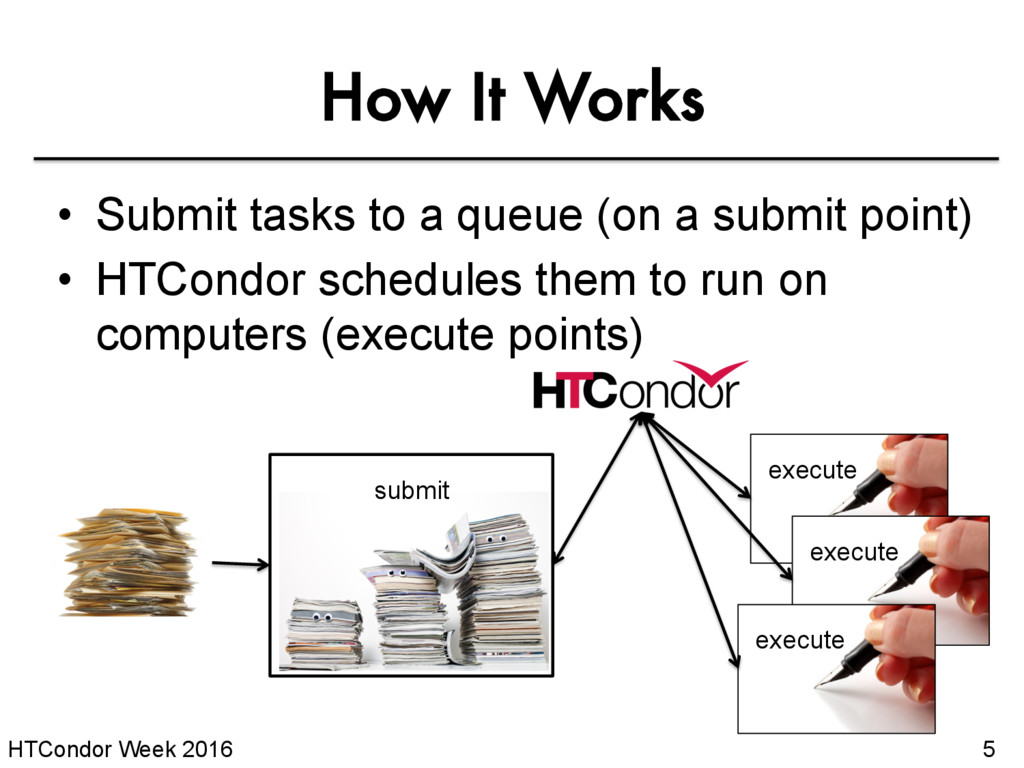
is HTCondor? • Running a Job with HTCondor • How HTCondor Matches and Runs Jobs - pause for questions - • Submitting Multiple Jobs with HTCondor • Testing and Troubleshooting • Use Cases and HTCondor Features • Automation
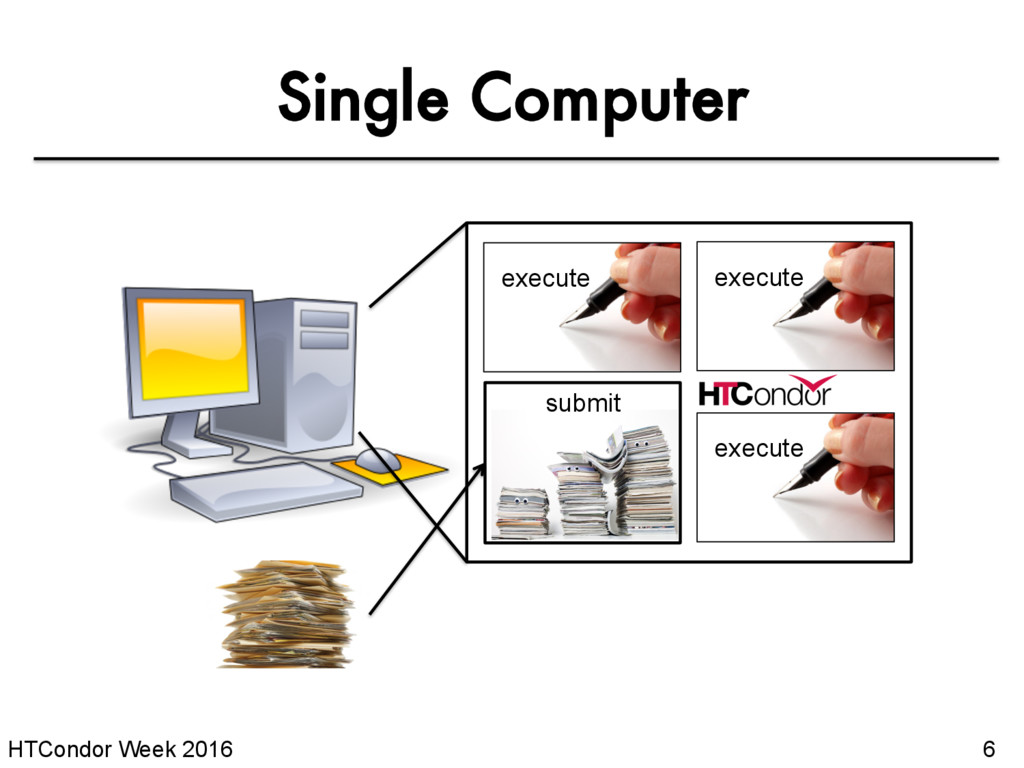
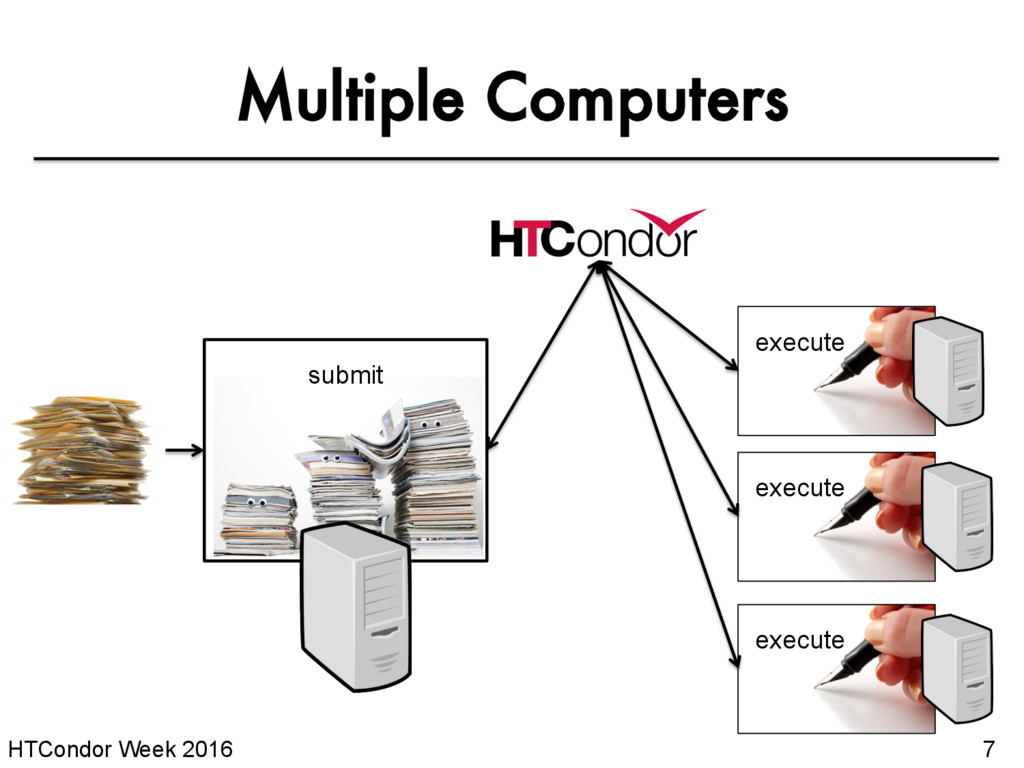
runs work on your behalf • Schedule tasks on a single computer to not overwhelm the computer • Schedule tasks on a group* of computers (which may/may not be directly accessible to the user) • Schedule tasks submitted by multiple users on one or more computers *in HTCondor-speak, a “pool”
of this tutorial, we are assuming that someone else has set up HTCondor on a computer/computers to create a HTCondor “pool”. • The focus of this talk is how to run computational work on this system. Setting up an HTCondor pool will be covered in “Administering HTCondor”, by Greg Thain, at 1:05 today (May 17)
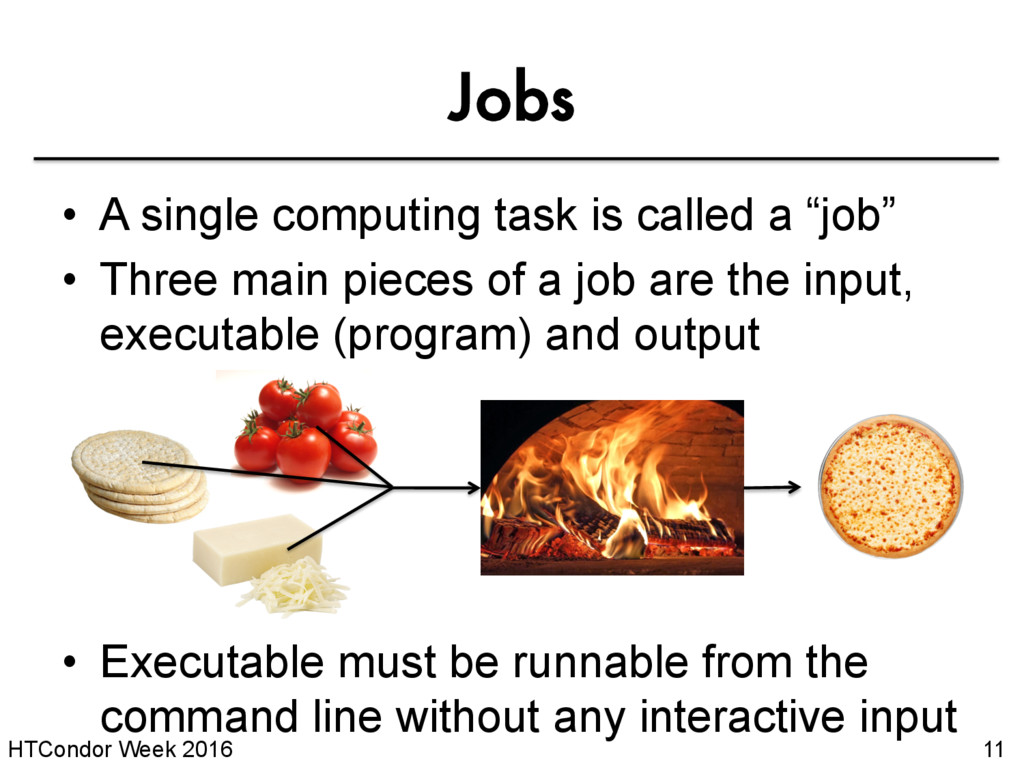
is called a “job” • Three main pieces of a job are the input, executable (program) and output • Executable must be runnable from the command line without any interactive input
we will be using an imaginary program called “compare_states”, which compares two data files and produces a single output file. wi.dat compare_ states us.dat wi.dat.out $ compare_states wi.dat us.dat wi.dat.out
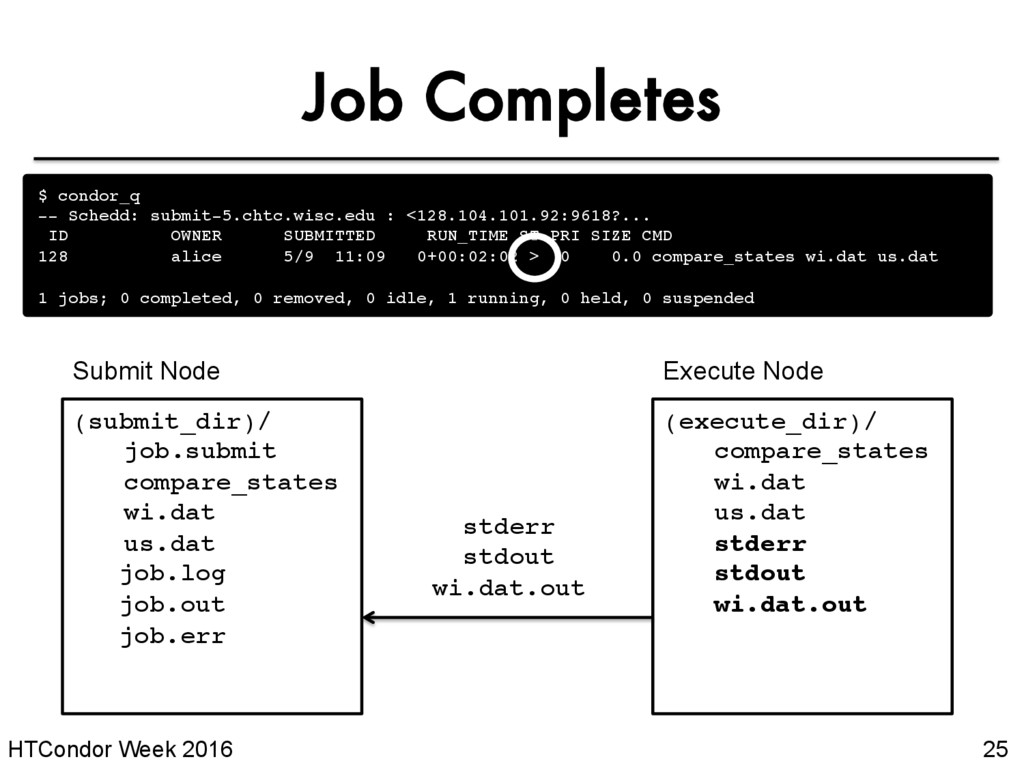
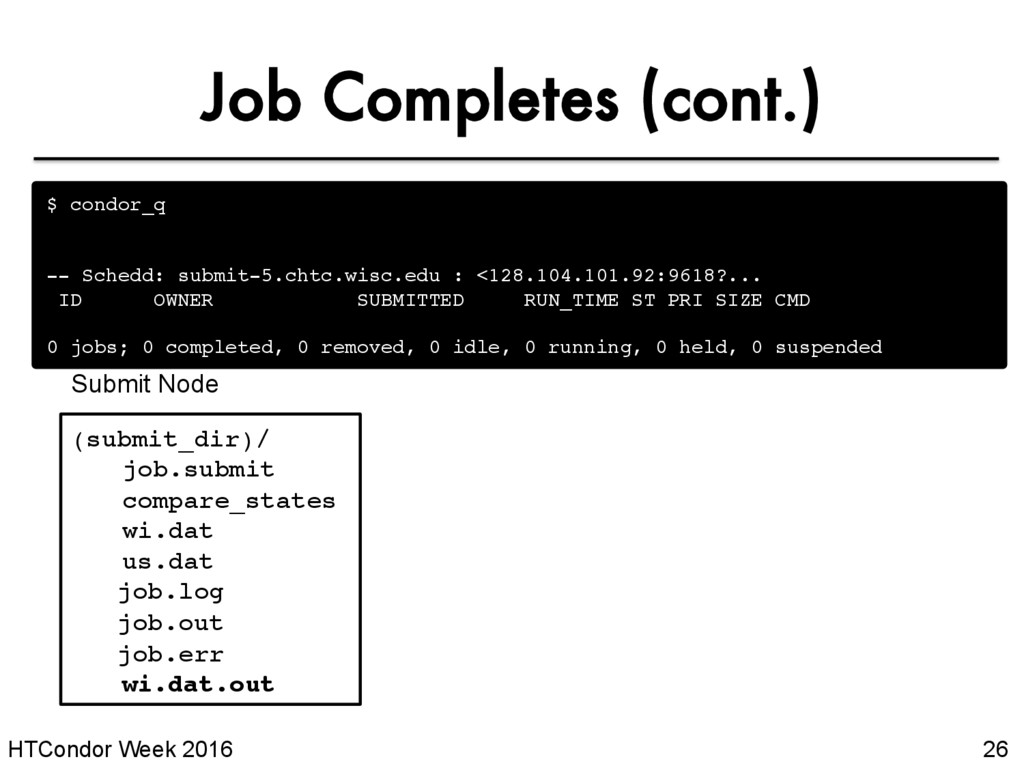
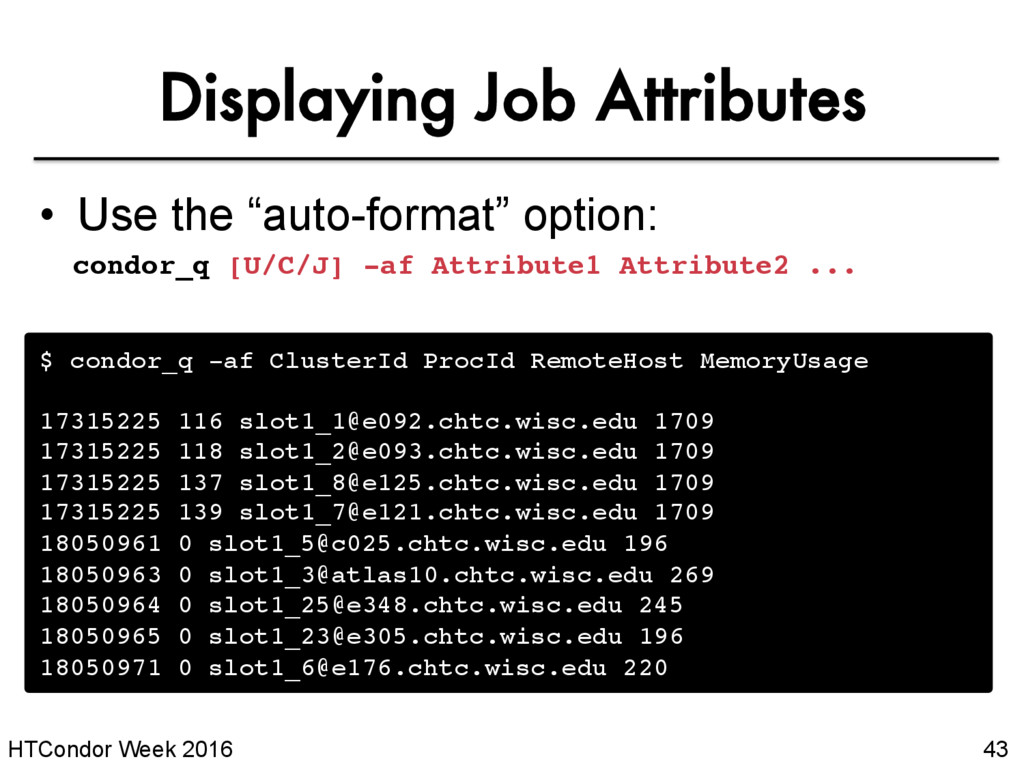
user’s job only* • Constrain with username, ClusterId or full JobId, which will be denoted [U/C/J] in the following slides $ condor_q -- Schedd: submit-5.chtc.wisc.edu : <128.104.101.92:9618?... ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 128.0 alice 5/9 11:09 0+00:00:00 I 0 0.0 compare_states wi.dat us.dat 1 jobs; 0 completed, 0 removed, 1 idle, 0 running, 0 held, 0 suspended * as of version 8.5 JobId = ClusterId .ProcId
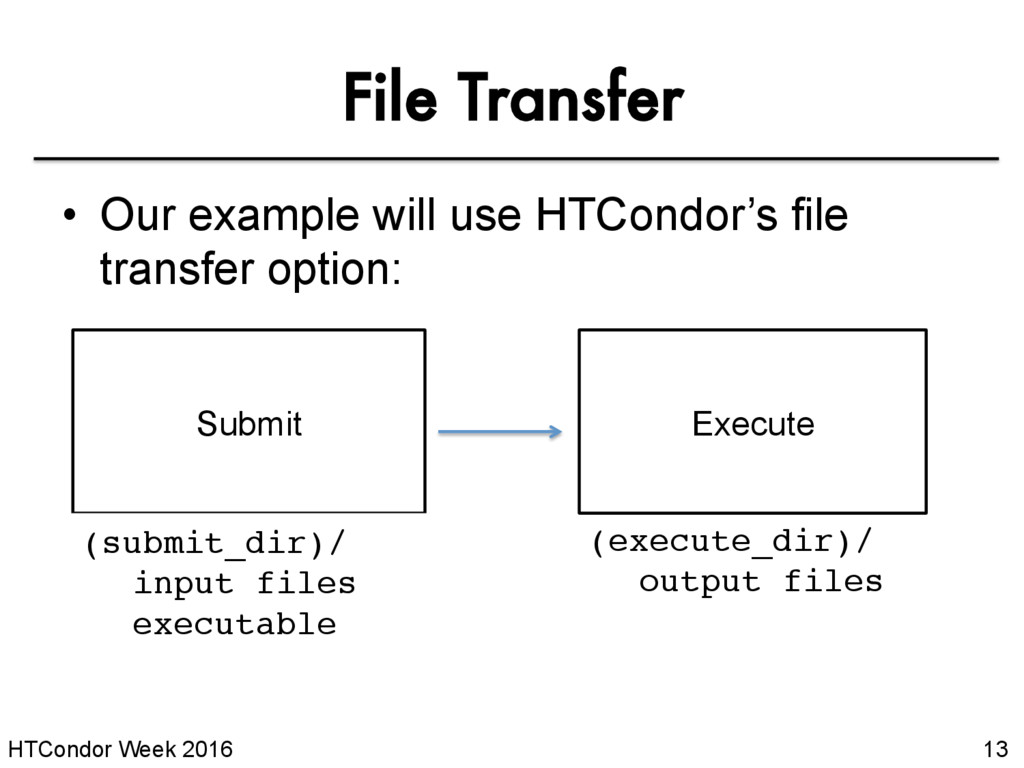
file may be dictated by infrastructure + configuration • For example: file transfer – previous example assumed files would need to be transferred between submit/execute – not the case with a shared filesystem should_transfer_files = NO should_transfer_files = YES
has a shared filesystem, where file transfer is not enabled, the submit directory and execute directory are the same. shared_dir/ input executable output Submit Execute Submit Execute
always using a part of a computer, not the whole thing • Very important to request appropriate resources (memory, cpus, disk) for a job whole computer your request
system has default CPU, memory and disk requests, these may be too small! • Important to run test jobs and use the log file to request the right amount of resources: – requesting too little: causes problems for your and other jobs; jobs might by held by HTCondor – requesting too much: jobs will match to fewer “slots”
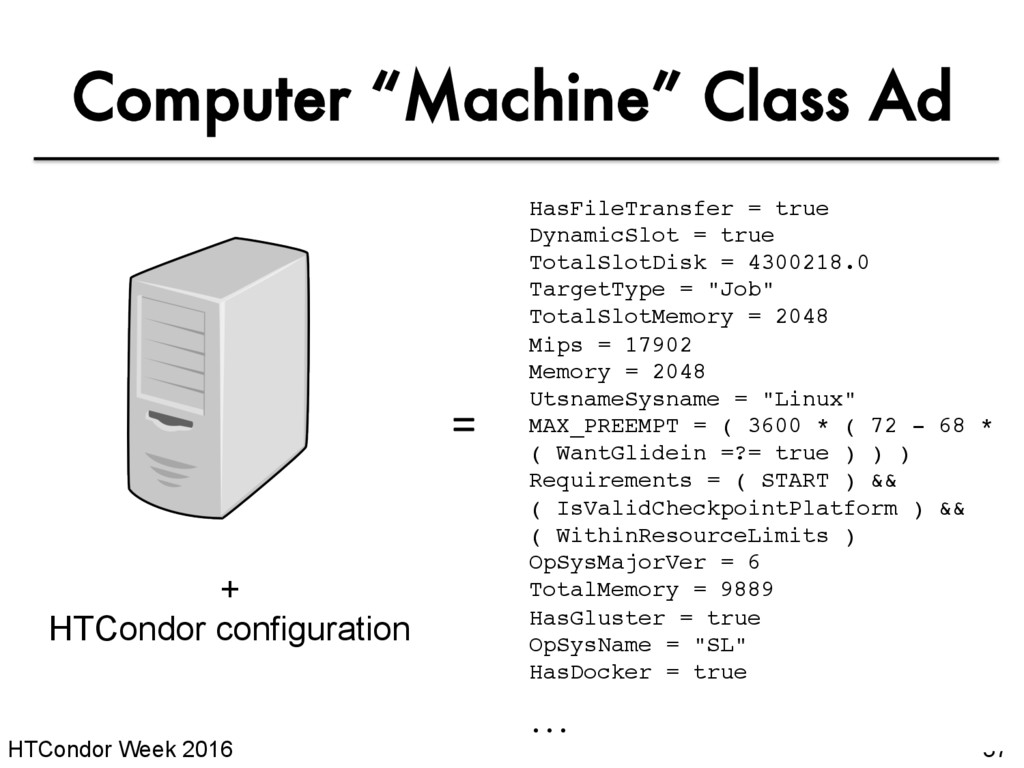
list of information about each job and each computer. • This information is stored as a “Class Ad” • Class Ads have the format: AttributeName = value HTCondor Manual: Appendix A: Class Ad Attributes can be a boolean, number, or string
of job log • Iwd: Initial Working Directory (i.e. submission directory) on submit node • MemoryUsage: maximum memory the job has used • RemoteHost: where the job is running • BatchName: optional attribute to label job batches • ...and more
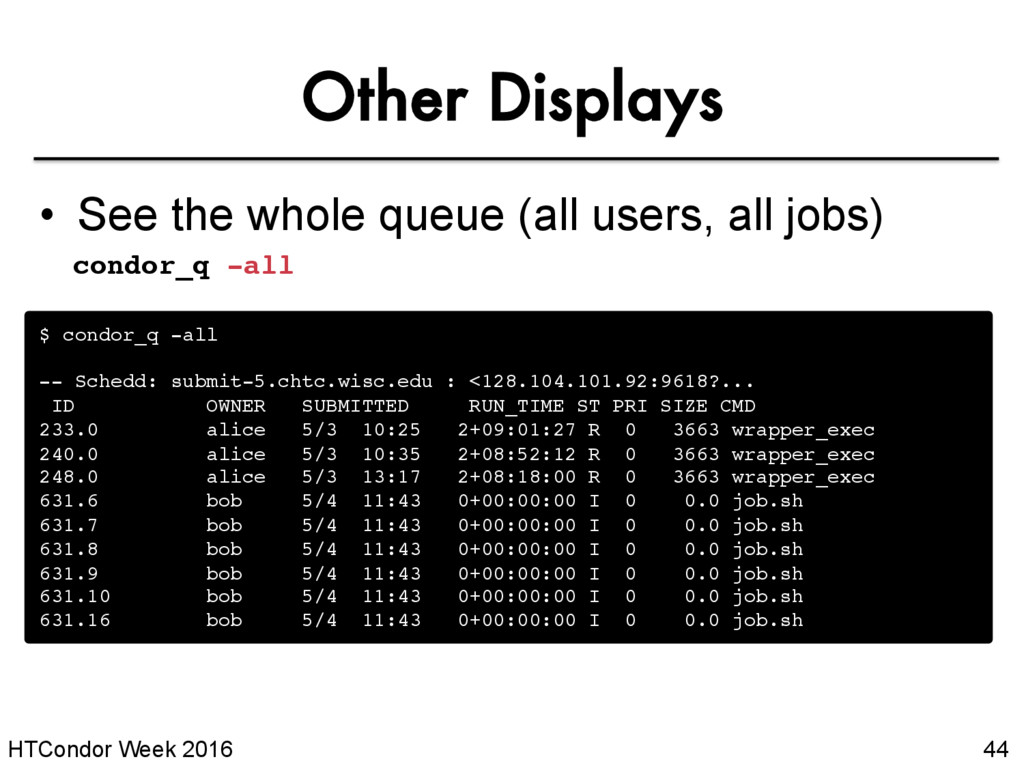
Schedd: submit-5.chtc.wisc.edu : <128.104.101.92:9618?... ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 233.0 alice 5/3 10:25 2+09:01:27 R 0 3663 wrapper_exec 240.0 alice 5/3 10:35 2+08:52:12 R 0 3663 wrapper_exec 248.0 alice 5/3 13:17 2+08:18:00 R 0 3663 wrapper_exec 631.6 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh 631.7 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh 631.8 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh 631.9 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh 631.10 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh 631.16 bob 5/4 11:43 0+00:00:00 I 0 0.0 job.sh • See the whole queue (all users, all jobs) condor_q -all
– analyze multiple data files – test parameter or input combinations – and more! • ...without having to: – start each job individually – create separate submit files for each job
and ProcId numbers are saved as job attributes • They can be accessed inside the submit file using: – $(ClusterId) – $(ProcId) queue N 128 128 128 0 1 2 ClusterId ProcId ... 128 N-1 ...
an entire directory or all the contents of a directory – transfer whole directory – transfer contents only • Useful for jobs with many shared files; transfer a directory of files instead of listing files individually transfer_input_files = shared/ transfer_input_files = shared job.submit shared/ reference.db parse.py analyze.py cleanup.py links.config (submit_dir)/
sub-directories* and use paths in the submit file to separate input, error, log, and output files. input output error log * must be created before the job is submi4ed
for each job using initialdir • Allows the user to organize job files into separate directories. • Use the same name for all input/output files • Useful for jobs with lots of output files job0 job1 job2 job3 job4
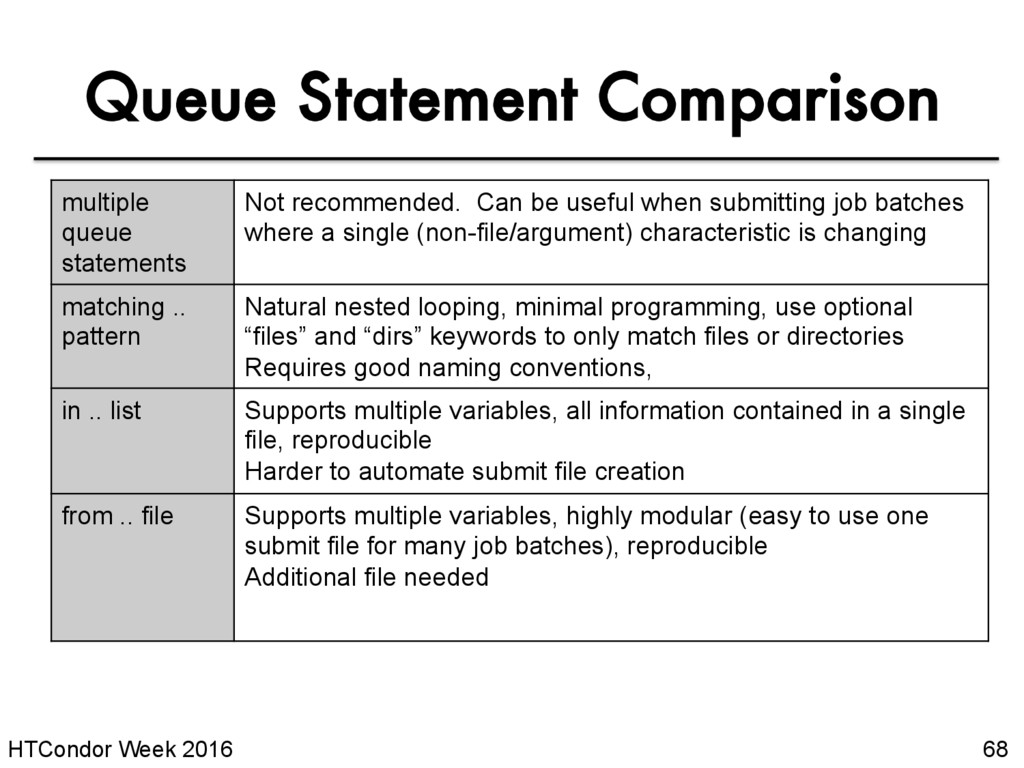
be useful when submitting job batches where a single (non-file/argument) characteristic is changing matching .. pattern Natural nested looping, minimal programming, use optional “files” and “dirs” keywords to only match files or directories Requires good naming conventions, in .. list Supports multiple variables, all information contained in a single file, reproducible Harder to automate submit file creation from .. file Supports multiple variables, highly modular (easy to use one submit file for many job batches), reproducible Additional file needed Queue Statement Comparison
can go wrong “internally”: – something happens after the executable begins to run • Jobs can go wrong from HTCondor’s perspective: – A job can’t be started at all, – Uses too much memory, – Has a badly formatted executable, – And more...
log, output and error files can provide valuable information for troubleshooting Log Output Error • When jobs were submitted, started, and stopped • Resources used • Exit status • Where job ran • Interruption reasons Any “print” or “display” information from your program Ecaptured by the operating system
large group of jobs at once, use condor_history As condor_q is to the present, condor_history is to the past $ condor_history alice ID OWNER SUBMITTED RUN_TIME ST COMPLETED CMD 189.1012 alice 5/11 09:52 0+00:07:37 C 5/11 16:00 /home/alice 189.1002 alice 5/11 09:52 0+00:08:03 C 5/11 16:00 /home/alice 189.1081 alice 5/11 09:52 0+00:03:16 C 5/11 16:00 /home/alice 189.944 alice 5/11 09:52 0+00:11:15 C 5/11 16:00 /home/alice 189.659 alice 5/11 09:52 0+00:26:56 C 5/11 16:00 /home/alice 189.653 alice 5/11 09:52 0+00:27:07 C 5/11 16:00 /home/alice 189.1040 alice 5/11 09:52 0+00:05:15 C 5/11 15:59 /home/alice 189.1003 alice 5/11 09:52 0+00:07:38 C 5/11 15:59 /home/alice 189.962 alice 5/11 09:52 0+00:09:36 C 5/11 15:59 /home/alice 189.961 alice 5/11 09:52 0+00:09:43 C 5/11 15:59 /home/alice 189.898 alice 5/11 09:52 0+00:13:47 C 5/11 15:59 /home/alice HTCondor Manual: condor_history
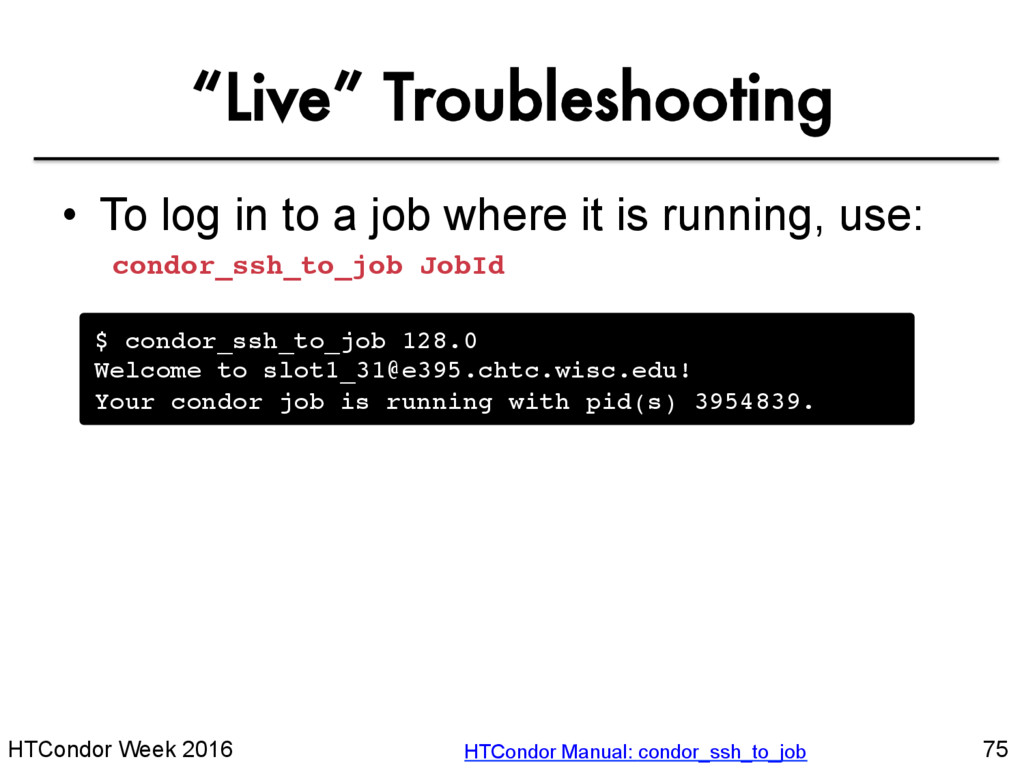
to a job where it is running, use: condor_ssh_to_job JobId $ condor_ssh_to_job 128.0 Welcome to [email protected]! Your condor job is running with pid(s) 3954839. HTCondor Manual: condor_ssh_to_job
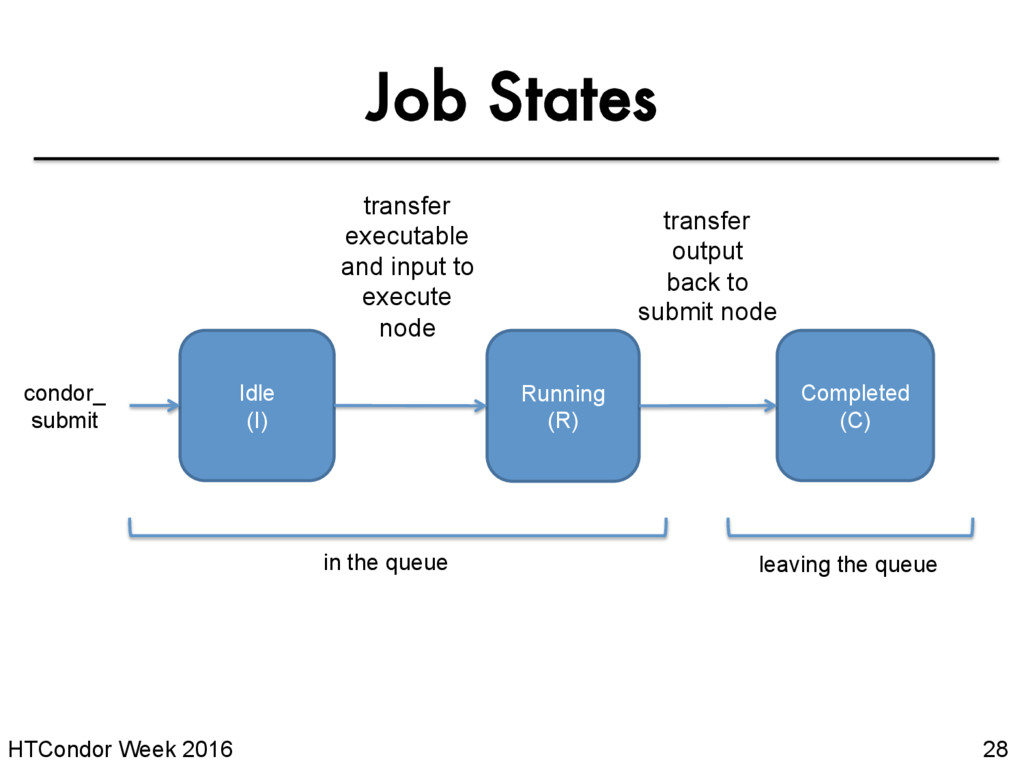
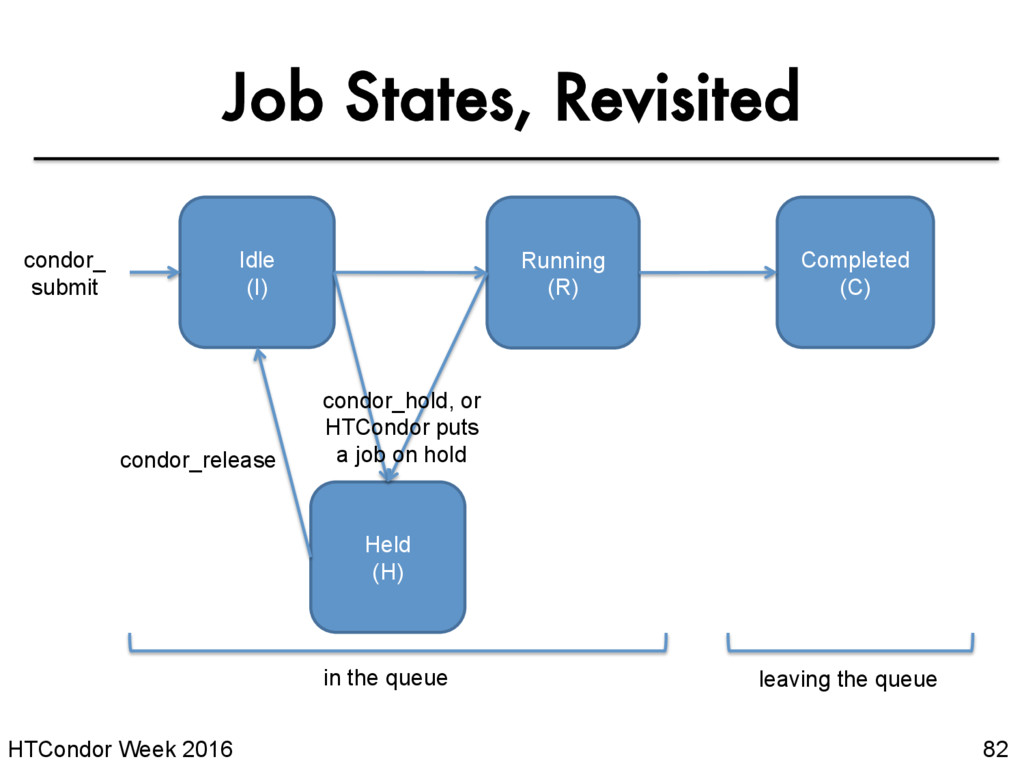
your job on hold if there’s something YOU need to fix. • A job that goes on hold is interrupted (all progress is lost) and kept from running again, but remains in the queue in the “H” state.
a job on hold, it provides a hold reason, which can be viewed with: condor_q -hold $ condor_q -hold 128.0 alice 5/2 16:27 Error from [email protected]: Job has gone over memory limit of 2048 megabytes. 174.0 alice 5/5 20:53 Error from [email protected]: SHADOW at 128.104.101.92 failed to send file(s) to <128.104.101.98:35110>: error reading from /home/alice/script.py: (errno 2) No such file or directory; STARTER failed to receive file(s) from <128.104.101.92:9618> 319.959 alice 5/10 05:23 Error from [email protected]: STARTER at 128.104.101.138 failed to send file(s) to <128.104.101.92:9618>; SHADOW at 128.104.101.92 failed to write to file /home/alice/Test_18925319_16.err: (errno 122) Disk quota exceeded 534.2 alice 5/10 09:46 Error from [email protected]: Failed to execute '/var/lib/condor/execute/slot1/dir_2471876/condor_exec.exe' with arguments 2: (errno=2: 'No such file or directory')
used more memory than requested • Incorrect path to files that need to be transferred • Badly formatted bash scripts (have Windows instead of Unix line endings) • Submit directory is over quota • The admin has put your job on hold
be edited while jobs are in the queue using: condor_qedit [U/C/J] Attribute Value • If a job has been fixed and can run again, release it with: condor_release [U/C/J] $ condor_qedit 128.0 RequestMemory 3072 Set attribute ”RequestMemory". $ condor_release 128.0 Job 18933774.0 released HTCondor Manual: condor_qedit HTCondor Manual: condor_release
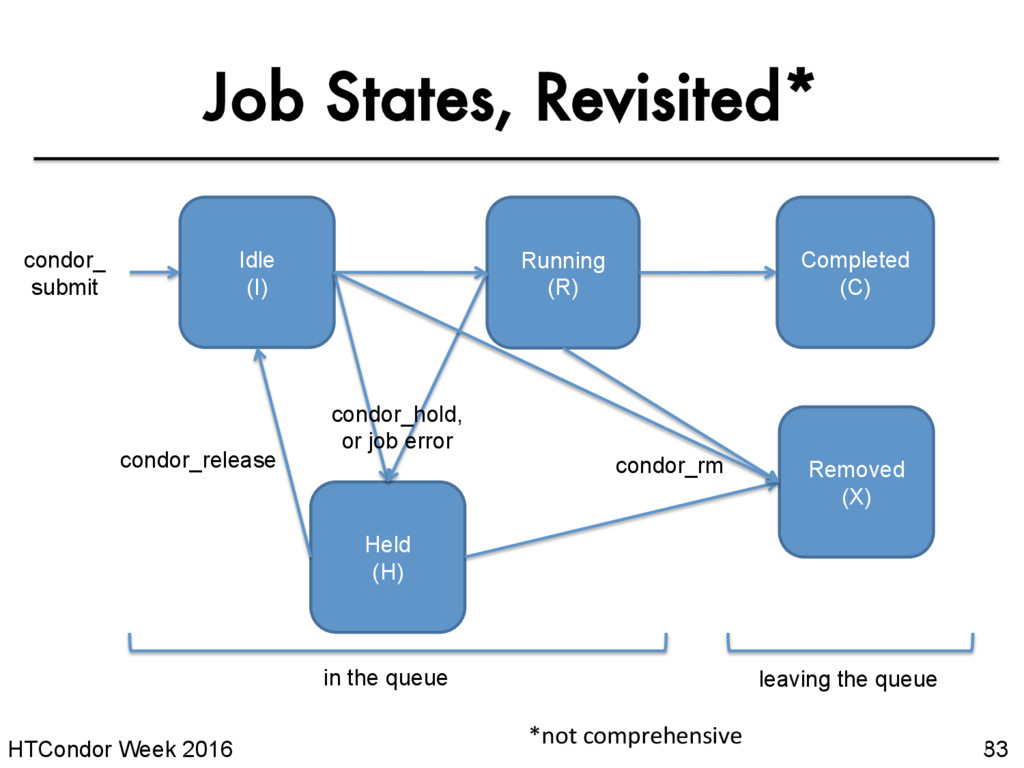
you know your job has a problem and it hasn’t yet completed, you can: – Place it on hold yourself, with condor_hold [U/C/J] – Remove it from the queue, using condor_rm [U/C/J] $ condor_hold bob All jobs of user ”bob" have been held $ condor_hold 128.0 Job 128.0 held $ condor_hold 128 All jobs in cluster 128 have been held HTCondor Manual: condor_hold HTCondor Manual: condor_rm
(R) Completed (C) condor_ submit Held (H) Removed (X) condor_rm condor_hold, or job error condor_release in the queue leaving the queue *not comprehensive
proceeds like a normal batch job, but opens a bash session into the job’s execution directory instead of running an executable. condor_submit -i submit_file • Useful for testing and troubleshooting $ condor_submit -i interactive.submit Submitting job(s). 1 job(s) submitted to cluster 18980881. Waiting for job to start... Welcome to [email protected]!
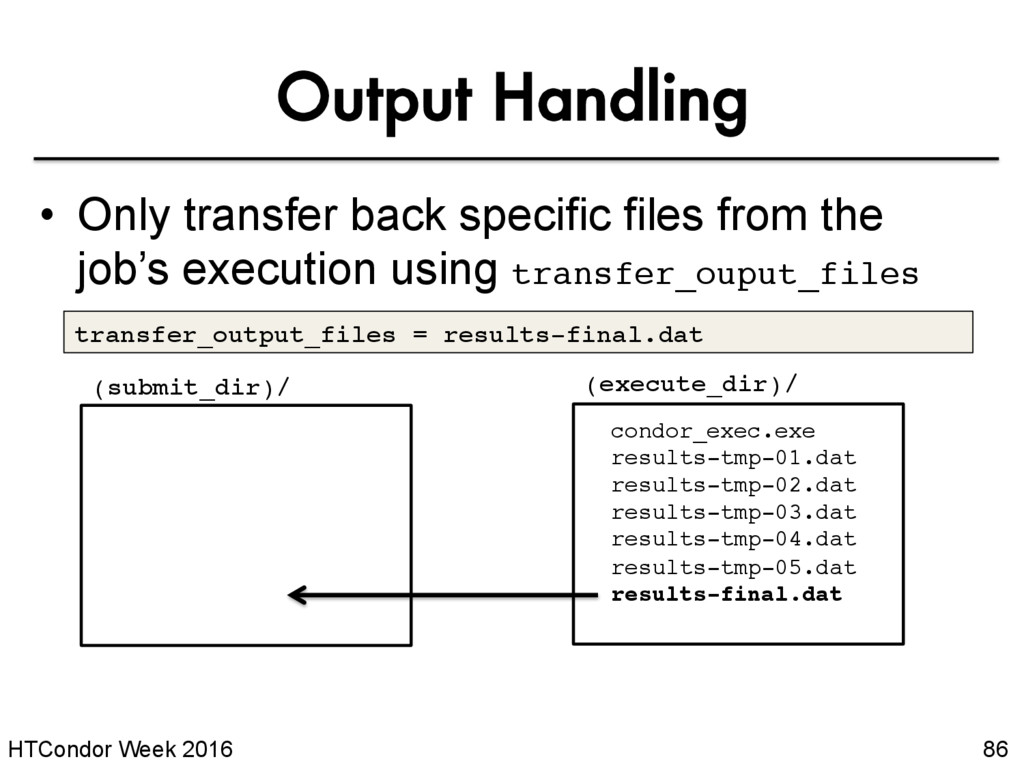
specific files from the job’s execution using transfer_ouput_files condor_exec.exe results-tmp-01.dat results-tmp-02.dat results-tmp-03.dat results-tmp-04.dat results-tmp-05.dat results-final.dat transfer_output_files = results-final.dat (submit_dir)/ (execute_dir)/
that is interrupted will start from the beginning if it is restarted. • It is possible to implement self- checkpointing, which will allow a job to restart from a saved state if interrupted. • Self-checkpointing is useful for very long jobs, and being able to run on opportunistic resources.
intermediate states to a checkpoint file – Always check for a checkpoint file when starting • Add HTCondor option that a) saves all intermediate/output files from the interrupted job and b) transfers them to the job when HTCondor runs it again when_to_transfer_output = ON_EXIT_OR_EVICT
“universes” for running specialized job types HTCondor Manual: Choosing an HTCondor Universe • Vanilla (default) – good for most software HTCondor Manual: Vanilla Universe • Set in the submit file using: universe = vanilla
code (C, fortran) that can be statically compiled with condor_compile HTCondor Manual: Standard Universe • Java – Built-in Java support HTCondor Manual: Java Applications • Local – Run jobs on the submit node HTCondor Manual: Local Universe
Run jobs inside a Docker container HTCondor Manual: Docker Universe Applications • VM – Run jobs inside a virtual machine HTCondor Manual: Virtual Machine Applications • Parallel – Used for coordinating jobs across multiple servers (e.g. MPI code) – Not necessary for single server multi-core jobs HTCondor Manual: Parallel Applications
that use multiple cores on a single computer can be run in the vanilla universe (parallel universe not needed): • If there are computers with GPUs, request them with: request_cpus = 16 request_gpus = 1
manages jobs based on its configuration • You can use options that will customize job management even further • These options can automate when jobs are started, stopped, and removed.
of jobs fail with a known error code; if they run again, they complete successfully. • Solution: If the job exits with the error code, leave it in the queue to run again on_exit_remove = (ExitBySignal == False) && (ExitCode == 0)
job should run in 2 hours or less, but a few jobs “hang” randomly and run for days • Solution: Put jobs on hold if they run for over 2 hours, using a periodic_hold statement periodic_hold = (JobStatus == 2) && ((CurrentTime - EnteredCurrentStatus) > (60 * 60 * 2)) job is running 2 hours How long the job has been running, in seconds
to previous): A few jobs are being held for running long; they will complete if they run again. • Solution: automatically release those held jobs with a periodic_release option, up to 5 times periodic_release = (JobStatus == 5) && (HoldReason == 3) && (NumJobStarts < 5) job is held job was put on hold by periodic_hold job has started running less than 5 times
are repetitively failing • Solution: Remove jobs from the queue using a periodic_remove statement periodic_remove = (NumJobsStarts > 5) job has started running more than 5 times
these pieces together, the following lines will: – request a default amount of memory (2GB) – put the job on hold if it is exceeded – release the the job with an increased memory request request_memory = ifthenelse(MemoryUsage =!= undefined,(MemoryUsage * 3/2), 2048) periodic_hold = (MemoryUsage >= ((RequestMemory) * 5/4 )) && (JobStatus == 2) periodic_release = (JobStatus == 5) && ((CurrentTime - EnteredCurrentStatus) > 180) && (NumJobStarts < 5) && (HoldReasonCode =!= 13) && (HoldReasonCode =!= 34)
time • EnteredCurrentStatus: time of last status change • ExitCode: the exit code from the job • HoldReasonCode: number corresponding to a hold reason • NumJobStarts: how many times the job has gone from idle to running • JobStatus: number indicating idle, running, held, etc. • MemoryUsage: how much memory the job has used HTCondor Manual: Appendix A: JobStatus and HoldReason Codes
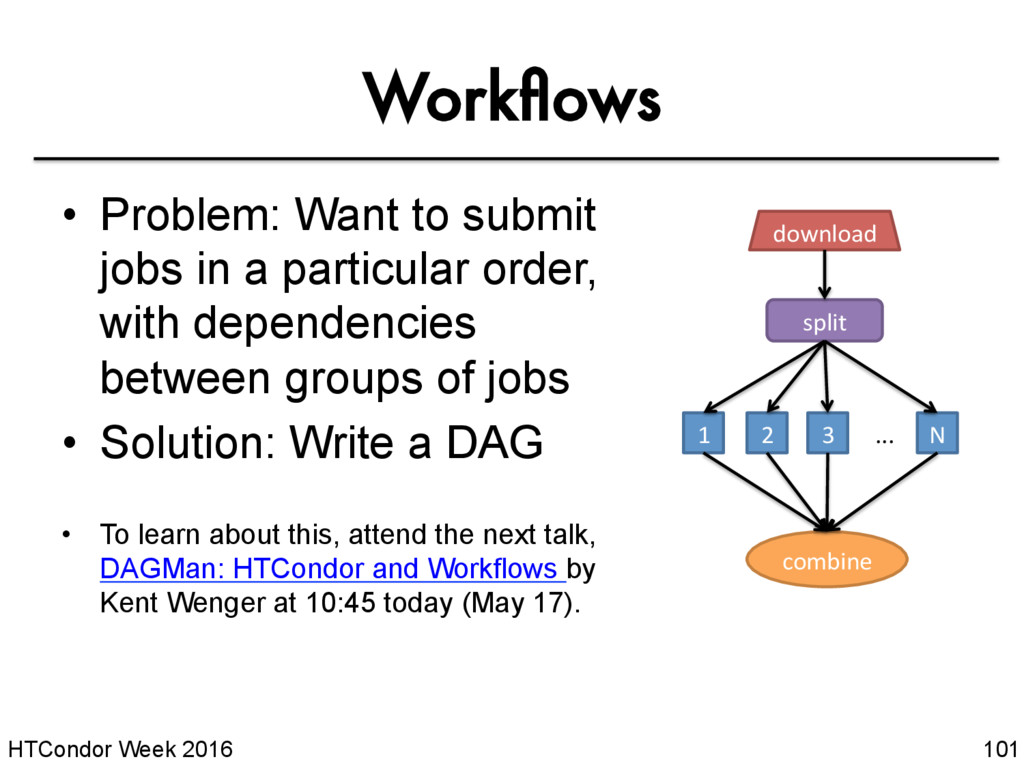
jobs in a particular order, with dependencies between groups of jobs • Solution: Write a DAG • To learn about this, attend the next talk, DAGMan: HTCondor and Workflows by Kent Wenger at 10:45 today (May 17). split 1 2 3 N combine ... download
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![HTCondor Week 2016 47 Machine Attributes $ condor_status -l [email protected]](https://files.speakerdeck.com/presentations/e378b05cacd8430096ae326ce319eac2/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}