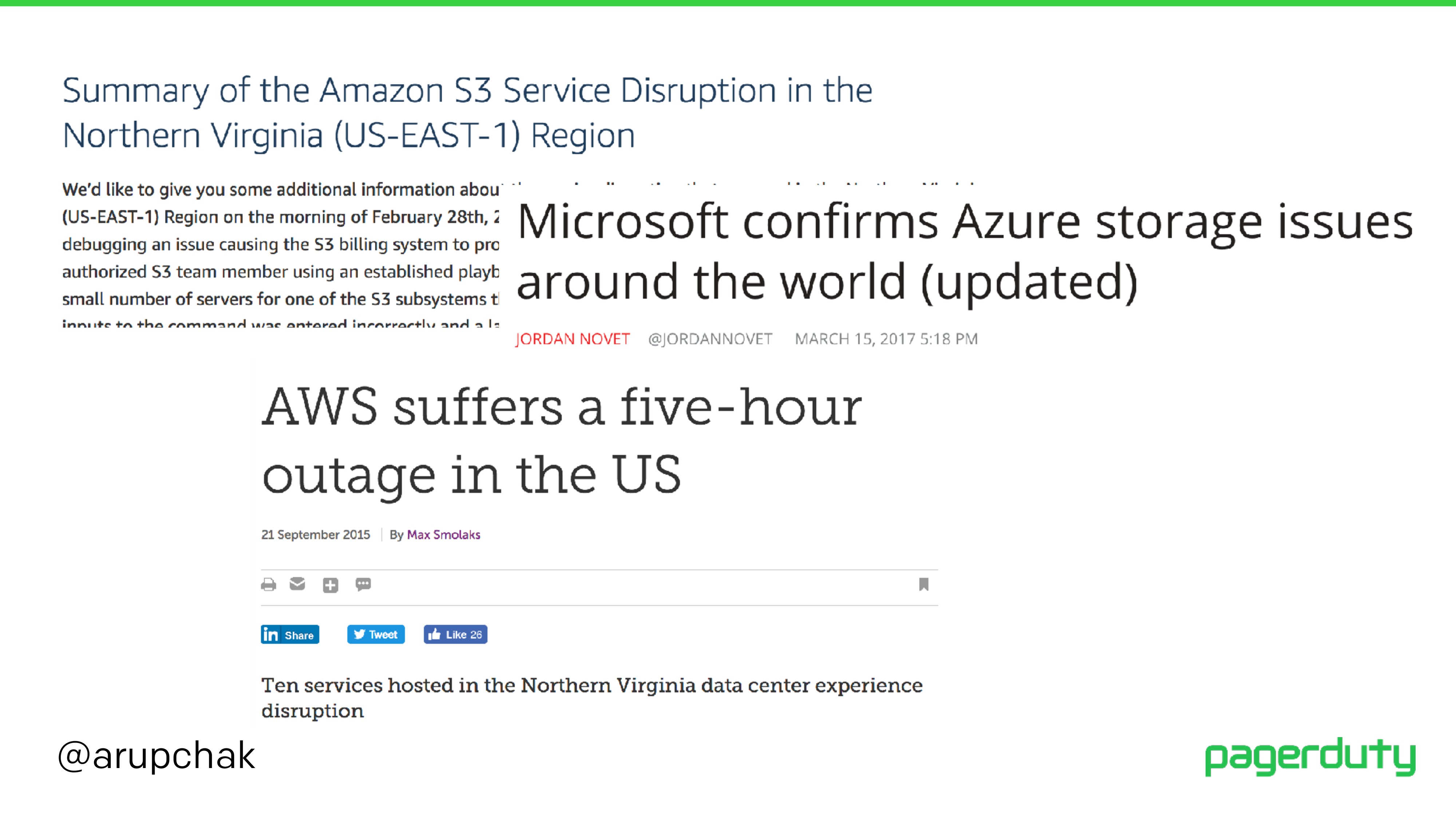
PagerDuty has been running a multi-cloud infrastructure over the past 5 years. In that time, we have tested multiple providers, learned about fun networking routes, saw what traffic filtering looks like, and many other horrors.
In this talk, I will be going over the decisions and events that led up PagerDuty's multi-cloud environment and how we managed it. I will go through the benefits and problems with our setup and the assumptions that we made that turned out to be completely wrong. By the end of this talk, you will be able to better answer the question of whether a multi-cloud setup is the right thing for your team or company.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}