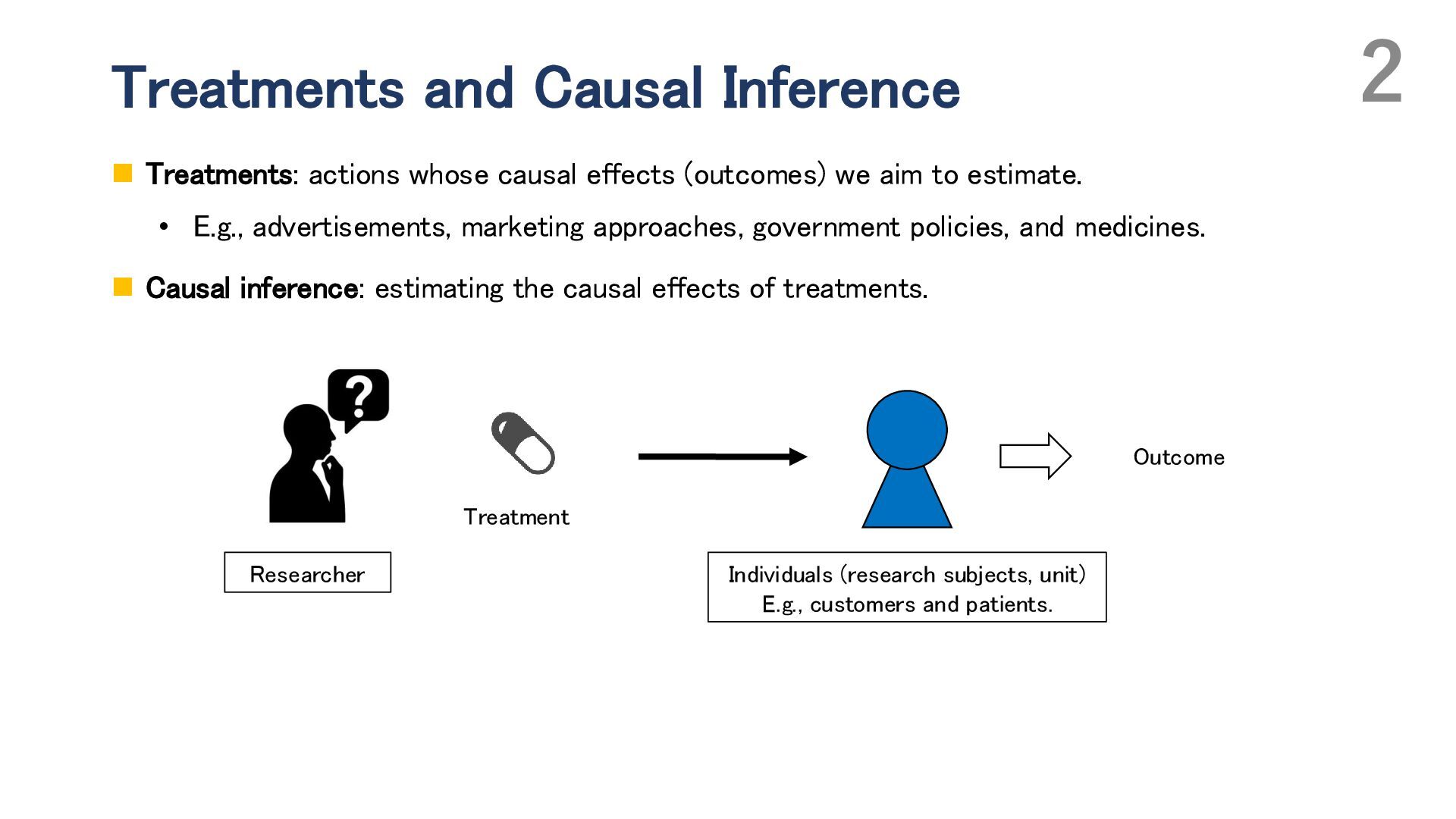
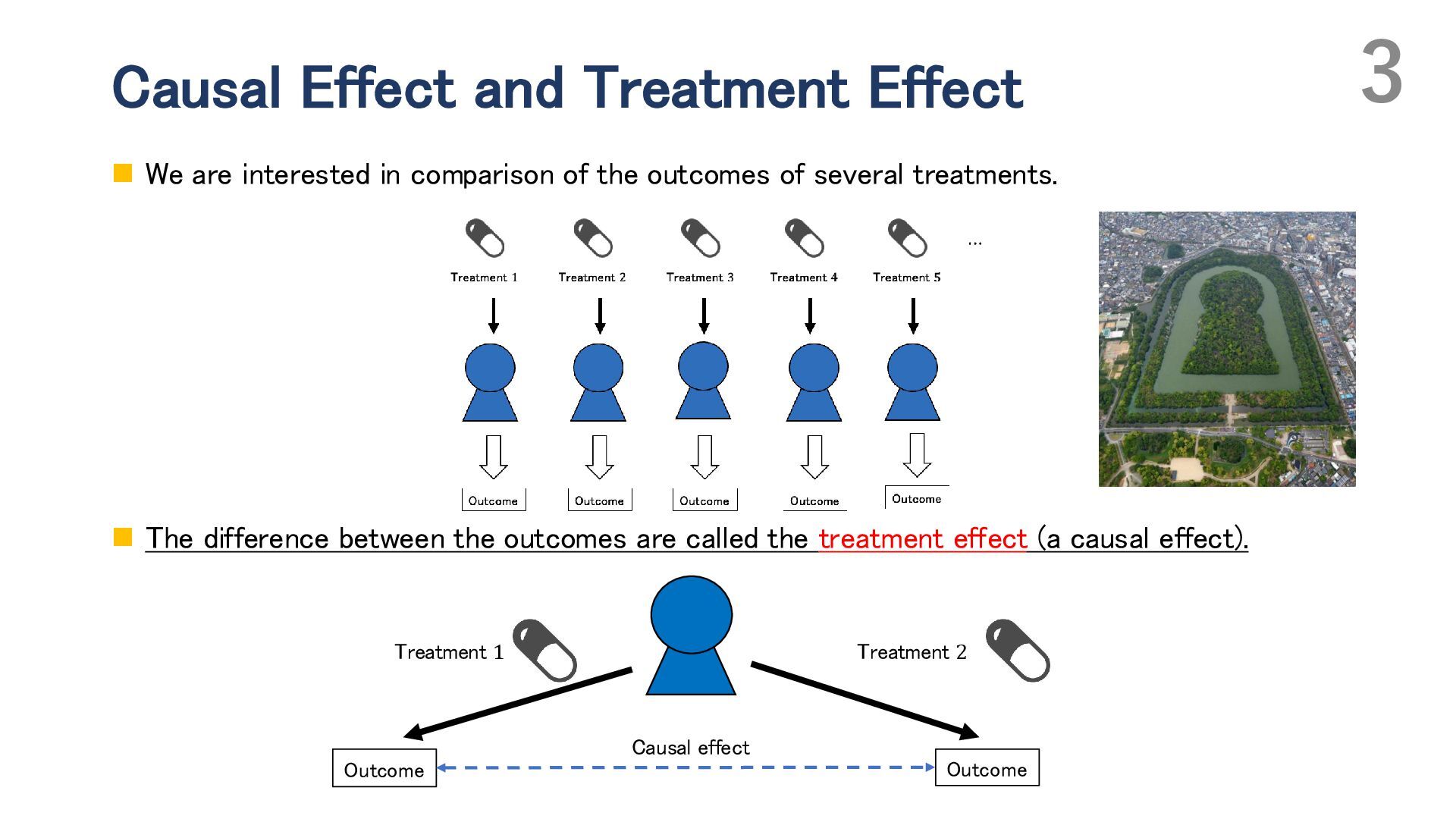
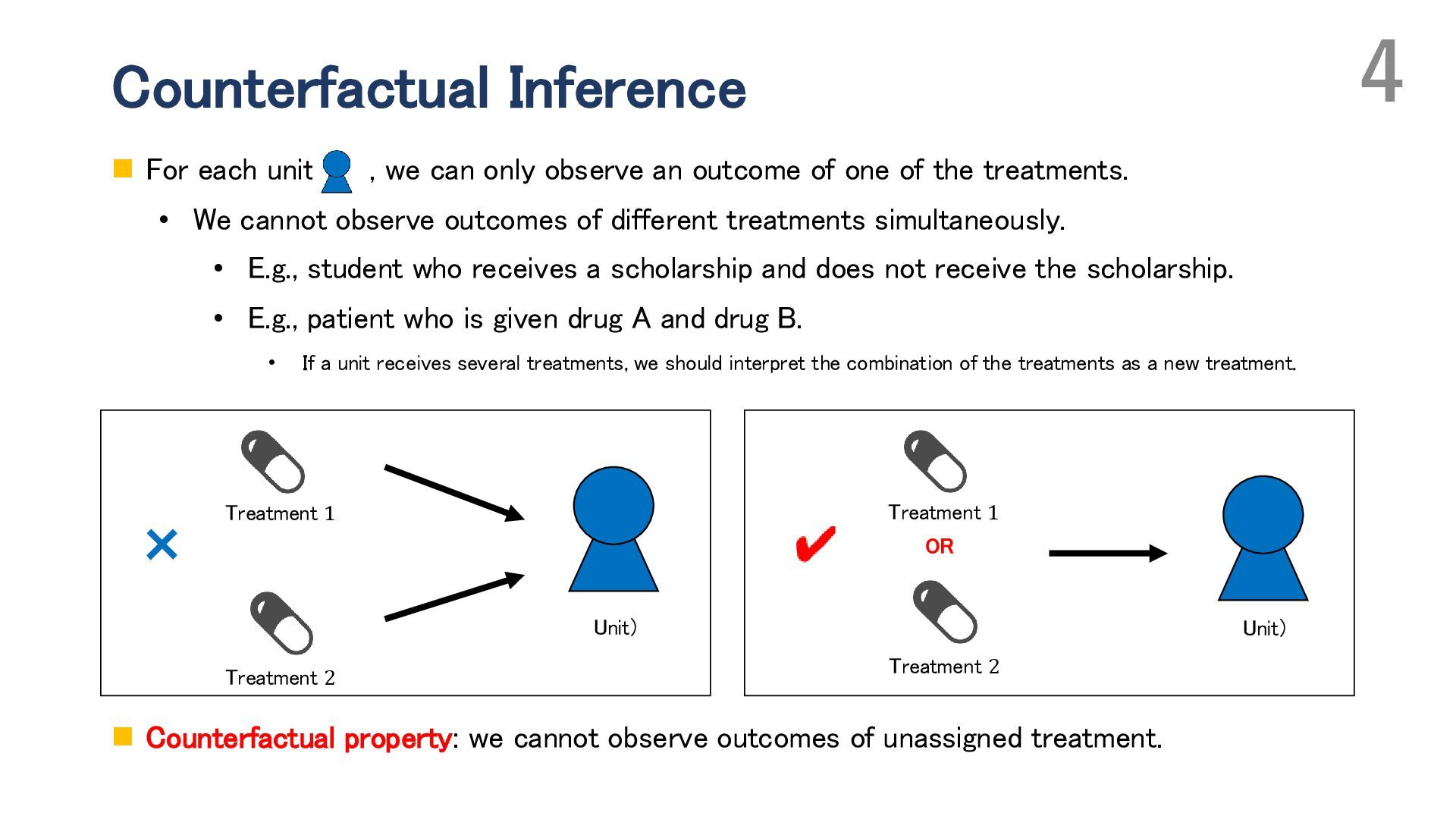
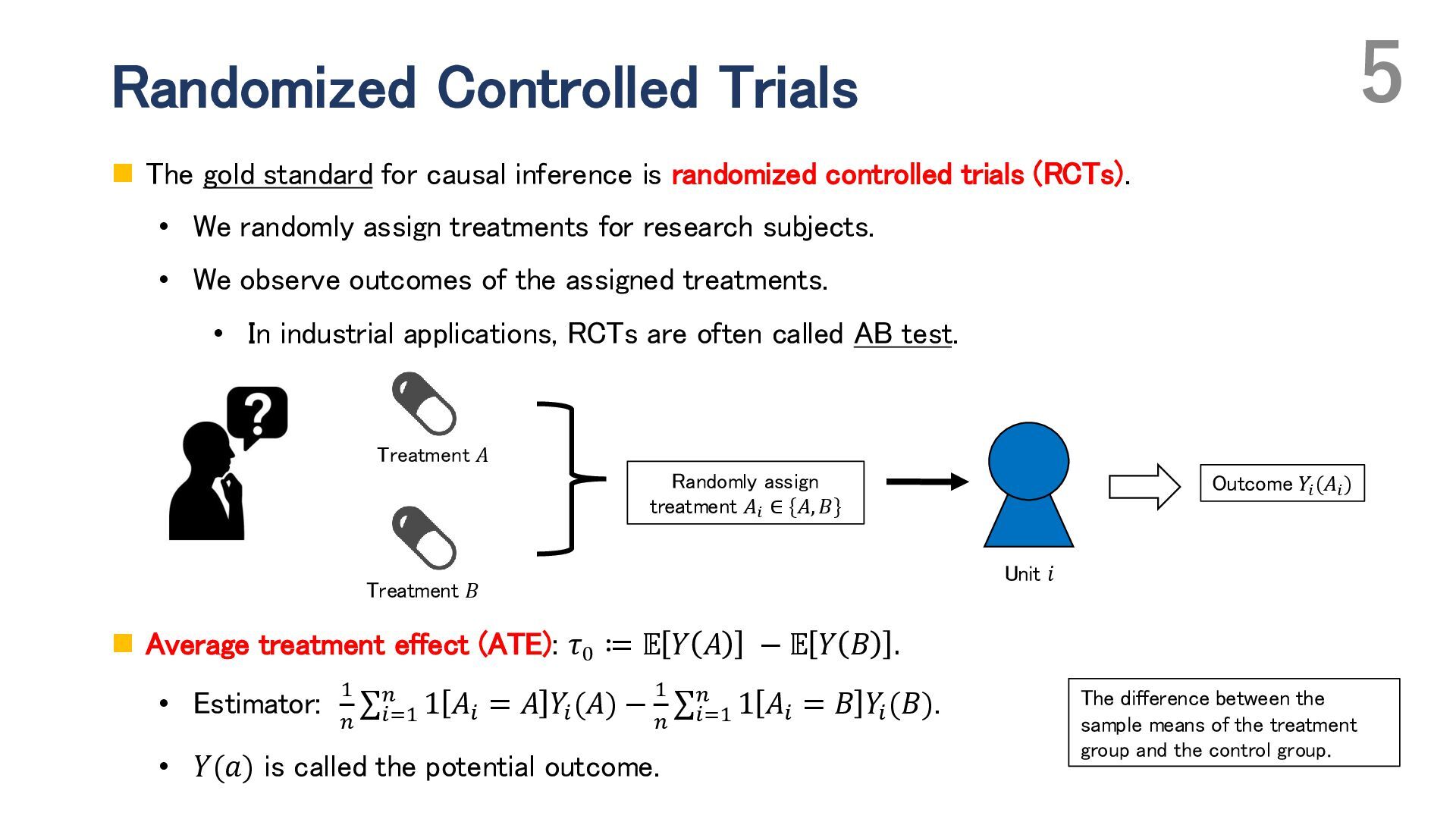
Adaptive experimental design has attracted attention for improving the efficiency of both average treatment effect (ATE) estimation and treatment choice. In such designs, the probability of assigning treatments (i.e., the propensity score) can be updated during the experiment based on previously collected observations. In ATE estimation, the objective is to reduce the estimation error of the ATE, whereas in treatment choice, the goal is to identify the best treatment—the one with the highest expected outcome. While ATE estimation typically involves binary treatments, treatment choice problems often consider multiple treatment options. In this talk, I begin by discussing adaptive experimental design for ATE estimation. I introduce the basic approach based on Neyman allocation, which provides a treatment-assignment probability that minimizes the asymptotic variance of ATE estimators, and then present several extensions, including adaptive optimization of the covariate distribution. Next, I address adaptive experimental design for treatment choice, also known as the best-arm identification problem, and highlight the challenges in developing “optimal” algorithms, especially in the presence of multiple treatments. I propose minimax and Bayes optimal algorithms for treatment choice in the setting without covariates. In particular, I generalize Neyman allocation to construct a minimax optimal algorithm. Finally, I discuss how incorporating covariates can further enhance the efficiency of treatment choice, focusing on conditional treatment choice (policy learning).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
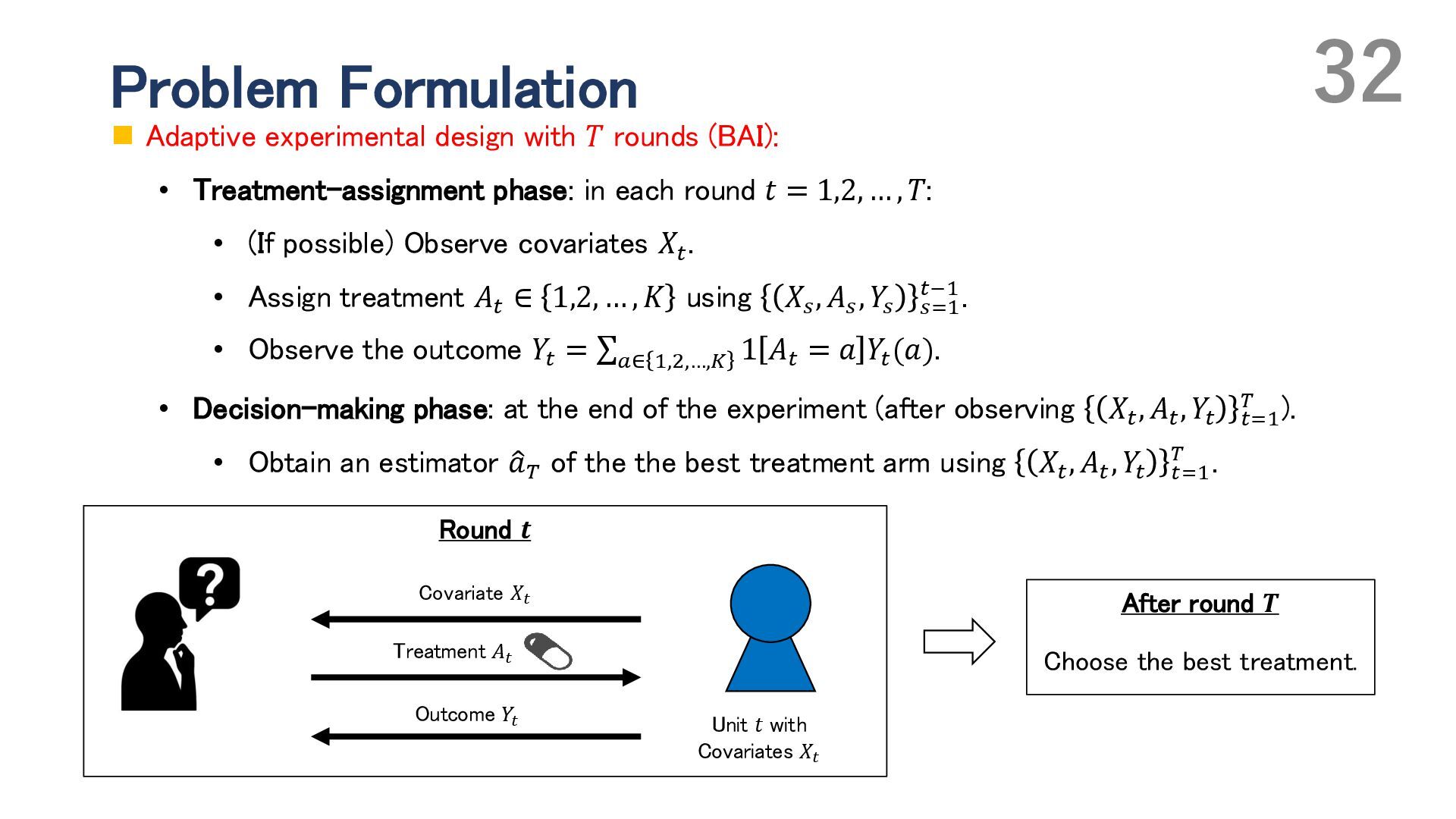{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
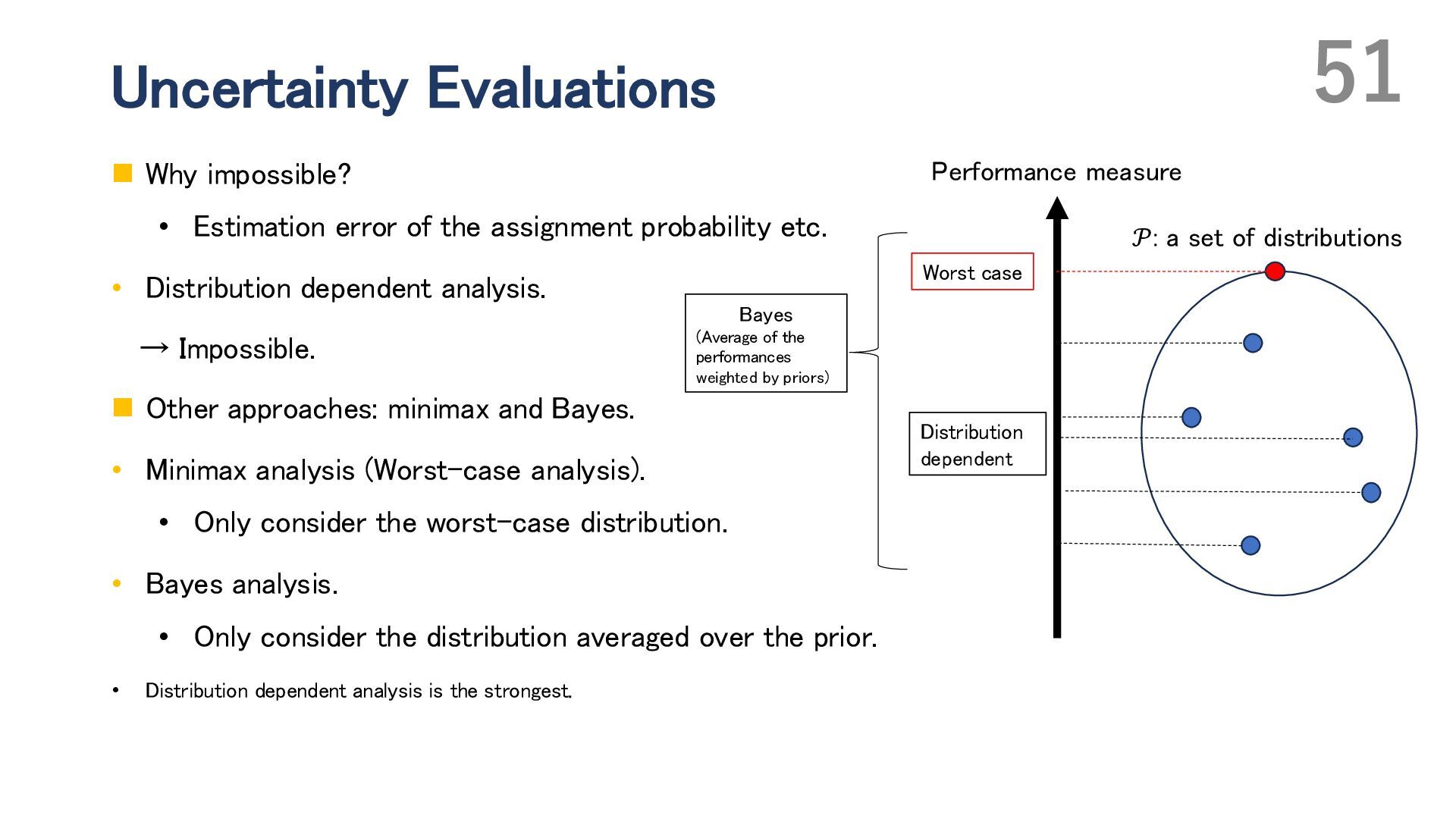{kind=link}
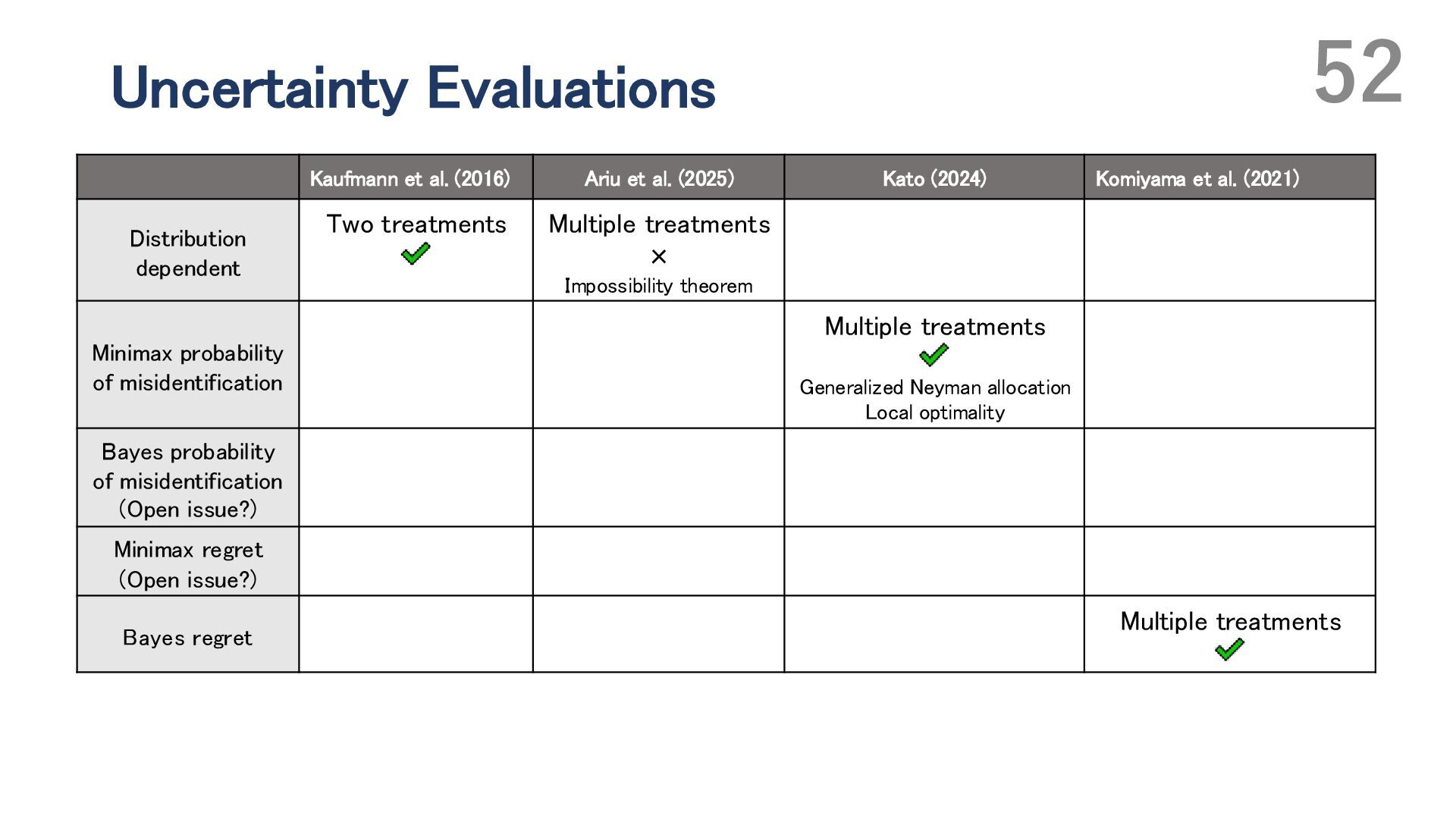{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}