The dirty little secret about DevOps is that everybody talks about what it means for operations teams, and hardly anybody talks about what it means for software engineers. Which is possibly even more important!
Operations is not really a dedicated role, it is more like a social contract. Your ops org consists of all the skills, habits, tribal knowledge, and cultural values you have built up around delivering software, and every single engineer (and execs, and customer support) participates in this org. Engineering teams tend to struggle when software engineers don't have the operational skills they need to truly own their own services, and don't know how to learn those skills, and may not even understand why they should care.
So: how do you help your software engineers develop their ops muscles? How do you interview and hire for engineers who will enthusiastically co-create a vibrant ops culture? How do you identify and reward the heroes doing the silent, unsung work of paying down technical debt and shipping stable software? We'll talk about how to create the kind of tight feedback loops that help engineers improve their craft, prevent burnout, and encourage a healthy, fun, collaborative culture of operational excellence.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
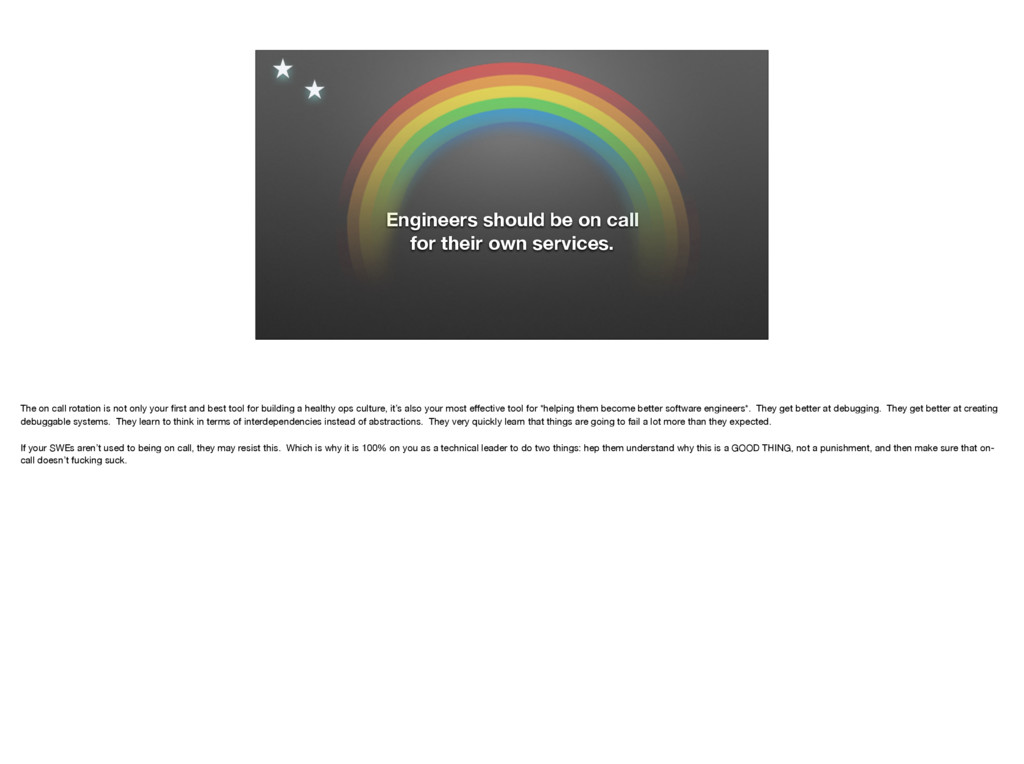{kind=link}
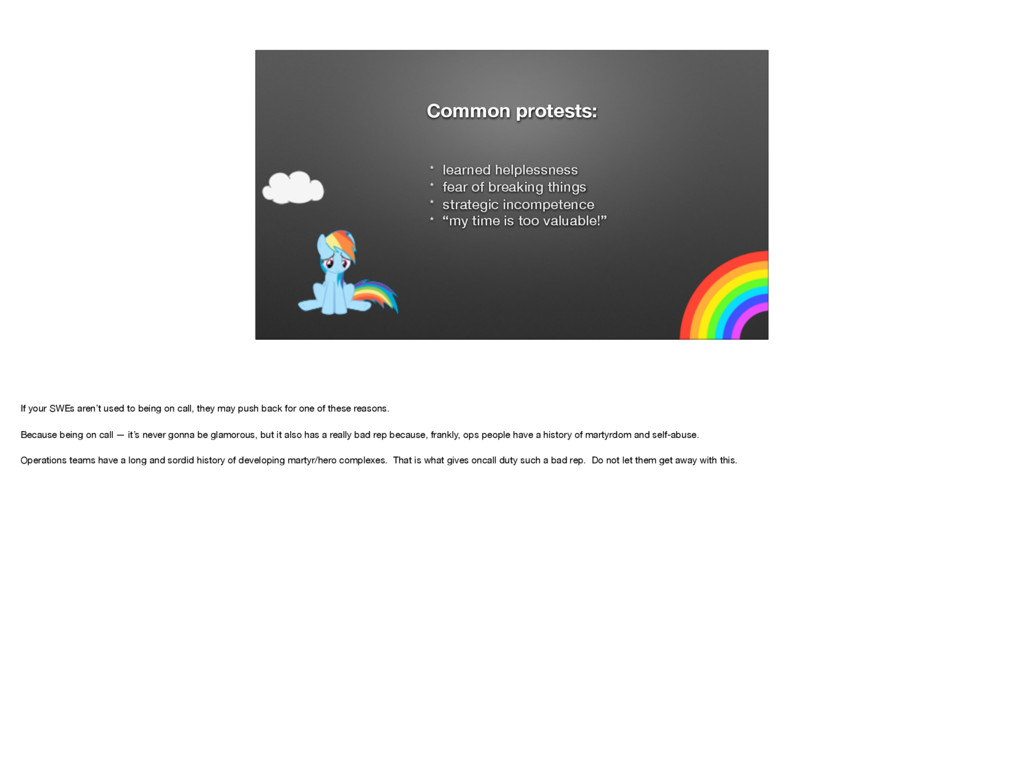{kind=link}
{kind=link}
{kind=link}
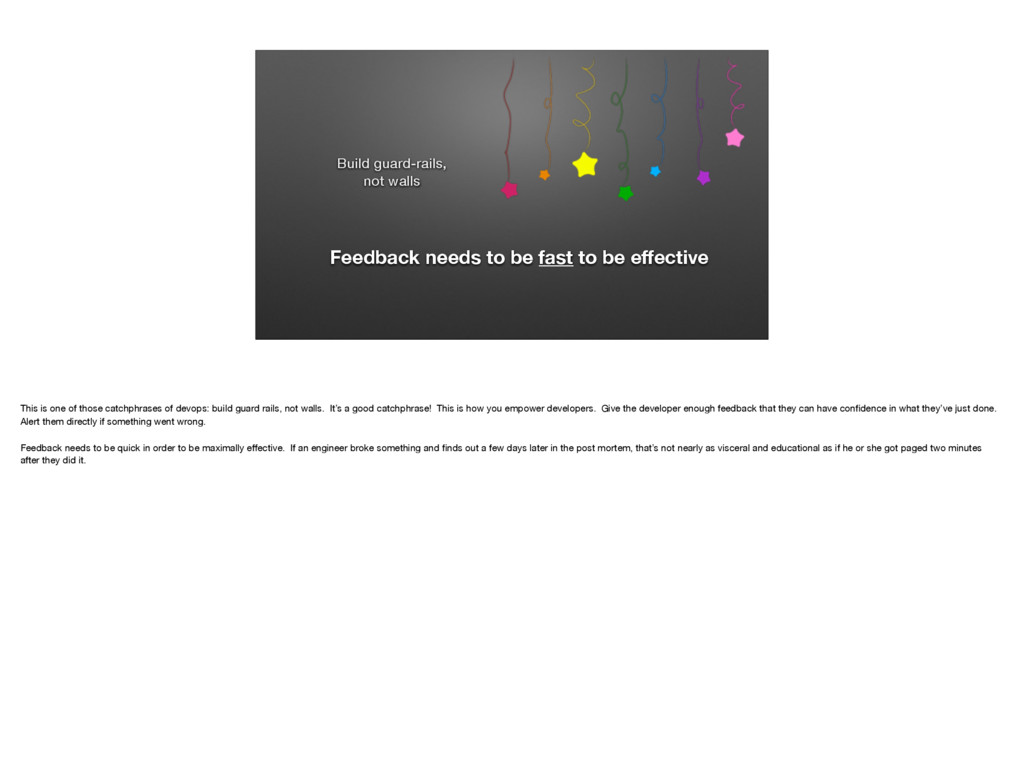{kind=link}
{kind=link}
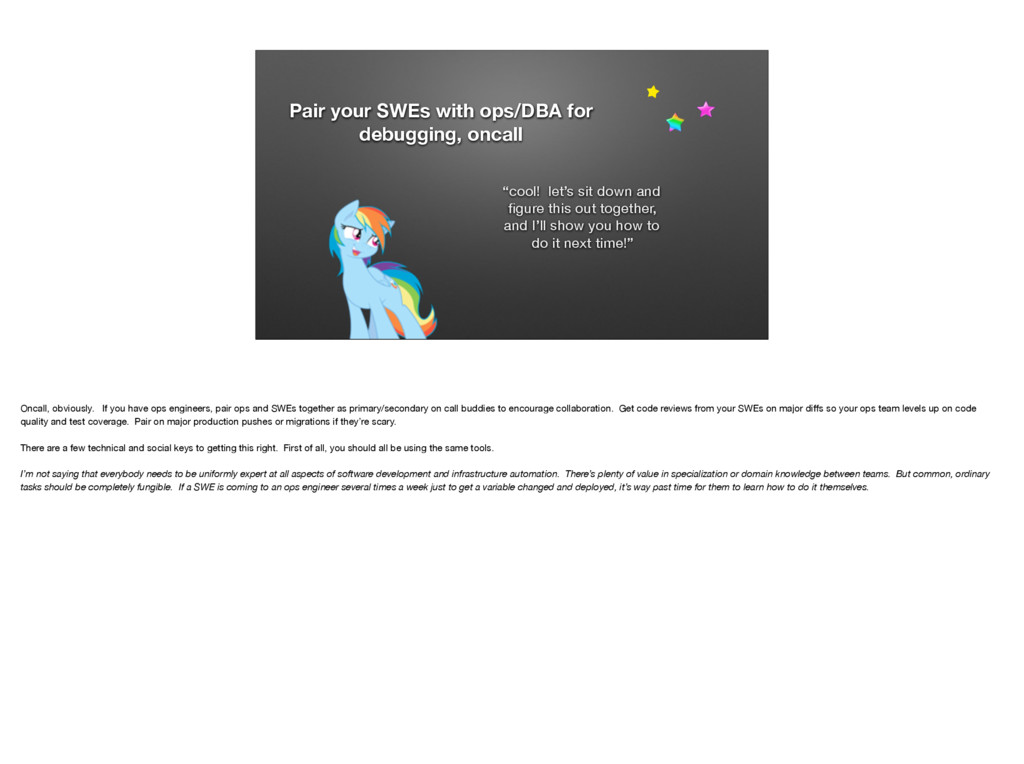{kind=link}
{kind=link}
{kind=link}
{kind=link}
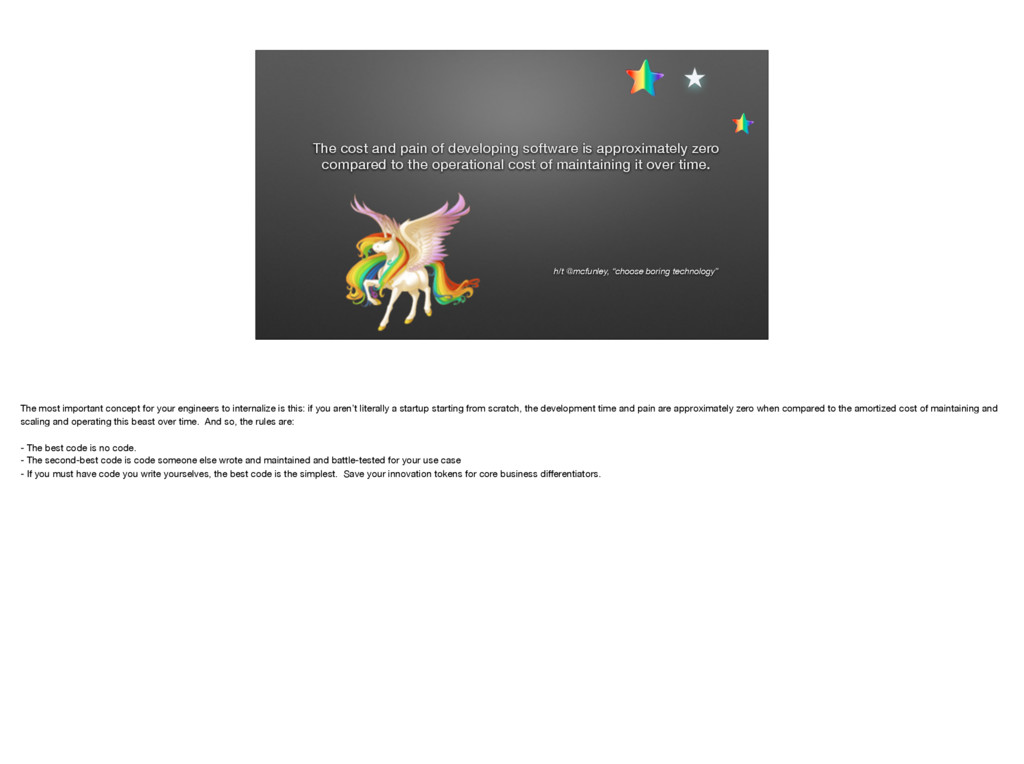{kind=link}
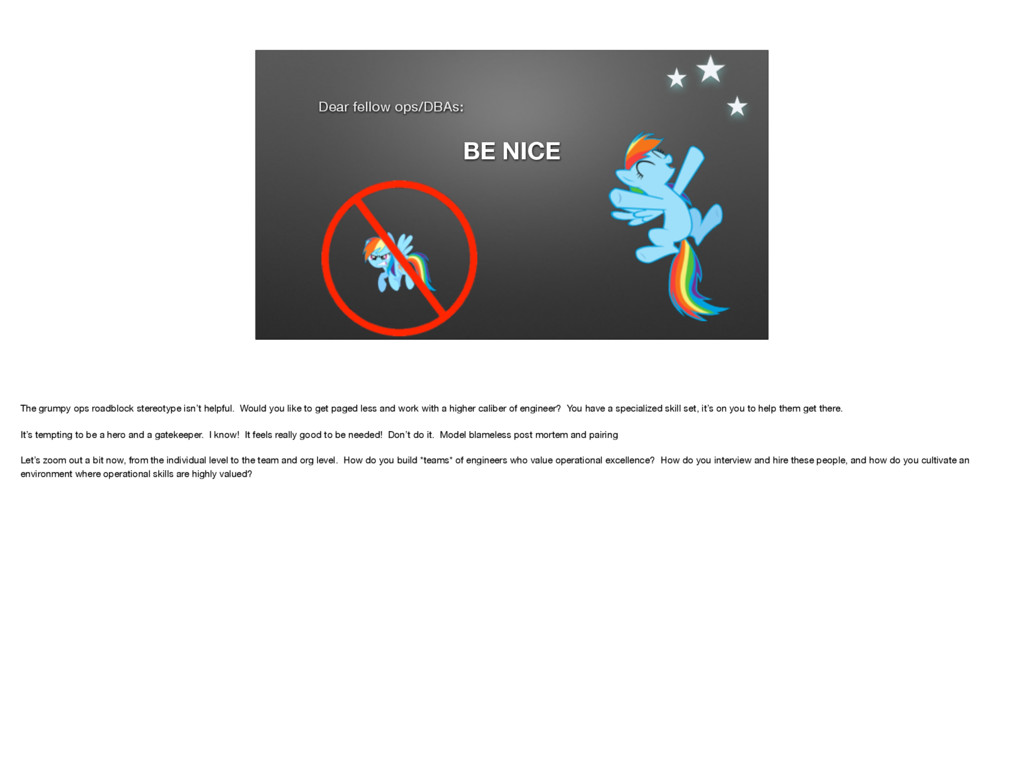{kind=link}
{kind=link}
{kind=link}
{kind=link}
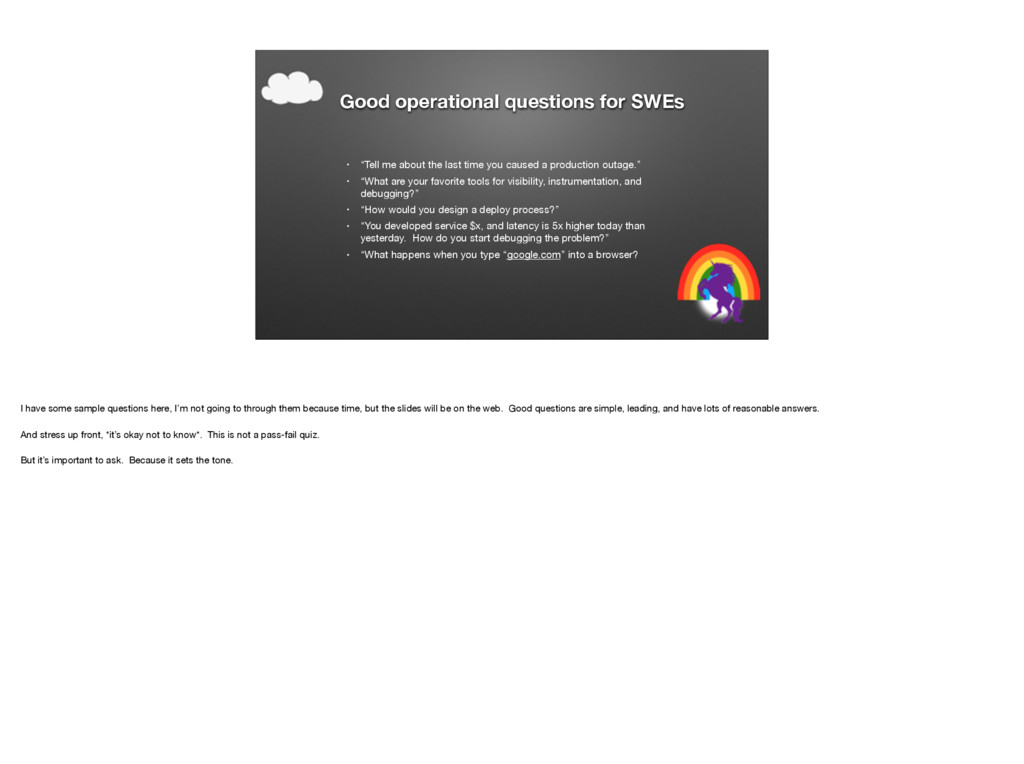{kind=link}
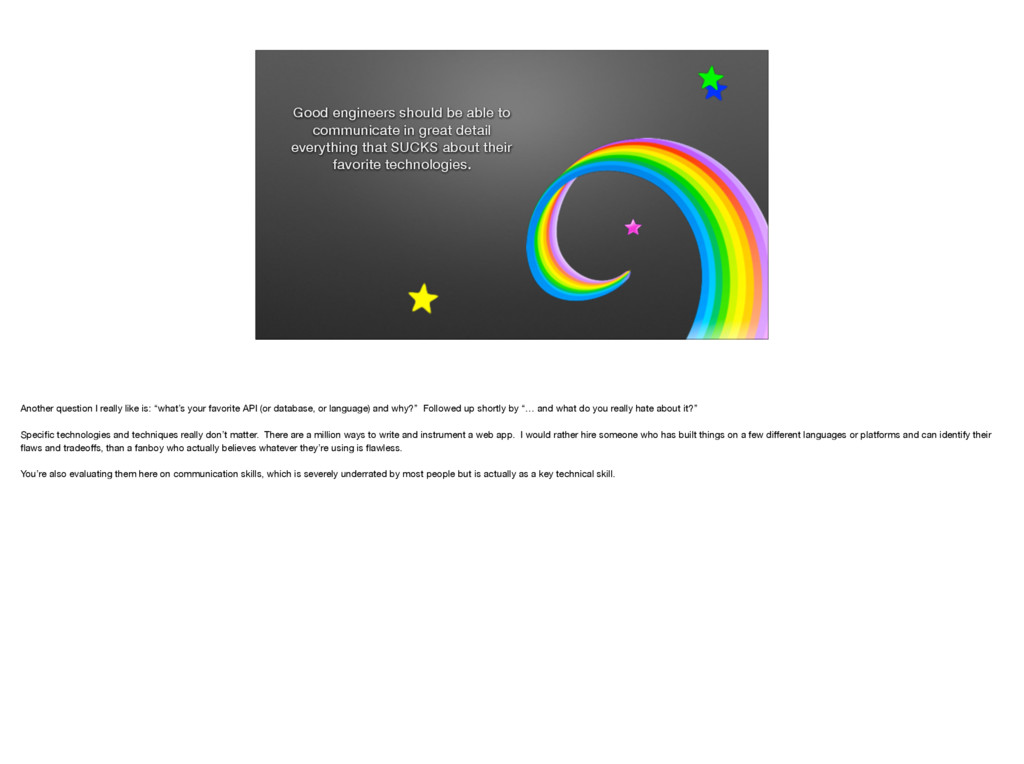{kind=link}
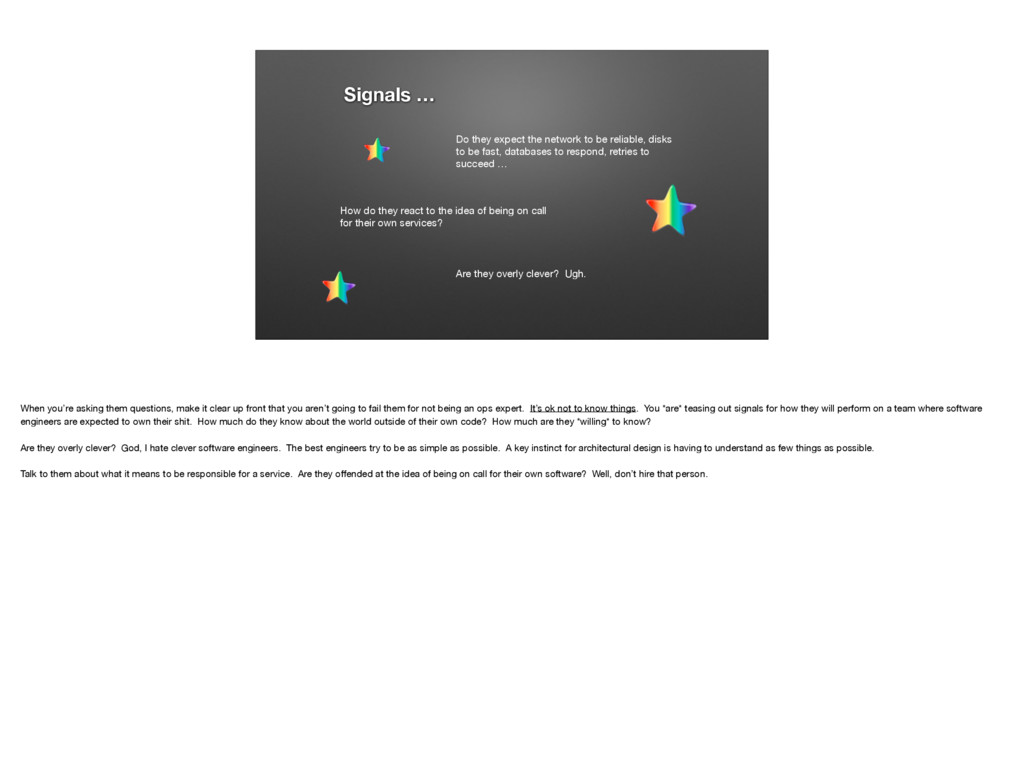{kind=link}
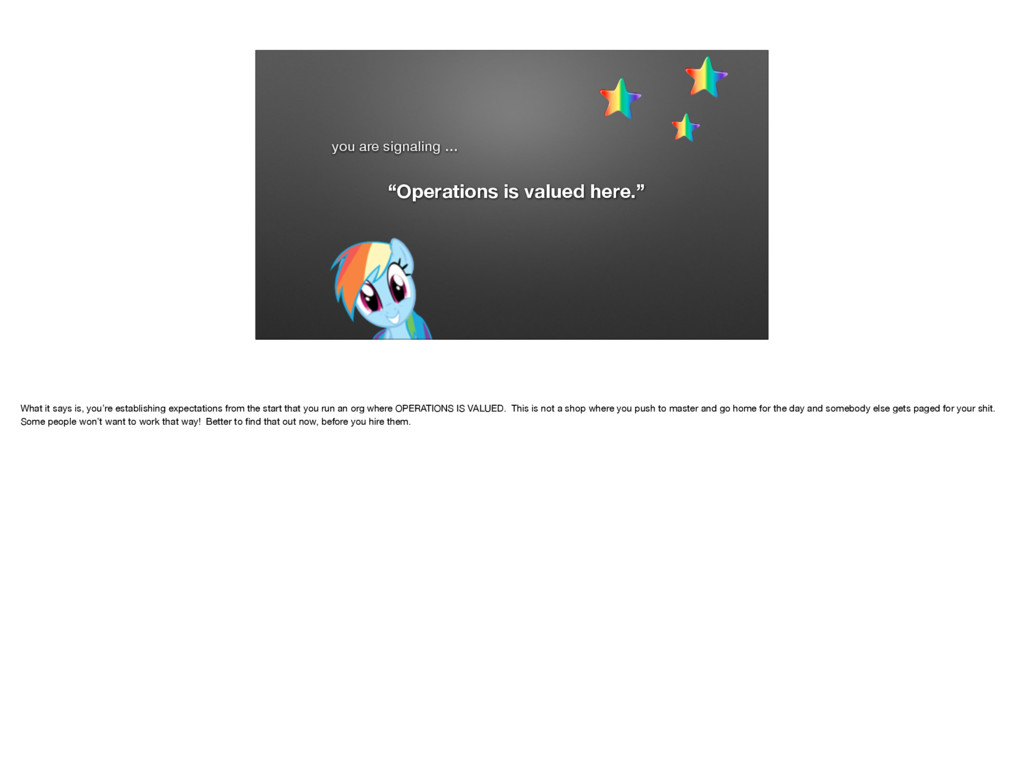{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
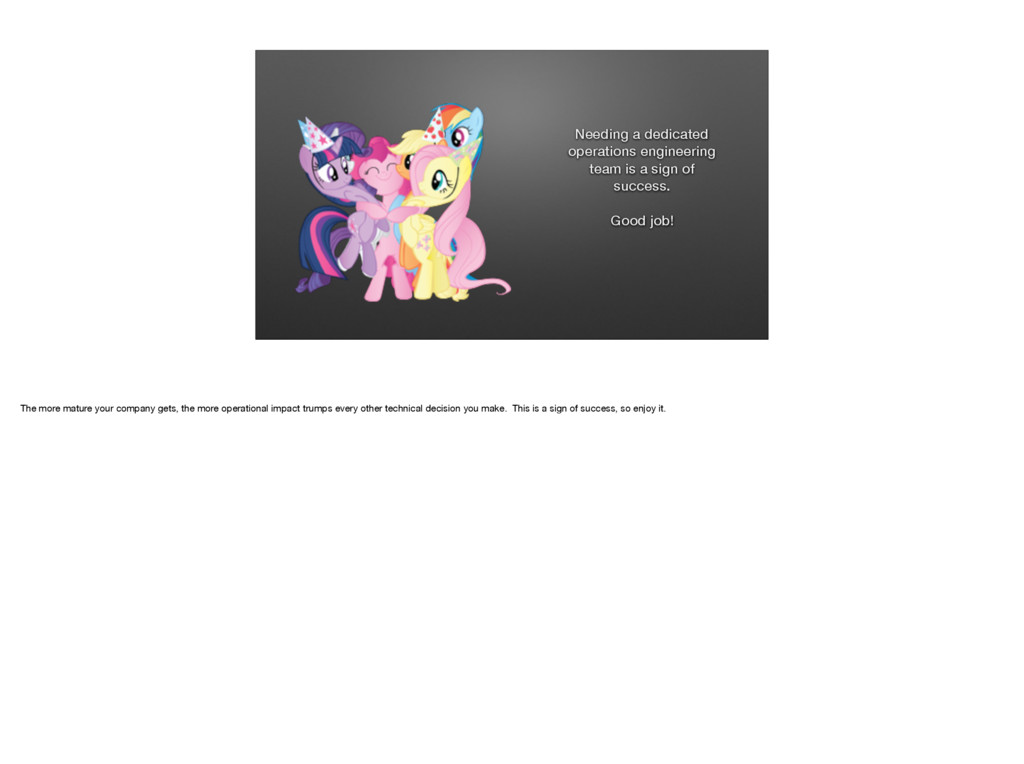{kind=link}
{kind=link}
{kind=link}
{kind=link}