ANDY PETRELLA KENSU & ME Started in Belgium by building en enterprise stack for Data Scientists (Agile Data Science Toolkit) Pivot on internal component: Data Science Catalog Focus on Data Science Governance Accelerated by Alchemist Accelerator in San Francisco and The Faktory in Belgium Kensu Inc. in October! Spark Notebook O’Reilly Training
due pessimism Resurgence in 1980s Machine Learning (and related) is used since the 1990s (esp. SVM and RNN) Deep learning see widespread commercial use in 2000s Machine learning receives great publicity (read: buzz) in 2010s 5 ref: https://en.wikipedia.org/wiki/Timeline_of_machine_learning
Patil in 2008. Pretty much where Machine Learning was part of Softwares In a way, when we added “engineering” to the mix Also, engineering is even more prominent with Big Data Distributed Computing 6
tools, libraries, frameworks, … So many things we can try We have distributed computing now, right? => Let’s try everything Discover new insights (and potentially new businesses) 7
on Engineering: ETL, Databases, Computing framework, Softwares, Platforms, … Creativity: “From business intelligence To intelligent business” - Michael Fergusson Data Science is an umbrella on top of all activities on data 8
potentially involving several technologies. A pipeline is generally thought as an End-to-End processing line to solve one problem. But, part of pipelines are reused to save computation, storage, time, … Thus interdependency between pipeline segments grows with initiatives 1 1
for the beauty of it. The ultimate goal is always to take decisions. Decisions are generally taken or linked to humans with responsibilities. (even for self driving cars, in case of problem) Given that pipelines are cutandwired, interleaved, … How not to be anxious at deploying the last piece used by the decision maker 1 2
data used in the process has different patterns suddenly? • one of the tools, projects or similar is modified upstream? • the insights are deviating from the reality? • … 1 3
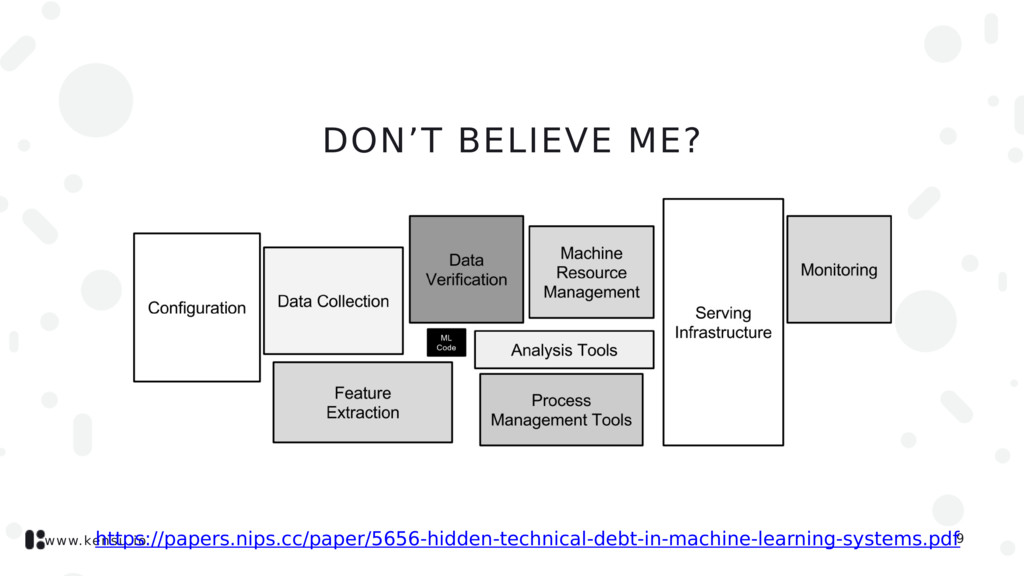
risks, we need ways to debug. In pure engineering, we have unit, function, integrations tests,… but How do we do when the problems come from the data themselves? We can’t generate all cases of data variations, right? How to debug? Without the big picture, we may try to optimise a model for weeks for nothing 1 4
precise standards and involves monitoring against production data. Data Science Governance: control that data activity meets precise standards and involves monitoring against production data activity. A Data Activity is described by at least technologies, users, systems, data, processing 1 5
and where it is done? What is the impact of a process on the global system? What are the performance metrics (quality, execution,…) of the processes? 1 6
view on all the activities applied to the original sources used in his/her own process. They also have a control on their own results in production They have the opportunity to analyse and debug a pipeline involving all activities: • independently of the technologies • involving several people in the enterprise 1 7
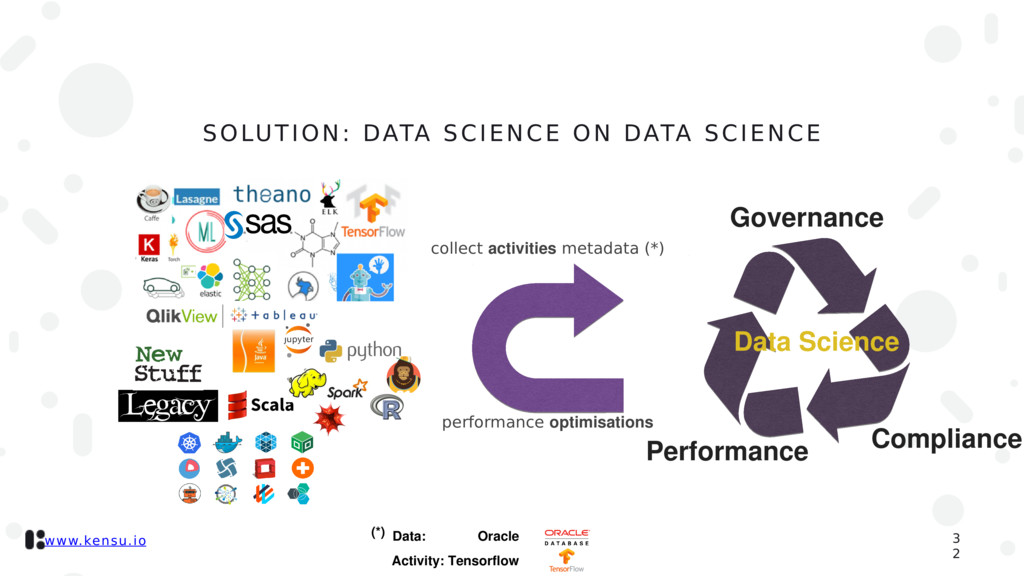
the right data to take right decision. First run an assessment to create a high level map of all the tools involved into a company. For each tool, do whatever it takes to collect information about the activities it is creating. Information are metadata, lineage, statistics, accuracy measures, … 2 0
picture. To do that we need to connect all data that can be collected. So that, it is possible to create a cartography of all on-going processes. This map tracks all data and their descendants 2 1
starts… the map of data activities is an amazing source of information Here are a few things you can think of when using this kind of data: • impact analysis • dependency analysis • optimisation • recommendation 2 2
ensure and demonstrate that you comply. This may include internal data protection policies such as staff training, internal audits of processing activities, and reviews of internal HR policies. 2 4
clear and transparent privacy policies, if your organisation has more than 250 employees, you must maintain additional internal records of your processing activities. 2 5
as a continuous integration solution: we have to explain and measure activities independently of the technologies. With this information we can reliably create transparent reports of activities across the whole chain of processing 2 7
Science Governance First Governance, Compliance and Performance solution for Data science Feature Benefit Why it matters Connect.Collect.Learn Automatically captures all data science relevant activities related to governance, compliance and performance within a given domain. Provided endtoend control and insights into all relevant aspects of data science related activities #GDPR DPO Dashboard Onestop control center for all potential data privacy violations Nearrealtime notifications and actionable intelligence current state of “compliance health” #GDPR Compliance Reporting Oneclick reports for all relevant governance and compliance reports Guarantee for good relationship with authorities in charge by respecting their templates #GDPR
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}