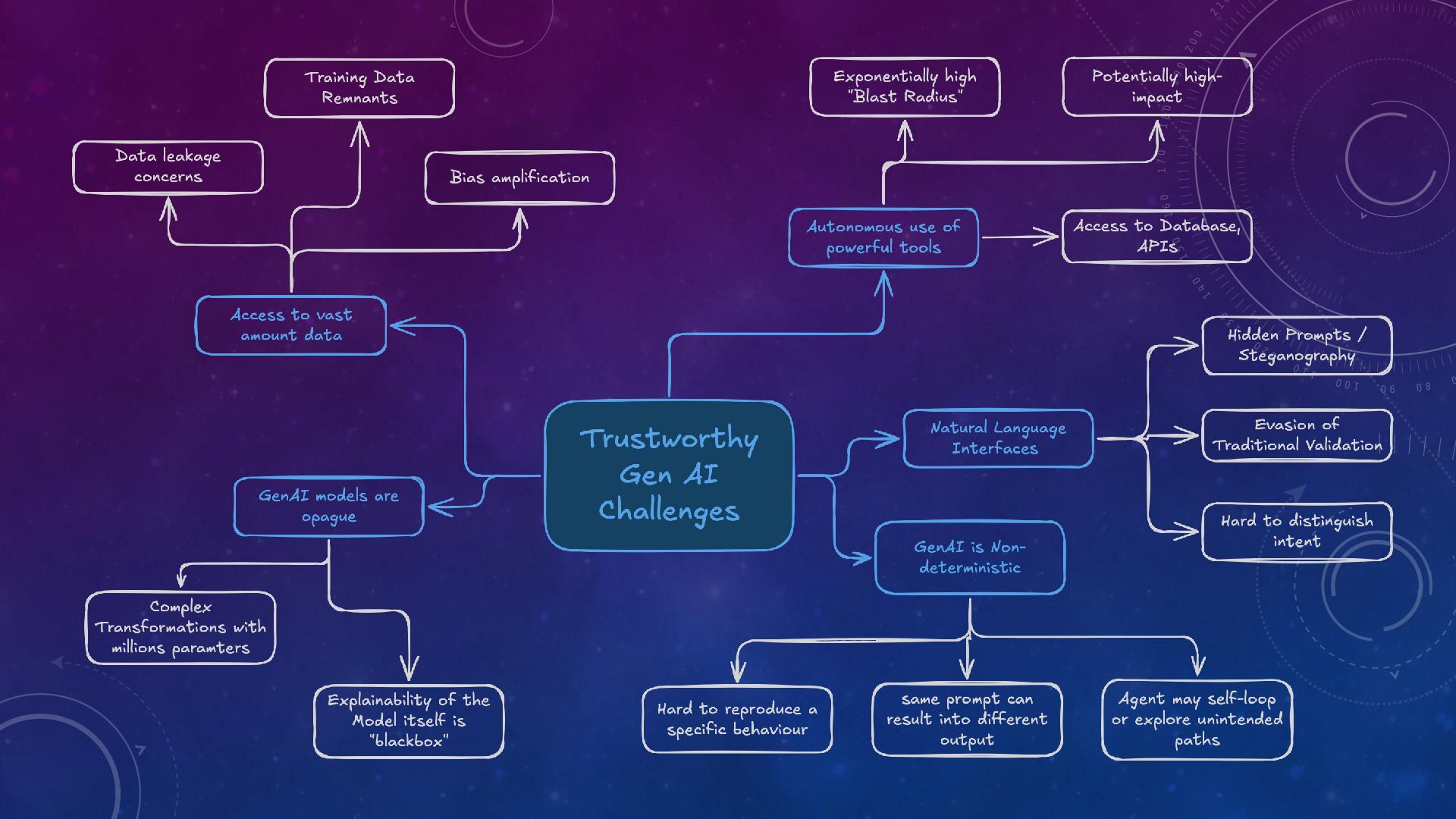
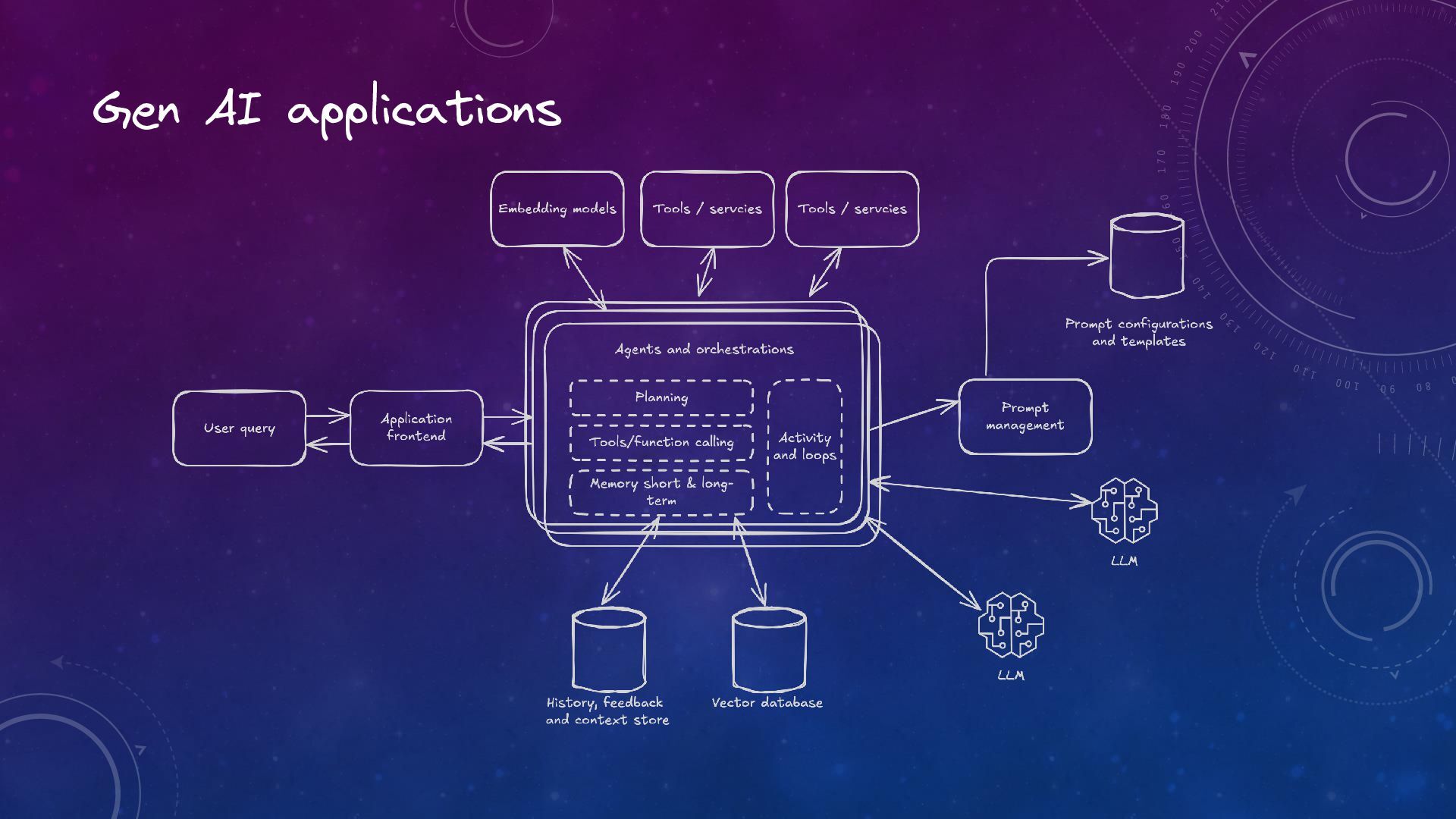
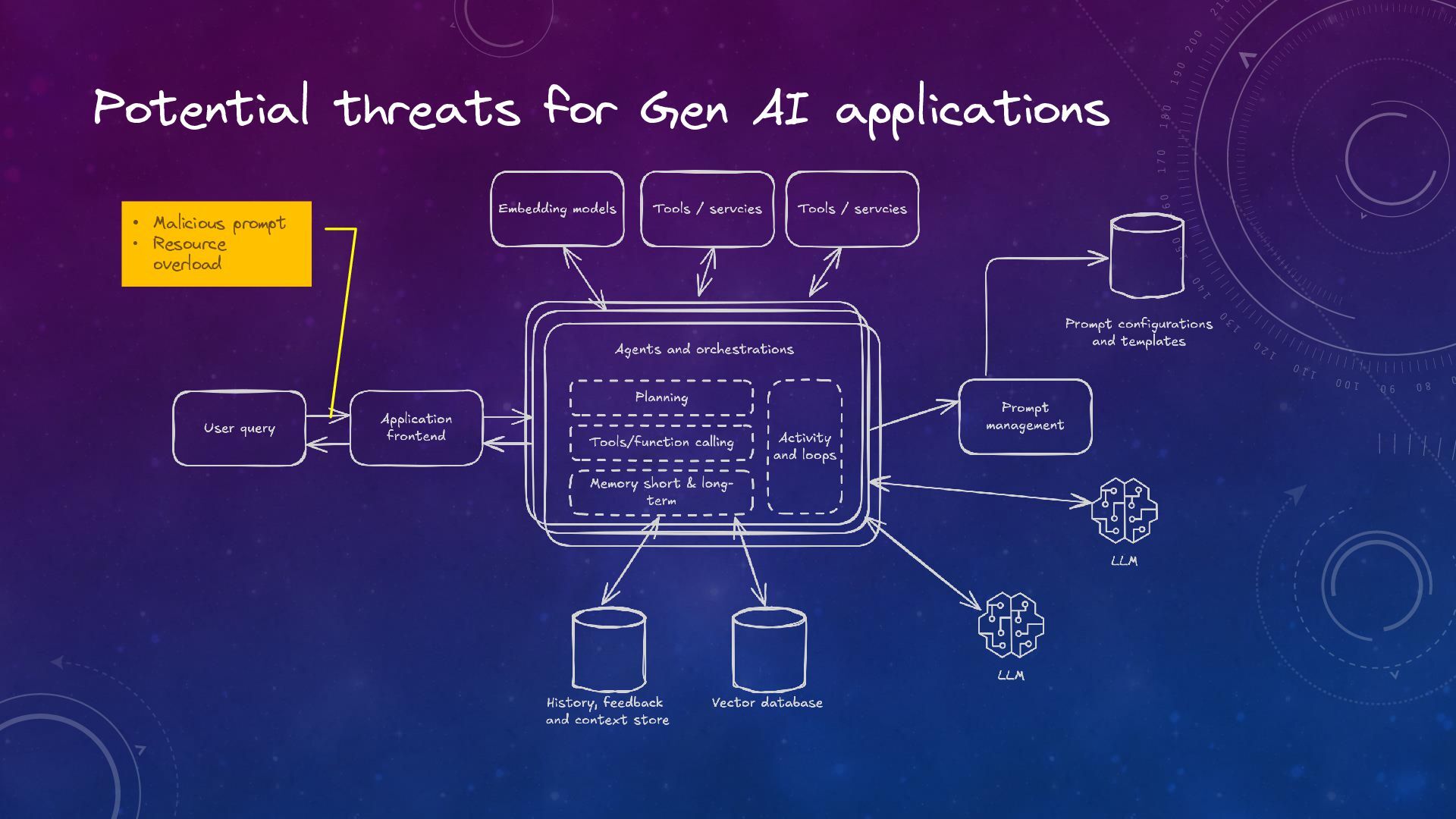
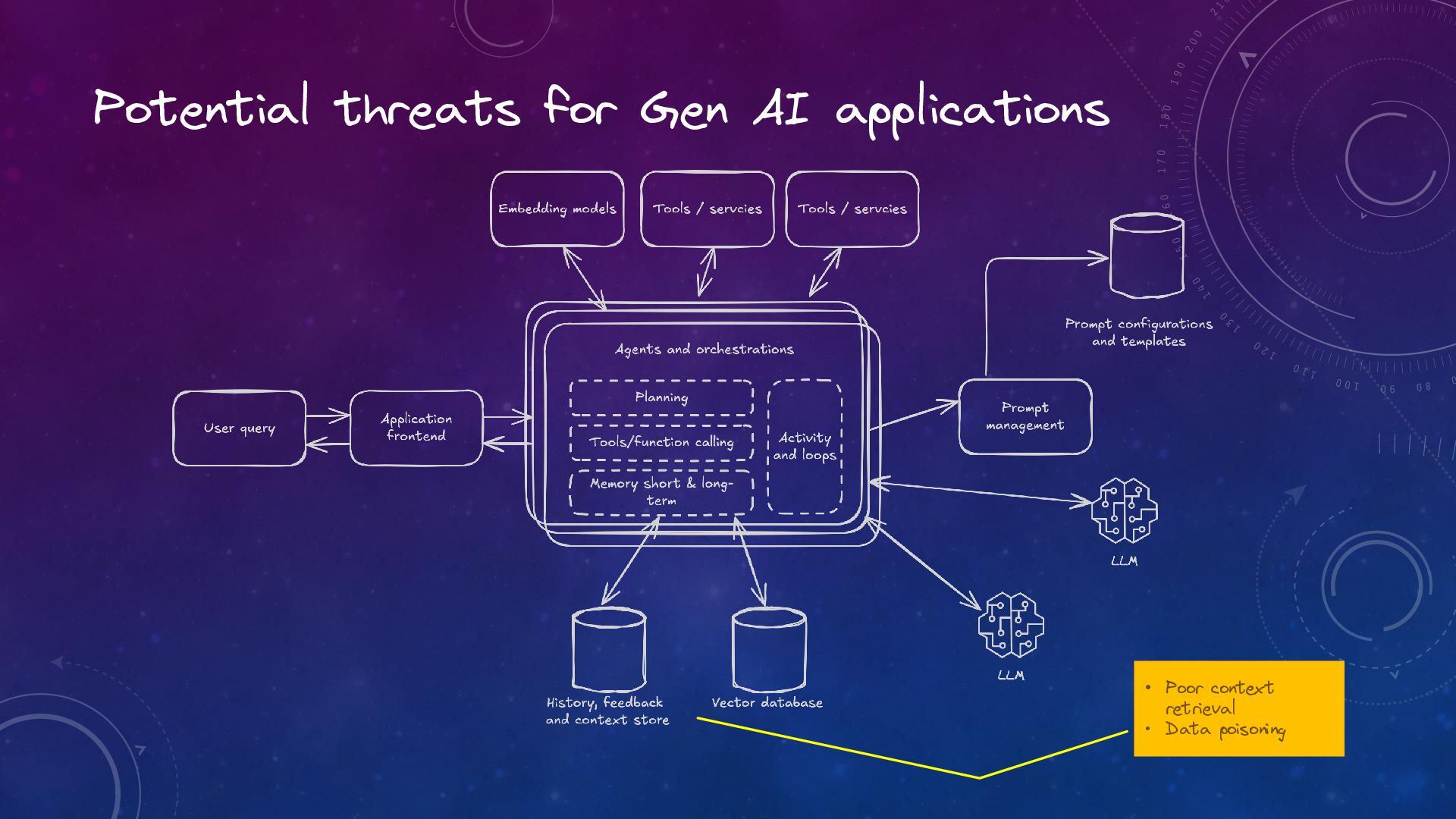
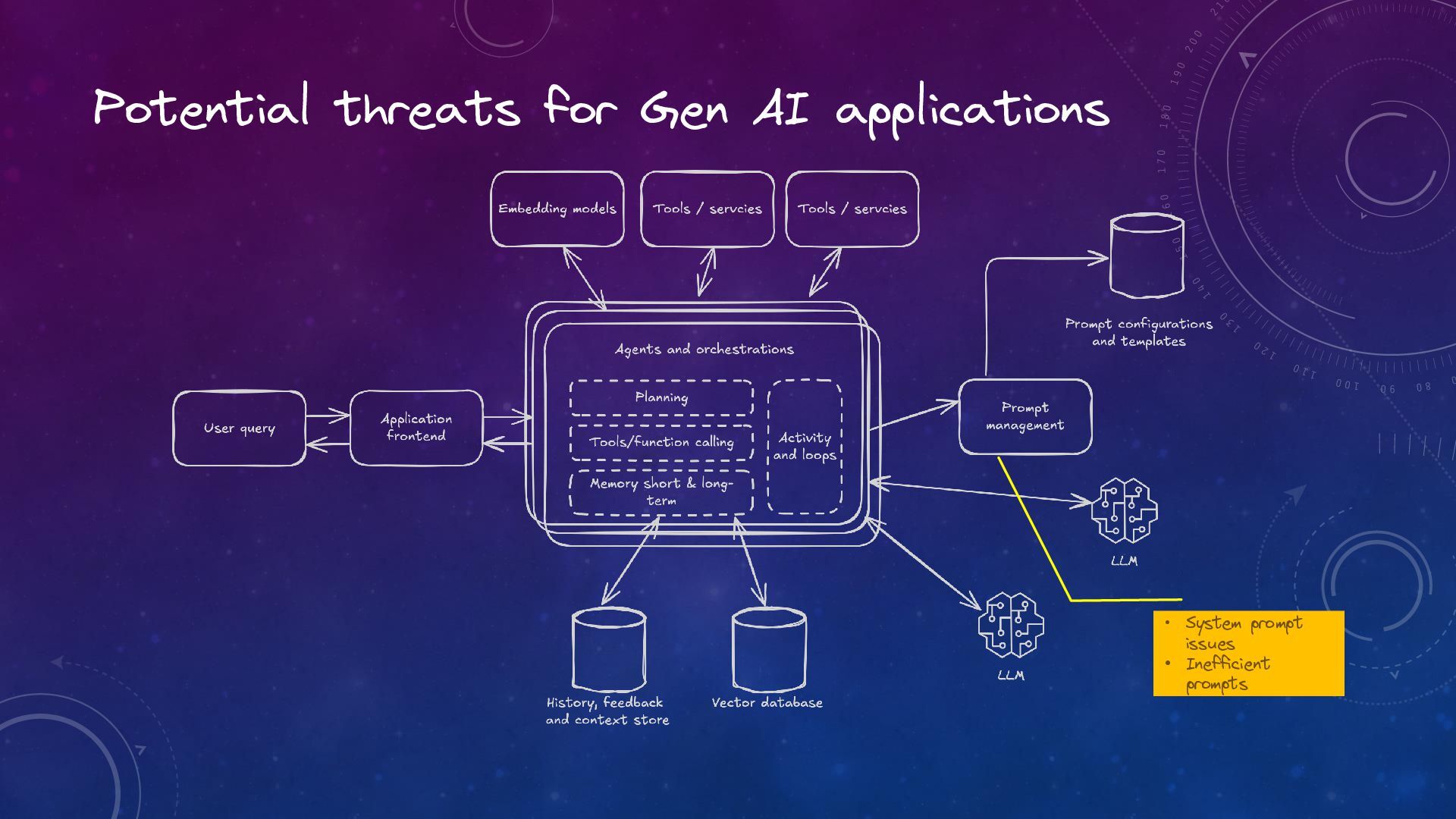
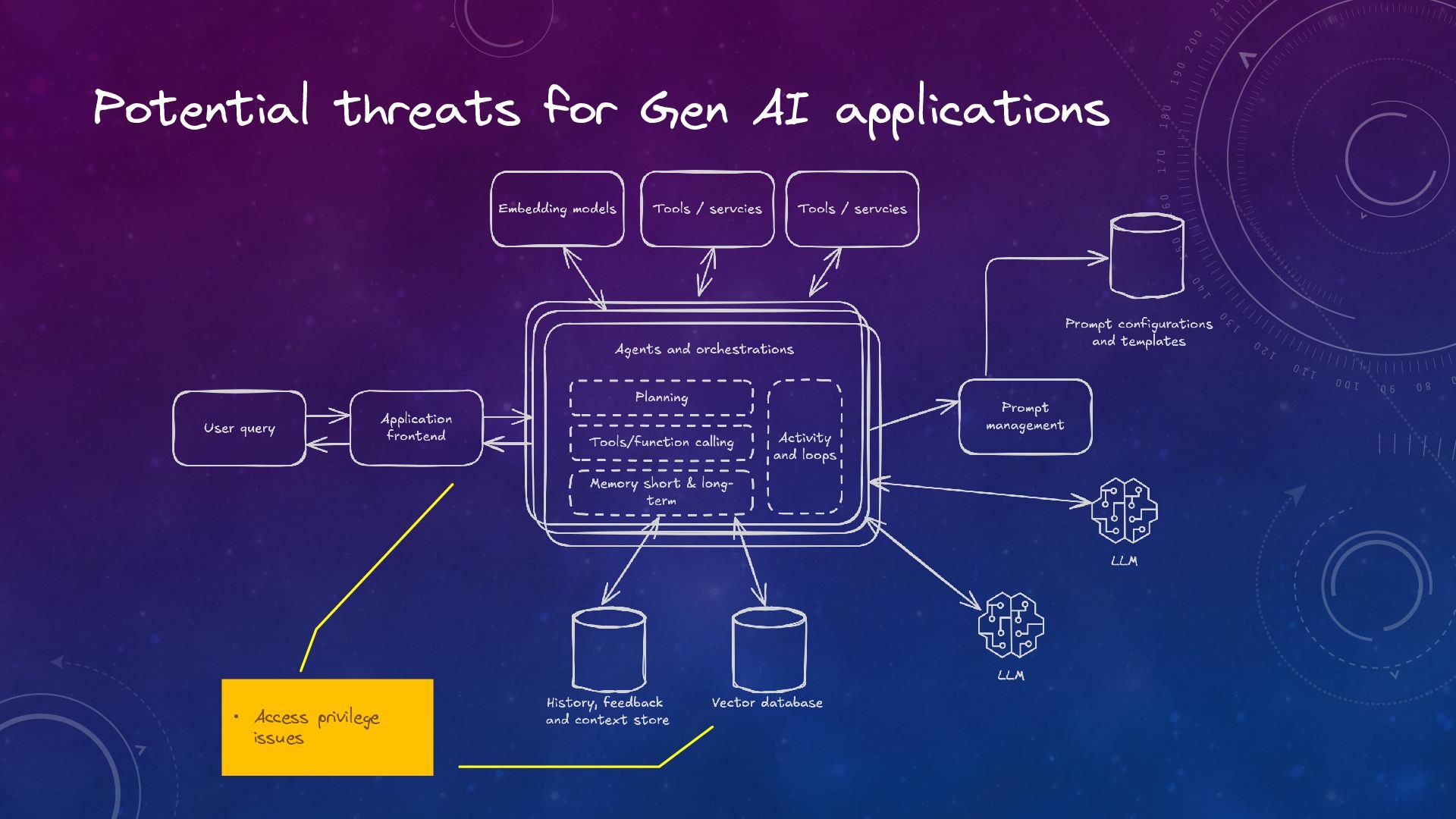
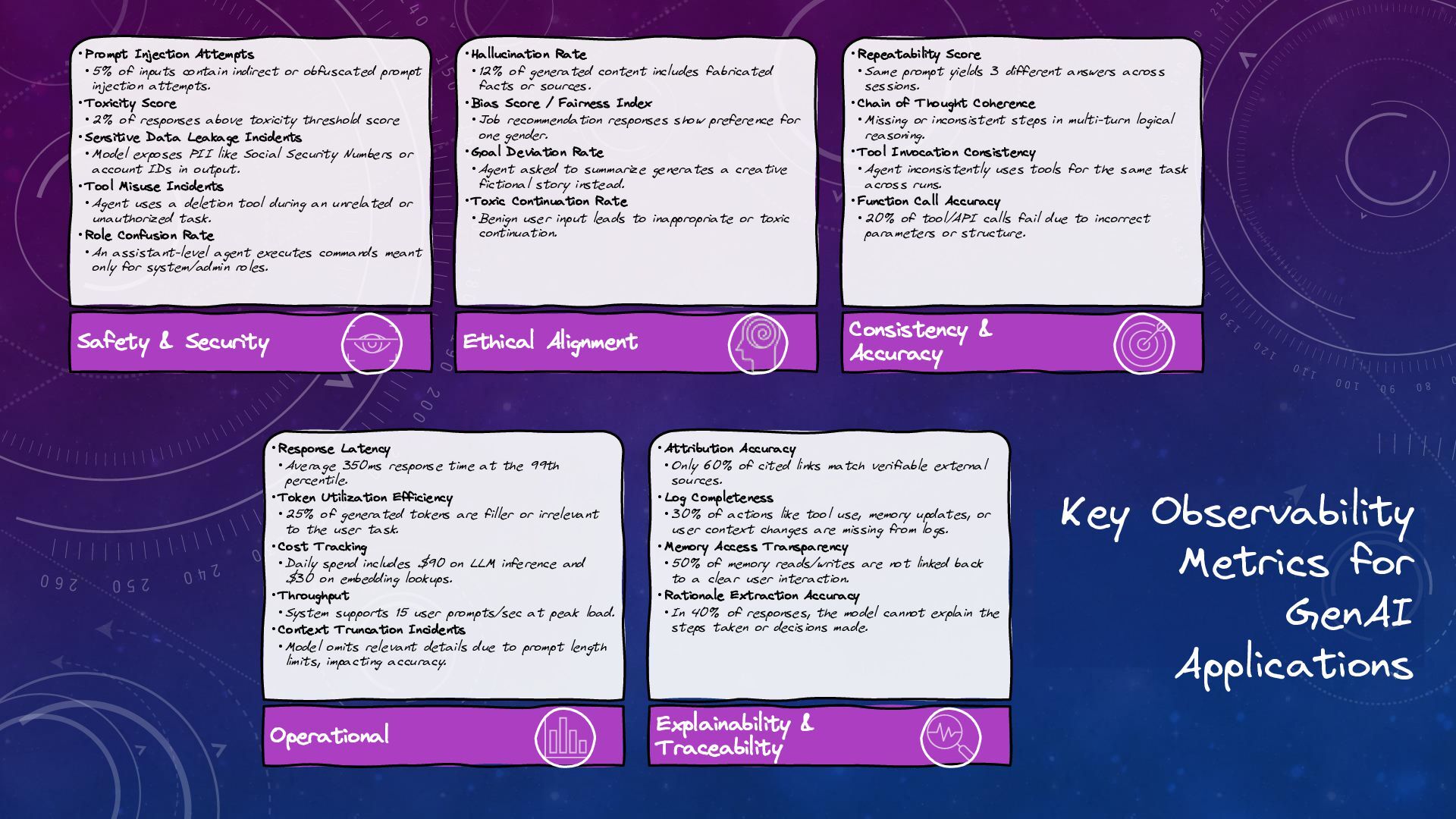
Trustworthy Generative AI: The Role of Observability and Guardrails
Santanu Dey, VP - Emerging Technology at OCBC
apidays Singapore 2025
Where APIs Meet AI: Building Tomorrow's Intelligent Ecosystems
April 15 & 16, 2025
------
Check out our conferences at https://www.apidays.global/
Do you want to sponsor or talk at one of our conferences?
https://apidays.typeform.com/to/ILJeAaV8
Learn more on APIscene, the global media made by the community for the community:
https://www.apiscene.io
Explore the API ecosystem with the API Landscape:
https://apilandscape.apiscene.io/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}