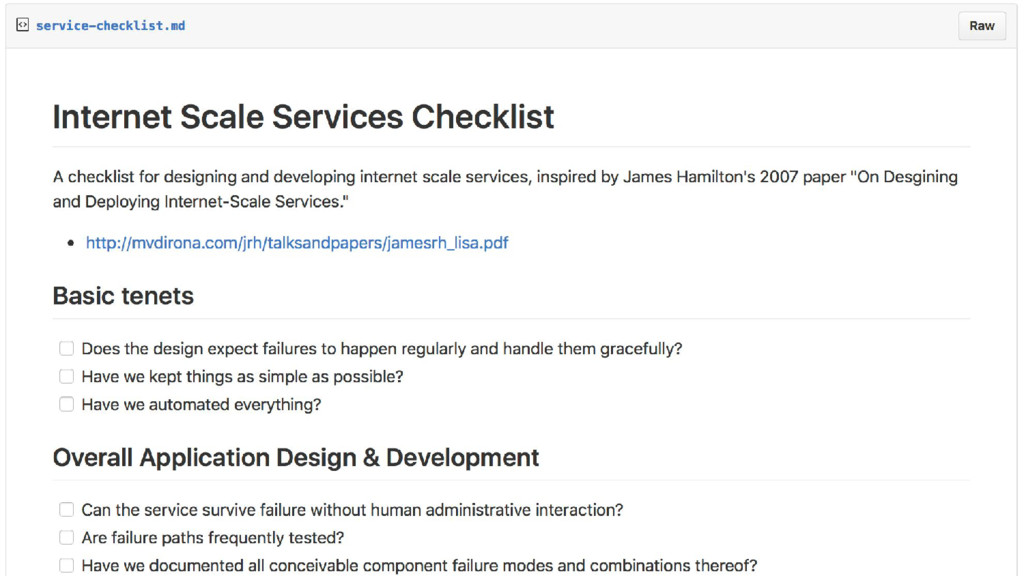
of operations issues originate in design and development... when systems fail, there is a natural tendency to look first to operations since that is where the problem actually took place. Most operations issues however, either have their genesis in design and development or are best solved there. “ ”
called in the middle of the night, automation is the likely outcome. If operations is frequently called, the usual reaction is to grow the operations team. “ ”
often implemented as complex, large-scale distributed systems. These applications are constructed from collections of software modules that may be developed by different teams, perhaps in different programming languages, and could span many thousands of machines across multiple physical facilities…. Understanding system behavior in this context requires observing related activities across many different programs and machines.
just dozens of subsystems but dozens of engineering teams, even our best and most experienced engineers routinely guess wrong about the root cause of poor end-to-end performance. In such situations, Dapper can furnish much-needed facts and is able to answer many important performance questions conclusively. ”
Facebook systems we study; they grow organically over time in a culture that favors innovation over standardization (e.g., “move fast and break things” is a well-known Facebook slogan). There is broad diversity in programming languages, communication middleware, execution environments, and scheduling mechanisms. Adding instrumentation retroactively to such an infrastructure is a Herculean task. “ ”
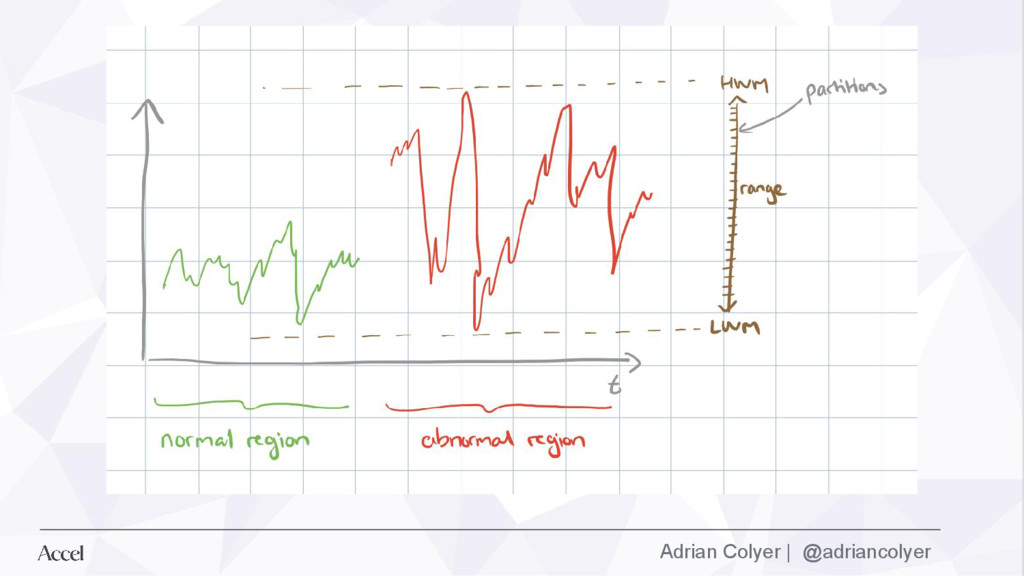
• Request identifier • Host identifier • Host-local timestamp • Unique event label “ ” Our key observation is that the sheer volume of requests handled by modern services allows us to gather observations of the order in which messages are logged over a tremendous number of requests.
logs is sufficiently rich to allow the recovering of the inherent structure of the dispersed and intermingled log output messages, thus enabling useful performance profilers like lprof. ”
lprof can accurately attribute 88% of the log messages from widely-used production quality distributed systems and is helpful in debugging 65% of the sampled real-world performance anomalies. ”
posed by bugs that only recur in production and cannot be reproduced in-house. Diagnosing the root cause and fixing such bugs is truly hard. In [57] developers noted: "We don't have tools for the once every 24 hours bug in a 100 machine cluster". An informal poll on Quora asked "What is a coder's worst nightmare?," and the answers were "The bug only occurs in production and can't be replicated locally," and "The cause of the bug is unknown." ”
prototype using 11 failures from 7 different programs including Apache, SQLite, and Memcached. The Gist prototype managed to automatically build failure sketches with an average accuracy of 96% for all the failures while incurring an average performance overhead of 3.74%. On average, Gist incurs 166x less runtime performance overhead than a state-of-the-art record/replay system. ”
that our algorithm is highly effective in identifying the correct explanations and is more accurate than the state-of-the-art algorithm. As a much needed tool for coping with the increasing complexity of today's DBMS, DBSherlock is released as an open-source module in our workload management toolkit. ”
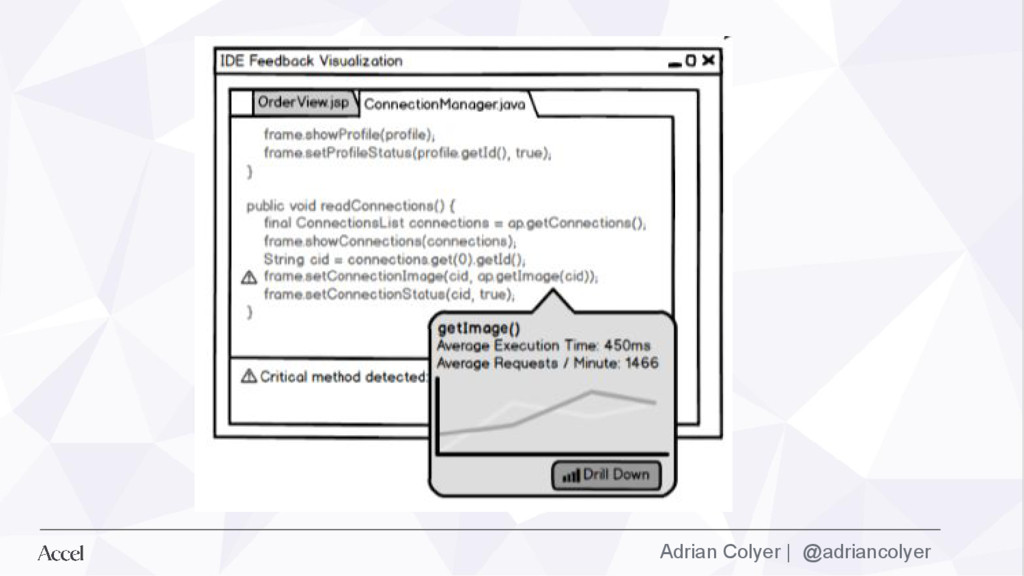
many ongoing trends in software engineering is a blurring of the boundaries between building and operating software products. In this paper, we explore what we consider to be the logical next step in this succession: integrating runtime monitoring data from production deployments of the software into the tools developers utilize in their daily workflows (i.e., IDEs) to enable tighter feedback loops. We refer to this notion as feedback-driven development (FDD). ”
systems makes it impossible for them to run without multiple flaws being present. Because these are individually insufficient to cause failure, they are regarded as a minor factor during operations. Complex systems therefore run in degraded mode as their normal mode of operation. ”
Straight to your inbox If you prefer email-based subscription to read at your leisure. 02 Announced on Twitter I’m @adriancolyer. 03 Go to a Papers We Love Meetup A repository of academic computer science papers and a community who loves reading them. 04 Share what you learn Anyone can take part in the great conversation. 05
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Adrian Colyer | @adriancolyer #define SIZE 20 double mult(double z[],](https://files.speakerdeck.com/presentations/ea9b0a6d192743f7bf820e137bd9432e/slide_26.jpg){kind=link}
![Adrian Colyer | @adriancolyer t(double z[],int n){int i,j;for(;;){i=i+j+1;z[i]=z[i]*z[0]+0;}ret urn z[n];}](https://files.speakerdeck.com/presentations/ea9b0a6d192743f7bf820e137bd9432e/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}