Series Data Storage • Business Use Case — Time Series Data Aggregation • The Solution • Inspiration • Intuitions — Functions, Monads & Applicatives • Code
Series Data Storage • Business Use Case — Time Series Data Aggregation • The Solution • Inspiration • Intuitions — Functions, Monads & Applicatives • Code • Future Work
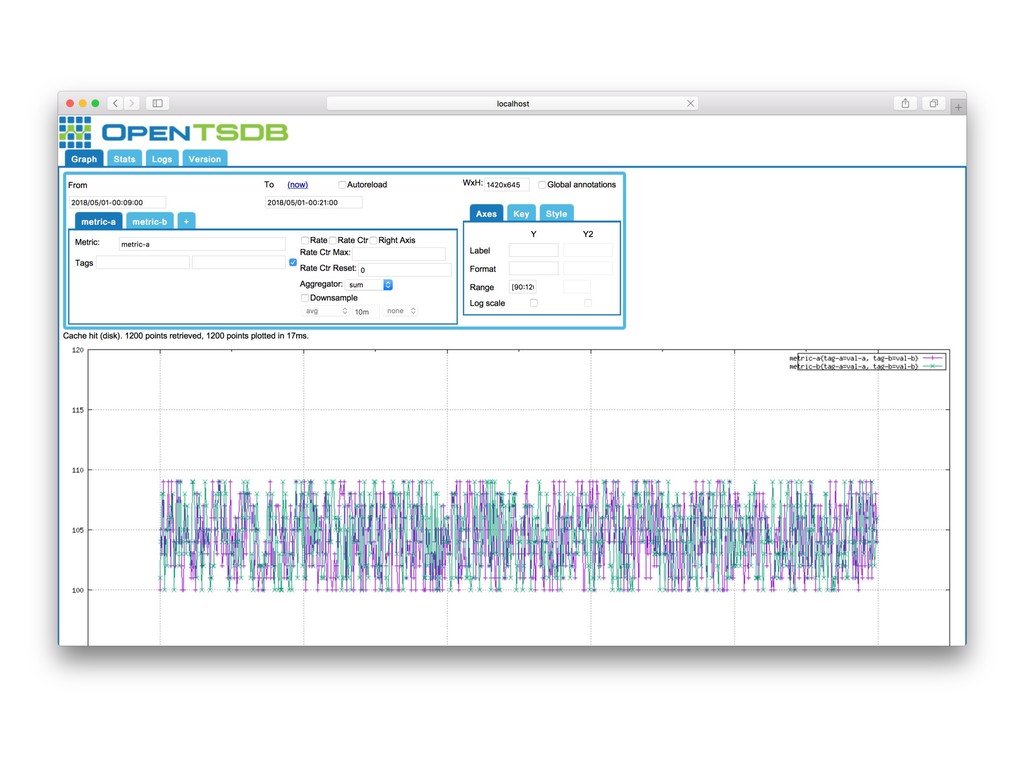
• Basis for end-of-month reports • Past: everything computed at end of month from raw OpenTSDB data • Now: pre-compute aggregations continuously at various frequencies, e.g., 5 minutes, and use these for reporting
• Basis for end-of-month reports • Past: everything computed at end of month from raw OpenTSDB data • Now: pre-compute aggregations continuously at various frequencies, e.g., 5 minutes, and use these for reporting • We call these aggregations roll-ups
• Basis for end-of-month reports • Past: everything computed at end of month from raw OpenTSDB data • Now: pre-compute aggregations continuously at various frequencies, e.g., 5 minutes, and use these for reporting • We call these aggregations roll-ups • Decreases time to generate reports
??? def bar(): Task[String] = ??? // No data dependency between function calls. val a = foo() val b = bar() val c = a.flatMap(_ => b) // sequential val d = (a, b).mapN((a, b) => ...) c.unsafeRunSync()
model time series data fetching and constrain its usage to an Applicative interface. Then, statically analyze the EDSL to batch and deduplicate issued queries before making the actual network calls.
If a type is a monadic, a lawful Applicative instance has to be sequential. This is why Cats exposes a Parallel type-class, inspired by PureScript, which allows client code to choose between semantically-sequential and semantically-parallel Applicative instances.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def rollup(metric: List[Datapoint]): Double](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
: B =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_51.jpg){kind=link}
: B =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_52.jpg){kind=link}
: B =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_53.jpg){kind=link}
: B =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![// Effectful functions; encoded in signature. def foo(): Task[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_65.jpg){kind=link}
![// Effectful functions; encoded in signature. def foo(): Task[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_66.jpg){kind=link}
![// Effectful functions; encoded in signature. def foo(): Task[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_67.jpg){kind=link}
![// Effectful functions; encoded in signature. def foo(): Task[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_68.jpg){kind=link}
{kind=link}
![// Effectful functions; encoded in signature. def foo(): IO[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_70.jpg){kind=link}
![// Effectful functions; encoded in signature. def foo(): IO[String] =](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Call for Presentations [email protected]](https://files.speakerdeck.com/presentations/947c19460d964aff9d046d9691a277c4/slide_82.jpg){kind=link}
{kind=link}
{kind=link}