What matters when choosing a data processing platform, and when getting the most out of that platform. And what will matter most as we take things to the next level...
to consider the data accesses that don’t use the API. These include back-ups, bulk import and deletion of data, bulk migrations from one data format to another, replica creation, asynchronous replication, consistency monitoring tools, and operational debugging. An alternate store would also have to provide atomic write transactions, efficient granular writes, and few latency outliers. - Facebook 2013 (TAO) “ ”
standard verification techniques in industry are necessary but not sufficient. We use deep design reviews, code reviews, static code analysis, stress testing, fault-injection testing, and many other techniques, but we still find that subtle bugs can hide in complex concurrent fault-tolerant systems.” - Amazon 2014
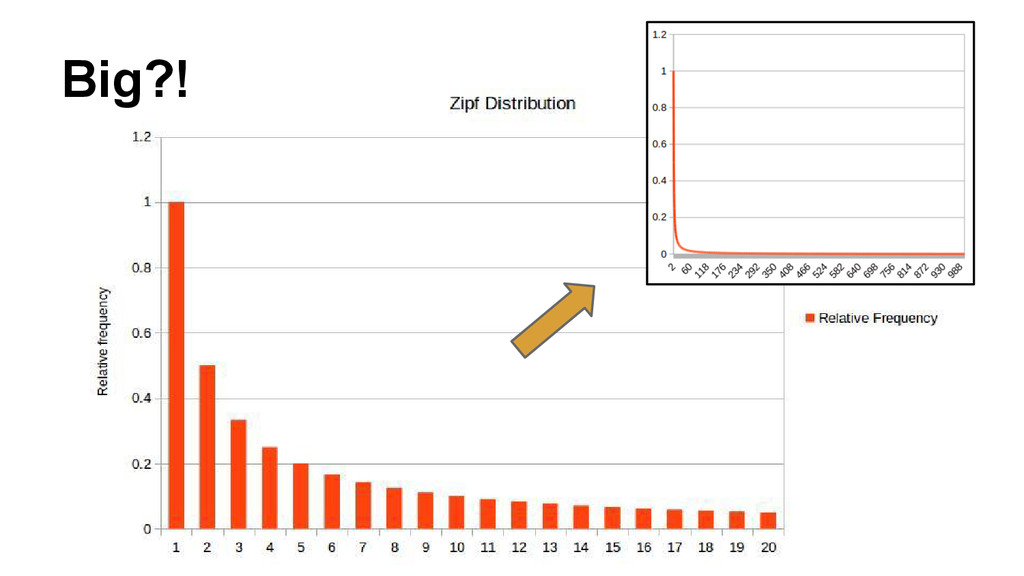
in memory all but the very largest datasets, which we avoid storing in memory altogether. For example, the distribution of input sizes of MapReduce jobs at Facebook is heavy- tailed. Furthermore, 96% of active jobs can have their entire data simultaneously fit in the corresponding clusters’ memory” - Tachyon, Lie et al. 2014
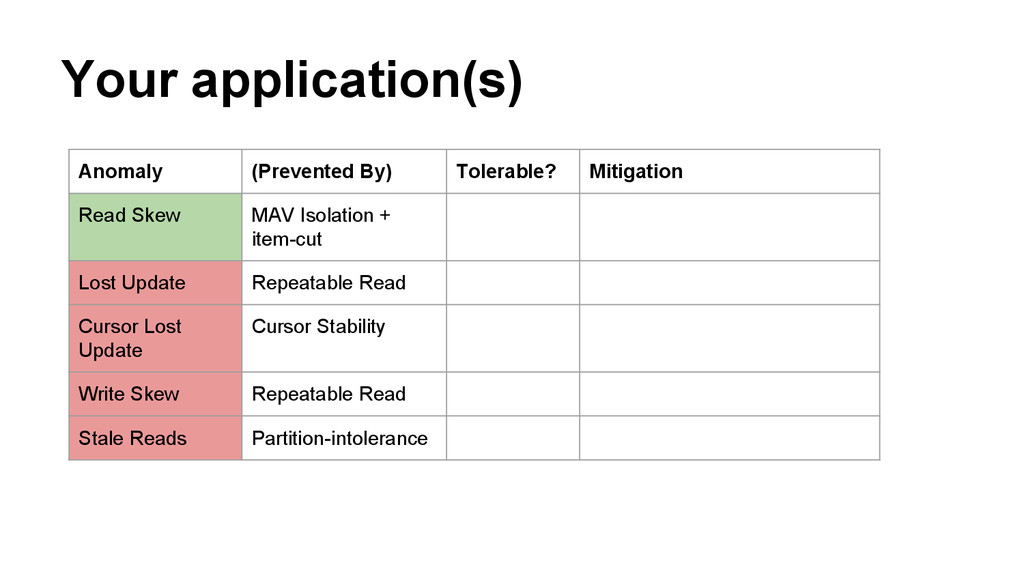
you planned for anomalies? • Does it actually work? • Are you distributing for the right reasons? (AL…) • Do you need exact? • Do you need it ASAP? • Can you keep CALM? • Do you understand your application’s invariants?
et al. 2014 http: //blog.acolyer.org/2014/11/07/highly-available-transactions-virtues-and- limitations/ • Building on Quicksand - Helland 2009 http://blog.acolyer. org/2015/03/23/building-on-quicksand/ • F1: A Distributed SQL Database that Scales - Google 2012 http://blog. acolyer.org/2015/01/06/f1-a-distributed-sql-database-that-scales/ • Scalability! But at what COST? - McSherry et al. 2015 http://blog.acolyer. org/?p=941 (to appear, June 5th 2015) • Applying the Universal Scalability Law to Organisations - Colyer 2015 http: //blog.acolyer.org/2015/04/29/applying-the-universal-scalability-law-to- organisations/
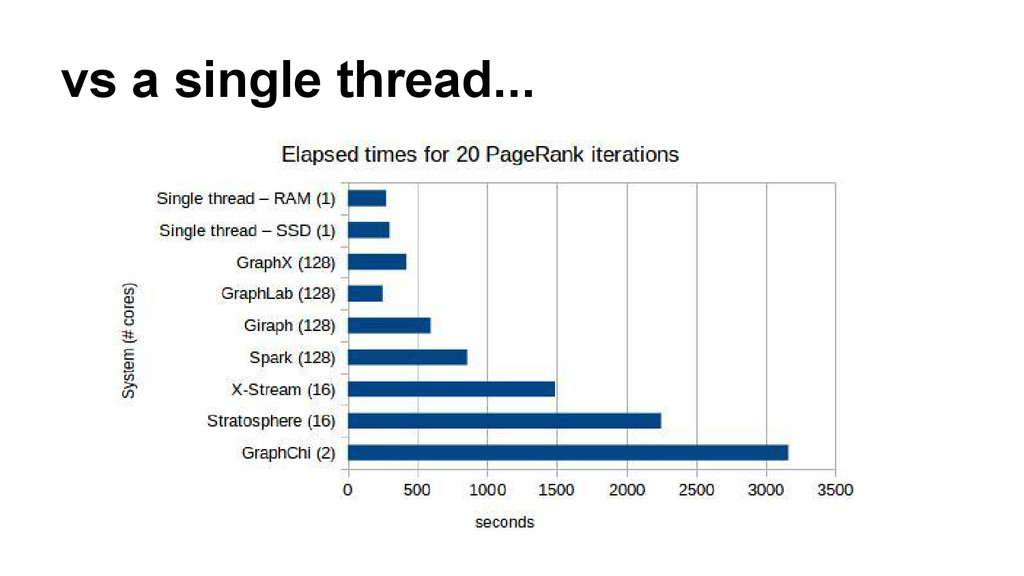
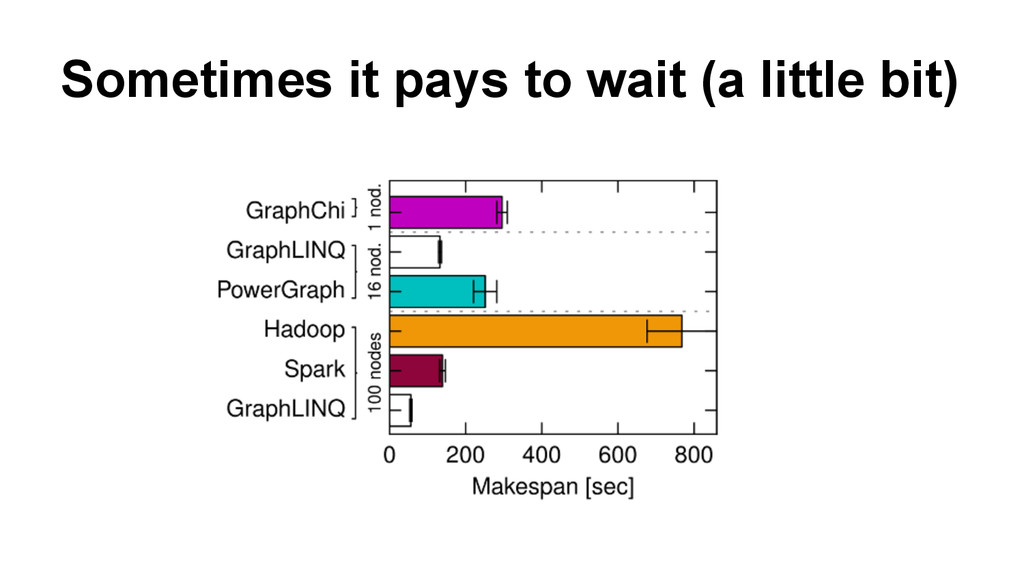
data processing systems - Gog et al. 2015 http://blog.acolyer.org/2015/04/27/musketeer-part-i-whats-the-best- data-processing-system/ and http://blog.acolyer. org/2015/04/28/musketeer-part-ii-one-for-all-and-all-for-one/ • Pregel: A System for Large-Scale Graph Processing - Google 2010 http: //blog.acolyer.org/2015/05/26/pregel-a-system-for-large-scale-graph- processing/ • FlashGraph: Processing Billion Node Graphs on an array of commodity SSDs - Zheng et al. 2015 http://blog.acolyer.org/?p=935
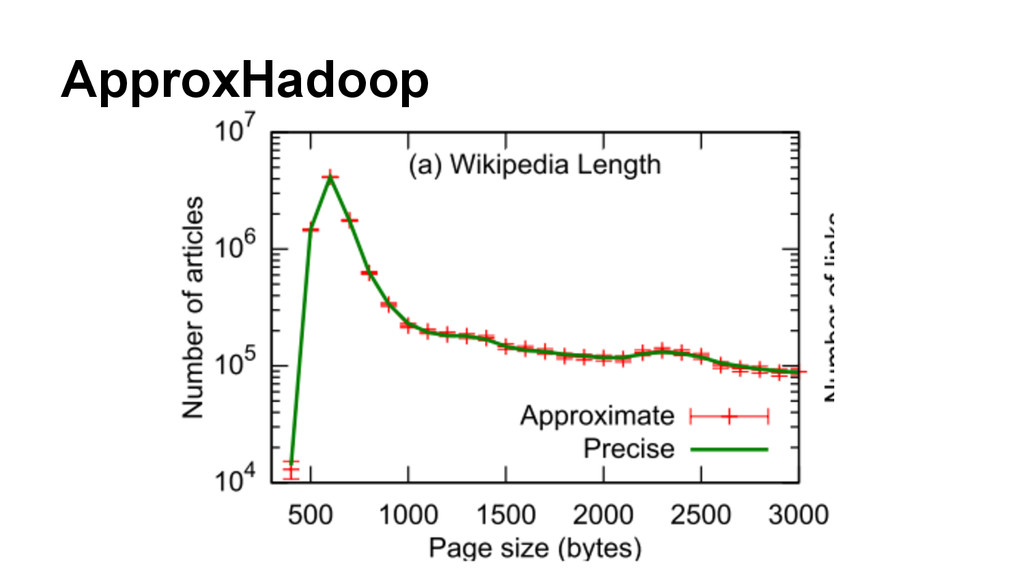
2015 http://blog.acolyer.org/2015/04/16/approxhadoop-bringing- approximations-to-mapreduce-frameworks/ • BlinkDB: http://blinkdb.org/ • Making Sense of Performance in Data Analytics Frameworks - Ousterhout et al 2015 http://blog.acolyer.org/2015/04/20/making-sense-of- performance-in-data-analytics-frameworks/ • A Comprehensive Study of Convergent and Commutative Replicated Data Types - Shapiro et al. 2011 http://blog.acolyer.org/2015/03/18/a- comprehensive-study-of-convergent-and-commutative-replicated-data- types/
al. 2014 http: //blog.acolyer.org/2015/03/19/coordination-avoidance-in-database- systems/ • Putting Consistency Back into Eventual Consistency - Balegas et al. 2015 http://blog.acolyer.org/2015/05/04/putting-consistency-back-into-eventual- consistency/ • Use of Formal Methods at Amazon Web Services - Newcombe et al. 2014 http://blog.acolyer.org/2014/11/24/use-of-formal-methods-at-amazon-web- services/ • Consistency Trade-offs in Modern Distributed Database Systems Design - Abadi 2012 http://cs-www.cs.yale.edu/homes/dna/papers/abadi-pacelc.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
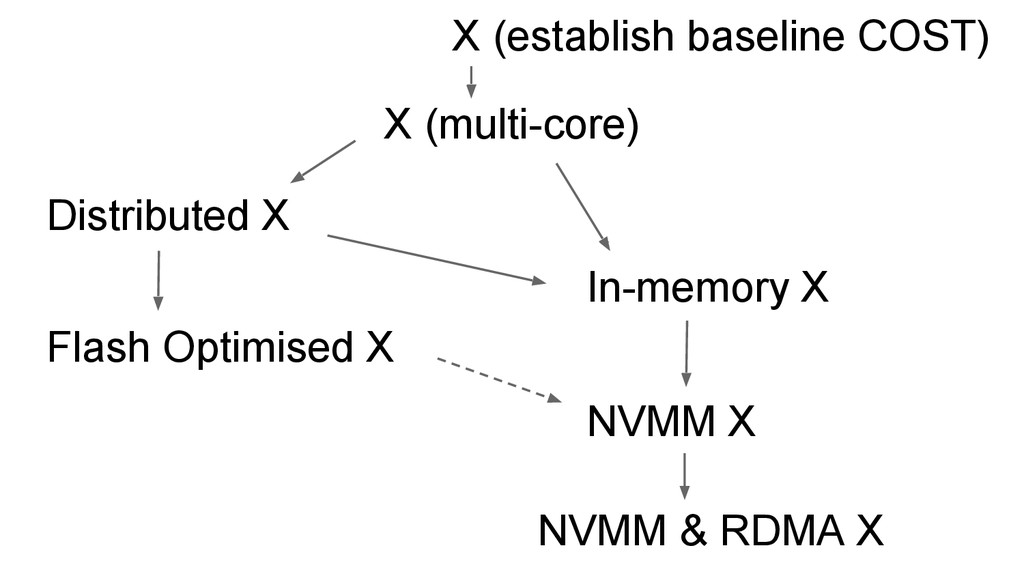{kind=link}
{kind=link}
{kind=link}
{kind=link}
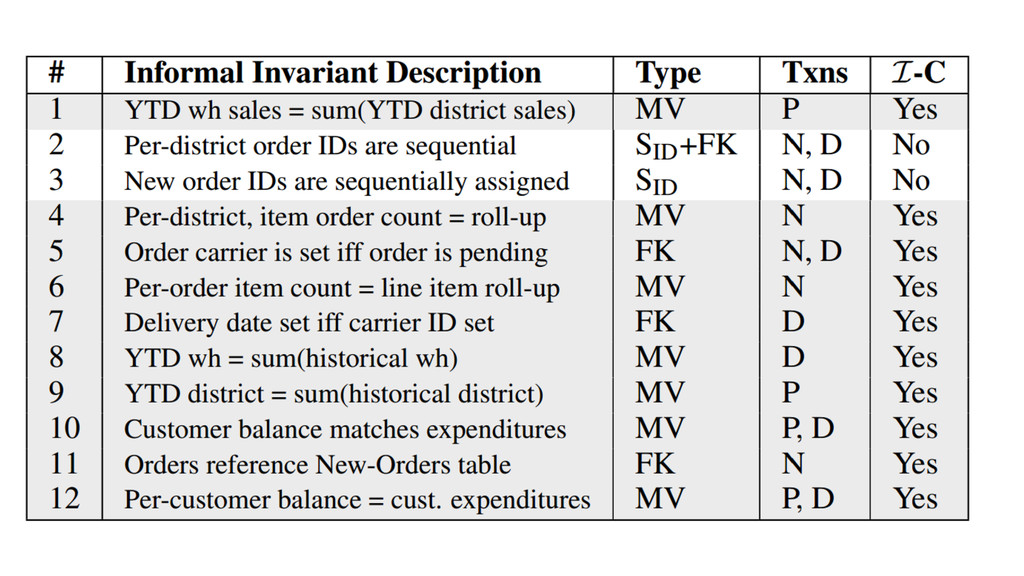{kind=link}
{kind=link}
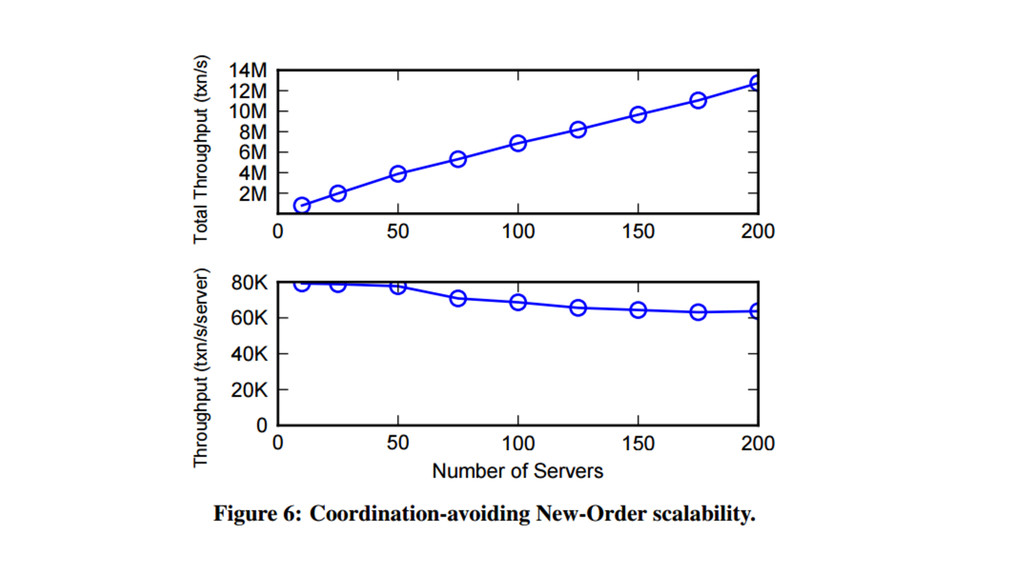{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}