overview of python2/3 changes - Python 3: incompatible with py2, to clean up the language - dropping obsolete constructs; simplifying; improving stdlib - 3.3 final was just released
end="", file=sys.stderr) - print is now a built-in function, not a statement - double-angle-bracket notation, setting the line ending now keyword arguments - retraining my fingers for this is the hardest thing
as exc: ... - catching exceptions slightly different - uses the 'as' keyword instead of a comma - motivation: to fix an occasional user error when trying to catch multiple classes - a semantic change here: 'exc' is now cleared at the end of the handling block
classes are now automatically derived from 'object' class - this means all classes are 'new-style' - so method-resolution order is different - has different hooks when creating instances
- exceptions must derive from BaseException - classes you write will generally inherit from Exception - only special things like SystemExit, KeyboardInterrupt derive from BaseException
dict.keys() .values() .items() -> return view objects dict.iterkeys() .itervalues() .iteritems() -> gone - in general, more methods & features return iterators instead of lists - example: dictionary keys/values/items return 'views' - Py2's iter*() variants are now gone - 'views' are iterable, but track contents of dictionary - (you still can't modify dict while you're iterating over it) - views also support some set operations: intersect, union
a list map(), filter() return iterators reduce() moved to functools.reduce() - map() and filter() return iterators, like itertools.imap / ifilter - rarely-used reduce() moved to a module
x # x is now 9, the last element [... for x in range(10)] print(x) # NameError: 'x' is not defined - list comprehensions no longer leak their loop variable - in py2, a listcomp left the value lying around - in py3, doesn't leave 'x' behind; if 'x' already existed, it's unchanged
a relative import, then an absolute from module import name -> always absolute from .module import name -> relative import (also supported in 2.x) - when code in a package imports a name, Py2 first tried the same dir. - if that failed, tried an absolute - importing from sys.path - Py3: always does absolute import - unless you specify a relative import by adding a leading dot
repr cPickle/pickle configparser queue copyreg reprlib pickle - py2's module names were inconsistent with pep8 - mixed-case, occasional underscores, shadowing builtins - py3 renames modules to lowercase - pure-Python/C versions were merged; they should import the C version where it exists.
(use hashlib) mimewriter, mimetools rfc822 urllib (use urllib2) UserDict (just subclass dict) - many modules that were obsolete or unmaintained were removed - this has been a brief & incomplete survey; I'll talk about more changes as I go. - now let's start trying to port something
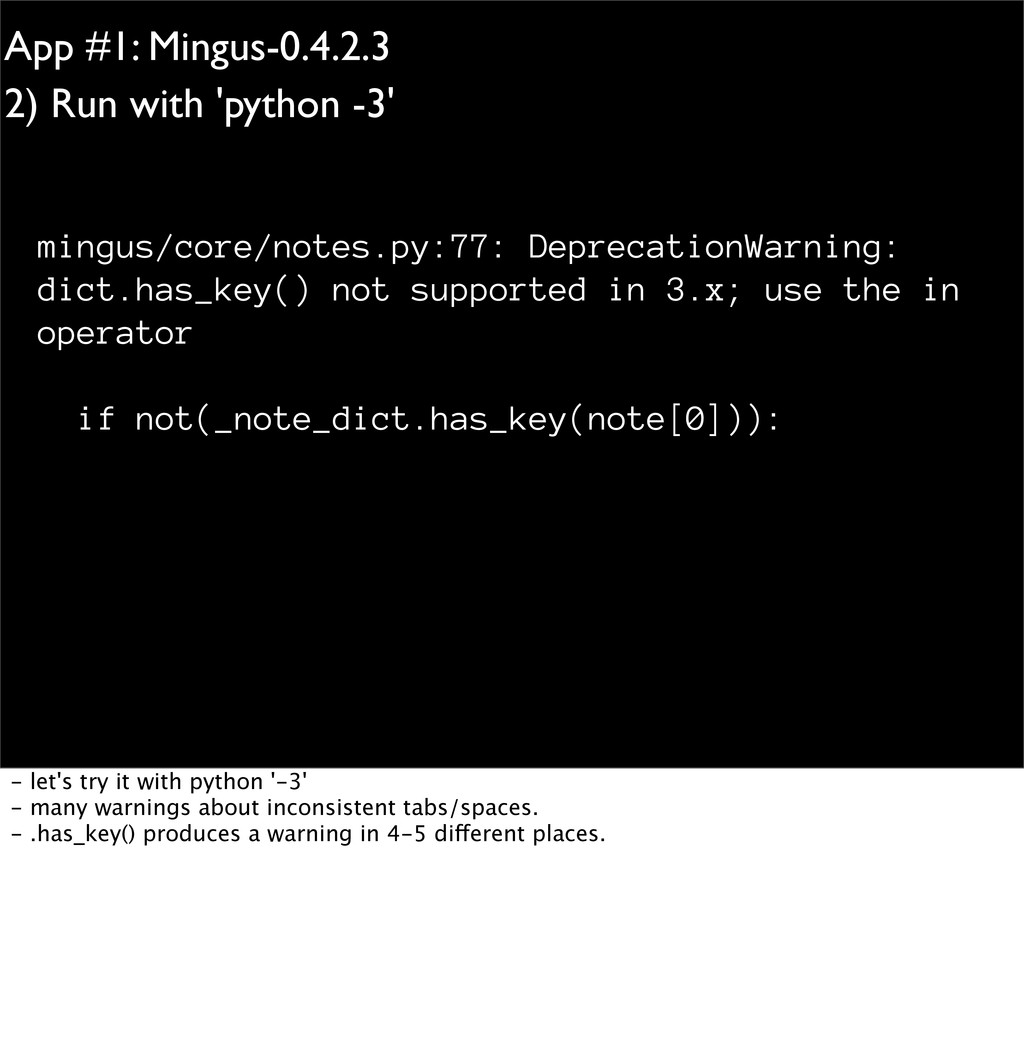
with Python 2.7 • Ensure code has a reasonable test suite • Check coverage • Run code with "python2.7 -3" • Fix resulting warnings, if any. • Convert Python2 to Python3 code - because migration is such an effort, Python devs provide tools to assist with it. - this lays out the steps - run w/ Python 2.7 - ensure there's a good test suite - run w/ -3 switch. - -3 makes Python2 print warnings about code that's an issue in py3 - as we go I'll talk more about the problems it warns about.
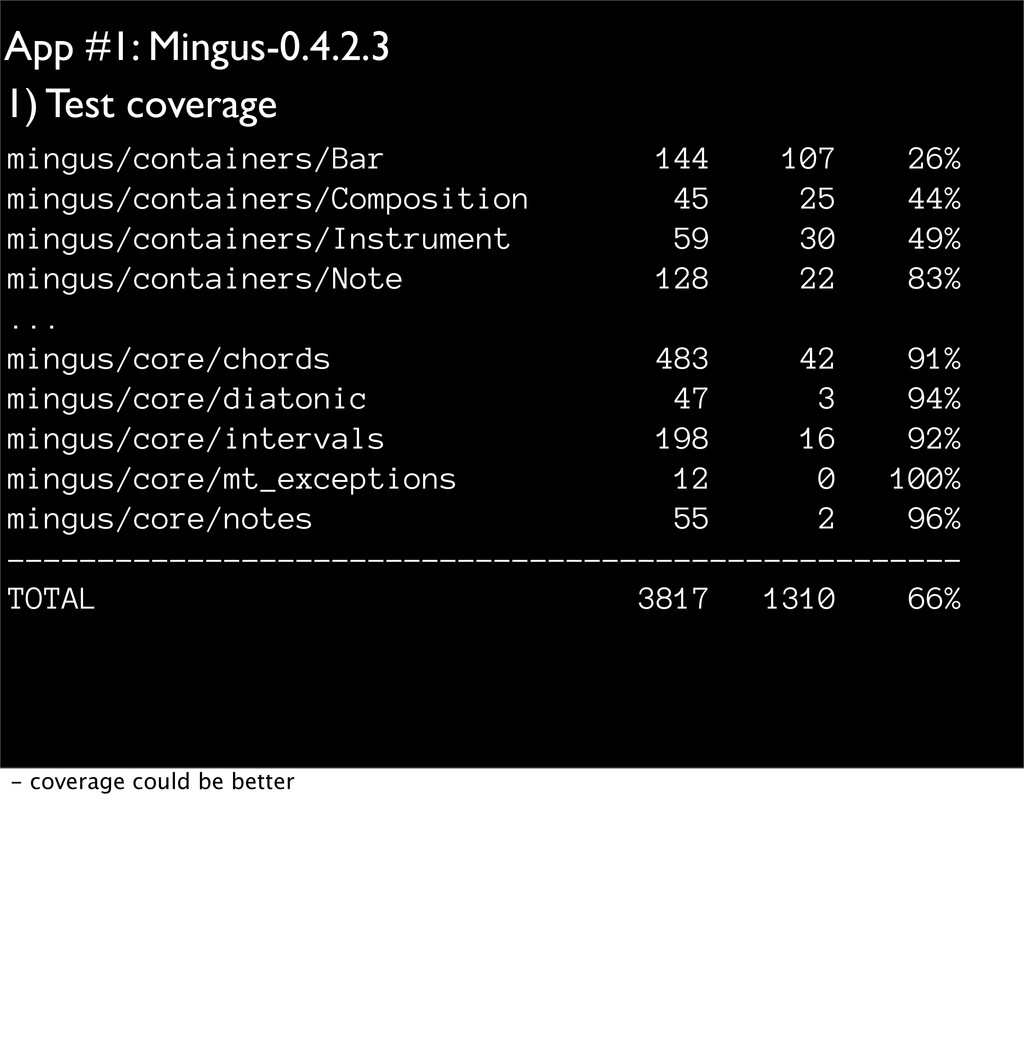
Classes for Note, Interval, Chord, Bar • Can read/write MIDI files • 4 packages, 34 modules, 9000 lines, 2200 lines of tests - a fairly large library for music - could be used for automatic composition, analyzing music - outputting MIDI files and typeset scores.
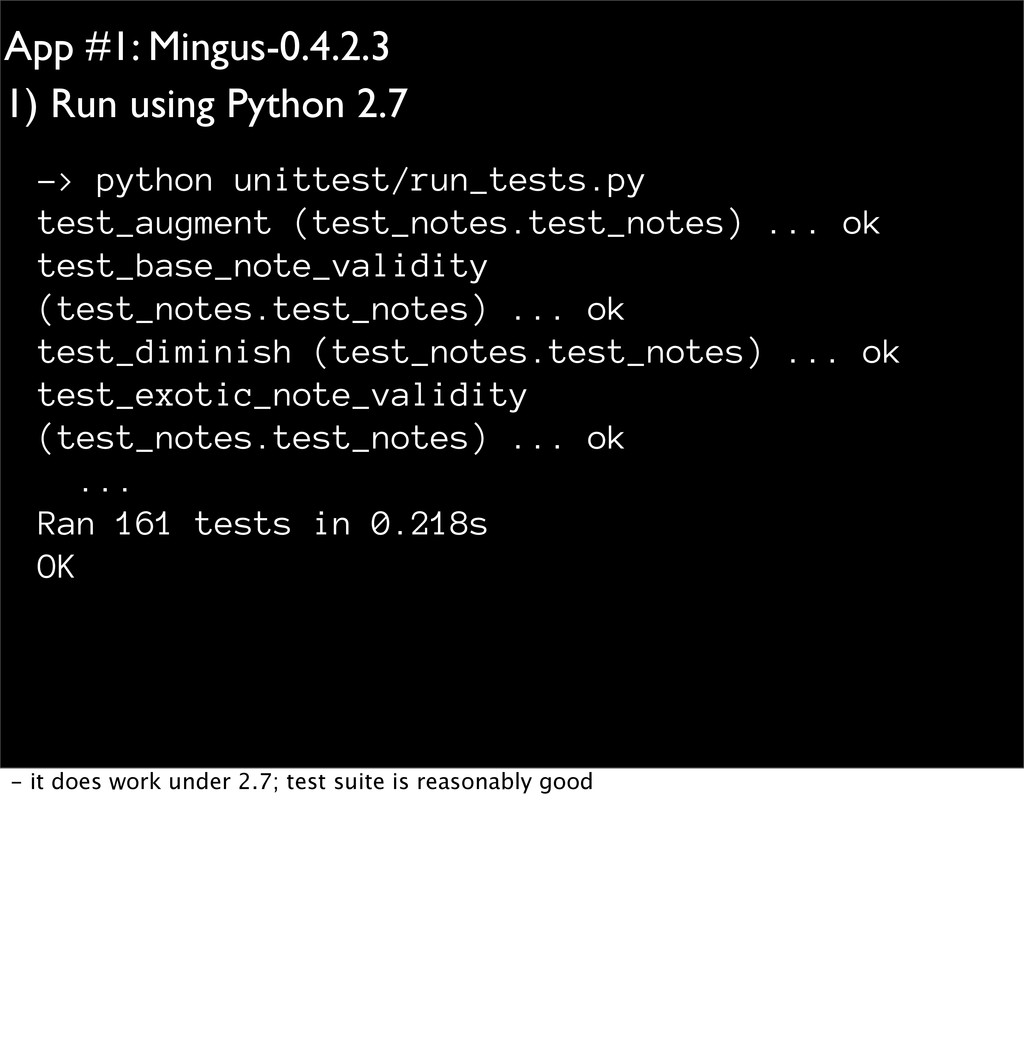
unittest/run_tests.py test_augment (test_notes.test_notes) ... ok test_base_note_validity (test_notes.test_notes) ... ok test_diminish (test_notes.test_notes) ... ok test_exotic_note_validity (test_notes.test_notes) ... ok ... Ran 161 tests in 0.218s OK - it does work under 2.7; test suite is reasonably good
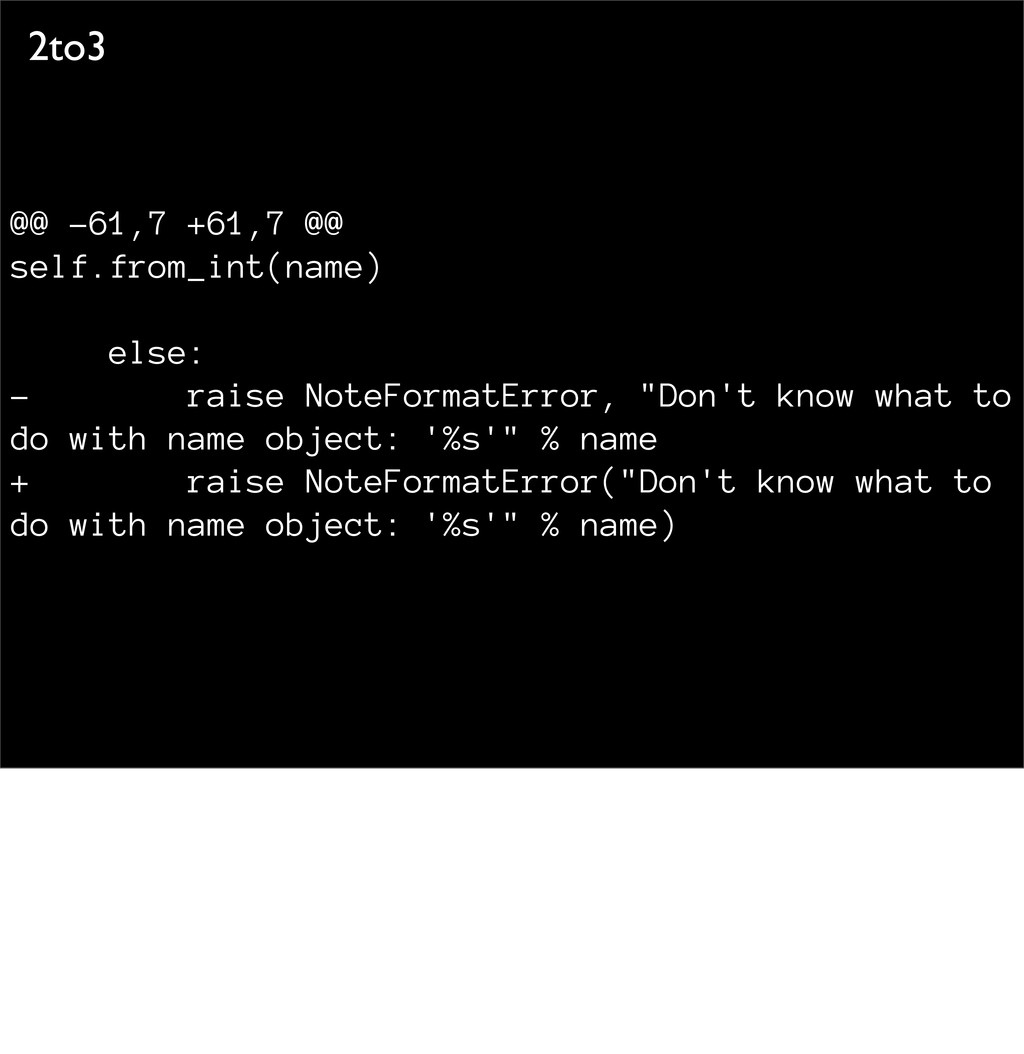
dict.has_key() not supported in 3.x; use the in operator if not(_note_dict.has_key(note[0])): - let's try it with python '-3' - many warnings about inconsistent tabs/spaces. - .has_key() produces a warning in 4-5 different places.
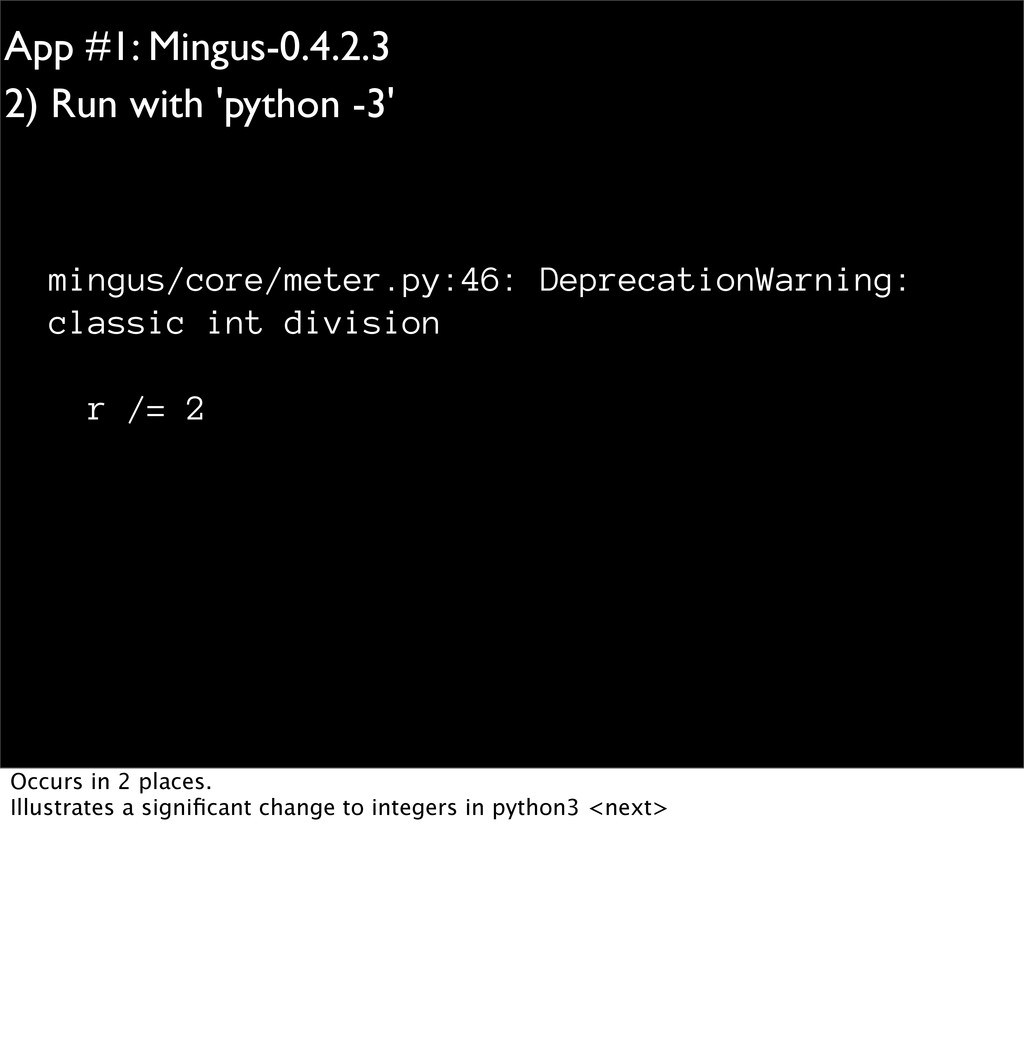
/ 4 = 1.25 5 / 4 = 1.25 5 // 4 = 1 - in python2, dividing two ints gives an int, so it truncates - in py3, division gives an accurate answer, returning a float - this is called true division. - a different operator, // floor division, does the old truncation (classic division).
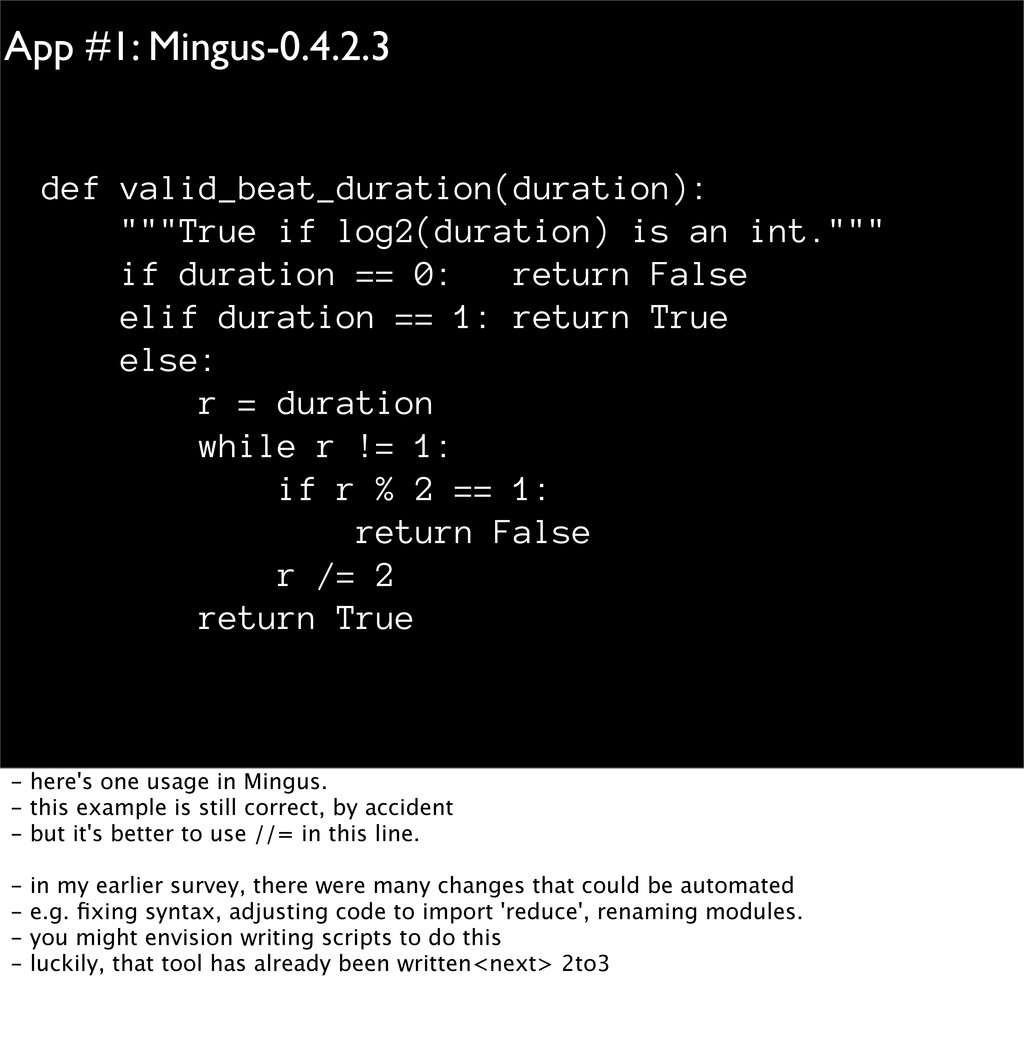
int.""" if duration == 0: return False elif duration == 1: return True else: r = duration while r != 1: if r % 2 == 1: return False r /= 2 return True - here's one usage in Mingus. - this example is still correct, by accident - but it's better to use //= in this line. - in my earlier survey, there were many changes that could be automated - e.g. fixing syntax, adjusting code to import 'reduce', renaming modules. - you might envision writing scripts to do this - luckily, that tool has already been written<next> 2to3
modules, - translates them into python3 code - can output a diff or write out updated code - code lives in 'lib2to3' package: provides framework for writing refactoring tools
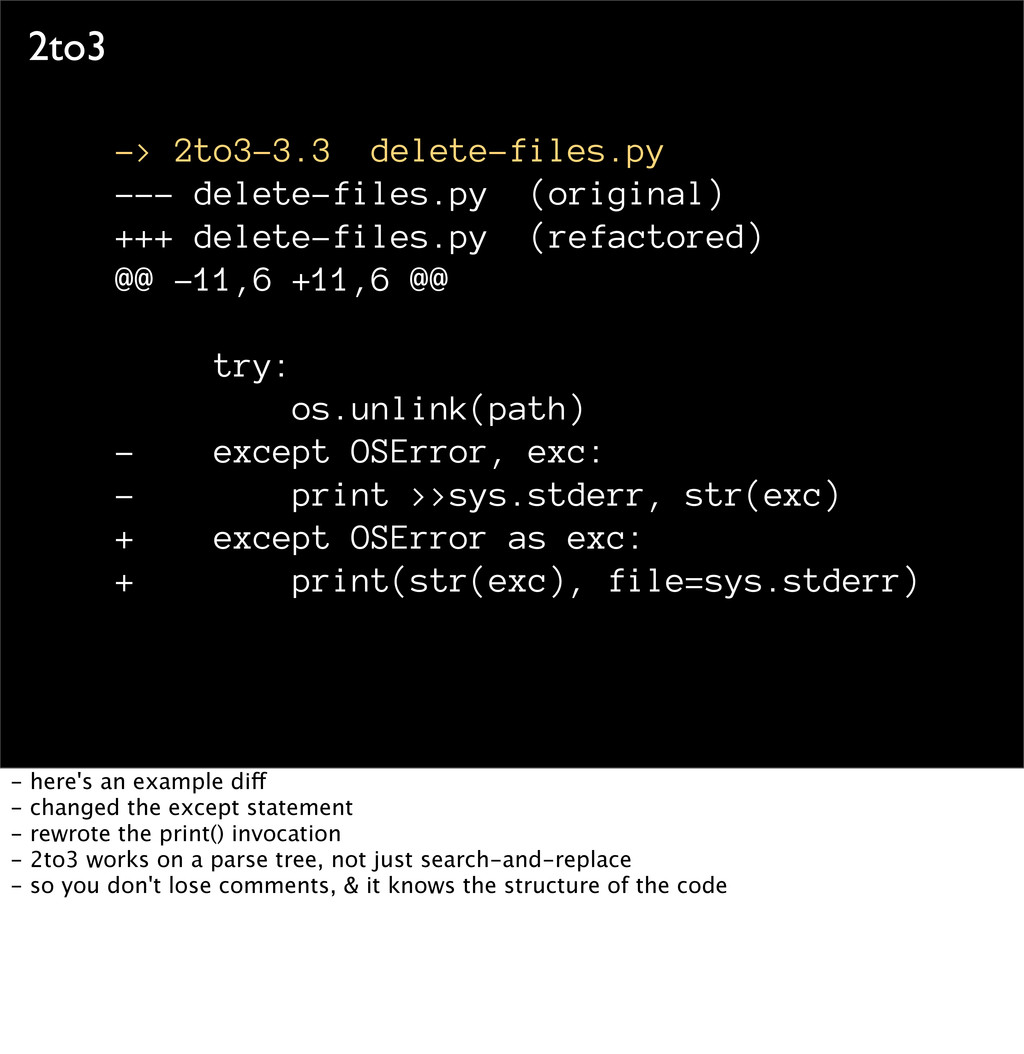
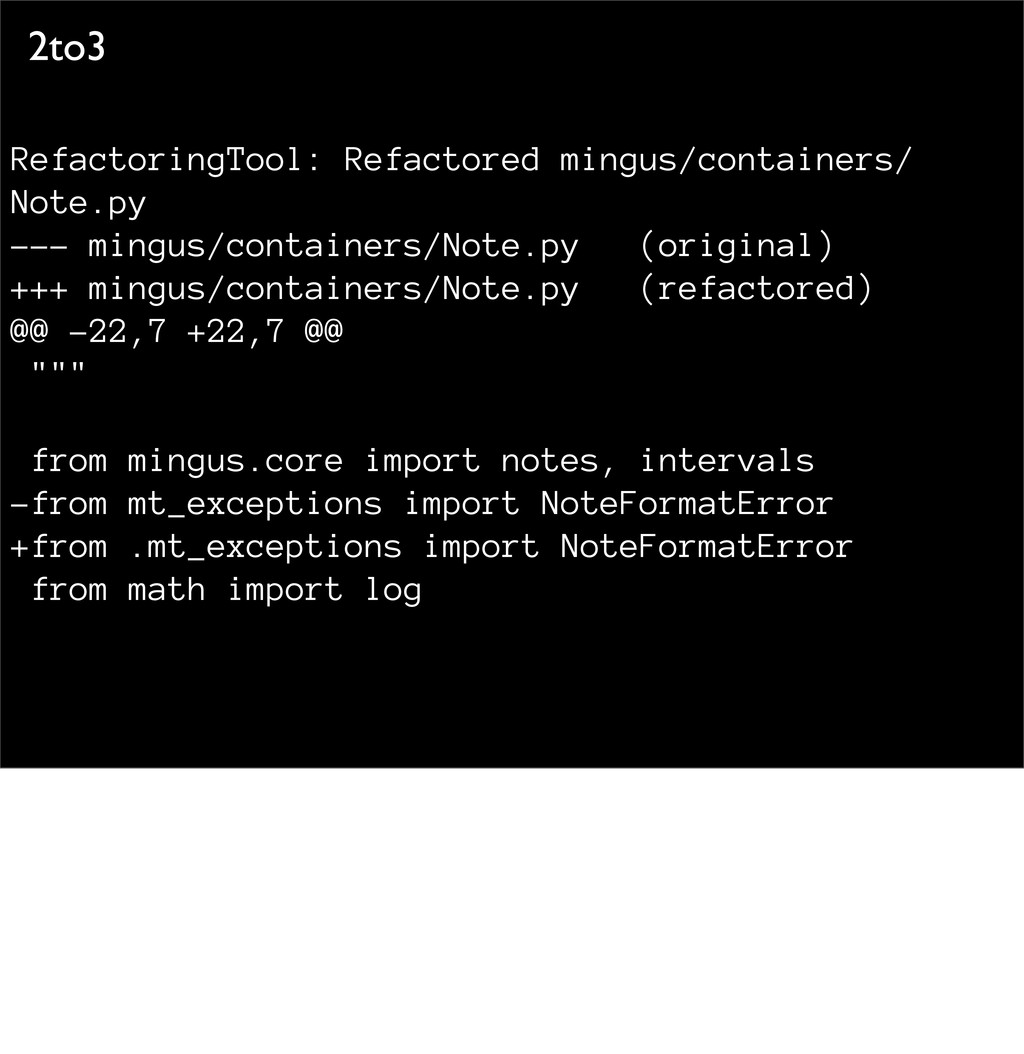
@@ -11,6 +11,6 @@ try: os.unlink(path) - except OSError, exc: - print >>sys.stderr, str(exc) + except OSError as exc: + print(str(exc), file=sys.stderr) - here's an example diff - changed the except statement - rewrote the print() invocation - 2to3 works on a parse tree, not just search-and-replace - so you don't lose comments, & it knows the structure of the code
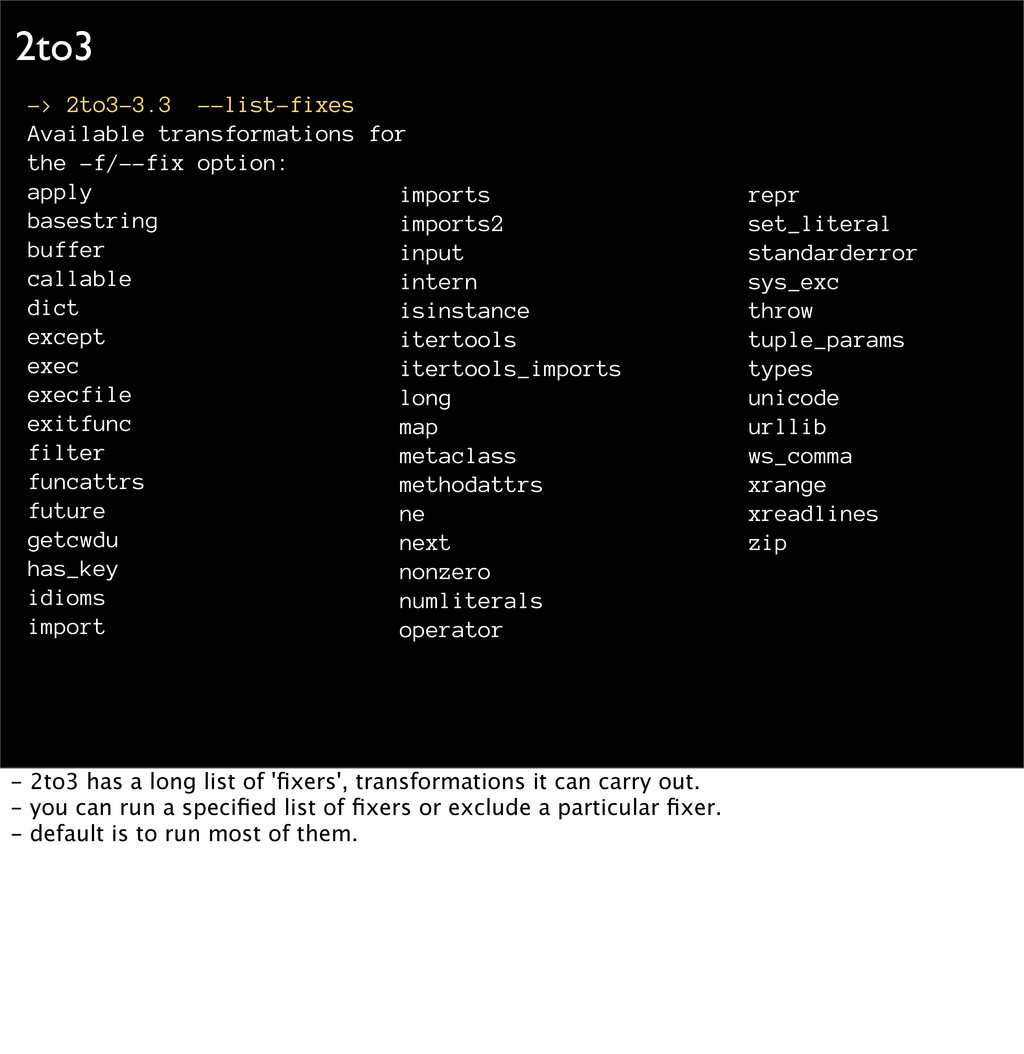
apply basestring buffer callable dict except exec execfile exitfunc filter funcattrs future getcwdu has_key idioms import repr set_literal standarderror sys_exc throw tuple_params types unicode urllib ws_comma xrange xreadlines zip imports imports2 input intern isinstance itertools itertools_imports long map metaclass methodattrs ne next nonzero numliterals operator - 2to3 has a long list of 'fixers', transformations it can carry out. - you can run a specified list of fixers or exclude a particular fixer. - default is to run most of them.
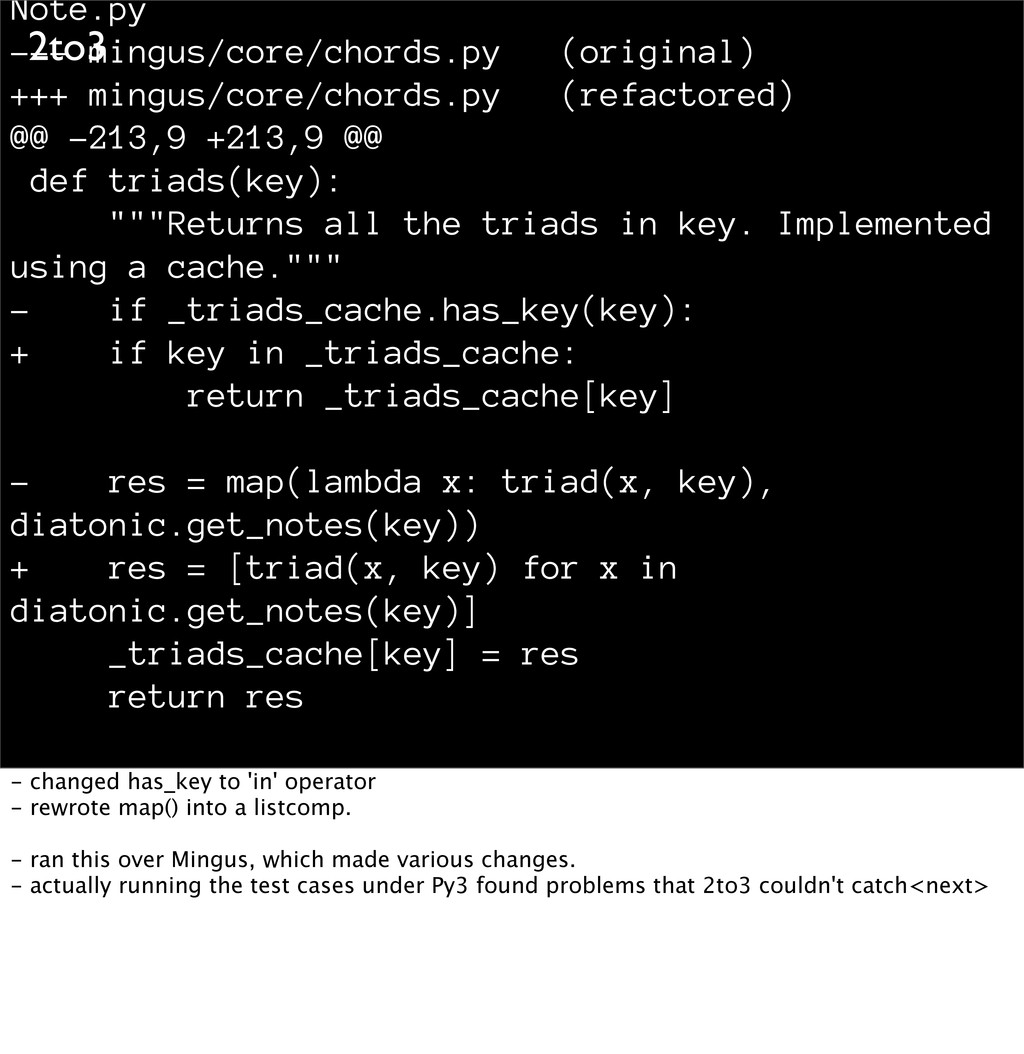
+213,9 @@ def triads(key): """Returns all the triads in key. Implemented using a cache.""" - if _triads_cache.has_key(key): + if key in _triads_cache: return _triads_cache[key] - res = map(lambda x: triad(x, key), diatonic.get_notes(key)) + res = [triad(x, key) for x in diatonic.get_notes(key)] _triads_cache[key] = res return res - changed has_key to 'in' operator - rewrote map() into a listcomp. - ran this over Mingus, which made various changes. - actually running the test cases under Py3 found problems that 2to3 couldn't catch<next>
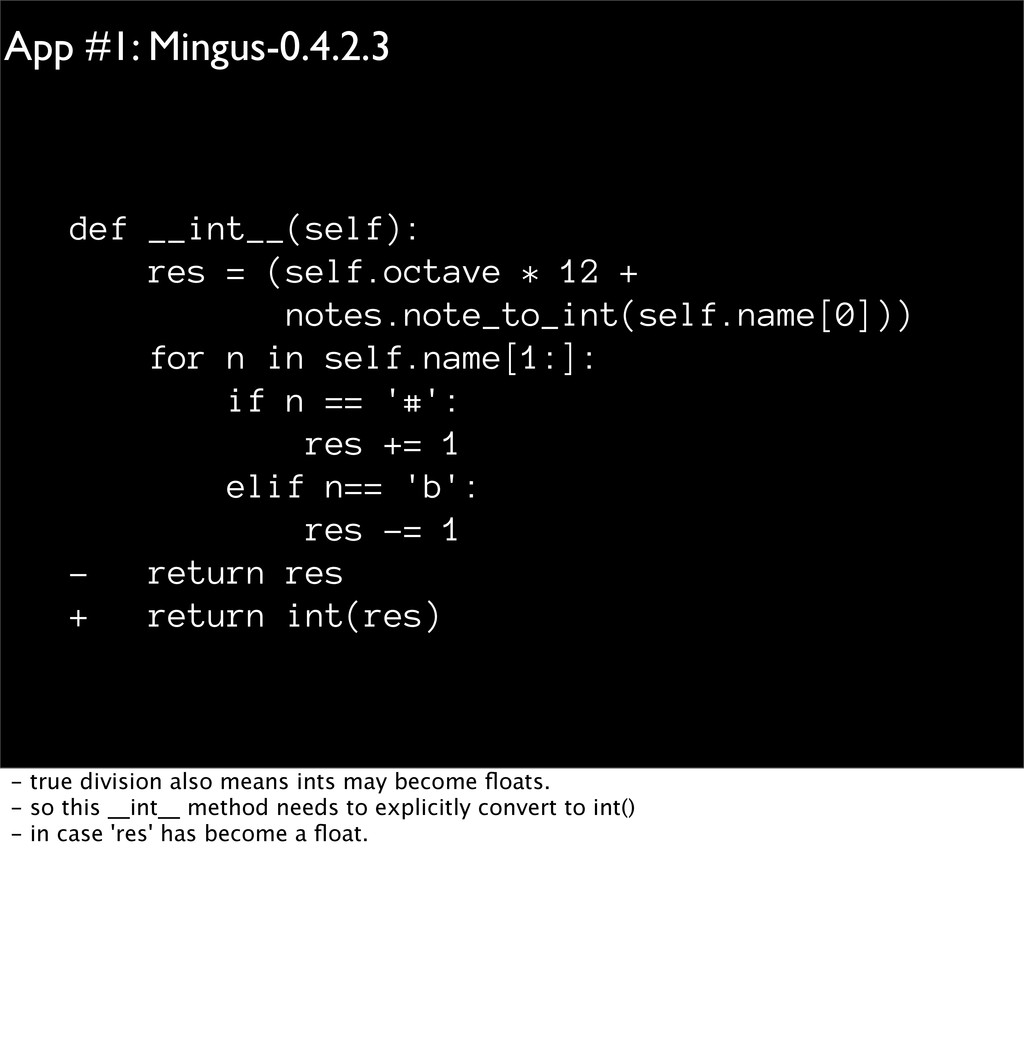
+ notes.note_to_int(self.name[0])) for n in self.name[1:]: if n == '#': res += 1 elif n== 'b': res -= 1 - return res + return int(res) - true division also means ints may become floats. - so this __int__ method needs to explicitly convert to int() - in case 'res' has become a float.
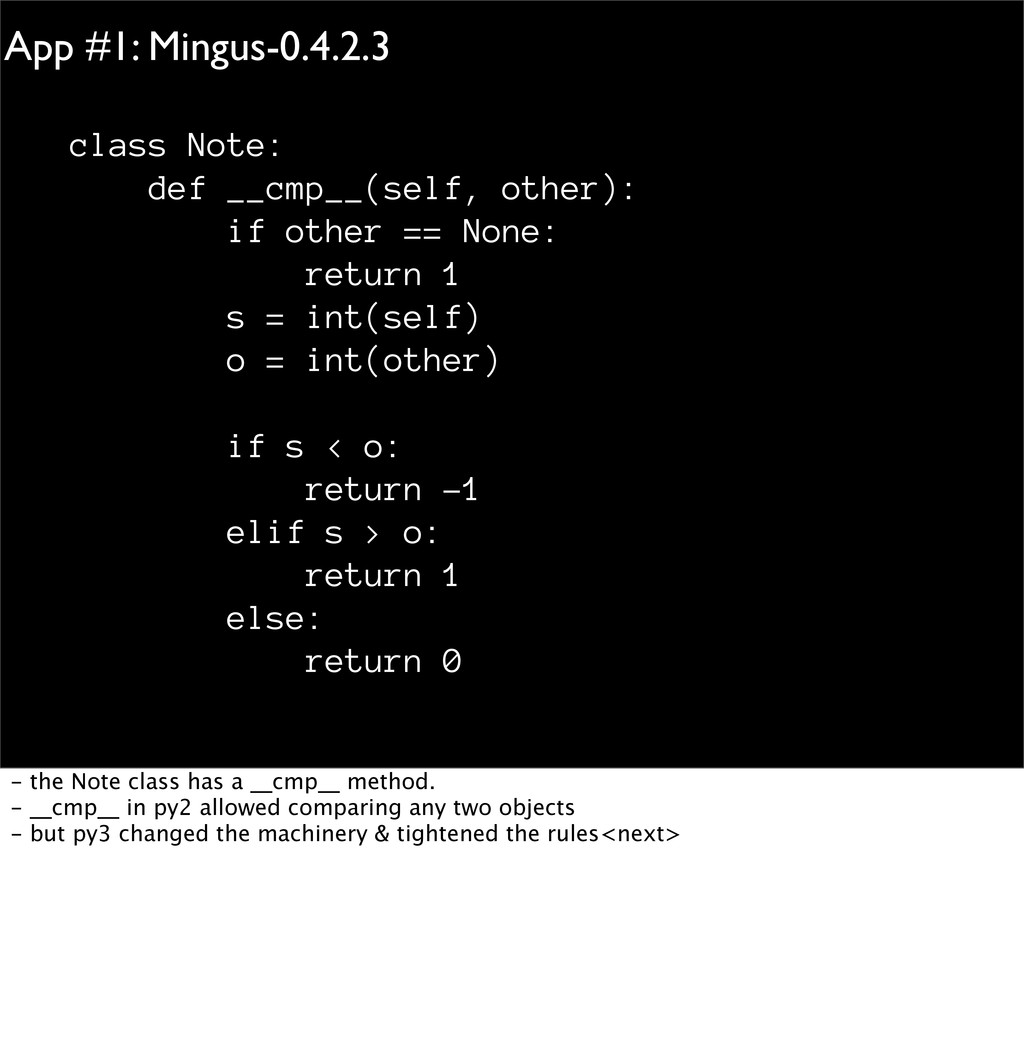
== None: return 1 s = int(self) o = int(other) if s < o: return -1 elif s > o: return 1 else: return 0 - the Note class has a __cmp__ method. - __cmp__ in py2 allowed comparing any two objects - but py3 changed the machinery & tightened the rules<next>
< 'abc') -> True (2 < None) -> TypeError: unorderable types: int() < NoneType() (2 < 'abc') -> TypeError: unorderable types: int() < str() - in py2, you could compare any type to any other type with <, > - the result was arbitrary, not often useful - if you had a list & sorted it, you'd get some ordering. - py3 raises a TypeError for types that aren't comparable
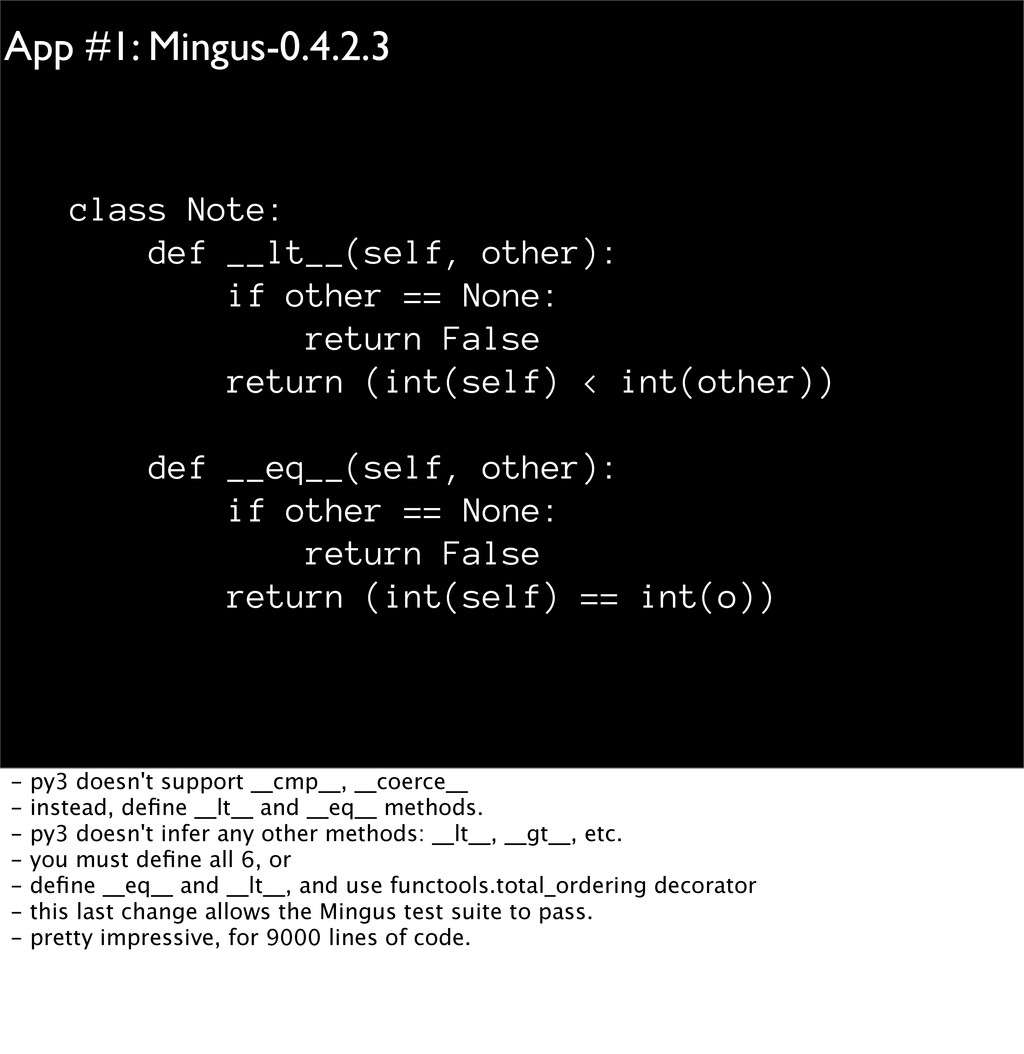
== None: return False return (int(self) < int(other)) def __eq__(self, other): if other == None: return False return (int(self) == int(o)) - py3 doesn't support __cmp__, __coerce__ - instead, define __lt__ and __eq__ methods. - py3 doesn't infer any other methods: __lt__, __gt__, etc. - you must define all 6, or - define __eq__ and __lt__, and use functools.total_ordering decorator - this last change allows the Mingus test suite to pass. - pretty impressive, for 9000 lines of code.
now, it so happens that the rewritten Mingus works in both Py2 and 3. - not true of programs in general. - if this is a package you maintain, you have a decision: how to maintain the Python3 port? Options are 1) abandon Py2; the Py3 is the only version you'll maintain. 2) have separate Py2 and Py3 branches. 3) maintain python2 code; translate at release or install time w/ 2to3 - this is why 2to3 is so controllable: write output to new directory; control which fixers are run. - I'm not maintaining any of these apps, so not a decision I need to make. Let's move on to #2.
file • Automatically re- reads file when mtime changes • 4 modules, 157 lines. second app: jsonfig. reads a config from a JSON file and produces a dictionary-like object Dictionary is updated if the file is edited. Test coverage is reasonably good. 'python -3' produces no warnings. 2to3 makes 1 change: ValueError, e -> except ValueError as e This seems like a cakewalk! <next>
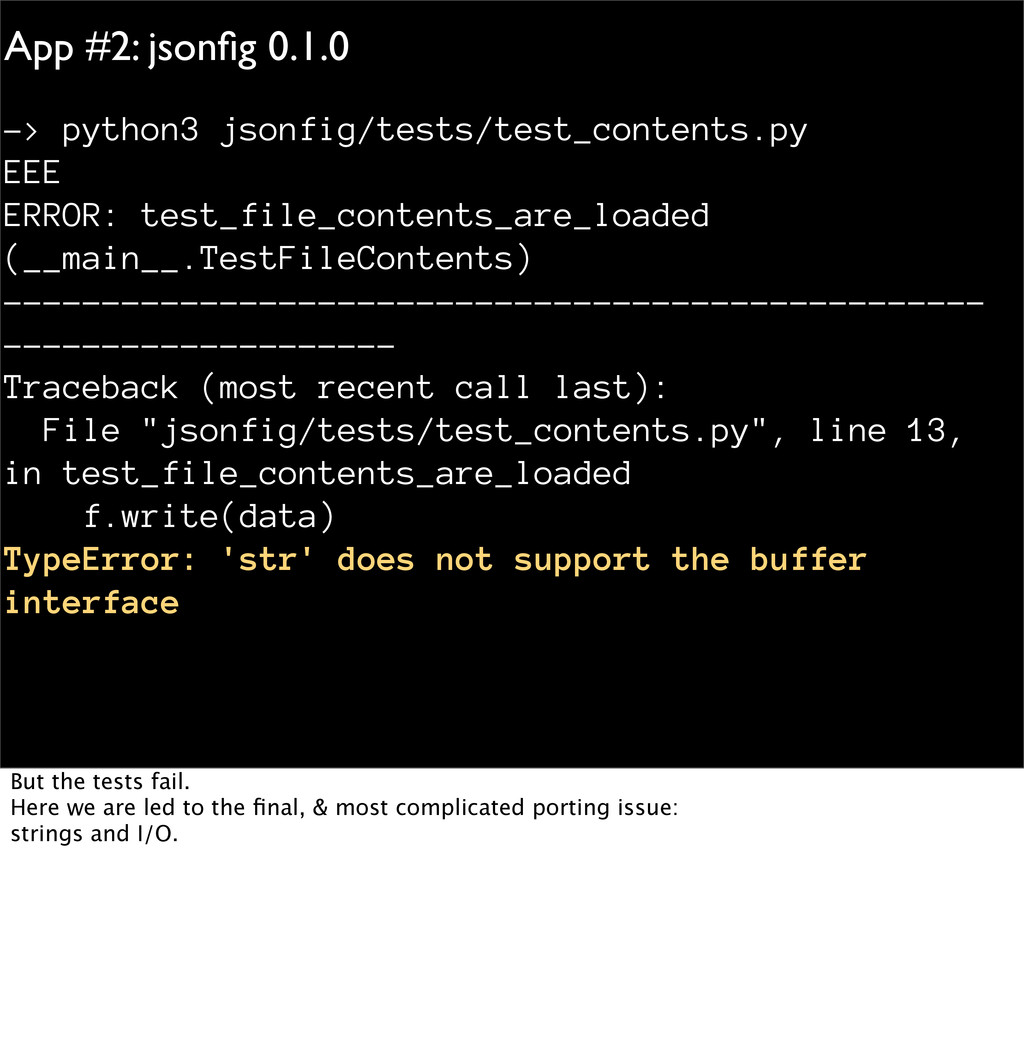
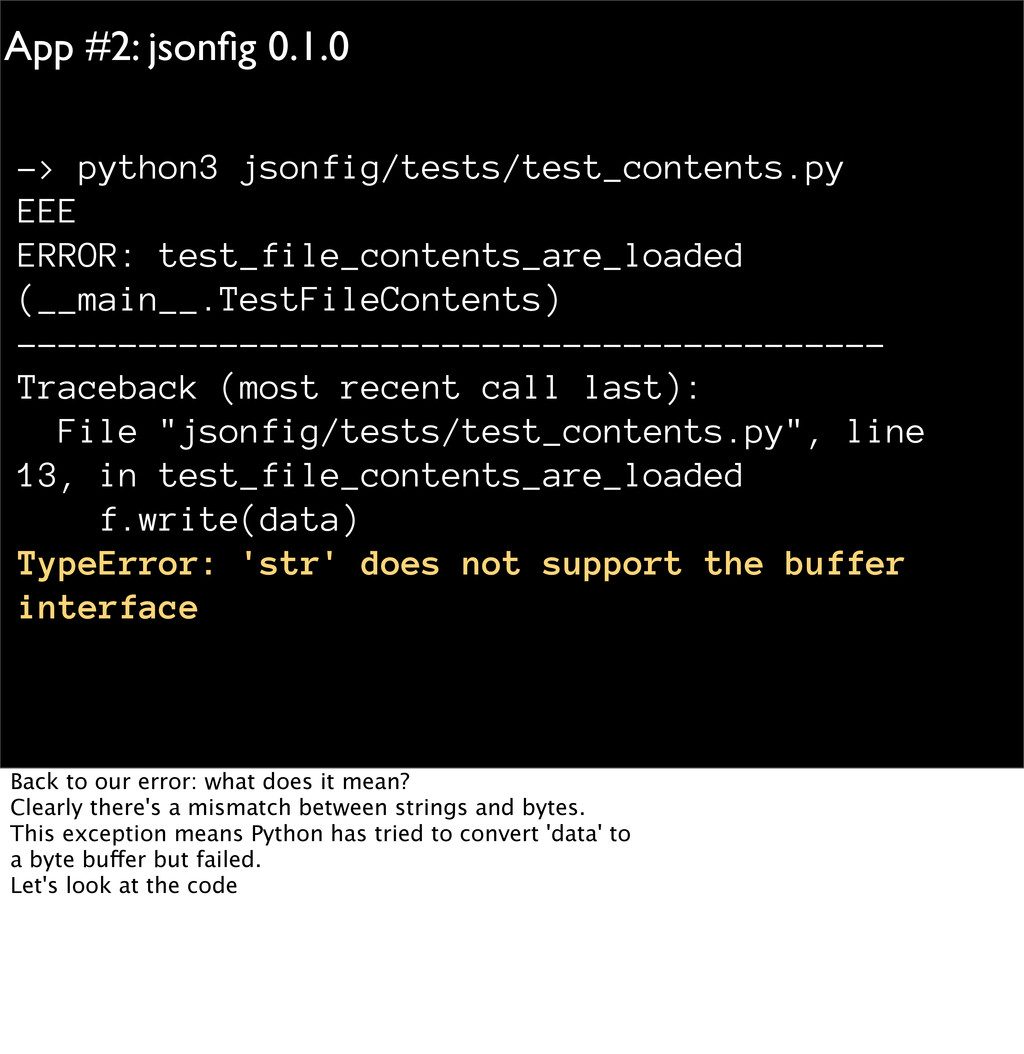
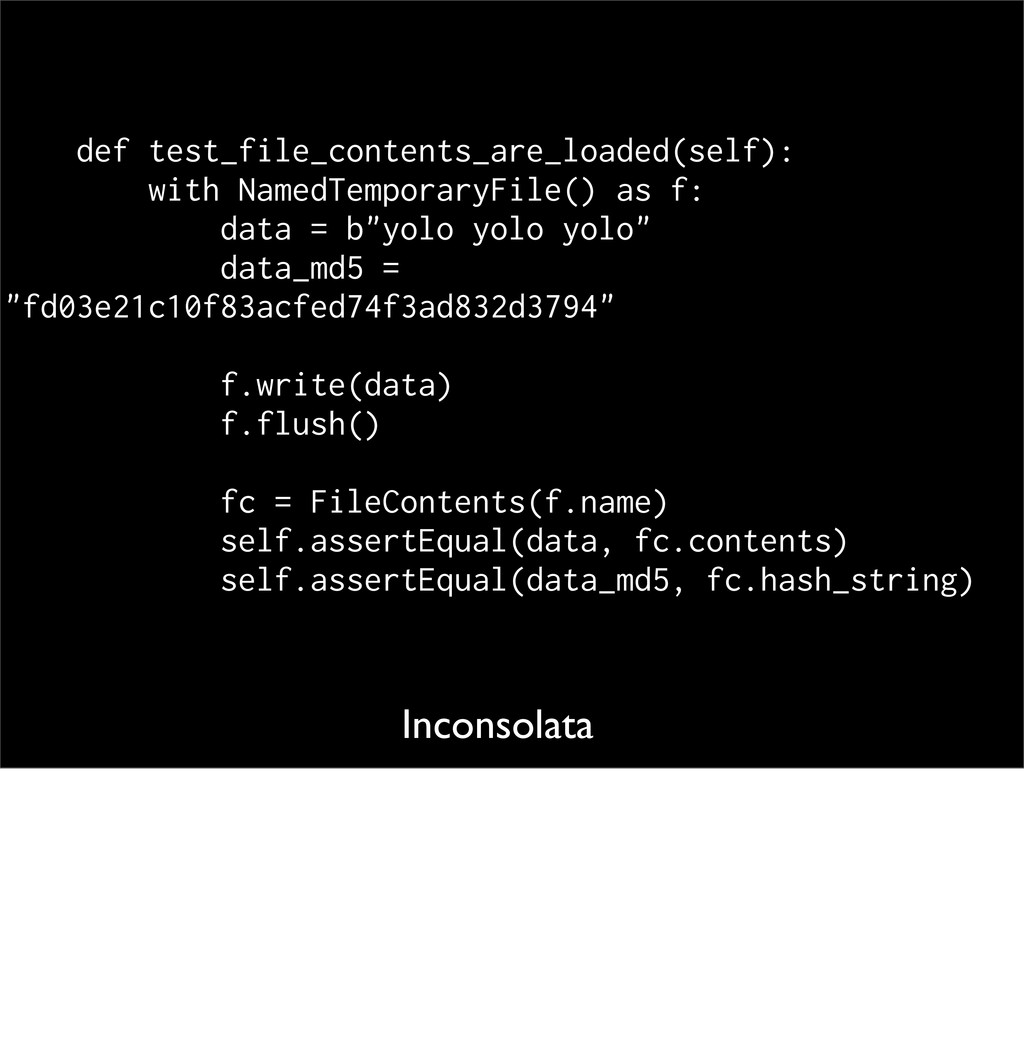
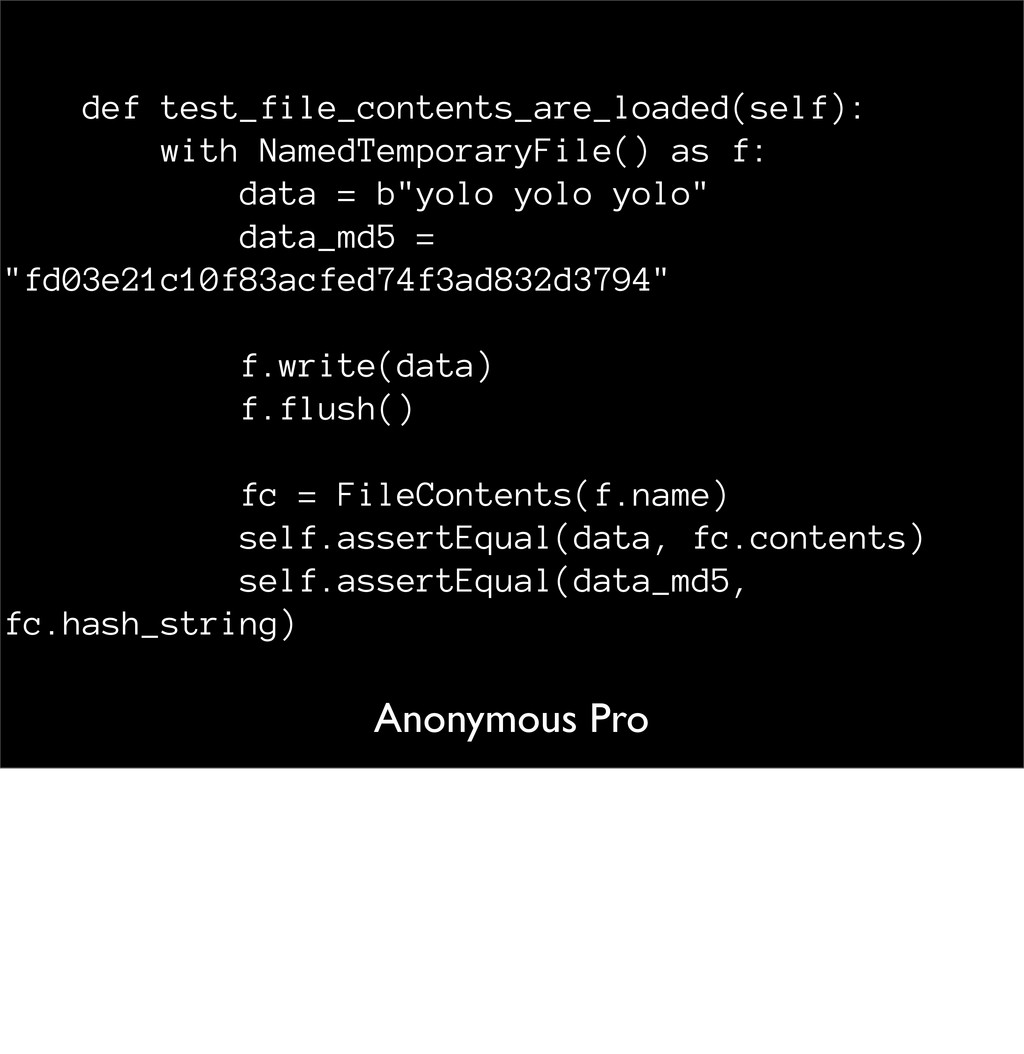
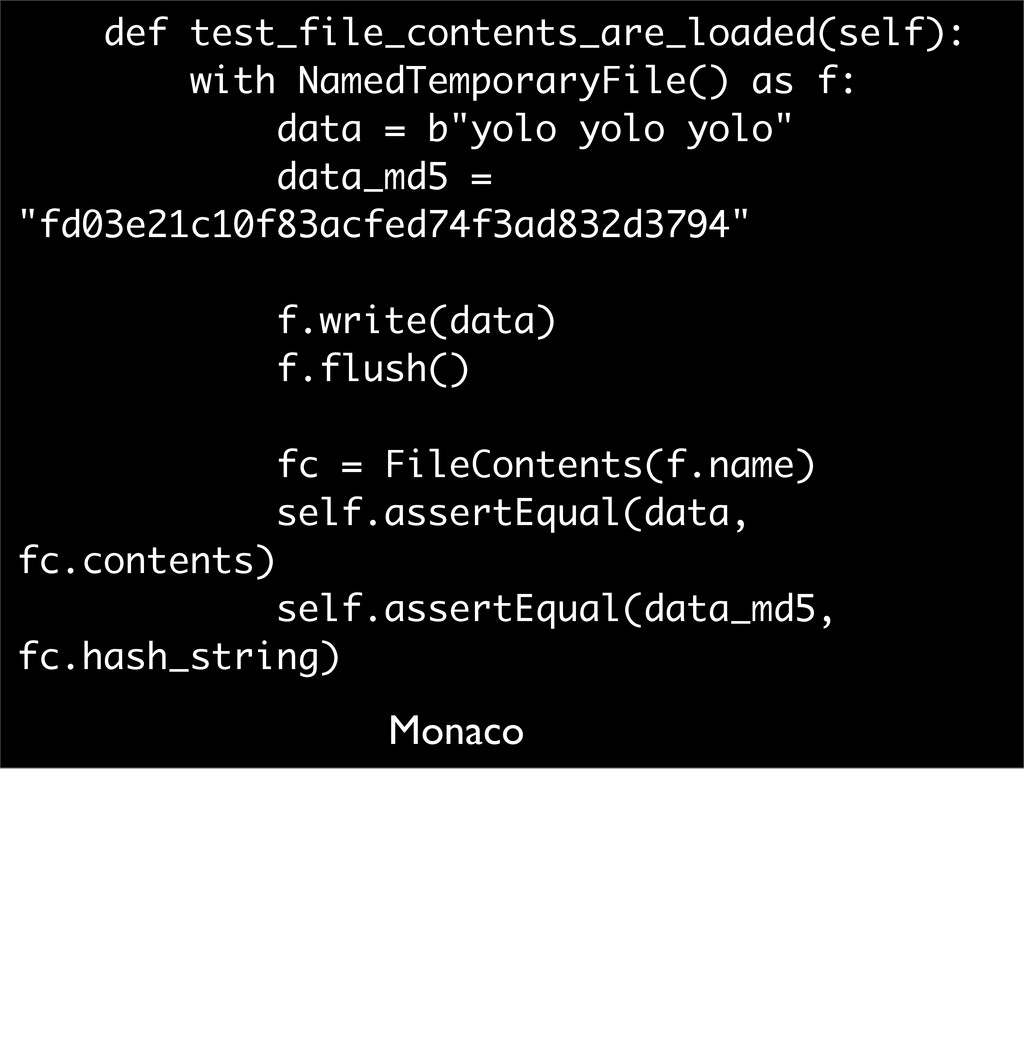
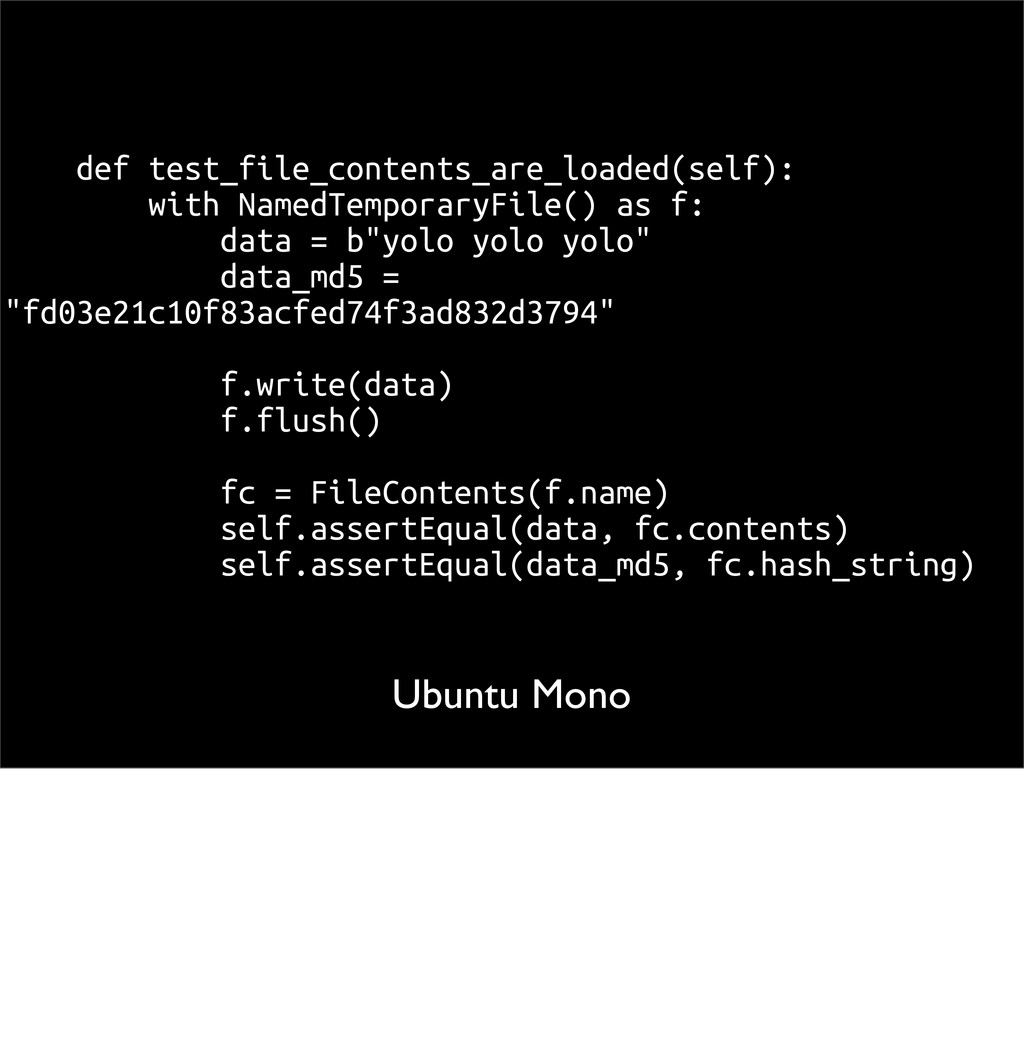
(__main__.TestFileContents) -------------------------------------------------- -------------------- Traceback (most recent call last): File "jsonfig/tests/test_contents.py", line 13, in test_file_contents_are_loaded f.write(data) TypeError: 'str' does not support the buffer interface But the tests fail. Here we are led to the final, & most complicated porting issue: strings and I/O.
Μπορῶ νὰ φάω σπασμένα γυαλιὰ χωρὶς νὰ πάθω τίποτα. Character: abstract idea of a symbol in a language. A b M Μ ω θ Code point: integer value from 0 to 0x10FFFF 65 98 77 924 969 952 - a very brief intro to Unicode terms. - read the Unicode howto for more. - or watch 'Pragmatic Unicode' from PyCon 2012 (pyvideo.org) 'M' in the Greek text is 924; M in English is 77.
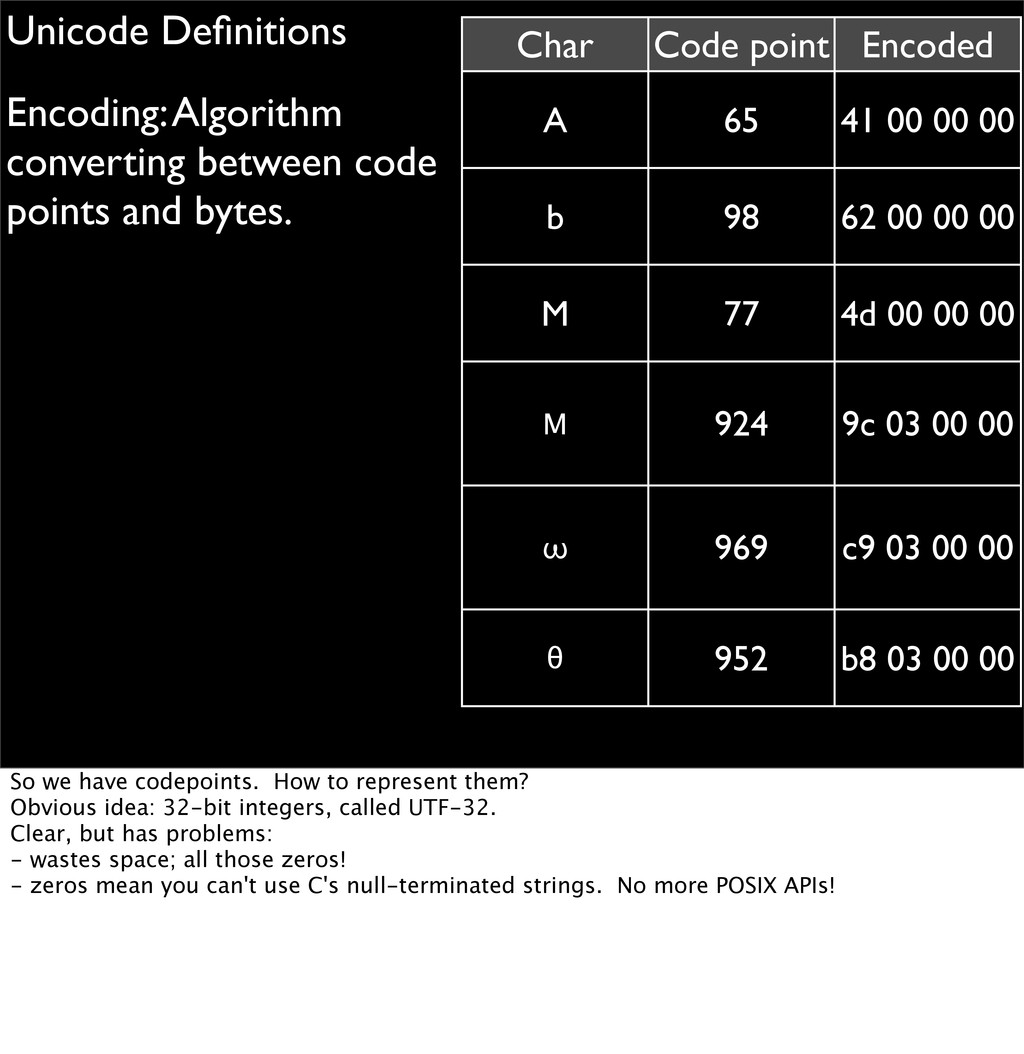
Char Code point Encoded A 65 41 00 00 00 b 98 62 00 00 00 M 77 4d 00 00 00 Μ 924 9c 03 00 00 ω 969 c9 03 00 00 θ 952 b8 03 00 00 So we have codepoints. How to represent them? Obvious idea: 32-bit integers, called UTF-32. Clear, but has problems: - wastes space; all those zeros! - zeros mean you can't use C's null-terminated strings. No more POSIX APIs!
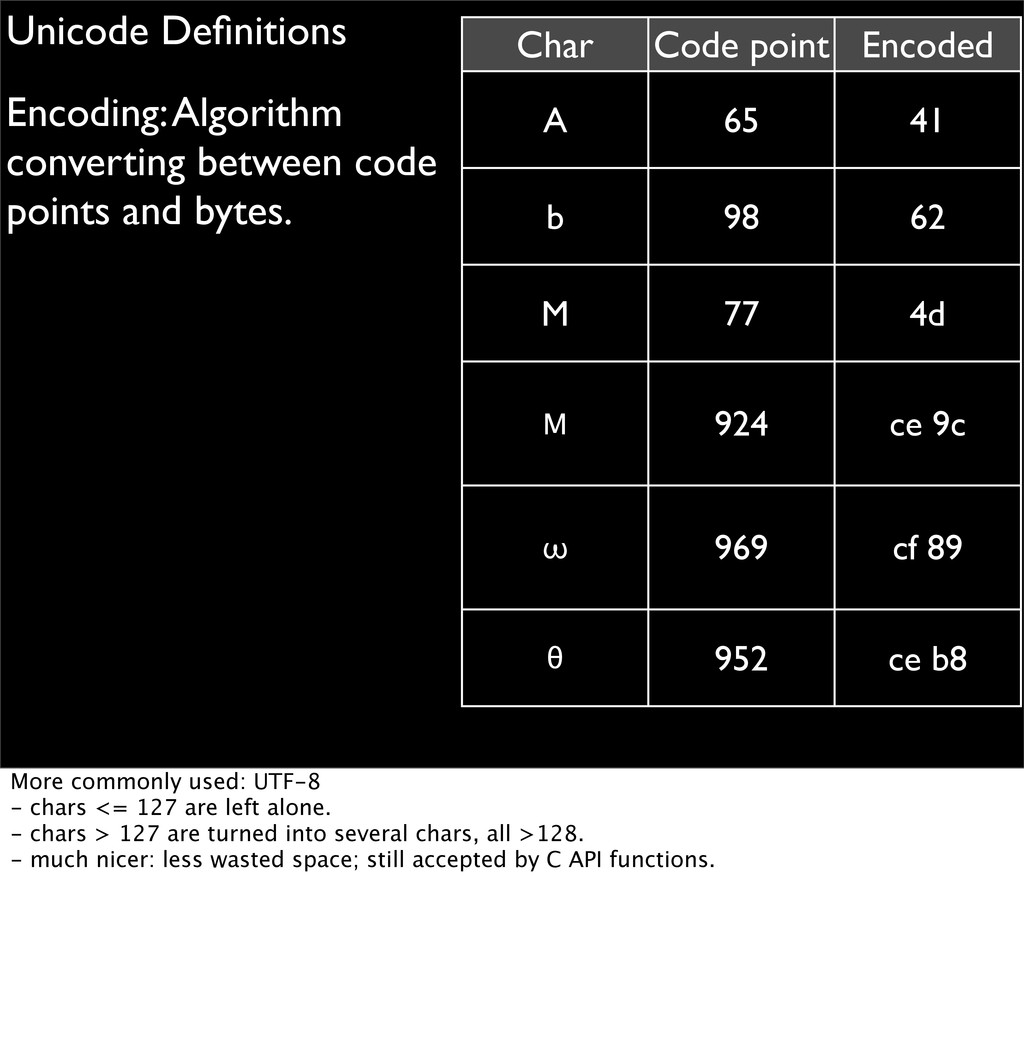
Char Code point Encoded A 65 41 b 98 62 M 77 4d Μ 924 ce 9c ω 969 cf 89 θ 952 ce b8 More commonly used: UTF-8 - chars <= 127 are left alone. - chars > 127 are turned into several chars, all >128. - much nicer: less wasted space; still accepted by C API functions.
str[5] returns a one-character string unicode : string of Unicode characters str : string of Unicode characters str[5] returns a one-character string bytes : immutable string of 8-bit characters bytes[5] returns an integer - python2 had string (meaning 8-bit) and Unicode types, both string-ish. - indexing into a string returns another string - combining strings/Unicode uses a default encoding - even a base_string type for checking if something is string-ish. - in python3, strings are always Unicode. - 8-bit data is represented as the 'bytes' type, which doesn't behave like strings. - e.g. indexing returns int, not string. - and there's a mutable byte type: bytearray : mutable string of 8-bit characters
b'abc\xe9' : bytes is alias for str 'abc\u039c' : str u'abc' : SyntaxError in Python 3.0-3.2 u'abc' : alias for str in Python 3.3 b'abc' : bytes - in python2, u-prefix means Unicode. - in python3, no prefix is Unicode, and b-prefix means bytes. - for ease of writing compat. code, python2 supports b'' - and Python 3.3 supports u'' (Python 3.0-3.2 didn't) Python 2.x's base-string is gone.
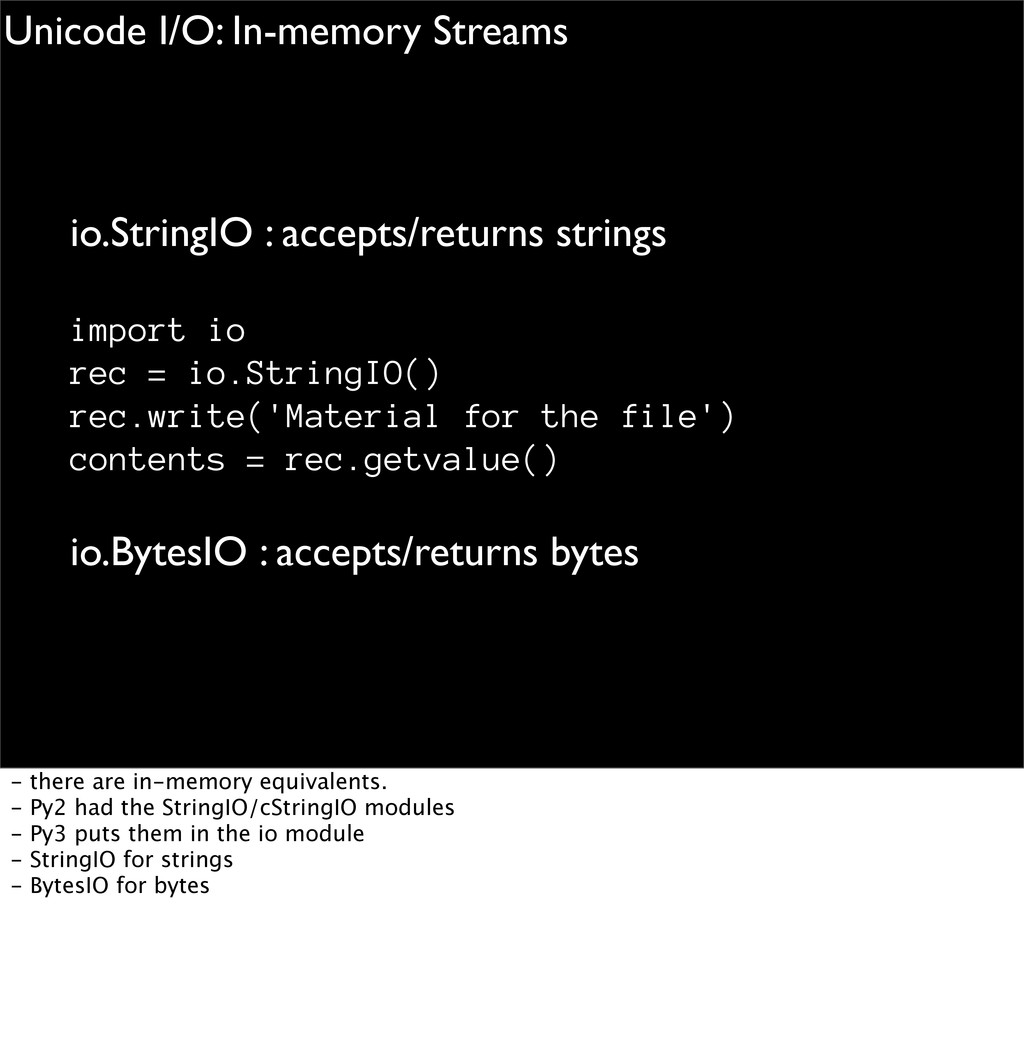
a string .write() accepts a string .encoding : string giving the encoding open (filename, 'rb' or 'wb') .read(), .readline() return bytes .write() accepts bytes .encoding : raises AttributeError - what's the impact on input & output? - opening text files returns Unicode strings, or requires writing Unicode strings. - opening binary files means you must use bytes. - OS interfaces like socket module expect bytes. - there are also string/byte equivalents of the StringIO module
(__main__.TestFileContents) ------------------------------------------- Traceback (most recent call last): File "jsonfig/tests/test_contents.py", line 13, in test_file_contents_are_loaded f.write(data) TypeError: 'str' does not support the buffer interface Back to our error: what does it mean? Clearly there's a mismatch between strings and bytes. This exception means Python has tried to convert 'data' to a byte buffer but failed. Let's look at the code
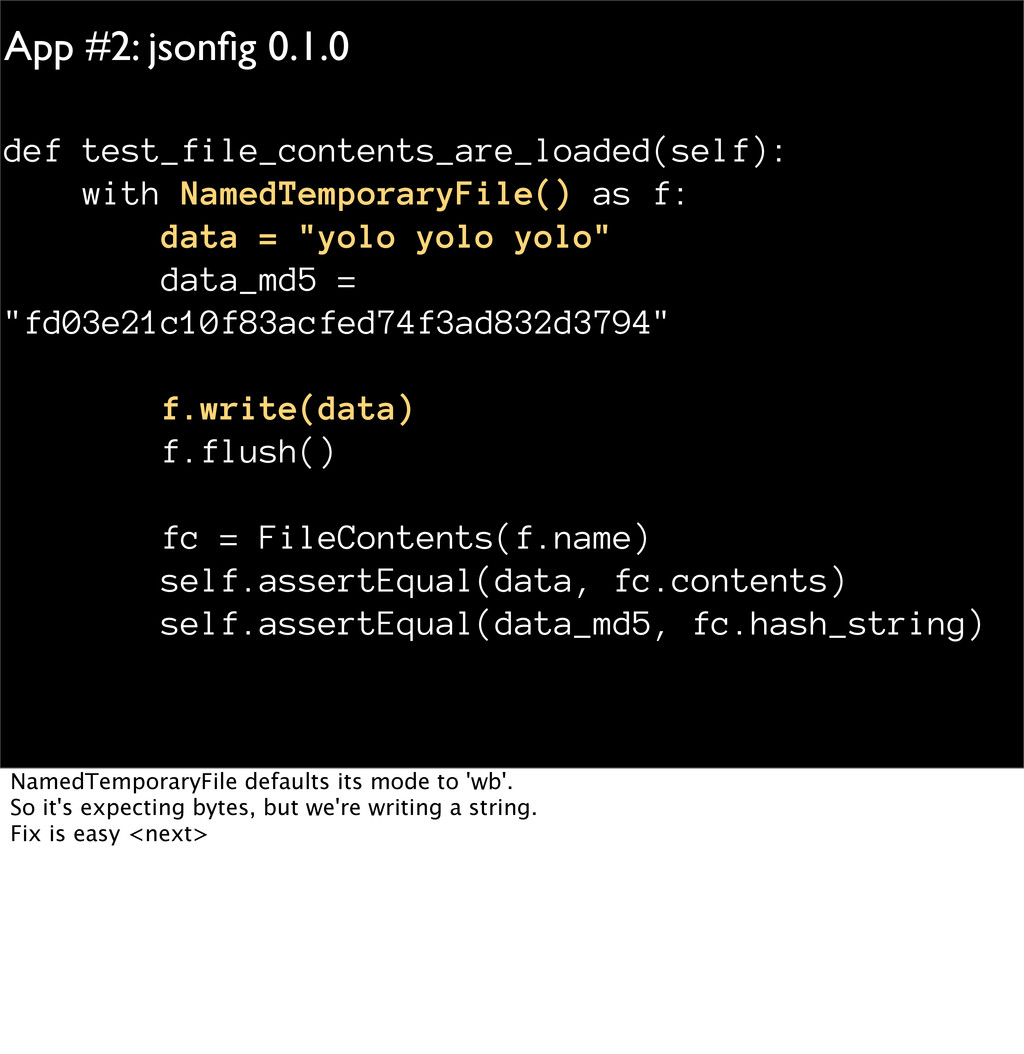
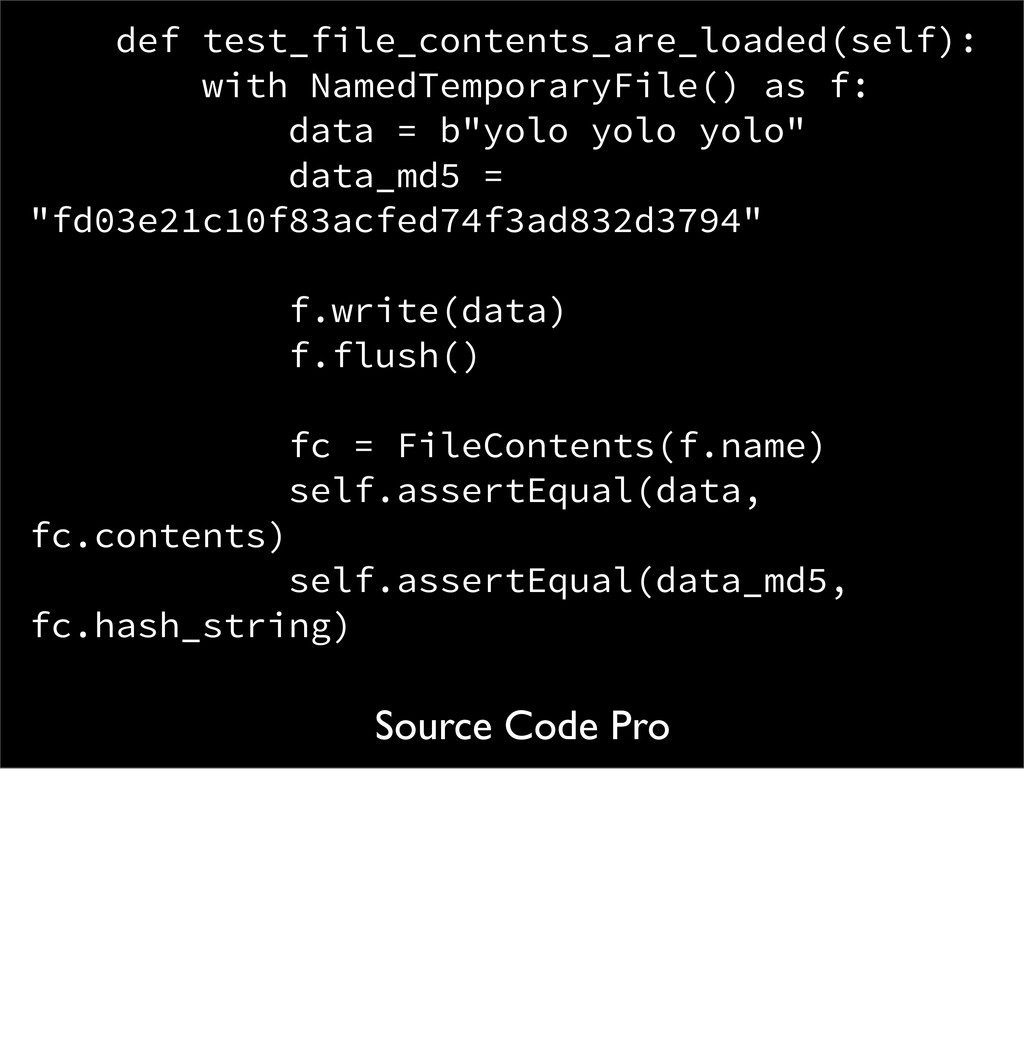
data = "yolo yolo yolo" data_md5 = "fd03e21c10f83acfed74f3ad832d3794" f.write(data) f.flush() fc = FileContents(f.name) self.assertEqual(data, fc.contents) self.assertEqual(data_md5, fc.hash_string) NamedTemporaryFile defaults its mode to 'wb'. So it's expecting bytes, but we're writing a string. Fix is easy <next>
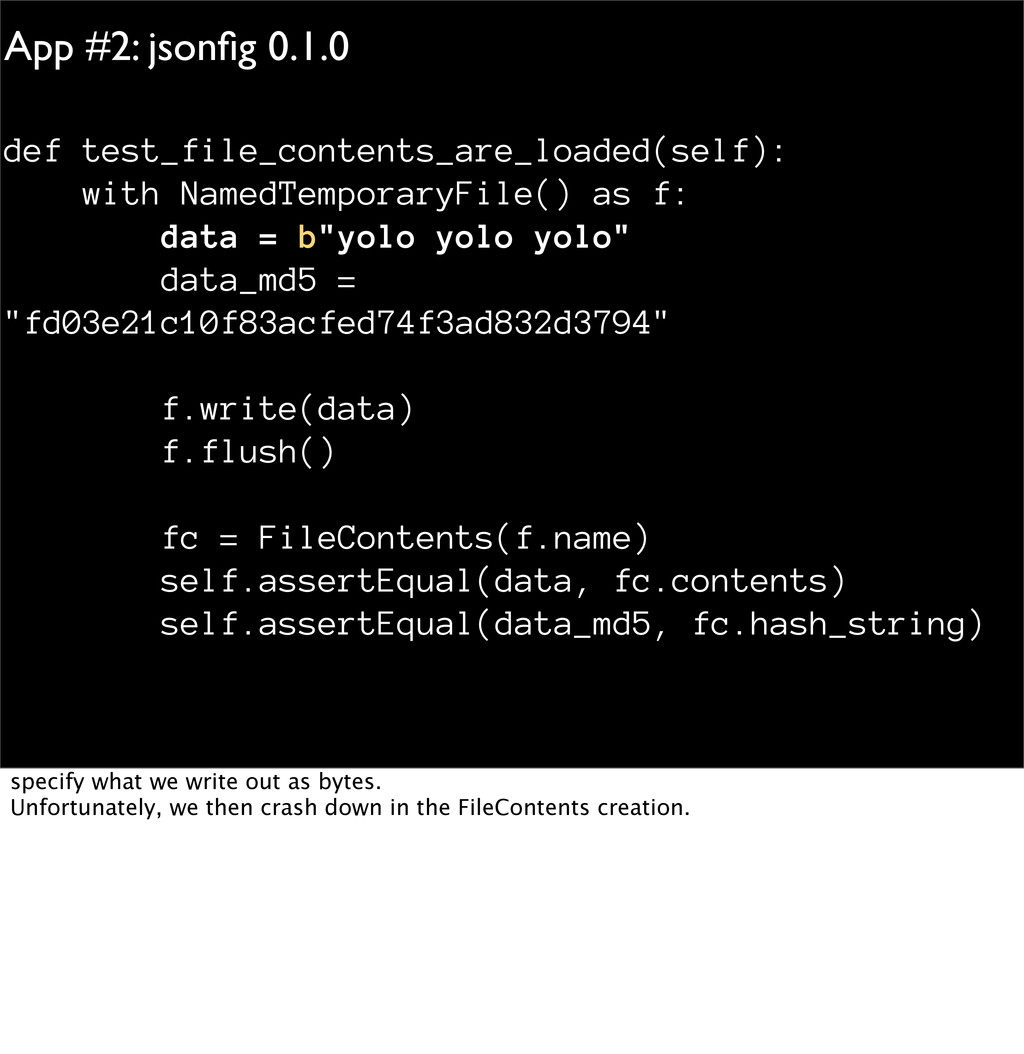
data = b"yolo yolo yolo" data_md5 = "fd03e21c10f83acfed74f3ad832d3794" f.write(data) f.flush() fc = FileContents(f.name) self.assertEqual(data, fc.contents) self.assertEqual(data_md5, fc.hash_string) specify what we write out as bytes. Unfortunately, we then crash down in the FileContents creation.
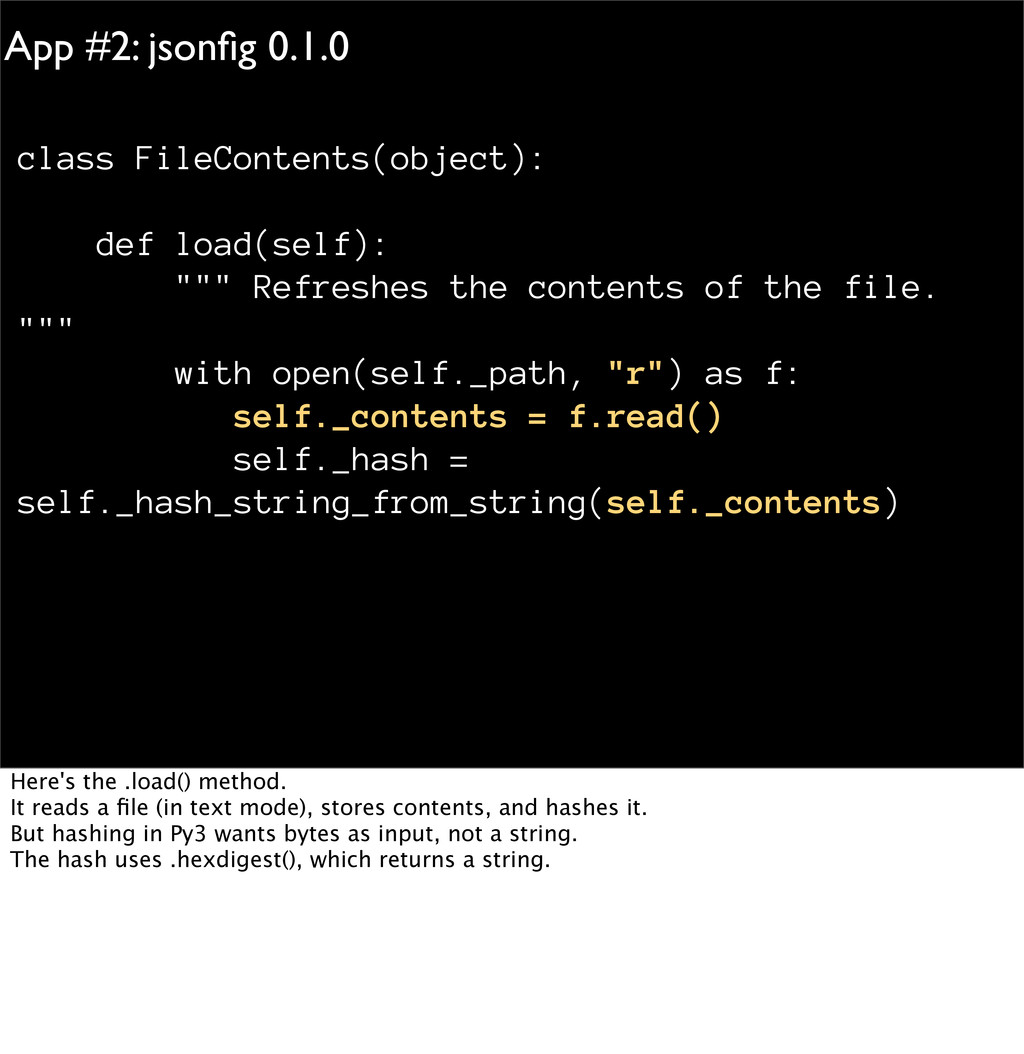
the contents of the file. """ with open(self._path, "r") as f: self._contents = f.read() self._hash = self._hash_string_from_string(self._contents) Here's the .load() method. It reads a file (in text mode), stores contents, and hashes it. But hashing in Py3 wants bytes as input, not a string. The hash uses .hexdigest(), which returns a string.
the contents of the file. """ with open(self._path, "rb") as f: contents = f.read() self._hash = self._hash_string_from_string(contents) self._contents=contents.decode('utf-8') Fix: open the file in binary mode. Read the contents as bytes and hash that. We'll then decode the bytes into a string, assuming utf-8. (We could rename _from_string method.) We could add an 'encoding' argument, but that's an API change. porting to py3 may well require reworking APIs in this way. py2 let you be sloppy: functions could return a string or Unicode, and most code would behave the same. Default encoding would handle it if your data didn't have accented characters. py3 makes str and bytes very different.
def as_text(self): ... def as_xml(self, encoding='UTF-8'): ... qt = Quotation(...) sys.stdout.write(qt.as_text()) xml = qt.as_xml('iso-8859-1') sys.stdout.write(xml.encode('iso-8859-1')) - example from a package of mine: - I had as_html/as_text/as_xml methods. - for text and html, result was written directly to files. - for xml, it was converted to an encoding. - in py3 terms: html and text return bytes; xml returns a string.
community. there's been some angst about how long it's taken, but transitions often take longer to get started than expected - but then go faster than expected.
12.10 October 18th Django 1.5 beta November 1st Django 1.5 final December 24th - Python 3.0 released in December 2008, 4 years ago. - 3.1 rewrote the I/O to be much faster. - 3.2 reduced GIL contention and enhanced the stdlib (argparse, concurrent.futures) - 3.3 reduces memory use, adds C decimal module, IP addresses. - go over the calendar - if you've been debating whether to convert, dip your toe in the water - try writing command-line, filesystem-only scripts in Python3 - playing on an AWS instance? try Python3 + Django
a classifier, Python :: 3, for code that supports Py3. The Python3 ecosystem is still relatively small, but growing, & I think the next year will see a lot of change.
for the file') contents = rec.getvalue() io.BytesIO : accepts/returns bytes Unicode I/O: In-memory Streams - there are in-memory equivalents. - Py2 had the StringIO/cStringIO modules - Py3 puts them in the io module - StringIO for strings - BytesIO for bytes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Python 3: Python 2: [... for x in range(10)] print](https://files.speakerdeck.com/presentations/1bd3c8b0778e013053f51231380952b2/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}