problems: • When a blocking I/O operation occurs, everything in that thread halts and waits; potentially idle system resources • Internally, that “blocking” operation is a big loop per operation asking “Are we there yet?” • “Idleness” occurs because the thread waiting for I/O to complete is doing nothing while it waits • This can vastly limit our ability to scale Friday, October 19, 12
Eschew blocking individually on each operation • Find ways to work with the kernel to more efficiently manage multiple blocking resources in groups • Now that threads aren’t “stuck” when waiting on I/O... • Reuse “waiting” threads to handle other requests • Resume execution when I/O completes Friday, October 19, 12
longer blocking and instead reusing threads while I/O waits, we need a way to handle “completion” events • Asynchronous techniques (such as callbacks) allow us to achieve this • “Step to the side of the line, and we’ll call you when your order is ready” Friday, October 19, 12
us into some paradigms • Servers • A 1:1 ratio of threads to client connections (scale limited) • Clients • Connection pools often larger • More connection threads to mitigate “unavailable-while-blocking” connections Friday, October 19, 12
change our destiny • Servers • <Many Client Connections>:<One Thread> Ratio becomes possible (Scale - C10K and beyond) • Threads hand blocking I/O to kernel and return to available pool (reusability!) • Some ops, such as “write” may queue up (often behind the scenes) until resource is available.. callback on completion • Of course, this makes dispatch and good concurrency even tougher (Who said doing things right was ever easy?) Friday, October 19, 12
change our destiny •Clients • Significantly reduce pool sizes • connection resources can be reused simultaneously by multiple threads Friday, October 19, 12
1.4 • Focus on low-level I/O as opposed to “Old” I/ O’s high level-API • Introduced ByteBuffers: http://www.kdgregory.com/ index.php?page=java.byteBuffer Friday, October 19, 12
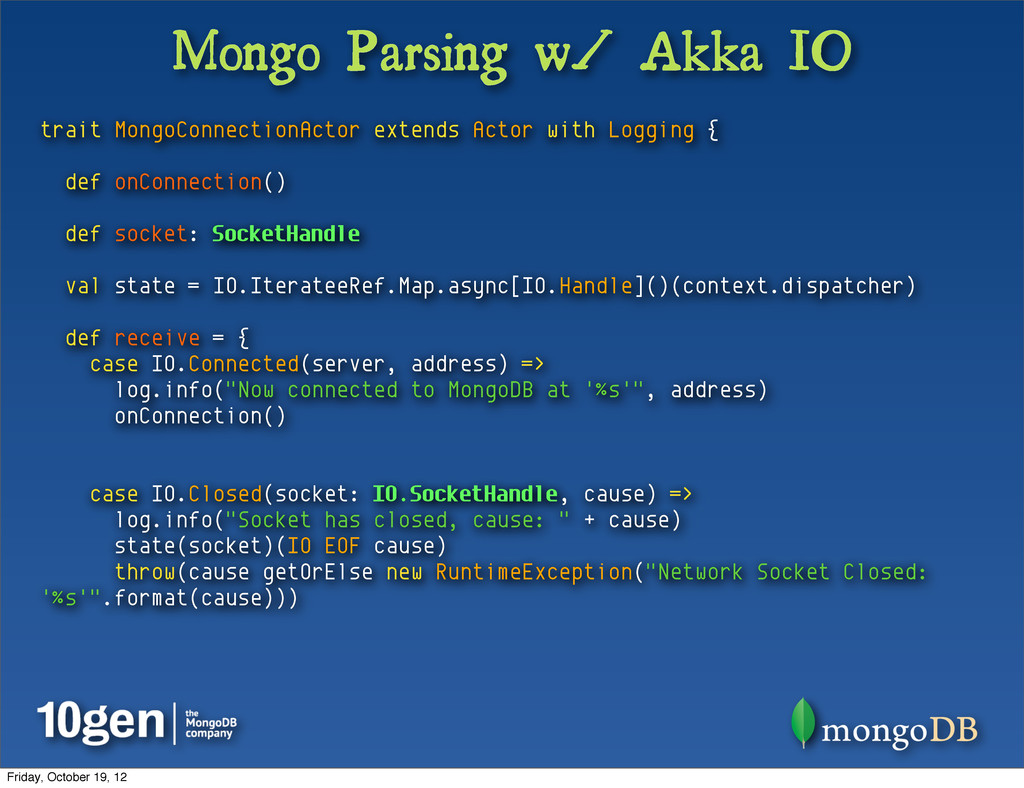
Selector • Selector is an event monitor, watching multiple Channel instances from one thread (the kernel coordinator) • Relocates the task of checking I/O status out of the “execution” threads Friday, October 19, 12
• Register “Interests” with a Selector (Read, Write, etc) • Write a Selector loop which checks for notification events • Dispatch incoming events (such as “read”) • Want to write? Tell the Selector you want to write • Eventually, when the Channel is available to write, an event will notify the Selector • Remove “interested in writing” status • Dispatch “time to write” to original caller • Write • Rinse, repeat. Friday, October 19, 12
access to “Old” IO Layer) • Really, just wrapping NIO to provide higher level abstraction • Hides the Selector nonsense away • Composable “Filter Pipeline” allows you to intercept multiple levels of input and output Friday, October 19, 12
Organize individual pieces in one composite buffer • Supports ByteBuffer, Arrays, etc • Avoid memory copy as much as possible • Direct Memory allocated (rumors of memory leaks abound) Friday, October 19, 12
Boss")), Executors.newCachedThreadPool(ThreadFactories("Hammersmith Netty Worker"))) protected implicit val bootstrap = new ClientBootstrap(channelFactory) bootstrap.setPipelineFactory(new ChannelPipelineFactory() { private val appCallbackExecutor = new ThreadPoolExecutor(/** constructor snipped for slide sanity */) private val appCallbackExecutionHandler = new ExecutionHandler(appCallbackExecutor) def getPipeline = { val p = Channels.pipeline(new ReplyMessageDecoder(), appCallbackExecutionHandler, handler) p } }) bootstrap.setOption("remoteAddress", addr) private val _f = bootstrap.connect() protected implicit val channel = _f.awaitUninterruptibly.getChannel Friday, October 19, 12
plot element that catches the viewers’ attention or drives the plot of a work of fiction” (Sometimes “maguffin” or “McGuffin” as well) Friday, October 19, 12
Server • This is a project I’ve already spent a good bit of time on – Hammersmith • Hammersmith is an attempt to create a pure scala Asynchronous driver for MongoDB • A few focal points to lead our discussion • Decoding & dispatching inbound messages • Handling errors & exceptions across threads, time, and space • “Follow up” operations which rely on serverside “same connection” context • Working with multi-state iterations which depend on IO for operations... a.k.a. “Database Cursors” Friday, October 19, 12
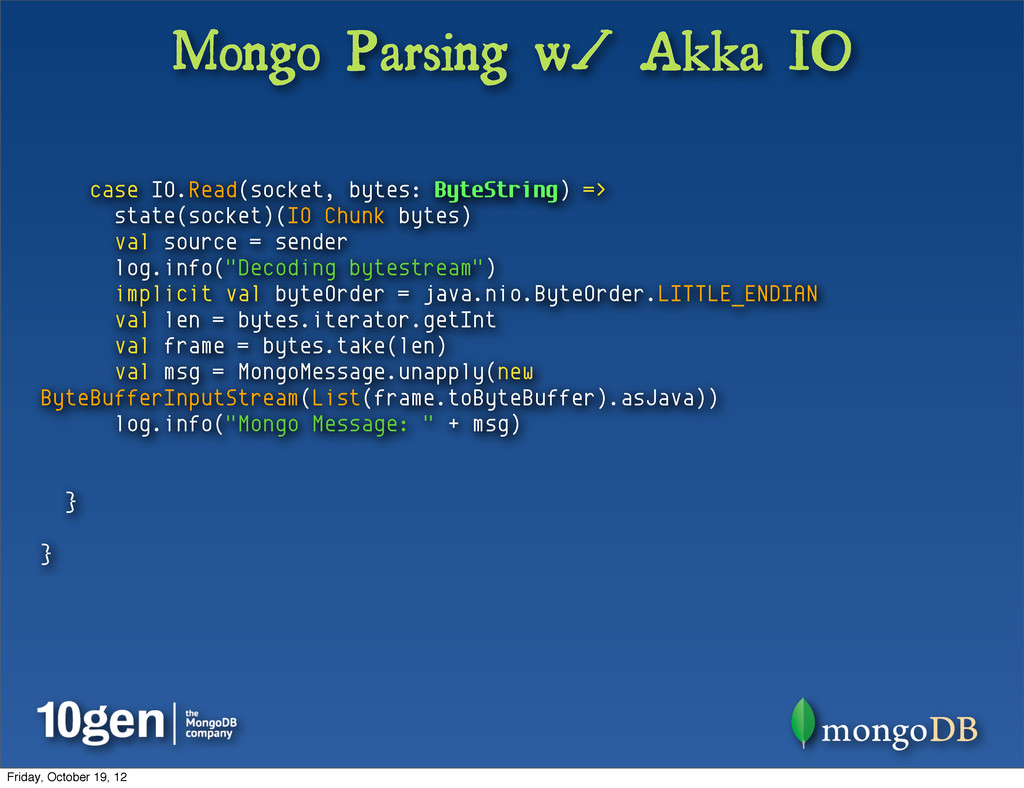
• Network layers don’t know or care about your fancy application layer protocol • The kernel reads things off the network into a big buffer of bytes • It’s up to us to figure out what parts of the bytes are relevant where Friday, October 19, 12
individual writes and send them to the right place • Conceptually, “Law of Demeter” (loose coupling) helps here. Doing it by hand you have to be careful not to eat somebody else’s lunch • NIO leaves you on your own • Netty’s pipeline helps provide the “don’t eat my lunch” fix quite well Friday, October 19, 12
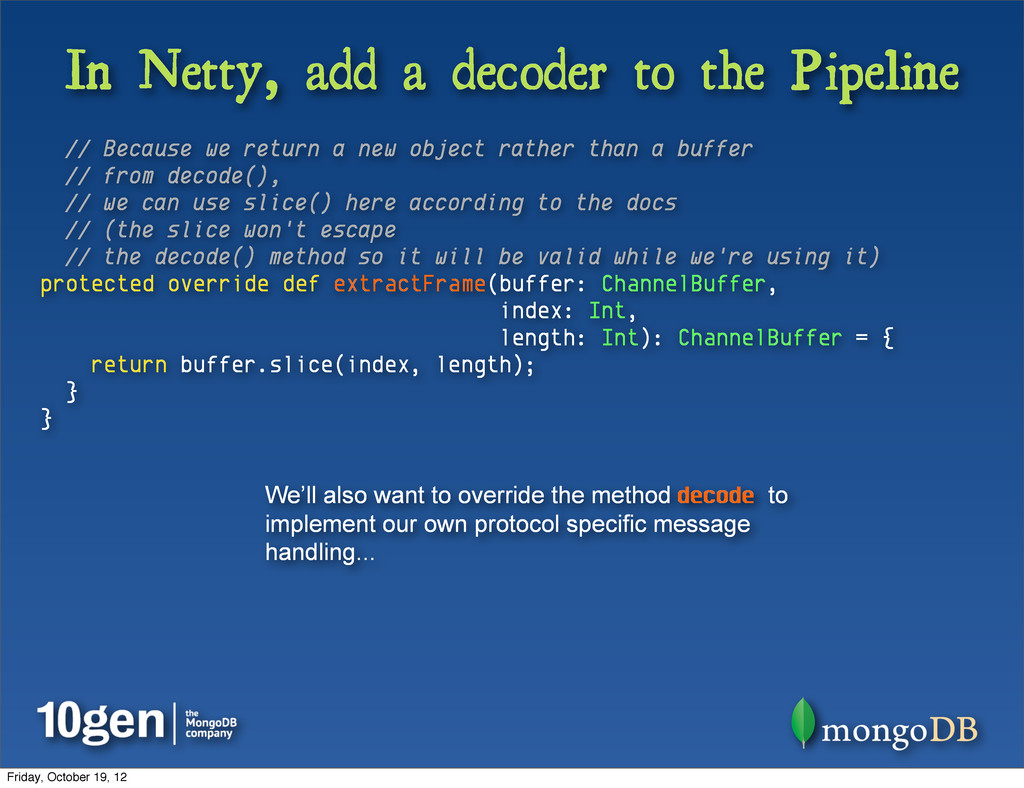
extends LengthFieldBasedFrameDecoder(1024 * 1024 * 16, 0, 4, -4, 0) LengthFieldBasedFrameDecoder is an abstract Netty class that can automatically decode protocol packets (frames) with a fixed length. To implement, we must define a method extractFrame which specifies how to decode the protocol packet Friday, October 19, 12
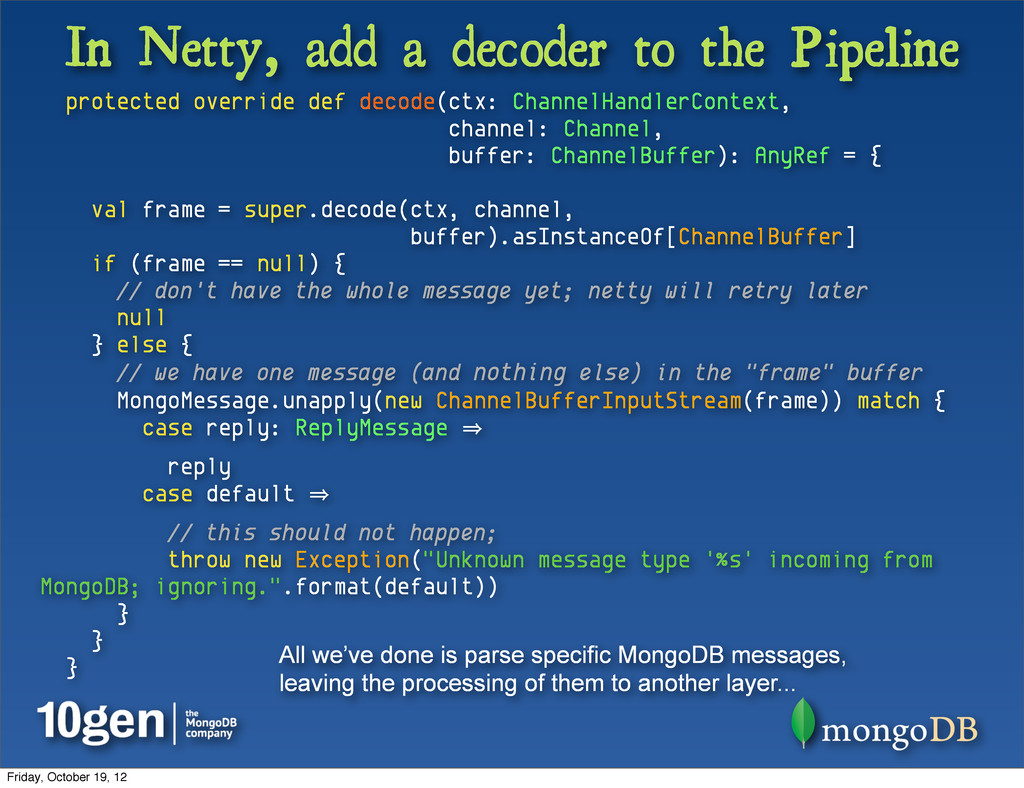
we return a new object rather than a buffer // from decode(), // we can use slice() here according to the docs // (the slice won't escape // the decode() method so it will be valid while we're using it) protected override def extractFrame(buffer: ChannelBuffer, index: Int, length: Int): ChannelBuffer = { return buffer.slice(index, length); } } We’ll also want to override the method decode to implement our own protocol specific message handling... Friday, October 19, 12
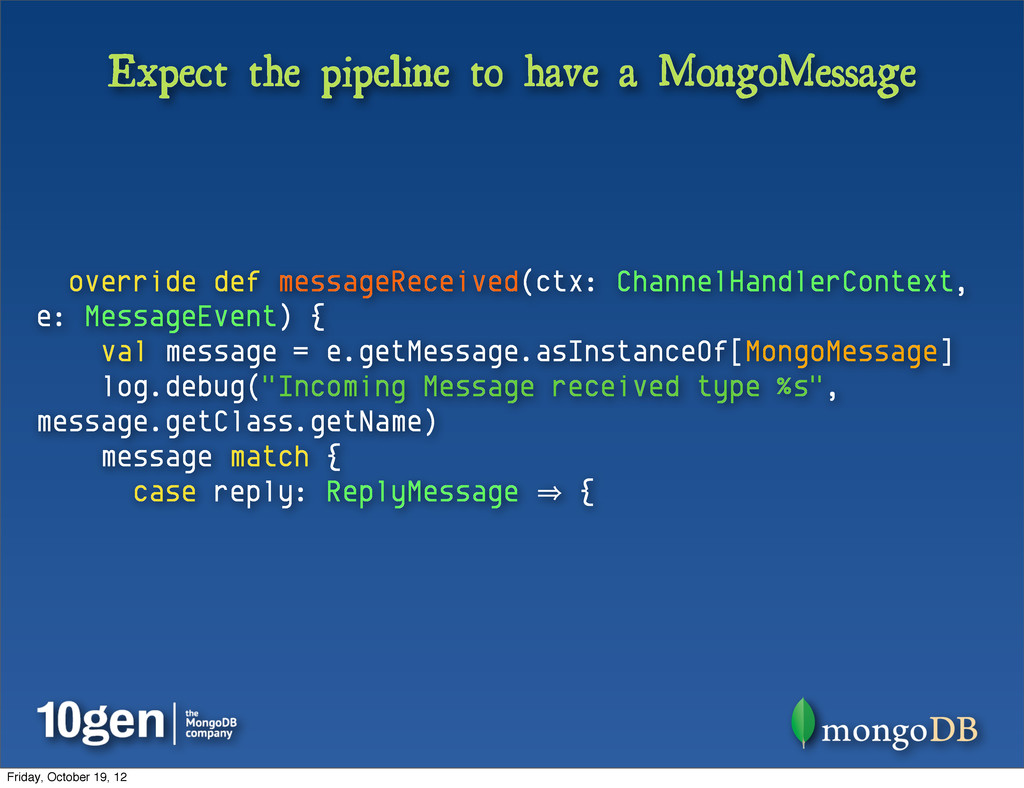
def decode(ctx: ChannelHandlerContext, channel: Channel, buffer: ChannelBuffer): AnyRef = { val frame = super.decode(ctx, channel, buffer).asInstanceOf[ChannelBuffer] if (frame == null) { // don't have the whole message yet; netty will retry later null } else { // we have one message (and nothing else) in the "frame" buffer MongoMessage.unapply(new ChannelBufferInputStream(frame)) match { case reply: ReplyMessage 㱺 reply case default 㱺 // this should not happen; throw new Exception("Unknown message type '%s' incoming from MongoDB; ignoring.".format(default)) } } } All we’ve done is parse specific MongoDB messages, leaving the processing of them to another layer... Friday, October 19, 12
ChannelHandlerContext, e: MessageEvent) { val message = e.getMessage.asInstanceOf[MongoMessage] log.debug("Incoming Message received type %s", message.getClass.getName) message match { case reply: ReplyMessage 㱺 { Friday, October 19, 12
has a great construct to help with this: Either[L, R] • Pass a monad that can have one of two states: • Failure or Success • By convention, “Left” is an Error, “Right” is success • Node does a similar passing of Success vs. Result Friday, October 19, 12
Either[L, R] • No special “different” handling in Netty vs. NIO •Implicit tricks for the lazy who want to just write a “success” block Friday, October 19, 12
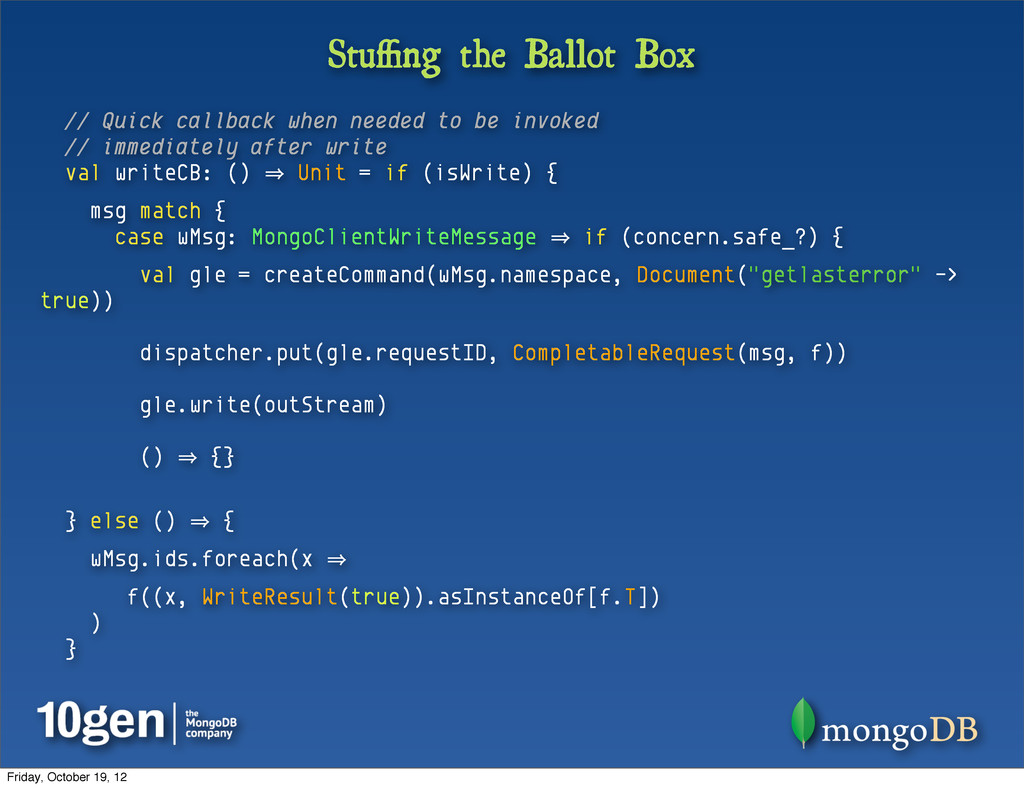
RequestFutures.write( (result: Either[Throwable, (Option[AnyRef], WriteResult)]) 㱺 { result match { case Right((oid, wr)) 㱺 { // success, w/ data about the write ok = Some(true) id = oid } case Left(t) 㱺 { // ignominy & failure, w/ a throwable ok = Some(false) log.error(t, "Command Failed.") } } } ) mongo.insert(Document("foo" -> "bar", "bar" -> "baz"))(handler) case Right((oid, wr)) 㱺 { // success, w/ data about the write ok = Some(true) id = oid } case Left(t) 㱺 { // ignominy & failure, w/ a throwable ok = Some(false) log.error(t, "Command Failed.") } Friday, October 19, 12
f: (Option[AnyRef], WriteResult) 㱺 Unit ): WriteRequestFuture = SimpleRequestFutures.write(f) def write(f: (Option[AnyRef], WriteResult) 㱺 Unit) = new WriteRequestFuture { val body = (result: Either[Throwable, (Option[AnyRef], WriteResult)]) 㱺 result match { case Right((oid, wr)) 㱺 f(oid, wr) case Left(t) 㱺 log.error(t, "Command Failed.") } } Now, if the user chooses to skip a custom error handler we can register a default (or even “global”) one automatically, via implicits... implicit def asSimpleWriteOp( f: (Option[AnyRef], WriteResult) 㱺 Unit ): WriteRequestFuture = SimpleRequestFutures.write(f) Friday, October 19, 12
etc. have contextual operations as “follow ups” to a write, which can only be called on the same connection as the write • MySQL has last_insert_id() to fetch the lastgenerated auto increment ID • MongoDB has getLastError() to check success/failure of a write (and explicitly specify consistency requirements) Friday, October 19, 12
followups: “Do this, then that” • Somewhat easy in a synchronous framework • Lock the connection out of the pool and keep it private • Don’t let anyone else touch it until you’re done • In Async, harder • Only solution I’ve found is “ballot box stuffing” • Deliberate reversal of the “decoding problem” Friday, October 19, 12
iteration, we are working with a dual-state monad • Two primary calls on an Iterator[A] • hasNext: Boolean • next(): A • In a pure and simple form, the Iterator[A] is prepopulated with all of its elements. • If the buffer is non-empty, hasNext == true and next() returns another element. • When the buffer is *empty*, iteration halts completely. • hasNext == false • next() == null ( throws an exception or similar ) Friday, October 19, 12
simple database, a query would return a batch of all of the query results, populating an Iterator[DBRow] • This maps nice and simply to the Iterator[A] monad • Details hidden behind abstraction, client shouldn’t know if we are synchronous or asynchronous • The reality? Forcing a client to buffer all results to a large query is inefficient • Do you have enough memory on the client side for the entire result set? • With async, we may have a lot of potentially large result sets buffered Friday, October 19, 12
return an initial batch of results • If there are more results available on the server a “Cursor ID” is returned w/ the batch • Client can use getMore to fetch additional batches • Eventually, server-side results exhausted • getMore will return a batch and a Cursor ID of 0 (indicating “no more results”) • Try doing this cleanly without blocking... Friday, October 19, 12
have 3 states with a Cursor • Has Local Entries • Local Empty - More On Server • All Results Exhausted • The typical solution in a synchronous driver • hasNext: Boolean • “Is the local buffer non-empty?” || “are there more results on the server?” • next: A • If non-empty local buffer, return item • If more on server, call getMore (Smarter code could be “predictive” about this and prefetch ahead of need) Friday, October 19, 12
that block on getMore will put you in the weeds • The goal is less threads, with each doing more work • Blocking on reads is bad, and will quickly defeat our asynchronous frameworks (such as Netty) • While blocking, thread halts any other execution • Blocking for getMore will block all of the interleaved ops Friday, October 19, 12
this problem with Hammersmith • It initially led to heavy drinking • John De Goes (@jdegoes) [Precog] and Josh Suereth (@jsuereth) [Typesafe] suggested Iteratees as a solution • Reading Haskell white papers and scalaz code made my brain hurt... • ... As such, what follows is *my interpretation* and any mistakes & stupidity are entirely my own Friday, October 19, 12
• Pass a function which takes an argument of “Iteration State” • Return “Iteration Commands” based on the state • A command wraps a function of the same type (chained invocation) • Code becomes asynchronous • If “Local Empty - More On Server” then getMore can be non-blocking • Pass a copy of the current method with the getMore command • Iteration continues after buffer replenishment Friday, October 19, 12
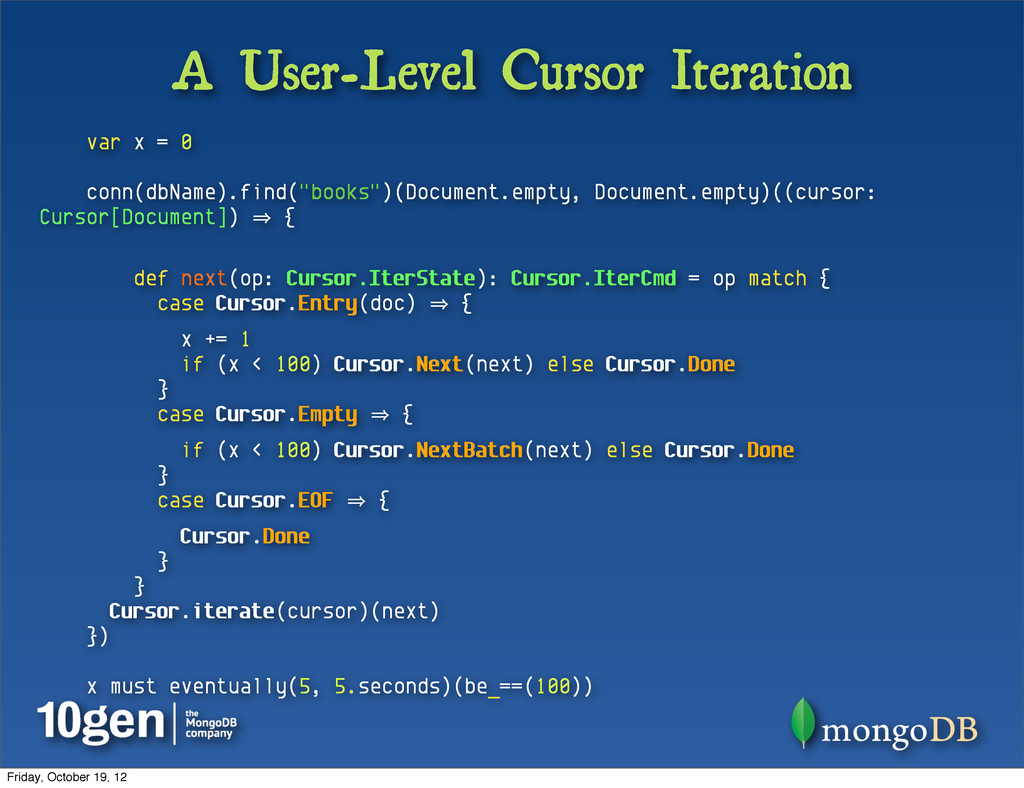
fun! case class Entry[T: SerializableBSONObject](doc: T) extends IterState // Client buffer empty, but more on server case object Empty extends IterState // Both client buffer and server are exhausted case object EOF extends IterState Friday, October 19, 12
cursor - clean it up, shut it down, take out the trash case object Done extends IterCmd // Go get me an item to work on ... here’s a function to handle all states case class Next(op: (IterState) 㱺 IterCmd) extends IterCmd // Call getMore & retrieve another batch - here’s a function to handle all states case class NextBatch(op: (IterState) 㱺 IterCmd) extends IterCmd Friday, October 19, 12
try { if (docs.length > 0) Cursor.Entry(docs.dequeue()) else if (hasMore) Cursor.Empty else Cursor.EOF } catch { // just in case // error handling... } def iterate = Cursor.iterate(this) _ This internal method determines the current “State” of the Cursor Friday, October 19, 12
def next(f: (IterState) 㱺 IterCmd): Unit = f(cursor.next()) match { case Done 㱺 { cursor.close() } case Next(tOp) 㱺 { next(tOp) } case NextBatch(tOp) 㱺 cursor.nextBatch(() 㱺 { next(tOp) }) } next(op) } This default method can walk the Iteratee function, and has pre-baked responses to standard Commands Friday, October 19, 12
Cursor[Document]) 㱺 { def next(op: Cursor.IterState): Cursor.IterCmd = op match { case Cursor.Entry(doc) 㱺 { x += 1 if (x < 100) Cursor.Next(next) else Cursor.Done } case Cursor.Empty 㱺 { if (x < 100) Cursor.NextBatch(next) else Cursor.Done } case Cursor.EOF 㱺 { Cursor.Done } } Cursor.iterate(cursor)(next) }) x must eventually(5, 5.seconds)(be_==(100)) Friday, October 19, 12
is a way to better optimize my networking layer • Though some like it, I find the Netty model to be a bit cumbersome • I love the Akka model, using discreet Actors to handle messaging • Akka 2.0+ Introduced “Akka IO” • Wrappers to NIO • Iteratee based API • Actor invoked with Iteratee messages (e.g. Open, Close, Read, etc) • A quick look at an attempt to port Hammersmith... Friday, October 19, 12
level async API to NIO without going as high level as Netty does • NIO.2 / AIO brings in “AsynchronousSocketChannels” • Removes need to select / poll by hand • Configurable timeouts • Two options for how to get responses; both sanely map to Scala • java.util.concurrent.Future • CompletionHandler • Easily logically mapped to Either[E, T] with implicits • Probably not ‘prime time’ usable for library authors *yet* ... due to dependency on JDK7 Friday, October 19, 12
![Brendan McAdams 10gen, Inc. [email protected] @rit Asynchronous + Non-Blocking Scala](https://files.speakerdeck.com/presentations/50812b4b5b45fd0002028666/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![sealed trait RequestFuture { type T val body: Either[Throwable, T]](https://files.speakerdeck.com/presentations/50812b4b5b45fd0002028666/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(op: (IterState) 㱺 IterCmd) {](https://files.speakerdeck.com/presentations/50812b4b5b45fd0002028666/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Want to Know More About MongoDB?] Free Online Classes, Starting](https://files.speakerdeck.com/presentations/50812b4b5b45fd0002028666/slide_58.jpg){kind=link}