database usage and especially in data warehousing that involves: • Extracting data from outside sources • Transforming it to fit operational needs, which can include quality levels • Loading it into the end target @ Wikipedia ETL
Update data: which data is different 3. Data consistency is horrible 4. Large datasets 5. Quick transforms 6. Every source has different format ETL software problems: 1. Hard to use & not user friendly GUI 2. Expensive software 3. Console tool is not available Most common problems
Information Server (Datastage) • SAS Data Integration Studio • PowerCenter Informatica • Elixir Repertoire • Data Migrator • SQL Server Integration Services • Talend Studio for Data Integration • DataFlow Manager • Pentaho Kettle • … ETL Tools
known (specific) set of data where the test results are repeatable. Some frameworks use fixtures to load default (or new) data into relational database. Not suitable for periodical updated data migration! Fixtures
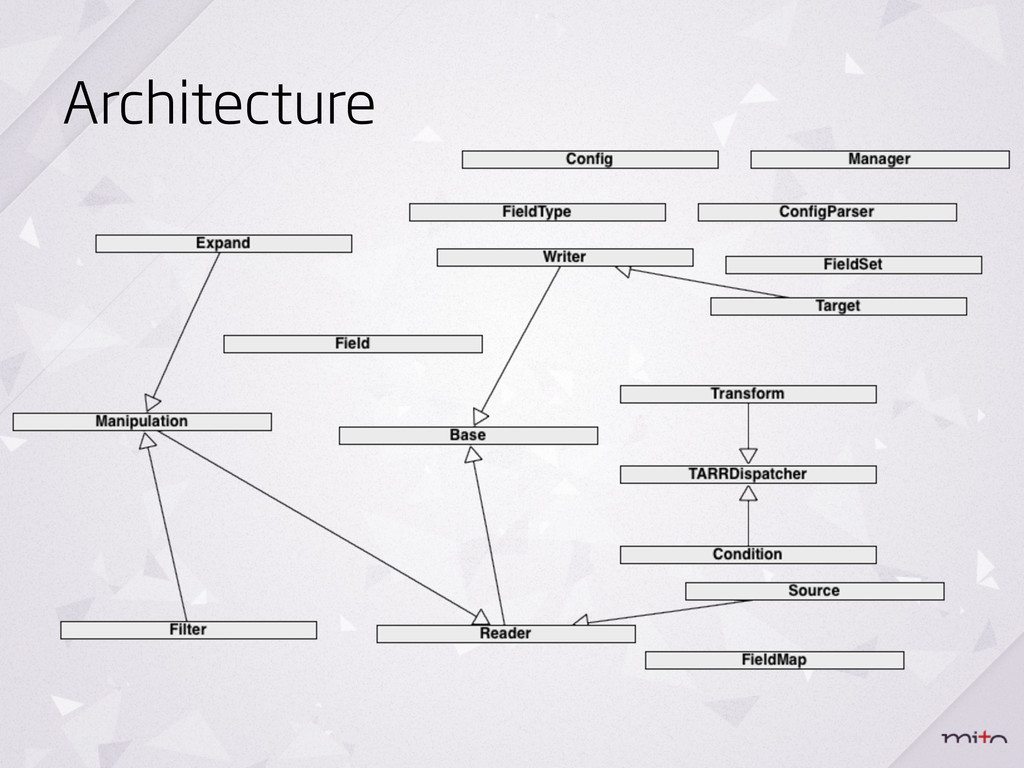
migration file management - Check differences between migrations - Configuration in YAMLformat - Programming skills is not required - Transformations are using TARR, with Conditions and Statements - Quick transforms and manipulations - Easy to extend (for special use) - 9 source types & 8 target types Features
Update data: which data is different 3. Data consistency is horrible 4. Large datasets 5. Quick transforms 6. Every source has different format Unexpected challenges: 7. Filtering data via different source(s) 8. Type conversion 9. Readable field map for every source type Solutions
which data is different Every row gets a generated hash in the field value’s final stage and a unique id based on the marked* fields in the configuration file. Saving row’s primary key and the generated hash into a pickle migration file. If the unique id exists with the same hash, we skip the row, if the hash is different we update the row. * Not required Solutions
Quick transforms mETL has 8 transforms to produce consistent data sets. These transforms are supported by statements and conditions. Uses TARR* package which is a non-parallel data flow language created by CEU Economics with multiple thread support. * It will be open source as well. Solutions
file with all fields and information. You don’t have to write program code, just change the field’s mapping setting and run the console script again with different source. These Yaml files are savable and changeable if the source format is modified. Easy to maintain. Solutions
final type But: All field’s have to be the same type. We have to manage type conversion in runtime with transforms: • ConvertType: change type to the Field and add a default value if it necessary. • Set: set any value to the Field. After the transform process we have to force type change automatically. Solutions
every source input into dicts and lists and give a route for the data. If the route’s item is not exists we set the field’s value to empty. E.g. in XML: pictures/picture/0/picture_thumb/url E.g. in CSV, XLS, …: 5 E.g. in Database: created Easy to learn because not using different keywords (e.g.: index, route, cell, …) for every type. Solutions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![FALUDI, Bence [email protected] Thank you for your attention!](https://files.speakerdeck.com/presentations/c8bd7d207a310130222e12313809347f/slide_24.jpg){kind=link}