Web crawling is a hard problem and the web is messy. There is no shortage of semantic web standards -- basically, everyone has one. How do you make sense of the noise of our web of billions of pages?
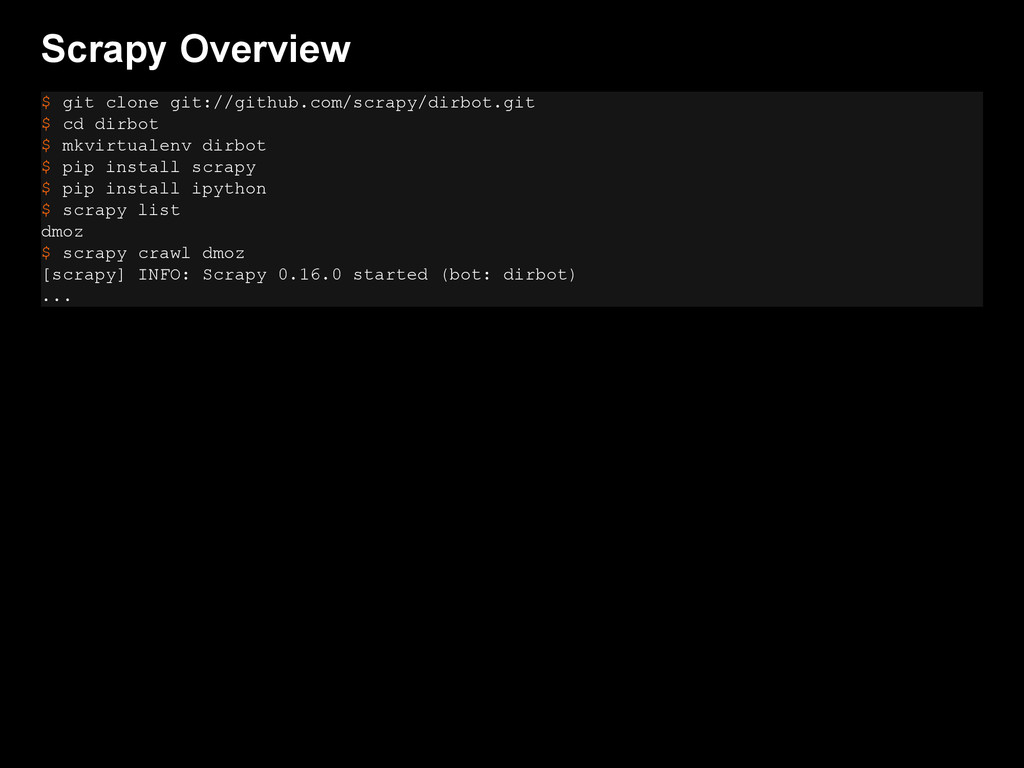
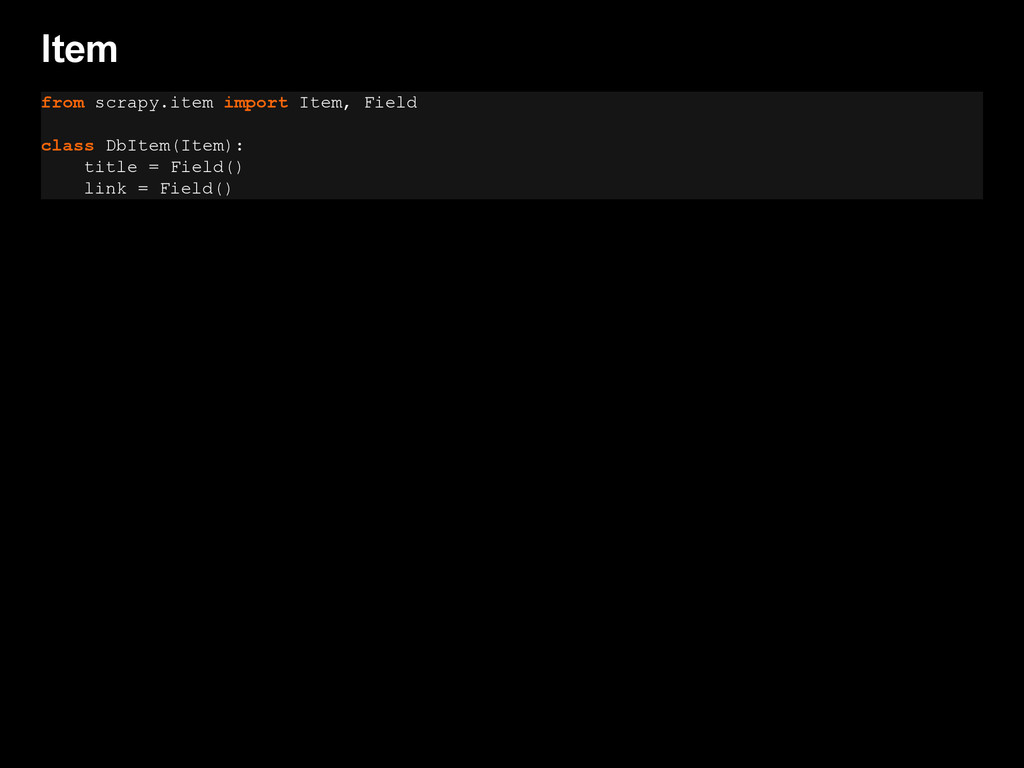
This talk presents two key technologies that can be used: Scrapy, an open source & scalable web crawling framework, and Mr. Schemato, a new, open source semantic web validator and distiller.
Talk given by Andrew Montalenti, CTO of Parse.ly. See http://parse.ly
Slides were built with reST and S5, and thus are available in raw text form here (quite pleasant to browse): https://raw.github.com/Parsely/python-crawling-slides/master/index.rst
You can also view these slides directly in the browser, using your arrow keys to navigate. http://bit.ly/crawling-slides
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example Output [dmoz] DEBUG: Crawled (200) <GET http://dmoz.org/Comp.../Python/Resources/> [dmoz] DEBUG:](https://files.speakerdeck.com/presentations/508c3e5dc211400002043921/slide_18.jpg){kind=link}
![Spider Example class DmozSpider(BaseSpider): name = "dmoz" allowed_domains = ["dmoz.org"]](https://files.speakerdeck.com/presentations/508c3e5dc211400002043921/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
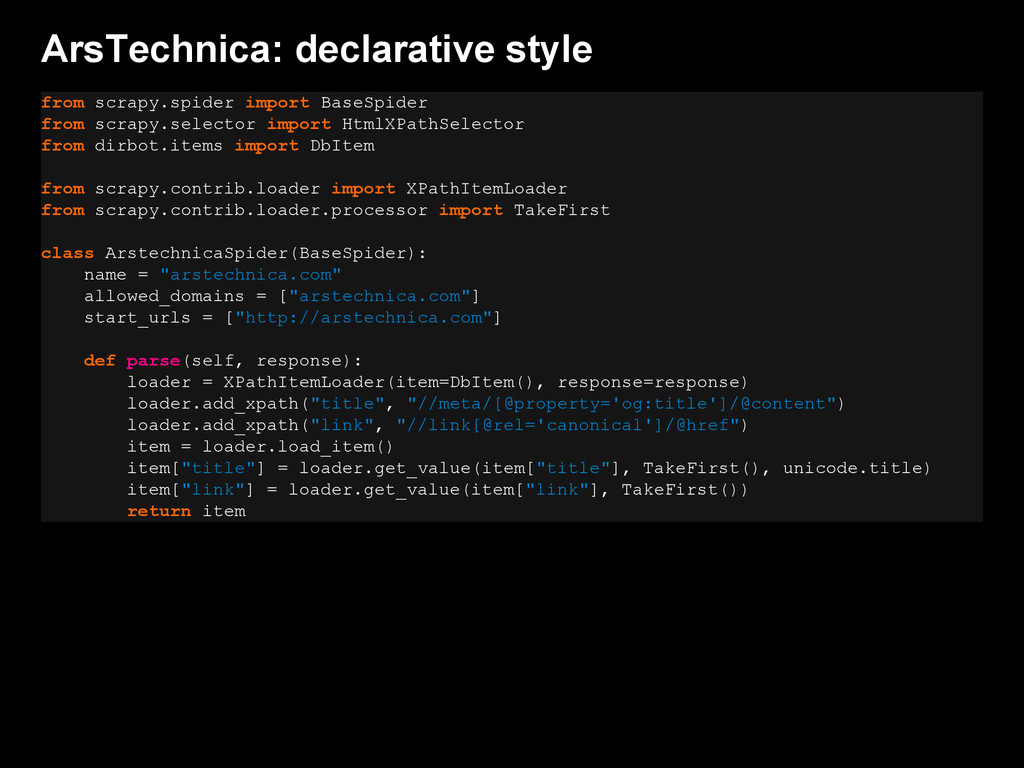{kind=link}
![Live Spider Shell >>> fetch("http://dailycaller.com/2012...-most-rallies/") [dailycaller.com] INFO: Spider opened [dailycaller.com]](https://files.speakerdeck.com/presentations/508c3e5dc211400002043921/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
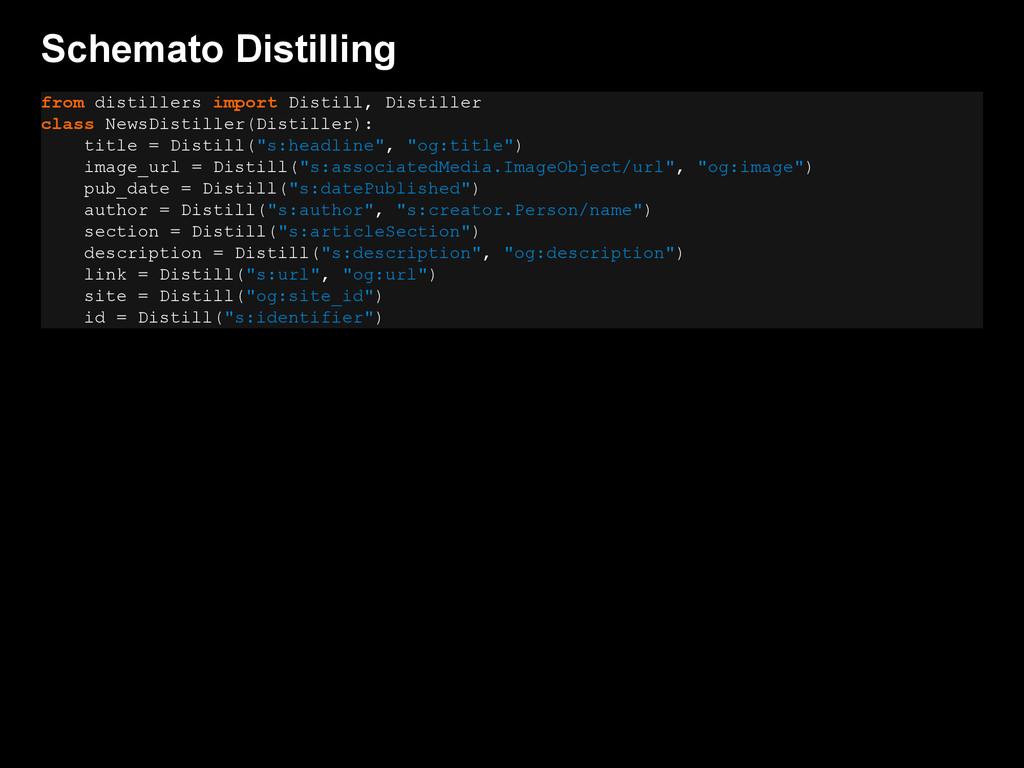{kind=link}
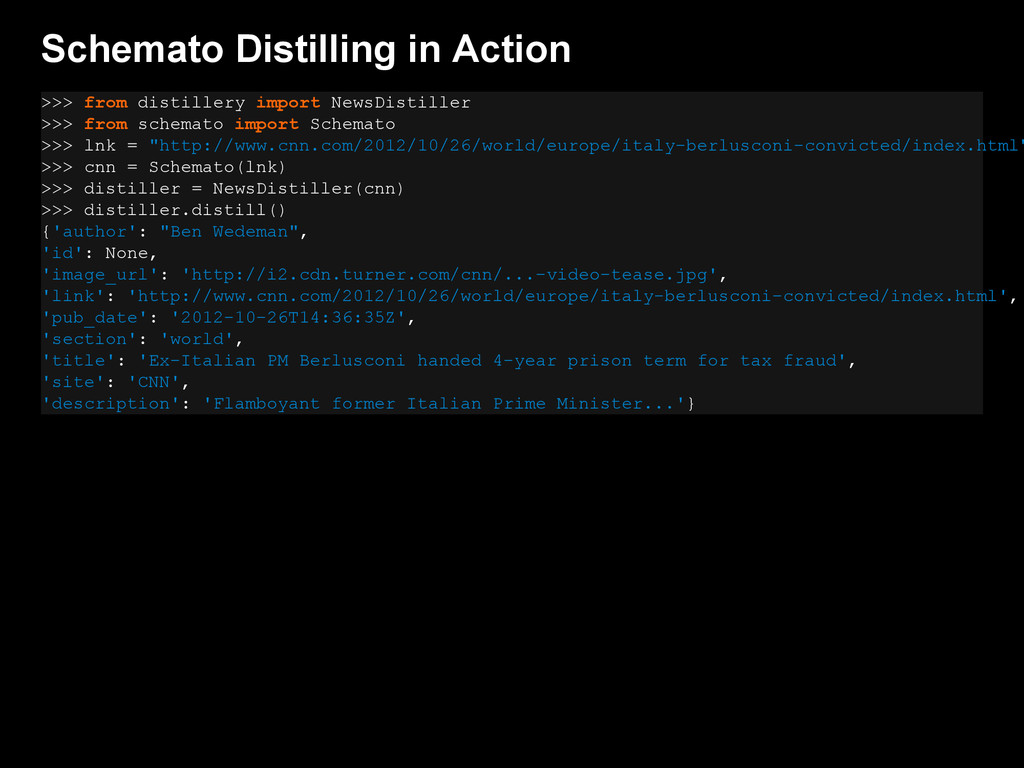{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}