This talk was presented at PyCon Ireland, 2015.
Did you feel like using R is too complex and Java is pain in the ass? Is your company using PHP because somebody said it would be okay? You started working with R and realized you can't write a micro service and need to pick another language?
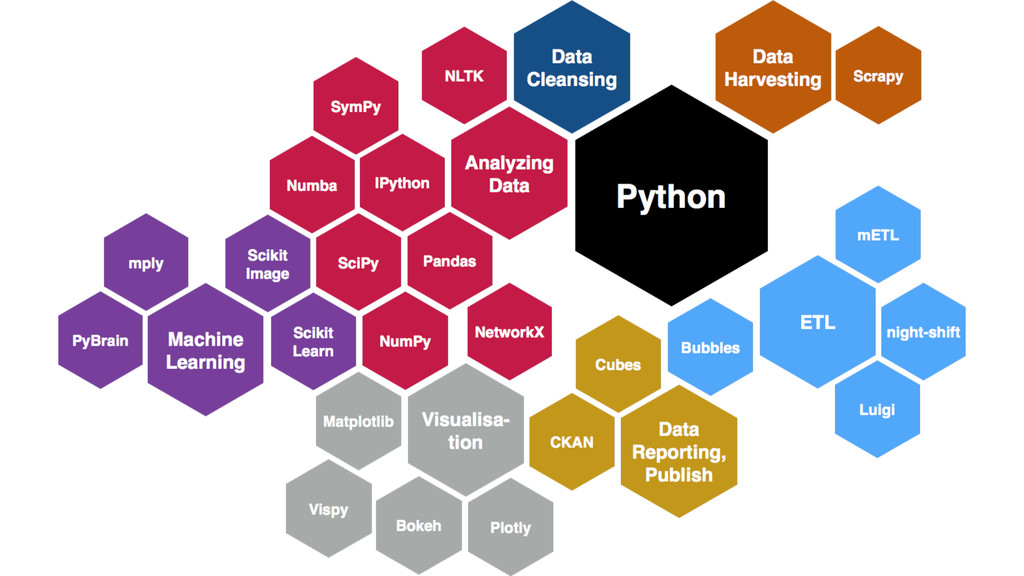
Regardless of your answers, this lecture is about what your biggest problem would be if you have had chosen Python for your work in the first place.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
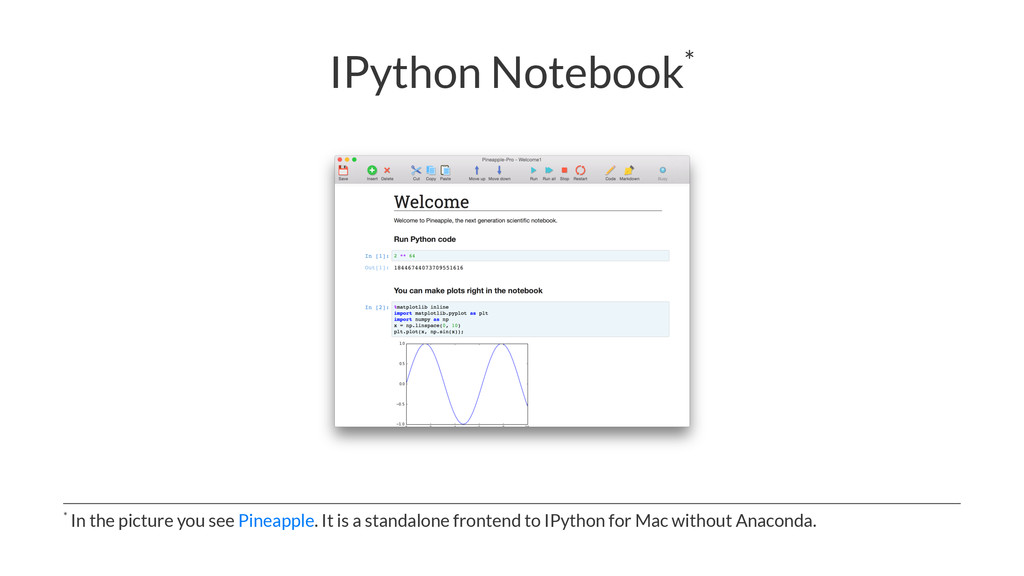{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
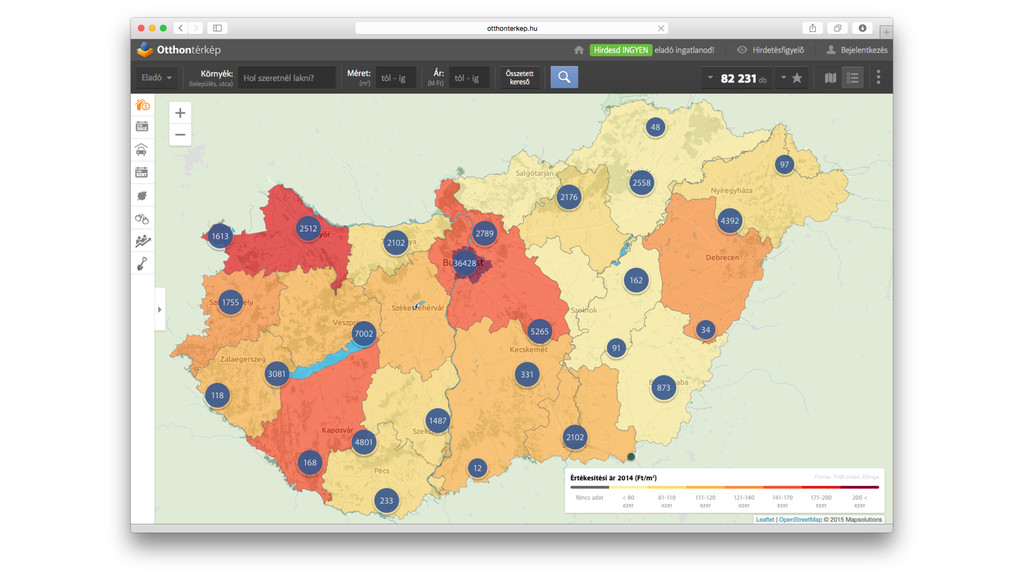{kind=link}
{kind=link}
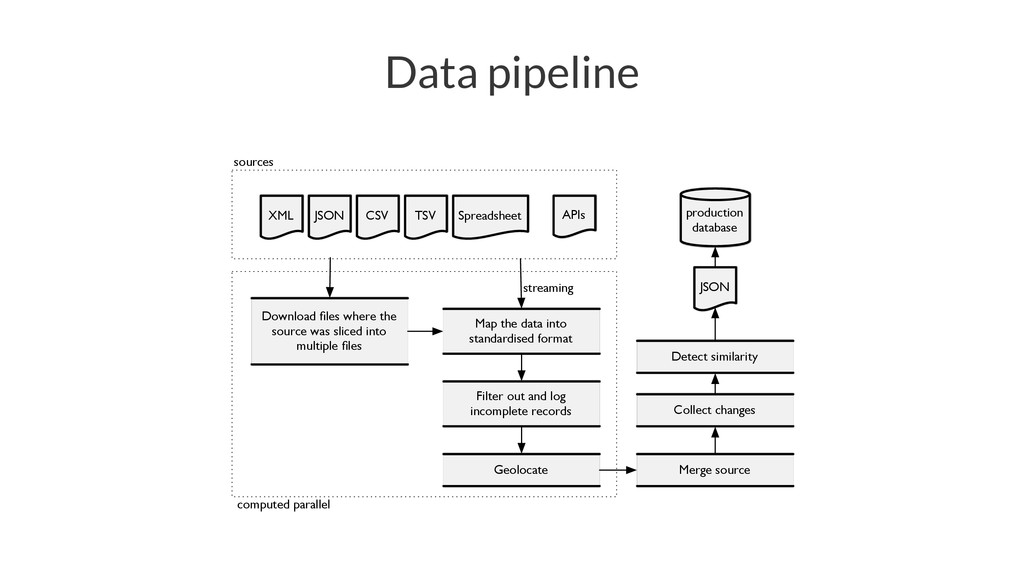{kind=link}
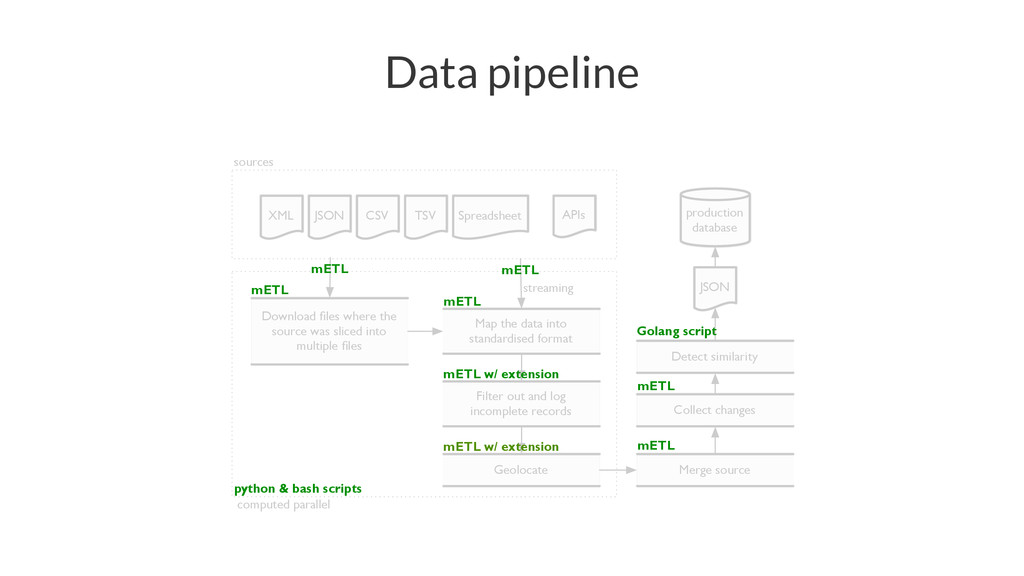{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
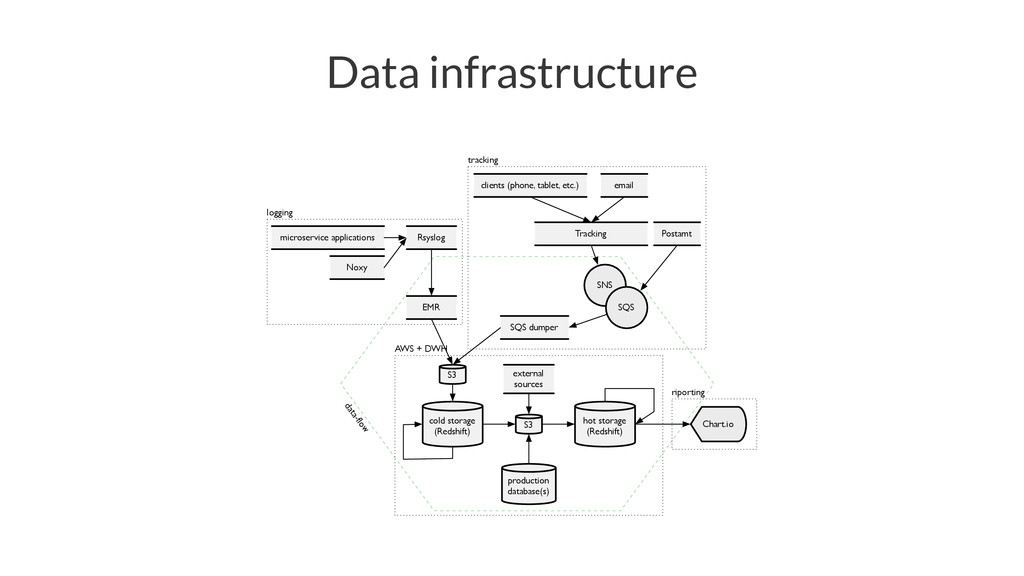{kind=link}
{kind=link}
{kind=link}
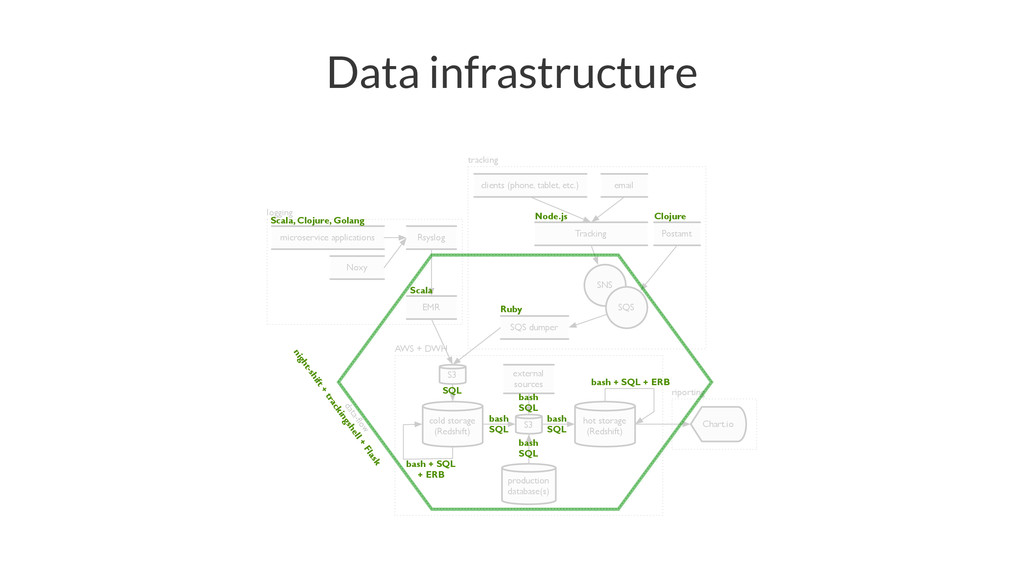{kind=link}
{kind=link}
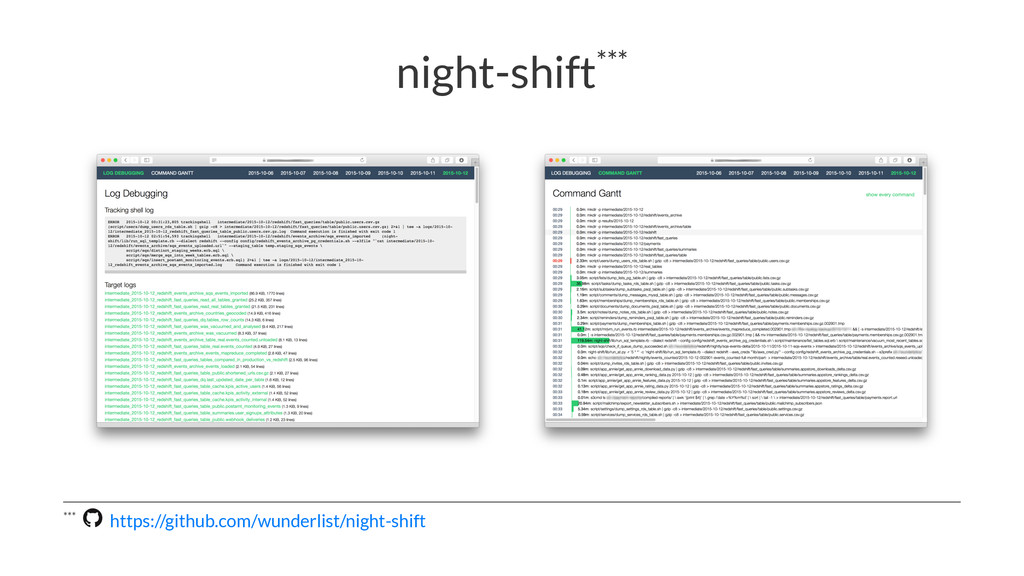{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}