with a partner or managing multiple work projects, Wunderlist is here to help you tick off all your personal and professional to-dos. 20+ million users Wunderlist is the easiest way to get stuff done.
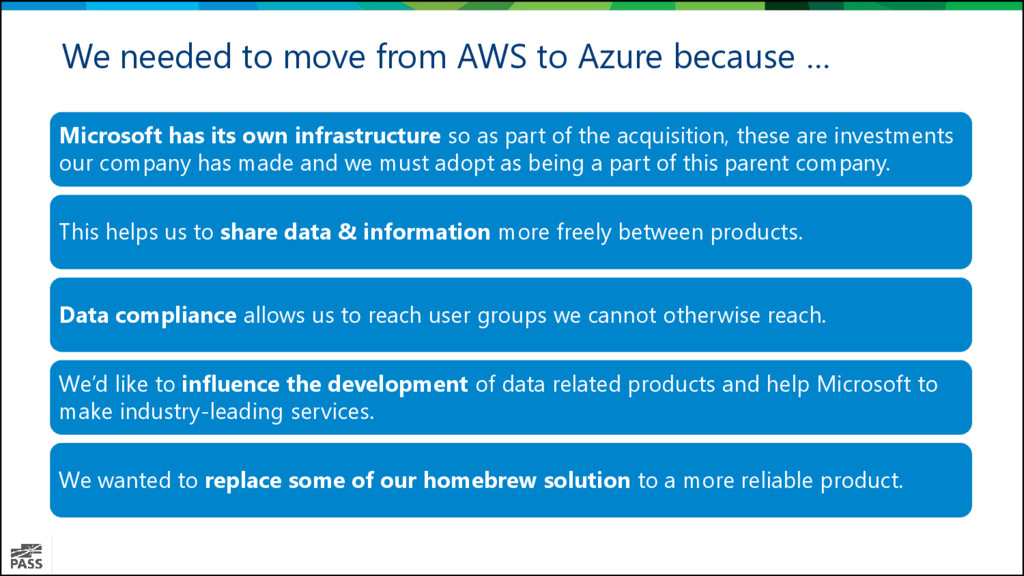
Microsoft has its own infrastructure so as part of the acquisition, these are investments our company has made and we must adopt as being a part of this parent company. This helps us to share data & information more freely between products. Data compliance allows us to reach user groups we cannot otherwise reach. We’d like to influence the development of data related products and help Microsoft to make industry-leading services. We wanted to replace some of our homebrew solution to a more reliable product.
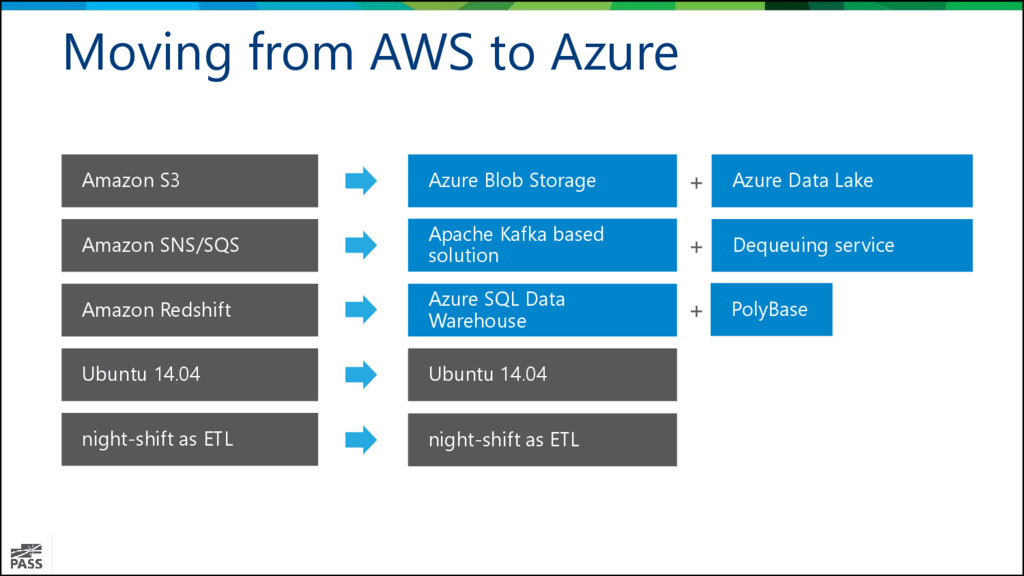
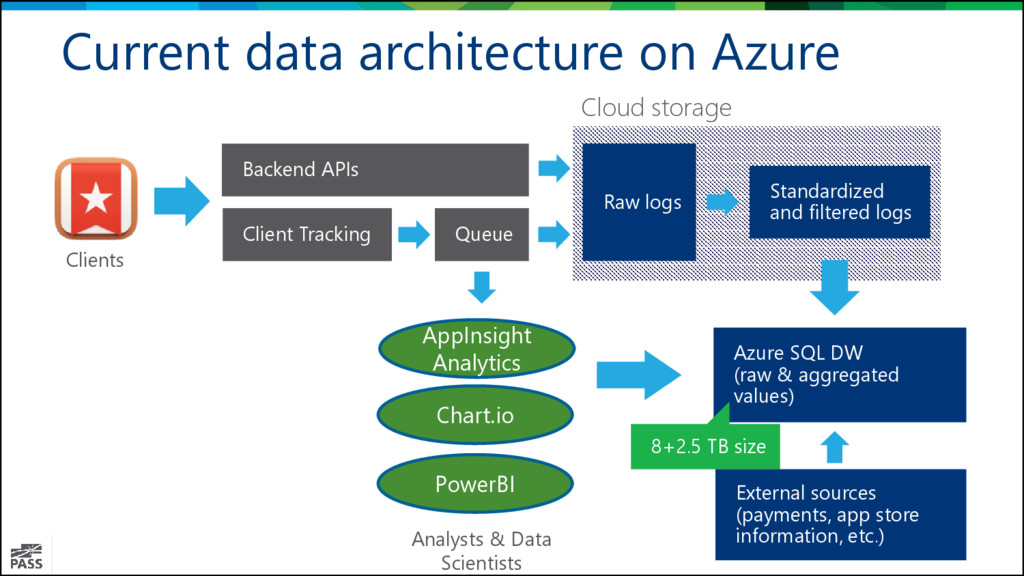
Redshift Ubuntu 14.04 night-shift as ETL Azure Blob Storage Azure Data Lake + Azure SQL Data Warehouse PolyBase + Ubuntu 14.04 night-shift as ETL Apache Kafka based solution Dequeuing service +
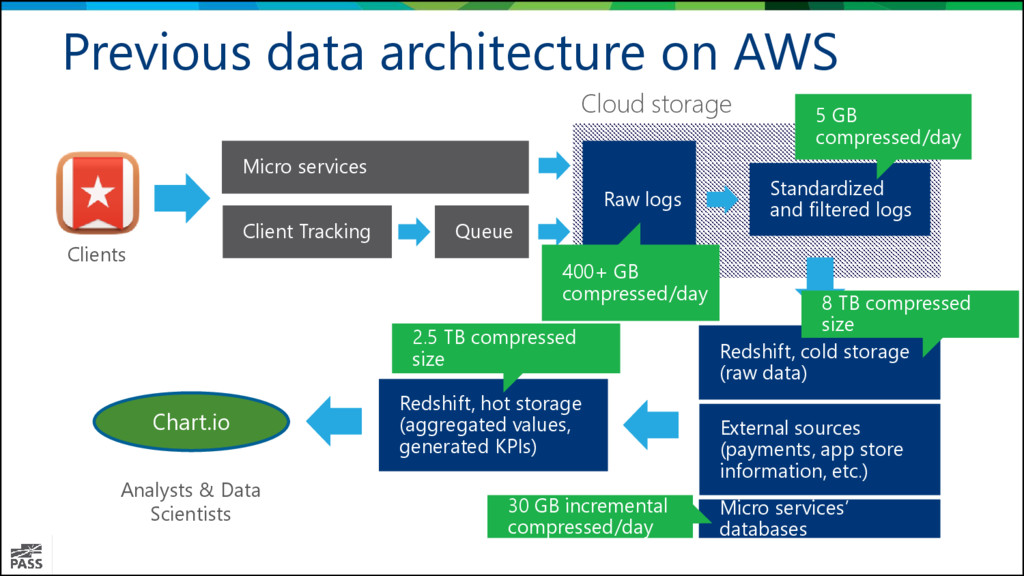
the same distribution key everywhere to improve performance, minimizing data movement. Partitions are fantastic for storing raw data, no need to create multiple tables. Using largerc resource class for daily running ELT and smallrc for visualization tools. ELT, do the transformation within the SQL DW. We’re doing KPI calculations, aggregations, data enrichment. Creating VIEWs for the most popular queries and questions.
to test your heaviest queries and figure out the distribution & partition settings. Only migrate your raw data and calculate the aggregations within the database (ELT). Create statistics for every column & update statistics after every load. Use the same distribution column. Create as many compressed files as possible when exporting/importing your table’s data to decrease the transferable size and run parallel processes. COPY command supports more date formats but not comfortable to define the schema of your data.
for SQL DW and/or PolyBase. Wish: Improved monitoring dashboard. Performance is as good as Amazon Redshift. Stable and reliable Easy and quick to scale up, using T-SQL code. Perfect to do the transformations within the DWH. Carefully consider the distribution key, otherwise you have to redistribute frequently. Connecting from Linux/OSX is challenging. We made Cheetah to solve this issue.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}