Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
A Study in Bitmap: Is NDK the fast Processing m...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
bigbackboom
July 10, 2024
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
A Study in Bitmap: Is NDK the fast Processing method by CPU?
bigbackboom
July 10, 2024
More Decks by bigbackboom
See All by bigbackboom
Learn as a Pair
bigbackboom
0
75
Not 2 L8 JKでもわかるMaterial 3
bigbackboom
0
62
JKでもわかるSFace Recognition
bigbackboom
0
82
Androidタブレットアプリ作成_棚から牡丹餅を得るにはまず棚から
bigbackboom
0
70
Proto Datastoreを使う前の心構え
bigbackboom
0
330
Extended A Study in Bitmap: Is NDK the fast Processing method by CPU?
bigbackboom
0
35
Have A Dog in CircleCI
bigbackboom
0
94
Androidエンジニアのお仕事でのショボーン
bigbackboom
0
97
解明!楽しいプレゼンする話すスキル
bigbackboom
0
130
Featured
See All Featured
Six Lessons from altMBA
skipperchong
29
4.4k
Optimizing for Happiness
mojombo
378
71k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
420
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Crafting Experiences
bethany
1
230
AI: The stuff that nobody shows you
jnunemaker
PRO
9
840
For a Future-Friendly Web
brad_frost
183
10k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Marketing to machines
jonoalderson
1
5.6k
A designer walks into a library…
pauljervisheath
211
24k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Transcript
A Study in Bitmap: Is NDK the Fastest Processing Method
by CPU? キクチコウダイ
自己紹介 菊池 広大(キクチコウダイ) 2023年6月 株式会社マネーフォワードに入社 埼玉出身、Iターンで東京から福岡に引越し Androidエンジニア、たまにバックエンド Github: https://github.com/BigBackBoom
WE ARE HIRING!!!!
概要
概要 C++で実行されるAndroidのNDKは 本当に実行速度最速なのか? Bitmapファイルを処理して その速度を検証してみよう
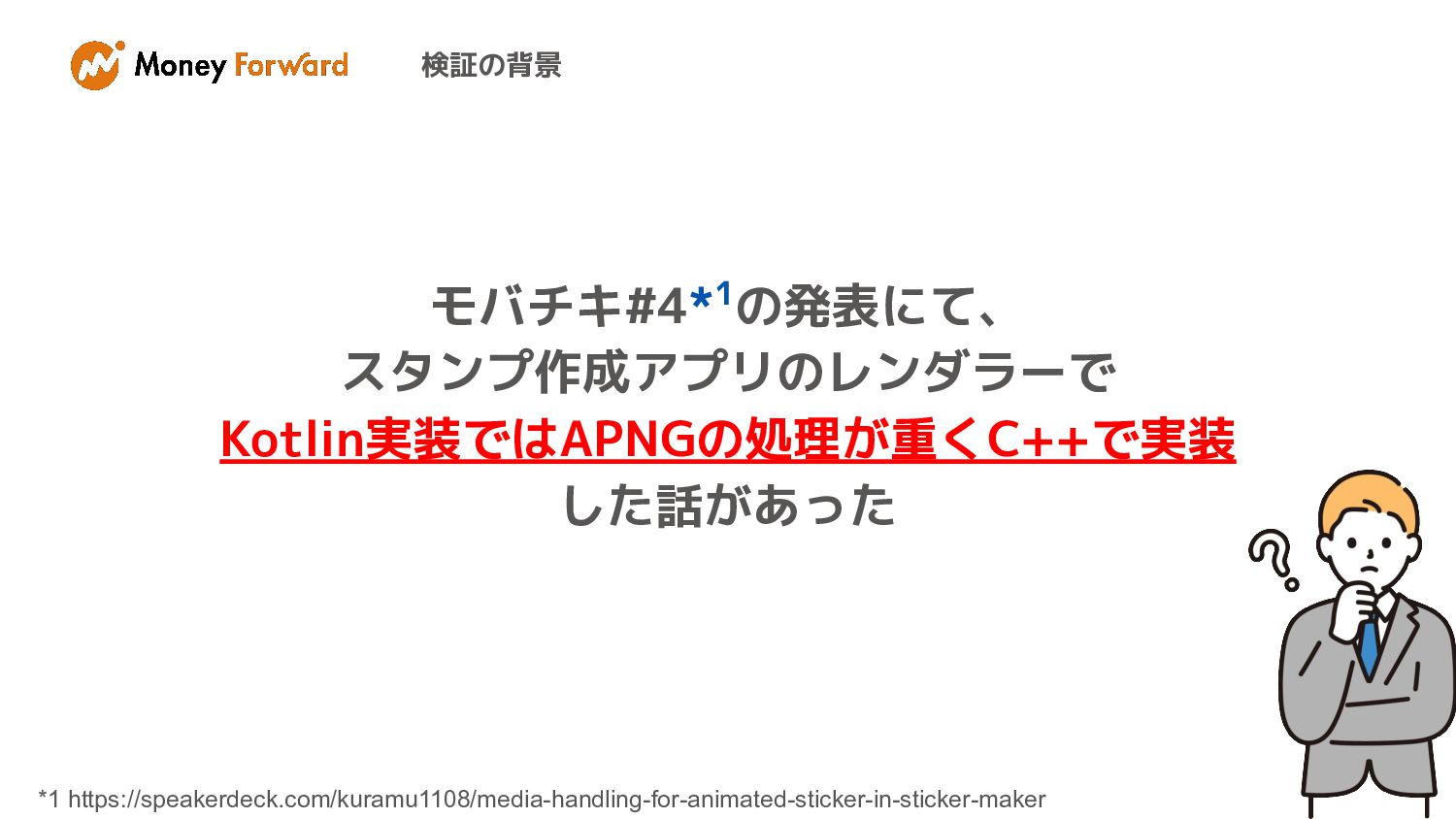
検証の背景
検証の背景 モバチキ#4*1の発表にて、 スタンプ作成アプリのレンダラーで Kotlin実装ではAPNGの処理が重くC++で実装 した話があった *1 https://speakerdeck.com/kuramu1108/media-handling-for-animated-sticker-in-sticker-maker
検証の背景 • Native処理はどれぐらい早いのかな? • GPUでの処理を行なっているかのかな? • そんなに差が出るものか興味が湧いた。
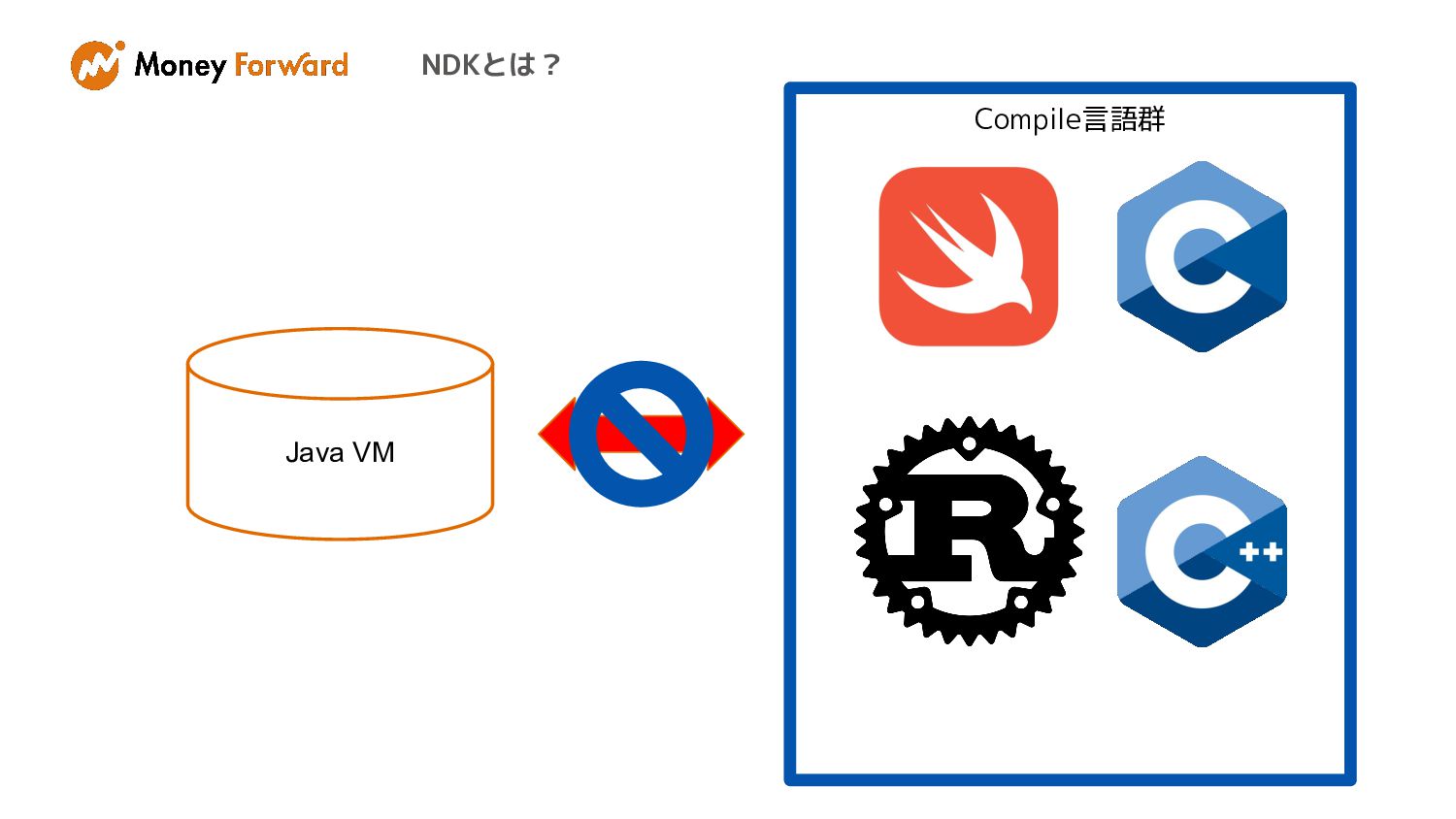
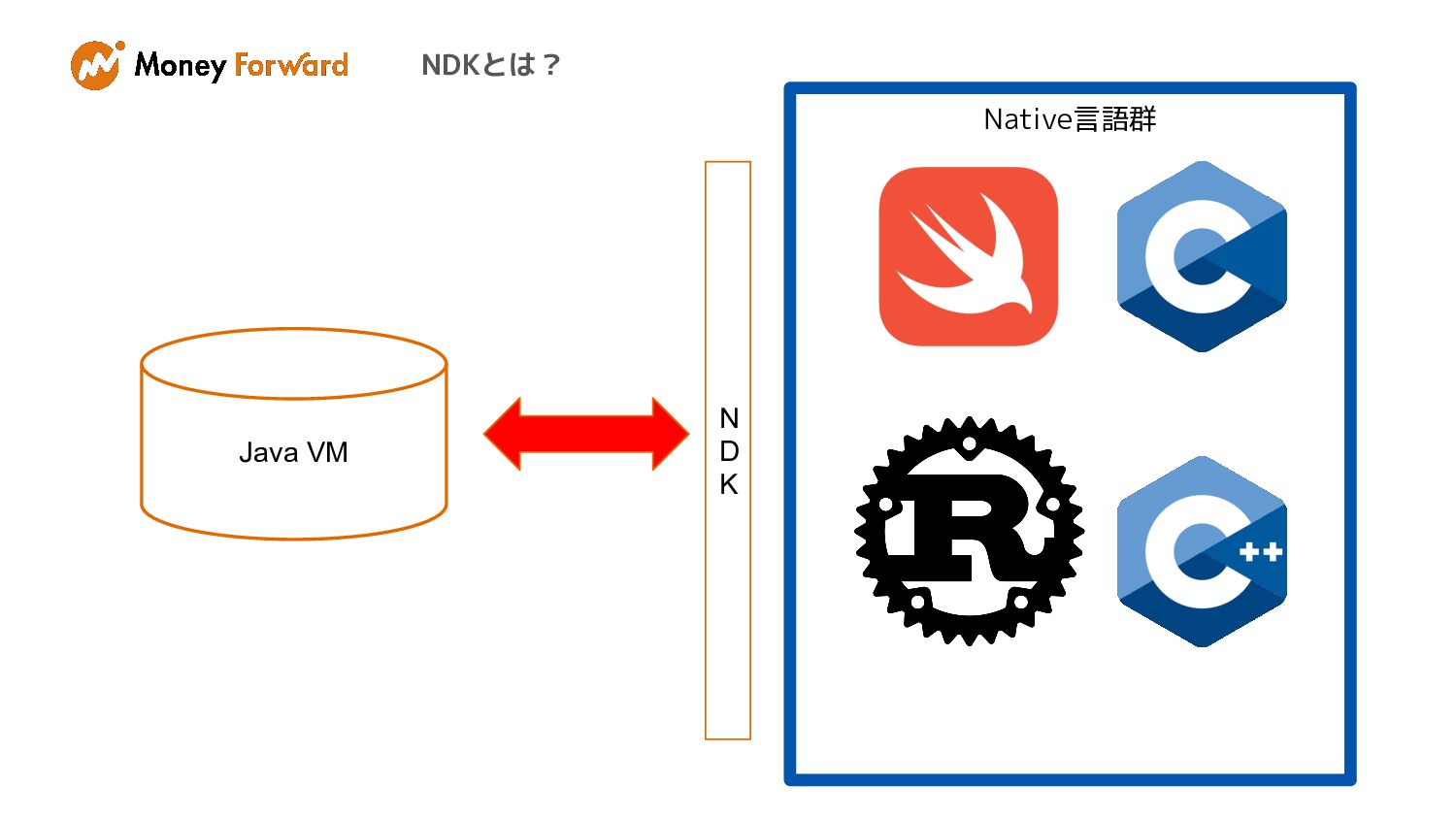
NDKとは?
NDKとは? The Android NDK is a toolset that lets you
implement parts of your app in native code, using languages such as C and C++. For certain types of apps, this can help you reuse code libraries written in those languages.*2 *2 https://developer.android.com/ndk
NDKとは? • C/C++などのNativeコードでの開発が可能 • C/C++でしか提供されていないパワフルなライブラリ を利用可能 • Nativeコードのロジックを再利用できる。
NDKとは? Java VM Compile言語群
Native言語群 NDKとは? Java VM N D K
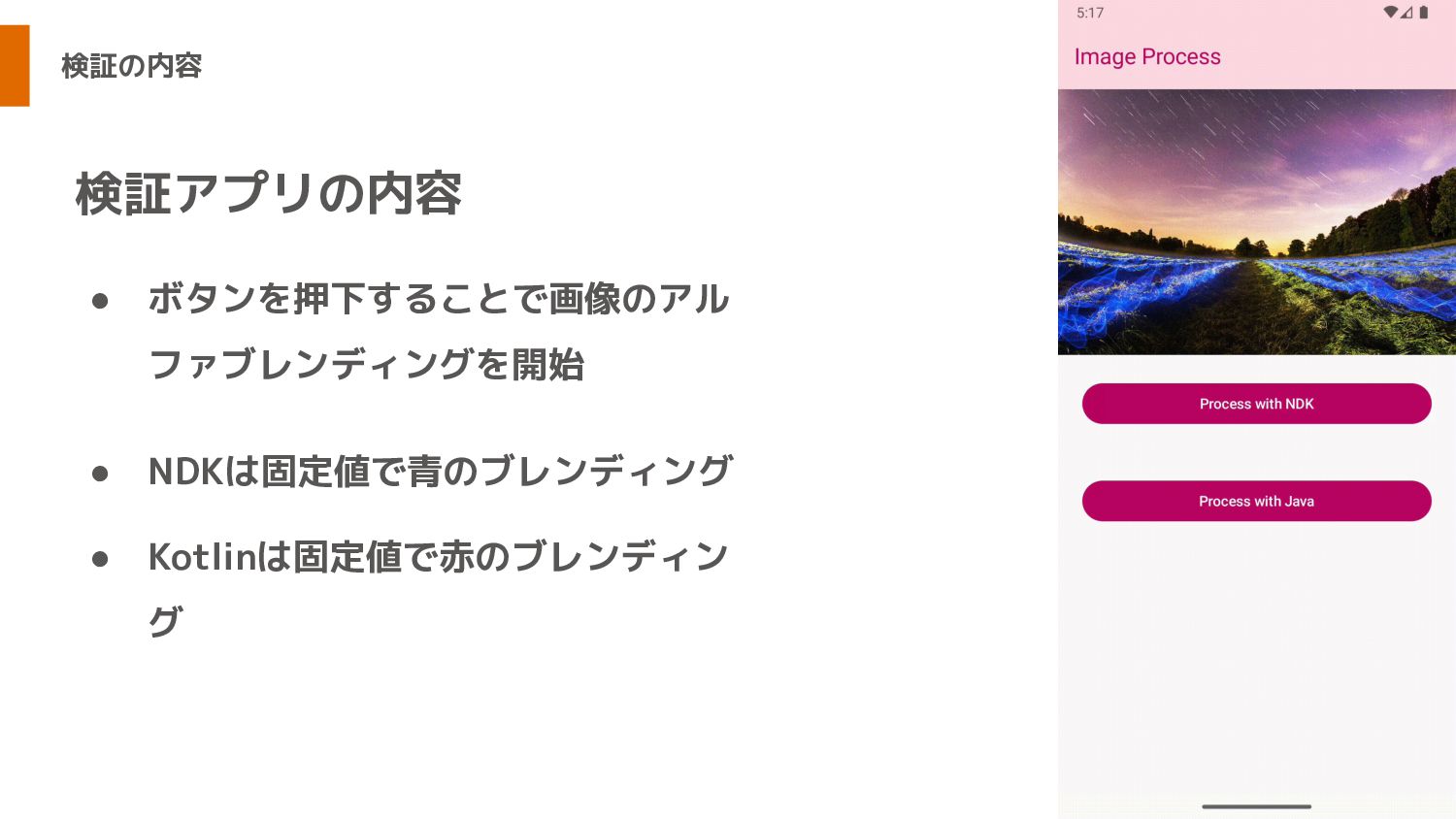
検証内容
検証内容 4KのBMPファイルを アルファブレンディングして 処理時間を測る
検証の内容 • ボタンを押下することで画像のアル ファブレンディングを開始 • NDKは固定値で青のブレンディング • Kotlinは固定値で赤のブレンディン グ 検証アプリの内容
Javaの実装 • NDKは固定値で青のブレ ンディング • Javaは固定値で赤のブレ ンディング Kotlinの実装 object AlphaBlender
{ const val RED = 0 const val GREEN = 1 const val BLUE = 2 const val ALPHA = 3 fun processImageJava ( bmpByteArray: ByteArray, rgbArray: IntArray ) { val alpha = rgbArray[ ALPHA] * 0.01 val beta = 1.0f - (rgbArray[ ALPHA] * 0.01) var index = 54 while (index < bmpByteArray. size) { val a = bmpByteArray[index].toInt() and 0xff val b = bmpByteArray[index + 1].toInt() and 0xff val c = bmpByteArray[index + 2].toInt() and 0xff bmpByteArray[index] = ((alpha * a).toInt() + (beta * rgbArray[ BLUE]).toInt()).toByte() bmpByteArray[index + 1] = ((alpha * b).toInt() + (beta * rgbArray[ GREEN]).toInt()).toByte() bmpByteArray[index + 2] = ((alpha * c).toInt() + (beta * rgbArray[ RED]).toInt()).toByte() index += 3 } } // NDK implementation below // . // . // . }
NDKの実装 • NDKはKotlin側に external関数を用意して おく • これに対応するC++実装 を用意する。 NDKの実装 //
AlphaBlender.kt object AlphaBlender { // . // . // . // Java implementation above external fun processImage( bmpByteArray: ByteArray, rgbaArray: IntArray ) }
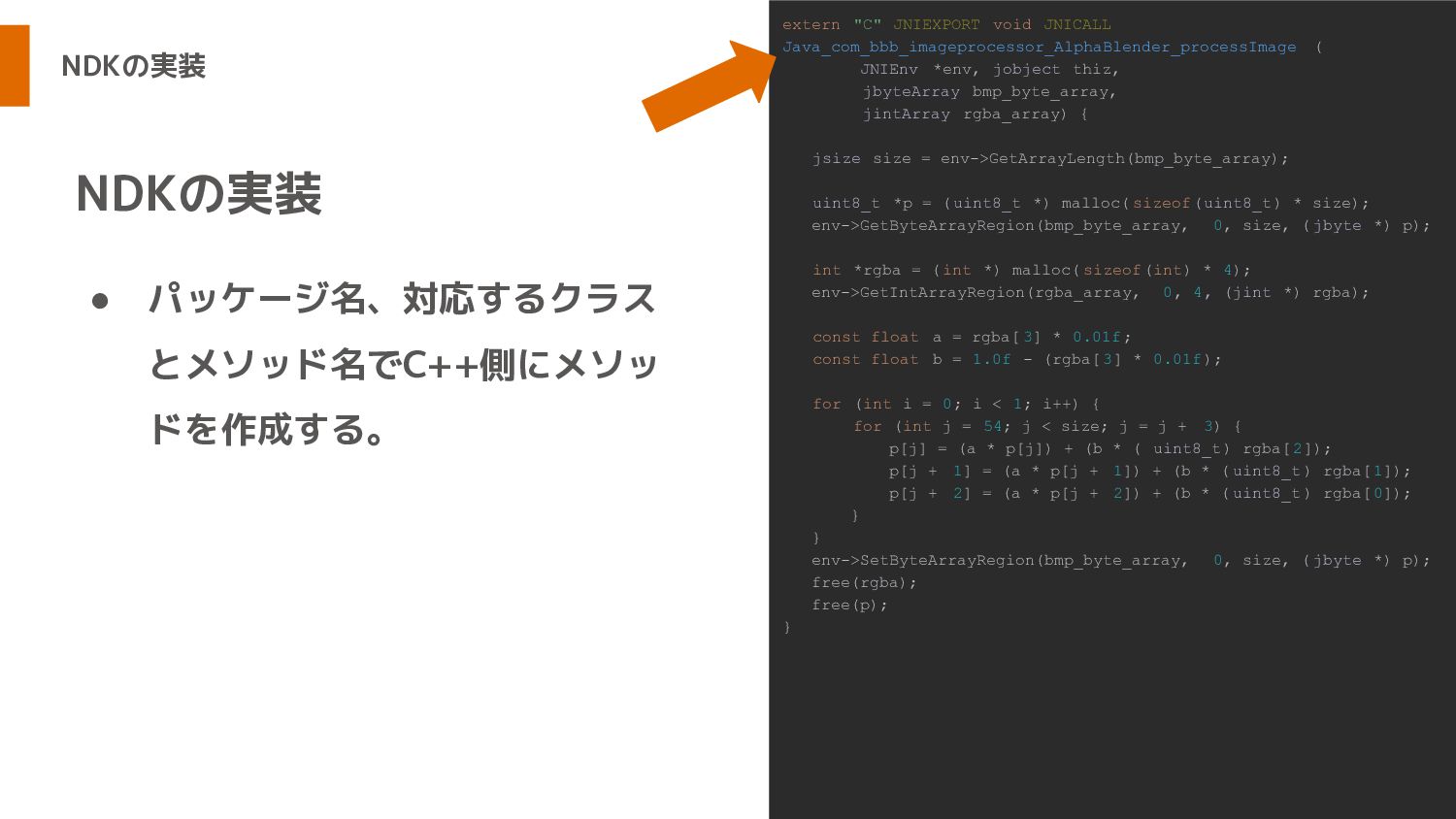
NDKの実装 • パッケージ名、対応するクラス とメソッド名でC++側にメソッ ドを作成する。 NDKの実装 extern "C" JNIEXPORT void
JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
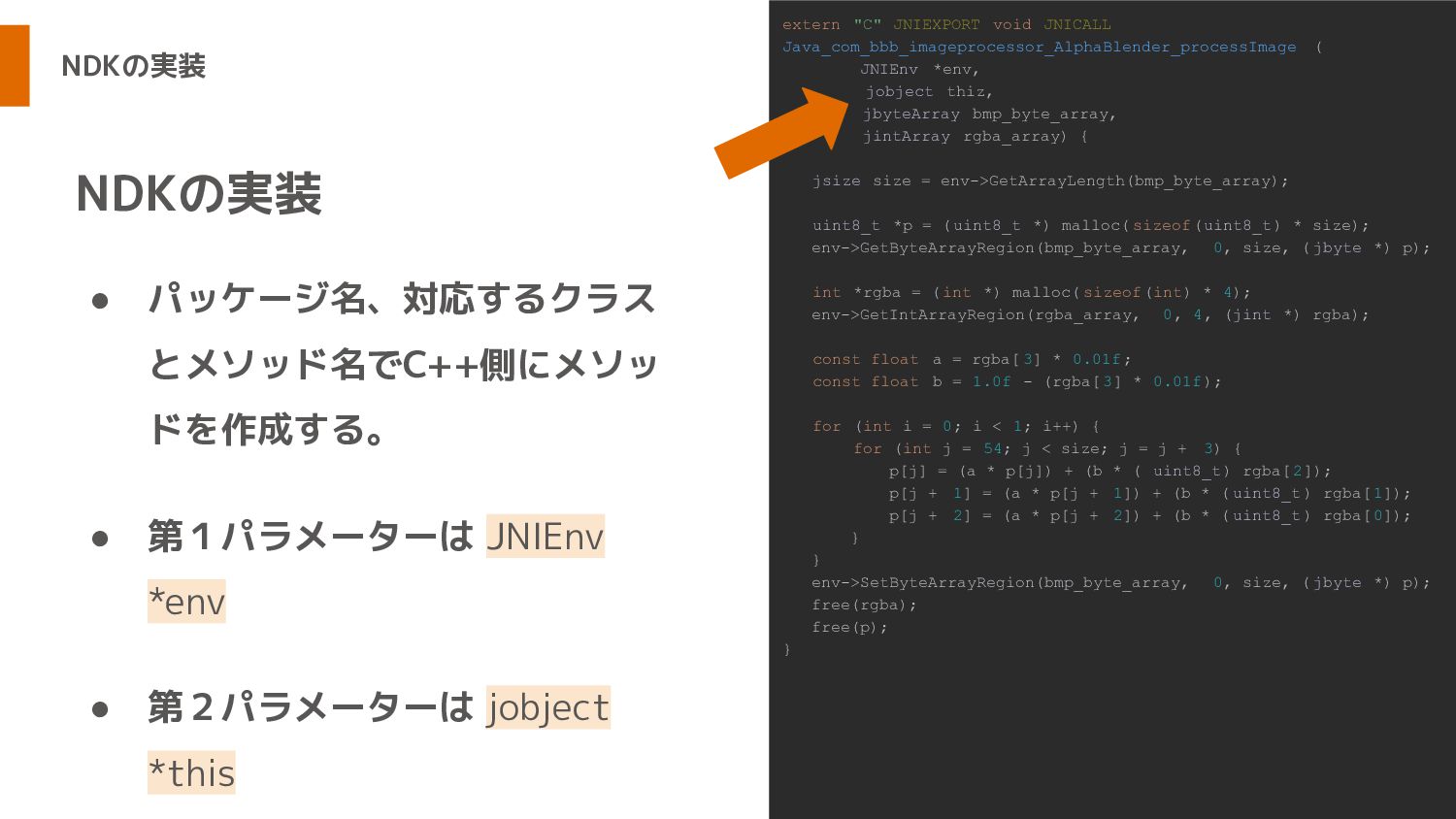
NDKの実装 • パッケージ名、対応するクラス とメソッド名でC++側にメソッ ドを作成する。 • 第1パラメーターは JNIEnv *env •
第2パラメーターは jobject *this NDKの実装 extern "C" JNIEXPORT void JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
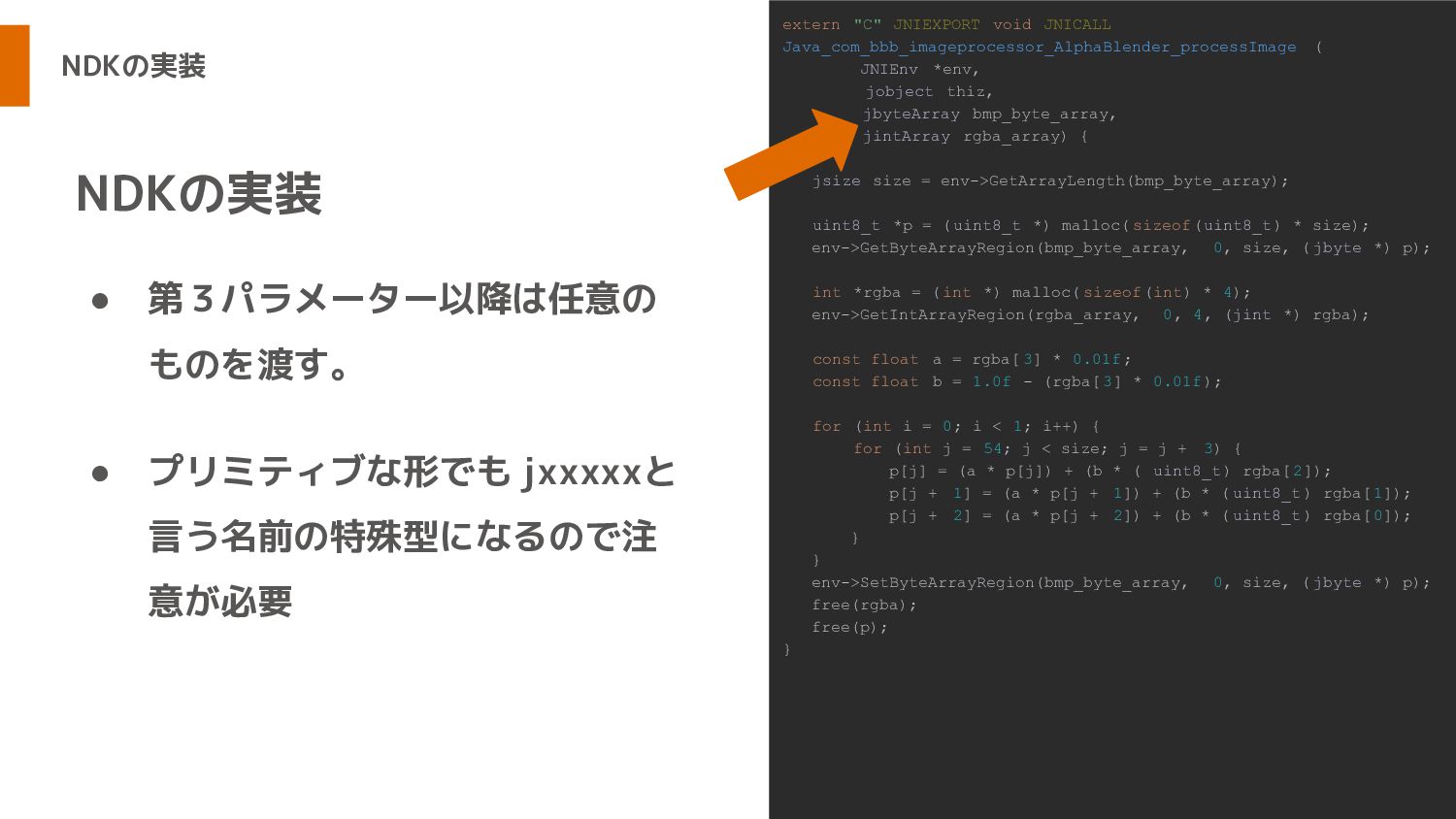
NDKの実装 • 第3パラメーター以降は任意の ものを渡す。 • プリミティブな形でも jxxxxxと 言う名前の特殊型になるので注 意が必要 NDKの実装
extern "C" JNIEXPORT void JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
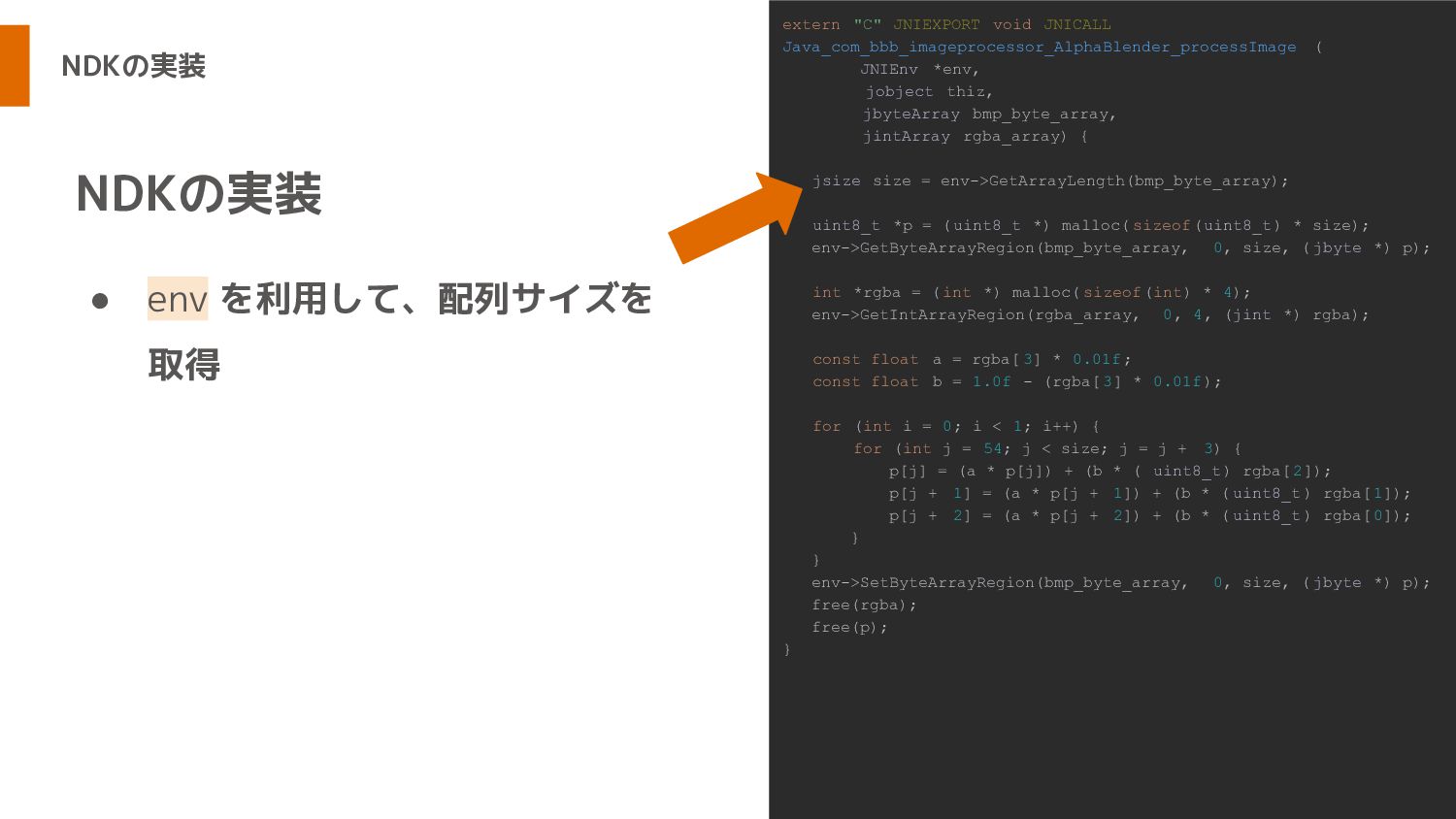
NDKの実装 • env を利用して、配列サイズを 取得 NDKの実装 extern "C" JNIEXPORT void
JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
NDKの実装 • env を利用して、配列サイズを 取得 • malloc 動的に配列を作成。 C/C++は固定値で作成できる配 列に限りがあるため、mallocを
使う • bmp_byte_arrayをpにコピー NDKの実装 extern "C" JNIEXPORT void JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
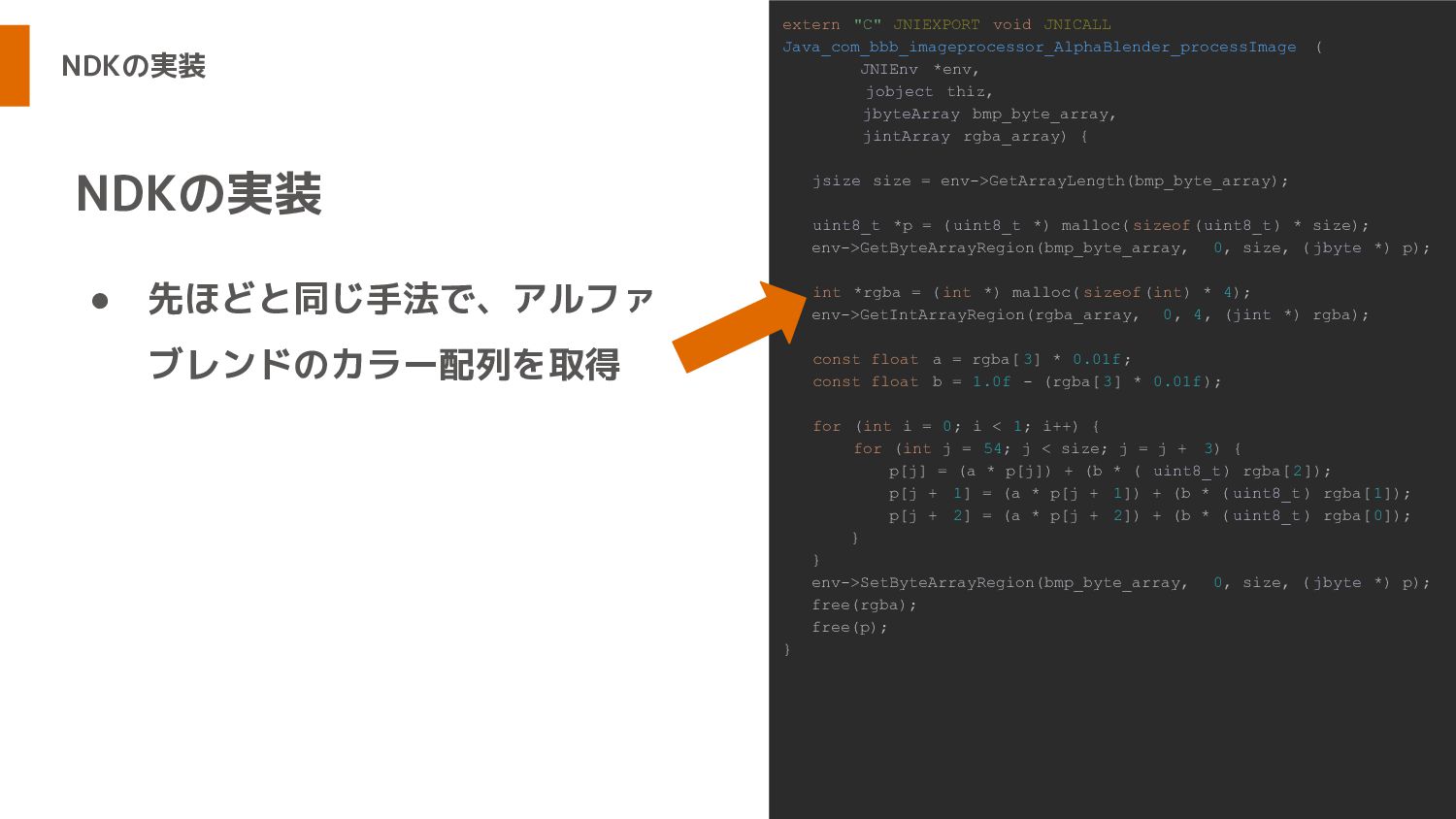
NDKの実装 • 先ほどと同じ手法で、アルファ ブレンドのカラー配列を取得 NDKの実装 extern "C" JNIEXPORT void JNICALL
Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
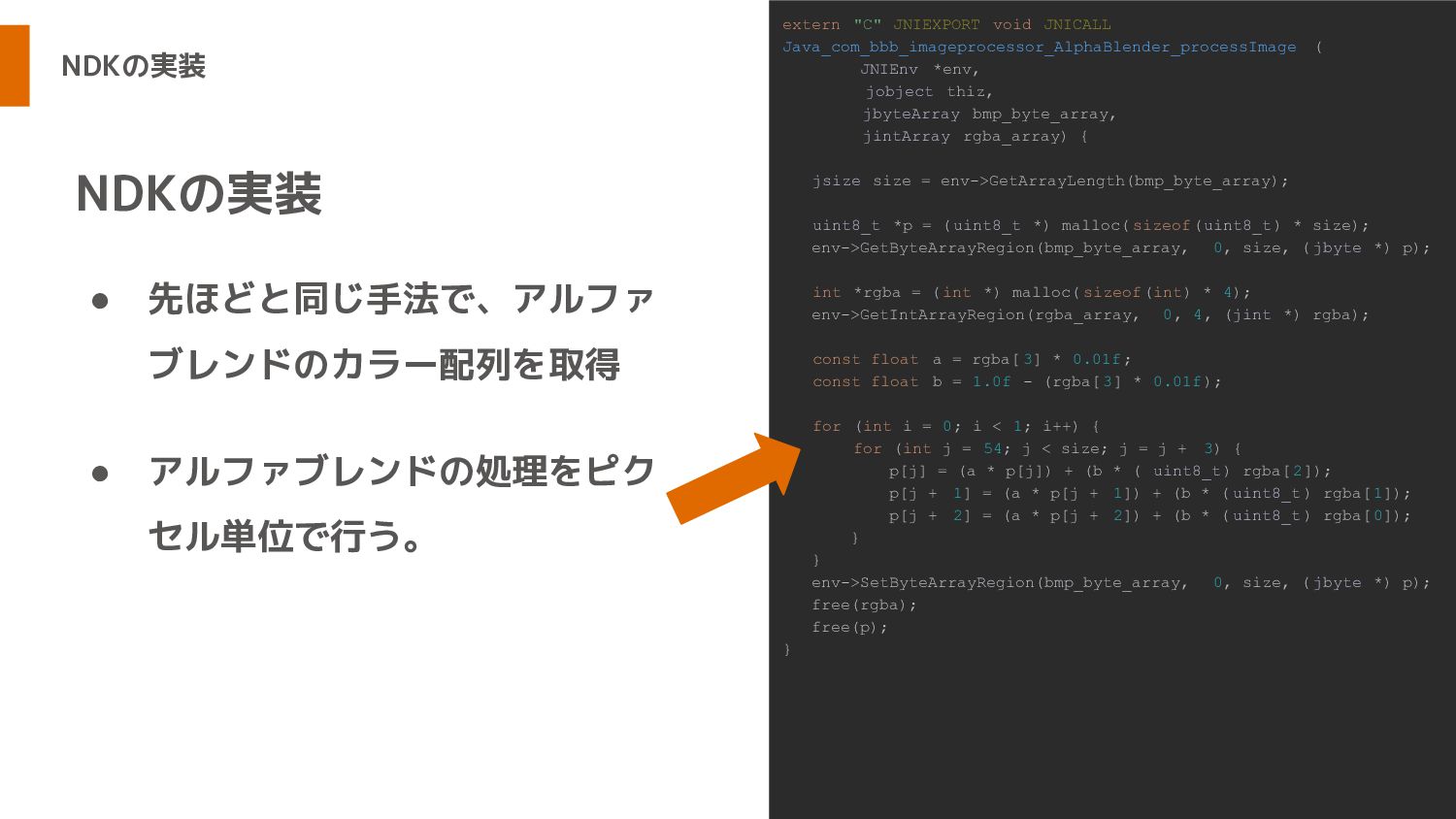
NDKの実装 • 先ほどと同じ手法で、アルファ ブレンドのカラー配列を取得 • アルファブレンドの処理をピク セル単位で行う。 NDKの実装 extern "C"
JNIEXPORT void JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
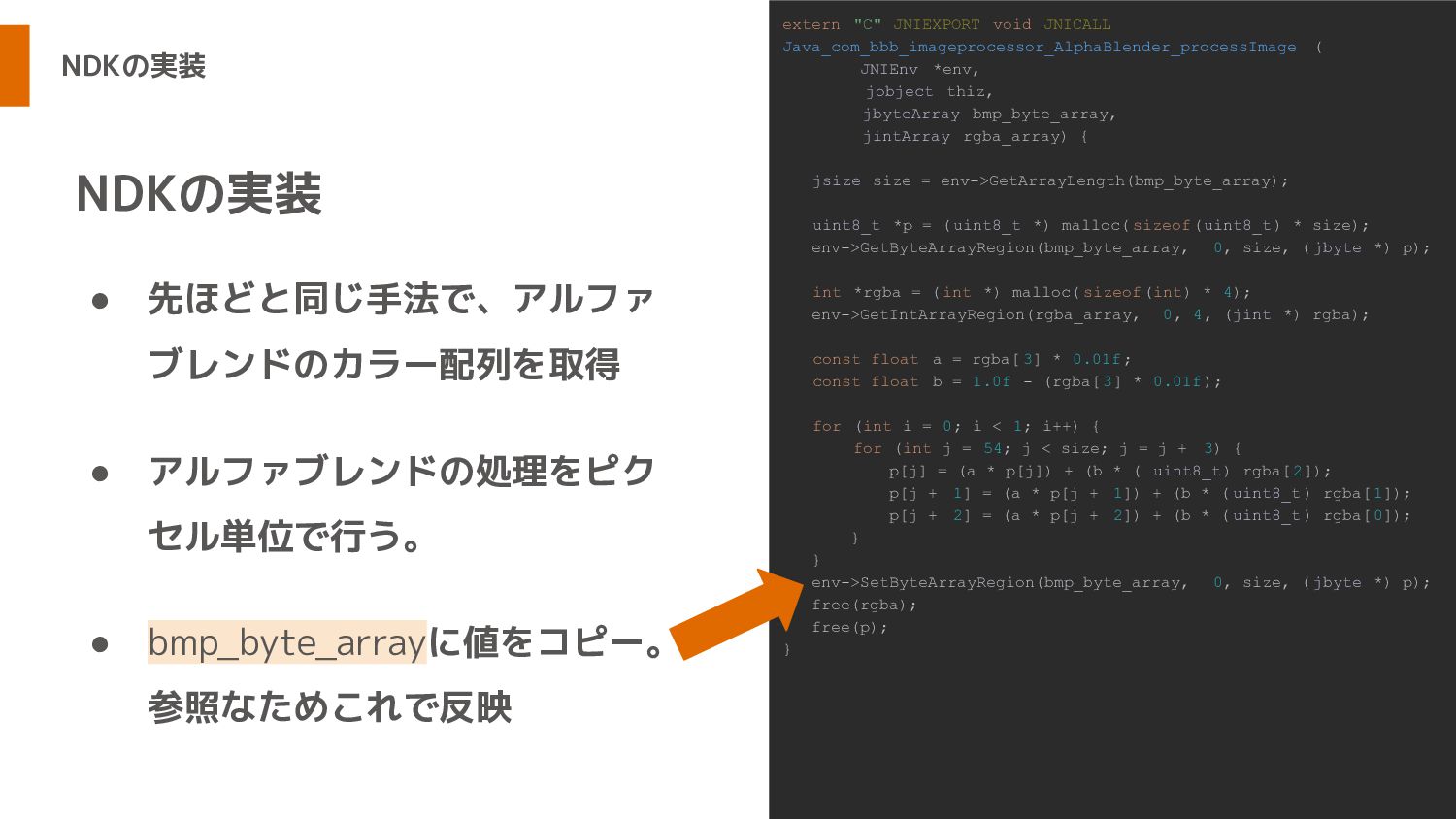
NDKの実装 • 先ほどと同じ手法で、アルファ ブレンドのカラー配列を取得 • アルファブレンドの処理をピク セル単位で行う。 • bmp_byte_arrayに値をコピー。 参照なためこれで反映
NDKの実装 extern "C" JNIEXPORT void JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
NDKの実装 • 確保したメモリーは自動で解放 されないので、ちゃんとお片付 け。 NDKの実装 extern "C" JNIEXPORT void
JNICALL Java_com_bbb_imageprocessor_AlphaBlender_processImage ( JNIEnv *env, jobject thiz, jbyteArray bmp_byte_array, jintArray rgba_array) { jsize size = env->GetArrayLength(bmp_byte_array); uint8_t *p = (uint8_t *) malloc( sizeof(uint8_t) * size); env->GetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); int *rgba = ( int *) malloc( sizeof(int) * 4); env->GetIntArrayRegion(rgba_array, 0, 4, (jint *) rgba); const float a = rgba[ 3] * 0.01f; const float b = 1.0f - (rgba[ 3] * 0.01f); for (int i = 0; i < 1; i++) { for (int j = 54; j < size; j = j + 3) { p[j] = (a * p[j]) + (b * ( uint8_t) rgba[2]); p[j + 1] = (a * p[j + 1]) + (b * ( uint8_t) rgba[1]); p[j + 2] = (a * p[j + 2]) + (b * ( uint8_t) rgba[0]); } } env->SetByteArrayRegion(bmp_byte_array, 0, size, ( jbyte *) p); free(rgba); free(p); }
パフォーマンス
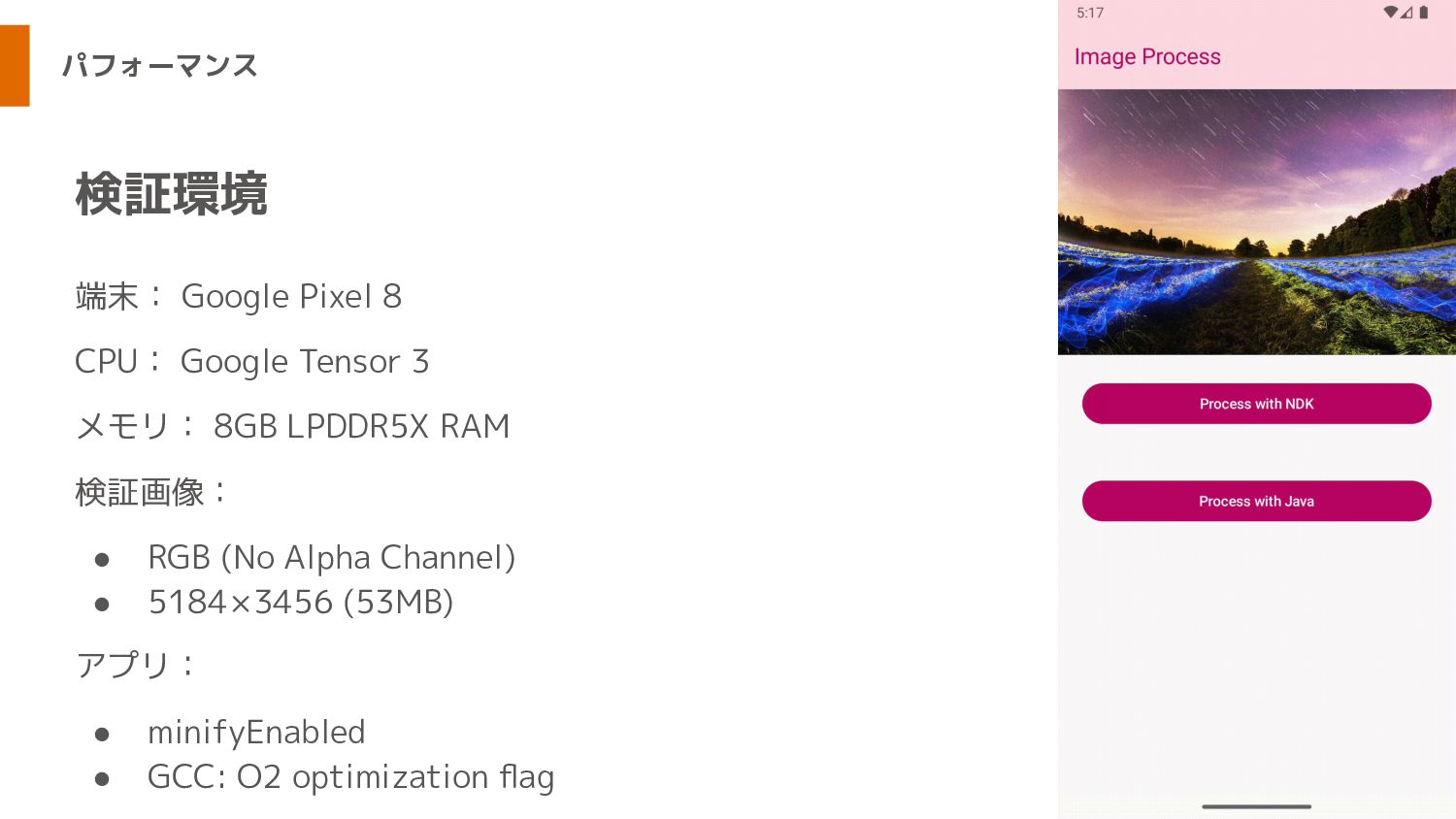
パフォーマンス 端末: Google Pixel 8 CPU: Google Tensor 3 メモリ:
8GB LPDDR5X RAM 検証画像: • RGB (No Alpha Channel) • 5184 × 3456 (53MB) アプリ: • minifyEnabled • GCC: O2 optimization flag 検証環境
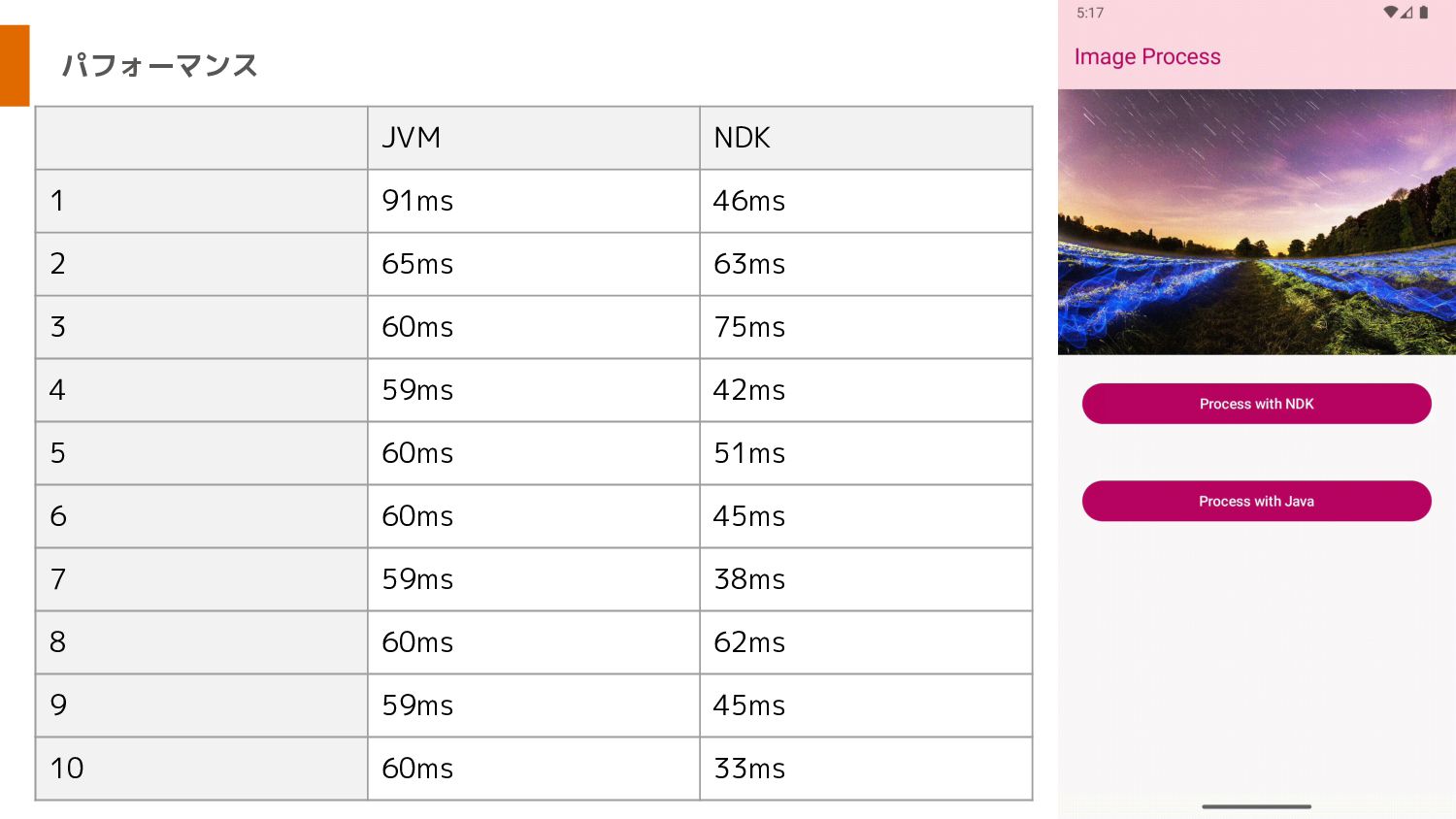
パフォーマンス JVM NDK 1 91ms 46ms 2 65ms 63ms 3
60ms 75ms 4 59ms 42ms 5 60ms 51ms 6 60ms 45ms 7 59ms 38ms 8 60ms 62ms 9 59ms 45ms 10 60ms 33ms
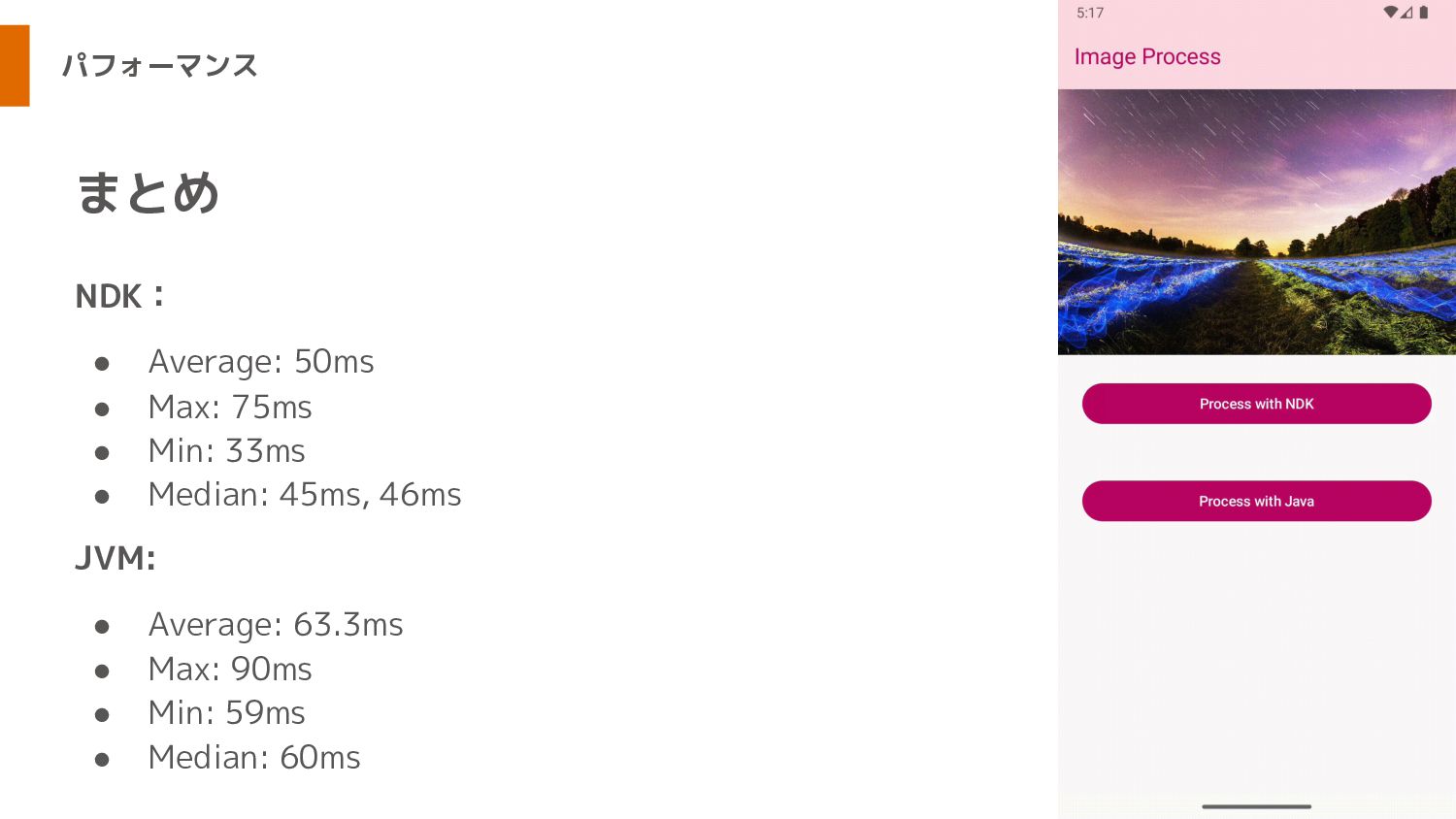
パフォーマンス NDK: • Average: 50ms • Max: 75ms • Min:
33ms • Median: 45ms, 46ms JVM: • Average: 63.3ms • Max: 90ms • Min: 59ms • Median: 60ms まとめ
結論
結論 NDKだから劇的に早くなるものでもない
結論 • NDKだから早いのとは限らない • おそらくC側で使うライブラリで、ハードウェアアクセラレーションが かかる何かを利用している? • 【パフォーマンスチューニング】は大事だが、ゲームアプリのフレーム レート改善でもない限り、msレベルのチューニングは無駄
結論 処理速度のためにNDKの利用の検討は 普通に処理書くだけなら やめた方がいい! (0.016ms|60FPS の世界観は除く)
以上、ありがとうございました!
Sample Repository: ❖ Kotlin 2.0 ❖ Multi-Module with NDK ❖
Jetpack Compose https://github.com/BigBackBoom/hades
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}