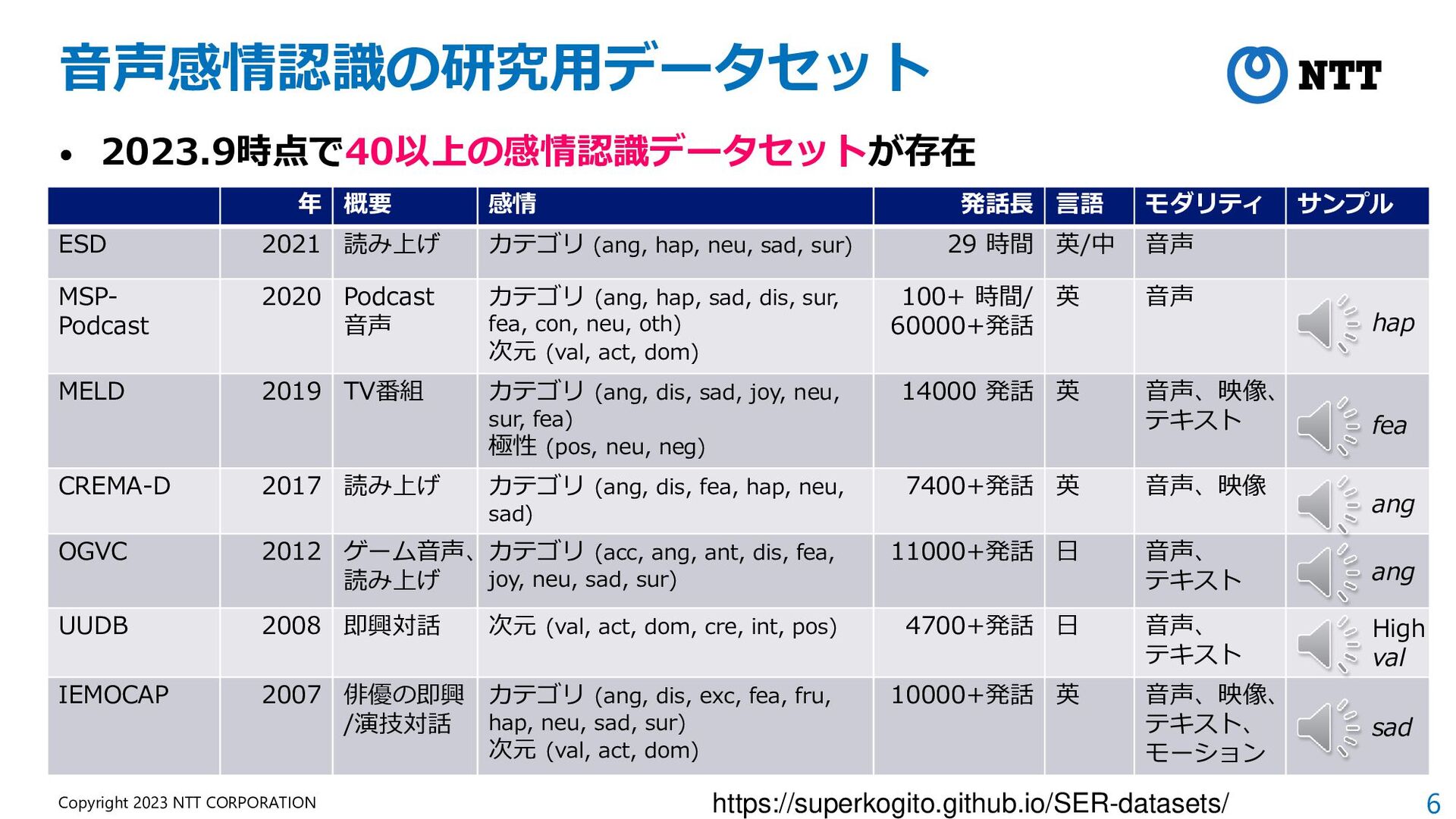
概要 感情 発話長 言語 モダリティ サンプル ESD 2021 読み上げ カテゴリ (ang, hap, neu, sad, sur) 29 時間 英/中 音声 MSP- Podcast 2020 Podcast 音声 カテゴリ (ang, hap, sad, dis, sur, fea, con, neu, oth) 次元 (val, act, dom) 100+ 時間/ 60000+発話 英 音声 MELD 2019 TV番組 カテゴリ (ang, dis, sad, joy, neu, sur, fea) 極性 (pos, neu, neg) 14000 発話 英 音声、映像、 テキスト CREMA-D 2017 読み上げ カテゴリ (ang, dis, fea, hap, neu, sad) 7400+発話 英 音声、映像 OGVC 2012 ゲーム音声、 読み上げ カテゴリ (acc, ang, ant, dis, fea, joy, neu, sad, sur) 11000+発話 日 音声、 テキスト UUDB 2008 即興対話 次元 (val, act, dom, cre, int, pos) 4700+発話 日 音声、 テキスト IEMOCAP 2007 俳優の即興 /演技対話 カテゴリ (ang, dis, exc, fea, fru, hap, neu, sad, sur) 次元 (val, act, dom) 10000+発話 英 音声、映像、 テキスト、 モーション hap fea ang sad High val ang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
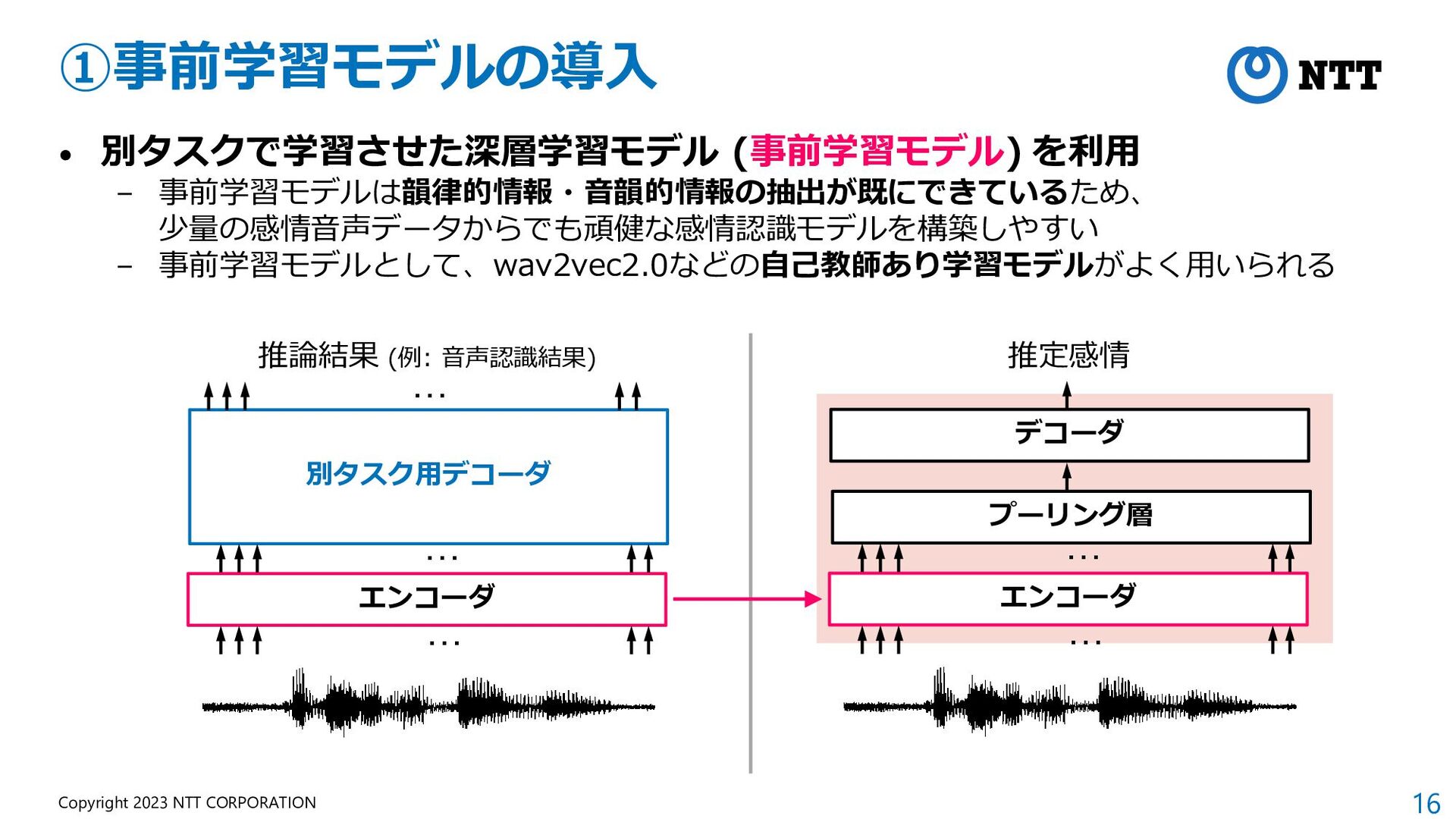{kind=link}
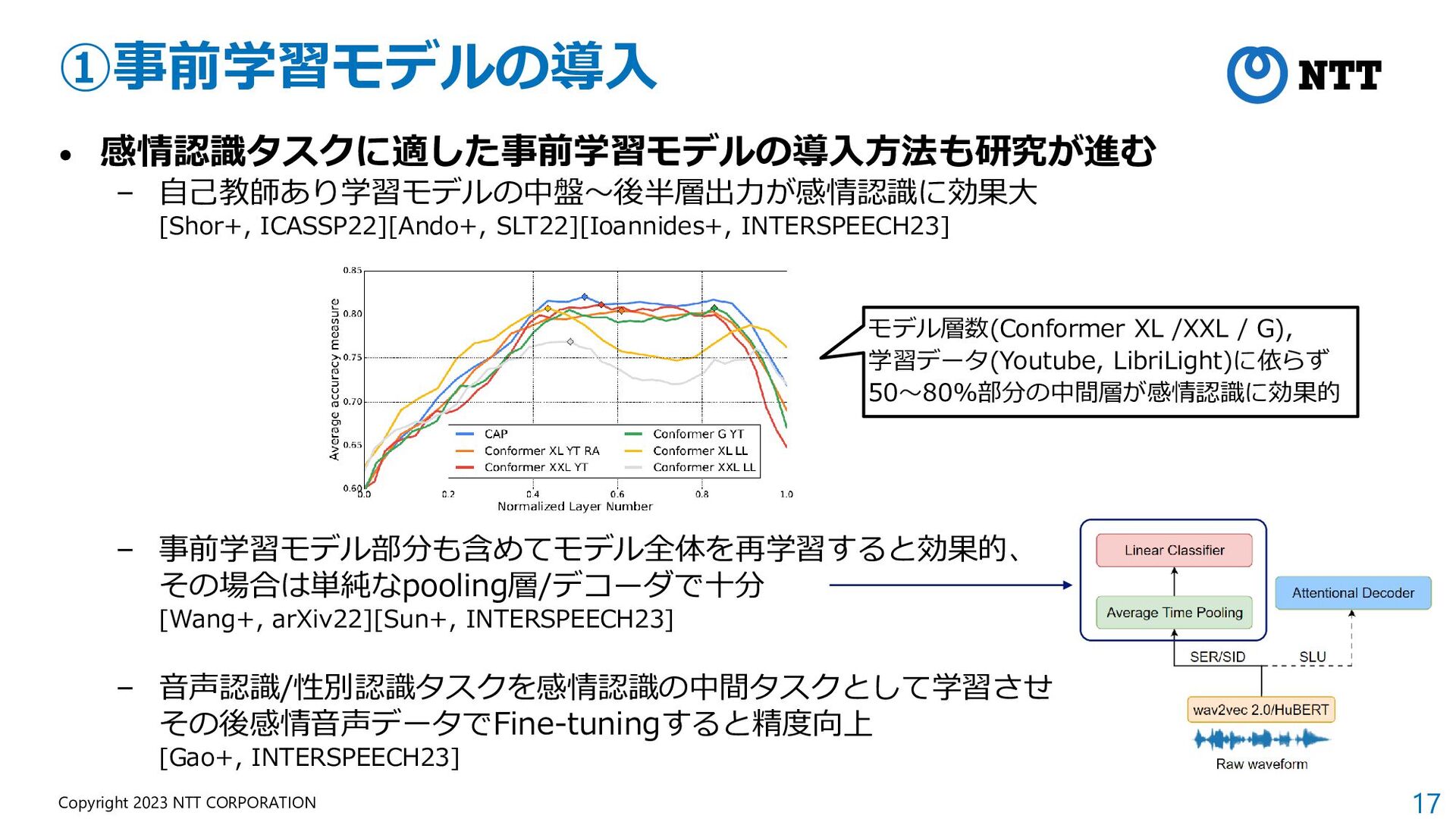{kind=link}
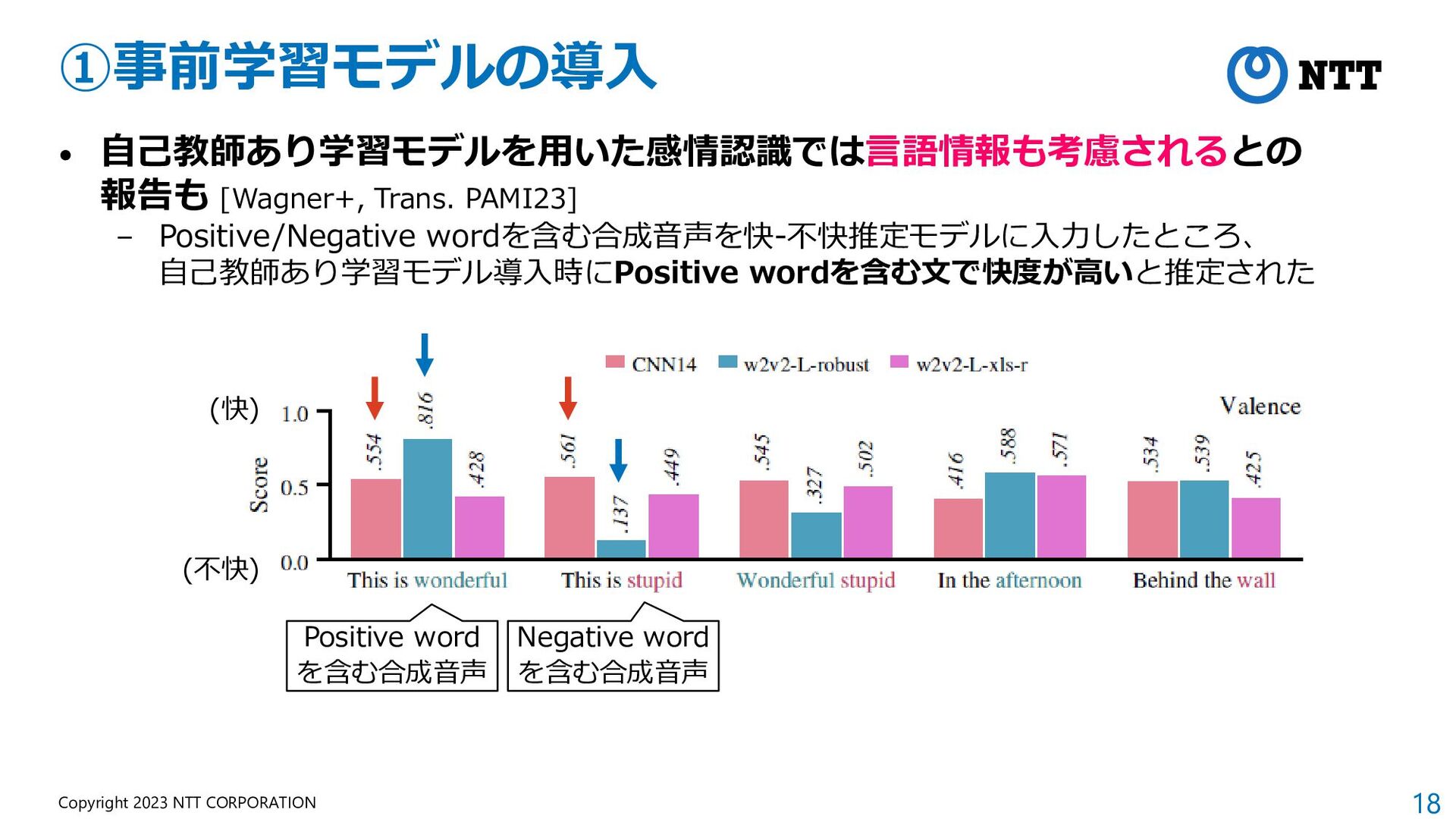{kind=link}
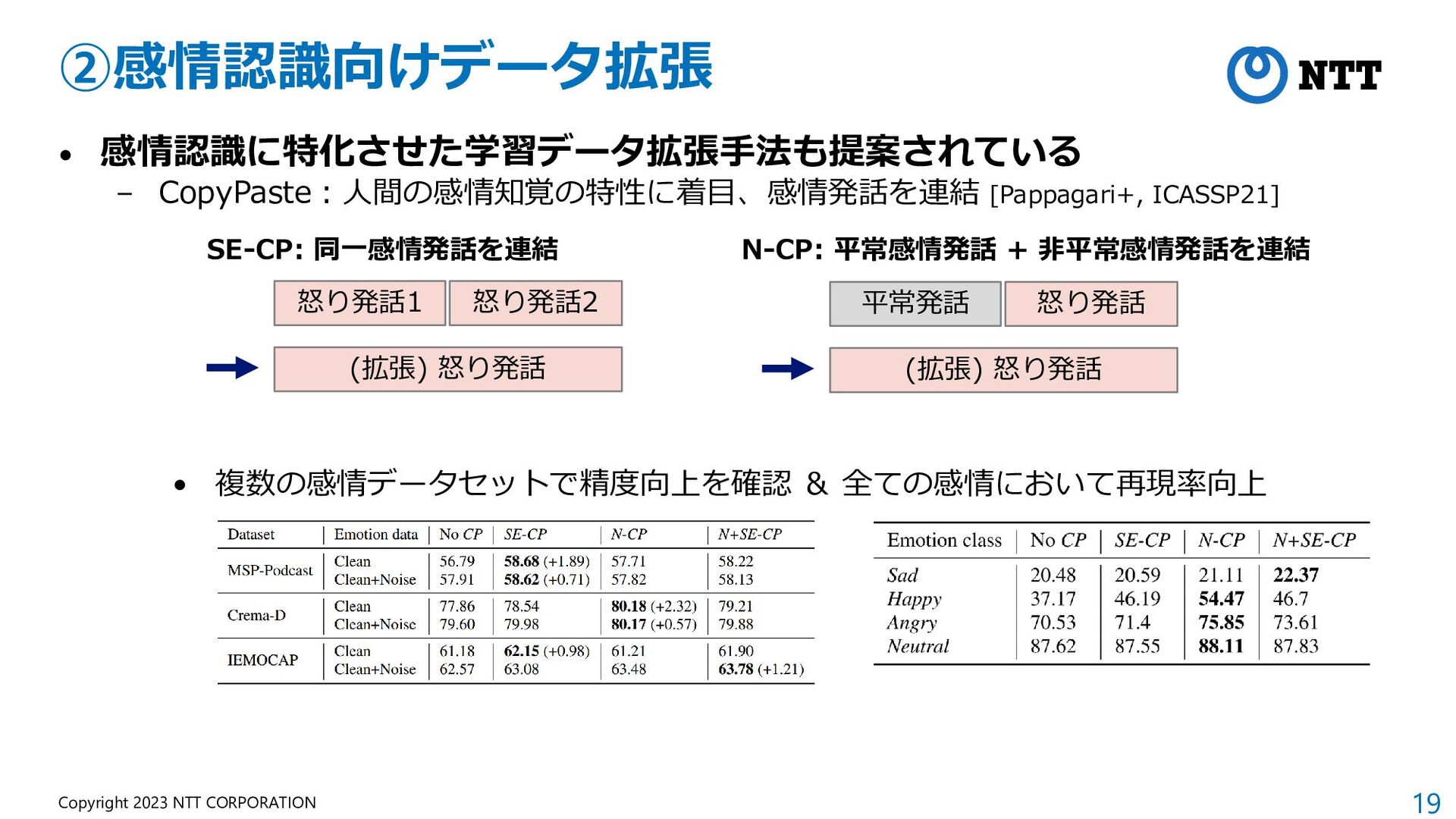{kind=link}
{kind=link}
{kind=link}
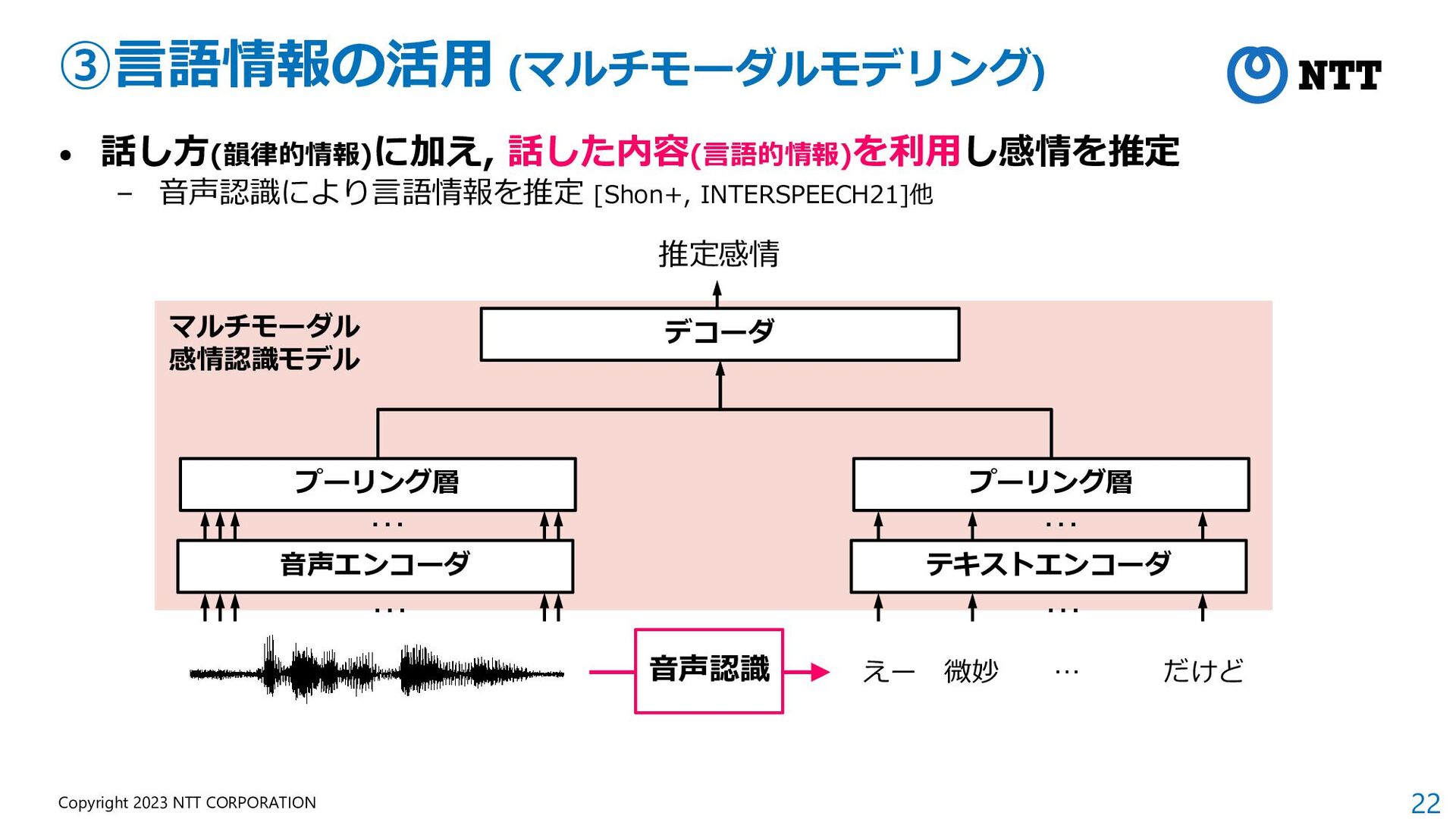{kind=link}
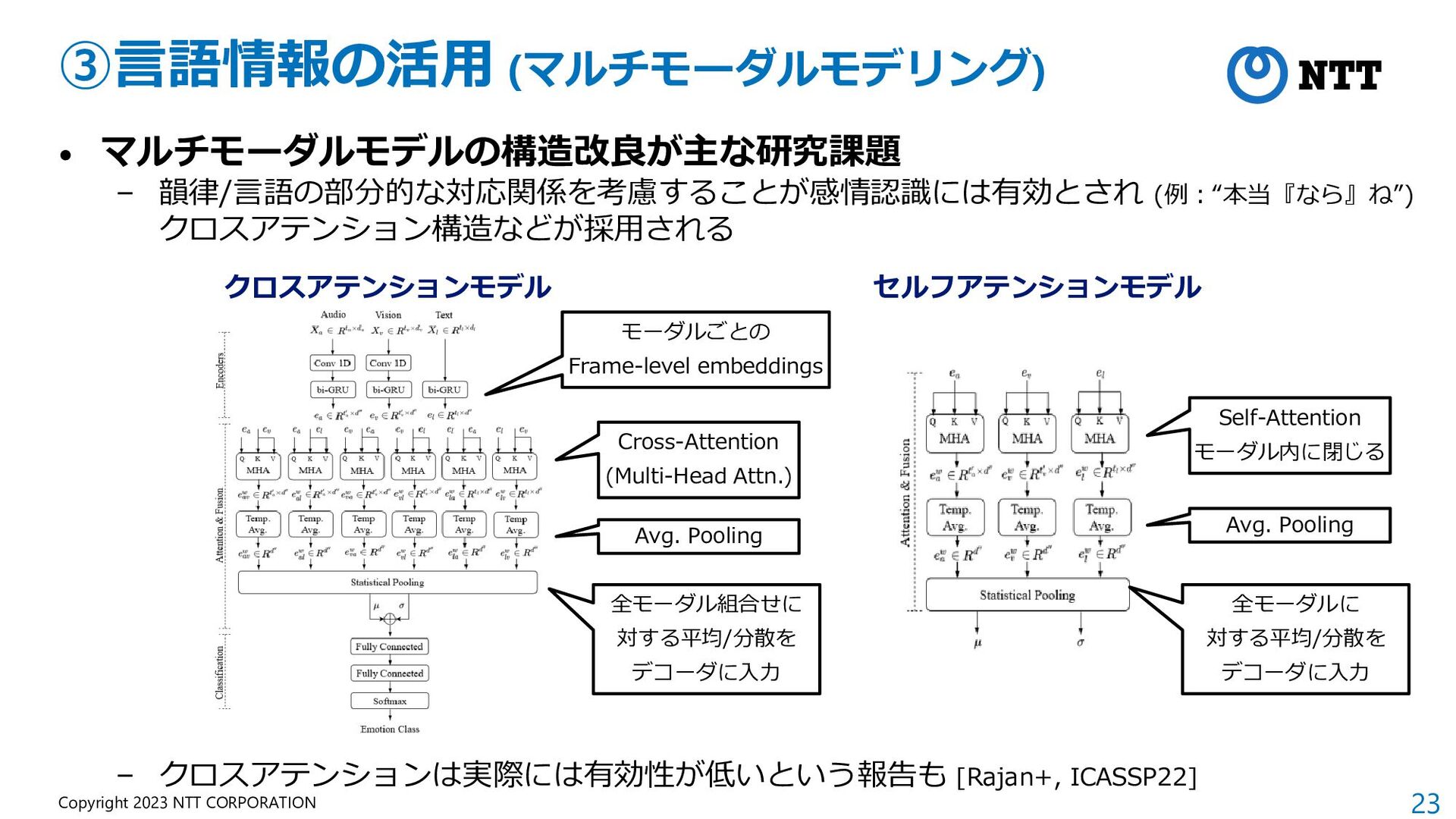{kind=link}
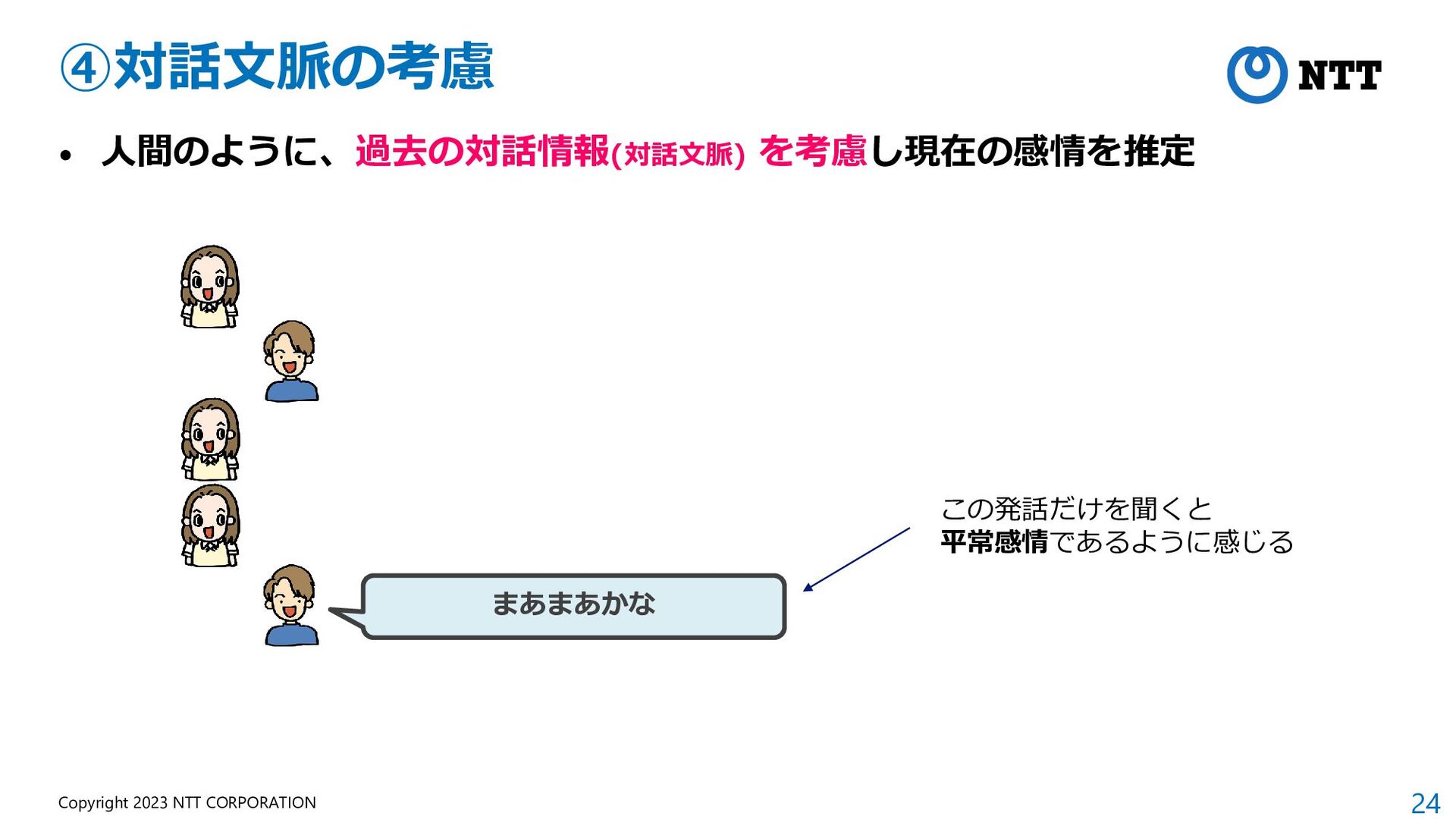{kind=link}
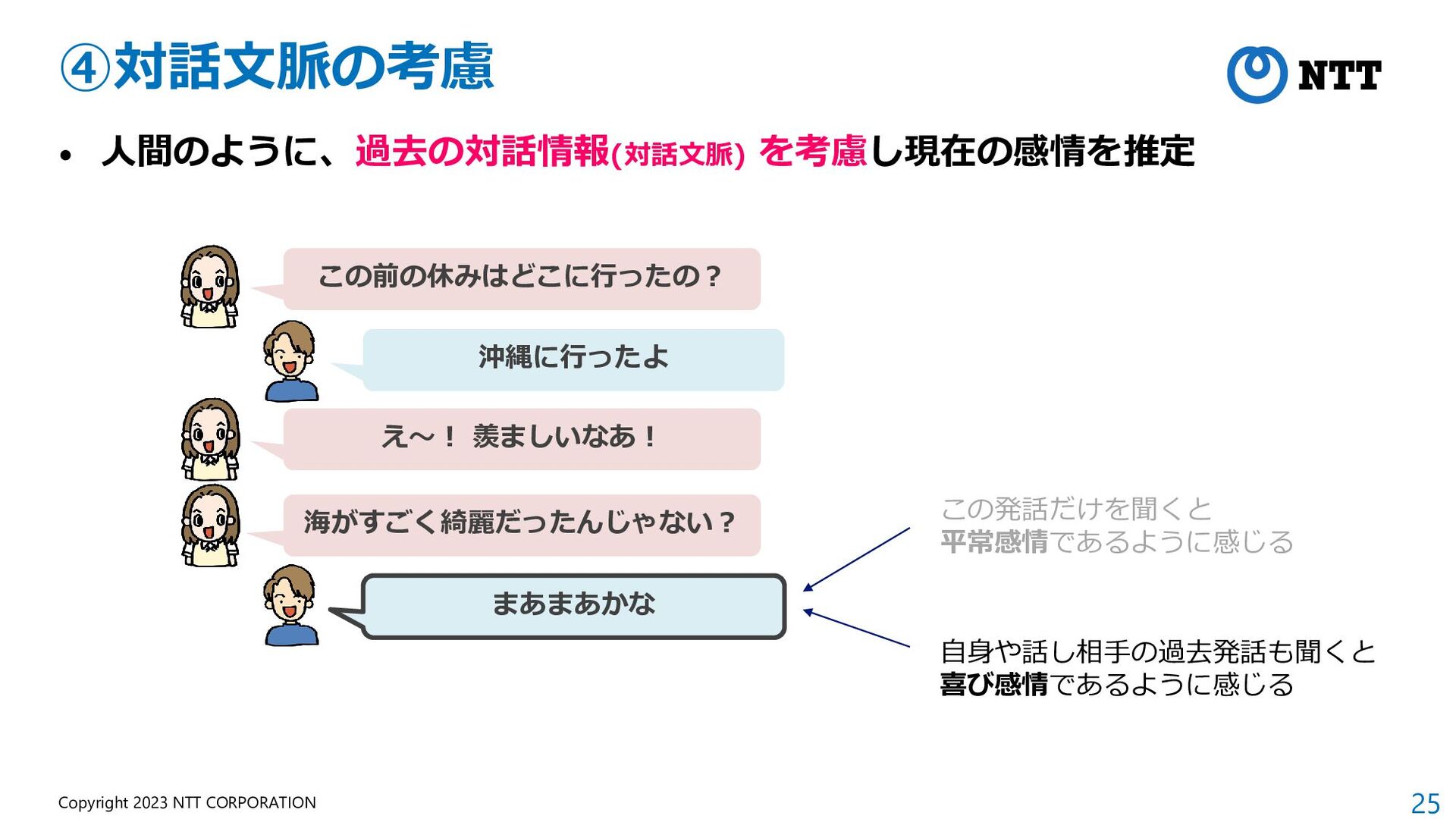{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}