based protocol TCMP • In-order guaranteed delivery between members • NACKs for low latency communications • Can work over UDP, TCP, SSL (+ Oracle ExoBus) • Limited use of multicast (deprecated) Cluster housekeeping protocol • TCP Ring – fast way to detect killed processes • Witness protocol for disconnecting members • Communication pausing
remote service have one connection at time Single TCP is shared between all service users Number of connection can be increase used multiple services • Request pass-through if Extend connection and cluster are using same serialization
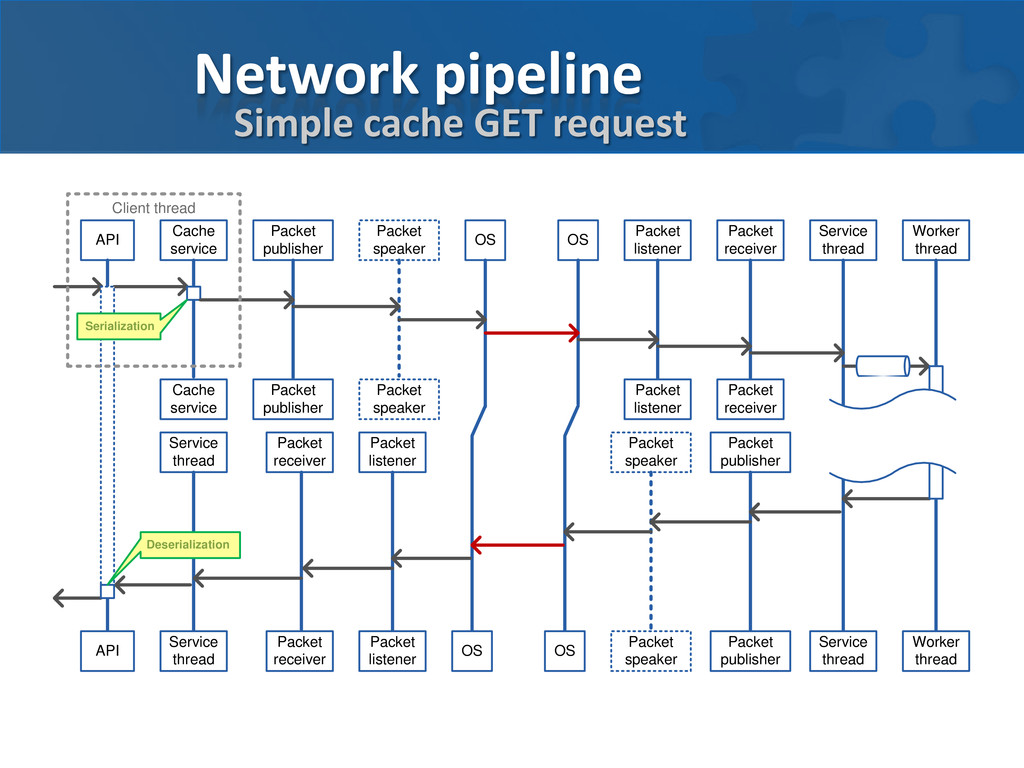
better Starving on CPU – more context switches • Network IO is effectively single threaded Multiple nodes per server may be required to utilize network • Each service has single control thread
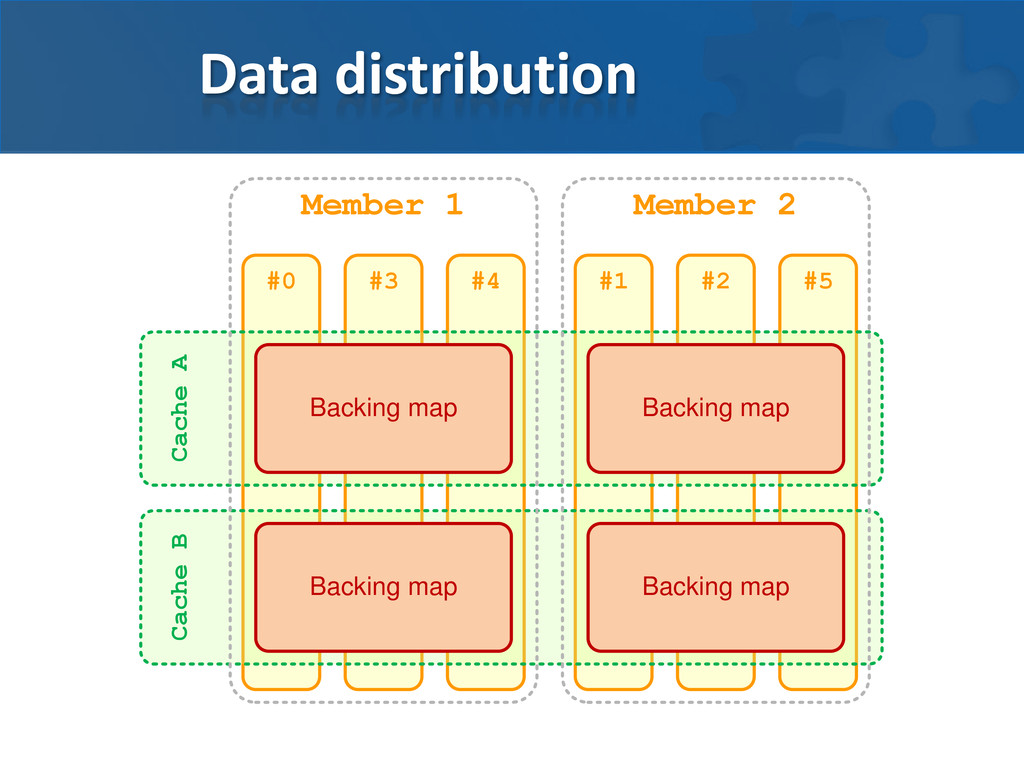
caches in same service • can be exploited for collocating data in caches Balancing by partition count Single backing map per cache • per node (default) • per partition (can be configured) Partition backup is stored in separate backing map
receive network messages • perform cache operations in no thread pool configured Thread pool – optional, size is configured • desterilize data in request (if needed) • perform operation (aggregators, processor, backing map access) • serialize result data (if needed) Event thread – one per service • call map listeners
• Reads including aggregators – lock free • “read dirty” – cross operation visibility • Updates are atomic per job • Jobs – (only if thread pool enabled) Key set based request are split – job per partition Filter based request – one multiple partition job Calculate key set, lock partitions, execute job
• Dispatching of large request may block control thread, making service unresponsive • No discrimination between tasks Few long running task may saturate thread pool, making cache unresponsive • Limited scheduling priorities • Key based requests are producing more jobs, occupying more threads Single large getAll() request for DB backed cache may saturate all thread pools on all nodes for considerable time
by events • events received by thread, execution write operation, added to transaction change set (change sets are replicated atomically) • events received out of bound, replicated asynchronously • backup partition copy is passive
network latency Too bulky operations • blocking control thread for long • Saturation thread pools Solutions • Grouping operations in limited size batches • Grouping operations per member • Grouping operations per partitions
on storage nodes is limited resources • grid-side processing may require more total serialization efforts Solution, account all factors choosing • As is data retrieval requires no marshaling on grid side • Network bandwidth is rarely a limitation • Grid nodes CPUs are shared and limited resource
![Oracle Coherence Architecture key notes Alexey Ragozin [email protected] May 2012](https://files.speakerdeck.com/presentations/503f46582d2b070002042bfc/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Alexey Ragozin [email protected] http://blog.ragozin.info - my articles http://code.google.com/p/gridkit](https://files.speakerdeck.com/presentations/503f46582d2b070002042bfc/slide_16.jpg){kind=link}