Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SQLite 调优实践
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Frank Xu
September 02, 2014
Programming
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SQLite 调优实践
QQMail for Android 的 SQLite 调优实践
Frank Xu
September 02, 2014
More Decks by Frank Xu
See All by Frank Xu
Proxy Pattern
yyfrankyy
0
110
微信读书阅读器架构
yyfrankyy
2
2.3k
Watcher - EventBus Reinvented
yyfrankyy
0
170
FtnApp 的缩略图实践
yyfrankyy
0
83
JSDoc 的使用
yyfrankyy
0
170
交易平台化(前端)
yyfrankyy
0
200
淘宝搜索前端优化
yyfrankyy
0
230
淘宝排行榜 V3 项目总结
yyfrankyy
0
160
Other Decks in Programming
See All in Programming
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
520
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
9.1k
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
240
共通化で考えるべきは、実装より公開する型だった
codeegg
0
250
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
140
act2-costs.pdf
sumedhbala
0
110
1B+ /day規模のログを管理する技術
broadleaf
0
140
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
390
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
170
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
500
Featured
See All Featured
Facilitating Awesome Meetings
lara
57
7k
Un-Boring Meetings
codingconduct
0
350
Believing is Seeing
oripsolob
1
170
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
350
Thoughts on Productivity
jonyablonski
76
5.2k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
390
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Transcript
QQMail (Android) SQLite 调优实践 ayangxu
SQLite 调优实践 ❖ 统计先⾏行! ❖ ⽤用例分析! ❖ 策略选择
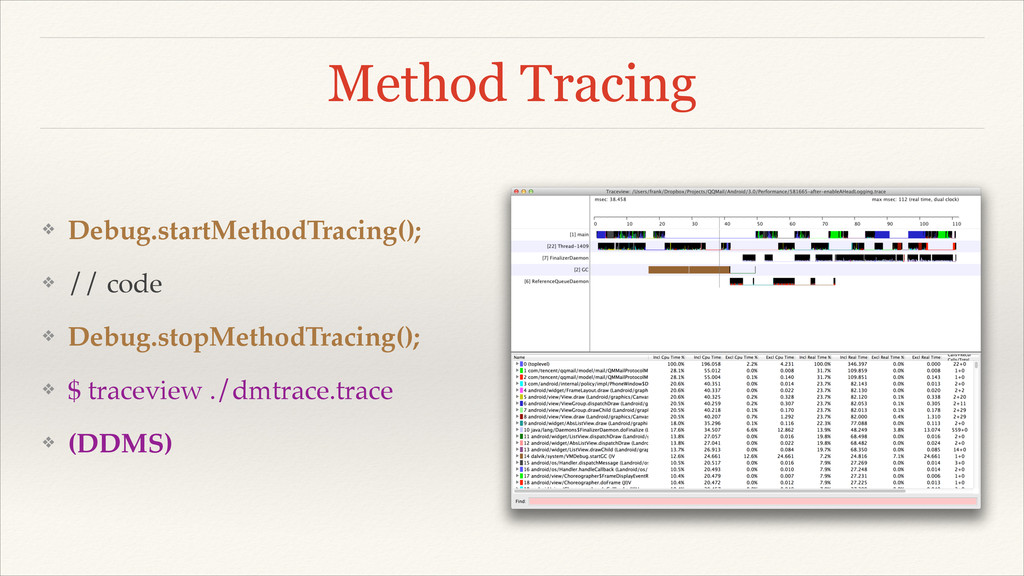
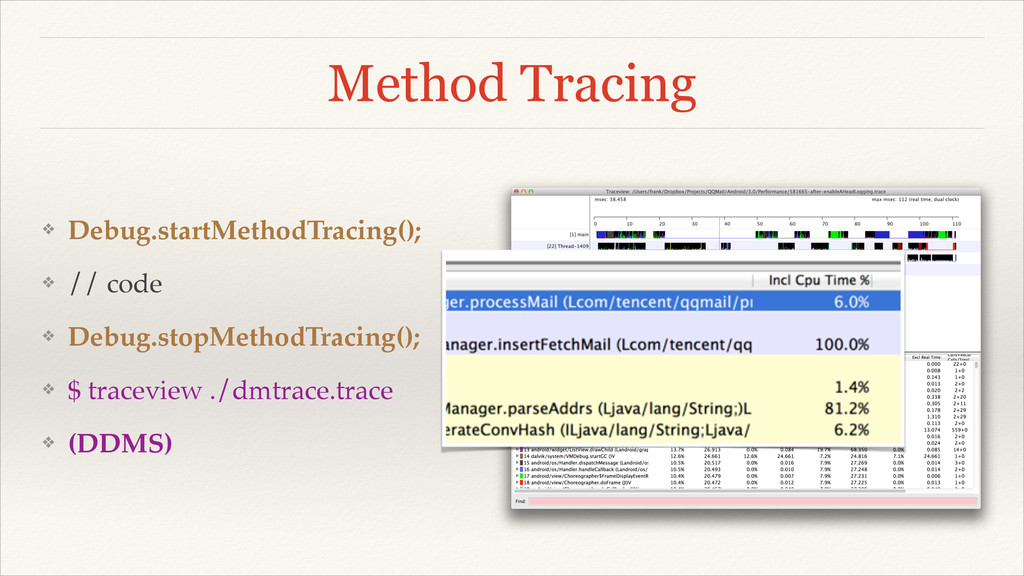
Method Tracing ❖ Debug.startMethodTracing();! ❖ // code! ❖ Debug.stopMethodTracing();! ❖
$ traceview ./dmtrace.trace! ❖ (DDMS)
Method Tracing ❖ Debug.startMethodTracing();! ❖ // code! ❖ Debug.stopMethodTracing();! ❖
$ traceview ./dmtrace.trace! ❖ (DDMS)
⽇日志打点 ❖ 基类抽象⽅方法前后! ❖ ⽐比较重的操作逐⾏行定位! ❖ 关键⼊入⼜⼝口/出⼜⼝口
⽇日志打点 ❖ 基类抽象⽅方法前后! ❖ ⽐比较重的操作逐⾏行定位! ❖ 关键⼊入⼜⼝口/出⼜⼝口
⽇日志打点 ❖ 基类抽象⽅方法前后! ❖ ⽐比较重的操作逐⾏行定位! ❖ 关键⼊入⼜⼝口/出⼜⼝口
⽇日志打点 ❖ 基类抽象⽅方法前后! ❖ ⽐比较重的操作逐⾏行定位! ❖ 关键⼊入⼜⼝口/出⼜⼝口
Case 分析 ❖ Case 1: Account/Folder 列表卡! ❖ Case 2:
重要联系⼈人列表查询慢! ❖ Case 3: 邮件操作后更新未读数! ❖ Case 4: MailList 滚动卡,⽆无法读信! ❖ Case 5: QMReadMailActivity
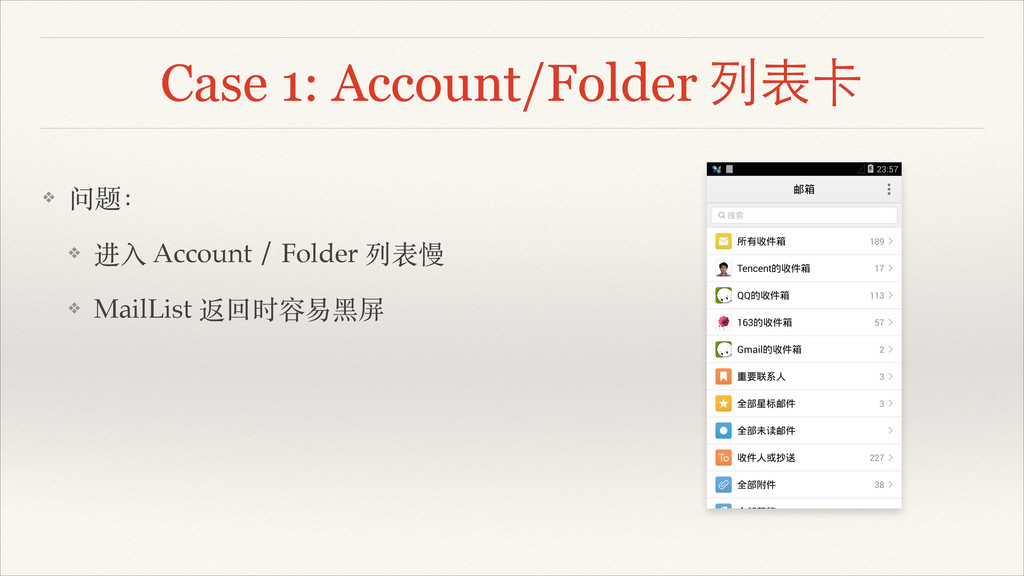
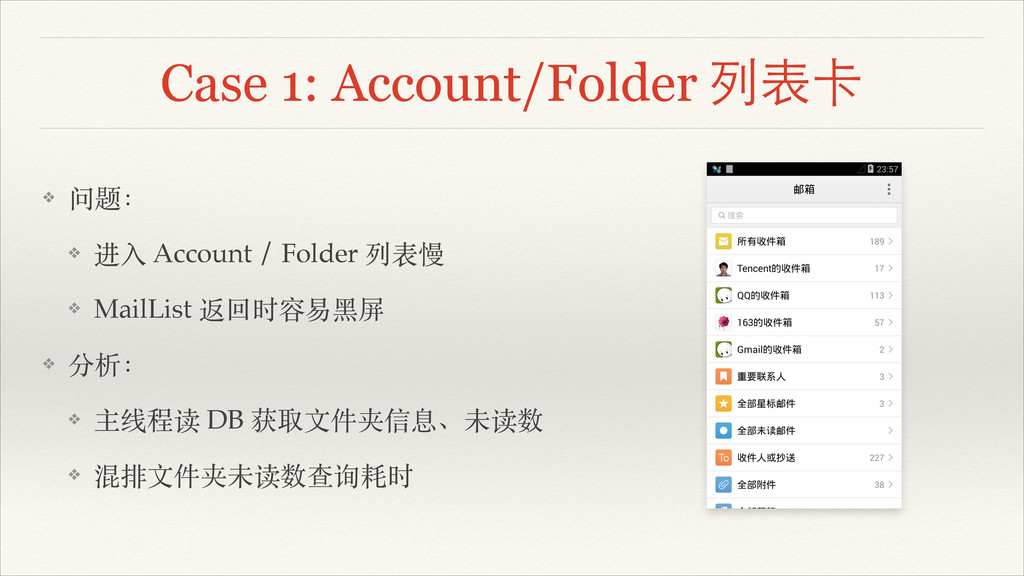
Case 1: Account/Folder 列表卡 ❖ 问题:! ❖ 进⼊入 Account /
Folder 列表慢! ❖ MailList 返回时容易⿊黑屏
Case 1: Account/Folder 列表卡 ❖ 问题:! ❖ 进⼊入 Account /
Folder 列表慢! ❖ MailList 返回时容易⿊黑屏 ❖ 分析:! ❖ 主线程读 DB 获取⽂文件夹信息、未读数! ❖ 混排⽂文件夹未读数查询耗时
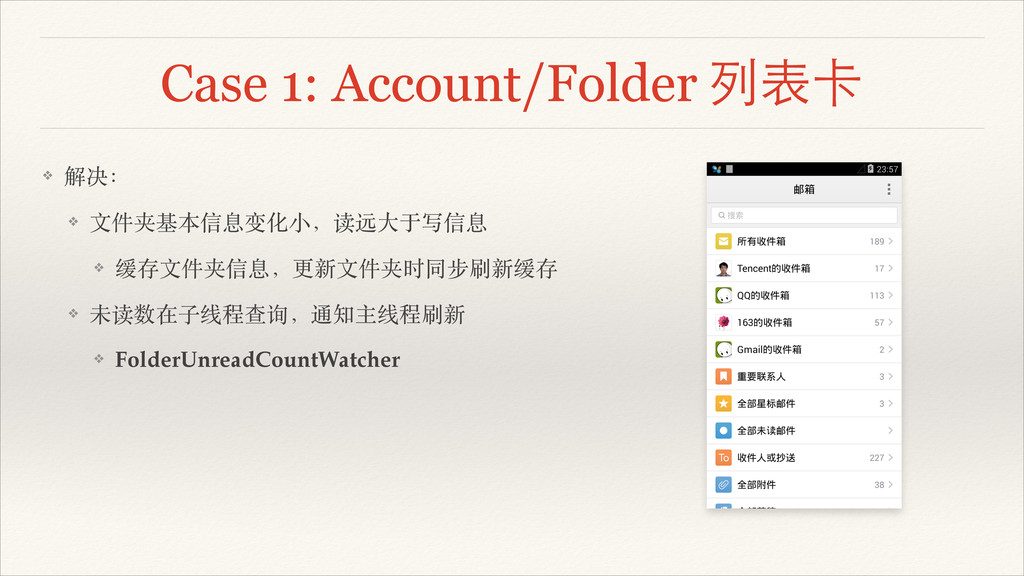
Case 1: Account/Folder 列表卡 ❖ 解决:! ❖ ⽂文件夹基本信息变化⼩小,读远⼤大于写信息! ❖ 缓存⽂文件夹信息,更新⽂文件夹时同步刷新缓存!
❖ 未读数在⼦子线程查询,通知主线程刷新! ❖ FolderUnreadCountWatcher
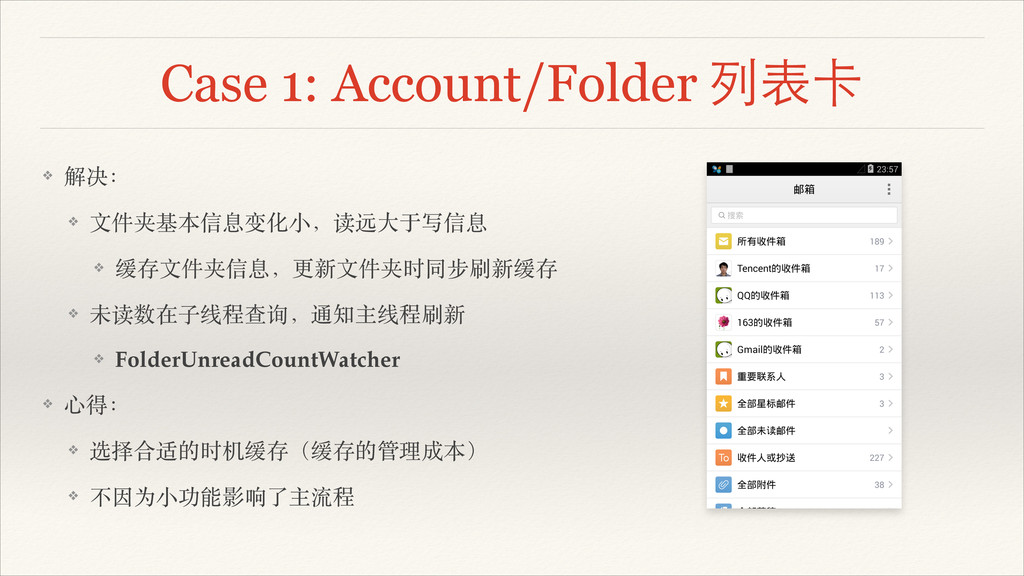
Case 1: Account/Folder 列表卡 ❖ 解决:! ❖ ⽂文件夹基本信息变化⼩小,读远⼤大于写信息! ❖ 缓存⽂文件夹信息,更新⽂文件夹时同步刷新缓存!
❖ 未读数在⼦子线程查询,通知主线程刷新! ❖ FolderUnreadCountWatcher ❖ ⼼心得:! ❖ 选择合适的时机缓存(缓存的管理成本)! ❖ 不因为⼩小功能影响了主流程
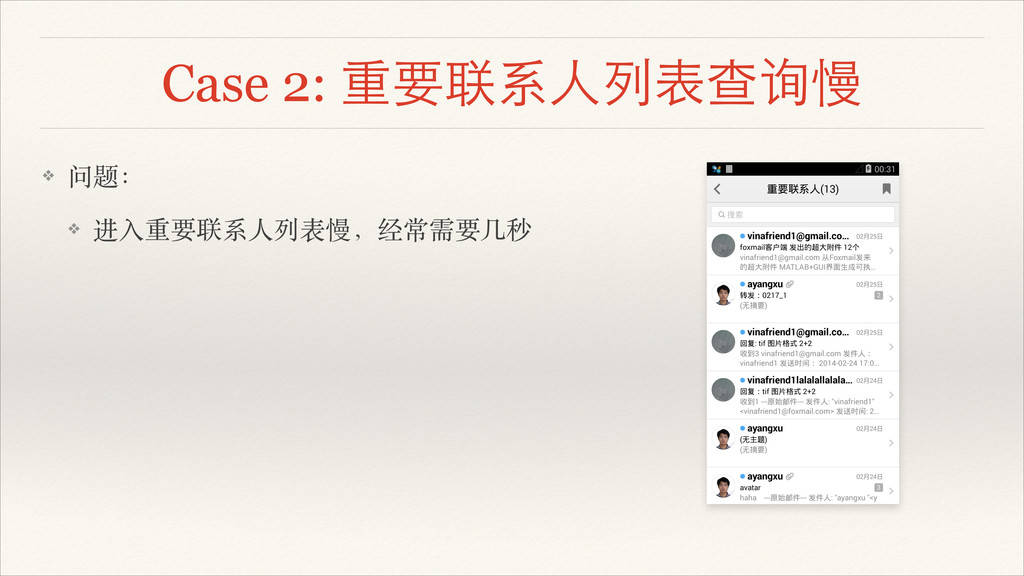
Case 2: 重要联系⼈人列表查询慢 ❖ 问题:! ❖ 进⼊入重要联系⼈人列表慢,经常需要⼏几秒
Case 2: 重要联系⼈人列表查询慢 ❖ 问题:! ❖ 进⼊入重要联系⼈人列表慢,经常需要⼏几秒 ❖ 分析:! ❖
SQL 查询复杂,四个表 INNER JOIN! ❖ 两次 QM_MAIL_INFO 表查询! ❖ 时间复杂度是 O (n^2 * m * a * b) n: 邮件数! ❖ 随着邮件数和联系⼈人数增长查询时间飙升
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优:
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms) ❖ CREATE INDEX(不佳,INNER JOIN 基本都是整表扫)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms) ❖ CREATE INDEX(不佳,INNER JOIN 基本都是整表扫) ❖ CREATE VIEW(不佳,因为 View 就是个快捷⽅方式)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms) ❖ CREATE INDEX(不佳,INNER JOIN 基本都是整表扫) ❖ CREATE VIEW(不佳,因为 View 就是个快捷⽅方式) ❖ ⼦子查询只查出来需要的字段,⽤用来代替 INNER JOIN(只加⼀一个⼦子查询不明显)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms) ❖ CREATE INDEX(不佳,INNER JOIN 基本都是整表扫) ❖ CREATE VIEW(不佳,因为 View 就是个快捷⽅方式) ❖ ⼦子查询只查出来需要的字段,⽤用来代替 INNER JOIN(只加⼀一个⼦子查询不明显) ❖ 更换 JOIN 的顺序(不佳,X * Y 和 Y * X 的区别)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优: ❖ GROUP BY ⼦子查询 (1400ms
→ 300 ms) ❖ CREATE INDEX(不佳,INNER JOIN 基本都是整表扫) ❖ CREATE VIEW(不佳,因为 View 就是个快捷⽅方式) ❖ ⼦子查询只查出来需要的字段,⽤用来代替 INNER JOIN(只加⼀一个⼦子查询不明显) ❖ 更换 JOIN 的顺序(不佳,X * Y 和 Y * X 的区别) ❖ ⽤用 DISTINCT convHash 代替以上的 GROUP BY(300ms → 20ms)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼀一次调优⼼心得:! ❖ DISTINCT 可以加速⼦子查询,减少⼦子查询的结果集! ❖ 重复字段多时,GROUP
BY 也是⼀一种⽅方案,⽤用于查询多列信息时加速
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼆二次调优(w/ terrytan):! ❖ sender_list 给 contact
表增加近 10 倍的数据,仅内域需要,拆表(~10x)! ❖ from 很多情况下都需要,冗余到 INFO 表! ❖ 全部 INNER JOIN 换成⼦子查询 DISTINCT (~2x)! ❖ 对引⽤用字段建⽴立索引(与 DISTINCT ⼀一起评估)
Case 2: 重要联系⼈人列表查询慢 ❖ 第⼆二次调优⼼心得:! ❖ ⼦子查询果断全部使⽤用 DISTINCT,放弃 INNER JOIN!
❖ 根据业务适当的做冗余和拆表
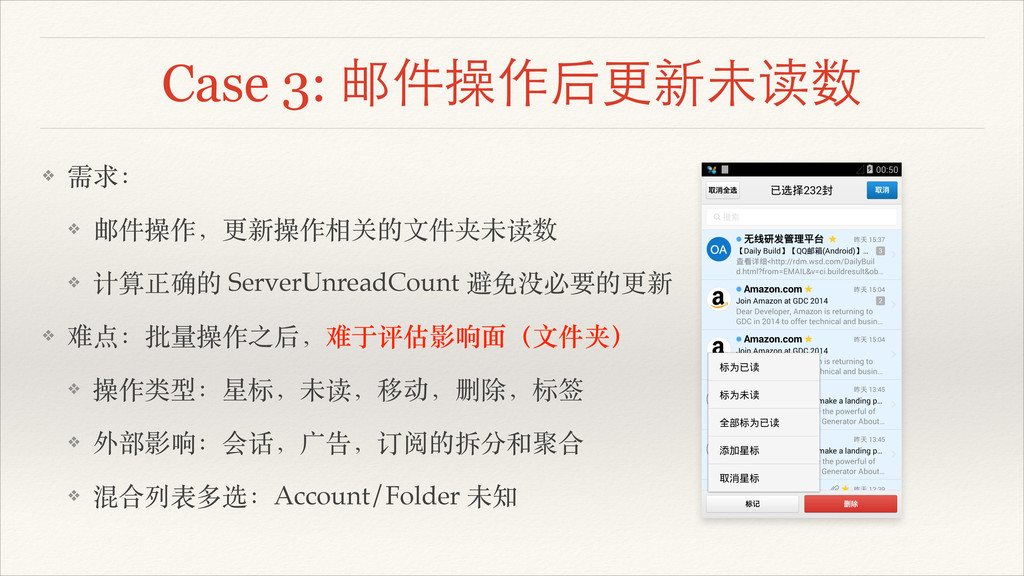
Case 3: 邮件操作后更新未读数 ❖ 需求:! ❖ 邮件操作,更新操作相关的⽂文件夹未读数! ❖ 计算正确的 ServerUnreadCount
避免没必要的更新
Case 3: 邮件操作后更新未读数 ❖ 需求:! ❖ 邮件操作,更新操作相关的⽂文件夹未读数! ❖ 计算正确的 ServerUnreadCount
避免没必要的更新 ❖ 难点:批量操作之后,难于评估影响⾯面(⽂文件夹)! ❖ 操作类型:星标,未读,移动,删除,标签! ❖ 外部影响:会话,⼴广告,订阅的拆分和聚合! ❖ 混合列表多选:Account/Folder 未知
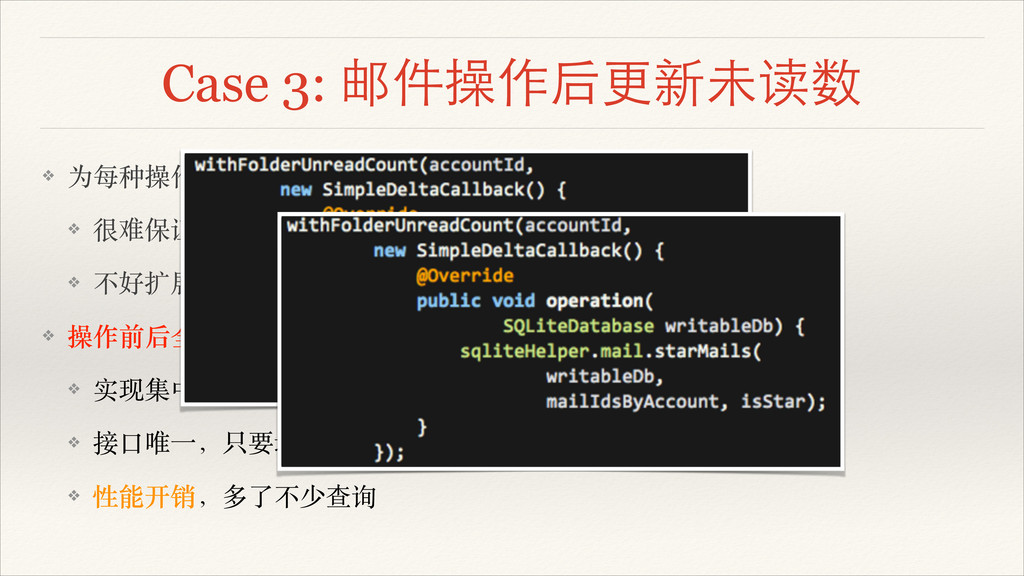
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
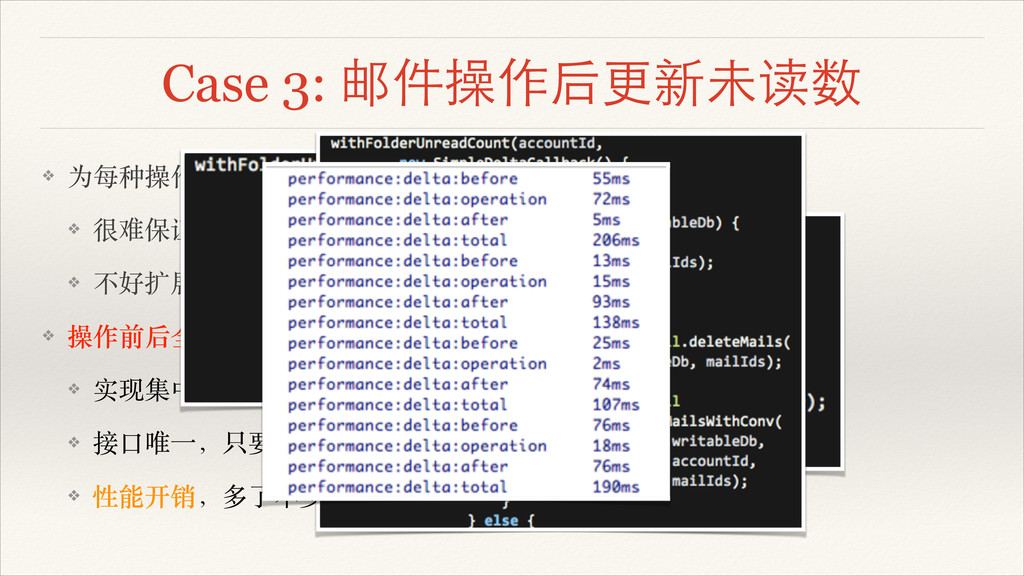
❖ 操作前后全部影响⾯面都算⼀一遍! ❖ 实现集中,BUG 也好定位! ❖ 接⼜⼝口唯⼀一,只要增加了影响未读数的操作,调⽤用的是同个接⼜⼝口! ❖ 性能开销,多了不少查询
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
❖ 操作前后全部影响⾯面都算⼀一遍! ❖ 实现集中,BUG 也好定位! ❖ 接⼜⼝口唯⼀一,只要增加了影响未读数的操作,调⽤用的是同个接⼜⼝口! ❖ 性能开销,多了不少查询
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
❖ 操作前后全部影响⾯面都算⼀一遍! ❖ 实现集中,BUG 也好定位! ❖ 接⼜⼝口唯⼀一,只要增加了影响未读数的操作,调⽤用的是同个接⼜⼝口! ❖ 性能开销,多了不少查询
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
❖ 操作前后全部影响⾯面都算⼀一遍! ❖ 实现集中,BUG 也好定位! ❖ 接⼜⼝口唯⼀一,只要增加了影响未读数的操作,调⽤用的是同个接⼜⼝口! ❖ 性能开销,多了不少查询
Case 3: 邮件操作后更新未读数 ❖ 为每种操作,评估影响⾯面,考虑各种因⼦子! ❖ 很难保证结果正确,BUG 位置分散! ❖ 不好扩展,增加⼀一种操作,就要考虑各种影响⾯面
❖ 操作前后全部影响⾯面都算⼀一遍! ❖ 实现集中,BUG 也好定位! ❖ 接⼜⼝口唯⼀一,只要增加了影响未读数的操作,调⽤用的是同个接⼜⼝口! ❖ 性能开销,多了不少查询
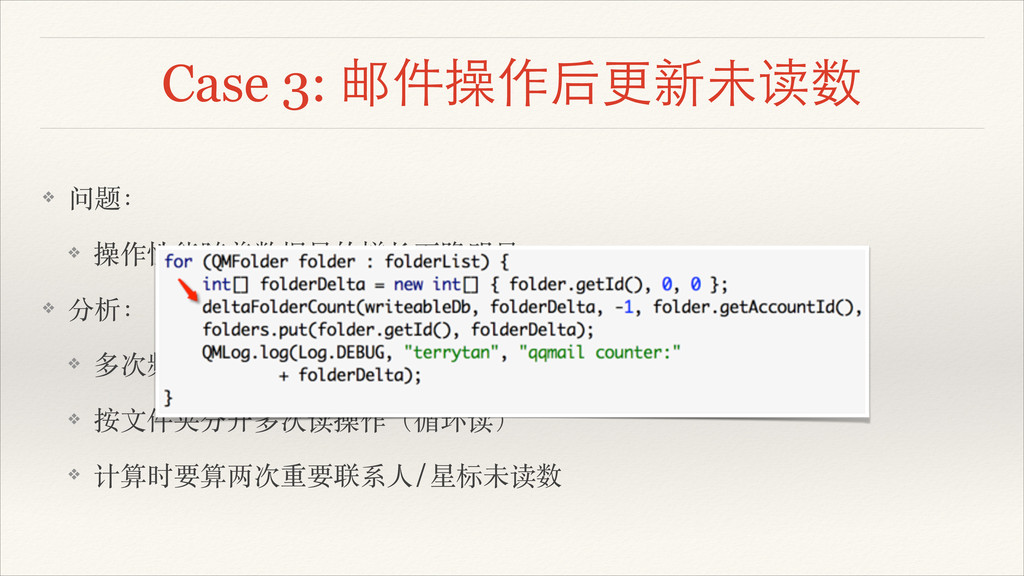
Case 3: 邮件操作后更新未读数 ❖ 问题:! ❖ 操作性能随着数据量的增长下降明显! ❖ 分析:! ❖
多次频繁扫 INFO 表! ❖ 按⽂文件夹分开多次读操作(循环读)! ❖ 计算时要算两次重要联系⼈人/星标未读数
Case 3: 邮件操作后更新未读数 ❖ 问题:! ❖ 操作性能随着数据量的增长下降明显! ❖ 分析:! ❖
多次频繁扫 INFO 表! ❖ 按⽂文件夹分开多次读操作(循环读)! ❖ 计算时要算两次重要联系⼈人/星标未读数
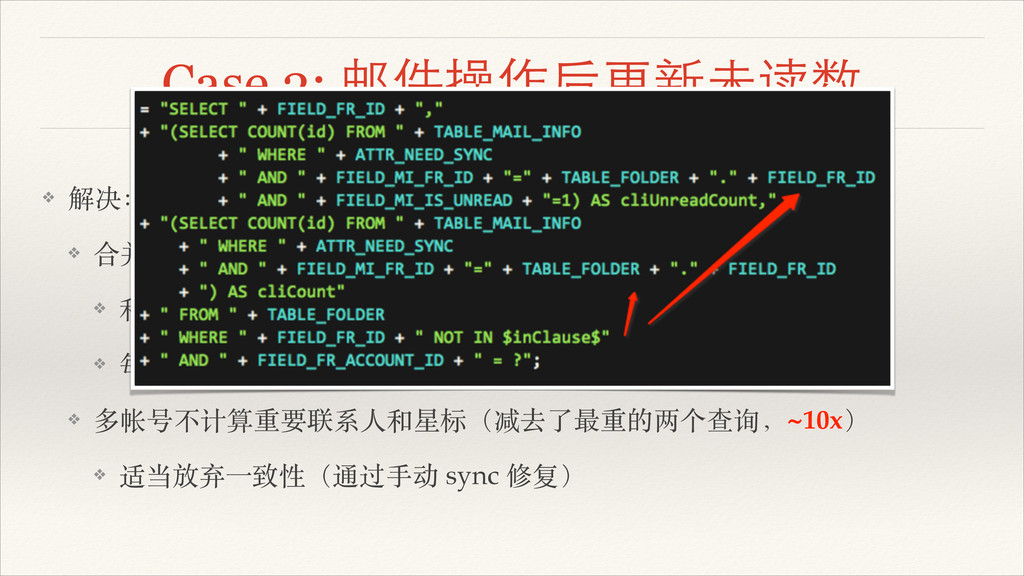
Case 3: 邮件操作后更新未读数 ❖ 解决:! ❖ 合并⽂文件夹查询到⼀一个 SQL 语句! ❖
利⽤用 SQL 内部变量传参! ❖ 每个帐号,前后各仅需⼀一次查询(原来是 N 个⽂文件夹 N 次)! ❖ 多帐号不计算重要联系⼈人和星标(减去了最重的两个查询,~10x)! ❖ 适当放弃⼀一致性(通过⼿手动 sync 修复)
Case 3: 邮件操作后更新未读数 ❖ 解决:! ❖ 合并⽂文件夹查询到⼀一个 SQL 语句! ❖
利⽤用 SQL 内部变量传参! ❖ 每个帐号,前后各仅需⼀一次查询(原来是 N 个⽂文件夹 N 次)! ❖ 多帐号不计算重要联系⼈人和星标(减去了最重的两个查询,~10x)! ❖ 适当放弃⼀一致性(通过⼿手动 sync 修复)
Case 4: MailList 滚动卡,⽆无法读信 ❖ 问题:! ❖ Update/LoadMore 时⽆无法读信,甚⾄至⽆无法滚动
Case 4: MailList 滚动卡,⽆无法读信 ❖ 问题:! ❖ Update/LoadMore 时⽆无法读信,甚⾄至⽆无法滚动 ❖
分析:! ❖ 列表需要在 LoadMore/操作时维持列表状态;popIn 需要当前列表的 mailIds! ❖ 列表需要刷新更换 Cursor 更新邮件状态,同时滚动也需要 getItem! ❖ 为了避免任何⼀一⽅方肆意关闭 Cursor,所有读操作都加了 synchronized! ❖ 此外,很多影响到列表的写⼊入操作使⽤用了读写互斥的事务锁
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive()
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive() ❖ 对 Cursor 进⾏行引⽤用管理,去掉所有相关的 synchronized
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive() ❖ 对 Cursor 进⾏行引⽤用管理,去掉所有相关的 synchronized ❖ ⽤用 ConcurrentHashMap<Cursor, Integer> 进⾏行引⽤用计数
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive() ❖ 对 Cursor 进⾏行引⽤用管理,去掉所有相关的 synchronized ❖ ⽤用 ConcurrentHashMap<Cursor, Integer> 进⾏行引⽤用计数 ❖ 每次担⼼心 Cursor 遍历时被其他线程关闭,引⽤用加⼀一,操作完减⼀一
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive() ❖ 对 Cursor 进⾏行引⽤用管理,去掉所有相关的 synchronized ❖ ⽤用 ConcurrentHashMap<Cursor, Integer> 进⾏行引⽤用计数 ❖ 每次担⼼心 Cursor 遍历时被其他线程关闭,引⽤用加⼀一,操作完减⼀一 ❖ 每次关闭时,尝试扫描需要关闭的 Cursor,关掉
Case 4: MailList 滚动卡,⽆无法读信 ❖ 解决: ❖ popIn:跟主流程关系不⼤大,直接 query ⼀一个新
Cursor ❖ 读写互斥的事务锁,换成读写不互斥的事务 ❖ beginTransaction() VS beginTransactionNonExclusive() ❖ 对 Cursor 进⾏行引⽤用管理,去掉所有相关的 synchronized ❖ ⽤用 ConcurrentHashMap<Cursor, Integer> 进⾏行引⽤用计数 ❖ 每次担⼼心 Cursor 遍历时被其他线程关闭,引⽤用加⼀一,操作完减⼀一 ❖ 每次关闭时,尝试扫描需要关闭的 Cursor,关掉
Case 5: QMReadMailActivity ❖ 问题:! ❖ 读信慢! ❖ 分析:! ❖
每次 onResume 花了 100-150ms(其他Activity 20-40ms)! ❖ readmail ⼀一次性读取了太多的信息 (INFO, Contact, Attachment, Body)! ❖ 为了上下⼀一封按钮,又各同步⾛走了⼀一次 readmail
Case 5: QMReadMailActivity ❖ 解决:! ❖ 针对 QMReadMailActivity 做了部分异步读信,读取完后回调刷新正⽂文! ❖
onResume 降到 20ms-40ms! ❖ 上下⼀一封直接调⽤用 readMailInfo! ❖ 分离 DB 的 readmail 的⽅方法,INFO 单独读(其他地⽅方调⽤用也同样耗时)
Case 5: QMReadMailActivity ❖ 解决:! ❖ 针对 QMReadMailActivity 做了部分异步读信,读取完后回调刷新正⽂文! ❖
onResume 降到 20ms-40ms! ❖ 上下⼀一封直接调⽤用 readMailInfo! ❖ 分离 DB 的 readmail 的⽅方法,INFO 单独读(其他地⽅方调⽤用也同样耗时)
策略选择 - WAL ❖ 存储级别的读写分离,写⼊入 -wal ⽂文件,不影响主库任何并发读
策略选择 - WAL ❖ 存储级别的读写分离,写⼊入 -wal ⽂文件,不影响主库任何并发读 ❖ 问题:短暂的数据不⼀一致! ❖
实时性要求⾼高的场合(邮件操作)! ❖ 需要时 disabled ,执⾏行完了再 enable! ❖ ⼤大部分 INFO 表的写⼊入场景都要求实时性(除了⼊入信)
策略选择 - WAL ❖ 存储级别的读写分离,写⼊入 -wal ⽂文件,不影响主库任何并发读 ❖ 问题:短暂的数据不⼀一致! ❖
实时性要求⾼高的场合(邮件操作)! ❖ 需要时 disabled ,执⾏行完了再 enable! ❖ ⼤大部分 INFO 表的写⼊入场景都要求实时性(除了⼊入信) ❖ 暂时不采⽤用
策略选择 - ⾃自编 SQLite ❖ SQLITE_TEMP_STORE=2 link! ❖ 临时缓存默认使⽤用内存,出错数据由 rollback
纠正! ❖ SQLITE_ENABLE_ATOMIC_WRITE link! ❖ ⼩小数据 flush 到磁盘的及时性,减少⼤大事务最终 commit 的开销! ❖ SQLITE_ENABLE_STAT4 和 ANALYSE link! ❖ 使⽤用 SQLite 的 Query Plan 优化 WHERE 条件的前后位置! ❖ SQLITE_OMIT_AUTOMATIC_INDEX link! ❖ 避免没必要的⾃自动索引,减少写⼊入和查询负担
写在最后 ❖ IO 操作尽量不要在主线程做,从业务的⾓角度区分轻重缓急! ❖ 从 UI 的⾓角度,需要长时间等待的操作都应该⽤用回调来完成! ❖ 调整
SQL 查询,合并读;⽤用事务来批量写(存储不需要每次都 fsync 到磁盘)! ❖ 避开对 DB 操作启⽤用线程锁,SQLite 是线程安全的! ❖ 要防⽌止和写事务造成死锁! ❖ 在⼦子查询使⽤用 DISTINCT;经常交叉查询的字段,建⽴立索引! ❖ 不需要数据的情况下,不要随便 JOIN 表! ❖ 选择合适的字段做冗余,拆表
谢谢
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}