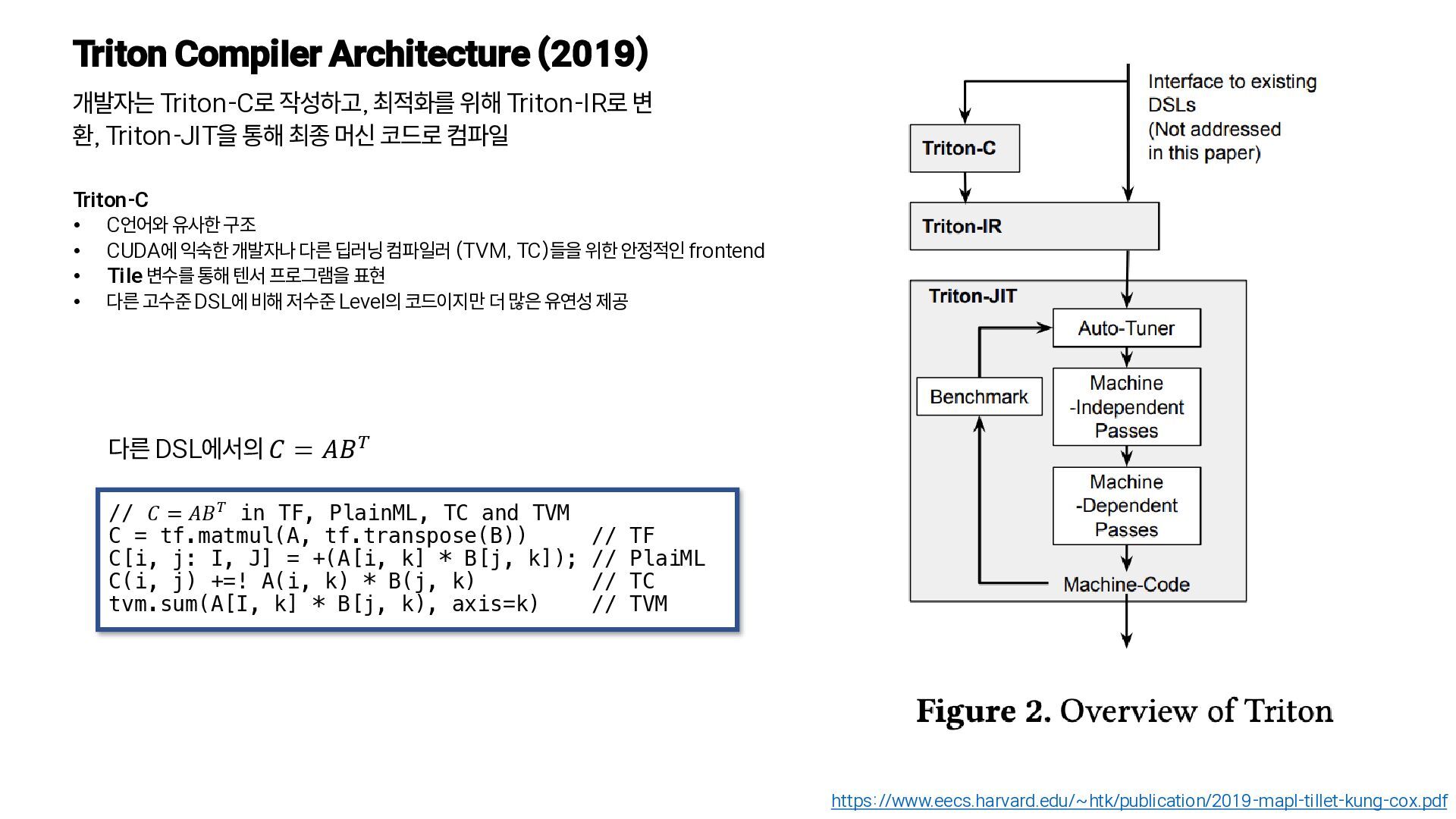
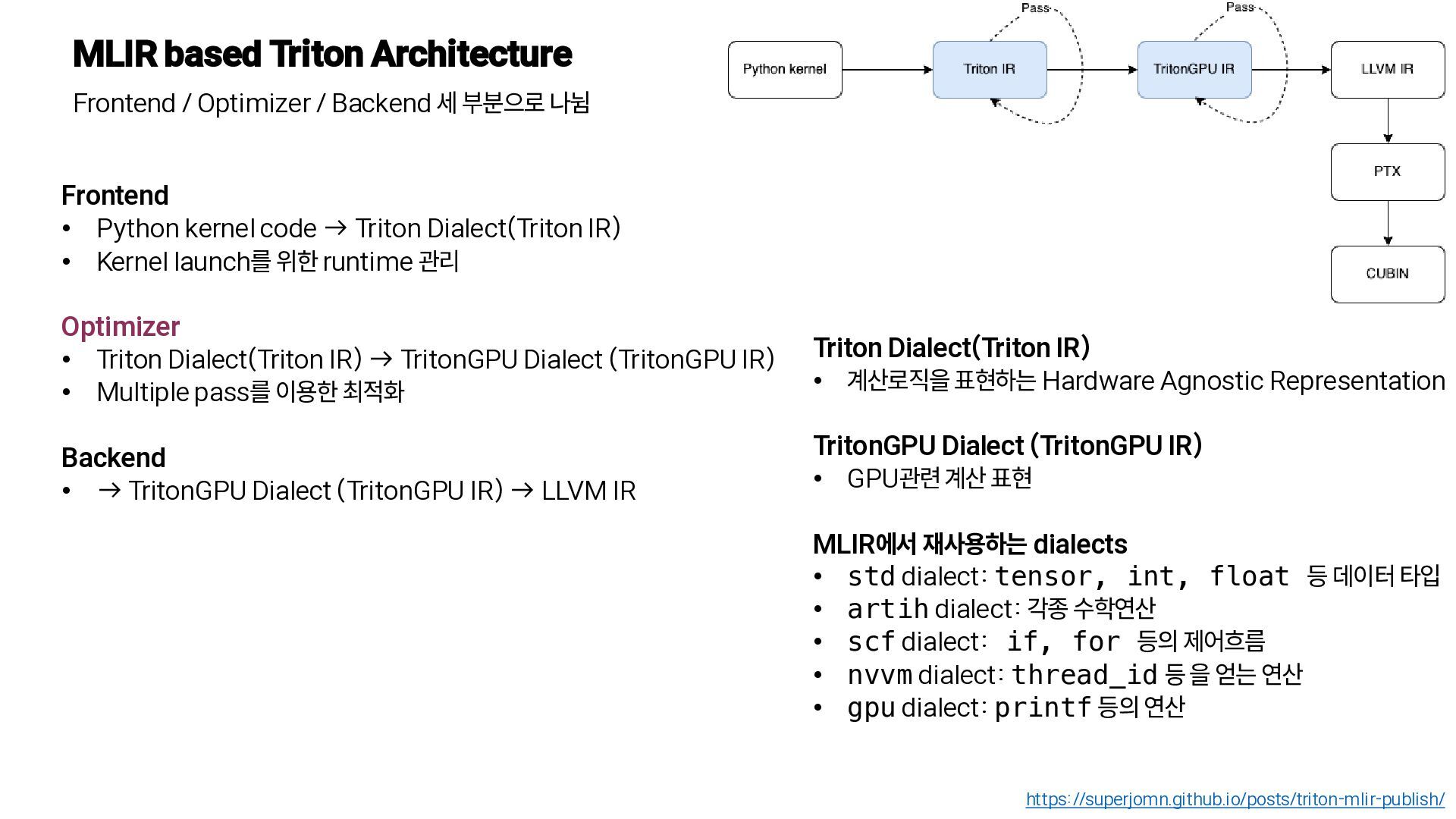
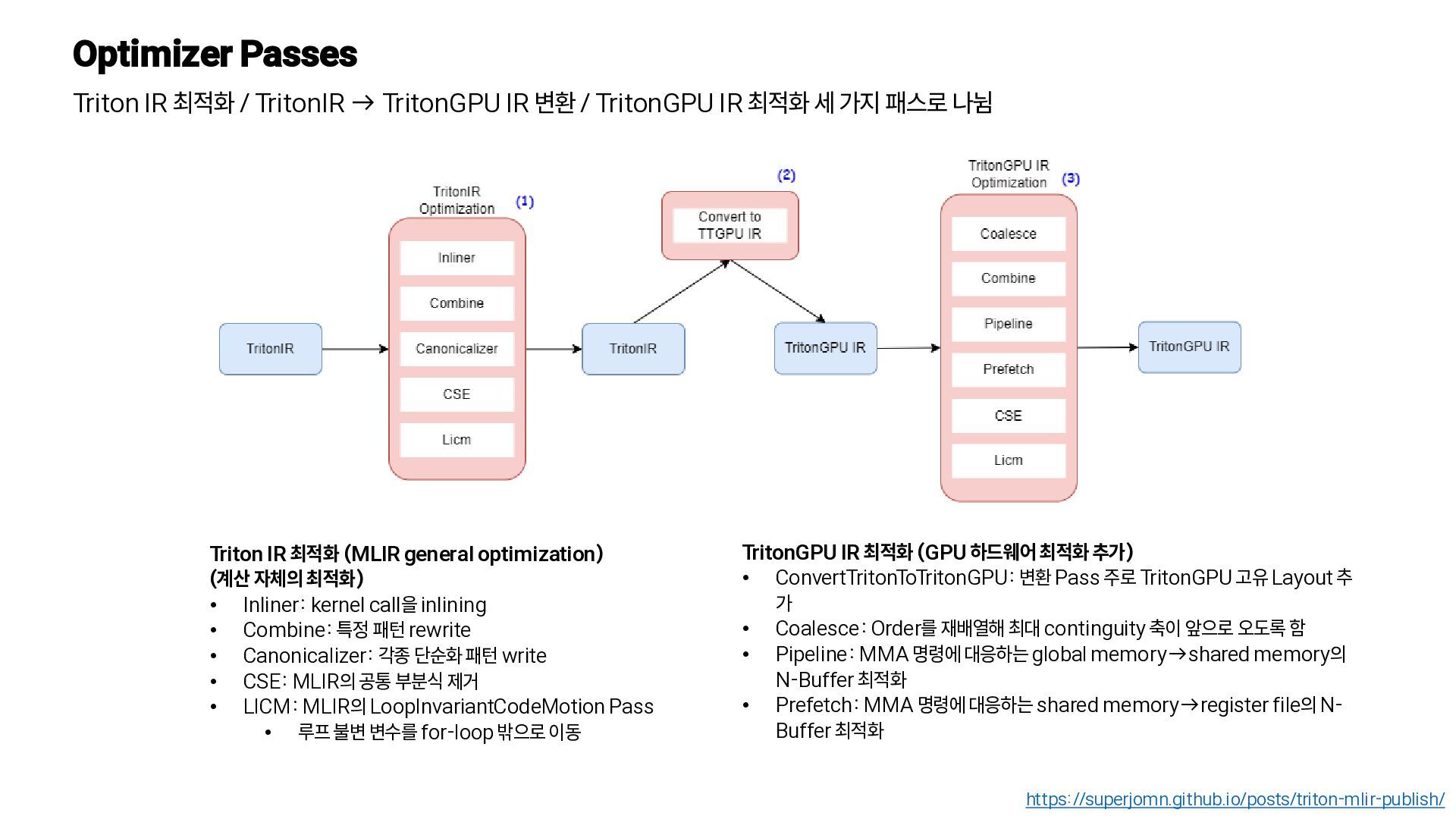
변 환, Triton-JIT을 통해 최종 머신 코드로 컴파일 https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf Triton-C • C언어와 유사한 구조 • CUDA에 익숙한 개발자나 다른 딥러닝 컴파일러 (TVM, TC)들을 위한 안정적 인 frontend • Tile 변수를 통해 텐서 프로그램을 표현 • 다른 고수준 DSL에 비해 저수준 Level의 코드이지만 더 많은 유연성 제공 // Tile shapes are parameteric and // can be optimized by compilation backends const tunable int TM = {16, 32, 64, 128}; const tunable int TN = {16, 32, 64, 128}; const tunable int TK = {8, 16}; // C = A * B.T kernel void matmul_nt(float *a, float *b, float *c, int M, int N, int K) { // 1D tile of indicies int rm[TM] = get_global_range(0); int rn[TN] = get_global_range(1); int rk[TK] = 0 ... TK; // 2D tile of accumulators float C[TM, TN] = 0; // 2D tile of pointers float *pa[TM, TK] = a + rm[:, newaxis] * K + rk[newaxis, :]; float *pb[TN, TK] = b + rn[:, newaxis] * K + rk[newaxis, :]; for (int k = K; k > 0; k = k - TK) { bool check_k[TK] = rk < k; bool check_a[TM, TK] = (rm < M)[:, newaxis] && check_k; bool check_b[TN, TK] = (rn < N)[:, newaxis] && check_k; // Load tile operands float A[TM, TK] = @check_a ? *pa : 0; float B[TN, TK] = @check_b ? *pb : 0; // accumulate C += dot(A, trans(B)); // Update pointers pa = pa + TK; pb = pb + TK; } // Write-back accumulators float *pc[TM, TN] = c + rm[:, newaxis] * N + rn[newaxis, :]; bool check_c[TM, TN] = (rm < M)[:, newaxis] && (rn < N)[newaxis, :]; @check_c *pc = C; } • 타일 크기의 정의: TM, TN, TK로 파라미터화되어 컴파일러가 최적화 • 작업 범위 설정: get_global_range를 통해 커널이 행렬의 어느 부분을 계산할지 결정 (1D tile of indices) • 결과 타일 초기화 (2D tile of accumulators) • 포인터 준비 (2D tile of pointers) • 반복 계산 (루프) • A, B로부터 타일조각을 SRAM으로 로드 • dot(A, trans(B))를 통해 행렬 곱셈을 수행하고 C에 더함 • 포인터 이동 • 계산이 완료된 C 타일을 다시 메모리에 write-back Triton에서의 𝐶 = 𝐴𝐵𝑇
{kind=link}
{kind=link}
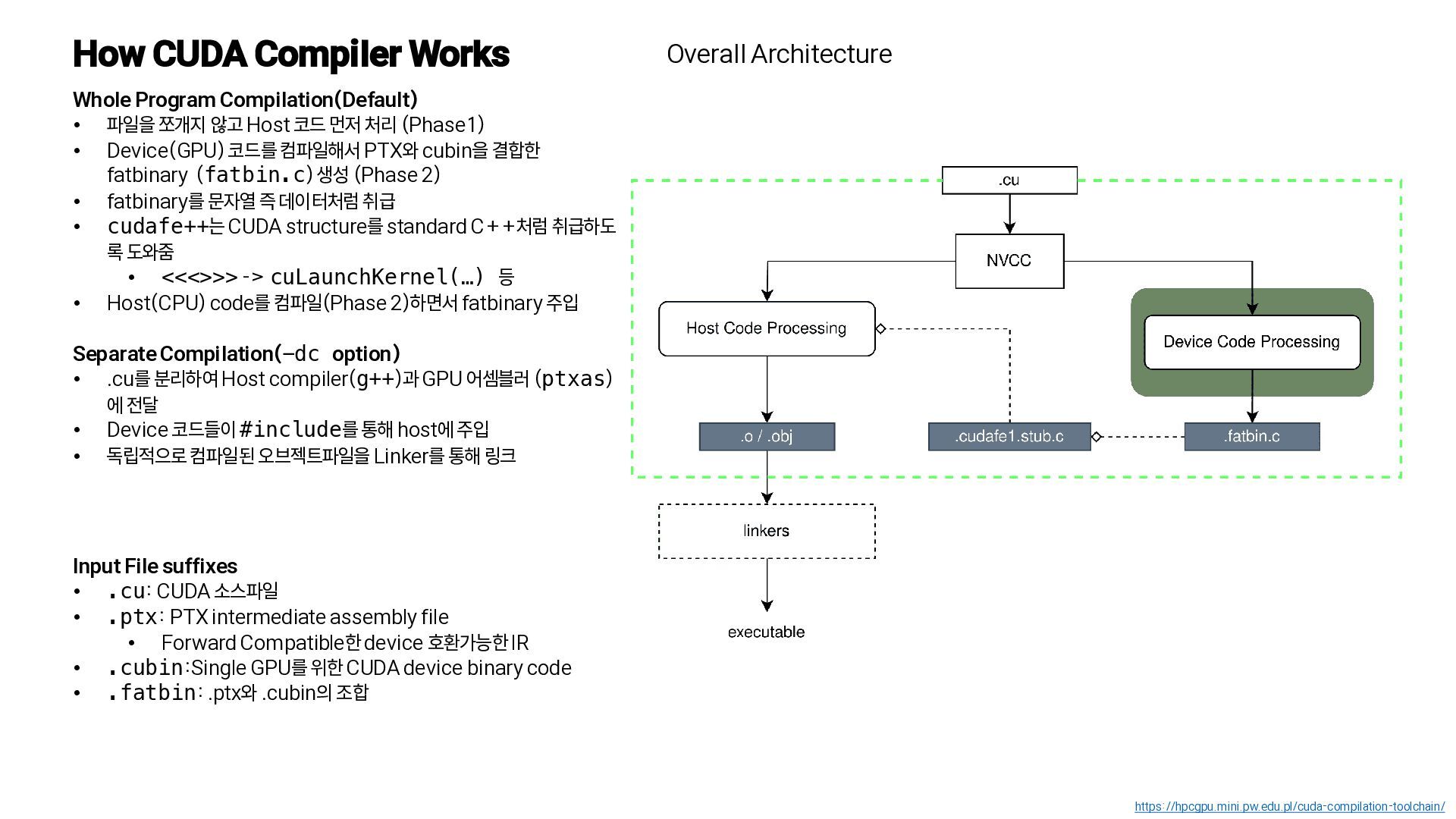{kind=link}
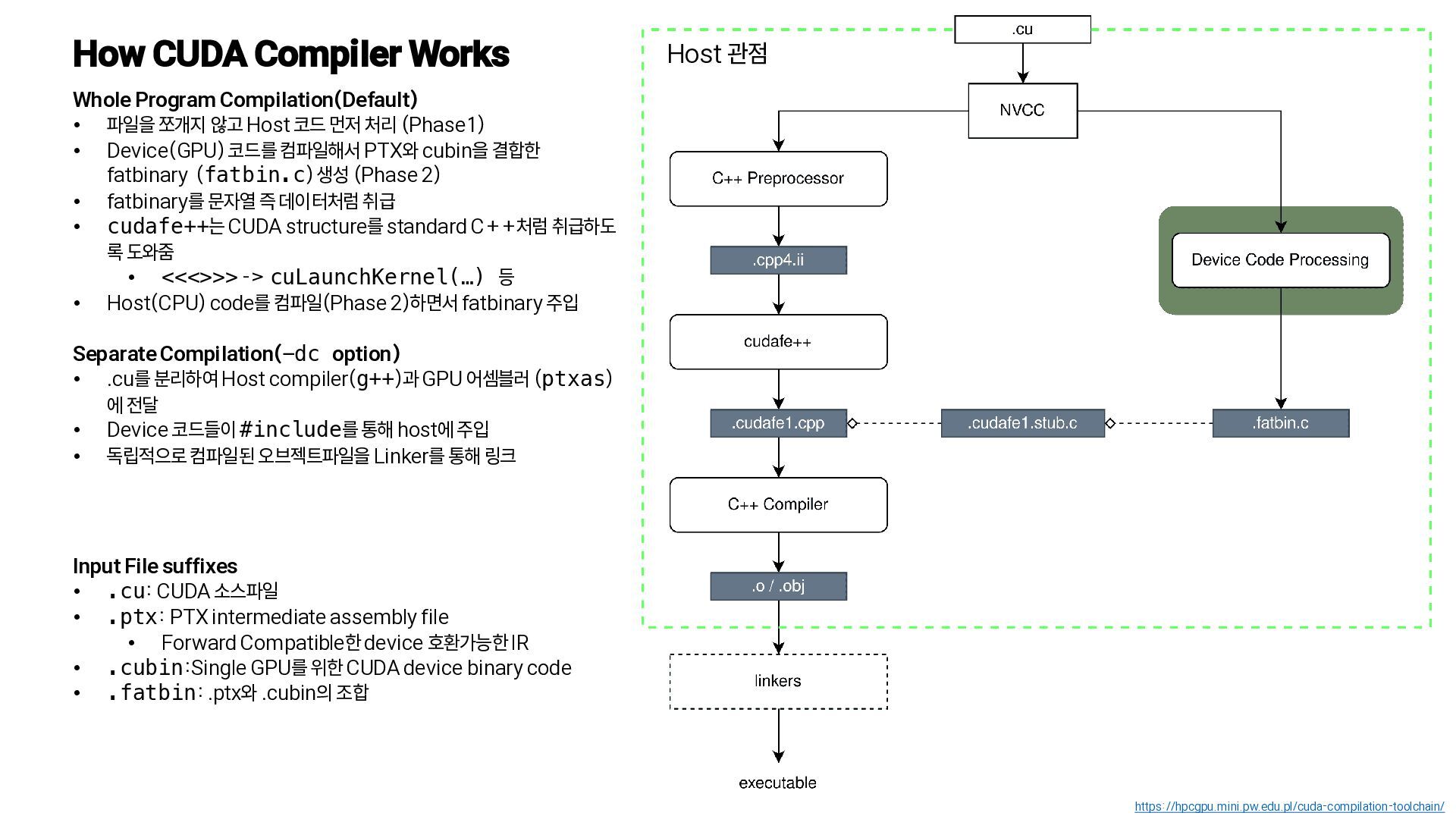{kind=link}
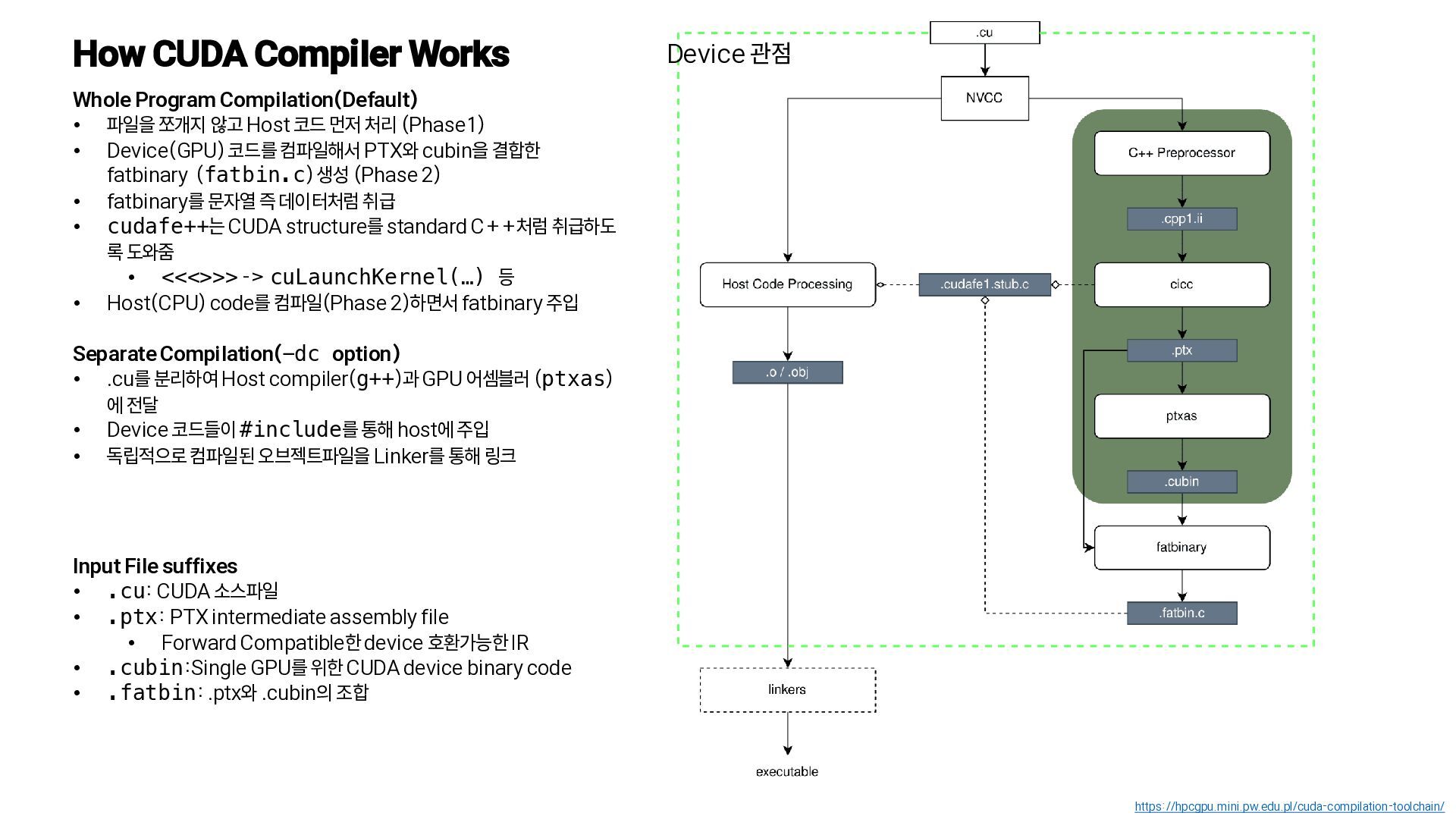{kind=link}
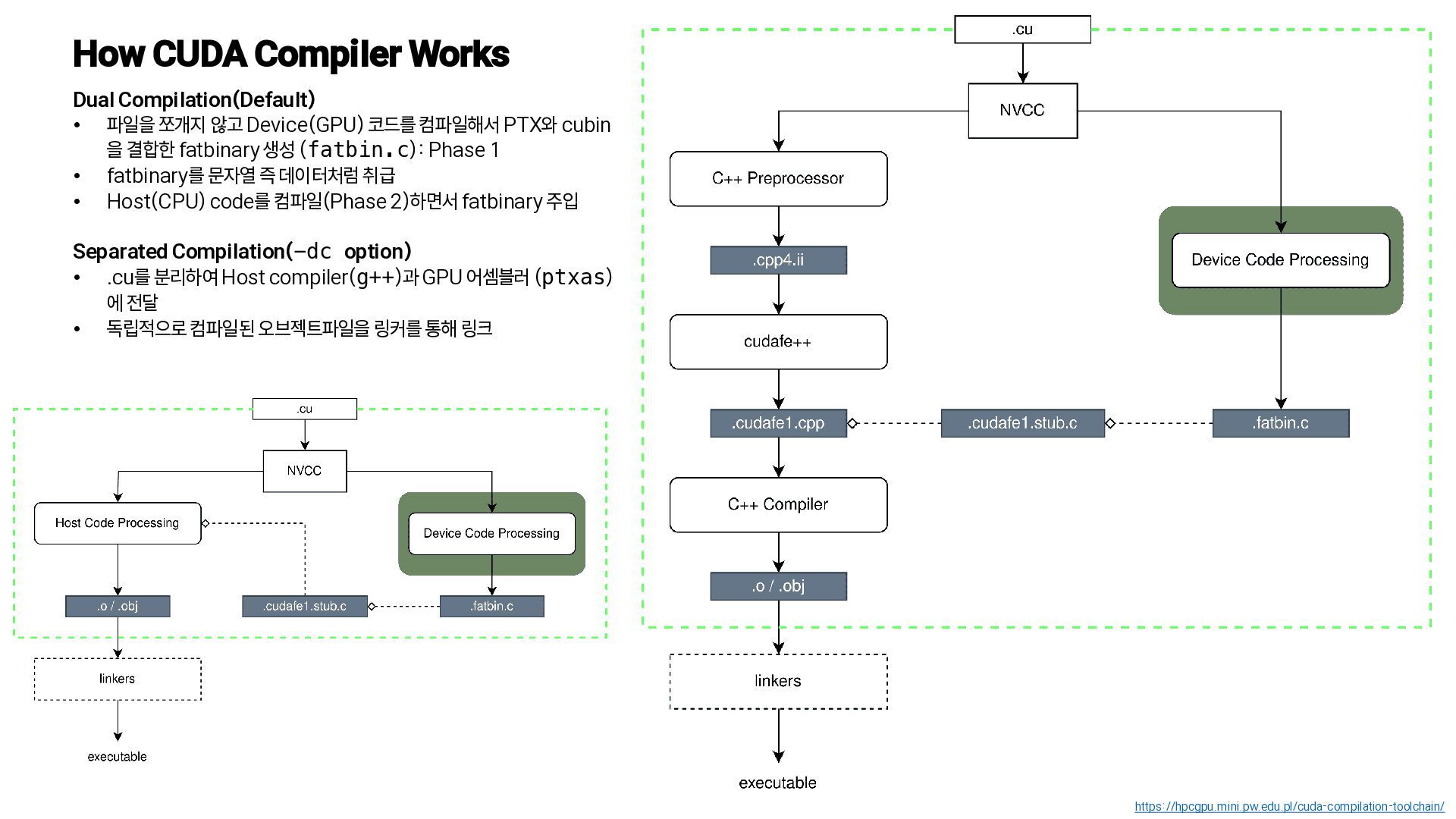{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}