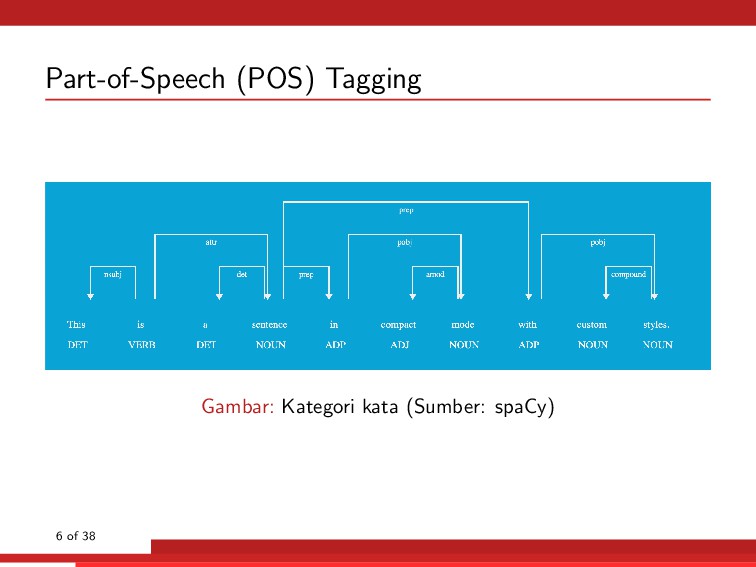
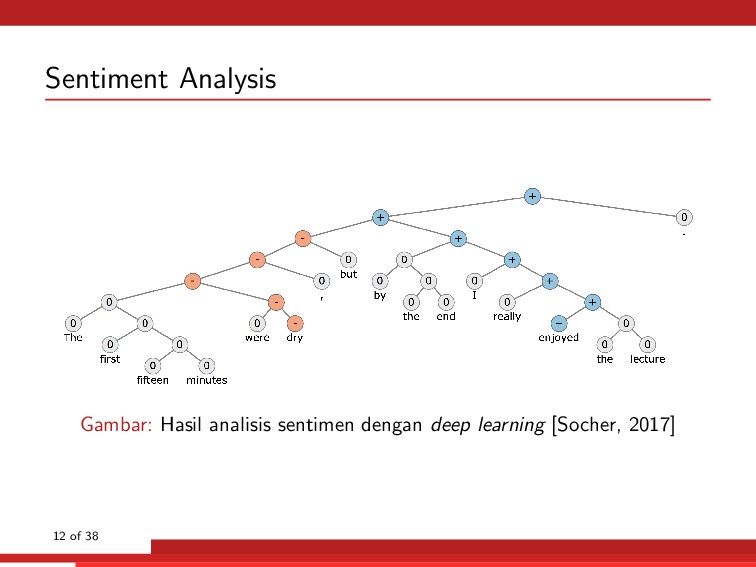
interaksi manusia dan komputer melalui bahasa alami manusia. Beberapa hal yang dibahas di dalamnya antara lain: • Part-of-Speech (POS) tagging • Parsing • Stemming • Machine translation • Named entity recognition (NER) • Question answering • Sentiment analysis • Automatic summarisation • Speech recognition • Text-to-speech 3 of 38
karena mencoba merepresentasikan makna dari kata, frasa, kalimat, dan dokumen melalui distribusinya • Distribusi tersebut direpresentasikan dalam vektor konteks 15 of 38
karena mencoba merepresentasikan makna dari kata, frasa, kalimat, dan dokumen melalui distribusinya • Distribusi tersebut direpresentasikan dalam vektor konteks • “Dalam suatu dokumen, kata apa saja yang muncul bersamaan?” 15 of 38
karena mencoba merepresentasikan makna dari kata, frasa, kalimat, dan dokumen melalui distribusinya • Distribusi tersebut direpresentasikan dalam vektor konteks • “Dalam suatu dokumen, kata apa saja yang muncul bersamaan?” • Begitu pula di level semantik → Bag-of-Words (BoW) model 15 of 38
karena mencoba merepresentasikan makna dari kata, frasa, kalimat, dan dokumen melalui distribusinya • Distribusi tersebut direpresentasikan dalam vektor konteks • “Dalam suatu dokumen, kata apa saja yang muncul bersamaan?” • Begitu pula di level semantik → Bag-of-Words (BoW) model • Bahkan, bisa sampai ke level karakter! 15 of 38
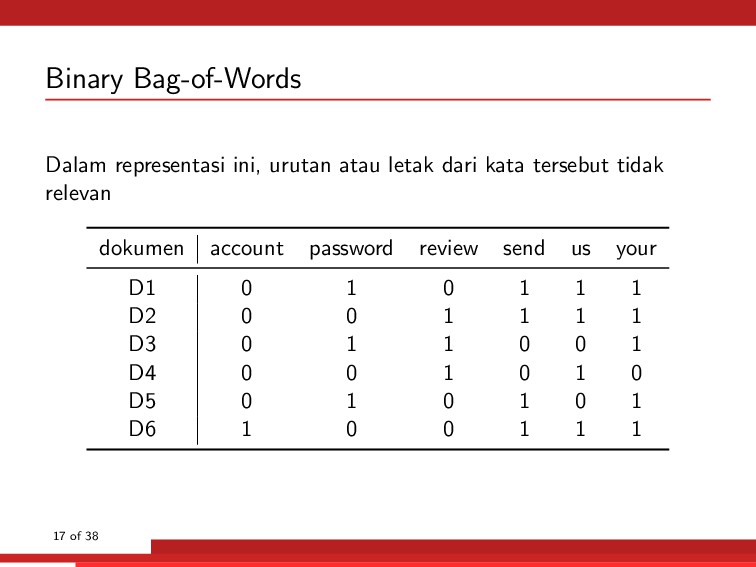
tidak relevan D1 “send us your password” D2 “send us your review” D3 “review your password” D4 “review us” D5 “send your password” D6 “send us your account” 16 of 38
) • tft,d ... frekuensi kata t dalam dokumen d, N ... jumlah dokumen, dft ... jumlah dokumen yang mempunyai kata t • Kata yang sering muncul mungkin tidak penting, e.g. kata hubung • Kata yang langka akan bernilai lebih – lihat posisi dft! 20 of 38
jarak yang umum • Untuk dokumen, jumlah kemunculan kata mungkin tidak begitu penting • Yang penting adalah keberadaan katanya → cosine similarity cos(x, y) = x · y x · y 21 of 38
algoritma lainnya, e.g. Latent Semantic Analysis (LSA), kita bisa menggunakan kakas ini untuk tes seperti TOEFL • LSA berhasil menjawab 64.4% soal 22 of 38
algoritma lainnya, e.g. Latent Semantic Analysis (LSA), kita bisa menggunakan kakas ini untuk tes seperti TOEFL • LSA berhasil menjawab 64.4% soal • Pengguna bahasa Inggris non-natif rata-rata berhasil menjawab 64.5% soal 22 of 38
algoritma lainnya, e.g. Latent Semantic Analysis (LSA), kita bisa menggunakan kakas ini untuk tes seperti TOEFL • LSA berhasil menjawab 64.4% soal • Pengguna bahasa Inggris non-natif rata-rata berhasil menjawab 64.5% soal • Cukup untuk masuk banyak universitas di US! 22 of 38
berbeda, e.g. “beruang” • Token yang tidak dikenali, e.g. salah tik (typo), neologisme, slang • Kata dapat berubah makna dalam frasa, e.g. “mahasiswa” itu netral, tetapi “harga mahasiswa” itu positif 23 of 38
Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning...” 25 of 38
(2009). Natural Language Processing with Python. O’Reilly Media Inc. 2. Jurafsky, D. & Martin, J. H. (2018). Speech and Language Processing (Vol. 3). Pearson. 3. Manning, C., Raghavan, P., & Sch¨ utze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. 33 of 38
of Edinburgh: Text Technologies for Data Science 3. Stanford CS276: Information Retrieval and Web Search (advanced) 4. Stanford CS224n: Natural Language Processing with Deep Learning (advanced) 34 of 38
Liang • EdinburghNLP: Sharon Goldwater, Mirella Lapata, Ivan Titov, Mark Steedman, Shay Cohen, Walid Magdy, etc. • UniMelb CIS School: Tim Baldwin, Trevor Cohn, Karin Verspoor • UWNLP: Noah Smith, Luke Zettlemoyer • QCRI • Chris Dyer (DeepMind), Sebastian Ruder (DeepMind), Hal Daum´ e III (UMaryland), Graham Neubig (CMU), Kyunghyun Cho (NYU), Phil Blunsom (Oxford), Richard Socher (Salesforce), Isabelle Augenstein (Copenhagen) 35 of 38
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}