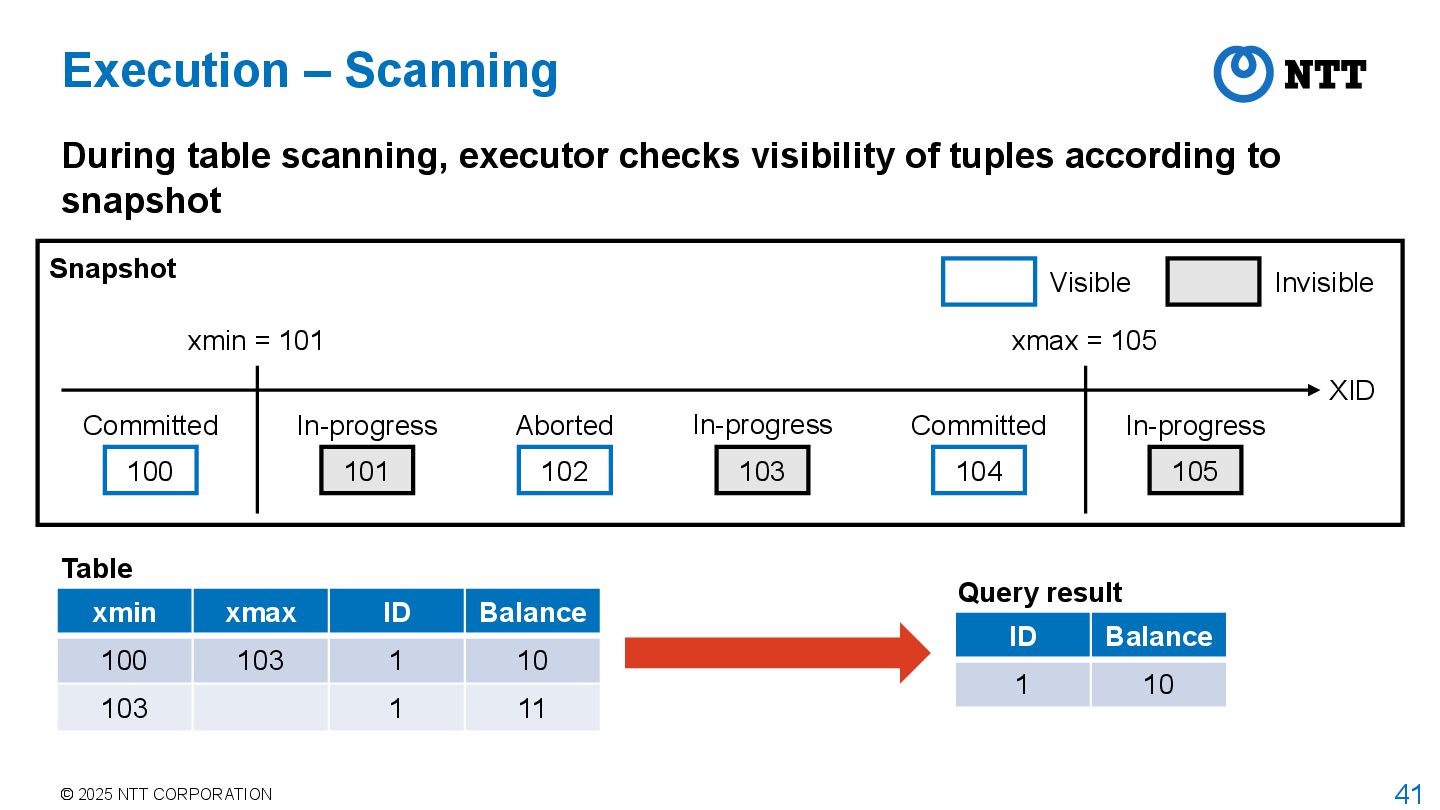
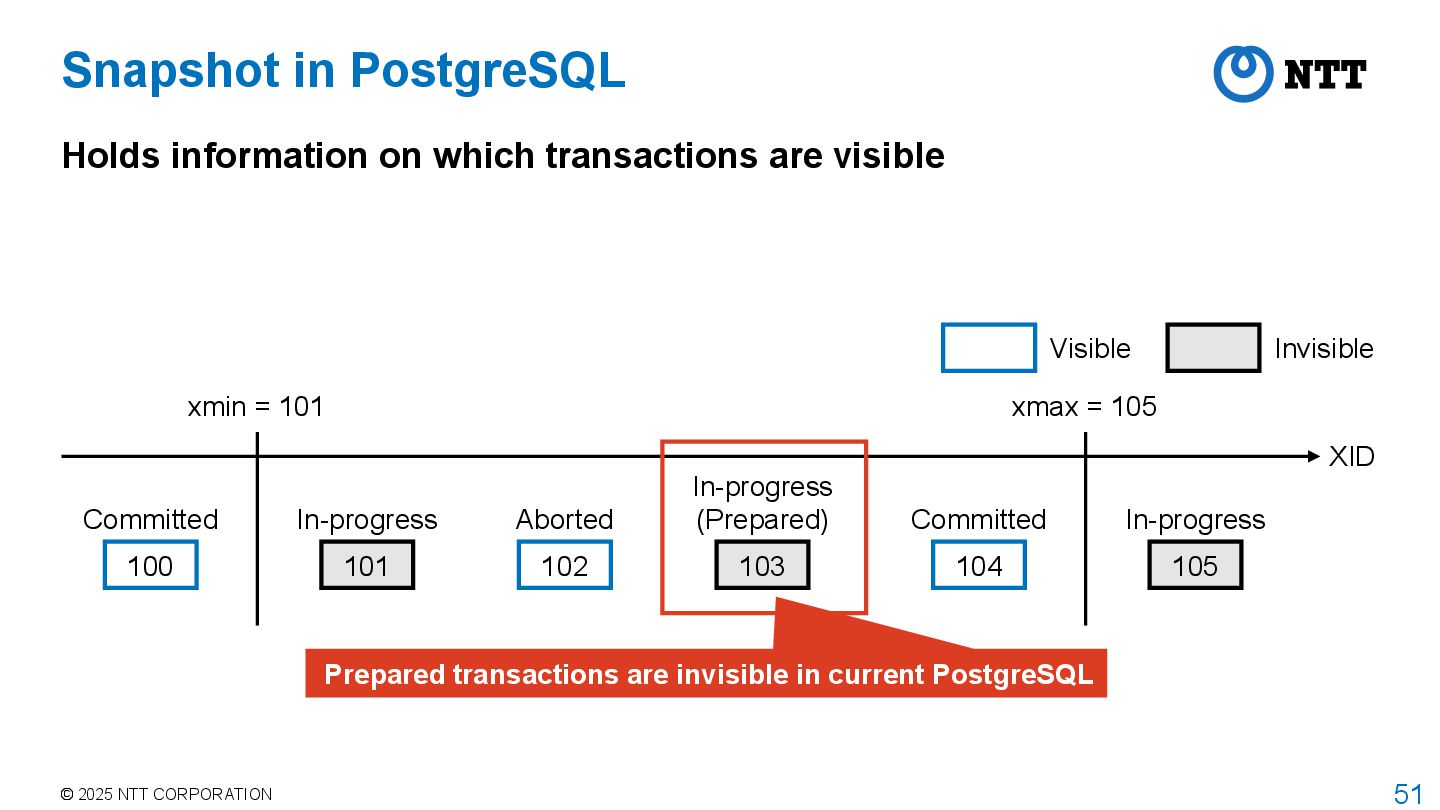
PostgreSQL adopts MultiVersion Concurrency Control (MVCC) to achieve isolation between transactions with high concurrency Transaction manager assigns transaction id (XID) to each transaction Transaction manager obtains a snapshot when transaction starts • This is the behavior when isolation level is REPEATABLE READ or higher • For READ COMMITTED, transaction manager obtains a snapshot for each command • Snapshot stores information about which transactions are committed, aborted, or in- progress when the snapshot was taken Executor returns tuples that are visible according to the current snapshot • Called tuple visibility determination
transactions are visible XID 100 Committed 101 In-progress 102 Aborted 103 In-progress 104 Committed 105 In-progress xmin = 101 xmax = 105 Visible Invisible Transactions between xmin and xmax have different visibility Stored in array of snapshot data structure
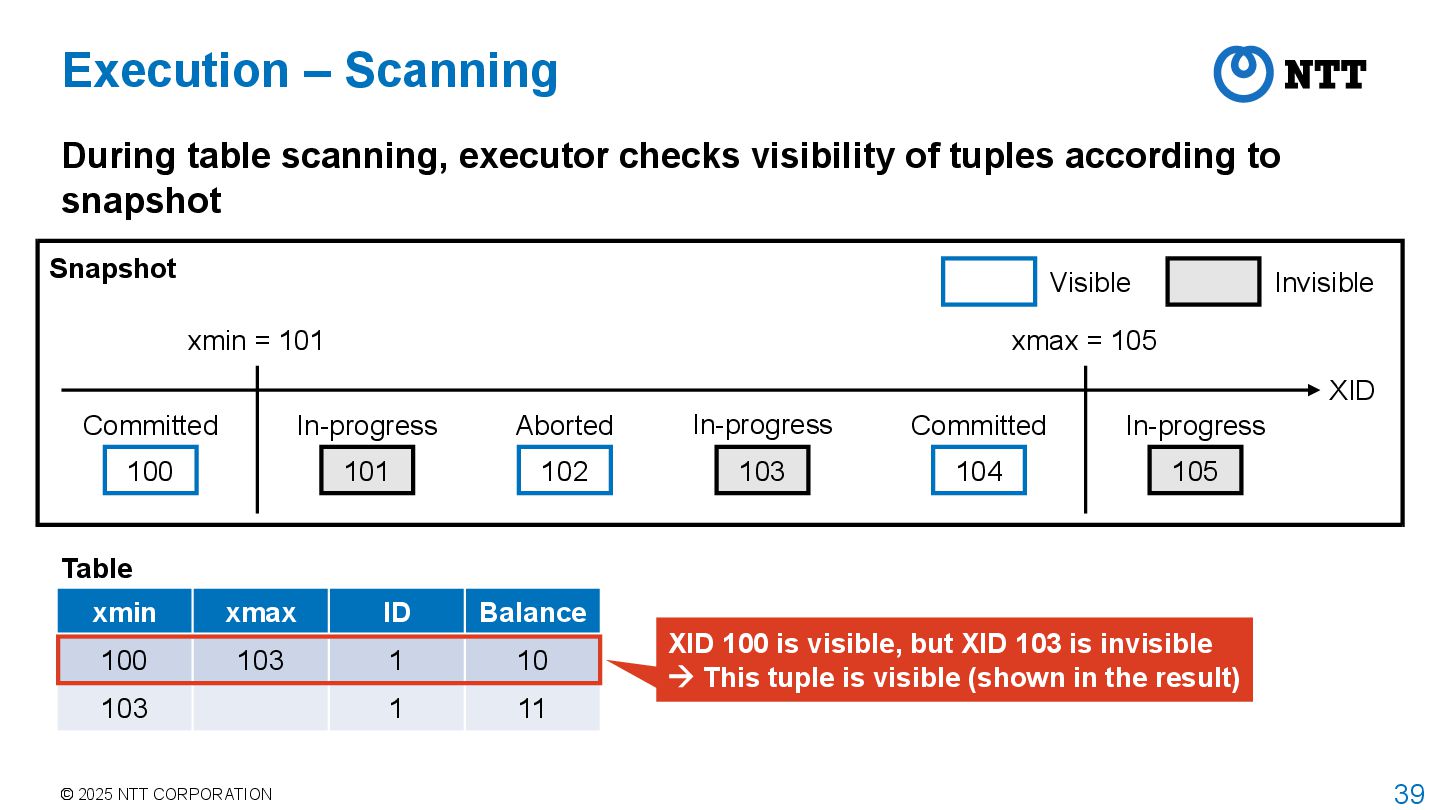
tuple stores XIDs that wrote and deleted it xmin xmax ID Balance 100 103 1 10 103 1 11 Table After updating this record by XID 103, a new tuple is added to the table
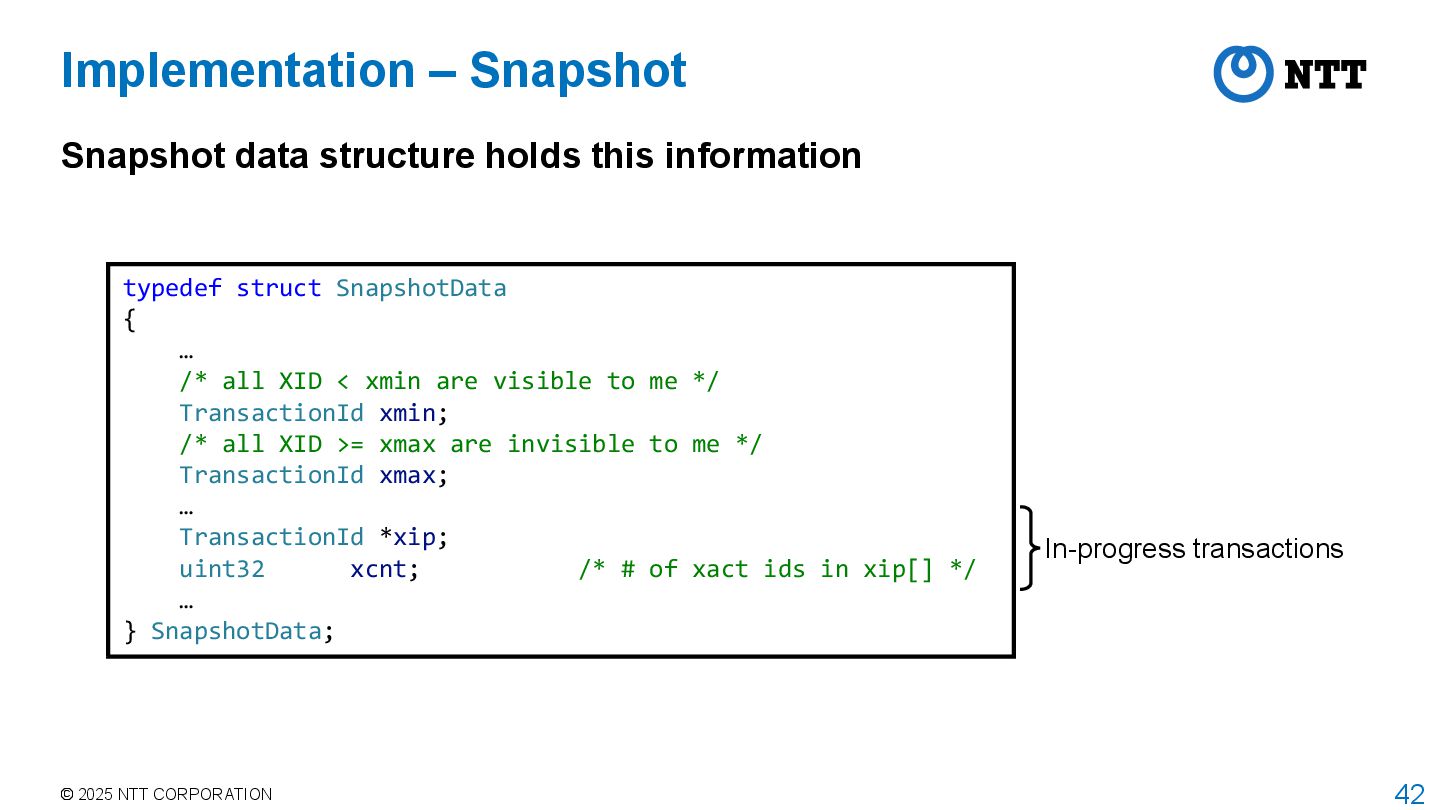
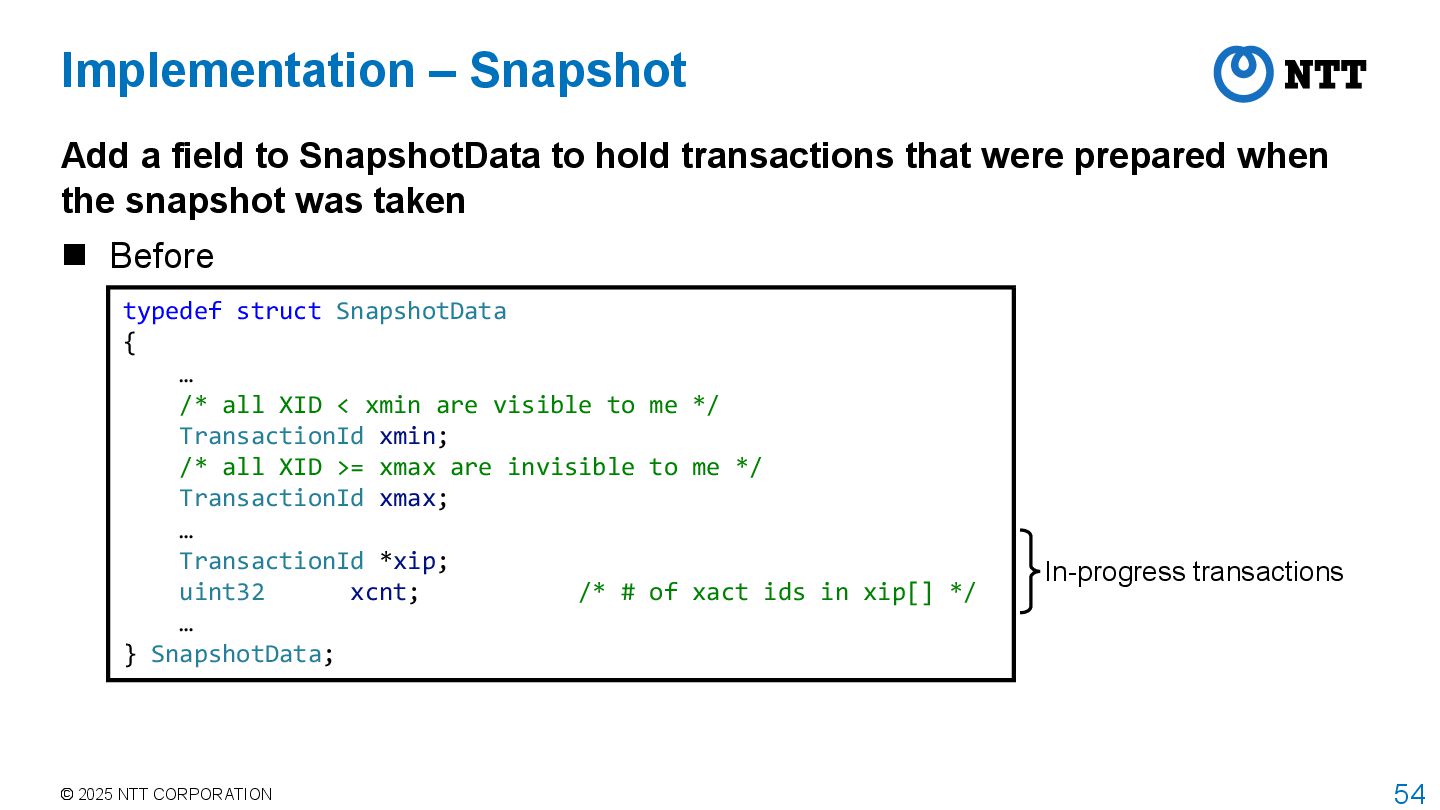
structure holds this information typedef struct SnapshotData { … /* all XID < xmin are visible to me */ TransactionId xmin; /* all XID >= xmax are invisible to me */ TransactionId xmax; … TransactionId *xip; uint32 xcnt; /* # of xact ids in xip[] */ … } SnapshotData; In-progress transactions
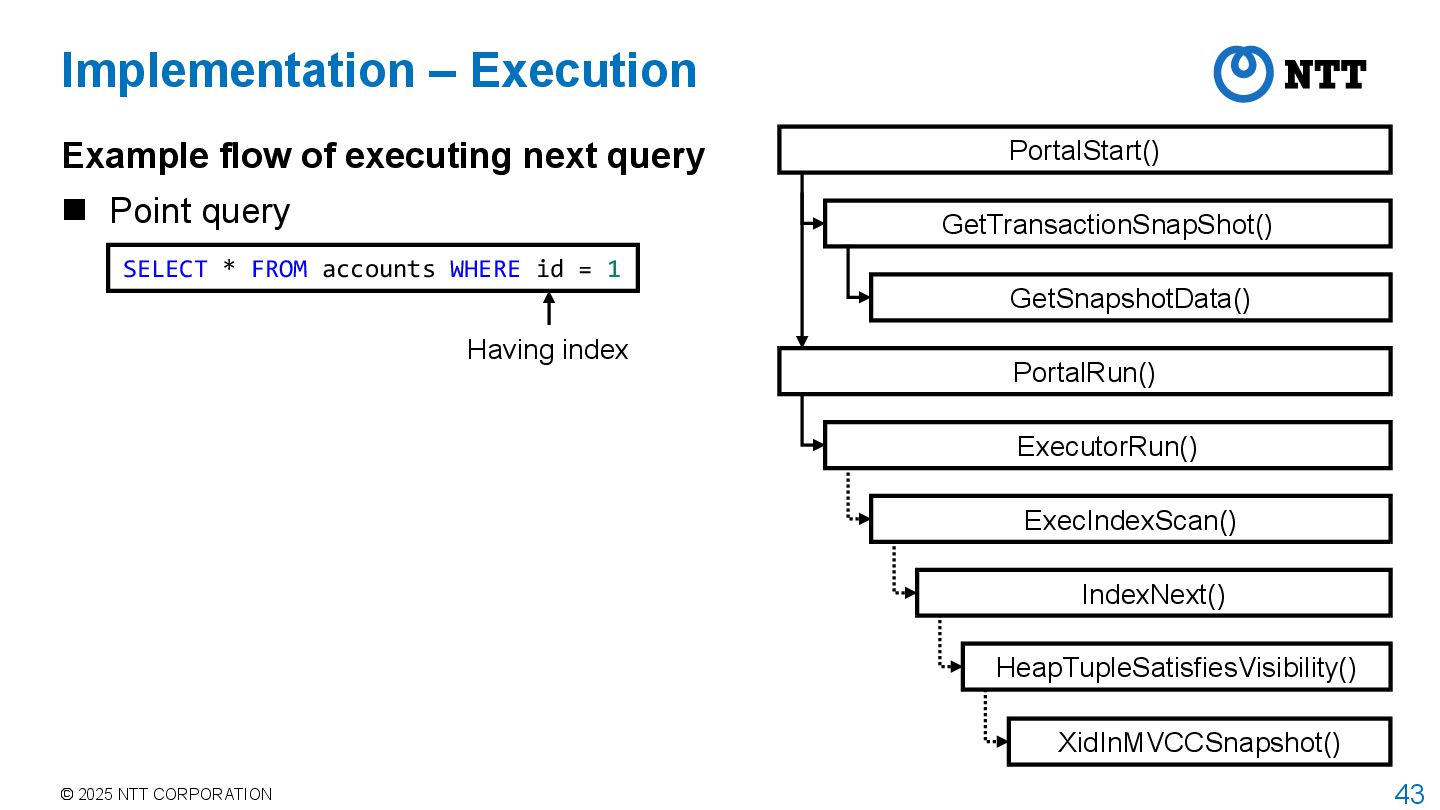
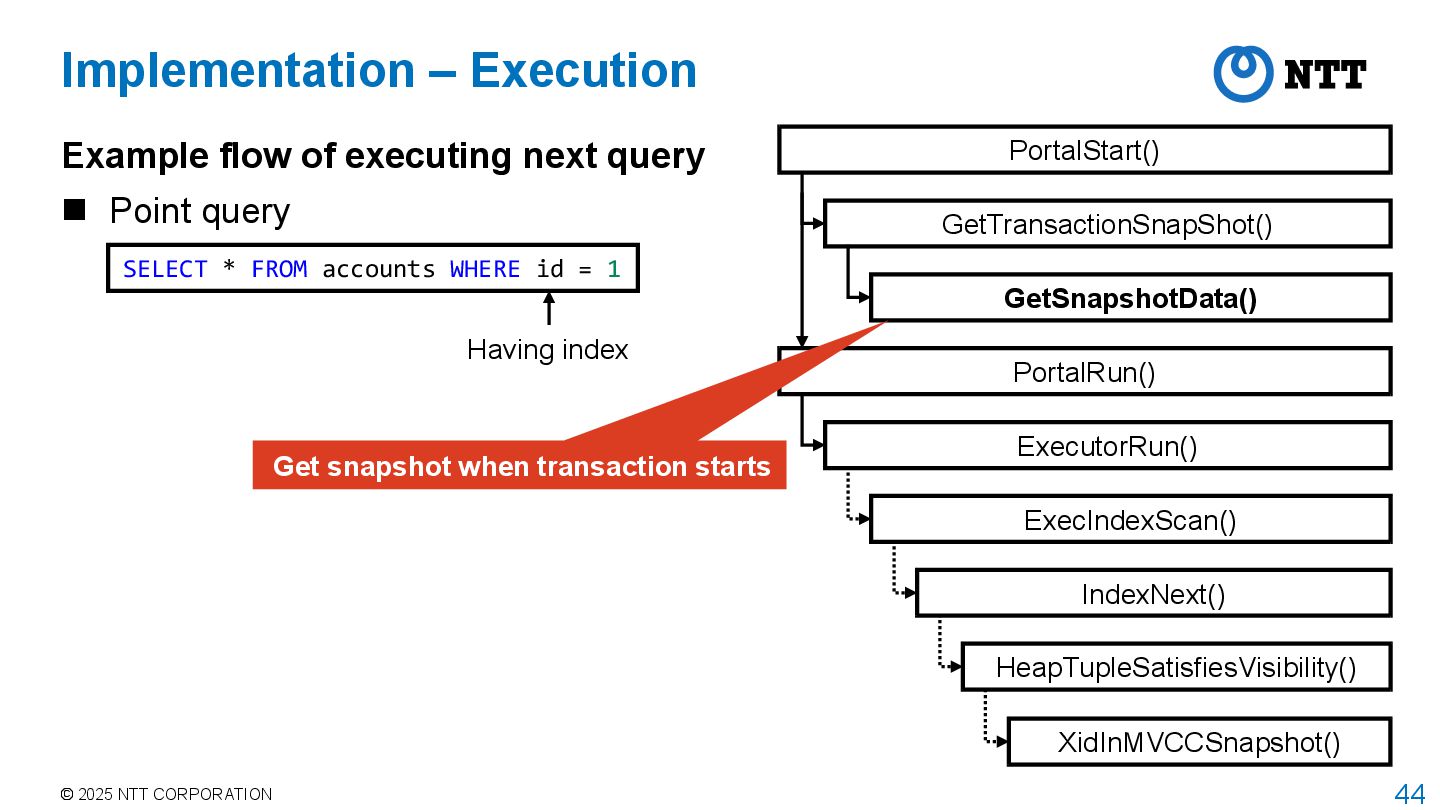
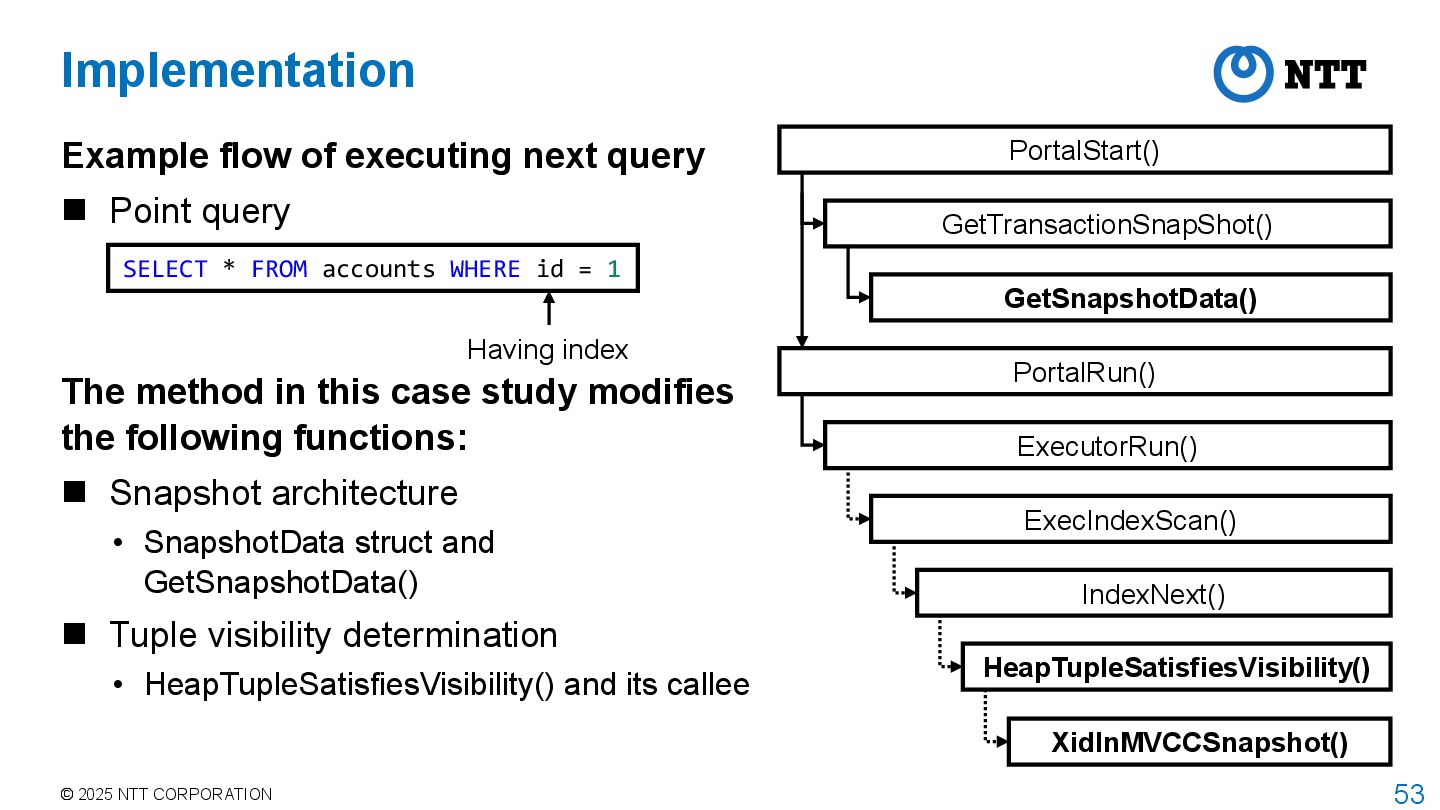
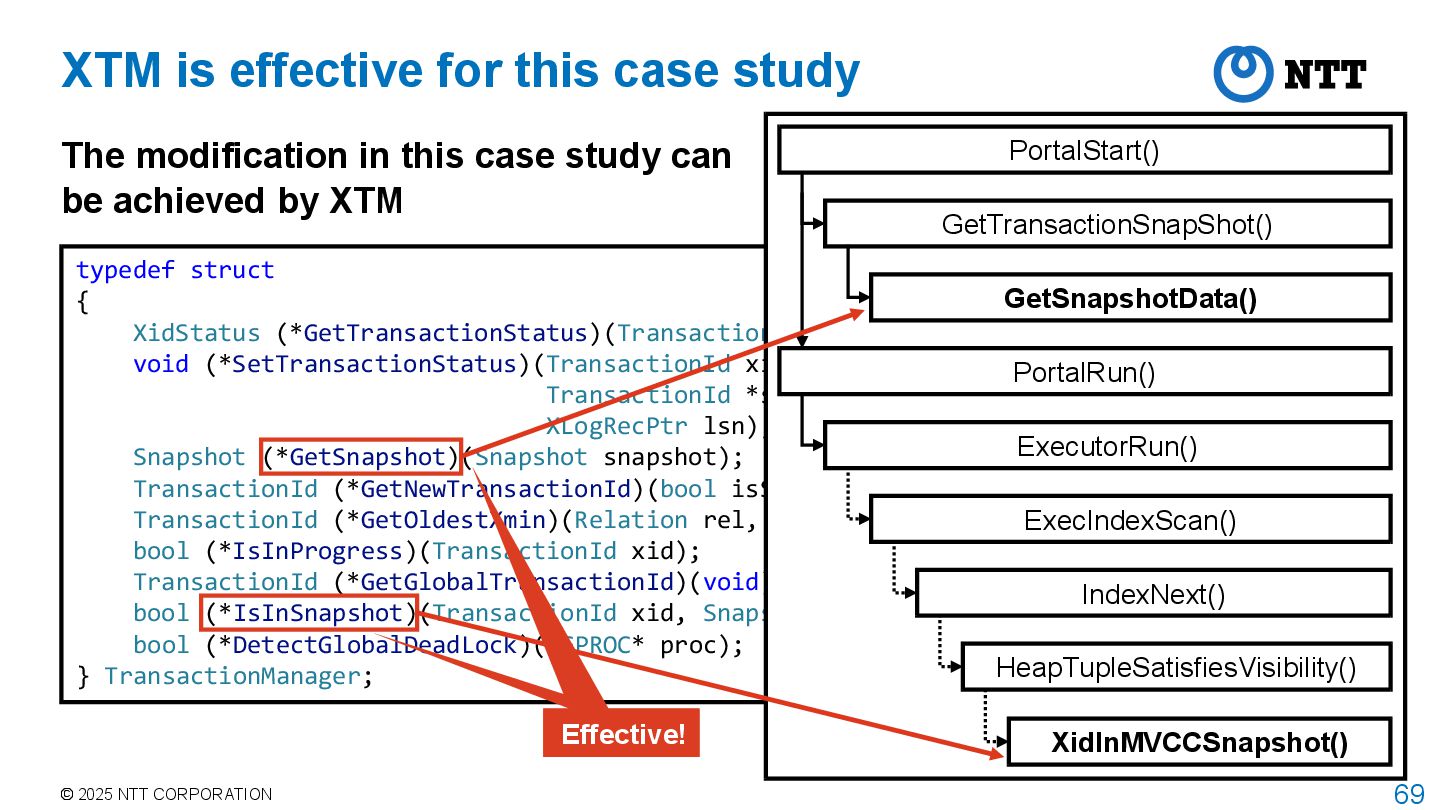
of executing next query Point query SELECT * FROM accounts WHERE id = 1 Having index PortalStart() GetTransactionSnapShot() PortalRun() ExecutorRun() GetSnapshotData() ExecIndexScan() IndexNext() HeapTupleSatisfiesVisibility() XidInMVCCSnapshot()
query Point query PortalStart() GetTransactionSnapShot() PortalRun() ExecutorRun() GetSnapshotData() ExecIndexScan() IndexNext() HeapTupleSatisfiesVisibility() XidInMVCCSnapshot() Implementation – Execution Having index SELECT * FROM accounts WHERE id = 1 Get snapshot when transaction starts
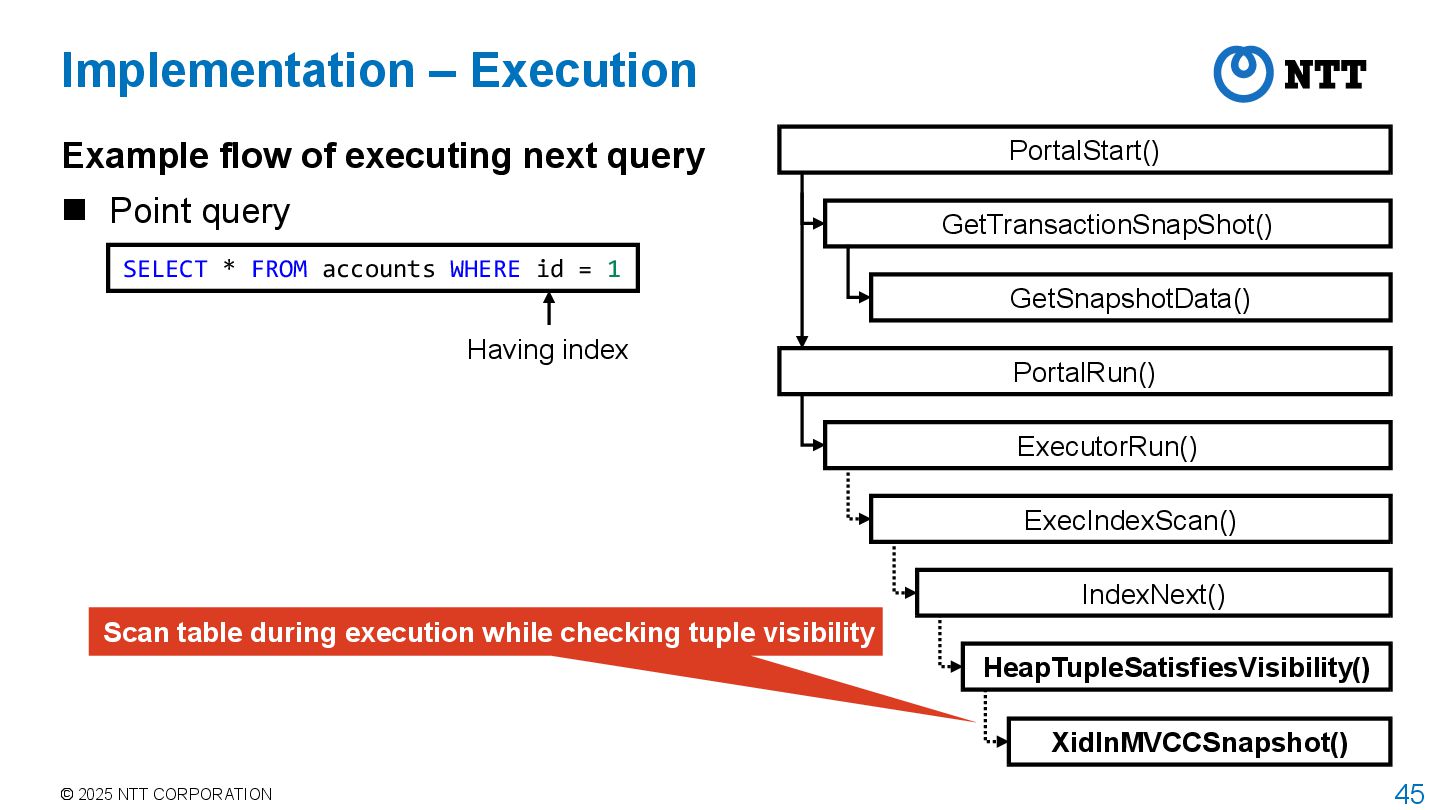
query Point query PortalStart() GetTransactionSnapShot() PortalRun() ExecutorRun() GetSnapshotData() ExecIndexScan() IndexNext() HeapTupleSatisfiesVisibility() XidInMVCCSnapshot() Implementation – Execution Having index Scan table during execution while checking tuple visibility SELECT * FROM accounts WHERE id = 1
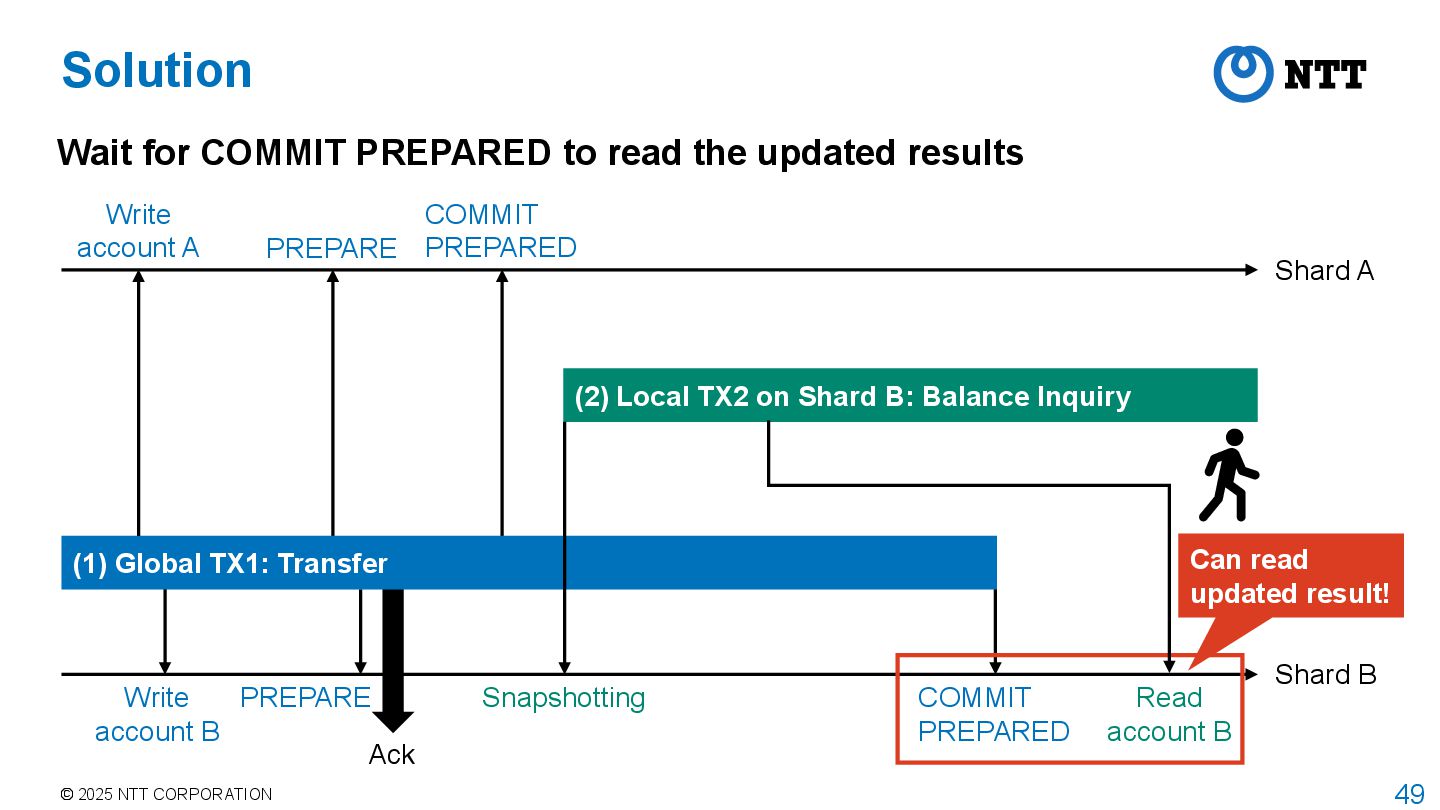
Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B Problem is that the read of account B is done before COMMIT PREPARED
to read the updated results Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B Can read updated result!
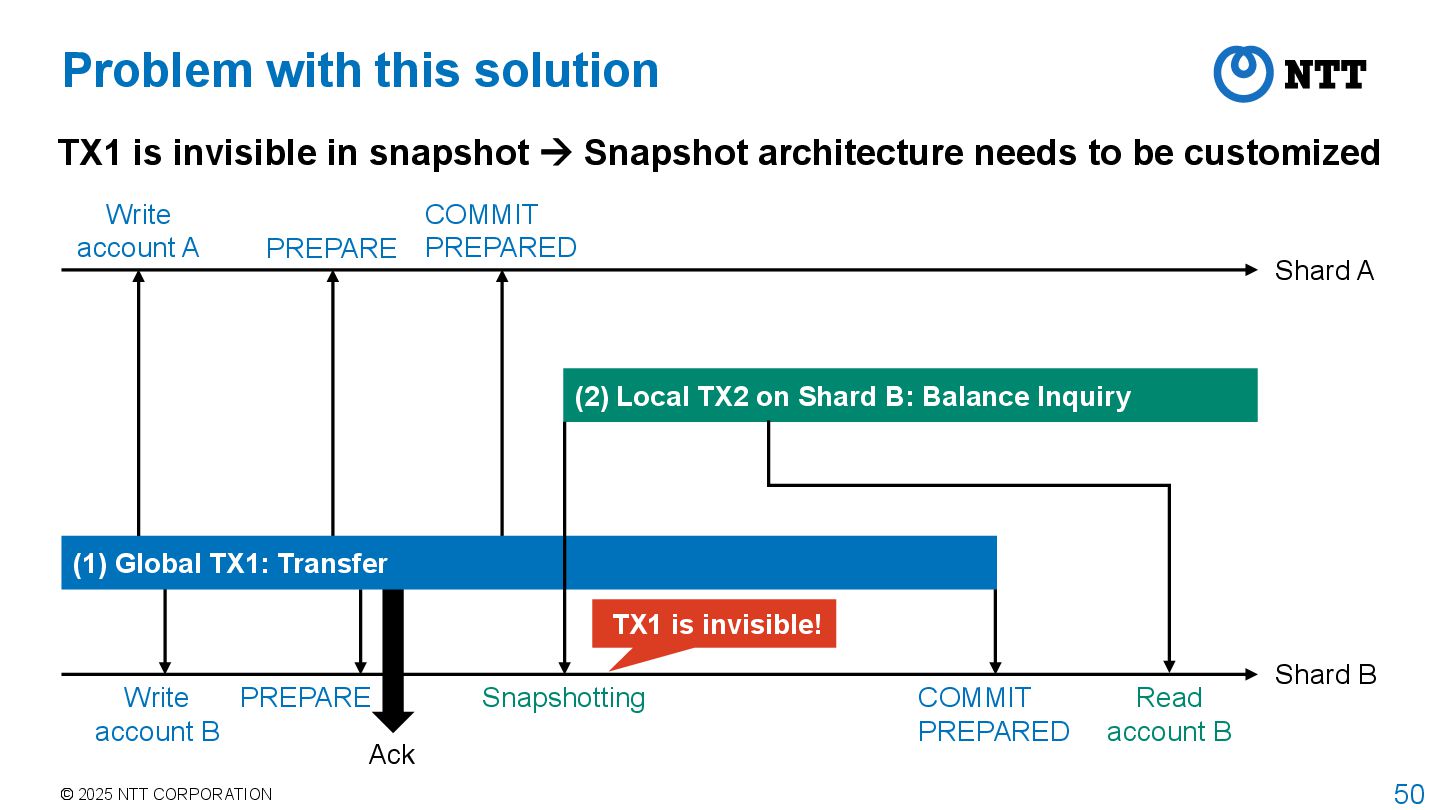
is invisible in snapshot Snapshot architecture needs to be customized Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B TX1 is invisible!
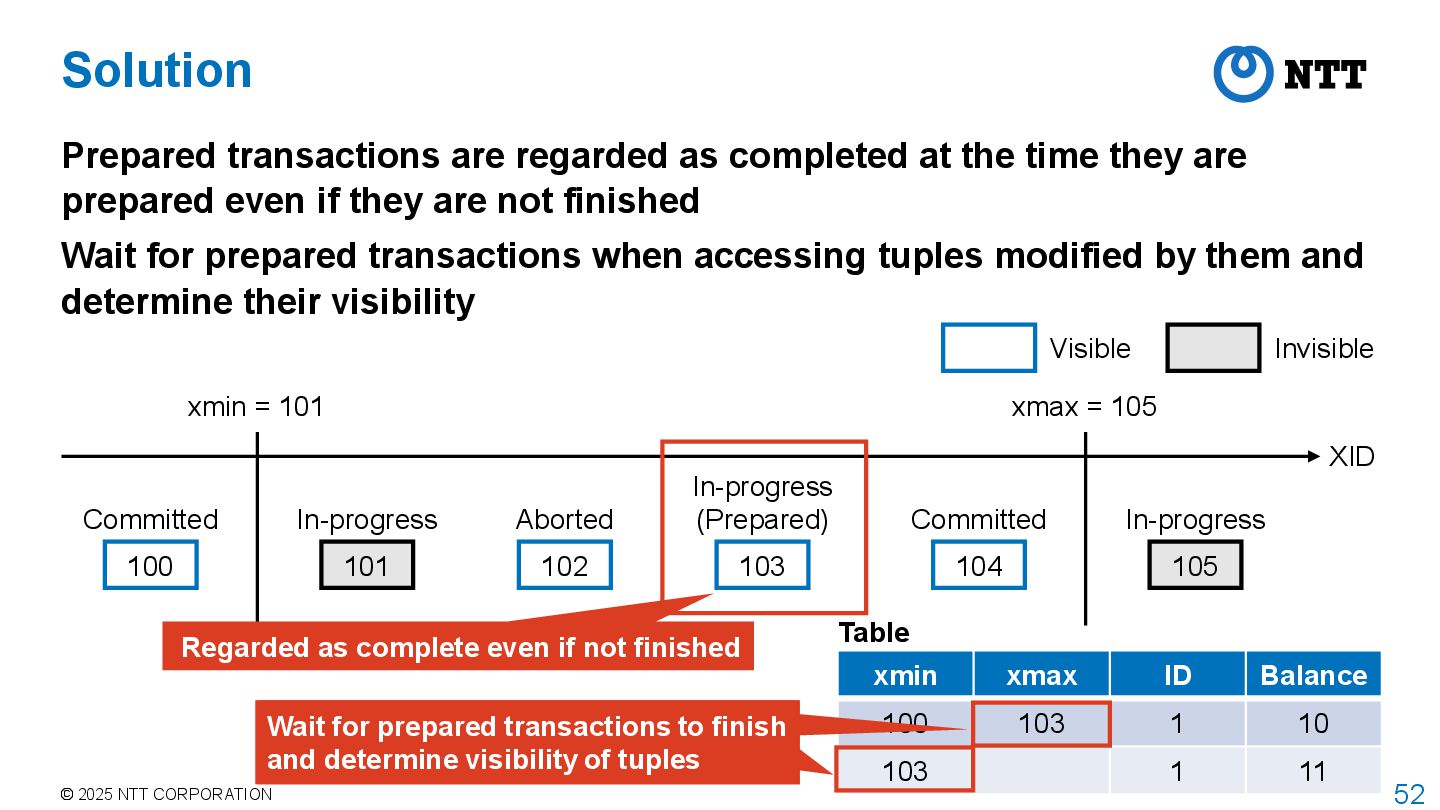
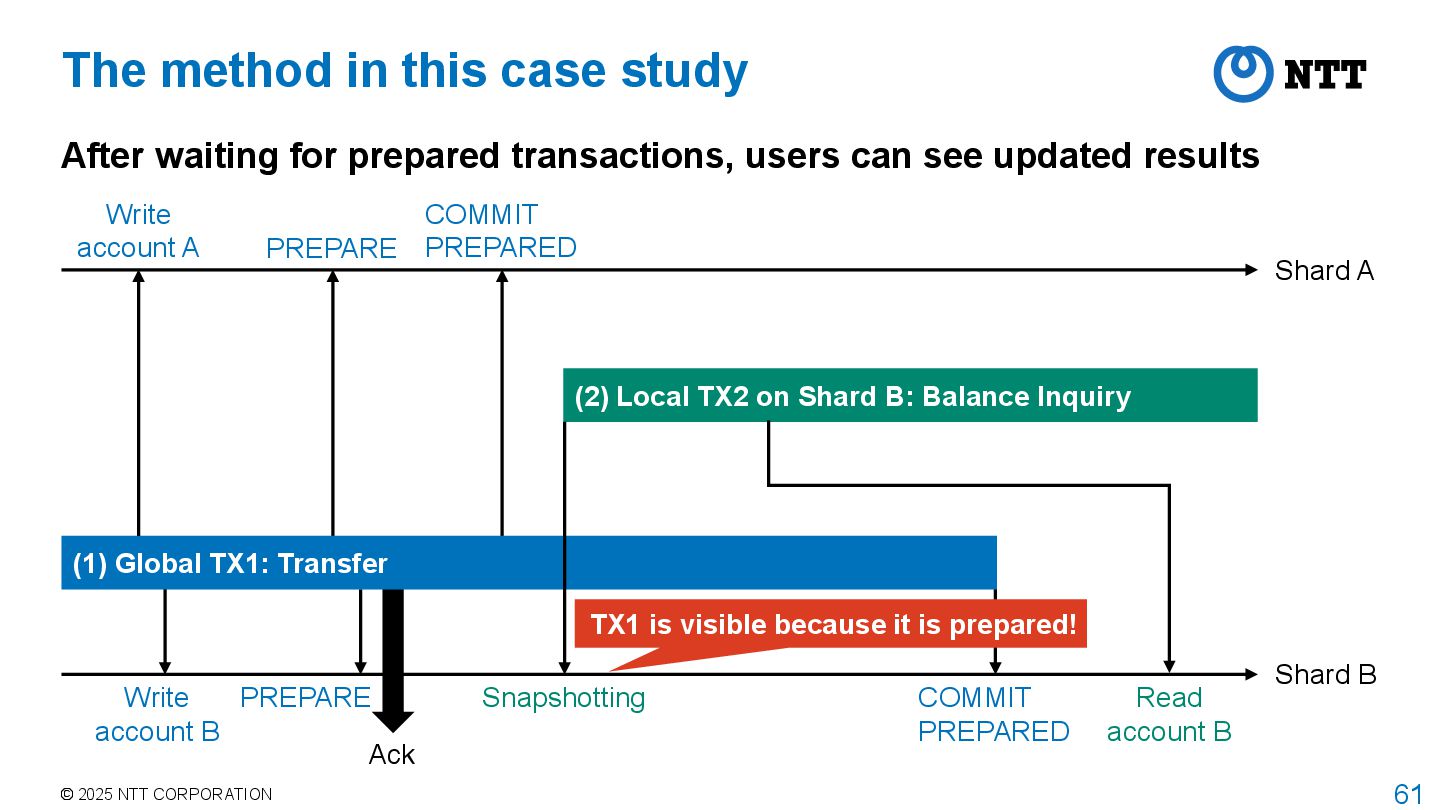
as completed at the time they are prepared even if they are not finished Wait for prepared transactions when accessing tuples modified by them and determine their visibility XID 100 Committed 101 In-progress 102 Aborted 103 In-progress (Prepared) 104 Committed 105 In-progress xmin = 101 xmax = 105 Visible Invisible Regarded as complete even if not finished xmin xmax ID Balance 100 103 1 10 103 1 11 Wait for prepared transactions to finish and determine visibility of tuples Table
next query Point query The method in this case study modifies the following functions: Snapshot architecture • SnapshotData struct and GetSnapshotData() Tuple visibility determination • HeapTupleSatisfiesVisibility() and its callee Having index SELECT * FROM accounts WHERE id = 1 PortalStart() GetTransactionSnapShot() PortalRun() ExecutorRun() GetSnapshotData() ExecIndexScan() IndexNext() HeapTupleSatisfiesVisibility() XidInMVCCSnapshot()
to hold transactions that were prepared when the snapshot was taken Before typedef struct SnapshotData { … /* all XID < xmin are visible to me */ TransactionId xmin; /* all XID >= xmax are invisible to me */ TransactionId xmax; … TransactionId *xip; uint32 xcnt; /* # of xact ids in xip[] */ … } SnapshotData; In-progress transactions Implementation – Snapshot
typedef struct SnapshotData { … /* all XID < xmin are visible to me */ TransactionId xmin; /* all XID >= xmax are invisible to me */ TransactionId xmax; … TransactionId *xip; uint32 xcnt; /* # of xact ids in xip[] */ … TransactionId *x2pc; uint32 x2pc_cnt; /* # of xact ids in x2pc[] */ … } SnapshotData; Implementation – Snapshot Add a field to SnapshotData to hold transactions that were prepared when the snapshot was taken After Prepared transactions
visibility determination is done by HeapTupleSatisfiesVisibility() MVCC is important in this case study bool HeapTupleSatisfiesVisibility(HeapTuple htup, Snapshot snapshot, Buffer buffer) { switch (snapshot->snapshot_type) { case SNAPSHOT_MVCC: return HeapTupleSatisfiesMVCC(htup, snapshot, buffer); … } … } Is the given tuple (htup) visible according to the given snapshot?
the given snapshot bool XidInMVCCSnapshot(TransactionId xid, Snapshot snapshot) { /* Wait for prepared transactions */ if (pg_lfind32(xid, snapshot->x2pc, snapshot->x2pc_cnt)) XactLockTableWait(xid, NULL, NULL, XLTW_None); } Implementation – Visibility determination static bool HeapTupleSatisfiesMVCC(HeapTuple htup, Snapshot snapshot, Buffer buffer) { if (!HeapTupleHeaderXminCommitted(tuple)) { else if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot)) return false; else if (TransactionIdDidCommit(HeapTupleHeaderGetRawXmin(tuple))) SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED, HeapTupleHeaderGetRawXmin(tuple)); } } Check xmin according to snapshot If xmin is prepared in snapshot, wait for it to finish
study After waiting for prepared transactions, users can see updated results Shard A Shard B PREPARE COMMIT PREPARED PREPARE Snapshotting (2) Local TX2 on Shard B: Balance Inquiry (1) Global TX1: Transfer Read account B COMMIT PREPARED Ack Write account A Write account B TX1 is visible because it is prepared!
with SmallBank benchmark Schema • Tables for users and their accounts Six types of queries • Balance inquiry • Amalgamate • Etc. CREATE TABLE accounts ( custid bigint NOT NULL, name varchar(64) NOT NULL, CONSTRAINT pk_accounts PRIMARY KEY (custid) ); CREATE INDEX idx_accounts_name ON accounts (name); CREATE TABLE savings ( custid bigint NOT NULL, bal float NOT NULL, CONSTRAINT pk_savings PRIMARY KEY (custid), FOREIGN KEY (custid) REFERENCES accounts (custid) ); CREATE TABLE checking ( custid bigint NOT NULL, bal float NOT NULL, CONSTRAINT pk_checking PRIMARY KEY (custid), FOREIGN KEY (custid) REFERENCES accounts (custid) ); SELECT bal FROM savings WHERE custid = ? UPDATE savings SET bal = bal - ? WHERE custid = ?
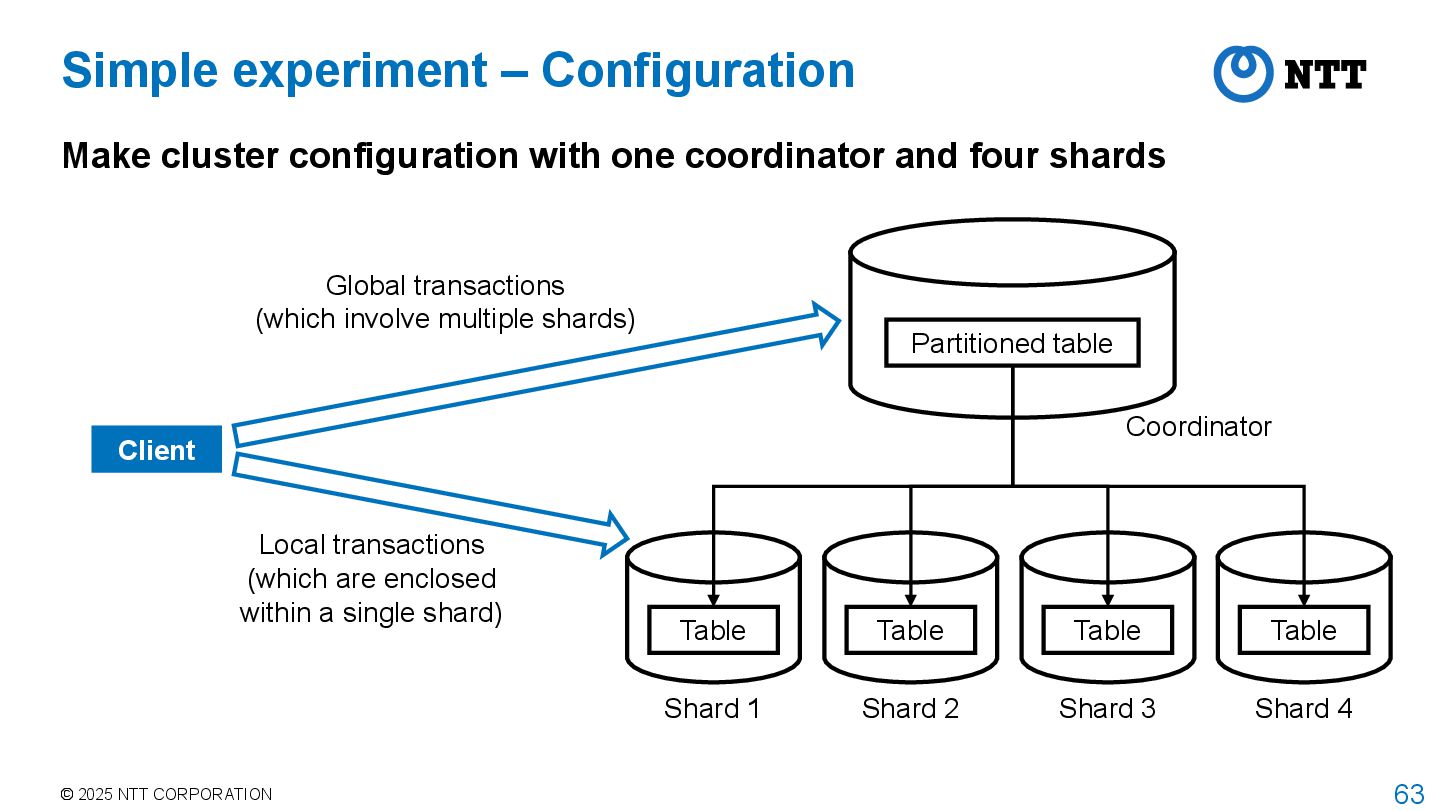
cluster configuration with one coordinator and four shards Table Table Table Partitioned table Coordinator Shard 1 Shard 2 Shard 3 Table Shard 4 Client Global transactions (which involve multiple shards) Local transactions (which are enclosed within a single shard)
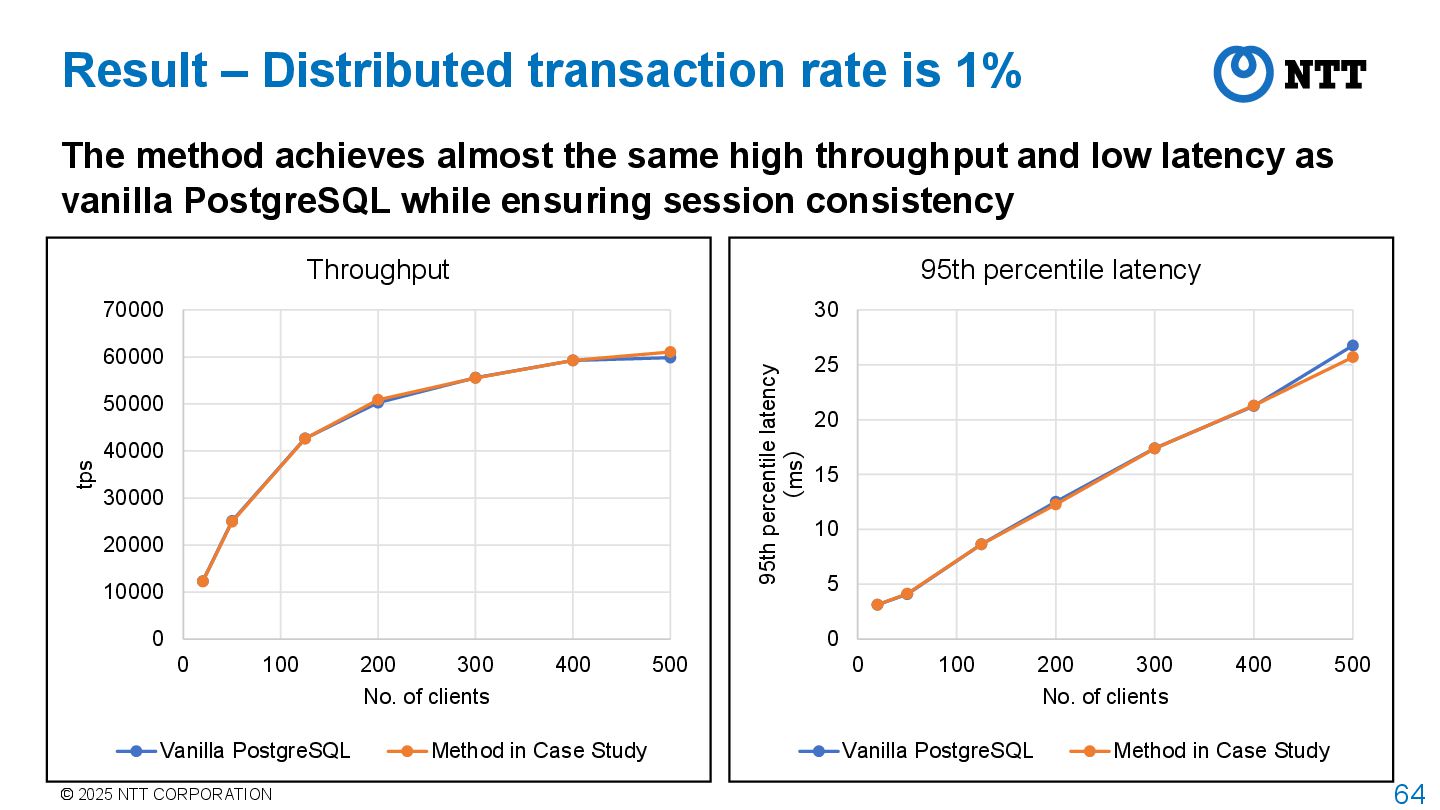
is 1% The method achieves almost the same high throughput and low latency as vanilla PostgreSQL while ensuring session consistency 0 10000 20000 30000 40000 50000 60000 70000 0 100 200 300 400 500 tps No. of clients Throughput Vanilla PostgreSQL Method in Case Study 0 5 10 15 20 25 30 0 100 200 300 400 500 95th percentile latency (ms) No. of clients 95th percentile latency Vanilla PostgreSQL Method in Case Study
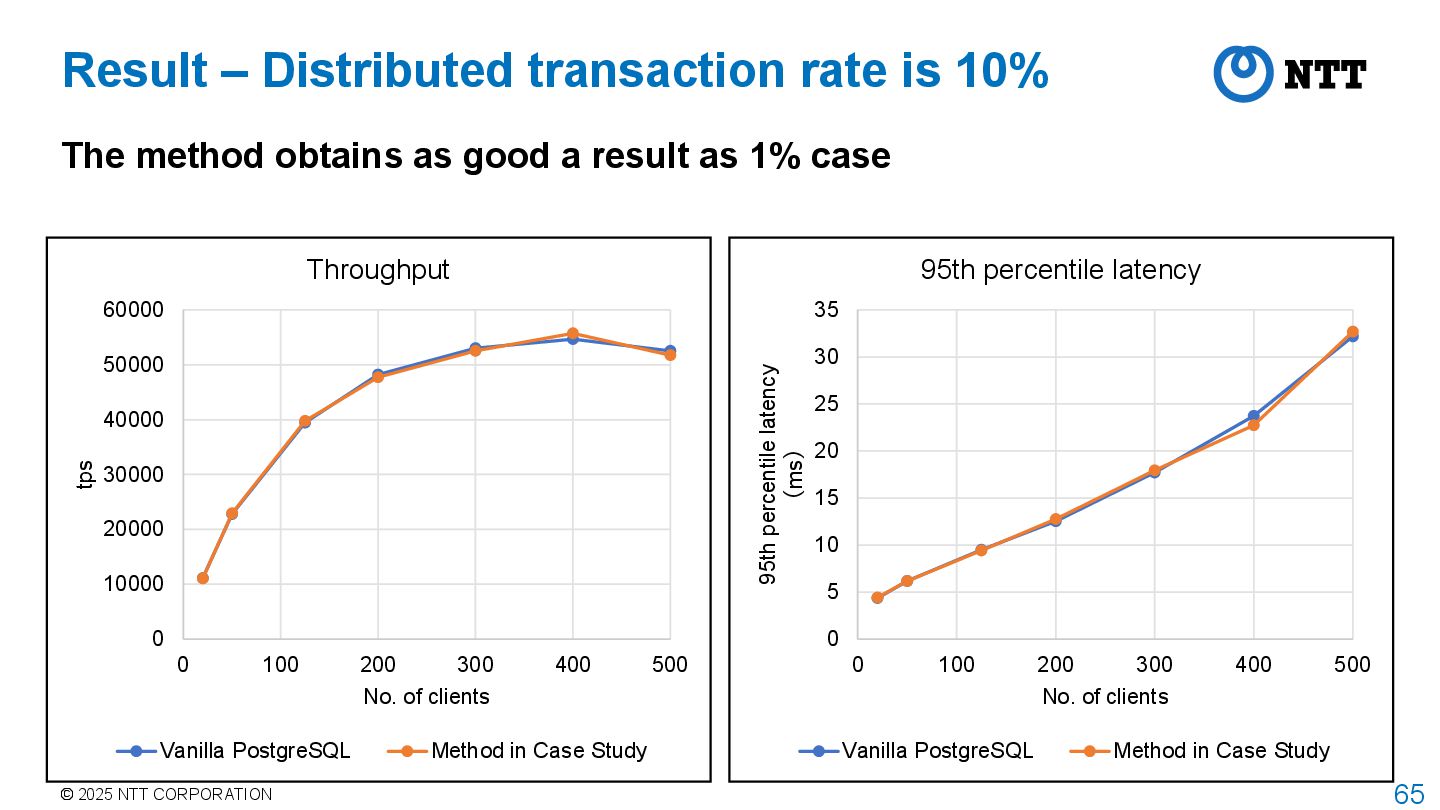
a result as 1% case 0 10000 20000 30000 40000 50000 60000 0 100 200 300 400 500 tps No. of clients Throughput Vanilla PostgreSQL Method in Case Study 0 5 10 15 20 25 30 35 0 100 200 300 400 500 95th percentile latency (ms) No. of clients 95th percentile latency Vanilla PostgreSQL Method in Case Study Result – Distributed transaction rate is 10%
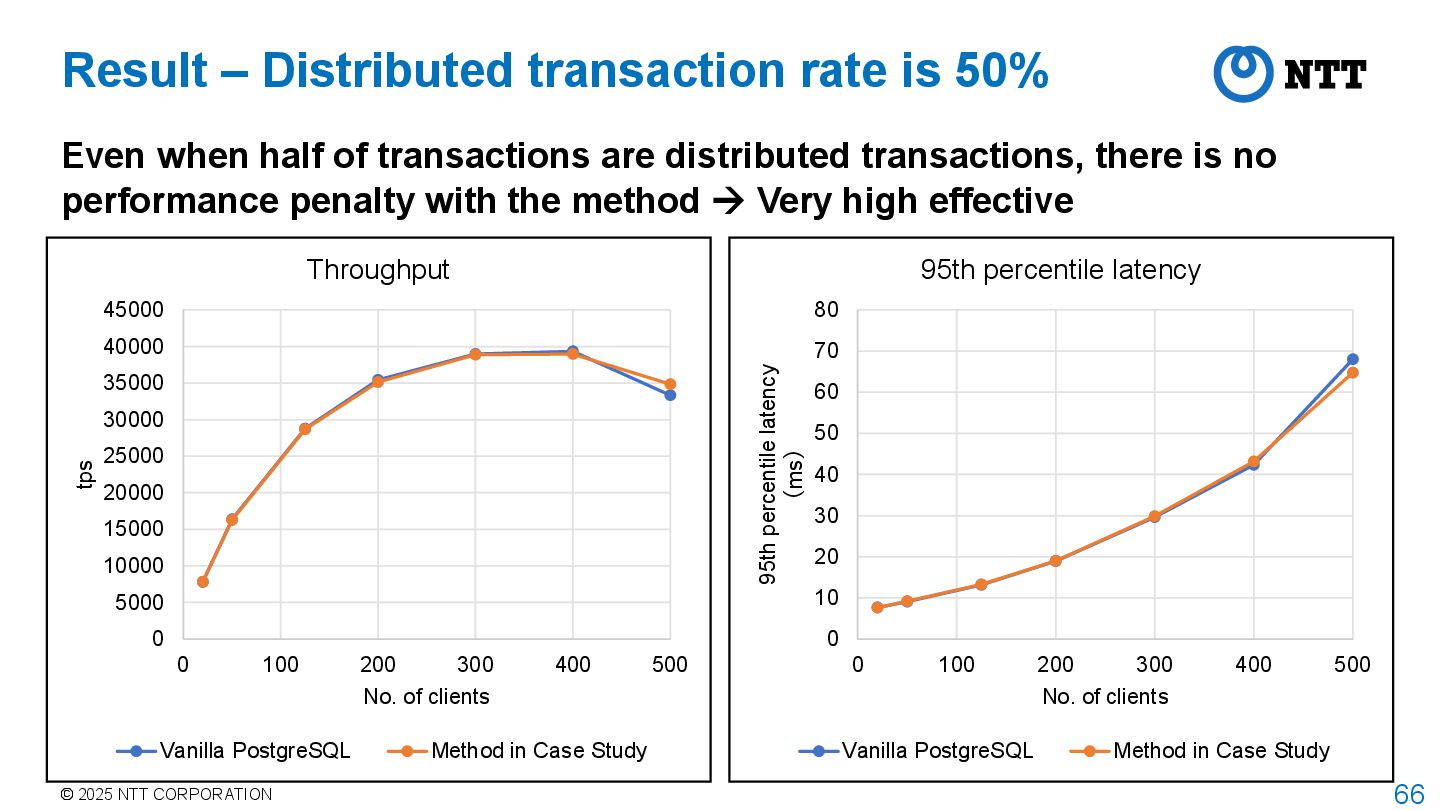
are distributed transactions, there is no performance penalty with the method Very high effective 0 5000 10000 15000 20000 25000 30000 35000 40000 45000 0 100 200 300 400 500 tps No. of clients Throughput Vanilla PostgreSQL Method in Case Study 0 10 20 30 40 50 60 70 80 0 100 200 300 400 500 95th percentile latency (ms) No. of clients 95th percentile latency Vanilla PostgreSQL Method in Case Study Result – Distributed transaction rate is 50%
method is generally not suitable for snapshot isolation Transactions that were in progress when the snapshot was taken are visible It behaves differently from snapshot isolation in PostgreSQL However, it takes advantage of the following user-specific assumptions READ COMMITTED is enough as an isolation level • READ COMMITTED allows reading the latest data for each command • In PostgreSQL, if two transactions write the same tuple, the successor waits for the predecessor and re-reads the updated tuple (“READ COMMITTED Update Checking”) • The method in this case study is similar to this (but has potential risk of infinite wait) If users understand these restrictions and assumptions, they can enjoy significant benefits that are not available with normal transaction methods Highlights the strong need for introducing custom transaction methods
Very simple implementation Ensures session consistency even when users bypass coordinator High throughput and low latency Cons Different behavior from standard snapshot isolation Potential risk of infinite wait Requires modifications to PostgreSQL core XTM is needed! Preferable to be implemented as an extension for users who can understand the method deeply and use it carefully Significant benefits that are not available with normal transaction methods
situation surrounding PostgreSQL has changed greatly since 2015 2015, when XTM was first proposed • Sharded clusters were underdeveloped in PostgreSQL • Distributed configurations were limited to a few users 2025 (Today) • PostgreSQL is widely utilized with many distributed configurations, such as built-in sharding or other extensions • Cloud providers also offer a wide range of managed distributed databases • Many users are taking full advantage of these technologies No single transaction manager can meet all these increasingly diverse requirements XTM is significantly rising in importance today
XTM provide enough APIs for transactional extensibility? If XTM is merged into the PostgreSQL core, we need to maintain it forever To provide APIs for XTM, we must confirm that the APIs can satisfy a wide range of needs for transactional extensibility and are sufficient Finishing the design of XTM too early has potential problems from this point of view We need to implement various distributed transaction methods including lightweight or user-specific ones through XTM and discuss what extensibilities are missing in the current proposal to improve XTM designs A variety of user-specific examples are needed for discussion in the community I hope today’s talk will be the beginning of such a discussion
extensibility may be required to implement various kinds of transaction methods Modifications to the transaction manager affect a wide range of components in the PostgreSQL system • Replication, crash recovery, WAL logging, etc. The case study in this talk may indeed have some problems (e.g., with WAL application, etc.) Rather than simply making the transaction manager pluggable, we must explore which modules of PostgreSQL will be affected by custom transaction methods and should be pluggable
continue to spread, the requirements for transaction methods are now diversifying, and existing methods fail to meet them The current PostgreSQL lacks transactional extensibility, thus preventing users from implementing user-specific transaction methods as extensions XTM is a promising solution, and this talk has presented a case study that highlights the potential of XTM to meet diverse user-specific needs The case study addressed the banking system and showed that XTM is effective to implement a user-specific transaction method while maintaining high performance To merge XTM into the PostgreSQL core, we need to discuss other extensibilities that are required to implement various transaction methods XTM is growing in importance and is worthy of continued discussion
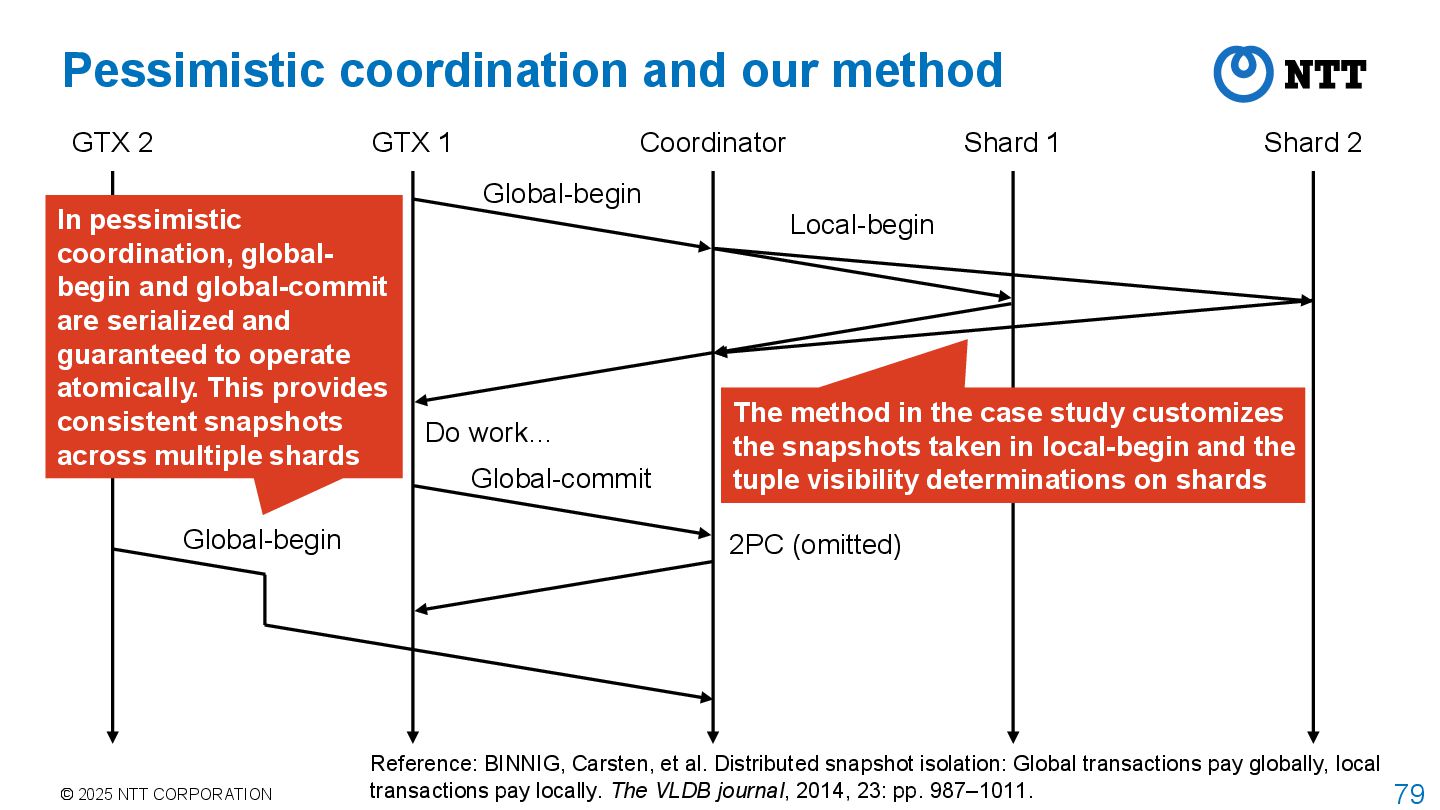
Coordinator Shard 1 Shard 2 GTX 1 GTX 2 Global-begin Local-begin Do work… Global-commit 2PC (omitted) Global-begin In pessimistic coordination, global- begin and global-commit are serialized and guaranteed to operate atomically. This provides consistent snapshots across multiple shards The method in the case study customizes the snapshots taken in local-begin and the tuple visibility determinations on shards Reference: BINNIG, Carsten, et al. Distributed snapshot isolation: Global transactions pay globally, local transactions pay locally. The VLDB journal, 2014, 23: pp. 987–1011.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}