. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Revolution of Retrieval Block (Cont’d) Improving Similarity Module S : (Rd, Rd) → R S(˜ x,˜ xi) = −||WK(˜ x) − WK(˜ xi)||2 · d−1/2 (3) Authors found that instead of the original dot-product mechanism in self-attention, removing the notion of queries and using the L2 regularization improves the per- formance Adding context labels V : (Rd, Rd, Y) → Rd V(˜ x,˜ xi, yi) = WV(˜ xi) + WY(yi) (4) Utilize labels of the context objects, which is an embedding table for classifica- tion tasks and a linear layer for regression tasks Your name Short title September 7, 2024 13 / 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
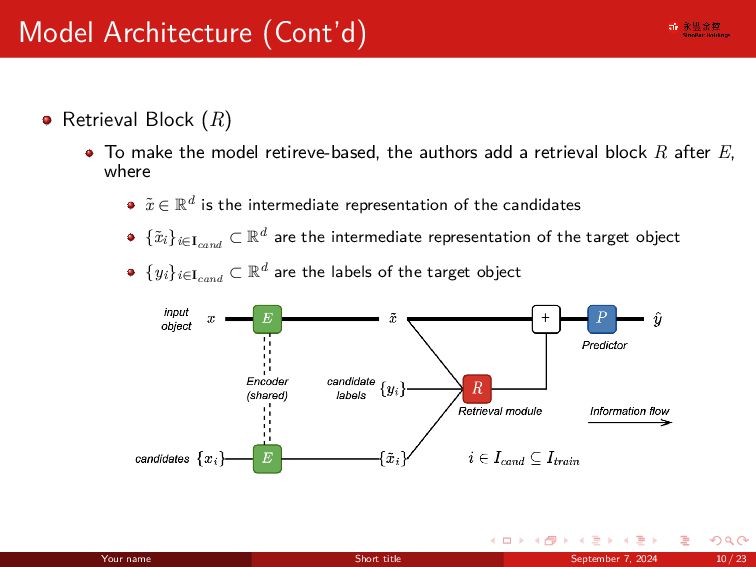{kind=link}
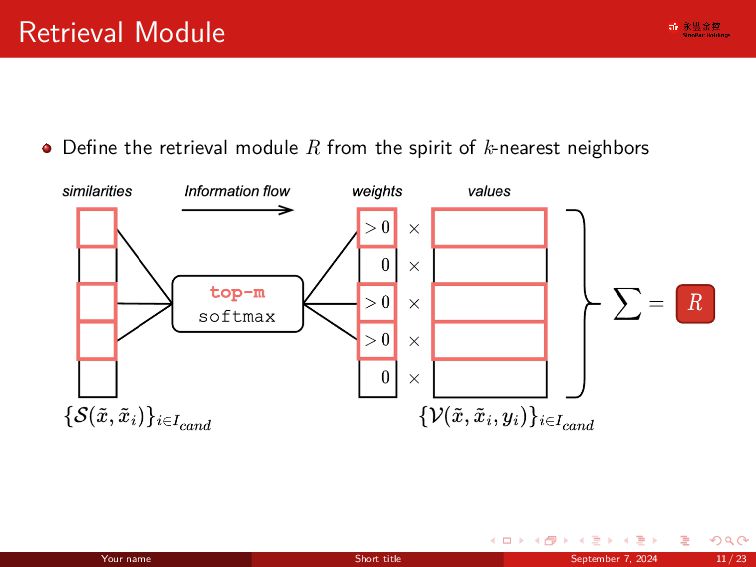{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
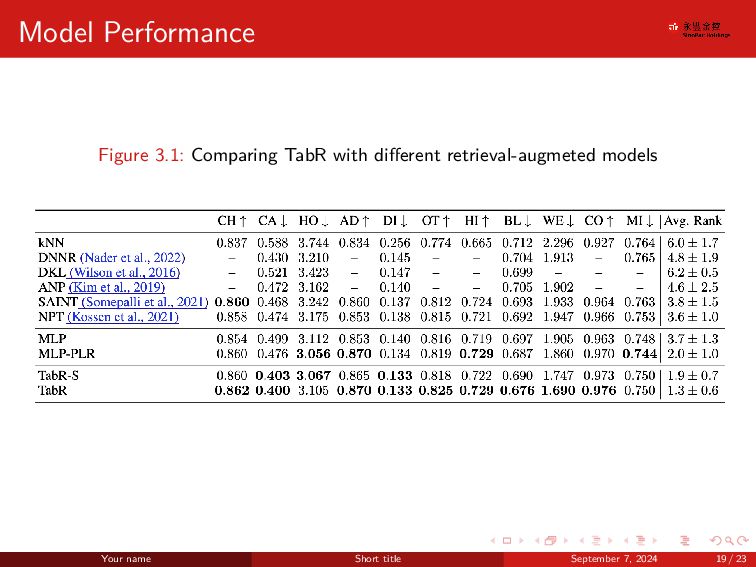{kind=link}
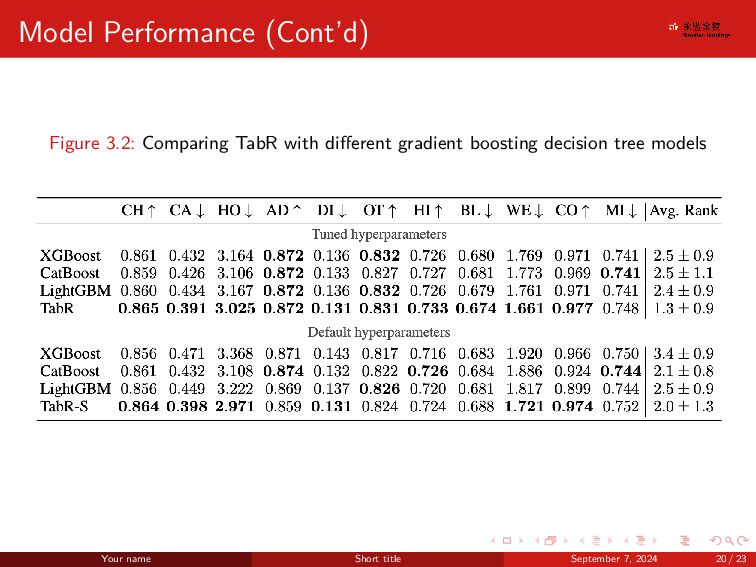{kind=link}
{kind=link}
{kind=link}
{kind=link}